核心结论(TL;DR)
- Orin/Thor 不会被
快速替代,本质原因不是单点算力,而是生态与工程稳定性 - M100 的意义不在"
更强 GPU",而在于开始引入数据流与专用化路径 - 智驾芯片的下一阶段竞争,不再只是
TOPS,而是数据流效率、模型-硬件协同和系统级能效 - 长期形态:
专用单元占比提升、数据流优化加深,出现智驾专用芯片。
1. 先说明立场:这是一篇个人闲聊
这一篇不是官方路线图,也不是参数评测报告;理想目前也还没有公开 M100 的具体结构细节。
文中关于 M100 的判断,主要基于公开渠道已披露的"数据流架构"方向和我的开发经验推演。
重点不是给出唯一正确答案,而是把判断路径说清楚:我为什么这么看、我在看哪些变量、哪些地方还不确定。
2. 当前平台现状和问题
2.1 平台现实:Orin + Thor 双轨并行
虽然 M100 已经明确发布、也马上要上车,但从目前量产现实看,理想AD Max当前主流仍是 NVIDIA 技术栈,主要由 单 Thor 与上一代 双 Orin 共同构成。
i6 这类热销车型仍在使用 Thor,这说明它在当前阶段依然是量产主线之一,而且有足够的保有量。
从 VLA 版本演进看,当前量产推送的 8.3 仍基于上一代 VLA 体系,而不是最新的 MindVLA-o1。
官方也提到 MindVLA-o1 会做蒸馏并下放到老平台(GTC互动回答内容),这意味着 Orin 和 Thor 至少还会共同迭代一个阶段。
Thor 和 Orin 都属于 NVIDIA 平台,很多开发与分析工具是通用的。
因此,我个人判断,NVIDIA 体系短期不会快速退场,大概率还会持续 2-4 年。
2.2 模型适配策略:帕累托最优,而不是统一模型
理想当前策略更像是在不同芯片上寻找各自的帕累托最优点,为每个平台配置对应的模型组合。
比如说同样是 MindVLA-o1 架构,模型中某一个模块参数量可以是 1B 和 1.5B 两个版本。
这样可以在保证功能完整的前提下尽量榨出性能上限,同时也意味着老平台通常是"效果上限略低",而不是"功能直接缺失"。
再举一个例子:Orin 平台可能百公里接管 5 次,Thor 平台接管 4 次,M100 平台接管 3 次。
注意,我这里用"百公里接管次数"、"模型参数量"类比只是帮助理解,不代表实测结论,请注意区分。
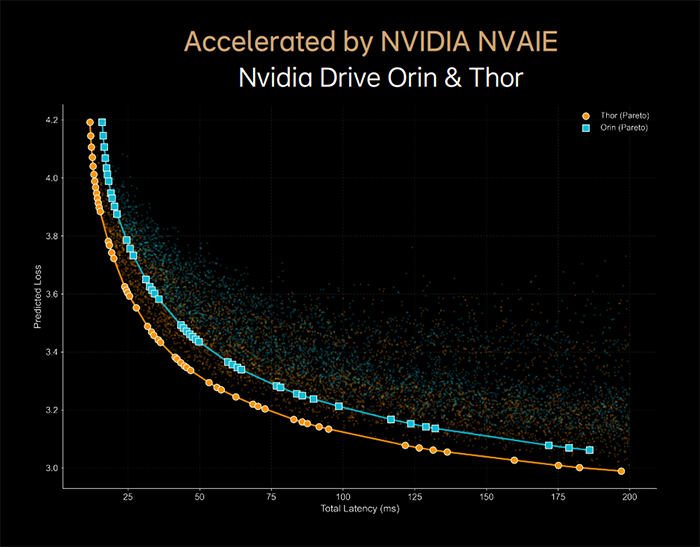
结合这张图可以更直观地理解"效果更差"的含义。
例如在同一时延点(假设 50ms)下,不同平台的预测损失可能只有小幅差别(如 3.3 vs 3.45)。
这类差异映射到真实驾驶体验时,不一定是断崖式变化,更可能是接管频次、边角场景稳定性、处理余量这类 渐进差异。
目前理想有3种智驾芯片组合,以后可能更多。既然芯片有差异,高算力芯片就没有必要为了照顾低算力芯片算力,自砍一刀强行用一样的模型;寻找各自的帕累托最优点,才是我认为更合适的方案。
2.3 纸面算力TOPS和有效算力同样重要
如果只看 双Orin-X 和 单Thor-U 的理论算力(约 500T vs 700T),差距并不算特别夸张;但实际可用性能并不只由 TOPS 决定。
例如,Thor 支持更激进的 4bit 计算,而双 Orin 存在跨芯片通信损失,因此两者有效吞吐未必按纸面参数线性对应。
这里可以把关系简单写成:
有效吞吐 ≈ 理论算力 × 利用率
这里再补一个公开口径信息:李想本人曾微博提到,数据流架构可把单芯片(M100)处理视觉任务时,有效算力提升到英伟达 Thor U 的约 3 倍,双芯片方案可到约 5-6 倍。
我理解这句话的重点不是"绝对数字",而是再次强调:有效算力提升的核心在架构与数据路径,而不只是纸面 TOPS。
所以 500T vs 700T 在工程上并不等价,芯片算力也不是简单线性叠加。
2.4 一个关键推论:退场顺序取决于"优化空间",不是代际
如果某些新模型在双 Orin 上优化空间不足,Orin 版本可能会早于 Thor 进入维护收缩期;
但如果针对双 Orin 的调度、量化和编译优化仍有收益,它也可能和 Thor 一起维持更久。
所以平台退场顺序不只看"代际先后",更取决于每个平台的可优化空间和维护投入。
3. 新芯片上车是必然:参数更好,效果也会更好
芯片代际替换是必然趋势,区别只在节奏,不在方向。
M100 已经明确上车,后续我猜测大概率会有单 M100 和双 M100 这类配置分层,用来覆盖不同车型和价位段。
不管具体落地成几个版本,新平台相对现有两套 NVIDIA 平台,大方向一定是性能更高、余量更大。
这个"更好"不只体现在峰值算力,也体现在时延、稳定性和模型规模上限这些长期体验指标。
另外,M100 也不会是终极版本芯片。
后面一定还会继续迭代(比如 M200、M300 这类方向),M100 未来也会进入被替换周期。
所以消费电子和智能车的选择逻辑本质上还是那句老话:早买早享受,晚买享配置或价格优势。
4. 为什么新芯片更快:数据流架构与异构计算视角
先说我的核心判断:新芯片快,不只是算力数字更大,更关键是数据流组织方式更高效。
有效算力的提升,通常是制程、芯片架构、数据架构、编译调度、算法协同一起作用的结果,而不是单一参数提升。
如果数据搬运、访存路径、调度策略不改,单纯堆算力很快就会碰到收益上限。智驾系统本质上是软硬件协同工程,任何一个短板都会触发"木桶效应"。
4.1 先把三类计算体系摆清楚
这里我用一个简化视角看三类路线:CPU / GPU / ASIC。
- CPU:通用控制能力强,灵活,但不适合高吞吐并行推理。
- GPU:并行能力强,生态成熟,是当前智驾量产的主力计算底座。
- ASIC:专用路径效率最高,适合高频固定工作负载,长期看更容易做极致能效。
4.2 拿比特币挖矿做类比
比特币挖矿这件事,实际走过的路非常接地气,基本就是"谁电费低、谁机器效率高,谁就能活下来"。
- 早期 CPU 挖矿:那时候用家用电脑就能参与,很多人是"顺手挖一下"。
- 后来 GPU 挖矿:显卡并行能力强,同样电费下算得更多,CPU 很快被打掉。
- 最后 ASIC 主导:比特币这种固定算法场景,专用矿机效率最高,结果就是行业基本只剩 ASIC 在打。
所以现在回头看,这条演进路径其实很一致:
任务越固定、规模越大,大家越不会继续用"通用但不高效"的方案,而是会往"专用化 + 极致能效"走。
除了挖矿,图像处理 ISP、视频编解码这些方向,本质上也在重复同样的迭代逻辑。
4.3 为什么 ASIC 在固定负载下更有时延/能效优势:本质是弱化冯诺依曼瓶颈
ASIC 在固定算子、固定数据路径的任务中,往往更容易获得更低时延或更高能效。
通用架构为了兼容各种任务,会把不少晶体管花在通用控制能力上(比如复杂调度、缓存层级、控制逻辑);这些能力很重要,但在固定任务里不一定都能转化成有效吞吐。
而 ASIC 可以把更多晶体管直接投到"有效计算路径 + 片上数据通路"上,让数据按流水线持续流动,减少指令调度和内存往返开销。
所以在固定任务里,ASIC 的时延或能效通常更有优势,但不代表在所有场景下吞吐都更高。
另一个很实际的好处是:在同等功能目标下(尤其是 ASIC),往往可以用更少晶体管实现核心能力;或者在相同晶体管预算下,做出更高吞吐和更低功耗。
4.4 数据流架构是什么
放到智驾芯片上,这个规律同样成立:围绕核心算法做专用电路和数据通路定制。
从硬件级别看,数据流架构本质上也是在关键路径上尽量脱离传统冯诺依曼式的"取指令-访存-执行-回写"组织方式。
先明确一点:数据流架构不是"某一种芯片",而是一种围绕算法与数据路径做联合设计的执行与调度方法。
它关注的不是单纯把 TOPS 做大,而是围绕数据搬运、片上复用、执行流水与同步开销做系统优化,让数据少搬运、少等待、少回写,让算子在流水线上连续跑起来。
GPU 也能做数据流优化,但其底层目标仍是通用并行;与之相比,专用单元可围绕固定高频路径做更深的硬件/调度协同。
所以我更愿意把它理解成"算力中心"到"数据路径中心"的转变。
重点不只是把 TOPS 做大,而是把整条链路打通:
- 传感器到模型输入的路径更短。
- 中间特征尽量本地复用,减少反复读写。
- 算子顺序贴合流水线,减少同步阻塞。
这也是为什么很多时候纸面算力没翻倍,端到端时延却明显下降。
真正拖慢系统的,除了模型算子本身,还有数据在不同模块之间来回搬运的隐性损耗。
基于这个框架,再回头看 Orin 和 Thor 的定位会更清楚。
4.5 放在智驾上怎么理解 Orin / Thor / M100
NVIDIA 的 Orin 和 Thor,本质上是以 GPU 为主、并集成多类专用单元的异构 SoC平台。
展望后续演进,核心不是从"GPU 架构"突然跳到另一套新范式,而是在现有异构框架内持续提升专用单元占比并加深数据流优化。
当任务与模型进一步稳定后,算力重心可能逐步向专用单元倾斜,GPU更多承担通用并行与调度职责。
也就是说,需求会越来越明确,也越来越"逼着"架构做定制化。
原因很简单:下一阶段不是只追求能跑起来,而是要在量产条件下同时满足更高性能和更强确定性。
我理解的核心需求至少有这几条:
- 更高能效:同等功能下压功耗,给整车热设计和续航留出空间。
- 更强吞吐:支撑更大模型、更长上下文和更复杂多模态输入。
- 更高确定性:减少抖动,保证高频任务在最差情况下也可控。
- 更低系统成本:不只是芯片单价,还包括存储、散热、供电和整机 BOM。
在这些目标叠加下,单靠通用 GPU往往不够经济,最终就会走到"按算法需求做定制芯片"这一步。
所以我看未来智驾芯片,不是通用平台被替代,而是通用平台之上叠加更多专用加速单元,用分层架构去满足进一步需求。
也正因如此,M100 这类新平台会出现,并成为从通用 GPU 向更高专用化阶段过渡的关键节点。
5. 我期待的将来芯片形态
前面讲的是"为什么要走专用化",这一段我想讲"我期待什么样的专用化结果"。
5.1 先看 HC1:给我的核心启发
先说 HC1(Taalas)这条路线。
从目前披露的信息看,它最核心的理念是:Chip = Model,也就是把模型权重直接映射进芯片本身,而不是像传统 GPU 一样长期在显存里搬运权重。
HC1 更接近一种极端的 weight-stationary / in-memory 推理架构,可以视作数据流理念在权重侧固化的一种实现形态:重点不是堆更多通用算力,而是让数据尽量在片上流动,把外部搬运压到最低。
这件事的关键点:
- 把模型直接写进芯片:权重不再老是从外部内存搬来搬去。
- 存储分工更直接:
mask-ROM放固定权重,SRAM放运行时数据(如 KV Cache/LoRA)。
如果这些前提成立,它的收益就很清晰:
推理吞吐、时延和能效会有非常激进的提升(公开口径里常见数据约为 17000 tokens/s 级别,以及明显低于传统 GPU 方案的系统成本)。
这里再补一个关键对比:
- 传统 GPU 路线:模型权重主要放在 HBM,系统很容易被内存带宽卡住。
- HC1 路线:模型权重尽量放在片上 ROM,带宽瓶颈被大幅弱化,甚至在关键路径上接近"消灭"。
但 HC1 的缺点必须一起写清楚(这点非常重要):
- 可编程性极低:基本只服务特定模型,模型大改通常意味着硬件重做。
- 灵活性差:不适合多模型、多任务频繁切换的通用场景。
- 规模约束明显:当前更适合特定尺寸模型,大模型往往要靠多芯片拼接。
所以我对 HC1 的定位是:它代表的是"极端专用化 AI 硬件路线",用通用性换极致性能。
如果未来 MindVLA-oX 的某个版本在结构和参数上趋于稳定,就有机会走向类似 HC1 的 ASIC 固化路线。
5.2 再看 UE8M0:另一条可参考的路径
UE8M0 更准确地说是 microscaling FP8 体系里的 scale 编码表达,核心特征是 E8M0(8 位指数、0 位尾数),而不是对 FP8 元素格式本身(如 E4M3/E5M2)的直接替代。
为什么这个方向有价值?因为它在工程上非常"务实":
- 计算更简化:很多操作可转化为指数域处理,减少复杂浮点单元压力。
- 带宽更友好:scale 信息更轻,能明显降低传输负担。
- 可做过渡落地:在部分现有硬件上可以先跑通,但收益通常有限。
但这里要说清楚:UE8M0 也不是典型"拿来即用"的通用元素数据类型。
如果想把它的吞吐和能效优势真正吃满,通常需要芯片侧专门定制数据通路和指令支持(本质还是软硬件协同定制)。
我理解 UE8M0 的意义,不只在"精度优化",更在于它对缩放元数据存储/传输、量化流程和硬件实现友好性的工程价值。
历史上类似趋势确实出现过:
- INT8 的普及,推动了面向低比特推理的专门硬件路径。
- FP16 的普及,推动了 AI GPU 在训练和推理上的结构演进。
- BF16 的普及,推动了大模型训练侧的算子与硬件协同。
从这个角度看,UE8M0 更可能成为下一代推理链路里缩放元数据与量化工程演进中的一个候选方向。
它不一定会"一统标准",但至少提供了一个值得验证的软硬件协同路径。
所以 UE8M0 的意义,不是"再发明一颗神芯片",而是用数值体系去探索更现实的芯片适配路线。
这和 HC1 正好形成对照:一个是"硬件吃模型",一个是"模型适配硬件"。
6. 补充讨论:演化路径上的现实挑战
6.1 走向高度专用 ASIC 的过程中会遇到哪些约束?
这条路径方向明确,但推进节奏通常会受到以下现实约束:
模型迭代太快:如果模型结构和算子形态仍在高频变化,过早硬件固化会放大路线风险。多任务融合:智驾不是单一算子流水线,感知、预测、规划与控制并行时,负载不总是足够固定。工程与生态成本:工具链成熟度、开发效率、验证复杂度都会显著影响专用化推进速度。安全认证与 OTA 生命周期:车端长期维护要求较高,可更新性与可回退性往往要求保留更多通用能力。
6.2 推进"数据流"路线时还要同时解决什么问题?
数据流是关键方向,但最终效果仍取决于整条系统链路的协同:
软件栈与编译器质量:同一硬件思路下,编译调度、内核实现和算子融合能力会直接拉开差距。系统级瓶颈:传感器链路、存储系统、热设计与供电约束,任何一项都可能抵消局部算力优势。模型持续演化:当模型结构发生变化,当前最优硬件形态可能被重新排序。
7. 总结
从 Orin、Thor 到 M100,表面看是芯片代际升级,往深处看其实是智驾计算范式在变化。
这条演化并不是"纯 GPU 被替代"的故事,而是以GPU为主的异构 SoC 持续深化:一边保留通用并行与调度能力,一边把高频关键路径逐步交给更专用的数据通路和计算单元。
因此,未来智驾芯片竞争的重点,不只是"谁的 TOPS 更大",而是三件更底层的系统能力:
数据流组织能力:能否把传感器输入、特征复用、算子执行和回写路径做短、做稳、做高效。模型-硬件协同能力:能否让模型结构、量化策略、编译调度和硬件实现形成闭环优化。系统级工程能力:能否在性能之外,同时把成本、功耗、热约束、安全认证与 OTA 生命周期管理好。
同时,这条路的推进节奏也不会完全线性。模型迭代速度、多任务融合复杂度、工具链成熟度和系统约束,会决定专用化落地到底是"快进"还是"渐进"。
所以我更倾向于把 M100 看作一个阶段性信号:方向已经明确,但真正的竞争胜负,仍取决于谁能把架构、软件和工程交付长期稳定地协同起来。