快速了解部分
基础信息(英文):
- 题目: RLDX-1 Technical Report
- 时间: 2026.05
- 机构: RLWRLD, KAIST
- 3个英文关键词: VLA, Robot Policy, Dexterous Manipulation
1句话通俗总结本文干了什么事情
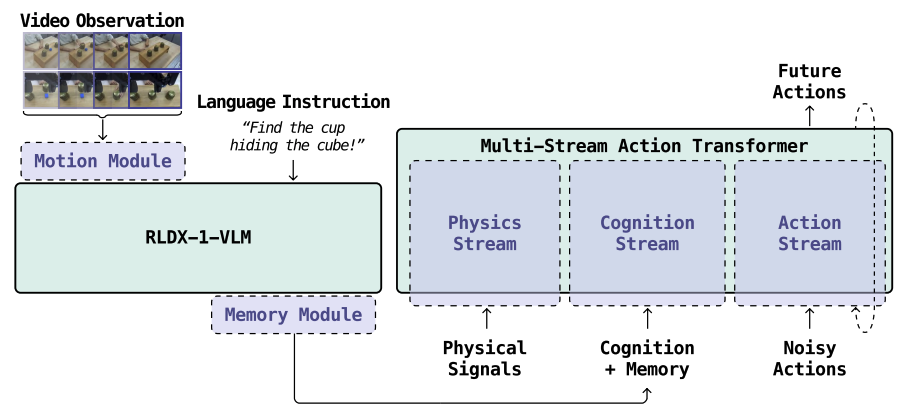
本文提出了一种名为RLDX-1的通用机器人策略模型,通过整合视觉、语言、动作以及触觉/扭矩等物理信号,并配合合成数据和推理优化,让机器人(尤其是人形机器人)能像人一样灵活地处理复杂的动态和接触丰富的操作任务。
研究痛点:现有研究不足 / 要解决的具体问题
现有的VLA模型虽然具备强大的视觉理解和泛化能力,但在处理真实世界的复杂任务时存在短板:
- 缺乏动态感知:只能处理静态画面,面对移动的物体(如传送带)无法预测轨迹。
- 缺乏长期记忆:只能看到眼前的画面,无法利用过去的历史信息做决策(如猜杯子游戏)。
- 缺乏物理感知:仅靠视觉无法感知接触力、滑动或重量变化(如插头插入、倒水),导致操作僵硬或失败。
核心方法:关键技术、模型或研究设计(简要)
核心是一个名为** Multi-Stream actioinTransformer (MSAT)的架构,它将视觉、语言、动作、物理信号(触觉/扭矩)分开处理再融合。配合 三阶段训练**(预训练+中段训练+后训练)和合成数据,让模型具备上述缺失的能力。
深入了解部分
作者想要表达什么
作者想表达:通用的机器人智能不仅需要强大的视觉语言理解能力,更需要具备运动感知、长期记忆和物理触觉这三项核心功能。通过系统性的架构设计和数据工程,RLDX-1证明了这些功能可以被统一在一个端到端的模型中,并显著提升机器人在真实复杂环境(如传送带抓取、插拔、倒水)中的操作成功率。
相比前人创新在哪里
- 架构创新 (MSAT):不同于以往将所有信息强行塞进VLM的做法,RLDX-1设计了独立的"物理流"和"认知流",既能处理物理信号,又能通过"认知token"提取视觉语言中的动作相关信息。
- 物理感知集成:明确引入了触觉和扭矩信号作为输入,并训练模型预测未来的物理信号,使其在视觉受限(如插头被手挡住)时依然能完成任务。
- 合成数据流水线:利用视频生成模型生成难以采集的稀有灵巧操作数据(如倒水、拧灯泡),并用"运动一致性过滤"保证生成的动作是物理上合理的。
解决方法/算法的通俗解释
RLDX-1的模型架构就像一个交响乐团:
- 视觉语言部分 (VLM) 是"指挥",看懂场景和听懂指令。
- 动作部分 (DiT) 是"乐手",负责具体怎么动。
- 物理流 (Physics Stream) 是"节拍器和触觉反馈",专门处理接触力和细微动作。
- 它们不是各自为战,而是通过"注意力机制"互相交流。同时,模型里还有一个"记忆模块"像备忘录一样记录过去发生的事,还有一个"运动模块"专门分析视频里的动态趋势。
解决方法的具体做法
- 数据:混合了公开数据、自家采集的带物理传感器数据、以及利用视频生成模型制作的合成数据(用于补充稀有场景)。
- 训练 :
- 预训练:在大规模多形态数据上学习通用操作。
- 中段训练:注入特定能力(如给ALLEX人形机器人加上记忆和物理感知模块,并进行训练)。
- 后训练:针对具体任务微调,甚至结合强化学习(RL)进行优化。
- 推理优化:通过静态图转换和定制内核,将推理延迟降低到43.7ms,满足实时控制需求。
基于前人的哪些方法
- Qwen3-VL:作为基础的视觉语言模型骨干。
- Flow Matching (Diffusion):用于动作生成的训练目标(类似之前的VLA模型如π0和GR00T)。
- Memory VLA:借鉴了之前关于在VLA中加入记忆模块的研究思路。
- RECAP:后训练阶段的强化学习框架基于RECAP方法,并改进了其中的Critic(评判器)设计。
实验设置、数据、评估方式、结论
- 评估方式:在模拟环境(LIBERO, RoboCasa)和真实机器人(ALLEX人形机器人、Franka Research 3机械臂)上进行测试。
- 数据:使用了Open-X-Embodiment、DROID等公开数据集,以及自采的ALLEX和Franka数据,还生成了合成数据。
- 结论 :
- 在模拟基准测试中全面超越了π0.5、GR00T N1.6等前沿模型。
- 在真实世界的ALLEX人形机器人 任务中(如传送带抓取、找卡片、倒水),成功率高达86.8%,而对比的基线模型(π0.5和GR00T)仅在40%左右。
- 证明了引入物理信号和记忆模块能显著提升特定任务(如插拔、猜杯子)的成功率。
提到的同类工作
- GR00T N1.6 (NVIDIA):主要的对比基线,同样是VLA模型,但在物理感知和动态任务上弱于RLDX-1。
- π0.5 / π0:也是主流的VLA模型,作为主要的性能对比对象。
- Octo:在数据处理和部分架构设计上进行了参考和对比。
和本文相关性最高的3个文献
- GR00T N1.6 (NVIDIA GEAR, Dec. 2025) <2025.12>:这是本文最主要的竞争对手和对比基线,RLDX-1在多个指标上旨在超越它。
- Qwen3-VL Technical Report (Bai et al., Nov. 2025) <2025.11>:RLDX-1模型的视觉语言基础骨干,是其感知能力的来源。
- RECAP (Amin et al., Nov. 2025) <2025.11>:RLDX-1在后训练阶段采用的强化学习框架的基础,用于提升模型在困难任务上的表现。
我的
少见的韩国公司工作。引入了触觉和扭矩这种物理信号输入。
还有一些Critic、多阶段训练的实验。