快速了解部分
基础信息(英文):
- 题目: Fast-WAM: Do World Action Models Need Test-time Future Imagination?
- 时间: 2026.03
- 机构: IIIS, Tsinghua University; Galaxea AI
- 3个英文关键词: World Action Models, Video Diffusion, Embodied Control
1句话通俗总结本文干了什么事情
发现WAM的核心价值在于训练时用视频预测任务学习更好的世界表征,而非测试时真的去生成未来视频,因此提出Fast-WAM:训练保留视频co-training,推理跳过未来预测,实现4倍加速且性能不降。
研究痛点:现有研究不足 / 要解决的具体问题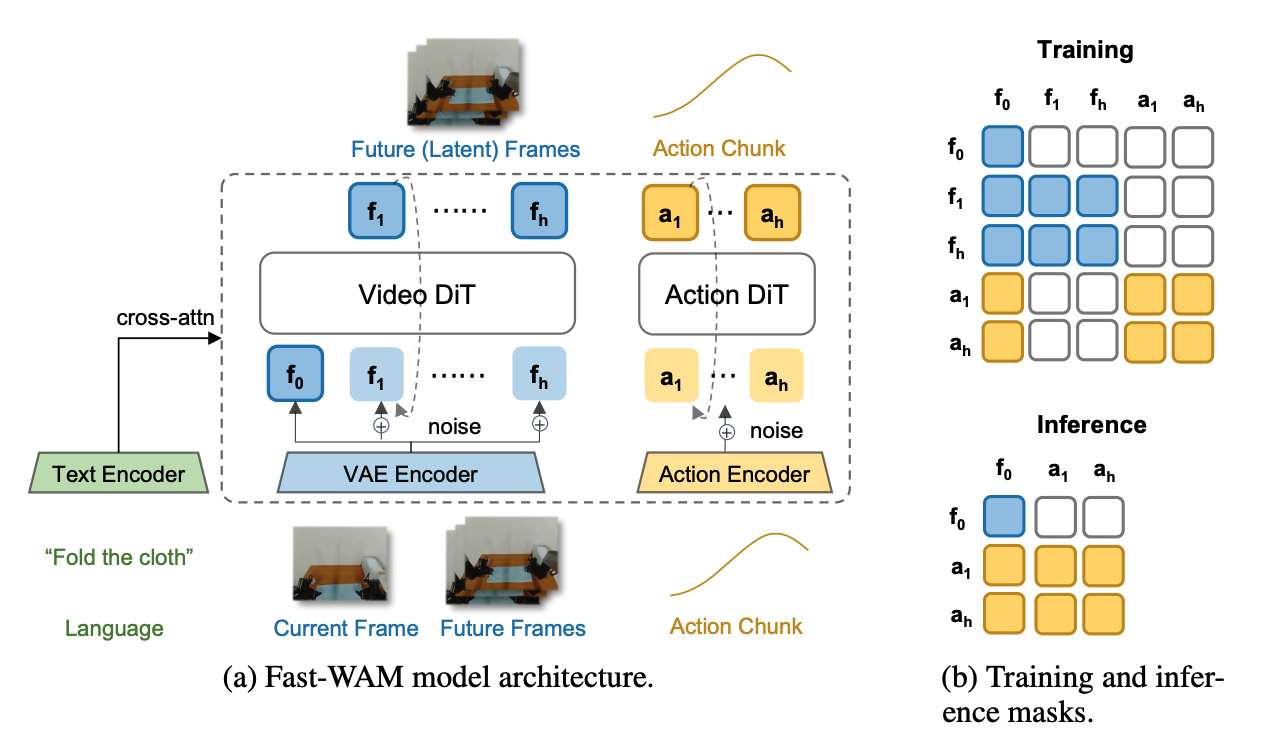
现有WAM采用"imagine-then-execute"范式,测试时需迭代视频去噪生成未来帧,推理延迟高;且不清楚性能提升到底来自"训练时的视频建模目标"还是"测试时的显式未来想象",两者被耦合在一起难以分析。
核心方法:关键技术、模型或研究设计(简要)
提出Fast-WAM架构:基于Mixture-of-Transformer,含Video DiT和Action DiT;训练时联合优化动作预测+视频预测的flow matching损失;推理时仅用Video DiT单向前向编码当前观测,得到latent world representation后直接输出动作,跳过未来视频生成。
深入了解部分
作者想要表达什么
WAM的性能增益主要来自训练阶段的视频预测目标(帮助模型学习物理先验和action-conditioned表征),而非测试时显式生成未来观测;因此可以移除测试时的未来想象步骤,在不损失性能的前提下大幅提升推理效率。
相比前人创新在哪里
- 首次解耦分析WAM中"训练时视频建模"与"测试时未来想象"两个因素的独立贡献
- 提出Fast-WAM架构,推理时单向前向、无需迭代去噪,190ms延迟,4×加速
- 无需embodied pretraining即可达到SOTA性能,数据效率更高
解决方法/算法的通俗解释
训练时让模型同时学两件事:预测机器人动作、预测未来视频长什么样;这样模型就能理解物理世界如何随动作变化。推理时只用"理解世界"的那部分能力,直接根据当前画面输出动作,不用真的去画未来视频,所以更快。
解决方法的具体做法
- 架构:基于Wan2.2-5B的Video DiT作为backbone,添加Action expert DiT,采用MoT架构+shared attention
- 输入token分三类:clean first-frame latents、noisy future video latents(仅训练用)、action tokens
- 结构化attention mask:action tokens不能attend to future video tokens,防止未来信息泄露
- 训练目标:joint flow matching,L = L_act + λL_vid
- 推理:仅保留first-frame clean tokens,单向前向通过Video DiT得到latent representation,Action DiT直接输出动作chunk
基于前人的哪些方法
- WAM框架:世界动作模型联合建模视频和动作
- Video DiT:Wan2.2-5B的视频扩散Transformer作为世界编码器
- Flow matching:用于视频latents和动作的联合生成建模
- VLA策略:测试时直接映射观测到动作的接口设计
实验设置、数据、评估方式、结论
- 基准:LIBERO(4 suites, 40 tasks)、RoboTwin 2.0(50+双手机器人任务)、真实世界毛巾折叠任务
- 数据:LIBERO每suite 500 demos;RoboTwin 2.5k clean + 25k randomized demos;真实世界60小时teleop数据
- 评估:任务成功率、平均完成时间、单卡推理延迟(RTX 5090D)
- 结论:
- Fast-WAM在仿真和真实任务上达到SOTA,无需embodied pretraining
- 与imagine-then-execute变体性能相当,但推理速度4倍快(190ms vs 810ms)
- 移除视频co-training导致性能大幅下降(RoboTwin: 91.8%→83.8%),证明训练目标比测试时想象更关键
提到的同类工作
- VLA策略:OpenVLA, π0, π0.5, RT-2, GR00T n1, Galaxea G0
- WAM/视频策略:Motus, LingBot-VA, Vidar, DreamGen, Cosmos Policy, VPP, UVA, Mimic-Video
- 视频生成基础:Wan2.2
和本文相关性最高的3个文献
- 4 World Action Models are Zero-shot Policies (Ye et al., 2026) - 定义WAM框架,joint denoising范式代表
- 3 Causal World Modeling for Robot Control (Li et al., 2026) - video-then-action范式,Fast-WAM-IDM的参考
- 5 Motus: A Unified Latent Action World Model (Bi et al., 2025) - 强baseline,对比实验核心参照