快速了解部分
基础信息(英文):
-
题目:
-
时间: 2026.04
-
机构: HKUST, XJTU, CUHK, THU, Tongyi Lab Alibaba Group, SmartMore Ltd.
-
3个英文关键词: Vision-Language-Action, VLM backbone, robotic manipulation
1句话通俗总结本文干了什么事情
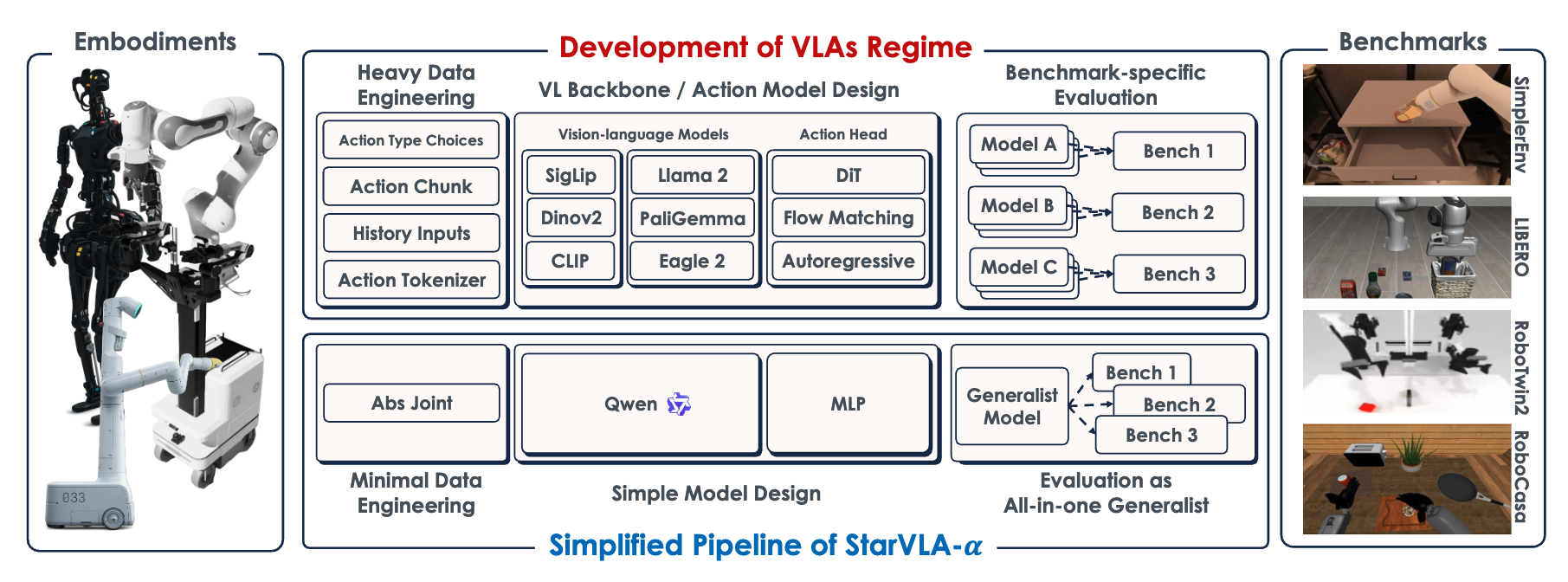
用一个强VLM backbone(Qwen3-VL) + 轻量MLP action head + 最小化数据处理,构建了一个简洁但强性能的VLA基线,系统验证了"很多复杂设计其实没必要"。
研究痛点:现有研究不足 / 要解决的具体问题
- VLA领域高度碎片化:架构、预训练数据、机器人配置、benchmark工程各不相同,难以公平比较
- 性能提升来源模糊:是建模创新还是benchmark-specific trick?
- 缺乏方法论共识,实验结果难以复现和跨任务泛化
核心方法:关键技术、模型或研究设计(简要)
- 预训练VLM backbone(Qwen3-VL)直接fine-tune,不做robot-specific pretraining
- 轻量MLP action head回归连续动作,无复杂action tokenizer或diffusion模块
- 最小化数据预处理:原始RGB+语言指令,仅action归一化,统一跨benchmark训练
深入了解部分
作者想要表达什么
强VLM初始化+简单设计+统一pipeline已足够达到SOTA性能;额外架构复杂度、数据工程、任务特定pretraining带来的增益有限且场景依赖。领域需要方法论共识而非堆叠技巧。
相比前人创新在哪里
- 不是提出新架构,而是建立可控基线系统"减法"分析现有设计选择
- 在统一backbone/数据/训练设置下,公平比较action head、pretraining、数据工程的影响
- 证明single generalist模型可跨5种机器人、4个benchmark泛化,无需task-specific适配
解决方法/算法的通俗解释
就像做菜:别人用复杂厨具+特殊调料+精细工序,作者发现用好食材(强VLM)+简单厨具(MLP)+基础工序就能做出好菜,很多花哨技巧在数据充足时收益甚微。
解决方法的具体做法
- 架构:Qwen3-VL backbone提取多模态feature,指定action token的hidden state经MLP回归连续动作块
- 数据:原始RGB+语言指令输入,仅用训练集统计做action零均值单位方差归一化
- 训练:Specialist(单benchmark)和Generalist(多benchmark联合)两种设置,action统一padding到32维
- 评估:严格遵循各benchmark官方协议,避免benchmark-specific超参调优
基于前人的哪些方法
- VLA框架继承RT系列、OpenVLA、π0、GR00T等端到端范式
- Action head设计对比参考FAST(离散token)、OpenVLA-OFT(MLP回归)、π0(扩散/flow matching)、GR00T(双系统)
- Benchmark采用LIBERO、SimplerEnv、RoboTwin 2.0、RoboCasa-GR1等标准测试集
实验设置、数据、评估方式、结论
- 设置:4 benchmarks(LIBERO/SimplerEnv/RoboTwin 2.0/RoboCasa-GR1),5种机器人(Single-arm/Dual-arm/Humanoid)
- 数据:每任务50-1000条demonstration,评估指标为任务成功率
- 结论:①连续action预测优于离散token;②不同连续action head性能相近,MLP足够;③robot pretraining在数据充足时增益有限,out-of-domain数据可能损害泛化;④数据工程技巧在小数据时有用,大数据时收益可忽略;⑤single generalist模型跨任务/跨机器人泛化有效;⑥真实机器人RoboChallenge上超越π0.5达20%
提到的同类工作
- VLA系统:OpenVLA, π0/π0.5, GR00T, Octo, RT-2, CogACT, SpatialVLA
- Action建模:FAST, Diffusion Policy, flow matching, autoregressive decoding
- 机器人数据:Open X-Embodiment, DROID, RoboCasa, RoboTwin
和本文相关性最高的3个文献
- OpenVLA: An open-source vision-language-action model (Kim et al., 2024)
- π0: A vision-language-action flow model for general robot control (Black et al., 2024a)
- GR00T N1: An open foundation model for generalist humanoid robots (Bjorck et al., 2025)