一、TL;DR
- 提出新结构:提出Robotics Transformer,一个能够消化海量多样性的机器人数据的高容量的模型结构
- 各种消融实验验证:在不同的数据规模、模型规模和数据多样性作为函数的泛化能力完成验证
- 取得什么效果:以97%的成功率执行超过700个训练指令,在新任务、干扰物和背景上的泛化分别比下一个最佳基线好25%、36%和18%
- 我觉得最重要的:设计了多个消融实验和测试条件,验证VLA对任务执行的成功是有绝对贡献和成功率提升
二、整体介绍
验证上述问题的难点:
- 组建高质量的规模化数据集
- 设计合适的模型
如何解决:
- 17个月内使用13台机器人收集的数据集,包含∼130,000个情节和超过700个任务
- 提出RT-1(Robotics Transformer 1),将高维输入和输出(包括摄像头图像、指令和电机命令)编码成紧凑token,高效推理-实时运行
贡献点:
- 提出RT-1模型
- 基于真实世界机器人任务数据集上完成验证
- RT-1可以以97%的成功率执行超过700个训练指令,并且在新任务、干扰物和背景上的泛化分别比下一个最佳基线好25%、36%和18%。
三、模型介绍
3.1 模型结构
- RT-1接收图像和自然语言指令,并输出离散化的token+action。
- 35M参数+3HZ执行
- EfficientNet + TokenLearner + Transformer
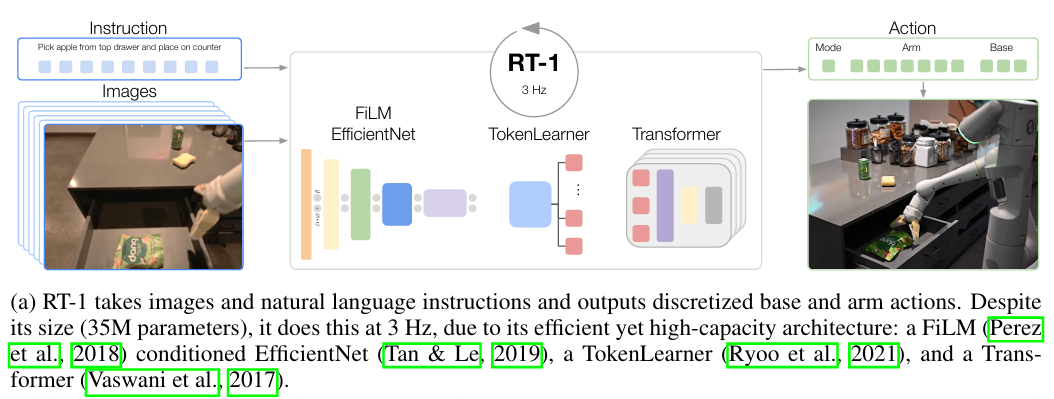
这里有一个值得思考的地方:text token其实根据token-prune相关的paper中会发现占比是很重要的,也就是当遇到这种类似场景时,text-token比视觉token更重要,会不会带来vla泛化性能有问题使得模型更关注指令而非视觉?
3.2 数据集规模和验证
在大规模、真实世界中训练(130,000个演示)和评估(3,000个真实世界试验)

3.3 前置知识
看一下就行了 没什么大用
 机器人目标是学习一个策略 π,最大化在指令、初始状态 x0 和转移动态的分布上的期望平均奖励。
机器人目标是学习一个策略 π,最大化在指令、初始状态 x0 和转移动态的分布上的期望平均奖励。

首先将输入 i,{xj} t j=0 映射到一个序列 {ξh} H h=0,将动作输出 at 映射到一个序列 {yk} K k=0,然后使用Transformer学习映射 {ξh} H h=0 → {yk} K k=0 来参数化 π。
四、系统概述
系统目的:
- 构建和展示一个通用的机器人学习系统,能够吸收大量数据并有效泛化。
如何做:
- 使用来自Everyday Robots的移动操纵器,它具有7个自由度的机械臂、一个两指夹持器和一个移动底座,如图2
使用了三个基于厨房的环境:
- 两个真实的办公室厨房和一个模拟这些真实厨房的训练环境。训练环境如图2(a)所示,由部分柜台构成,用于大规模数据收集。
- 两个真实环境如图2(b、c)所示,与训练环境具有相似的柜台,但在照明、背景和完整的厨房几何结构方面有所变化(例如,可能存在柜子而不是抽屉,或者可能可见水槽)

训练数据:
- 包括人类提供的演示,并用机器人刚执行的指令的文本描述注释每个 episode。这些指令通常包含一个动词和一个或多个描述目标对象的名词。
- 为了将这些指令分组在一起,将它们分为多个技能(例如,"pick"、"open"或"place upright"等动词)和对象(例如,"coke can"、"apple"或"drawer"等名词)。
- 数据规模:包含超过13万个单独的演示,涵盖了超过700个不同的任务指令,使用了大量不同的物体(见图2(f))
- 收集策略和细节在后文给出
五、RT-1: ROBOTICS TRANSFORMER
5.1 模型架构
指令被转换为一个USE-embedding,并通过FiLM层对预训练的EfficientNet进行条件处理(与各层的视觉特征进行融合)。生成的视觉语言tokrn经过TokenLearner减少后,再送到一个仅包含解码器的Transformer中,该Transformer输出token化的动作。如下图所示:
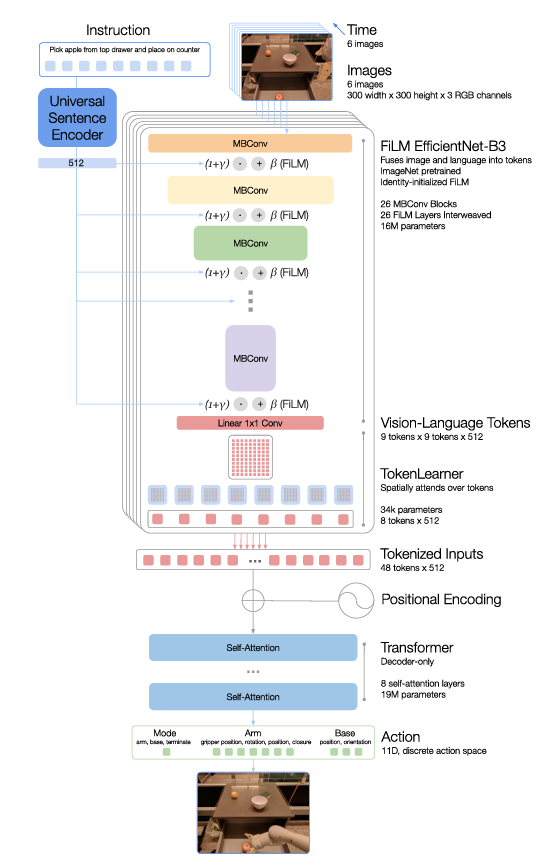
指令和图像token如何使用: RT-1模型接受分辨率为300×300的6张图像作为输入,并从最后的卷积层输出形状为9×9×512的空间特征图。然后输出特征图展平为81个视觉token,并将它们传递到网络的后续层。(其实和早期的groundingDino类似,在文本特征和图像特征早期做大量的融合)
- 遇到的问题:直接在预训练网络的内部插入FiLM层会破坏中间特征,使预训练失效;
- 怎么解决:生成FiLM仿射变换的密集层(fc和hC)的权重初始化为零,从而使FiLM层最初充当恒等式并保留预训练权重的功能(类似于LORA初始化)
TokenLearner: TokenLearner是一个逐元素注意力模块,学习将大量token映射到数量较少的token(本质上就是一个token-prune模块,视频内容理解的VLM大部分都会包含这个模块)。
- TokenLearner的加入将经过预训练FiLM-EfficientNet层的81个视觉token子采样为仅有8个最终token,然后传递给Transformer层。
Transformer: 每个图像的这8个token与历史上的其他图像连接在一起,形成48个总token(带有附加的位置编码),馈送到RT-1的Transformer骨干。Transformer是一个仅包含解码器的序列模型,具有8个自注意力层和总共19M参数,输出动作token。
动作token化: 为了对动作进行token化,RT-1中的每个动作维度都被离散为256个bins,动作维度包括:
- 七个变量用于手臂移动(x、y、z、横滚、俯仰、偏航、夹爪的张开)
- 三个变量用于底座移动(x、y、偏航),
- 以及一个离散变量,用于在三种模式之间切换:控制手臂、底座或终止剧集。
- 对于每个变量,我们将目标映射到256个bins中,其中bin在每个变量的边界内均匀分布。
**损失函数:**使用标准的分类交叉熵损失和在先前基于Transformer的控制器中使用的causal掩码。
5.2 数据
目的:收集一个大型、多样化的机器人轨迹数据集,包括多个任务、对象和环境,让模型具备泛化能力+高性能
怎么做:主要数据集包括约130k个机器人演示,使用13个机器人的车队在17个月内收集。在一系列办公厨房段中进行了这次大规模的数据收集,
技能和指令分类: 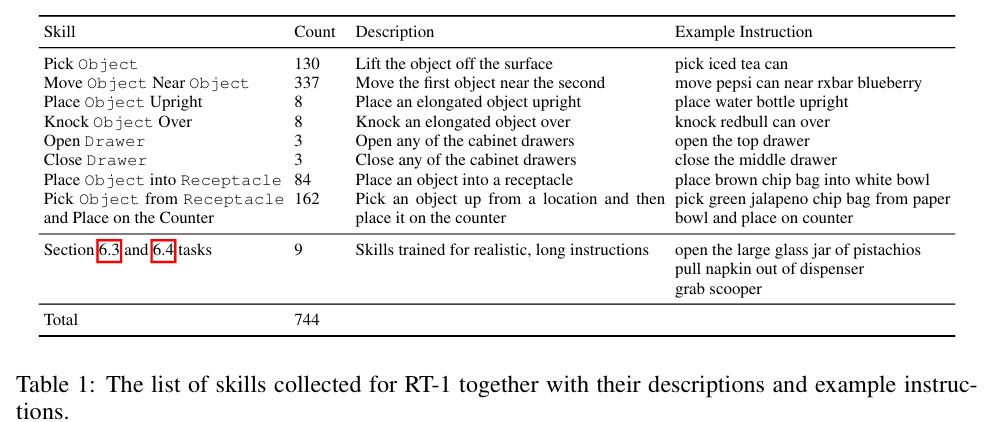
六、Experiments <我认为最重要的一节>
6.1 实验回答的问题
实验回答下述6个问题:
- RT-1能否学会执行大量指令,并在零样本情况下推广到新任务、新物体和新环境?
- 是的,可以
- 通过整合异构数据源,如模拟数据或不同机器人的数据,我们能否进一步推动生成的模型
- 是的,可以
- 不同方法在长时间跨度的机器人场景中的推广能力如何
- RT-1可以规划50个步骤的长时序任务
- 随着数据量和数据多样性的变化,各种推广指标如何变化?
- 多样性 > 数量
- 在模型设计中,哪些是重要且实际的决策,它们如何影响性能和推广能力?
- 见6.7节图(略)
6.2 测试场景/指令方面/实验维度
在三类场景中测试:
- 本次实验全面测评模型在训练任务、全新未知任务、陌生环境适配、长时序串联任务中的综合表现。具体环境在两处真实办公厨房,:
- 一处参照真实厨房搭建的训练仿真环境,训练环境如图 2 (a) 所示,仅包含局部操作台;
- 两处真实厨房(图 2b、2c)虽操作台布局与训练环境相近,但光照条件、背景环境、整体厨房结构均存在差异(例如储物柜替代抽屉、视野内可见水槽等)。

已知指令的性能:
从训练集中抽取的指令上在此评估中测试了200多项任务:
- 36项用于拾取物体
- 35项用于敲击物体,
- 35项用于将物体竖立放置,
- 48项用于移动物体,
- 18项用于打开和关闭各种抽屉,
- 36项用于从抽屉中拾取和放置物品。
未知指令的性能:
- 测试了21个新颖的、未见的指令。
- 指令分布在技能和对象之间。这确保了训练集中至少有一些每个对象和技能的实例,但它们将以新颖的方式组合。
- 例如,如果"拾取苹果"被保留,那么还有其他包含苹果的训练指令。所有未见指令的列表可以在附录D.1中找到。
稳健性:
- 进行了30个用于干扰物稳健性的真实任务和22个用于背景稳健性的任务。
- 通过在新的厨房中评估背景稳健性(其具有不同的照明和背景视觉效果)以及使用不同的柜台表面(例如,有图案的桌布)。稳健性评估场景的示例配置如图4所示。
环境鲁棒性:
鲁棒性实验包含两大维度:
- 干扰物鲁棒性测试 30 项、
- 背景环境鲁棒性测试 22 项。
- 背景鲁棒性通过切换全新厨房场景、更换操作台台面(如花纹桌布)、调整光照实现;鲁棒性实验场景示例见图 4。
长时序任务场景:
本文进一步测试模型在真实长时序复杂任务中的泛化能力,此类任务需要串联多步操作动作。该评估旨在融合全新任务、陌生物体、未知环境等多重泛化挑战,贴近真实落地需求。实验在两处真实厨房中设置 15 条长时序指令,单条指令需完成约 10 步连续操作,单步操作复杂度与训练指令保持一致。长时序任务的分步拆解依托 SayCan 系统(安等人,2022)自动完成(例如指令 "清理桌面所有杂物" 将被拆解为多步基础动作),具体拆解逻辑详见 6.4 节与附录 D.3。
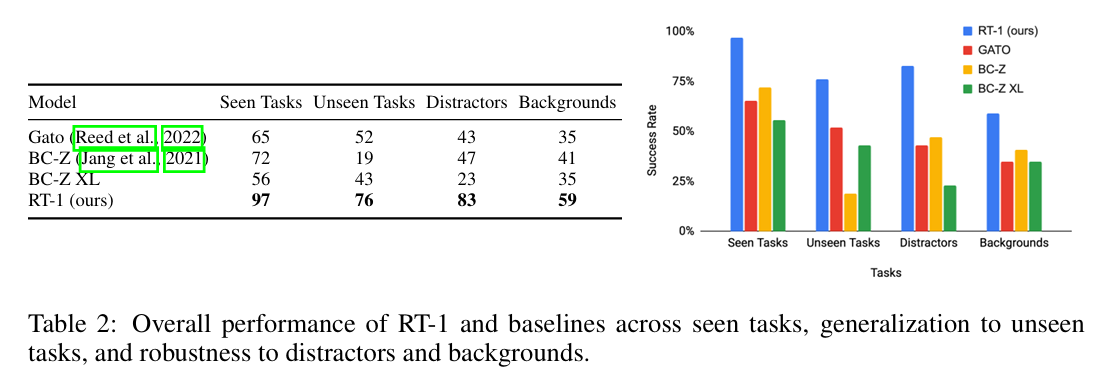
6.3 RT-1与竞品在各个维度对标
本节围绕三大核心维度,对比 RT-1 与现有模型的综合性能、泛化能力及环境鲁棒性,对照组包含 Gato、原版 BC-Z、大参数量版本BC-Z XL。
实验结果如表 2 所示:在所有测评维度中,RT-1 性能均大幅领先基线模型。
- 已见任务:RT-1 对 200 余条训练指令的执行成功率达97%,较 BC-Z 高出 25%,较 Gato 高出 32%;
- 未知任务:全新指令泛化成功率达76%,高出次优基线模型 24%。
6.4 拆解 RT-1 各核心模块对性能的贡献度
在环境抗干扰能力方面:
RT-1 表现优异:干扰物场景任务成功率 83%,背景陌生场景成功率 59%,分别高出次优模型 36%、18%。整体而言,RT-1 不仅基础执行能力更强,同时具备极强的跨场景泛化与环境鲁棒性。图 5 展示了 RT-1 在不同技能、环境、物体交互中的运行轨迹案例;

在真实复杂指令泛化能力:
为验证模型能否适配真实厨房的复杂落地场景,本文叠加全新任务组合、密集干扰物、陌生环境等多重分布偏移,设计连贯式任务流程。真实厨房实操任务包括:零食抽屉补给、倾倒调料瓶归位、闭合未关抽屉、橙子 + 纸巾简易餐食准备、全域搜寻收纳墨镜与章鱼玩偶等,完整指令清单见附录 D.1。
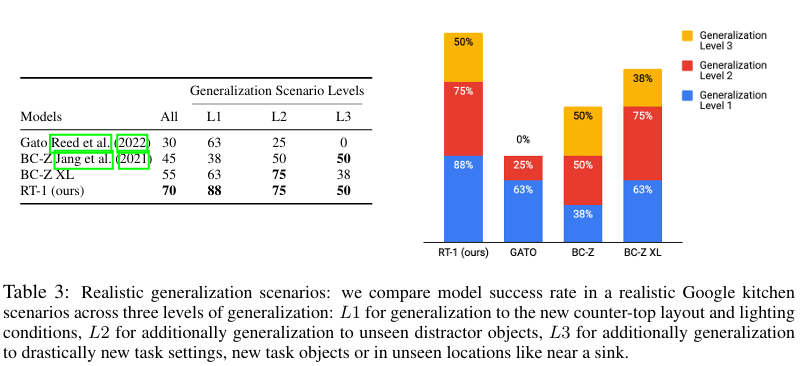
真实厨房与训练环境差异极大,本文按泛化难度划分三个等级:
- L1 级:仅操作台布局、光照条件变化;
- L2 级:在 L1 基础上,新增未知干扰物体;
- L3 级:在 L2 基础上,叠加全新任务逻辑、陌生交互物体、特殊场景位姿(如水槽周边操作)。
三级难度分别对应零食补给、餐食准备、物品搜寻三大真实任务,场景对照见图 4 末行;不同难度的运行轨迹案例见附录图 11。

表 3 统计了不同泛化等级下的任务成功率:RT-1 在全难度等级中鲁棒性最优。Gato 在简单 L1 级场景泛化表现尚可,但复杂场景下性能断崖式下跌;BC-Z 及 BC-Z XL 在 L2 级表现中等、L3 级优于 Gato,但整体泛化能力仍远不及 RT-1。
6.5 融合异构数据(仿真数据、跨机器人数据)能否进一步提升模型上限?
本节探究 RT-1 对异构异源数据的融合能力,验证模型能否吸收差异极大的多源数据、实现性能升级,且不损害原有任务的执行精度。本文设计两组对照实验:
- 融合真实机器人数据与仿真虚拟数据训练并测试;
- 融合多型号机器人采集的大规模异构数据集训练。
6.5.1 仿真数据融合能力
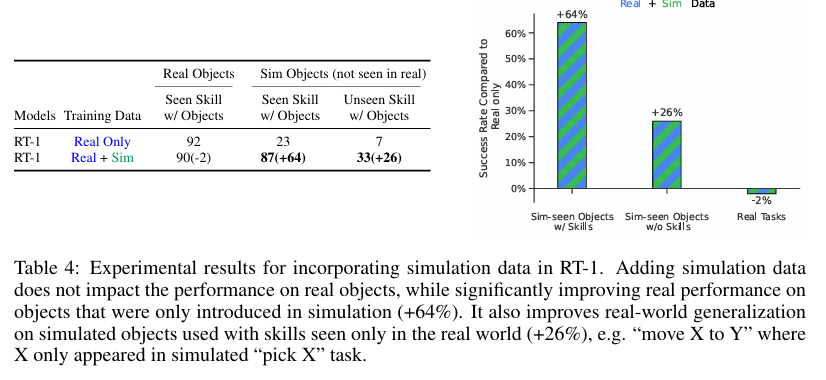
实验结论:融合仿真数据后,RT-1 原有真实任务性能无衰减;仅仿真场景出现的物体与任务,成功率从 23% 飙升至 87%,逼近真实任务精度,
表 4 对比了 RT-1 与基线模型融合真实 + 仿真数据的效果。实验固定全部真实演示数据,额外补充仿真场景数据集,包含现实中从未出现的虚拟物体。测评分为三类场景:
- 已学技能 + 真实物体:训练包含对应真实指令样本;
- 已学技能 + 仿真物体:训练仅包含该指令的仿真样本;
- 全新技能 + 仿真物体:仅训练过仿真物体基础交互,无对应组合指令样本。
所有测试均在真实物理环境中完成,聚焦拾取、位移两类核心基础动作。
体现极强的虚实域迁移能力;全新未知指令的执行成功率从 7% 提升至 33%------ 即便物体从未在现实中出现、指令完全陌生,模型仍可实现有效泛化。综上,RT-1 可高效吸收跨领域异构数据。
6.5.2 跨机器人数据融合能力
实验结果如表 5 所示:融合双机器人数据后的 RT-1,通用教室场景任务性能仅下降 2%,原有能力基本保留;在箱体抓取专项任务中,跨数据训练模型成功率达 39%,远高于仅用原生数据训练的 22%,性能提升近一倍。
为进一步挖掘数据融合上限,本文融合两类完全异构的机器人数据集:库卡 IIWA 机械臂数据、前文实验所用日常机器人移动机械臂数据。库卡数据集源自 QT-Opt 研究(卡拉什尼科夫等人,2018),包含 20.9 万条抓取交互轨迹,核心场景为箱体无序物体抓取(库卡机械臂实操案例见表 5)。
实验设置两类测评标准:
- 通用教室场景测评:沿用前文标准测试任务;
- 箱体抓取专项测评:复刻库卡机械臂的箱体无序抓取场景(见图 6)。
两类数据集存在本质差异:机器人外形结构、动作空间、环境视觉特征、物理动力学参数完全不同;且 QT-Opt 数据由强化学习智能体自主采集,而本文原始数据集均为人类演示样本,动作分布差异显著。
实验结论如下所示:

补充对照实验:仅用库卡抓取数据训练的模型,移植至日常机器人后,箱体抓取任务成功率为 0%,印证了跨机器人硬件形态直接迁移行为逻辑的局限性。而多源数据混合训练,可让 RT-1 自主推理适配新机器人的动作逻辑。
6.5 各类方法在长时序机器人场景中的泛化表现如何?
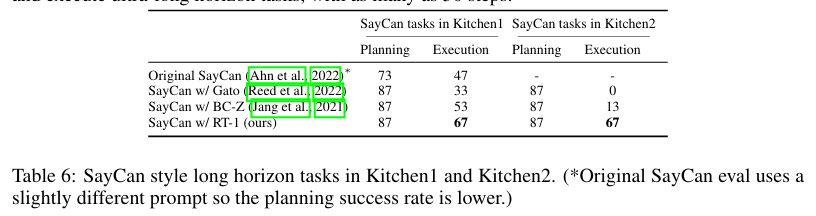
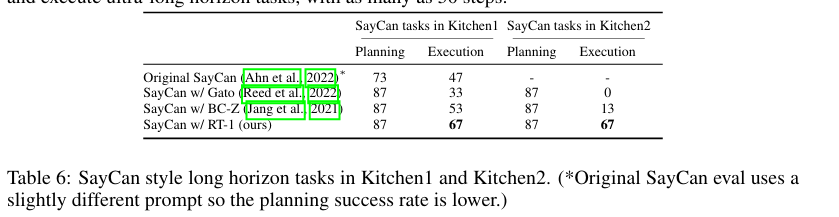
实验结论:SayCan-RT1 可规划并执行最高达 50 个步骤的超长时序任务。
本组实验旨在验证:本文方法是否具备充足泛化能力,可应用于真实厨房的长时序复杂任务场景。为解答该问题,我们在两处真实厨房环境中,基于 SayCan 框架(安等人,2022)分别部署 RT-1 与多种基线模型开展测试。
SayCan 的核心逻辑是拼接多条底层基础指令,从而完成高层复杂指令。因此,可行的高层指令数量会随操作技能种类呈组合式增长,能够充分体现 RT-1 的技能广度优势(SayCan 算法详情参见安等人 2022 年论文)。长时序任务的成功率会随步骤长度呈指数级下降,因此基础操作技能的高执行成功率至关重要。此外,移动操作任务同时包含导航与物体操控,策略对机器人底座位置变化的鲁棒性也极为关键。更多细节详见附录 D.3。
实验结果如表 6 所示(对应指令详见附录表 12)。除原生 SayCan 外,其余所有方法的规划成功率均为 87%;其中 RT-1 表现最优,在一号厨房的任务执行成功率达 67%。
二号厨房的泛化难度显著更高,原因是机器人训练教室场景完全仿照一号厨房搭建(两处厨房环境对比见图 2)。受高泛化难度影响:搭载 Gato 的 SayCan 无法完成任何长时序任务,搭载 BC-Z 的 SayCan 成功率仅为 13%。原版 SayCan 相关研究并未在全新厨房环境中开展测评。
值得注意的是,从一号厨房迁移至二号厨房时,本文方法的操控性能未出现明显下降 。补充视频中可以看到:RT-1 能够操作二号厨房中从未见过的全新抽屉;结合 SayCan 架构,SayCan-RT1 可规划并执行最高达 50 个步骤的超长时序任务。
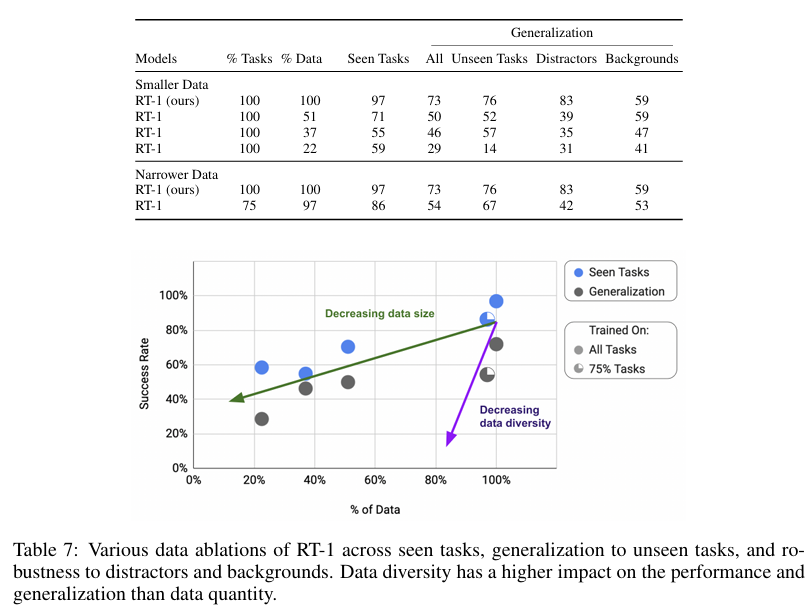
6.6 泛化指标如何随数据规模与数据多样性变化?
实验结论:数据多样性的重要性远高于数据总量。
本节最后一项研究问题,聚焦分析 RT-1 在不同数据特征下的性能缩放规律。
表 7 展示了在逐步缩减数据量占比 与任务多样性占比的条件下,RT-1 的基础性能、泛化能力与鲁棒性变化。为独立区分数据规模与数据多样性两大变量,本研究采用两组裁剪方案:
- 控制任务多样性不变、缩减数据量:剔除各任务下冗余样本,限制单任务样本上限,分别压缩至原数据总量的 51%、37%、22.5%;
- 控制数据总量不变、缩减任务多样性:剔除样本量最少的任务,保留整体 97% 的数据,但仅保留 75% 的任务类型,构建低多样性数据集。
实验结果表明:随着数据量缩减,模型整体性能平稳下降,泛化能力衰减幅度更为剧烈 ;而压缩任务多样性时,模型性能下滑速度显著加快,泛化指标受冲击尤为严重。事实上,仅剔除 25% 的任务种类、保留 97% 原始数据量,模型泛化水平的下降程度,与直接削减 49% 整体数据量的效果基本持平。
综上,本文核心结论:数据多样性的重要性远高于数据总量。
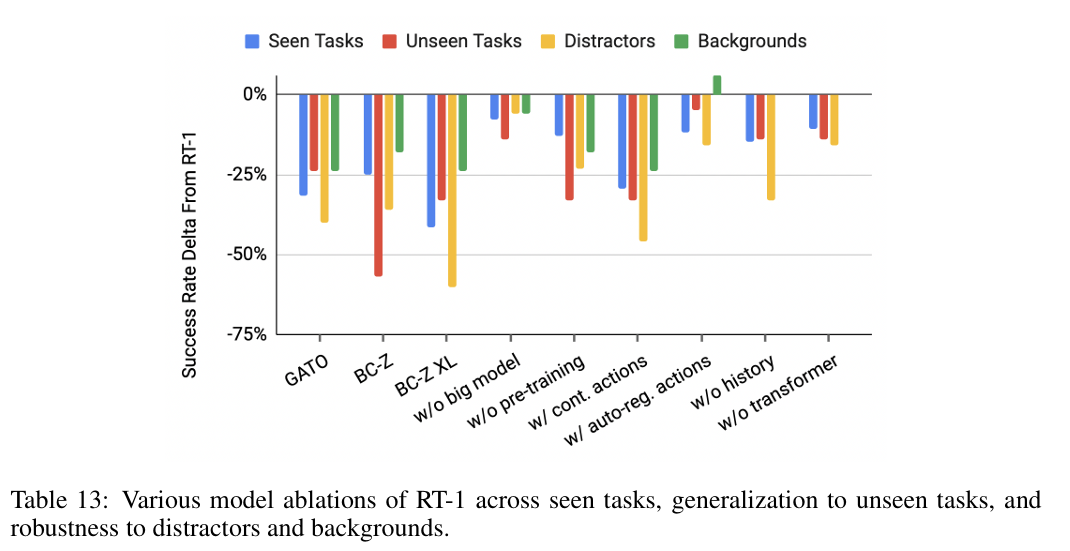
6.7 模型消融实验
七、结论、局限性与未来工作
- RT-1是一种能够高效吸纳海量数据、并可随数据规模与多样性实现性能扩容的机器人学习算法
- 该模型仍存在诸多局限性:
- 第一,本方法属于模仿学习范畴,天然受限于该类算法的固有缺陷,例如模型性能上限无法超越人类演示者;
- 第二,模型对新指令的泛化,仅局限于已有概念的重组组合,尚无法自主生成从未见过的全新运动行为;
- 第三,本文验证的操作任务虽覆盖范围广,但灵巧操作场景不足。后续我们将持续扩充可执行指令与泛化场景,弥补这一短板。
- 未来研究方向:
- 研发简易数据采集与模型提示调控方案,让非专业人员也能快速训练机器人,从而加速机器人技能的拓展迭代