qwen3.5 挺好用,输出质量高还支持多模态,但是思考过程经常会中英文混杂而且很冗长,一个很简单的问题哐哐输出一堆思考。
搜索了改 jinja 模板之类的解决方案无果,刷到了Jackrong/Qwen3.5-9B-Claude-4.6-Opus-Reasoning-Distilled 这个最近比较火的魔改版,换了跑起来确实思考精简了很多,但这玩意用的是 opus 的蒸馏数据来微调的,opus 那 summary 的思考过程,真的能被 9B 模型的智商理解么,作者也未给出测试结果。
以前我只是用自己的笔记本 GPU 微调过 0.6B 的模型,拿来搞搞内容提取、意图识别的小玩意,正好最近手里有点空余的算力服务器,于是决定复刻一下 Jackrong 的这版微调过程,以便对微调到底能干什么有个更深入的理解。
gpu 有了,下一个就是找合适的训练/测试数据了,这次我选了liucong/Chinese-DeepSeek-R1-Distill-data-110k-SFT 这份数据集,deepseek-r1 比较线性的思考过程更加适合比较笨的小参数模型,而中文思维链更适合中国宝宝的中文提问。从中筛出数学相关的问题构造一份训练集和一份测试集,为了不让微调灾难性遗忘,又把一些 Exam 、STEM 类型的数据掺进训练集中。
大约 6 个小时后微调就完成了,这 loss 曲线 emmm 。。勉强能看吧。
最后就是做测试和对比了,过程很简单,把训练集的问题都丢给原版 qwen3.5(sft_org)、Jackrong 微调版(sft_claude)、我自己的微调版(sft_r1),回答的 token 数量统计如下:
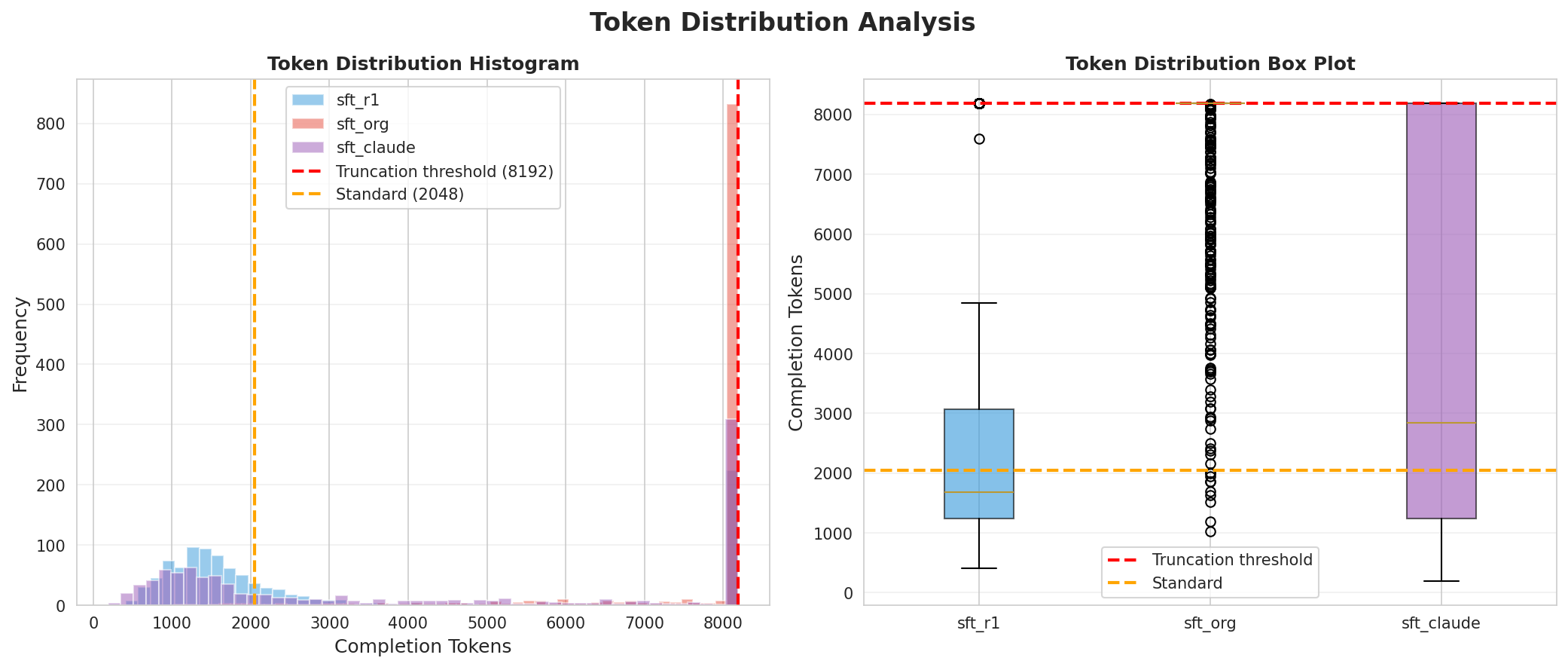
(这里有一些数据集中在 8192 个 tokens 是因为 sft_org 一直哐哐思考,我等得不耐烦了,所以为测试设置了一个 8192token 的阈值,超过就直接阶段,而 8192 这个值是测试集里面最大 token 数 2048 的 4 倍,也就是模型如果用了 ds 四倍的时间还没写完我就给它强制交卷了。)
可见,sft_claude 、sft_r1 都变得精简了,且 sft_r1 更精简一些。
接下来就是正确率的验证了,因为测试集中的答案都被\boxed{}字符包围,所以验证方式也比较简单,提示词里要求模型也把答案输出到 boxed 字符中,提取出来的答案和测试集提取的答案比较,完全相等就判对,否则丢给裁判模型定夺,正确情况统计如下:
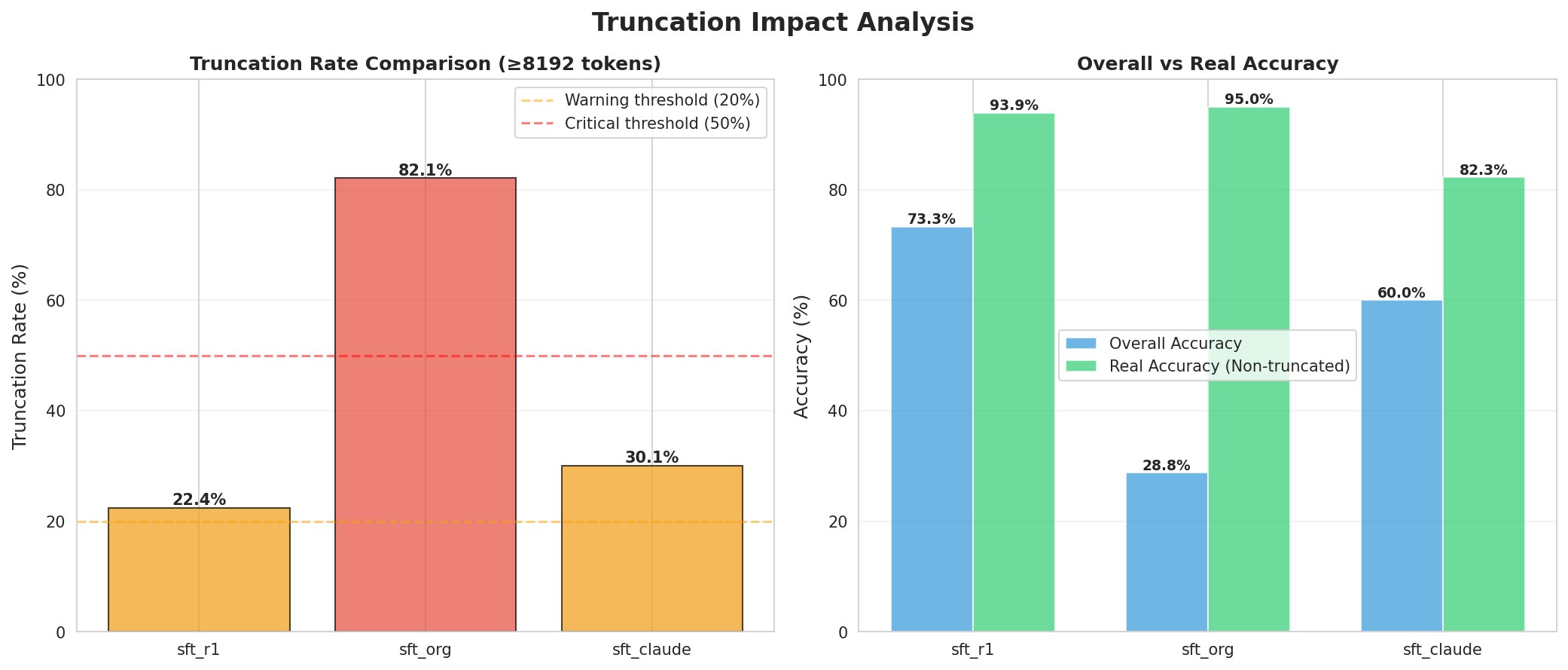
剔除掉截断,sft_org 的正确率高达 95%,而 sft_claude 、sft_r1 的正确率都有所下降,sft_claude 下降了 12.7%, 而 sft_r1 仅下降了 1.1%。这说明,微调思维链,还是一定程度上影响模型质量的,哪怕是 sft_r1 用了和测试集语言、问题类型、思考方式都接近的训练数据,也造成了轻微下降。当然,这也可能和我菜鸡的技术、粗糙的方案有关,下一步我会想想该怎么改进。
而算上截断的情况,即把 4 倍思考的异常情况算进去,sft_claude 、sft_r1 的优势就非常大了------这也是网上很多帖子用 sft_claude 这个模型来跑 openclaw 的原因,毕竟等待时间短也是不能忽略的体验。
微调后的模型及微调过程中涉及的代码、脚本等均以上传,27B 的微调正在跑,预计跑 3 天,新的评测方案也在思考中。至此,总算是凑齐了算力与数据这两个关键要素,用一次完整的微调实践验证了"gpu and data is all you need"这句话的分量。虽然结果谈不上完美,但至少让我对思维链微调的边界、代价以及改进方向有了更具体的认识。故事暂告一段落,后续若有新的思路,再来接着折腾。