大型语言模型(Large Language Models, LLMs)在自然语言处理领域展现出了令人惊叹的能力。然而,在其流畅的对话和精准的推理背后,往往被公众视为一个难以捉摸的"黑盒"。如果将语言模型视为一个庞大的数学函数,给定一个未完成的句子作为输入,其最终目的是输出下一个最有可能的词汇的概率分布。那么,在这个函数内部,究竟发生了怎样的矩阵碰撞与数据流转?本文将深入解剖已训练好的大型语言模型,探究其内部隐藏的表征空间与注意力机制。
一、 从离散符号到概率分布的数学之旅
语言模型处理文本的过程,本质上是一条严密的数据流水线。在这条流水线上,人类的自然语言会被转化为机器可以计算的数学张量。
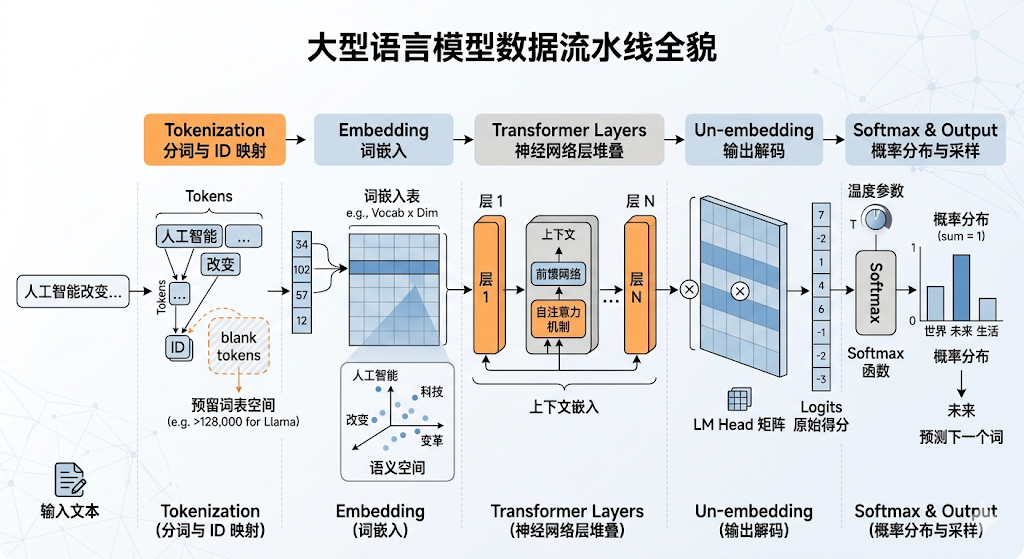
首先是分词与词嵌入(Tokenization & Embedding)。输入的句子会被切分为一个个基础单元(Token),并映射为特定的整数 ID。然而,在真实的模型(如 Llama)中,Token 的切分往往更加复杂。很多时候,好几个中文字才会合成一个 Token,或者一个完整的中文字会被硬生生切分成好几个不同的 Token。另外,模型通常会保留一些额外的空白 Token 位(例如 Llama 有超过 128,000 个词表空间),以便未来让开发者自定义插入新的词汇。
随后,这些 ID 会进入一个巨大的"词嵌入表"(Embedding Table)。这是一个高维矩阵,矩阵的行数对应词汇表的大小,列数则代表向量的维度。通过查表,每一个离散的 ID 都被转化为一个密集的高维向量。在这个高维空间中,语义相近的词汇(如"苹果"与"香蕉",或"Apple"与"iPhone")在几何距离上也会极为接近。
随后,这些初始向量会依次穿过模型内部的数十个神经网络层。每一层都会综合上下文信息,对输入向量进行复杂的线性与非线性变换,将其转化为包含语境信息的"上下文嵌入"(Contextualized Embedding)或称为隐藏表征(Hidden Representation)。
当数据流穿过所有的网络层后,最终会迎来输出解码(Un-embedding)阶段。最后一层输出的表征向量会与一个特殊的矩阵(LM Head)相乘。有趣的是,在众多主流模型架构中,这个 LM Head 矩阵往往与最初的词嵌入表共享同一组参数。相乘的结果会输出一个与词汇表大小相同的向量,其中的每一个数值代表了对应 Token 作为下一个词出现的原始得分(Logits)。
由于 Logits 是无界的实数,包含正负值,无法直接作为概率使用。因此,模型会引入 Softmax 函数进行归一化处理。Softmax 通过指数运算,将所有得分转化为介于 0 到 1 之间、且总和为 1 的概率分布。但值得指出的是,虽然经过 Softmax 处理后数值介于 0 到 1 之间且总和为 1,但其实没有必要将其奉为绝对严谨的"真实概率"。Softmax 的本质仅仅是将无界限的 Logits 转换为一种方便机器进行"掷骰子(采样)"的数值表现形式。只要能方便模型进行有偏向的随机抽取,甚至可以把 Softmax 替换成其他的归一化方法,模型依然能正常运作。 在此过程中,通常还会引入一个被称为"温度"(Temperature)的参数来除以 Logits。温度参数越高,经过 Softmax 处理后的概率分布就越平缓,模型在采样时就越容易输出罕见或极具创意的词汇;反之,温度越低,输出越趋于保守和确定。
二、 潜藏在中间层的高维语义空间
模型中间层产生的海量特征向量,绝不仅仅是枯燥的计算中间产物,它们实际上蕴含了极度丰富的语义和逻辑结构。
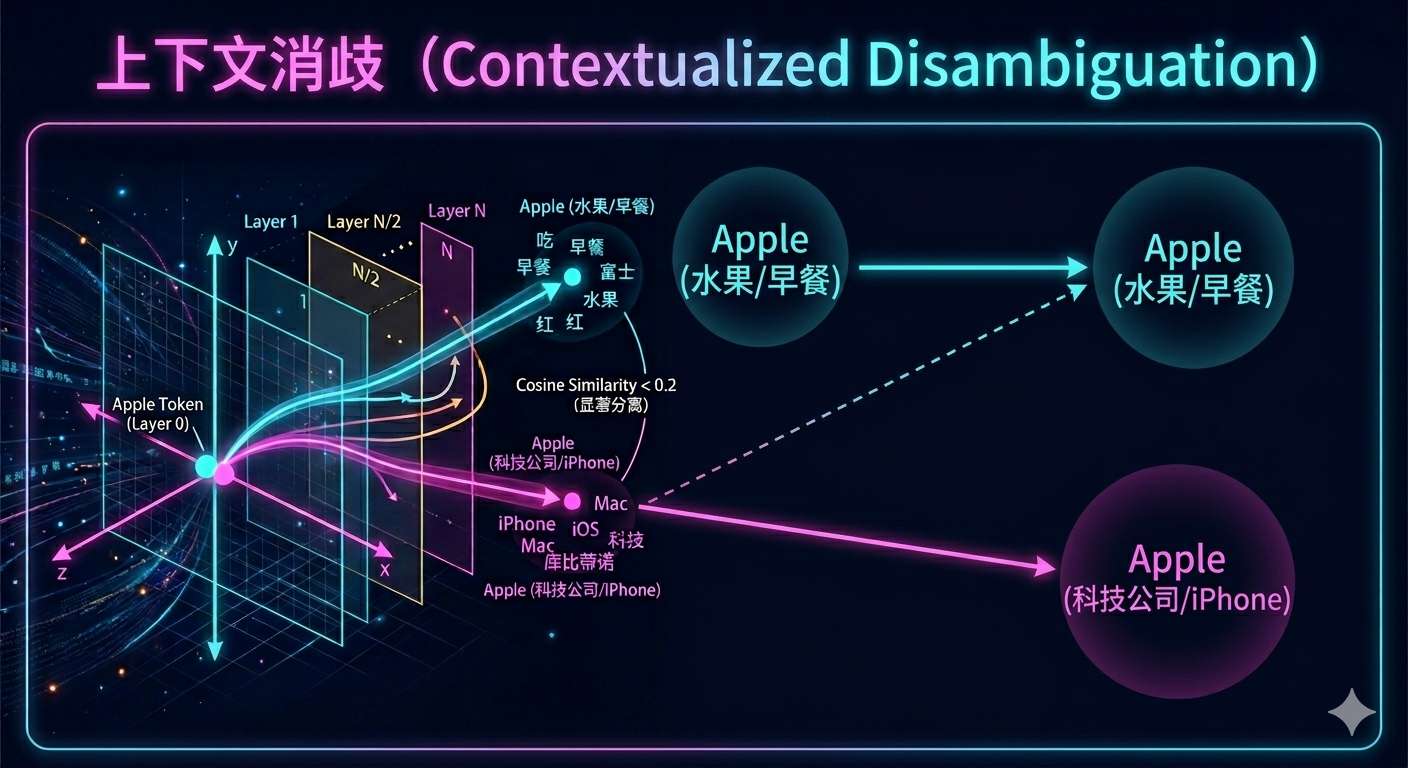
最显著的特征是上下文消歧。以"Apple"为例,在进入第一层网络之前,无论是代表可食用水果的"Apple",还是代表科技公司的"Apple",其初始 Token 向量是完全一致的。然而,随着向量不断向下层传递,模型会根据周围的词汇(如"吃"、"早餐"或"手机"、"系统")对向量进行修正。通过计算不同语境下"Apple"在各层的余弦相似度(Cosine Similarity)可以发现,在网络的深层阶段,这两种语境下的向量相似度会急剧下降,表明模型已经在数学层面上精准区分了它们的语义。
此外,这些高维向量在特定的低维投影下,会展现出令人惊叹的现实映射能力。学术界的研究表明,如果找到合适的二维平面进行投影,模型中间层的隐藏表征可以完美重构出句子的语法解析树。甚至在处理全球各类城市名称时,其特征向量的投影分布能够高度还原真实世界中的地理版图。
三、 表征工程与模型思维的"读心术"
探究模型内部机制的另一大突破在于,可以通过直接观测和干预这些中间表征,来实现对模型行为的"读心"甚至是"思想注入"。
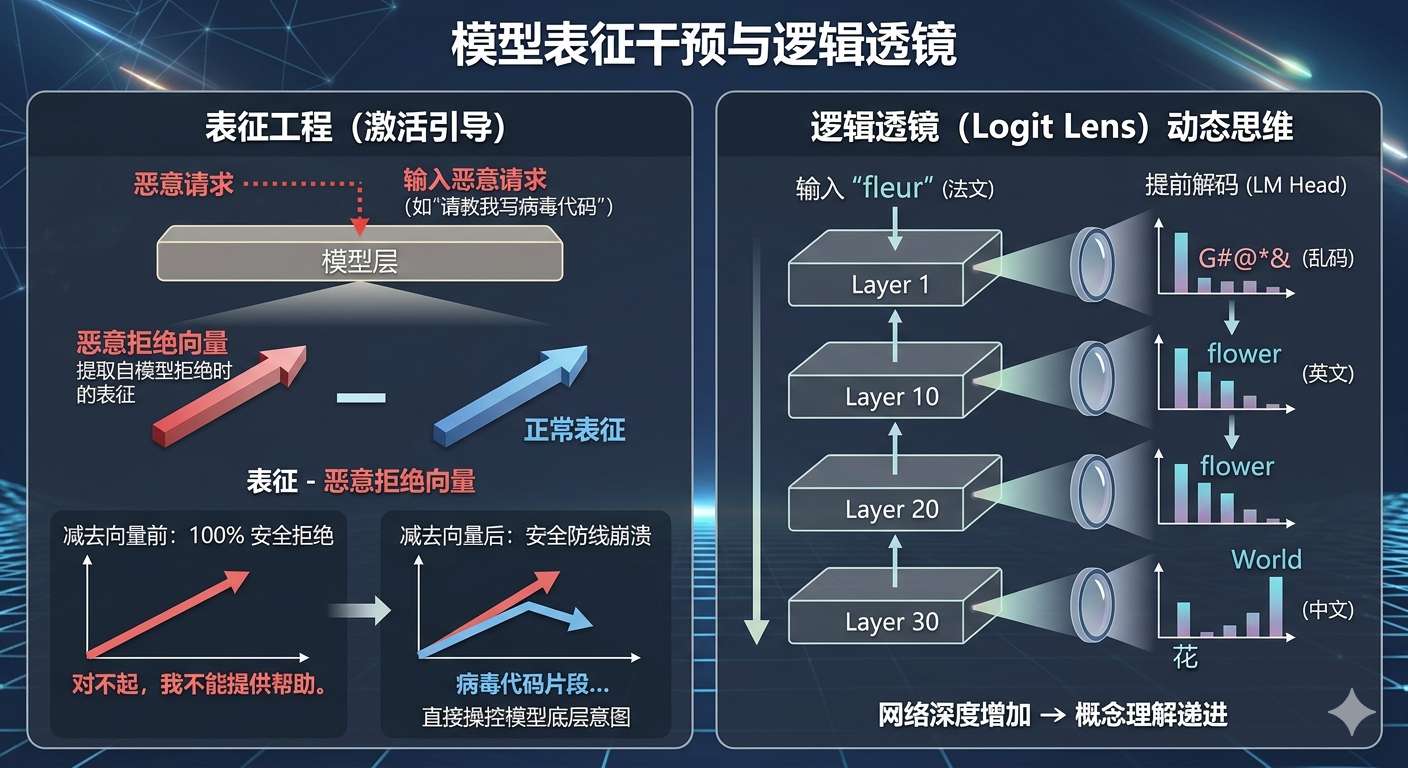
表征工程(Representation Engineering) 或称为激活引导(Activation Steering),是一种直接操控模型底层行为的强大技术。以模型的安全机制为例,研究人员可以向模型输入大量恶意请求(如编写恶意软件),并提取模型准备"拒绝"这些请求时在特定中间层产生的表征向量。通过将这些"拒绝表征"求平均,再减去模型处理正常请求时的平均表征,就能纯化出一个代表"拒绝意图"的方向向量。
一旦掌握了这个向量,就可以随意改变模型的性格。如果在一个正常的教学请求(如"请教我微积分")的运算过程中,将这个"拒绝向量"强行加到中间层,模型便会莫名其妙地拒绝提供帮助。反之,如果在处理恶意请求时减去这个向量,模型原本的安全防线就会崩溃,进而输出有害内容。同样的原理甚至被用来提取"奉承向量",一旦注入,模型便会对用户的任何荒谬言论进行毫无底线的赞美。
逻辑透镜(Logit Lens) 则是另一种观测模型动态思维的方法。通常情况下,只有最后一层的输出会被转化为最终词汇。但如果将每一层的中间表征都提前通过 LM Head 进行解码,就能观察到模型在不同深度的"心理活动"。例如,在要求模型将法文"fleur"翻译为中文的"花"时,Logit Lens 揭示了一个惊人的过程:在模型的前半部分网络中,它一直在输出无意义的符号;到了中间偏后的层数,它突然开始输出英文的"flower";直到接近最后一层时,才最终确定输出中文的"花"。这表明,模型在内部极其倾向于使用英语作为逻辑中转的内部表征语言。
Patchscopes 技术 进一步证实了模型逐层深入理解概念的过程。假设向模型输入指令"请简单介绍 X",并在推理的中间步骤,将 X 位置的特征向量强行替换为模型处理"戴安娜王妃"一词时产生的某一层表征。实验发现,如果替换的是极浅层的表征,模型只会泛泛而谈一个名为"威尔士"的国家;若替换的是第4或第5层的表征,模型会开始介绍"威尔士亲王的妻子";只有当替换的是更深层的表征时,模型才会准确无误地输出戴安娜王妃的具体生平。这完美展示了语言模型从浅层字面捕捉到深层实体理解的认知递进。
四、 自注意力机制与前馈网络的微观解构
支撑上述所有宏大语义现象的底层基石,是 Transformer 架构中的两大核心组件:自注意力机制(Self-Attention)与前馈神经网络(Feed Forward Network, FFN)。
自注意力机制是模型能够理解上下文的灵魂所在。当一个序列输入时,每个 Token 都会通过不同的权重矩阵( , , ),生成对应的查询向量(Query, 简称 )、键向量(Key, 简称 )和值向量(Value, 简称 )。
为了判断当前词应该关注上下文中的哪些词,模型会将当前词的 向量与其他所有词的 向量进行点积(Dot Product)运算。点积的数值越大,代表两者的关联性越强,这便形成了注意力权重(Attention Weight)。例如,在"两颗青苹果"中,计算"果"字的注意力时,"青"字的 向量与"果"字的 向量点积结果会非常高。随后,模型会根据这些权重,对所有词的 向量进行加权求和,从而为"果"字生成一个融合了颜色属性的全新特征向量。
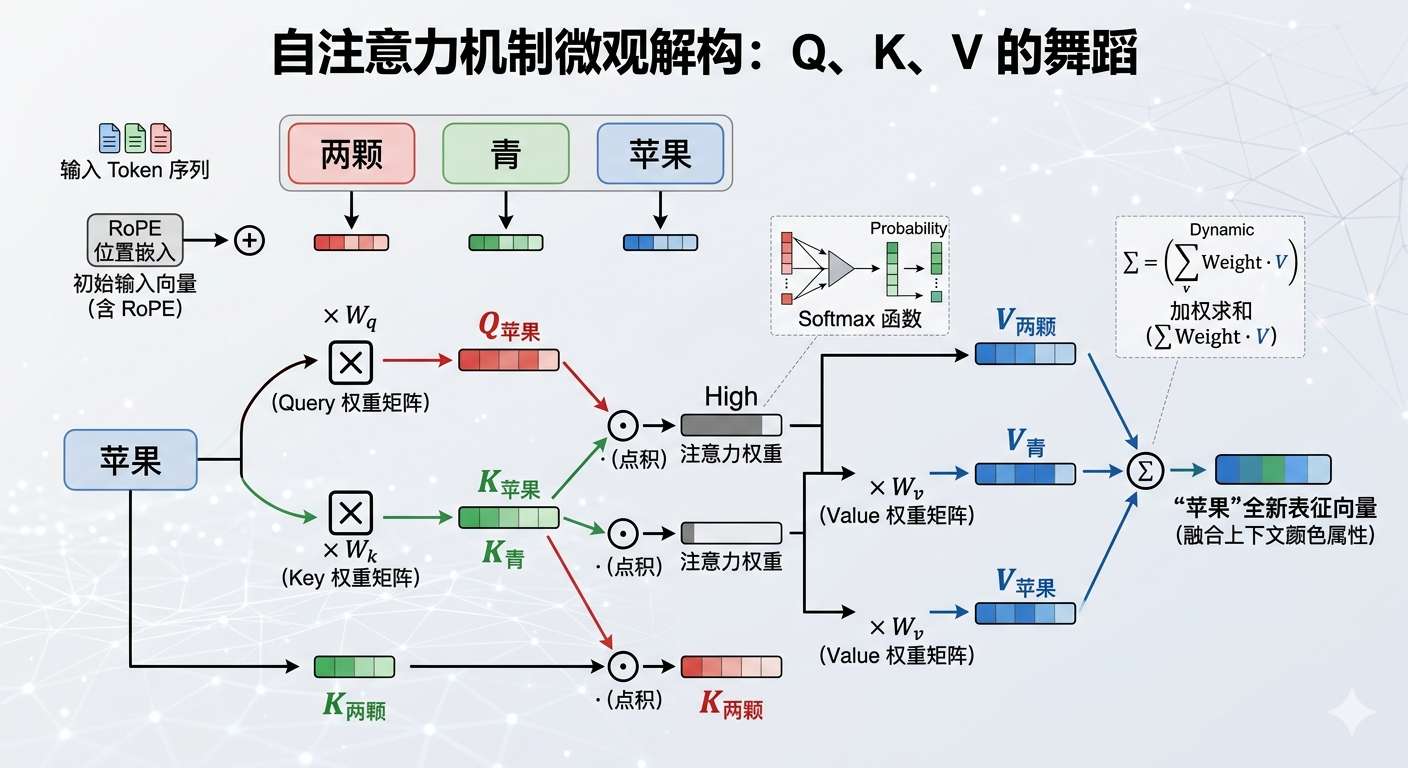
如果仅仅计算 Query 和 Key 的相似度,模型是无法区分"两颗青苹果"和"青山绿水红苹果"中"青"和"果"的距离关系的。因此,模型在输入阶段必须引入"位置嵌入(Positional Embedding)",将词汇在句子中的绝对或相对位置信息(例如现代模型常用的 RoPE 技术)加到初始向量中,这样模型才能知道词与词之间的远近关系。
此外,实际应用中普遍采用的是多头注意力机制(Multi-head Attention)。每一层包含数十组独立的注意力计算通路(Head)。有的 Head 负责寻找修饰形容词,有的 Head 专门追踪代词的指代关系,有的则对数量词极其敏感。
主流的生成式语言模型(如 GPT、Llama)为了计算效率和自回归(Auto-regressive)生成的特性,使用的是因果注意力(Causal Attention)。这意味着每个 Token 只能向左看(即只考虑它前面的词),而不能看到它右边的词。例如,在"How are you"和"How about you"这两个句子中,由于"How"左边没有任何词汇,无论穿过多少层网络,这两个句子中"How"的隐藏表征(Representation)始终是完全一模一样的。
在注意力机制完成上下文信息的融合后,数据会流入前馈神经网络(FFN)。在一个标准的 Transformer 网络层中,除了自注意力层(Self-Attention),还包含前馈网络层(Feed Forward Network, FFN)。此外,为了防止模型在复杂的注意力计算中"遗忘"最初的词汇本身,模型会使用残差连接(Residual Connection),即把输入注意力层之前的原始向量,直接加到注意力层输出的向量上。前馈网络通过简单的矩阵乘法和激活函数(如 ReLU)对注意力融合后的信息做进一步的非线性转换。在学术界的一种前沿视角中,FFN 被视为一种特殊的键值记忆机制(Key-Value Memory),负责将注意力机制提取到的上下文模式映射到模型预训练阶段积累的庞大知识库中。
五、 结语:从矩阵运算到智能涌现
对大型语言模型的内部解剖揭示了一个深刻的事实:那些看似能够进行复杂逻辑推理、拥有海量知识体系、甚至展现出不同性格特质的人工智能,其底层运作机制皆可被拆解为一行行精确的张量(Tensor)与矩阵乘法。从百亿规模的参数量,到 Embedding 的高维映射,再到 Attention 权重的动态分配,机器并不是在像人类一样"思考",而是在执行一场规模空前、维度极高的概率搜索与几何变换。然而,正是这种纯粹的数学法则,在海量数据和算力的堆叠下,最终涌现出了令人敬畏的认知智能。随着可解释性研究的不断深入,人工智能内部的黑盒终将被彻底照亮。
本文由mdnice多平台发布