一、卷积神经网络概述
定义:
卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks)。它通过卷积操作来提取输入数据的局部特征,并通过多层卷积和池化操作形成复杂的特征表示,最终通过全连接层进行分类或回归等任务。
特点:
局部连接:卷积层中的神经元仅与输入数据的一个局部区域(即局部感受野)相连,这有助于捕捉图像的局部特征。
权值共享:同一个卷积核在输入数据的所有位置上共享权重,这大大减少了网络的参数数量,降低了模型的复杂度。
平移不变性:无论输入数据中的特征出现在哪个位置,卷积操作都能提取到相同的特征,这使得卷积神经网络在处理图像等具有网格结构的数据时具有很高的效率和准确性。
基本结构:
输入层:输入图像等信息,输入层的主要作用是将这些数据以数值的形式传递给网络,以便进行后续的处理和分析。
接下来以手写数字识别为例(如MNIST数据集),该数据集包含0到9的手写数字图像,每张图像的大小为28x28像素。在这种情况下,输入层将包含784个神经元(因为28*28=784),每个神经元对应图像中的一个像素。
python
self.conv1 = nn.Sequential( #将多个层组合成一起。
nn.Conv2d( #2d一般用于图像,3d用于视频数据(多一个时间维度),1d一般用于结构化的序列数据
in_channels=3, # 图像通道个数,1表示灰度图(确定了卷积核 组中的个数),
out_channels=16,# 要得到几多少个特征图,卷积核的个数,
kernel_size=5, # 卷积核大小,5*5
stride=1, # 步长
padding=2, # 一般希望卷积核处理后的结果大小与处理前的数据大小相同,效果会比较好。那padding改如何设计呢?建议stride为1,kernel_size = 2*padding+1
), 卷积层:通过卷积操作提取输入数据的局部特征。卷积层中的每个卷积核可以提取一种特定的特征,多个卷积核可以并行工作以提取不同类型的特征。
卷积层通过卷积核(滤波器或特征检测器) 与输入图像进行局部连接和卷积运算,以生成特征图( 通过整个卷积过程又得到一个新的二维矩阵,此二维矩阵也被称为特征图),这些特征 图包含了输入数据的不同特征信息。
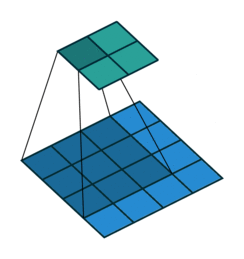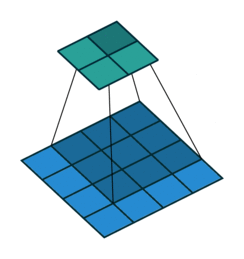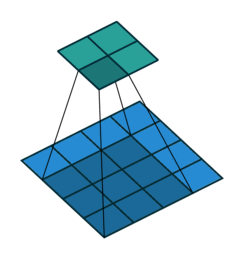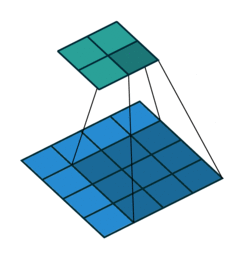
上方动图中,下方移动的深蓝色正方形就是卷积核,上方不动的青色正方形就是特征图。,通过上图发现,输入图像二维矩阵的边缘却只计算了一次,中间位置被计算多次,得到的特征图也会丢失边缘特征**,**最终会导致特征提取不准确。
为了解决这个问题,我们可以在原始的输入图像的二维矩阵周围再拓展一圈或者几圈,这样每个位置都可以被公平的计算到了,也就不会丢失任何特征,这种通过拓展解决特征丢失的方法又被称为Padding。
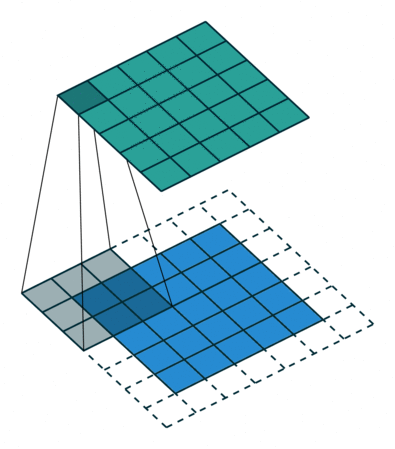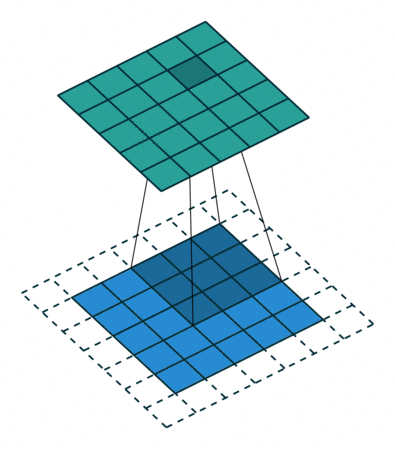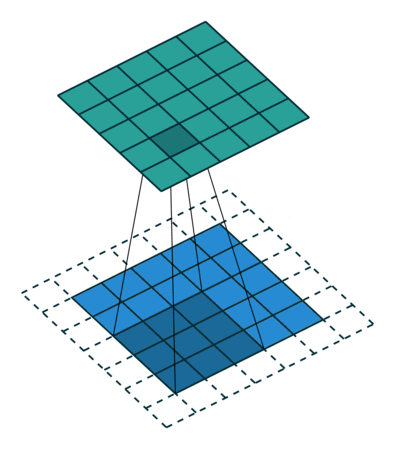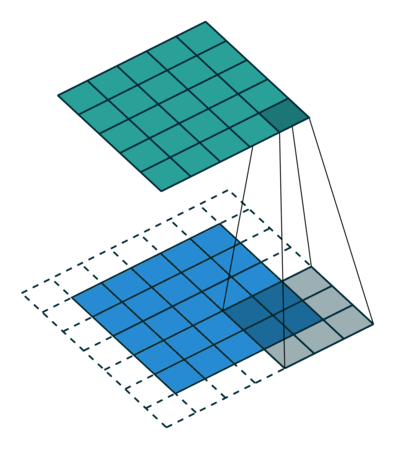
padding =1时卷积
此图致谢博主IronmanJay
以手写数字识别而为例,输入层将包含784个神经元(因为28*28=784),对应的每组卷积核就要有784个(至于每个卷积核的大小和组数根据实际情况指定)
以输入一张彩色图片(三通道)为例,由于为三通道,所以这里每组卷积核的个数需要使用3个,至于卷积核的大小,组数这里以3x3,2组为例。
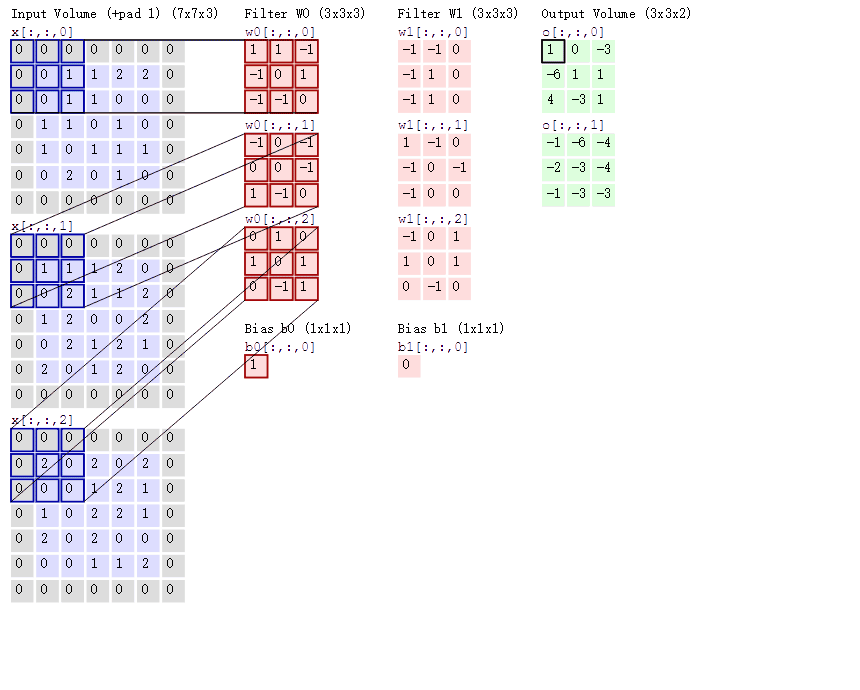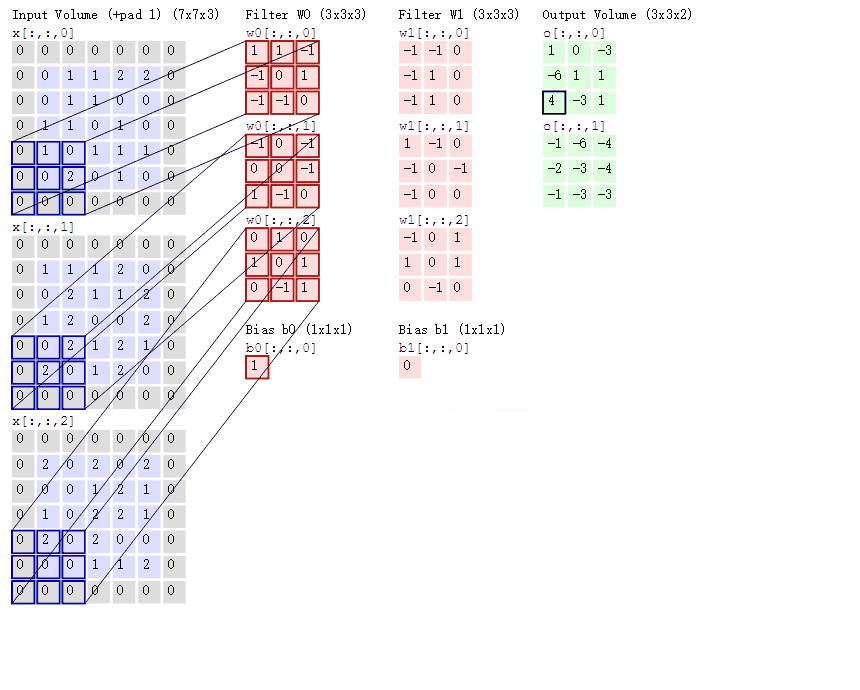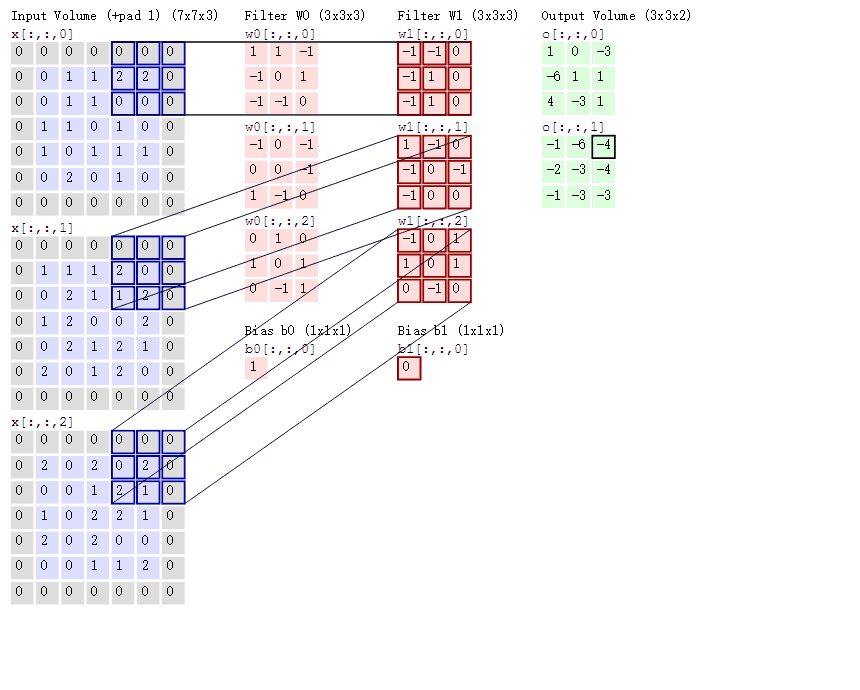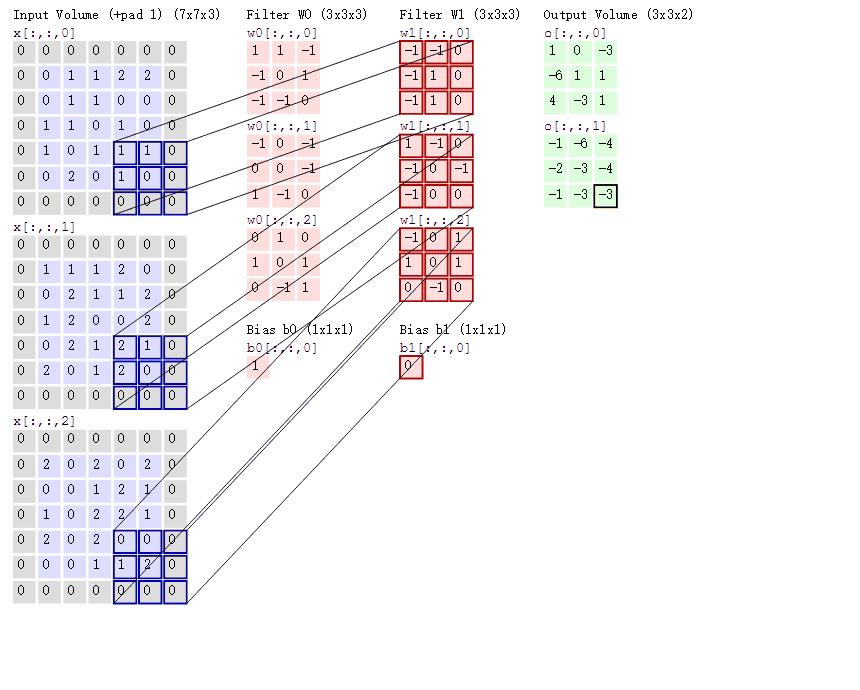
上图中的Bias是偏置项,最后计算的结果加上它就可以了。可以发现,有几个卷积核就有几个特征图,因为我们现在只使用了两个卷积核,所以会得到两个特征图。
示例:
python
self.conv1 = nn.Sequential( #将多个层组合成一起。
nn.Conv2d( #2d一般用于图像,3d用于视频数据(多一个时间维度),1d一般用于结构化的序列数据
in_channels=3, # 图像通道个数,1表示灰度图(确定了卷积核 组中的个数),
out_channels=16,# 要得到几多少个特征图,卷积核的个数
kernel_size = 5, # 卷积核大小,5*5
stride=1, # 步长
padding=2, # 一般希望卷积核处理后的结果大小与处理前的数据大小相同,效果会比较好。那padding改如何设计呢?建议stride为1,kernel_size = 2*padding+1
),池化层:对卷积层的输出进行下采样(或称为降维),以减少参数数量和提高计算效率。常见的池化操作包括最大池化和平均池化。
当特征图非常多的时候,意味着我们得到的特征也非常多,为了去除掉这些多余的特征,采用了池化层。将其中最具有代表性的特征提取出来,可以起到减小过拟合和降低维度的作用。
池化又分为:
最大池化:最大池化就是每次取池化核中所有值的最大值,这个最大值也就相当于当前位置最具有代表性的特征。
参数介绍:
kernel_size:表示池化过程使用的尺寸,如果是在卷积的过程中就说明卷积核的大小。
stride:每次正方形移动stride个位置(从左到右,从上到下),这个过程其实和卷积的操作过程一样
padding = 0:如果此值为0,说明没有进行拓展
平均池化:取此池化核框住输入图像区域中所有值的平均值。需要注意计算平均池化时采用向上取整。
池化层的优点:
在减少参数量的同时,还保留了原图像的原始特征
有效防止过拟合
为卷积神经网络带来平移不变性
python
nn.MaxPool2d(2)全连接层:将前面层提取的特征综合起来,用于分类或回归等任务。全连接层的每个神经元都与前一层的所有神经元相连。
只需要将提取到的所有特征图进行"展平",将其维度变为1 × X ,这个过程就是全连接的过程,也就是说,此步我们将所有的特征都展开并进行运算,最后会得到一个概率值,这个概率值就是输入图片是否是所属类别的概率。
python
self.out = nn.Linear(128*64*64,20) 输出层:将全连接层得到的一维向量经过计算后得到识别值的一个概率, 当然,这个计算可能是线性的,也可能是非线性的。在深度学习中,我们需要识别的结果一般都是多分类的,所以每个位置都会有一个概率值 ,代表识别为当前值的概率,取最大的概率值,就是最终的识别结果。 在训练的过程中,可以通过不断地调整参数值来使识别结果更准确,从而达到最高的模型准确率。
水果分类案例
这里采用三种方法对卷积神经网络------水果分类进行优化。
方法一:数据增强
方法二:使用最优模型
方法三:调整学习率
数据增强部分代码:
python
data_transforms = {
'train':
transforms.Compose([
transforms.Resize([300,300]), #是图像变换大小 opencv int8 0~
transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选
transforms.CenterCrop(256),#从中心开始裁剪[256,256]
transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率
transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
transforms.RandomGrayscale(p=0.1),#概率转换成灰度率,3通道就是R=G=B,
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#标准化,均值,标准差,
]),
'valid':#验证集 不需要对图像进行数据增强
transforms.Compose([
transforms.Resize([256,256]), #
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}使用最优模型:
python
def test(dataloader,model,loss_fn):
global best_acc
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss,correct = 0,0
with torch.no_grad():
for X,y in dataloader:
X,y = X.to(device),y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred,y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"test result:\n accuracy:{(100*correct)}%.avg loss: {test_loss}")
#保存最优模型的2种方法(模型的文件扩展名一般:pt、pth,t7)
if correct > best_acc:
best_acc = correct
#1、保存模型参数方法:torch.save (model.state_dict(),path) (W,b)
#print(model.state_dict().keys()) # 输出模型参数名称 cnn
#示例: # torch.save(model.state_dict(), "best2026-01.pth")
#2、保存完整模型(w,b,模型cnn),模型信息也保存下来
torch.save(model,'best2026-03.2.pt')调整学习率:
调整学习率主要对优化器进行处理,部分代码如下:
python
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)#创建一个优化器,SGD为随机梯度下降算法??
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.01)
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
scheduler.step()
test(test_dataloader, model, loss_fn)全部代码:
python
import torch
from torch.utils.data import Dataset,DataLoader
import numpy as np
from PIL import Image
from torchvision import transforms
data_transforms = { #机器学习的时候,数据进行归一化?? 图片做归一化 ->0~1
'train':
transforms.Compose([
transforms.Resize([300,300]), #是图像变换大小 opencv int8 0~
transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选
transforms.CenterCrop(256),#从中心开始裁剪[256,256]
transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率
transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
transforms.RandomGrayscale(p=0.1),#概率转换成灰度率,3通道就是R=G=B,
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#标准化,均值,标准差,
]),
'valid':#验证集 不需要对图像进行数据增强
transforms.Compose([
transforms.Resize([256,256]), #
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
#做了数据增强不代表 训练效果一定会变好,只能说大概率上会变好
class food_dataset(Dataset): #food_dataset是自己创建的类名称,可以改为你需要的名称
def __init__(self, file_path,transform=None): #类的初始化
self.file_path = file_path
self.imgs = []
self.labels = []
self.transform = transform
with open(self.file_path) as f:
samples = [x.strip().split(' ') for x in f.readlines()]
for img_path, label in samples:
self.imgs.append(img_path)
self.labels.append(label)
def __len__(self): #类实例化对象后,可以使用len函数测量对象的个数
return len(self.imgs)
def __getitem__(self, idx): #关键,可通过索引的形式获取每一个图片数据及标签
image = Image.open(self.imgs[idx]) #
if self.transform:
image = self.transform(image)
label = self.labels[idx]
label = torch.from_numpy(np.array(label,dtype = np.int64))
return image, label
training_data = food_dataset(file_path = './trainda.txt',transform = data_transforms['train'])
test_data = food_dataset(file_path = './testda.txt',transform = data_transforms['valid'])
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True) # 64张图片为一个包,
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
'''展示训练数据集中的图片'''
# from matplotlib import pyplot as plt
# image, label = iter(train_dataloader).__next__() #iter是一个迭代器函数。__next__()用于获取下一个数据
# sample = image[2] #image
# sample = sample.permute((1, 2, 0)).numpy() #tensor数据的维度转换
# plt.imshow(sample)
# plt.show()
# print('Label is: {}'.format(label[2].numpy()))
'''-------------cnn卷积神经网络部分----------------------'''
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")
''' 定义神经网络 '''
from torch import nn
class CNN(nn.Module):
def __init__(self): # 输入大小 (3, 288, 288)
super(CNN, self).__init__()
self.conv1 = nn.Sequential( #将多个层组合成一起。
nn.Conv2d( #2d一般用于图像,3d用于视频数据(多一个时间维度),1d一般用于结构化的序列数据
in_channels=3, # 图像通道个数,1表示灰度图(确定了卷积核 组中的个数),
out_channels=16,# 要得到几多少个特征图,卷积核的个数
kernel_size = 5, # 卷积核大小,5*5
stride=1, # 步长
padding=2, # 一般希望卷积核处理后的结果大小与处理前的数据大小相同,效果会比较好。那padding改如何设计呢?建议stride为1,kernel_size = 2*padding+1
), # 输出的特征图为 (16, 288, 288)
nn.ReLU(), # relu层
nn.MaxPool2d(kernel_size=2), # 进行池化操作(2x2 区域), 输出结果为: (16, 144, 144)
)
self.conv2 = nn.Sequential( #输入 (16, 144, 144)
nn.Conv2d(16, 32, 5, 1, 2), # 输出 (32, 144, 144)
nn.ReLU(), # relu层
nn.Conv2d(32, 32, 5, 1, 2), # 输出 (32, 144, 144)
nn.ReLU(),
nn.MaxPool2d(2), # 输出 (32, 72, 72)
)
self.conv3 = nn.Sequential( #输入 (32, 72, 72)
nn.Conv2d(32, 128, 5, 1, 2),
nn.ReLU(), # 输出 (128, 72, 72)
)
self.out = nn.Linear(128 * 64 * 64, 20) # 全连接层得到的结果
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)# 输出 (64,64, 32, 32)
x = x.view(x.size(0), -1) # flatten操作,结果为:(batch_size, 64 * 32 * 32)
output = self.out(x)
return output
model = torch.load('best2026-03-24.pt',weights_only=False)
model = CNN().to(device)
def train(dataloader, model, loss_fn, optimizer):
model.train()
#pytorch提供2种方式来切换训练和测试的模式,分别是:model.train() 和 model.eval()。
# 一般用法是:在训练开始之前写上model.trian(),在测试时写上 model.eval() 。
batch_size_num = 1
for X, y in dataloader: #其中batch为每一个数据的编号
X, y = X.to(device), y.to(device) #把训练数据集和标签传入cpu或GPU
pred = model.forward(X) #自动初始化 w权值
loss = loss_fn(pred, y) #通过交叉熵损失函数计算损失值loss
# Backpropagation 进来一个batch的数据,计算一次梯度,更新一次网络
optimizer.zero_grad() #梯度值清零
loss.backward() #反向传播计算得到每个参数的梯度值
optimizer.step() #根据梯度更新网络参数
train_loss = loss.item() #获取损失值
print(f"loss: {train_loss:>7f} [number:{batch_size_num}]")
batch_size_num += 1
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval() #
test_loss, correct = 0, 0
with torch.no_grad(): #一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的时候。这可以减少计算所用内存消耗。
for X, y in dataloader:#一个批次的循环
X, y = X.to(device), y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred, y).item() #
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
a = (pred.argmax(1) == y) #dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值对应的索引号
b = (pred.argmax(1) == y).type(torch.float)
test_loss /= num_batches
correct /= size
print(f"Test result: \n Accuracy: {(100*correct)}%, Avg loss: {test_loss}")
acc_s.append(correct)
loss_s.append(test_loss)
loss_fn = nn.CrossEntropyLoss() #创建交叉熵损失函数对象,因为手写字识别中一共有10个数字,输出会有10个结果
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)#创建一个优化器,SGD为随机梯度下降算法??
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.01)
'''训练模型'''
epochs = 150
acc_s = []#用来保存测试集每一轮的acc
loss_s = []#用来报错测试集每一轮的loss
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
scheduler.step()
test(test_dataloader, model, loss_fn)