GMP 是怎么来的
系列阅读:
GMP由来->GMP机制->GMP源码1(上)->GMP源码2(下)术语口径:
G=任务、M=线程、P=运行资源与本地队列、schedt=全局调度中心
这篇写给谁
- 刚接触 Go 并发,知道 goroutine 很轻,但不清楚它为什么轻。
- 想先建立调度器演化的直觉,再去看结构和源码。
先说结论
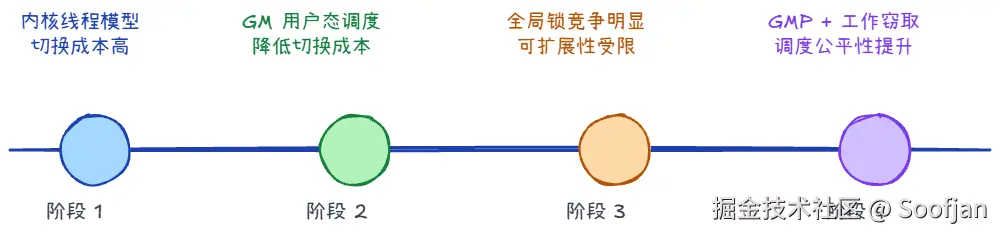
Go 的调度器不是一开始就叫 GMP。它是一步步"被问题逼出来"的:
- 传统线程模型太重。
- 先做了用户态协程调度(GM),减轻了切换成本。
- 再上多核并行后,GM 又出现全局锁和缓存失效等瓶颈。
- 于是引入 P,形成 GMP + 工作窃取。
- 最后补上抢占机制,避免某个 goroutine 长时间霸占 CPU。
1. 传统多线程:为什么"重"
在操作系统里,线程是内核调度单位。它并发能力强,但代价不低,主要有三类成本:
- 内存成本高:一个线程栈通常是 MB 级(常见 1~8MB)。
- 切换成本高:线程切换要保存/恢复寄存器、PC、栈指针等上下文。
- 内核成本高:创建、销毁、调度都要进内核,系统调用频繁。
这套模型在高并发场景下会越来越吃力:线程多了,内存和调度开销都上来。
2. 单线程用户态调度(GM):先把切换变轻
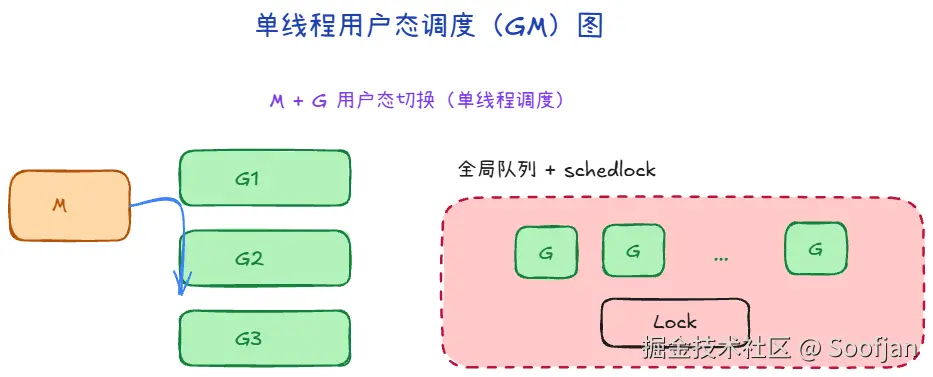
Go 先做的一步,是把"执行任务"拆成两层:
- M(Machine):内核线程,负责真正跑代码。
- G(Goroutine):用户态任务,数量可以很多。
直觉上可以理解为:M 是工人,G 是待办任务。一个 M 在用户态切换不同 G,无需进入内核态,内存开销极小。
为了防止在添加或提取 G 时发生混乱,Go 引入了一把全局锁 (schedlock)。只有拿到锁,M 才能去全局队列里挑选下一个要执行的 G。
在「单枚 M、用户态来回切 G」的阶段,一把全局锁往往还撑得住;为了吃满多核再挂上多枚 M 并行取 G 时,同一把锁和单条全局队列才会迅速变成热点------这就是下一节的出发点。
3. 多线程调度器:并行上来了,瓶颈也上来了
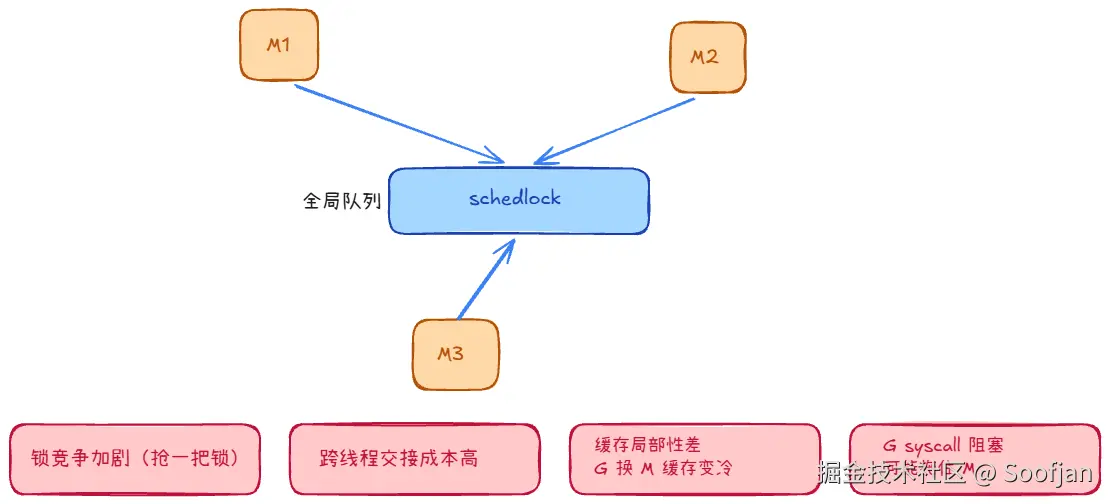
为了实现真正的并行,利用多核 CPU,Go 从"单线程调度"走向"多线程并行"(多个 M 同时工作),新的问题出现了:
- 全局锁争抢 :M 多了,大家都抢同一把
schedlock,锁竞争成瓶颈。 - 任务交接成本:新 goroutine 往全局队列放,跨线程传递频繁。
- 缓存局部性变差:G 在 M1 跑过有热缓存,阻塞回来可能改由 M2 接手,缓存变冷。
- syscall 拖累:G 做阻塞系统调用时,M 也可能被拖住,连带其他 G 受影响。
一句话:并行能力提高了,但"交通组织"不够细,导致拥堵。
4. GMP + 工作窃取:P 出场
为了解决上面的拥堵,Go 在 GM 之间加了一个关键角色 P(Processor)。
P 的定位可以理解成"资源管家":
- 每个 P 有自己的本地队列,M 先从本地拿活。
- 本地空了,再去全局队列拿,减少全局锁压力。
- 新建 G 优先放当前 P 的本地队列,减少跨线程来回搬运。
- 内存缓存(如 mcache)绑定到 P,提升局部性。
- 如果某个 M 因 syscall 卡住,会把 P 让出来给其他 M 接手。
并行度上还可记一句:「同时跑满几核」主要由 P 的数量(GOMAXPROCS)兜住 ;M(线程)可以多于 P(syscall、阻塞等场景),但 跑用户 G 时仍是 M 必须先绑上 P。
再加上 Work Stealing(工作窃取):
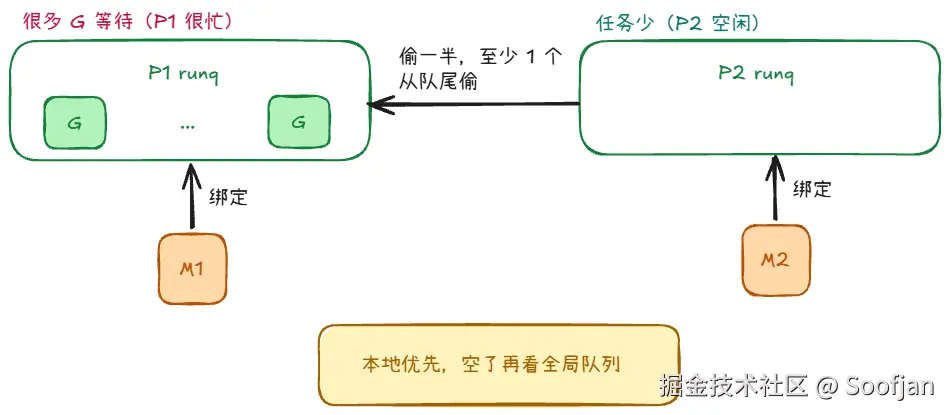
- 当某个 P 很闲、另一个 P 很忙时,闲的会去忙的那里"偷一半任务"(至少 1 个)。
这样系统整体更均衡,不容易出现"有人忙死、有人闲着"的情况。
还能降低全局热点与锁竞争,热点从「所有人抢一把锁」变成「多数时间在本地无锁/低开销路径上取 G」。
5. 抢占机制:防止一个 G 独占 CPU
即使有 GMP,如果某个 G 是长循环、长计算,不主动让出 CPU,其他 G 还是会饿。
Go 的抢占演进有两步:
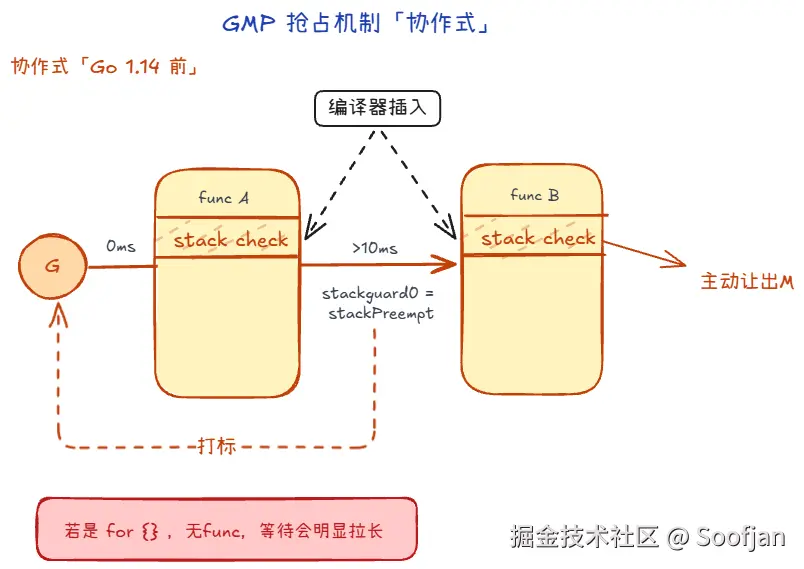
5.1 协作式抢占(Go 1.14 前)
- 编译器会在函数的开头(或结尾)偷偷插入几行汇编代码,叫
stack check - 调度器发现 G1 跑了太久(比如 10ms),就给这个 G1 打个标记:
stackguard0 = stackPreempt - G1 继续跑,当它运行到下一个函数调用时,会执行那段秘密的
stack check代码 - G1 一看,内存检测发现我不该继续跑了,于是它会主动调用
runtime.goschedImpl,自己把自己搬下台,把 M 让出来
问题是:如果代码是 for {} 这种没有函数调用的死循环,它就不容易被及时抢占。
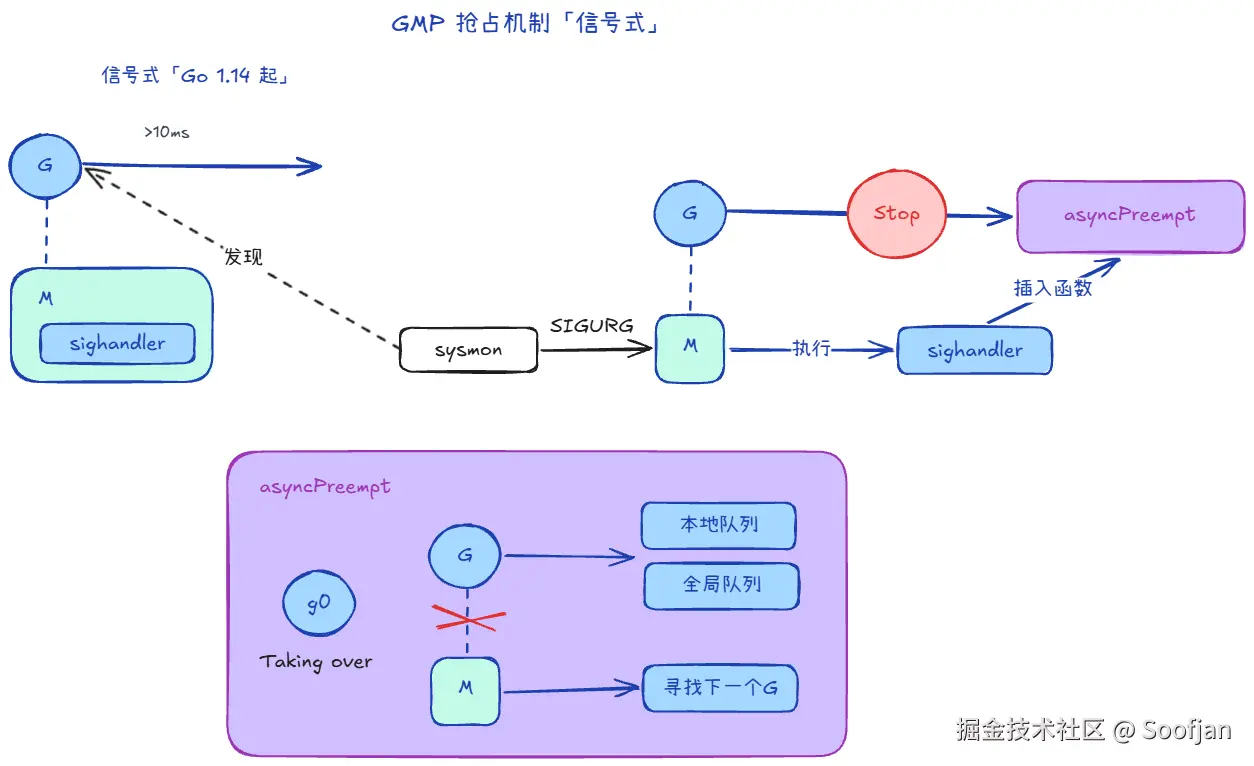
5.2 信号抢占(Go 1.14 起)
- Go给 M 注册了一个 sighandler
- **监控者(sysmon)**发现 M 上的 G 运行超过 10ms 了,且这哥们一直没下台,向 M 发送一个信号:SIGURG。
- 只要信号一到,操作系统内核会立刻暂停 M1 的当前工作。
- M1 会被迫跳转去执行 sighandler。在这个函数里,会直接操作 M1 的寄存器(PC 等),在当前的执行位置强行塞进一个叫 asyncPreempt 的函数调用。
- 当内核恢复 M1 的执行时,M1 以为自己还在接着刚才的代码跑,结果跑的第一行代码就是被塞进去的 asyncPreempt
- asyncPreempt 会通过mcall切换到 g0 栈(这是 Go 调度器的专属后台通道)。在 g0 栈里,它运行
gopreempt_m,正式把 G1 踢走。M1 找 G2 干活去了。
 这一步让"公平性"真正可控,不再完全依赖 G 自觉。
这一步让"公平性"真正可控,不再完全依赖 G 自觉。
6. 为什么 goroutine 轻量
综合上面的演进,goroutine 轻量主要来自:
- 初始栈小(KB 级),并且可动态增长/收缩。
- 主要在用户态调度,减少内核切换。
- GMP 让任务分发更高效(本地优先 + 全局兜底 + 窃取均衡)。
- 抢占机制避免长任务长期霸占 CPU。
- 数量上可以远高于线程,适合高并发模型。
这篇你应该记住的 3 件事
- GMP 不是"凭空设计",是被现实瓶颈一步步逼出来的。
- P 的价值是把调度和资源管理做了分层,让并发更可扩展。
- 抢占机制补齐了公平性,让 goroutine 不会被"长任务"长期压制。