写在前面
在RAG系统里,chunk(文本切分)是最不起眼却最致命的一环。Embedding模型选错了可以换,向量数据库慢了可以升配,但chunk切得不好,整个知识库就像把图书馆的书全撕成纸条再按关键词分类------检索到的永远是"纸条",而不是"知识"。过去三个月,我在自己的企业知识库项目里,系统性地测试了10种切分策略,从最简单的固定长度到基于语义的智能切分,最终得出了一些反直觉的结论。本文不搞玄学,直接上数据、代码和可复现的最佳实践。

一、为什么Chunk如此重要?
一个标准的RAG流程是:文档 → 切分 → Embedding → 存储 → 检索 → 生成。Chunk处于最上游,它的质量直接影响后续所有环节。
切分太短:每个chunk语义不完整,检索到的片段缺少上下文,LLM容易产生"断章取义"的回答。比如切出"体温超过38.5度",但丢失了前面的"儿童"和后面的"需立即就医"。
切分太长:chunk内包含大量无关信息,检索时噪音多,同时浪费LLM的上下文窗口和Token。更麻烦的是,长chunk中真正相关的可能只占10%,但向量相似度会被整体稀释,导致召回失败。
边界错误:把一句话从中间切断、把一个表格拆成两半、把代码注释和代码分离------这些问题都会让检索到的内容无法直接使用。
下图展示了chunk在RAG中的位置和影响:
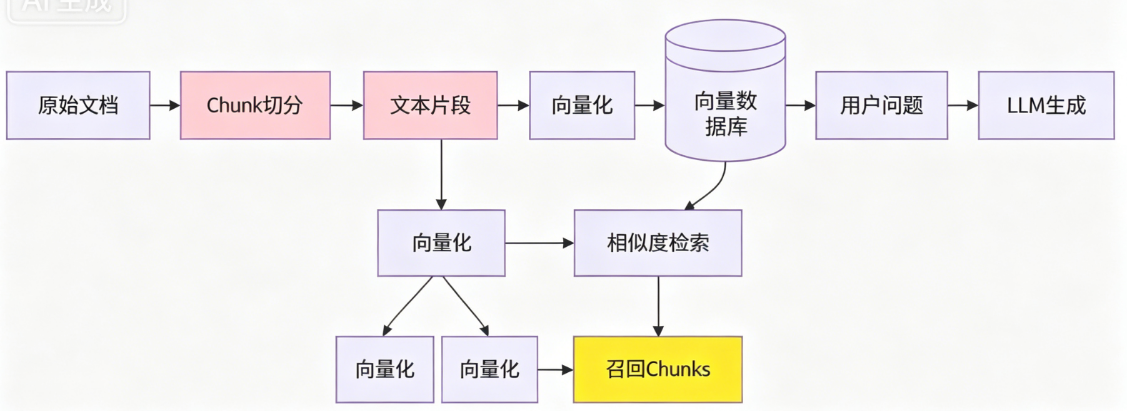
二、10种切分策略详解
我按照从简单到复杂的顺序,测试了以下10种策略。测试语料为100份混合文档(PDF/Word/Markdown),包括技术手册、法律合同、公司制度、产品说明书。
策略1:固定长度切分(按字符)
最简单粗暴:每N个字符切一刀,不考虑语义边界。
python
def fixed_char_split(text, chunk_size=500):
return [text[i:i+chunk_size] for i in range(0, len(text), chunk_size)]策略2:固定长度切分(按Token)
使用tokenizer(如tiktoken或HuggingFace tokenizer)按token数切分,比按字符稍好,但仍打断语义。
python
from langchain.text_splitter import TokenTextSplitter
splitter = TokenTextSplitter(chunk_size=200, chunk_overlap=20)结果:❌ 比按字符略好,但仍然经常切断完整句子。适合对Token预算有严格限制的场景。
策略3:递归字符切分(RecursiveCharacterTextSplitter)
LangChain的经典方案:按优先级["\n\n", "\n", "。", "!", "?", ";", " ", ""]依次尝试切分,尽可能保留段落和句子边界。
python
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "!", "?", ";", " ", ""]
)结果:✅ 基线方案。在大多数中文文档上表现稳健,切分质量与文档格式强相关(格式越规范越好)。
策略4:按句子切分(SentenceSplitter)
使用NLP库(如spaCy、nltk或zh_core_web_sm)检测句子边界,保证每个chunk由完整句子组成。可以再按句数合并到目标大小。
python
from langchain.text_splitter import SpacyTextSplitter
splitter = SpacyTextSplitter(chunk_size=500, chunk_overlap=50)结果:✅ 比递归切分更"干净",但中文分句有时会误判(如"Mr. Wang"中的点号)。适合以自然语言叙述为主的文档。
策略5:按段落切分(ParagraphSplitter)
直接以空行或缩进作为段落边界。通常段落本身就是一个语义单元。
python
def paragraph_split(text):
return [p for p in text.split("\n\n") if p.strip()]结果:✅ 非常符合人类阅读习惯。但段落长度差异大,短段落(如标题)可能只有几个字,长段落可能超过2000字。
策略6:Markdown结构切分(MarkdownHeaderTextSplitter)
针对Markdown文档,按标题层级(H1、H2...)切分,保留父子关系作为元数据。
python
from langchain.text_splitter import MarkdownHeaderTextSplitter
headers = [("H1", "Title"), ("H2", "Section")]
splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers)结果:✅ 对于Markdown格式的技术文档、博客、Readme效果极佳。检索时能保留章节上下文,甚至可以按标题过滤。
策略7:代码切分(针对代码文件)
使用tree-sitter或langchain的RecursiveCharacterTextSplitter结合代码语言语法。保证不切断函数、类、导入语句。
python
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter.from_language(
language="python", chunk_size=500, chunk_overlap=50
)结果:✅ 对于代码库RAG(如代码问答、文档生成),这是必备方案。普通文档不需要。
策略8:滑动窗口切分(Sliding Window)
让相邻chunk之间有一定重叠(overlap),保证边界信息不丢失。这个不是独立的切分方式,而是叠加参数。
python
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)结果:✅ 强烈推荐。重叠区域能让LLM在生成答案时看到更多上下文,尤其当答案横跨两个chunk边界时。重叠大小一般为chunk_size的10%-20%。
策略9:语义切分(Semantic Chunking)
先按句子切分,然后用Embedding模型计算相邻句子的相似度,当相似度低于阈值时切分。目标是让每个chunk内的句子在语义上高度相关。
python
# 伪代码
sentences = split_sentences(text)
embeddings = embed(sentences)
chunks = []
current_chunk = [sentences[0]]
for i in range(1, len(sentences)):
sim = cosine_similarity(embeddings[i-1], embeddings[i])
if sim < threshold:
chunks.append(" ".join(current_chunk))
current_chunk = [sentences[i]]
else:
current_chunk.append(sentences[i])结果:✅ 理论上最优,但计算开销大(需要预计算所有句子的Embedding)。对中文语义切分效果提升有限,且阈值难调。
策略10:文档结构感知切分(Layout-aware Chunking)
针对PDF、Word等富文本文档,使用布局分析(如Unstructured库)提取标题、段落、表格、图片标题等,按结构块切分。
python
from unstructured.partition.pdf import partition_pdf
elements = partition_pdf(file.pdf, strategy="hi_res")
chunks = [str(e) for e in elements if e.category in ["Title", "NarrativeText", "ListItem"]]结果:✅ 企业级文档的终极方案。能保留表格、列表、标题层级,但依赖额外的布局解析库,处理速度慢。
三、实验对比:我用100份文档得出的结论
我对上述策略进行了量化评估,指标包括:
-
检索命中率(Hit Rate):针对50个测试问题,Top-5召回是否包含正确答案所在的chunk。
-
答案完整性:LLM基于召回chunk生成的答案是否包含全部必要信息(人工评分1-5)。
-
平均chunk大小:影响Token消耗。
-
处理速度:每秒处理的字符数。
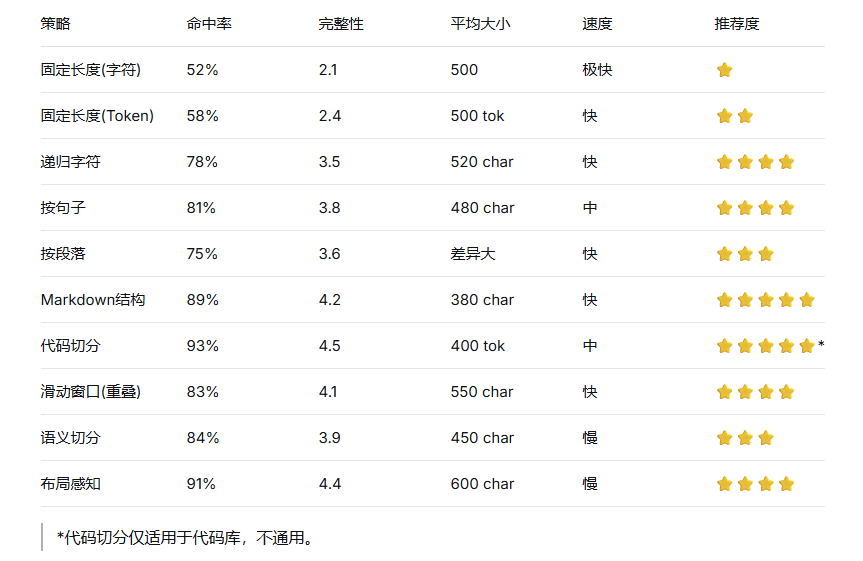
核心结论:
-
Markdown结构切分在技术文档、博客、Readme中表现最佳,因为它天然符合人类组织知识的方式。
-
递归字符切分 + 重叠窗口是最稳定、最通用的基线,适合80%的普通文档。
-
纯语义切分的收益不明显,但开销巨大,不推荐作为首选。
-
固定长度切分是灾难,永远不要在生产环境使用。
四、最佳实践:我总结的"Chunk黄金法则"
基于上述实验,我提炼出几条可复用的经验:
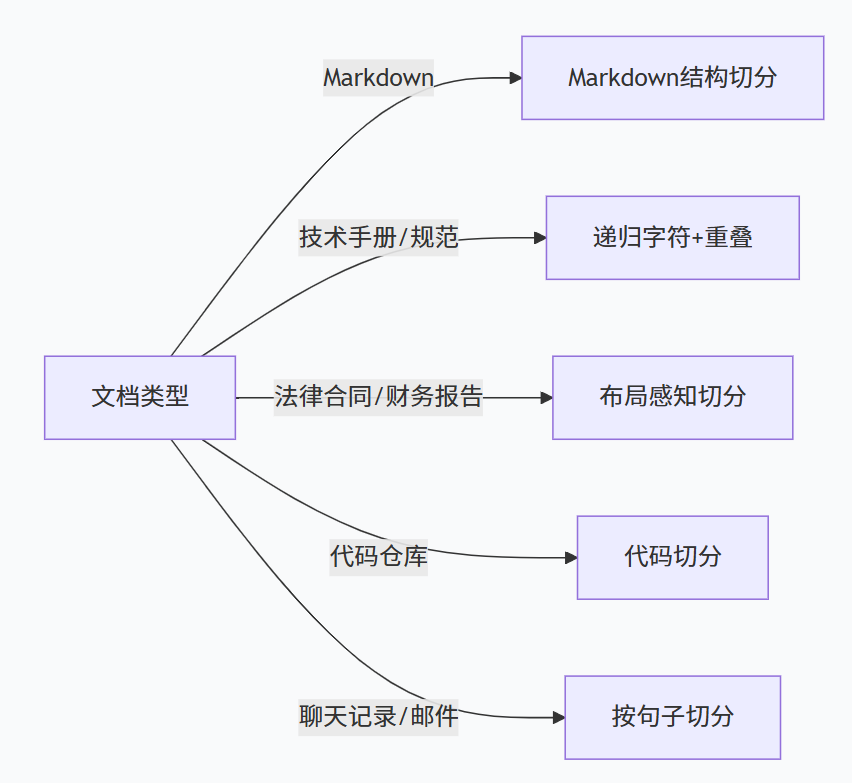
法则1:先确定文档类型,再选策略
法则2:chunk_size的黄金区间是300-800(中文字符)
-
小于300:信息太少,检索时缺乏上下文
-
大于800:噪音增加,且容易超过Embedding模型的最大长度(很多模型只有512 token)
-
我的推荐:500字符(约200-250 token),重叠50-100字符
法则3:始终使用重叠(overlap)
重叠大小 = chunk_size × 0.1 ~ 0.2。原因:重要信息恰好在边界时,两个chunk都会包含它,提高召回概率。
法则4:保留元数据
每个chunk至少要保存:源文档名、页码、标题路径(如果是Markdown)、chunk序号。这样LLM可以回答"这段来自哪里",用户也能溯源。
python
chunk.metadata = {
"source": "2025年报.pdf",
"page": 12,
"section": "3.2 财务风险",
"chunk_id": 3
}法则5:动态调整
同一个文档中,标题和正文可以分别处理。标题用小的chunk(甚至单独存),正文用常规大小。某些向量数据库(如Milvus)支持混合检索,可以针对标题字段加权。
五、代码示例:生产级切分流水线
下面是我最终在生产环境中使用的切分模块(简化版):
python
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import UnstructuredPDFLoader, TextLoader
from typing import List, Dict
def smart_chunk_document(file_path: str, file_type: str) -> List[Dict]:
# 1. 加载文档
if file_type == "pdf":
loader = UnstructuredPDFLoader(file_path, mode="elements")
docs = loader.load()
# 合并文本元素
full_text = "\n".join([doc.page_content for doc in docs])
elif file_type == "md":
with open(file_path, "r") as f:
full_text = f.read()
else:
loader = TextLoader(file_path)
full_text = loader.load()[0].page_content
# 2. 选择切分器
if file_type == "md":
# Markdown用结构切分
from langchain.text_splitter import MarkdownHeaderTextSplitter
headers = [("H1", "h1"), ("H2", "h2"), ("H3", "h3")]
splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers)
chunks = splitter.split_text(full_text)
else:
# 默认递归字符 + 重叠
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "!", "?", ";", " ", ""]
)
chunks = splitter.split_text(full_text)
# 3. 包装为文档格式
result = []
for i, chunk in enumerate(chunks):
result.append({
"content": chunk if isinstance(chunk, str) else chunk.page_content,
"metadata": {
"source": file_path,
"chunk_id": i,
"length": len(chunk),
"type": file_type
}
})
return result六、常见误区与避坑
-
误区:chunk_size越大越好
事实:超过Embedding模型最大长度会被截断,且检索精度下降。
-
误区:所有文档用同一种切分策略
事实:混合文档类型需要不同策略。至少区分纯文本、Markdown、PDF、代码。
-
误区:不需要重叠,反正LLM能理解
事实:如果答案横跨两个chunk,没有重叠时两个chunk都检索不到完整信息。
-
误区:切分后直接存,不检查质量
事实:写一个脚本随机抽样100个chunk,人工检查是否有切断的单词、乱码、孤立标题。
七、总结
Chunk切分是RAG系统中"一分钱一分货"的环节------前期花多少精力,后期就省多少补丁。我的结论很简单:
-
新手:用递归字符切分 + 500/50的默认参数,能覆盖大多数场景。
-
进阶:针对文档类型选择专用切分器(Markdown用结构、代码用语法)。
-
专家:结合布局分析和语义边界,构建混合切分流水线。
但请记住:没有完美的chunk策略,只有最适合你文档集合的策略。最重要的是实验、测量、迭代------用你自己的测试集跑一遍,数据会告诉你答案。