目录
一.专栏介绍
本专栏是我学习《head first》设计模式的笔记。这本书中是用Java语言为基础的,我将用C++语言重写一遍,并且详细讲述其中的设计模式,涉及是什么,为什么,怎么做,自己的心得等等。希望阅读者在读完我的这个专题后,也能在开发中灵活且正确的使用,或者在面对面试官时,能够自信地说自己熟悉常用设计模式。
本章将开始**解释器模式(Interpreter Pattern)**的简单学习,不涉及什么复杂的术语。
二.解释器模式简介
解释器模式定义了语法的文法表示,并构建一个解释器来解释语言中的句子。核心思想是将"语法规则"封装为不同的表达式类,通过组合这些类来解释复杂的语句。
解释器模式不是日常开发的高频通用模式,它的核心场景是简单语法 / 表达式解析 ,常用在比如正则表达式引擎、SQL 语法解析、配置文件解析、游戏里的简单脚本指令等。
核心结构:
-
抽象表达式(AbstractExpression) :定义解释操作的接口。其实就是抽象类,其它表达式类都要继承这个类,表达式们在这里就是用到了组合模式,也就是客户端将它们实例化后会再组合成一棵树型结构。
-
终结符表达式(TerminalExpression) :实现与文法中终结符相关的解释操作(如具体字符、数字)。这里其实就是具体字符 ,比如a,b,c。
-
非终结符表达式(NonterminalExpression) :实现与文法中非终结符相关的解释操作(如 "或""连接""重复" 等逻辑)。除了具体字符之外的字符,比如正则表达式里的***,?**等。
-
上下文(Context) :包含解释器之外的全局信息(如输入字符串、当前解析位置)。
-
客户端(Client):构建文法的抽象语法树,并调用解释操作。
三.例子与代码
相信大家都熟悉正则表达式,正则表达式这一类简单的语法规则就可以使用解释器模式进行解释。我以一个最简单的解释a*b的例子来展示解释器模式,也就是可以有零到n个a,只能有一个b,比如"b","ab","aab"等等。
Interpreter.h:
头文件并展开命名空间:
cpp
#include <iostream>
#include <string>
#include <memory>
using namespace std;首先是上下文类,保存输入字符串和当前解析位置:
cpp
// 上下文类:保存输入字符串和当前解析位置
class Context
{
public:
Context(const string& in) : input(in), position(0) {}
char peek() const
{
return (position < input.size()) ? input[position] : '\0';
}
void advance()
{
if (position < input.size()) position++;
}
bool isEnd() const
{
return position >= input.size();
}
size_t getPosition() const { return position; }
void setPosition(size_t pos) { position = pos; }
private:
string input;
size_t position;
};抽象表达式类,所有表达式的基类:
cpp
// 抽象表达式类
class Expression
{
public:
virtual ~Expression() = default;
virtual bool interpret(Context& context) = 0;
};interpret(Context& context)就是最核心的解释函数。
匹配单个字符的终结表达式类(终结表达式这个术语真的很奇怪):
cpp
// 终结符表达式:匹配单个字符
class LiteralExpression : public Expression
{
private:
char literal;
public:
LiteralExpression(char c) : literal(c) {}
bool interpret(Context& context) override
{
if (context.peek() == literal)
{
context.advance();
return true;
}
return false;
}
};与上下文对象的当前字符相等则返回true,不相等则返回false。
非终结表达式类,我们的简单例子中指的就是*:
cpp
// 非终结符表达式:处理*(0次或多次匹配)
class StarExpression : public Expression
{
private:
unique_ptr<Expression> expr;
public:
StarExpression(unique_ptr<Expression> e) : expr(move(e)) {}
bool interpret(Context& context) override
{
while (expr->interpret(context))
{
// 持续匹配,直到失败
}
return true; // 0次匹配也成功
}
};这里注意,哪怕 while 循环一次都没执行,还是 return true,因为*的正则语义是0 次或多次匹配,哪怕匹配 0 次也是合法的。
如果有其它表达式,比如?,^,我们就再创建一个类继承自表达式基类(Expression)。
处理连接的非终结表达式类:
cpp
// 非终结符表达式:处理连接(先匹配左表达式,再匹配右表达式)
class ConcatenationExpression : public Expression
{
private:
unique_ptr<Expression> left;
unique_ptr<Expression> right;
public:
ConcatenationExpression(unique_ptr<Expression> l, unique_ptr<Expression> r)
: left(move(l)), right(move(r))
{}
bool interpret(Context& context) override
{
size_t savedPos = context.getPosition();
if (left->interpret(context) && right->interpret(context))
{
return true;
}
context.setPosition(savedPos); // 匹配失败则回滚位置
return false;
}
};这里注意,如果左表达式匹配成功、右表达式匹配失败,必须把解析指针回退到匹配前的位置,否则会污染上下文的解析状态,导致后续匹配全部错乱。
逻辑就是星号表达式(StarExpression)表达式连接左边的终结表达式(LiteralExpression),连接表达式来连接星号表达式(StarExpression)和右边的终结表达式(LiteralExpression)。这样来构成一个树结构。也就是两个连接表达式对象是根结点,两个成员变量Expression就是它的两个子节点。
最终的树形结构如下:
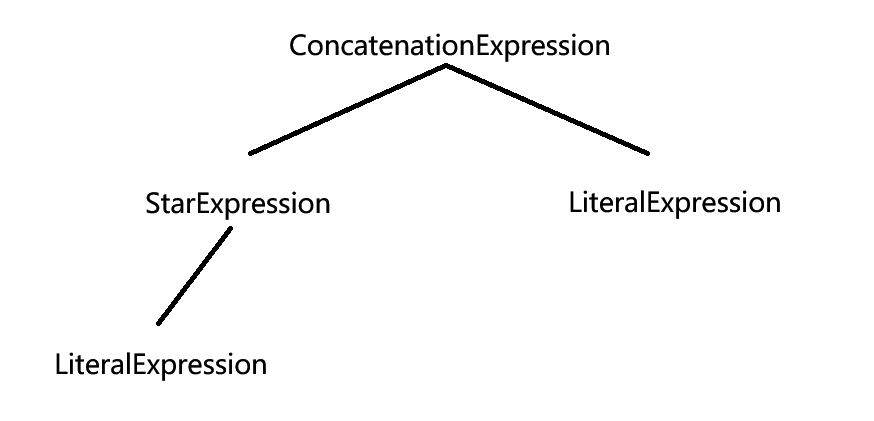
只要有一个分支返回false,那么最终结果就是false,反之就是true。这就是这个案例的语法树。可以说,有了语法树,我们就能用解释器模式来解释语法。
main.cpp:
cpp
#include "Interpreter.h"
// 辅助函数:构建 a*b 的抽象语法树
unique_ptr<Expression> createABStarPattern()
{
auto a = make_unique<LiteralExpression>('a');
auto starA = make_unique<StarExpression>(move(a));
auto b = make_unique<LiteralExpression>('b');
return make_unique<ConcatenationExpression>(move(starA), move(b));
}
// 测试
int main()
{
auto pattern = createABStarPattern();
std::string testCases[] = { "b", "ab", "aab", "aaab", "a", "acb", "abc" };
for (const auto& test : testCases)
{
Context context(test);
bool matched = pattern->interpret(context) && context.isEnd();
std::cout << "Input: \"" << test << "\" => "
<< (matched ? "Match" : "No Match") << std::endl;
}
return 0;
}我用辅助函数createABStarPattern()封装了连接的处理,main()函数里就是一些测试用例和相应的输出。
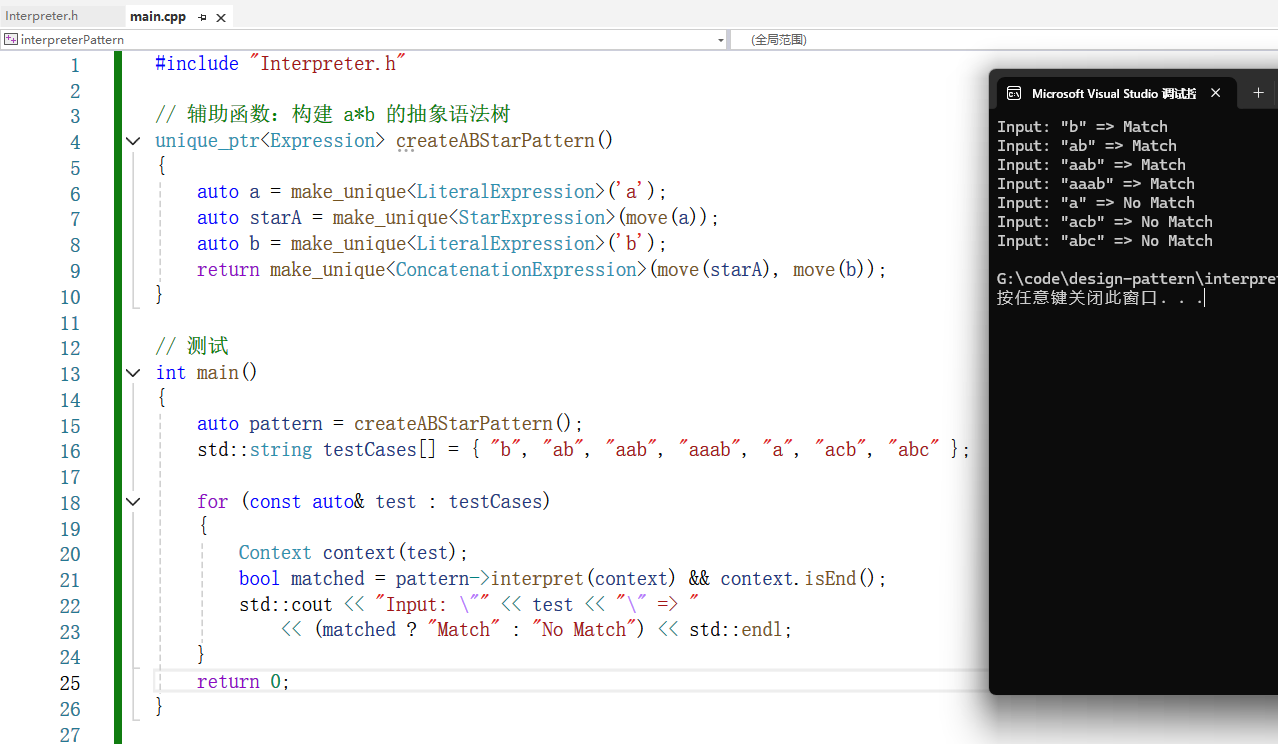
可以看到,输出结果与预期相符合。
四.解释器的优点
- 将每一个语法规则表达成一个类,使得语言容易实现。
- 因为语法由类表示,你可以轻易地改变或扩展该语言。
- 通过在类结构中添加方法,可以添加解释之外的新行为,例如打印格式的美化。
五.解释器模式的缺点
- 当语法规则的数目很大时,这个模式可能变得笨重。在这些情况下,一个解析器/编译器的生成器可能更适合。
- 复杂语法会导致 "类爆炸"、递归深度过大会有栈溢出风险、嵌套表达式会有性能问题
六.解释器模式的用途
- 当你需要实现一门简单的语言时,使用解释器。
- 当你由一个简单的语法,而且简单比效率重要时,适合用解释器。
- 用于脚本和编程语言。