从文字描述到高清图像,Stable Diffusion通过潜在空间扩散、文本条件引导与U-Net去噪的精密协同,实现了生成式AI的工程化突破。本文将深入拆解其三大核心组件(VAE、U-Net、CLIP)的协作机制,并提供从零开始的实战代码,带你掌握文本到图像生成的完整技术栈。
1 引言与背景:从像素扩散到潜在空间革命
传统的扩散模型(如DDPM)直接在像素空间进行迭代去噪,生成一张512×512的RGB图像需要处理约78.6万个像素点 (512×512×3),每一步的卷积运算与梯度更新均面临巨大的计算压力。这种架构虽然能产出高质量图像,但训练成本常达数百GPU天,推理延迟也难满足实时应用需求。
2022年,Robin Rombach等人发表的论文《High‑Resolution Image Synthesis with Latent Diffusion Models》(CVPR 2022 Oral)提出潜在扩散模型(LDM) ,将扩散过程从像素空间移至低维潜在空间。这一设计的核心优势在于:
- 计算效率跃升 :图像经变分自编码器(VAE)压缩为64×64×4的潜在表示,数据量减少至原来的约1/64,训练与推理时间大幅缩短;
- 细节保留与可控性平衡:潜在空间既保留了足够的语义信息(纹理、结构、色彩分布),又避免了像素级冗余,使模型更容易学习高级特征;
- 条件生成泛化:通过交叉注意力(Cross‑Attention)将CLIP文本嵌入融入去噪过程,实现了细粒度的文本‑图像对齐。
Stable Diffusion作为LDM的首个大规模开源实现,迅速成为生成式AI的标杆。其架构由三个专业模块组成:
| 组件 | 模型类型 | 输入维度 | 输出维度 | 参数量级 | 核心作用 |
|---|---|---|---|---|---|
| VAE(变分自编码器) | AutoencoderKL | 512×512×3 | 64×64×4 | ≈8500万 | 图像⇄潜在空间的双向映射 |
| U‑Net(条件去噪网络) | UNet2DConditionModel | 64×64×4 | 64×64×4 | ≈8.6亿 | 在文本引导下逐步去除噪声 |
| CLIP(文本编码器) | CLIPTextModel | 77 tokens | 77×768 | ≈1.23亿 | 将自然语言转换为语义向量 |
该架构在消费级GPU(≥10 GB显存)上即可运行,使得高质量图像生成从实验室走向千家万户。下面我们将逐一拆解各模块的数学原理与工程实现。
2 核心原理分析:三大组件的协同工作机制
2.1 VAE:图像与潜在空间的桥梁
变分自编码器(VAE)由编码器 EEE 与解码器 DDD 组成,其目标是最小化重建损失与正则项:
LVAE=∥x−D(z)∥22⏟重建损失+β⋅DKL (q(z∣x) ∥ N(0,I))⏟KL散度正则 \mathcal{L}{\text{VAE}} = \underbrace{\|x - D(z)\|2^2}{\text{重建损失}} + \beta \cdot \underbrace{D{\text{KL}}\!\big(q(z|x) \,\|\, \mathcal{N}(0, I)\big)}_{\text{KL散度正则}} LVAE=重建损失 ∥x−D(z)∥22+β⋅KL散度正则 DKL(q(z∣x)∥N(0,I))
其中 q(z∣x)=N(μ(x),σ2(x))q(z|x) = \mathcal{N}\big(\mu(x), \sigma^2(x)\big)q(z∣x)=N(μ(x),σ2(x)) 是编码器输出的分布,zzz 通过重参数化技巧采样:z=μ+σ⊙ϵ, ϵ∼N(0,I)z = \mu + \sigma \odot \epsilon,\ \epsilon \sim \mathcal{N}(0, I)z=μ+σ⊙ϵ, ϵ∼N(0,I)。
关键设计细节:
- 下采样因子:Stable Diffusion采用8倍下采样,将512×512×3图像压缩为64×64×4的潜在张量,计算量减少约64倍;
- 缩放因子:训练时潜在向量乘以固定缩放因子0.18215,以匹配扩散模型的数值范围;
- KL散度权重 (β\betaβ):通常设为0.001,平衡重建质量与潜在空间的正则化。
VAE的编码器仅在训练阶段使用,推理时仅需解码器将去噪后的潜在向量 z0z_0z0 映射回像素空间:
x^=D(z0/0.18215) \hat{x} = D(z_0 / 0.18215) x^=D(z0/0.18215)
2.2 CLIP:文本语义的向量化表示
CLIP(Contrastive Language‑Image Pre‑training)通过对比学习将文本与图像映射到同一语义空间。在Stable Diffusion中,CLIP文本编码器将提示词(prompt)转换为上下文感知的嵌入向量。
处理流程:
- 分词 :使用BPE分词器将输入文本转换为整数ID序列,例如
"a cat wearing steampunk goggles"→[101, 1032, 4937, 2031, 10547, 4012]; - 截断/填充:序列长度固定为77(Stable Diffusion v1‑v2),超长部分截断,不足部分用零填充;
- Transformer编码 :12层ViT‑L/14模型输出每个token的768维向量,得到形状为 (1,77,768)(1, 77, 768)(1,77,768) 的文本嵌入 EtextE_{\text{text}}Etext。
注意 :实际生成时,通常同时计算条件嵌入 (有prompt)与无条件嵌入(空prompt),用于分类器自由引导(CFG):
Ecfg=Euncond+s⋅(Econd−Euncond) E_{\text{cfg}} = E_{\text{uncond}} + s \cdot (E_{\text{cond}} - E_{\text{uncond}}) Ecfg=Euncond+s⋅(Econd−Euncond)
其中 sss 为引导尺度(guidance scale),典型值为7.5~12.0。
2.3 U‑Net:文本引导下的迭代去噪
U‑Net是扩散模型的核心生成引擎 ,其目标是在每一步 ttt 预测添加到噪声潜在 ztz_tzt 中的噪声 ϵ\epsilonϵ。训练目标简化为均方误差:
Ldiff=Et,x0,ϵ ∥ϵ−ϵθ(zt,t,Etext)∥22 \mathcal{L}{\text{diff}} = \mathbb{E}{t, x_0, \epsilon}\!\Big \\\|\\epsilon - \\epsilon_\\theta(z_t, t, E_{\\text{text}})\\\|_2\^2 \\Big Ldiff=Et,x0,ϵ∥ϵ−ϵθ(zt,t,Etext)∥22
其中 zt=αˉtz0+1−αˉtϵz_t = \sqrt{\bar{\alpha}_t} z_0 + \sqrt{1-\bar{\alpha}_t} \epsilonzt=αˉt z0+1−αˉt ϵ,αˉt\bar{\alpha}_tαˉt 为噪声调度系数。
架构创新点:
- 交叉注意力层 :文本嵌入 EtextE_{\text{text}}Etext 作为Key/Value,潜在特征作为Query,实现文本‑图像特征对齐;
- 时间步嵌入 :将标量时间步 ttt 通过正弦位置编码映射为高维向量,调制每层卷积的权重;
- 残差连接与跳跃连接:保留高频细节,避免信息丢失。
U‑Net的输入输出均为64×64×4的潜在张量,通过50~100步的迭代去噪,逐步将随机高斯噪声 zT∼N(0,I)z_T \sim \mathcal{N}(0, I)zT∼N(0,I) 转化为符合文本条件的干净潜在 z0z_0z0。
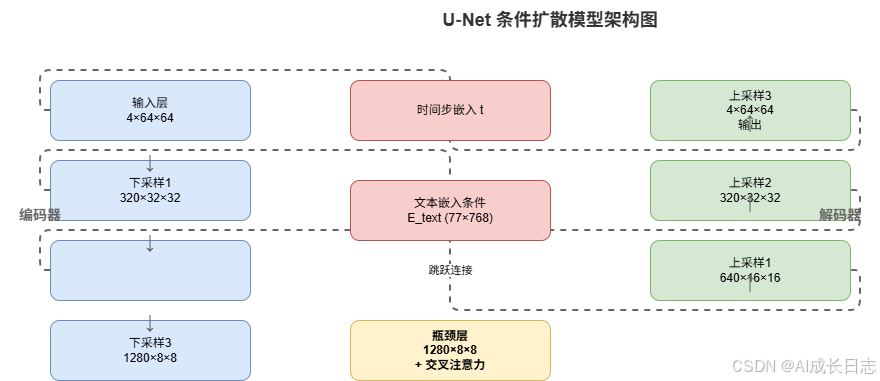
2.4 调度器:控制噪声衰减的节拍器
调度器(Scheduler)管理扩散过程中的噪声强度与时间步序列。常见调度器包括:
| 调度器 | 特点 | 适用场景 |
|---|---|---|
| DDIM | 确定性采样,生成结果可复现 | 实验调试、风格一致性要求高 |
| Euler A | 随机性较强,创意发散 | 艺术创作、抽象图像 |
| DPM++ 2M Karras | 高质量、收敛稳定 | 商业级输出、写实图像 |
噪声调度函数 αt\alpha_tαt 通常采用余弦调度(cosine schedule),避免早期阶段噪声衰减过快:
αt=cos(t/T+s)1+s(简化形式) \alpha_t = \frac{\cos(t/T + s)}{1+s} \quad \text{(简化形式)} αt=1+scos(t/T+s)(简化形式)
在实际采样循环中,调度器根据预测噪声 ϵθ\epsilon_\thetaϵθ 和当前时间步 ttt 计算更新步长,得到更干净的潜在 zt−1z_{t-1}zt−1。
3 架构设计与实现:从模块拼接到完整流程
3.1 整体生成流水线
一次完整的文本到图像生成包含以下步骤:
输入提示词 Prompt
CLIP 文本编码器
文本嵌入 E_text
1×77×768
初始化高斯噪声 z_T
1×4×64×64
迭代去噪循环
for t = T to 1
U‑Net 预测噪声 ε_θ
条件: E_text, t
调度器更新潜在 z_t → z_t-1
最终潜在 z_0
VAE 解码器
输出图像 x_hat
512×512×3
3.2 关键代码实现(核心逻辑≤20行)
以下代码使用Hugging Face diffusers 库,展示了Stable Diffusion生成流程的关键片段(省略了完整的错误处理与环境配置)。
3.2.1 CLIP文本编码器调用
python
import torch
from transformers import CLIPTokenizer, CLIPTextModel
def encode_prompt(prompt, tokenizer, text_encoder):
"""将文本提示编码为嵌入向量"""
# 分词与填充
text_inputs = tokenizer(
prompt,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt"
)
input_ids = text_inputs.input_ids
# 获取文本嵌入
with torch.no_grad():
text_embeddings = text_encoder(input_ids)[0]
return text_embeddings # 形状: (1, 77, 768)3.2.2 U‑Net条件扩散前向传播
python
def unet_forward_step(noisy_latents, timestep, text_embeddings, unet):
"""U‑Net单步噪声预测"""
# 时间步嵌入
t_emb = unet.time_proj(timestep)
t_emb = unet.time_embedding(t_emb)
# 条件输入:噪声潜在 + 时间嵌入 + 文本嵌入
noise_pred = unet(
sample=noisy_latents,
timestep=timestep,
encoder_hidden_states=text_embeddings
).sample
return noise_pred # 形状同 noisy_latents3.2.3 VAE解码器实现
python
def decode_latents(latents, vae):
"""将潜在向量解码为图像"""
# 缩放因子逆变换
latents = latents / 0.18215
with torch.no_grad():
image = vae.decode(latents).sample
# 归一化到 [0, 1]
image = (image / 2 + 0.5).clamp(0, 1)
return image # 形状: (1, 3, 512, 512)3.2.4 完整生成循环(简化版)
python
def generate_image(prompt, pipe, num_steps=50, guidance_scale=7.5):
"""文本到图像生成主函数"""
# 1. 文本编码
text_embeds = encode_prompt(prompt, pipe.tokenizer, pipe.text_encoder)
uncond_embeds = encode_prompt("", pipe.tokenizer, pipe.text_encoder)
# 2. 初始化噪声潜在
latents = torch.randn((1, 4, 64, 64), device=pipe.device)
# 3. 迭代去噪
for i, t in enumerate(pipe.scheduler.timesteps[:num_steps]):
# 分类器自由引导:拼接条件与无条件嵌入
latent_model_input = torch.cat([latents] * 2)
text_input = torch.cat([uncond_embeds, text_embeds])
# 预测噪声
noise_pred = unet_forward_step(latent_model_input, t, text_input, pipe.unet)
# 分离条件/无条件预测
noise_pred_uncond, noise_pred_cond = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_cond - noise_pred_uncond)
# 调度器更新潜在
latents = pipe.scheduler.step(noise_pred, t, latents).prev_sample
# 4. VAE解码
image = decode_latents(latents, pipe.vae)
return image3.3 架构示意图
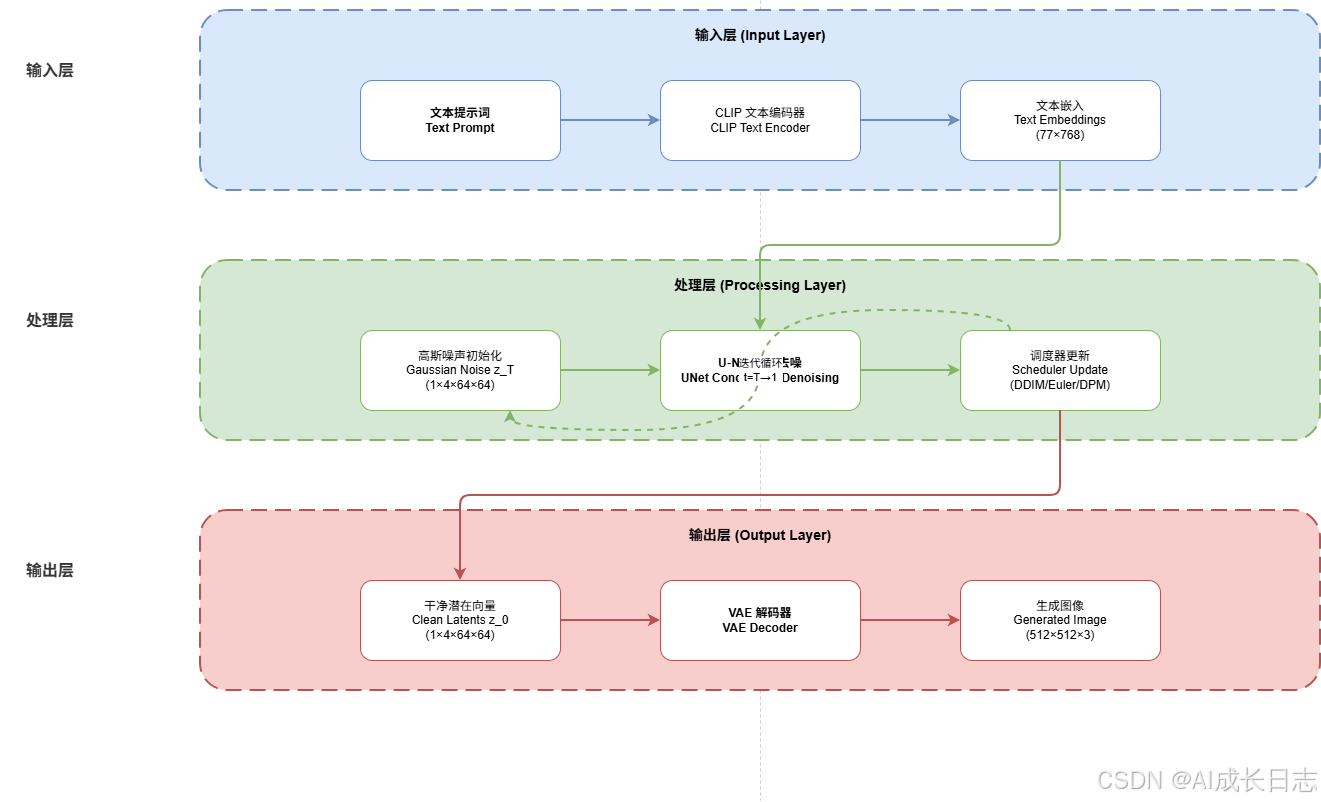
上图展示了Stable Diffusion三大组件的数据流与协作关系:
- 文本流:Prompt → CLIP Tokenizer → CLIP Text Encoder → 文本嵌入;
- 生成流:高斯噪声 → 迭代去噪(U‑Net + 调度器)→ 干净潜在;
- 解码流:潜在向量 → VAE解码器 → 高清图像。
4 实战案例与优化:从基础生成到高级调优
4.1 基础生成示例
下面是一个完整的、可直接运行的Stable Diffusion生成脚本:
python
from diffusers import StableDiffusionPipeline
import torch
# 1. 加载模型(半精度以节省显存)
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
variant="fp16"
).to("cuda")
# 2. 定义生成参数
prompt = "A cyberpunk cityscape at night, neon lights reflecting on wet streets, 4k detailed"
negative_prompt = "blurry, low resolution, deformed"
num_steps = 30
guidance_scale = 10.0
# 3. 生成图像
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=num_steps,
guidance_scale=guidance_scale,
).images[0]
# 4. 保存结果
image.save("cyberpunk_city.png")运行环境要求:
- Python 3.8+
- PyTorch 1.12+(与CUDA版本匹配)
- 至少10 GB显存(半精度模式)
- 安装依赖:
pip install diffusers transformers accelerate
4.2 高级调优技巧
4.2.1 负面提示词(Negative Prompt)策略
负面提示词用于排除不希望出现的特征,提升生成质量:
python
negative_prompt = """
ugly, deformed, noisy, blurry, low contrast,
distorted anatomy, bad proportions, extra limbs,
cloned face, mutilated, oversaturated
"""效果对比:
- 无负面提示词:可能出现脸部畸形、背景混乱;
- 加入负面提示词:显著改善解剖结构准确性、色彩平衡。
4.2.2 采样器选择与步数权衡
不同采样器对生成速度与质量的影响:
| 采样器 | 推荐步数 | 特点 | 适用场景 |
|---|---|---|---|
| Euler A | 20‑30 | 快速,创意发散 | 概念艺术、快速原型 |
| DDIM | 40‑50 | 确定性,细节丰富 | 写实图像、风格一致性 |
| DPM++ 2M Karr | 30‑40 | 高质量,收敛稳定 | 商业级输出、产品渲染 |
经验公式:推理时间 ≈ 步数 × 单步耗时(约0.1‑0.3秒/步,取决于硬件)。
4.2.3 引导尺度(Guidance Scale)调整
引导尺度 sss 控制文本条件的强度:
- s<5s < 5s<5:生成自由度高,但可能偏离提示;
- 5≤s≤105 \le s \le 105≤s≤10:平衡创意与文本遵循;
- s>10s > 10s>10:严格遵循提示,但可能丧失多样性。
调优建议 :从 s=7.5s=7.5s=7.5 开始,根据生成结果微调 ±2.0。
4.3 性能优化技术
4.3.1 显存优化:注意力切片与模型卸载
python
# 启用注意力切片(降低显存峰值)
pipe.enable_attention_slicing()
# 启用CPU卸载(显存不足时)
pipe.enable_model_cpu_offload()4.3.2 推理加速:xFormers与TensorRT
python
# 安装xFormers:pip install xformers
pipe.enable_xformers_memory_efficient_attention()
# ONNX导出与TensorRT优化(生产部署)
pipe = pipe.to("cuda")
pipe.unet = torch.compile(pipe.unet) # PyTorch 2.0 编译加速4.3.3 批量生成与缓存优化
python
# 批量生成(提升吞吐)
prompts = ["mountain landscape", "portrait of a knight", "abstract geometry"]
images = pipe(prompts, num_inference_steps=30).images
# KV缓存(减少重复计算)
pipe.unet.set_use_memory_efficient_attention(True)4.4 生成质量评估指标
| 指标 | 说明 | 目标值 |
|---|---|---|
| FID(Fréchet Inception Distance) | 生成图像与真实图像分布距离 | < 20(越低越好) |
| CLIP Score | 文本‑图像语义对齐度 | > 0.25(越高越好) |
| 美学评分(LAION‑Aesthetics) | 图像审美质量 | > 6.0(满分10) |
评估脚本示例:
python
from torchmetrics.image.fid import FrechetInceptionDistance
from PIL import Image
# 计算FID
fid = FrechetInceptionDistance(feature=2048)
fid.update(real_images, real=True)
fid.update(generated_images, real=False)
fid_score = fid.compute()
print(f"FID Score: {fid_score:.2f}")5 总结与展望:文本到图像生成的技术演进
5.1 技术总结
Stable Diffusion通过 VAE‑U‑Net‑CLIP 三元架构,实现了文本到图像生成的高效、可控与高质量:
- VAE:将图像压缩至低维潜在空间,降低计算复杂度64倍;
- U‑Net:在文本条件引导下执行迭代去噪,逐步生成语义对齐的潜在表示;
- CLIP:将自然语言转换为可计算的语义向量,提供细粒度的生成引导。
该架构的核心创新在于潜在空间扩散,相比像素空间扩散,在保持视觉质量的同时大幅提升了生成速度与资源效率。
5.2 前沿进展与未来趋势
5.2.1 架构演进:从U‑Net到MMDiT
2025年发布的Stable Diffusion 3.5 采用 多模态扩散Transformer(MMDiT) 替代传统U‑Net,实现文本‑图像的双向精准交互:
- 参数规模:从860M跃升至81亿,多模态理解能力显著增强;
- 注意力机制:QK归一化与双重注意力层,确保超大规模参数下的训练稳定性;
- 版本策略:提供Large(81亿)、Medium(25亿)与Turbo(4步成像)三个版本,适配不同硬件需求。
5.2.2 推理加速:蒸馏与一致性模型
为满足实时生成需求,业界发展了多种加速技术:
- 渐进式蒸馏:将教师模型的50步去噪过程压缩至学生模型的4步,速度提升10倍以上;
- 一致性模型:学习直接映射噪声潜在到干净潜在,实现单步高质量生成;
- 硬件定制优化:TensorRT‑LLM、ONNX Runtime等推理引擎的针对性优化。
5.2.3 应用拓展:多模态与可控生成
未来文本到图像生成将向以下方向演进:
- 视频生成:将扩散模型扩展至时间维度,实现文本到视频生成;
- 3D内容生成:结合NeRF与扩散模型,从文本生成三维场景与物体;
- 精细控制:通过ControlNet、IP‑Adapter等插件,实现对构图、姿势、风格的像素级控制。
5.3 实践建议
对于希望深入文本到图像生成领域的开发者,建议:
- 基础掌握:理解扩散模型的数学原理与Stable Diffusion的三元架构;
- 工具熟练 :掌握Hugging Face
diffusers、transformers等核心库的使用; - 调优经验:积累提示词工程、采样器选择、引导尺度调整等实战经验;
- 前沿跟踪:关注arXiv最新论文,了解MMDiT、一致性模型等最新进展。
6 常见问题与解决方案:实战中的典型问题排查
6.1 显存不足与优化策略
问题现象:运行Stable Diffusion时出现CUDA out of memory错误,尤其在生成高分辨率图像或使用较大模型时。
解决方案:
- 启用注意力切片 :
pipe.enable_attention_slicing(),将注意力计算分块处理,降低显存峰值; - 使用半精度推理 :加载模型时指定
torch_dtype=torch.float16,显存占用减半; - CPU卸载 :
pipe.enable_model_cpu_offload(),动态将暂时不用的层移到CPU内存; - 降低图像分辨率:从默认512×512降至384×384,显存需求减少约44%;
- 使用更小模型:考虑SD‑1.5而非SD‑XL,参数量从2.6B降至860M。
示例代码:
python
# 显存优化配置
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16
).to("cuda")
pipe.enable_attention_slicing() # 注意力切片
# pipe.enable_model_cpu_offload() # 显存极紧张时启用6.2 生成质量不佳:模糊、畸形与语义偏差
问题类型及对策:
| 问题类型 | 典型表现 | 解决方案 |
|---|---|---|
| 图像模糊 | 细节缺失,边缘不清晰 | 1. 增加采样步数至40‑50步 2. 使用高质量调度器(DPM++ 2M Karras) 3. 启用高分辨率修复(Hires.fix) |
| 面部畸形 | 五官错位、比例失调 | 1. 添加负面提示词:"deformed face, bad anatomy" 2. 使用面部修复插件(CodeFormer) 3. 调整CFG尺度(7‑10之间) |
| 文本不匹配 | 生成内容与提示词不符 | 1. 检查提示词语法(英文逗号分隔) 2. 增加关键权重:(important:1.2) 3. 使用更强大的文本编码器(CLIP‑L) |
技术原理:CFG(分类器自由引导)尺度控制生成多样性‑忠实度的平衡。过低(<5)导致创意发散,过高(>12)可能引发畸变。推荐范围7‑10。
6.3 生成速度慢:实时应用瓶颈
性能瓶颈分析:
- 模型加载:首次加载约15‑30秒(取决于硬件与网络);
- 去噪迭代:单步耗时0.1‑0.3秒,50步需5‑15秒;
- 解码阶段:VAE解码约0.5‑1秒。
加速方案:
- 使用蒸馏模型:SD‑Turbo、LCM‑Lora等可实现4‑8步高质量生成;
- 启用xFormers :
pipe.enable_xformers_memory_efficient_attention(),提升20‑30%推理速度; - 编译优化 :PyTorch 2.0+ 的
torch.compile()可进一步加速; - TensorRT部署:生产环境下使用TensorRT‑LLM进行极致优化。
基准测试参考(RTX 4090, 512×512, 30步):
- 原生SD‑1.5:约4.2秒
- 启用xFormers:约3.1秒
- SD‑Turbo(4步):约0.8秒
6.4 特定场景适配:风格迁移与领域定制
常见需求:
- 动漫风格生成:使用Waifu‑Diffusion、Anything‑v3等专用模型;
- 商业设计应用:结合ControlNet实现构图控制、色彩约束;
- 科学研究可视化:训练领域特定的LoRA适配器。
工作流程:
- 数据准备:收集目标领域图像‑文本对(≥1000组);
- 模型选择:基于基础模型(SD‑1.5/XL)进行微调;
- 训练配置:LoRA(低秩适应)参数高效微调;
- 评估部署:人工评估+自动指标(CLIP Score、FID)。
注意事项:
- 避免过拟合:使用数据增强、早停策略;
- 版权合规:确保训练数据来源合法;
- 计算成本:单次微调约10‑50 GPU时。
6.5 跨平台部署:移动端与边缘设备
技术挑战:
- 模型压缩:从8.6亿参数降至2‑3亿,保持视觉质量;
- 推理引擎:适配TensorFlow Lite、Core ML、ONNX Runtime;
- 实时性要求:端侧设备推理延迟需<2秒。
解决方案架构:
原始模型 → 知识蒸馏 → 量化(INT8/FP16) → 图优化 → 引擎编译推荐工具链:
- 模型压缩:NNCF(Neural Network Compression Framework)
- 格式转换 :
optimum.exporters.onnx、tf‑mobile‑net‑converter - 推理引擎:TFLite GPU Delegate、Core ML Tools
性能目标:高端手机(骁龙8 Gen 3)上512×512图像生成时间<5秒。
5.4 资源推荐
- 论文 :
- 《High‑Resolution Image Synthesis with Latent Diffusion Models》(LDM原论文)
- 《Progressive Distillation for Fast Sampling of Diffusion Models》
- 《Consistency Models》
- 代码库 :
- Hugging Face Diffusers:https://github.com/huggingface/diffusers
- Stable Diffusion WebUI:https://github.com/AUTOMATIC1111/stable-diffusion-webui
- 数据集:LAION‑5B、COCO、OpenImages