一、单个图像的识别原理
1.灰度:将颜色类别简单化,把不合适的差异颜色大的给过滤掉。
简单的图像规则图像颜色比较单一,它不像咱们正常一张照片。正常,它会受到光泽影响,颜色是渐变的。我们正常识别的物体,它的颜色它是有个过渡范围的。我们对如下图片行识别。先按照颜色跟它一样的颜色进行筛选,那么筛选之后。我们是怎么筛选是先进行灰度。
灰度就是将颜色类别简单化,把不合适的差异颜色差异大的给它过滤掉。这样图片就变得简单一些了。那么剩下来的都是颜色一样的,那么我们如何识别他们的形状呢?----:由边缘决定。
2.图片的边缘:
我们知道图片是由像素点组成,那么如何去找到他的边缘像素点呢?
我们需要遍历每一个像素点,然后以这个像素点为中心画出一个半径为XX的圆。一个边缘像素点以他为xx半径的圆之内至少有两种颜色。所以我们可以通过这个特点来找到边缘像素点。
挑选出来之后,这个像素点都有坐标,我们对它进行求导,不同形状它导数不一样,但是图片当中的C和D,它俩形状一样,但是旋转角度不一样,所以它导数也不一样。但是他们二阶段是一样的,也就是说,我们根据二阶导能把它排除掉,最终选择这两个符合,这是我们之前稍微讲讲的简单的这个图像识别。这个还是相对来说比较容易。
二、复杂照片识别与边缘技术处理
例如:我们想识别一张图片的头部,如下。

我们可能根据它颜色或者眼睛或者是嘴巴去识别他头部,那万一他侧对着咱们或者后脑勺对着咱们。咱就识别不到他的眼睛和嘴巴。那只能根据他头发来识别。根据他头发识别,我们看到他头发的边缘。边缘很不平凡。边缘是不平滑的。怎么办,这种边缘极度不平滑。我们对它的边缘确定非常麻烦。
第二、这种边缘有很多尖刺求的导数差异也极大。也就说,从远处一看,你看轮廓还可以,你把它放大一进来。它有很多毛发。这样的话,咱们对他来说,识别起来就很困难了。就你要想精确求导。误差会极大,所以其实我们主要想要什么要它的轮廓边缘并不想要它的精细化,边缘能拍得很清晰,比如说识别你的胳膊拿个照相机拍你胳膊连汗毛都拍上了。对汗毛进行求导。整体误差非常大。那么我们应该如何解决呢?
我们将想识别的东西我给咱们画一下。
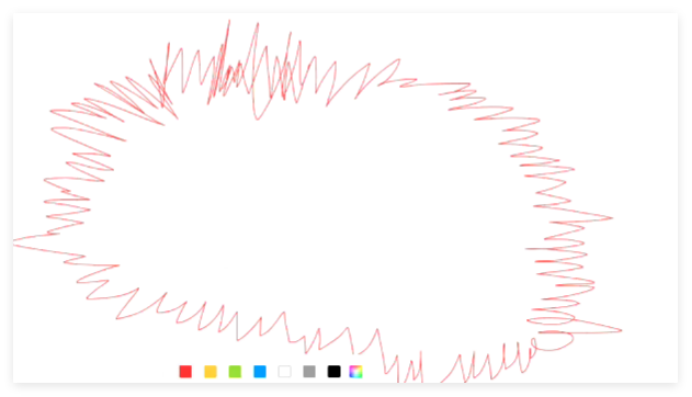
我们想要识别出该物体的轮廓。但是我们发现这个物体的轮廓边缘是在是太精确了。反而导致我们求导整体误差极大。那我们应该如何去解决这个问题呢?
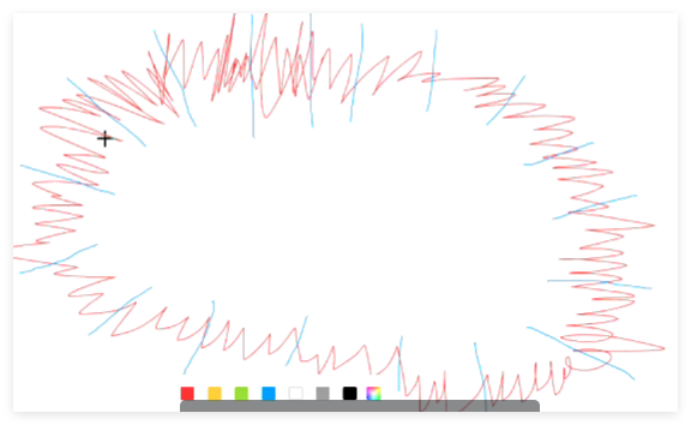
我们可以将其整体切分为多组。我们先对符合这些条件的像素点进行切分,按照坐标范围进行切分的话,形成一组组的
再从每组当中选出个代表点,比如说点来代表他们平均值,每一个区域都选出个平均值。
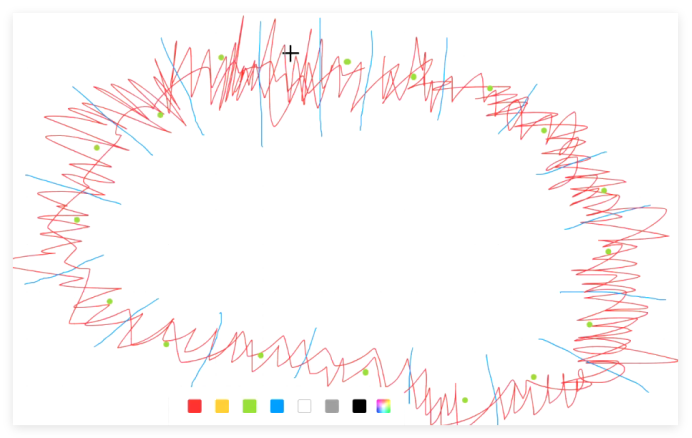
选出平均值之后。连接平均值。由平均值来代替全部的,这样的轮廓就平滑光滑的。也就是说,我们只需要对这个蓝色区域求导,就可以不再对红色区域求导,因为对红色区域求导太精确,反而导致计算不对,而我们现在通过找它们的代表值让边缘变得平滑。边缘变得平滑之后,我们对它的识别精度就提升了计算量也降低了,这就是什么,这叫迟化。:降低边缘的清晰度,让边缘变得平滑!
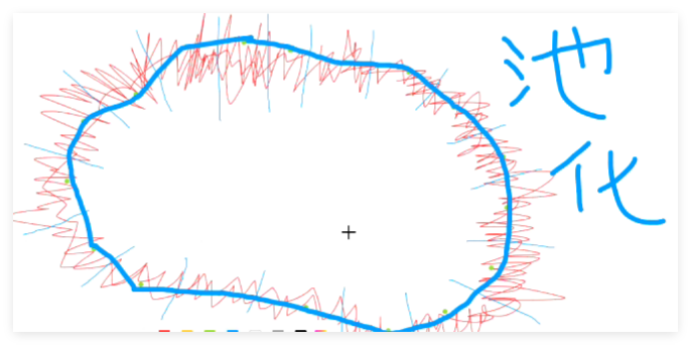
那么这个平均值是怎么找到的呢?
你比如说这个区域的所有的红色的像素点,比方说有一有八百个像素点,求这个八百个像素点的 X 值和 Y 值,比如说 X 值。相加 Y 值相加,各自除以八百,这就平均值。你甚至说,选一个最大的或者是一个最小的都可以。总而言之,就是用一个点来代替它们。只要用一个值来代替它,然后相连。都会变得很平缓。
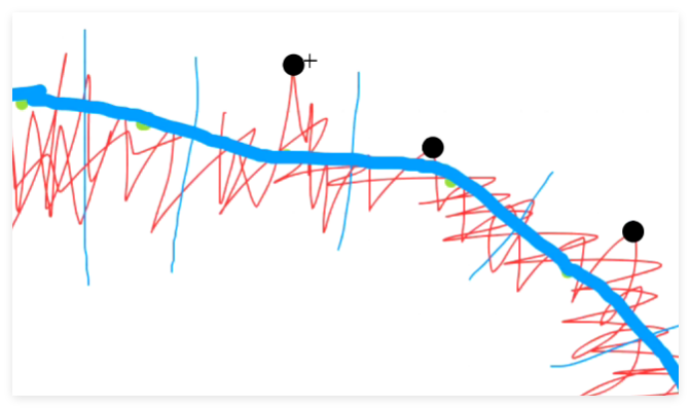
比如咱们选取的每个区域的最高点,连接他们边缘还是会变得很平滑。
边缘检测很容易受到很多小细节的干扰。为了解决这些干扰所以我们需要进行池化。池化就需要分割。此时我们发现切分的太细会不准确,切分的太粗也不会准确。那到底切分多少合适呢?这个要去测试,不同的场景不同的物体切分的力度是不一样的。我们图像识别的关键因素怎么样精准的边缘检测,而边缘检测是否做的精准,跟咱们切分力度还有关系,所以这就涉及到我们图像。而这些yolo都帮我们做了!
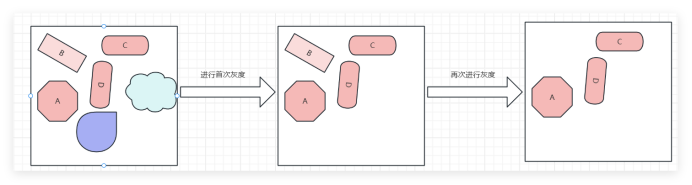
三、标注技术
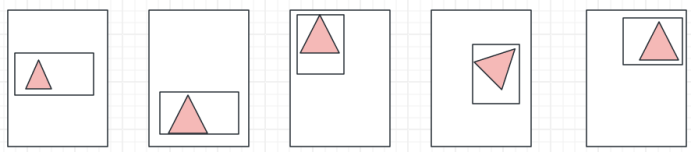
如上图,我们给三角形做标注,那么这些标注是如何识别的呢?首先我们输入图片以后,程序会把标准范围抽取出来,只做这一块区域识别。

从图像上原图上把这块区域的像素点拷贝出来,那拷贝出来之后,它怎么识别?它先根据颜色识别。先识别颜色,寻找颜色比例最大的。训练图片多的话,它自己寻找主流的颜色范围。如果是小范围训练,就说训练的数据没那么大,则可以手动去配置,手动配置程序,以哪个是颜色为主?你比如说就100张图片里边你标注的这些标注的苹果,那每一个颜色全都有点区别,那怎么办,你只能手动去通过配置文件告诉他。
现在通过训练我们找到了主流颜色,但是在我们标注的数据当中,有可能并不是那么准确。你想识别三角形,可能里边有个五角星,如下:

当我们找出颜色最大比例以后,那么可能会存在一些其他的图形也和我们要识别的物体的颜色相似,那如何将图像都识别出来呢?
我们需要都物体进行边缘检测。他自己会进行边缘检测来把它们的边都找出来之后进行二阶求导。找哪个是主流的形状,那会发现三角形是主流的形状,其他的不是主流形状。下次你再给他一张照片去识别,他会寻找某个颜色的三角形,去这个里边去找一找,找到了给你标注出来。yolo框架的原理就是这样的。
实际上我们讲完原理,咱们也可以写出一个框架出来,那其实 yolo 的框架接下来就是精细度识别。他在自己训练过程中,也可能会遇到那种边缘特别烂的那种情况。那我们会发现。识别那种特别复杂的边缘特别乱的那种图片样本太少,还训练不出来,图片数量样本越大。它颜色自己总结归纳的范围越准确,对于行政范围的判定也越准确。我们只需要大量的做标注。
数量越多,它越精准,就是这么来的。你包括它到底对外识别边缘的时候?他这个切分的力度到底是多少,他自己也不确定,样本太小也不确定,但是你给他一万个十万个,他自己确认我切分这些识别的更准一些。这就是训练的由来,数量是标注的越多,训练的越准就是这么来的。
四、图像识别框架的挑战与解决方案
那我们当前这个yolo框架是万能的吗?答案当前不是
比如墙上的裂缝,识别桥梁裂缝那种裂缝,标注了这么大范围,它根本就不是主流颜色,周边的面积才是主流面积。也就说你做标注的时候,如果这个东西太小,现在桥梁还是条线,他逼着你标的特别大,但他自己面积占比特别小,像这种的不好训练!

yolo在进行图像识别的时候会出现三个问题。第一太小的你标完之后它面积占比太小,不好识别第二是这种线。识别裂缝这条线很长,他逼着你把这个什么把这个标注做的特别大,它面积还是占少数?也不行。第三。无法做精确识别。你比如说你识别一下两个物体的距离有多远?他只是负责给你进行识别。他不负责,他的距离是多远?他也做不到。
那像很多场景图像识别很多场景,它得需要你手动这种写代码去识别了,那么你手动写代码就涉及到了原理这一块。很多这种科研的图像只能用标注做出来的很简单。但关键很多特殊场景,他没办法用标注去做。那没法用标注去做,只能咱们通过手动的方式来实现这些了,就是说你的编程你会遍历图像的像素点,你知道怎么进行编译检测,你知道怎么求导。知道相似度,知道概率。你不断的调调调能识别到它为止。能理解的加加一有的这个团队他需要你用 yolo就行了,有的是确实做不到。
**那么还有细一些问题需要我们去解决:**例如有的物体形状不一样,但是颜色一样,有的颜色形状一样,但是颜色不一样对我们yolo框架的识别还是有难度的。你配置里边可以配置上识别的颜色,里边有红色,也有绿色,也有过渡颜色,然后再去识别形状。那种的配置。那种得需要走配置光他靠他自己去识别。它智能性没那么高。
还有一点。它能识别简单型图形,你让它识别一个人脸就直接对人脸做标注,yolo是无法识别的,你看人脸里边颜色不一样。颜色的不一样,对于过于复杂的yolo做不到自动识别。就是你这个里边是个综合体。有这种颜色,这种形状,那种颜色,那种形状。他也很困难。
所以一般识别人脸怎么办?先去识别眼睛,先去识别嘴巴,先去识别眉毛识别完之后识别特征,然后再根据综合特征判断人脸在哪。这是特征值!
**你要碰到复杂的怎么办?**像人脸的就得把人脸拆成多个简单的特征,鼻子在哪,眉毛在哪,眼睛在哪,嘴巴在哪,耳朵在哪?复杂识别。复杂度高的。标注其特征。比如说复杂度高的需要识别什么,需要对它进行多特征识别,每次训练只识别他的某一个特征,然后你最终你的算法上。你的算法上,比如说识别出了 a 特征识别出了 beat,这识别出了 C 特征识别出了 D 特征识别出了 E 特征识别出了 F 特征识别出了 G 特征等等的。你比如说车辆识别,咱们看车辆

你看车辆各种颜色,各种形状都有。你要对车辆识,如果我们直接标注整理车,让他自己训练识别整个车,他做不到,你只能说识别车灯,后视镜轮胎?驾驶什么的,你看车车的不同角度,有的特征,你看得见有的特征你看不见,也就说,对车辆这种识别你就得找车的几百个特征全给他找出来。那你能根据多少个特征能去识别车,从不同角度。我们整个的是一个特征识别涉及到特征识别哪些是强特征,哪些弱特征权重是多少,这涉及到我们人工智能学的各种算法了。到现在才涉及到我们所学的各种 AI 的各种算法,比如说神经网络,先识别这一种特征,再识别这一组特征。在识别这几组特征。
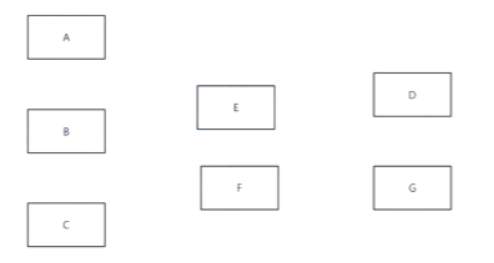
然后将识别的可疑目标当中入参(对应下图当中的1,2,3),将他们的特征进行综合判定。你得看看你这个物体里边有没有这几个特征。哪些是主特征,哪些次特征,这个都得经判定。判定完第一轮之后再识别出新特征,接着再进行判定。然后接着进行判定。最终的话对他们三个进行这个什么进行综合加分123哪个分高。
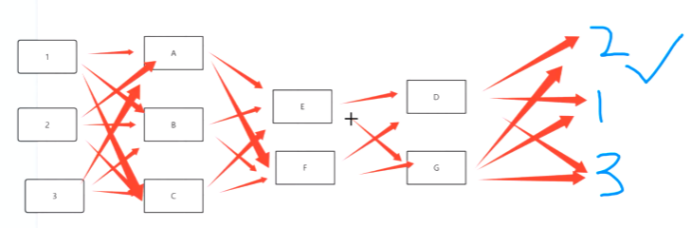
这涉及到神经网络了,但是你特征越多,网络层次越多。识别的越精准!
接下来的各种特征。我们需要用的,根据特征,我们可以聚类回归决策数等等的都有,其实 AI 里边学的很多都是根据特征来的。哪些特征是主要的权重什么都得先去测,先去调。哪些特征就识别他们精准哪些特征重要到什么程度,哪些特征,次要到什么程度就得调系数,所以就它们的重要程度的系数常数都要调整。这就涉及到多系数调整,多参数求解,那就涉及到求偏导求立体图像的问题了。又涉及到梯度下降等等。
所以整个的最终识别这样的整个识别流程,直到你大模型这个不大模型就是 GPU 训练完跑训练,GPU 跑训练。有训练这个模型,这是之前是图。之前这边有训练,这是这个 U 楼的图像训练,还有什么,还有参数训练到精准就是再给你背图片,你能精准识别。能识别到达到百分之多少为止,这就训练完毕了。那么最终形成一个当前识别精度下的常数系数值,就是我们最终的答案就可以发表论文了。