文章目录
- Spark基础概念
-
- [Spark 是什么](#Spark 是什么)
- [Spark VS Hadoop](#Spark VS Hadoop)
- [Spark 四大特点](#Spark 四大特点)
- [Spark 核心模块](#Spark 核心模块)
- [Spark 运行模式](#Spark 运行模式)
- [Spark 架构角色](#Spark 架构角色)
- PySpark与开发环境
- [Spark RDD](#Spark RDD)
-
- [RDD 是什么](#RDD 是什么)
- [RDD 编程入门](#RDD 编程入门)
-
- [程序入口: SparkContext](#程序入口: SparkContext)
- [RDD 的创建](#RDD 的创建)
- [RDD 算子 (Operators)](#RDD 算子 (Operators))
- [常用 Transformation 算子](#常用 Transformation 算子)
- [常用 Action 算子](#常用 Action 算子)
- [RDD 持久化](#RDD 持久化)
- [RDD 共享变量](#RDD 共享变量)
-
- [广播变量(Broadcast Variables)](#广播变量(Broadcast Variables))
- 累加器(Accumulators)
- [Spark 内核调度](#Spark 内核调度)
-
- DAG (有向无环图)
- [宽窄依赖与 Stage 划分](#宽窄依赖与 Stage 划分)
- 任务调度流程
- [Spark SQL](#Spark SQL)
-
- [Spark SQL 是什么](#Spark SQL 是什么)
- DataFrame
-
- [DataFrame 是什么](#DataFrame 是什么)
- [创建 DataFrame](#创建 DataFrame)
- [DataFrame 编程风格](#DataFrame 编程风格)
- [常用 API](#常用 API)
- SparkSession
- 函数与高级特性
Spark基础概念
Spark 是什么
Apache Spark 是一个用于大规模数据处理的统一分析引擎。其核心是 RDD (弹性分布式数据集),它是一种容错的、分布式的内存抽象,允许在大规模集群上进行高效的内存计算。
Spark 借鉴了MapReduce 思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的API提高了开发速度。
Spark VS Hadoop
Spark 在计算速度和易用性上优于 MapReduce,但不能完全替代 Hadoop,因为 Hadoop 提供了完整的生态系统(HDFS 存储, YARN 调度)。
| 对比项 | Hadoop (MapReduce) | Spark |
|---|---|---|
| 类型 | 基础平台 (计算、存储、调度) | 纯计算工具 |
| 计算模型 | 磁盘迭代计算 | 内存迭代计算、交互式计算、流计算 |
| 中间数据 | 存储在 HDFS 磁盘上 | 存储在内存中 |
| 执行方式 | Task 以进程方式运行 | Task 以线程方式运行 |
| API | 底层 (Map/Reduce) | 高层、丰富 |
Spark 四大特点
- 速度快: 官方宣称内存计算速度比 Hadoop MR 快100倍。
- 易于使用: 支持 Java, Scala, Python, R, SQL。
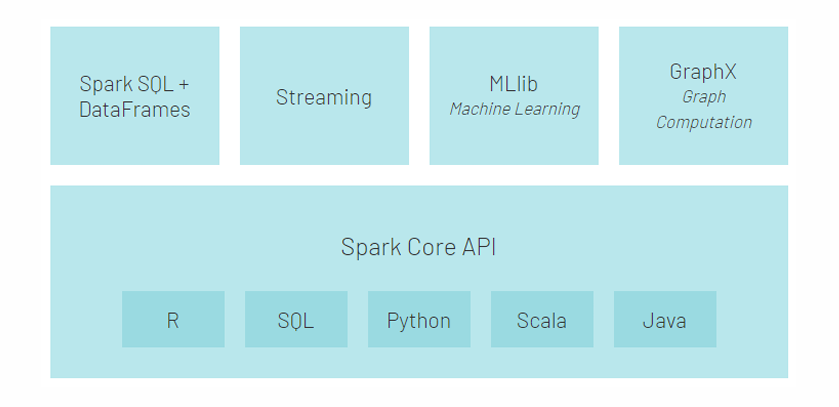
- 通用性强: 提供 Spark SQL, Streaming, MLlib, GraphX 等模块。
- 多种运行模式: Local, Standalone, YARN, Kubernetes。
Spark 核心模块
- Spark Core: 核心引擎,提供 RDD API。
- Spark SQL: 处理结构化数据。
- Spark Streaming / Structured Streaming: 流式计算。
- MLlib: 机器学习库。
- GraphX: 图计算库。
Spark 运行模式
- Local: 单机模式,用于开发测试。
- Standalone: Spark 自带的集群模式。
- YARN: 运行在 Hadoop YARN 资源管理器上(企业常用)。
- Kubernetes: 运行在 K8S 容器编排平台上。
Spark 架构角色
- Master: 集群资源管理者 (类比 YARN 的 ResourceManager)。
- Worker: 单机资源管理者 (类比 YARN 的 NodeManager)。
- Driver: 单个应用的管理者,负责任务调度 (类比 YARN 的 ApplicationMaster)。
- Executor: 真正执行计算任务的工作进程。
PySpark与开发环境
PySpark 库: Spark 官方提供的 Python 类库,可以在标准 Python 代码中 import pyspark 来编写 Spark 应用。
环境准备
在docker环境开发测试
sh
docker pull apache/spark:3.5.1
docker run -itd --name spark-dev --user root -p 4040:4040 -p 18080:18080 apache/spark:3.5.1 sleep infinity
export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin示例代码
python
from pyspark import SparkContext, SparkConf
import os
# 配置环境变量 (可选)
os.environ['SPARK_HOME'] = '/export/server/spark'
if __name__ == '__main__':
# 1. 创建 SparkContext (Driver 的工作)
conf = SparkConf().setAppName("WordCount").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 2. 数据处理 (Executor 的工作)
# 读取数据
wordsRDD = sc.textFile("file:///path/to/word.txt")
# 分割单词
flatMapRDD = wordsRDD.flatMap(lambda line: line.split(" "))
# 转换为 (word, 1) 的元组
mapRDD = flatMapRDD.map(lambda word: (word, 1))
# 按 key 聚合计数
resultRDD = mapRDD.reduceByKey(lambda a, b: a + b)
# 3. 输出结果 (触发 Job 执行)
print(resultRDD.collect())
resultRDD.saveAsTextFile("file:///path/to/output/")
# 4. 关闭上下文 (Driver 的工作)
sc.stop()分布式执行分析
- Driver 负责: 创建 SparkContext、定义计算逻辑 (RDD 转换)、触发 Action (collect, saveAsTextFile)、关闭 SparkContext。
- Executor 负责: 执行具体的 RDD 转换和 Action 计算任务。计算被并行地分发到多个 Executor 上执行。
Spark RDD
RDD 是什么
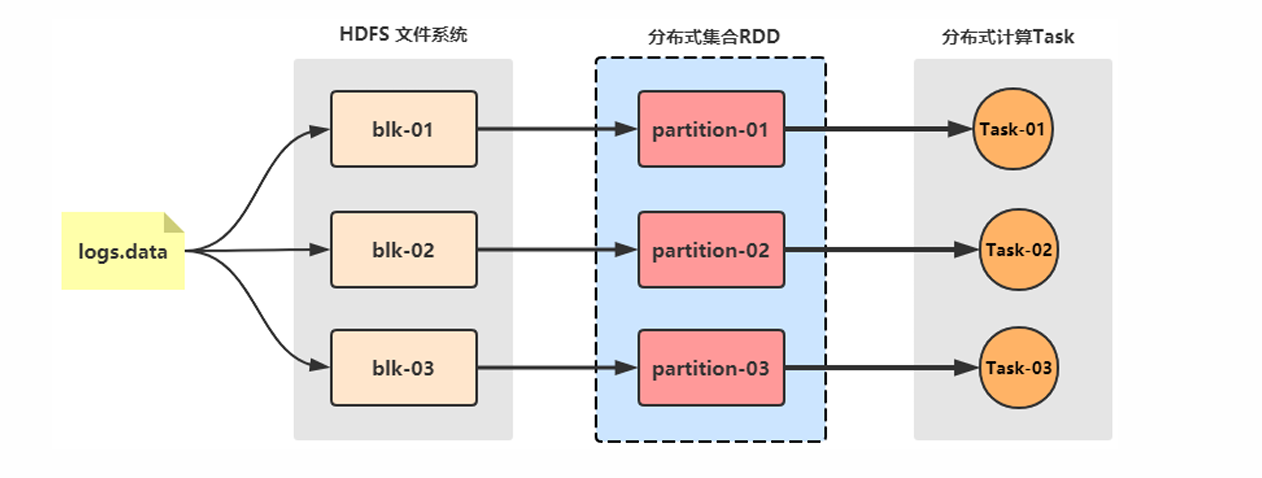
分布式计算需要统一的数据抽象来处理:分区控制、Shuffle 控制、数据序列化/传输、分布式计算 API 等。RDD 是 Spark 中最基本的数据抽象,代表一个不可变、可分区、元素可并行计算的集合。它是所有 Spark 运算和操作的基础。
定义: Resilient Distributed Dataset (弹性分布式数据集)
RDD 编程入门
程序入口: SparkContext
SparkContext 是 Spark 程序的主入口,负责与集群通信、申请资源、创建第一个 RDD。所有后续的 API 调用都基于 SparkContext 对象。
RDD 的创建
主要有两种方式:
并行化集合: 将驱动程序中的本地 Python 集合(如 list)转换为分布式 RDD。
py
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data)读取外部数据源: 从文件系统(如 HDFS, LocalFS)加载数据。
py
# 读取文本文件
rdd = sc.textFile("hdfs://path/to/file.txt")RDD 算子 (Operators)
- Transformation (转换): 从一个或多个 RDD 生成新的 RDD。是懒加载 (Lazy) 的,只有遇到 Action 才会触发实际计算。返回值是一个新的 RDD。
- Action (行动): 触发实际计算,并将结果返回给 Driver 或写入外部存储。返回值不是 RDD(如 list, int, None)。作用:是整个 Transformation 链条的"开关"。
常用 Transformation 算子
- map(func): 对每个元素应用函数。
- flatMap(func): 对每个元素应用函数,然后将结果扁平化。
- filter(func): 过滤出满足条件的元素。
- groupByKey(): 对 (K, V) 型 RDD,将相同 Key 的所有 Value 聚合成一个迭代器。
- reduceByKey(func): 对 (K, V) 型 RDD,先在分区内对相同 Key 的 Value 进行预聚合(Combine),再在分区间进行最终聚合。
- join(other): 对两个 (K, V) 和 (K, W) 型 RDD 进行内连接。
常用 Action 算子
- collect(): 将 RDD 的所有元素以 list 形式返回给 Driver(注意: 仅适用于小数据集)。
- count(): 返回 RDD 中元素的个数。
- take(n): 返回 RDD 中前 n 个元素。
- foreach(func): 对 RDD 中的每个元素应用函数(无返回值,常用于写入外部系统)。
- saveAsTextFile(path): 将 RDD 以文本文件形式保存到指定路径(无返回值)。
RDD 持久化
RDD 的数据是过程数据,默认情况下,RDD 的每次 Action 操作都会从源头开始重新计算整个血缘链(Lineage)。这对于迭代计算或多次使用的 RDD 来说效率极低。
RDD 缓存 (Cache / Persist)
- 目的: 将频繁使用的 RDD 数据物化到内存或磁盘上,避免重复计算。
- API: rdd.cache() 或 rdd.persist(StorageLevel)
- 特点:
轻量化: 数据分散存储在各个 Executor 上。
保留血缘: 如果缓存的数据丢失,可以通过血缘关系重新计算。
存储级别: 可以选择 MEMORY_ONLY, MEMORY_AND_DISK, DISK_ONLY 等。
RDD 检查点 (Checkpoint)
- 目的: 将 RDD 的数据可靠地保存到一个容错的分布式文件系统(如 HDFS)上,并切断血缘关系。
- API: 需要先设置检查点目录 sc.setCheckpointDir("hdfs://..."),然后调用 rdd.checkpoint()。
- 特点:
重量级: 涉及网络 IO,将数据集中写入 HDFS。
安全: HDFS 提供多副本容错。
切断血缘: 一旦设置了检查点,该 RDD 的祖先依赖关系会被移除,后续计算直接从检查点数据开始。
| 特性 | Cache/Persist | Checkpoint |
|---|---|---|
| 存储位置 | 内存/磁盘 (Executor) | HDFS (或其他可靠文件系统) |
| 数据可靠性 | 低 (依赖血缘恢复) | 高 (HDFS 多副本) |
| 血缘关系 | 保留 | 切断 |
| 性能 | 高 (本地读取) | 低 (涉及网络IO) |
| 适用场景 | 迭代计算、临时复用 | 长血缘、需要切断依赖、确保容错 |
RDD 共享变量
在 Spark 的分布式执行模型中,Driver 程序会将用户定义的函数(如 map、filter 中的 lambda)序列化后发送到各个 Executor 上执行。默认情况下,这些函数所引用的外部变量会被复制到每个 Task 中,彼此之间互不影响。
然而,在某些场景下,我们需要在多个 Task 之间共享或聚合数据。为此,Spark 提供了两种特殊的共享变量:广播变量(Broadcast Variables) 和 累加器(Accumulators)。
广播变量(Broadcast Variables)
- 目的: 高效地向所有 Executor 节点分发一个大型只读值(如字典、查找表、配置信息)。
- 解决的问题: 如果直接在闭包中使用一个大型变量(例如一个 1GB 的 dict),那么每次提交 Task 时,这个变量都会被序列化并随 Task 一起发送,造成巨大的网络开销和内存浪费。
- 工作原理:
Driver 将变量封装成一个广播变量。
Spark 使用高效的广播算法(如 BitTorrent 协议的变种)将该变量一次性发送到每个 Executor 节点。
该变量在 Executor 的内存中只保存一份副本,所有在该节点上运行的 Task 都可以共享读取它。 - 特点:
只读: 广播变量一旦创建就不能被修改。
节省资源: 极大地减少了网络传输和 Executor 内存占用。
生命周期: 与 SparkContext 绑定,当 SparkContext 关闭时,广播变量也会被清除。 - API 使用:
py
# 在 Driver 上创建广播变量
lookup_dict = {"key1": "value1", "key2": "value2"}
broadcast_dict = sc.broadcast(lookup_dict)
# 在算子中使用
rdd.map(lambda x: (x, broadcast_dict.value.get(x, "unknown"))).collect()累加器(Accumulators)
- 目的: 提供一种线程安全且高效的"加法"操作,用于在所有 Task 之间进行全局聚合(如计数器、求和)。
- 解决的问题: 在分布式环境下,普通的 Python 变量无法在多个 Task 之间安全地更新和聚合。
- 工作原理:
Driver 创建一个累加器。
Executor 上的 Task 只能对累加器执行 add 操作(或其他关联、可交换的操作)。
Spark 会在后台自动将各个 Task 的局部累加结果汇总回 Driver。
只有 Driver 可以读取累加器的最终值。 - API 使用:
py
# 创建一个整数累加器,初始值为 0
accum = sc.accumulator(0)
def count_words(line):
global accum
words = line.split()
accum += len(words) # Task 中只能执行 add 操作
return len(words)
rdd.foreach(count_words)
print(f"Total words: {accum.value}") # 只能在 Driver 上读取- 内置类型: Spark 原生支持数值型(Int, Float)和集合型(CollectionAccumulator)累加器。
- 自定义累加器: 用户可以通过实现 AccumulatorParam 接口来创建自定义类型的累加器。
- 特点:
写(更新): 只能在 Executor 的 Task 中进行。
读: 只能在 Driver 程序中读取最终结果。
容错性: Spark 会确保累加器的更新操作是幂等的,即使 Task 失败重试,最终结果也是正确的。
用途: 主要用于调试、监控和计数,而不是作为主要的计算逻辑输出。
Spark 内核调度
DAG (有向无环图)
Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心实现的重要一环,其作用就是任务调度。Spark的任务调度就是如何组织任务去处理RDD中每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage,
将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理,可以合理规划资源利用,做到尽可能用最少的资源高效地完成任务计算。
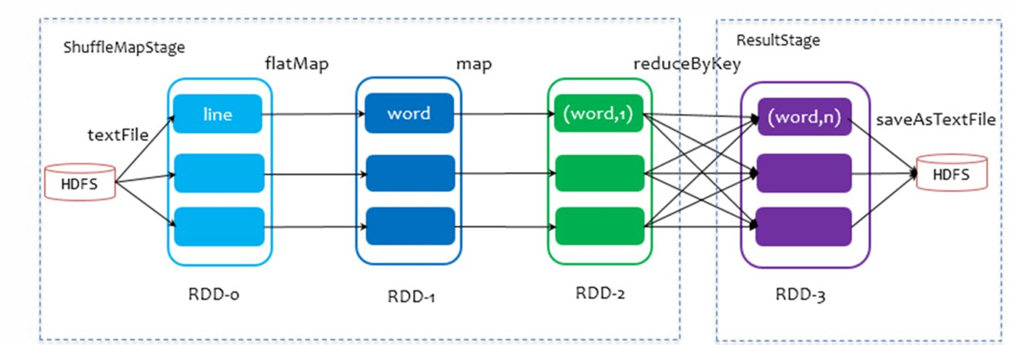
宽窄依赖与 Stage 划分
- 窄依赖 (Narrow Dependency): 父 RDD 的每个分区最多被子 RDD 的一个分区所依赖(如 map, filter)。可以在内存中形成计算管道 (Pipeline)。
- 宽依赖 (Wide Dependency / Shuffle Dependency): 父 RDD 的每个分区可能被子 RDD 的多个分区所依赖(如 groupByKey, reduceByKey)。需要进行 Shuffle 操作。
- Stage 划分: DAG Scheduler 会根据宽依赖将 DAG 切分成多个 Stage。每个 Stage 内部都是窄依赖,可以进行流水线式计算。
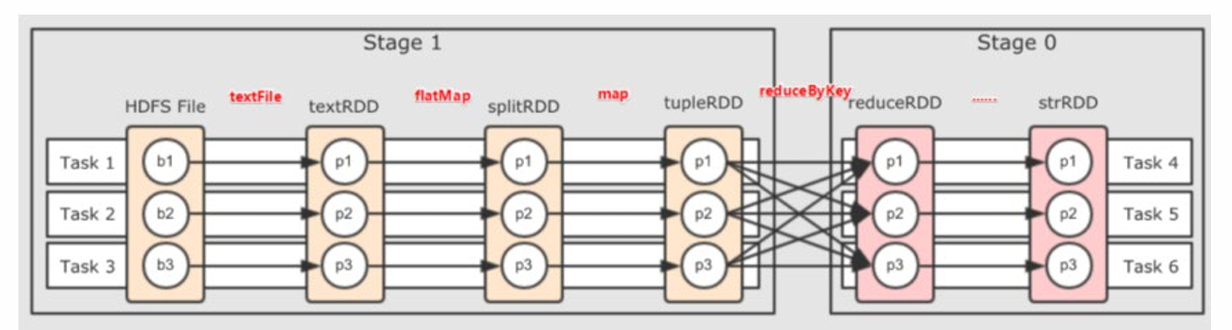
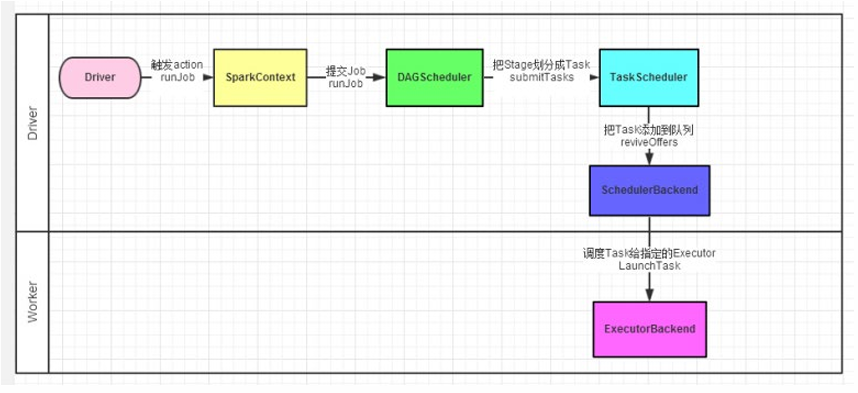
任务调度流程
- 用户代码触发 Action。
- DAGScheduler 将 Job 划分为多个 Stage。
- TaskScheduler 将每个 Stage 的 TaskSet 提交给集群管理器(如 YARN)。
- Executor 在 Worker 节点上接收并执行 Task。
- Task 执行结果汇报给 Driver。
Spark SQL
Spark SQL 是什么
SparkSQL 是 Spark 的一个模块,专为处理结构化数据而设计。它是一个非常成熟的分布式 SQL 计算引擎。
SparkSQL vs Hive
| 特性 | Hive | SparkSQL |
|---|---|---|
| 计算引擎 | MapReduce | Spark RDD |
| 计算模式 | 磁盘迭代 | 内存计算 |
| 执行速度 | 较慢 | 更快 |
| 开发方式 | 主要 SQL | SQL + 代码混合 |
| 元数据管理 | Hive Metastore | 可复用 Hive Metastore |
| 底层存储 | HDFS | HDFS / LocalFS / ... |
DataFrame
DataFrame 是什么
DataFrame是一种以二维表结构组织的、分布式的、弹性的数据集。
-
对比:
Pandas DataFrame: 单机二维表。
Spark RDD: 分布式集合,数据结构无限制。
Spark DataFrame: 分布式二维表,专为 SQL 计算优化。
-
结构层面:
StructType: 描述整个表的 Schema(列名、类型、是否为空)。
StructField: 描述单个列的信息。
-
数据层面:
Row: 表示一行数据。
Column: 表示一列数据及其信息。
创建 DataFrame
从 RDD 转换:
py
# 方式1: 只传列名,类型自动推断
df = rdd.toDF(['id', 'name', 'age'])
# 方式2: 显式定义 Schema
from pyspark.sql.types import StructType, StructField, IntegerType, StringType
schema = StructType([
StructField("id", IntegerType(), False),
StructField("name", StringType(), True)
])
df = spark.createDataFrame(rdd, schema=schema)从外部数据源读取 (统一 API):
py
# 读取 CSV
df = spark.read.csv("path/to/file.csv", sep=",", header=True)
# 读取 Parquet (推荐格式,自带 Schema)
df = spark.read.parquet("path/to/file.parquet")
# 通用格式
df = spark.read.format("json").load("path/to/file.json")DataFrame 编程风格
DSL (领域特定语言) 风格: 调用 DataFrame 的 API 方法链。
py
df.where("name = '语文'").limit(5).show()
df.groupBy("subject").avg("score").show()SQL 风格: 将 DataFrame 注册为临时视图,然后执行 SQL。
py
df.createTempView("score_table")
spark.sql("SELECT * FROM score_table WHERE name='语文' LIMIT 5").show()常用 API
- show(): 展示数据。
- printSchema(): 打印表结构。
- select(): 选择列。
- filter()/where(): 过滤行。
- groupBy(): 分组,返回 GroupedData 对象,可调用 count(), sum(), avg() 等聚合方法。
- withColumn(): 新增或修改列。
- dropDuplicates(), dropna(), fillna(): 数据清洗。
SparkSession
Spark 2.0 后引入的统一编程入口,取代了旧的 SparkContext
py
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("MyApp") \
.config("spark.sql.shuffle.partitions", "4") \
.getOrCreate()函数与高级特性
UDF (用户自定义函数)
扩展 SparkSQL 内置函数,实现自定义逻辑。
py
# 方式1: 通过 SparkSession 注册 (SQL & DSL 都可用)
def str_len(s):
return len(s) if s else 0
spark.udf.register("str_len", str_len, IntegerType())
spark.sql("SELECT str_len(name) FROM table").show()
# 方式2: 通过 functions 包注册 (仅 DSL 可用)
from pyspark.sql import functions as F
str_len_udf = F.udf(str_len, IntegerType())
df.select(str_len_udf(df['name'])).show()窗口函数 (Window Functions)
在数据的"窗口"(如分组内、排序后的前N行)上进行计算。仅在 SQL 风格中支持
python
-- 聚合窗口 (计算全表平均分)
SELECT *, AVG(score) OVER() AS avg_score FROM stu;
-- 分组聚合窗口 (计算班级平均分)
SELECT *, AVG(score) OVER(PARTITION BY class) AS avg_score FROM stu;
-- 排序窗口 (计算行号、排名)
SELECT *,
ROW_NUMBER() OVER(ORDER BY score DESC) AS row_number_rank,
RANK() OVER(ORDER BY score DESC) AS rank_score
FROM stu;