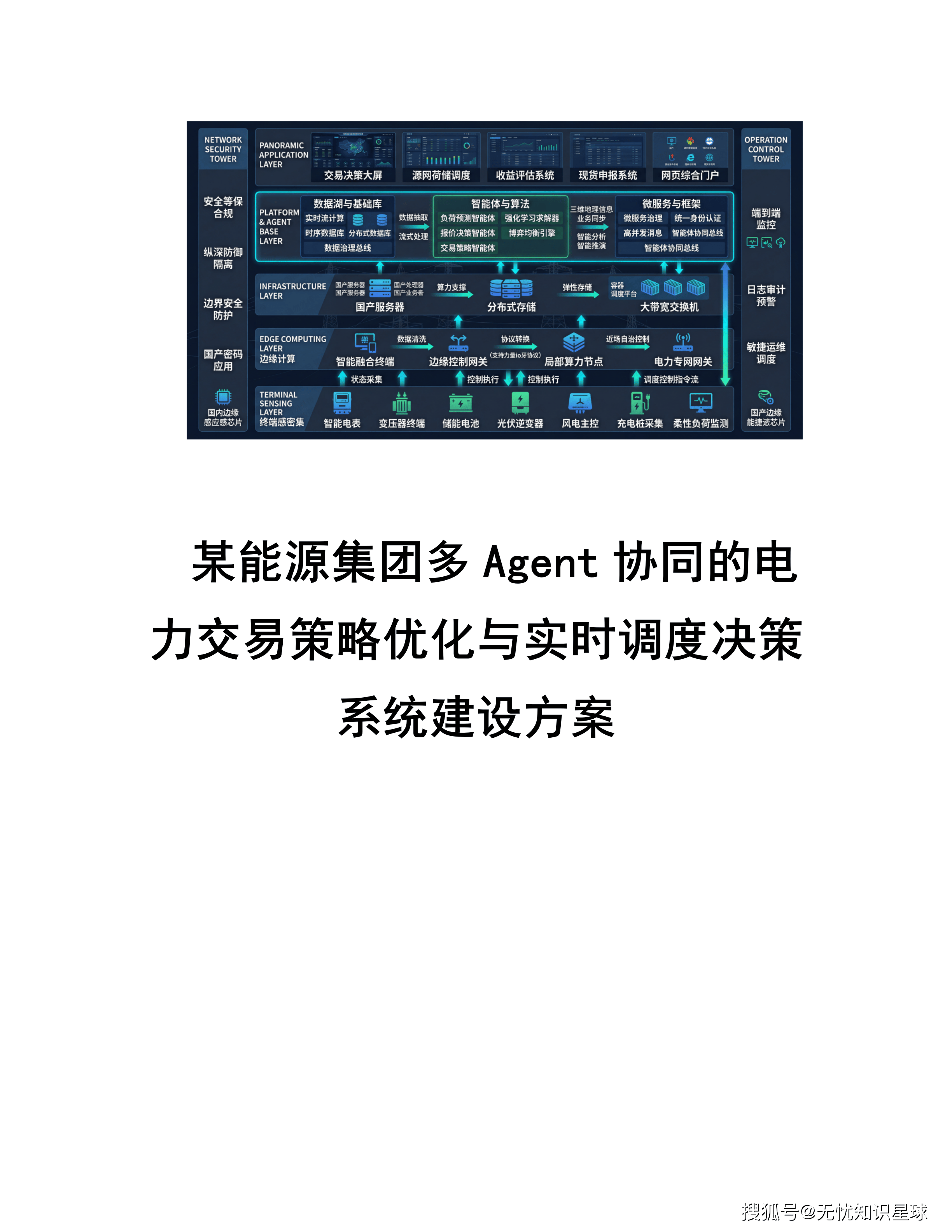
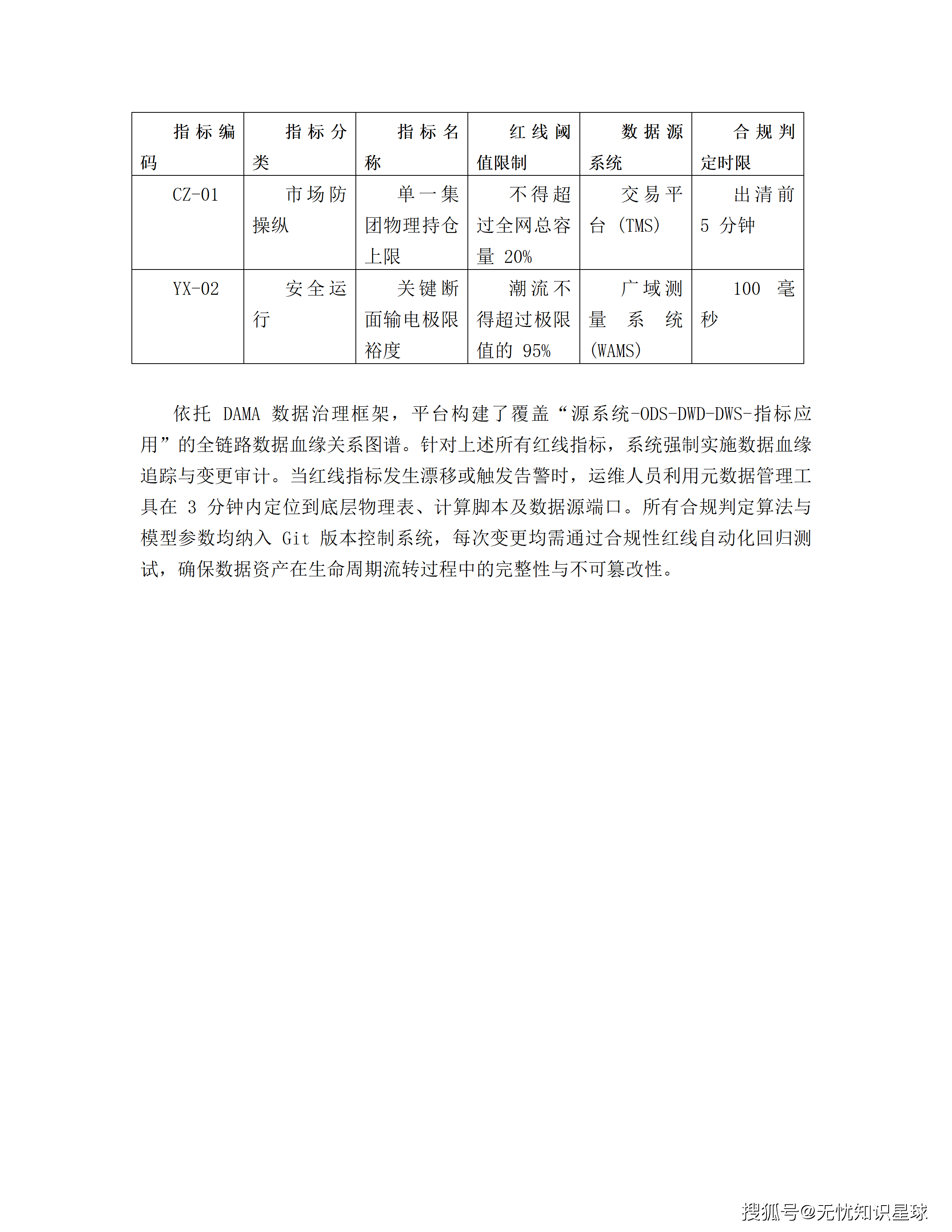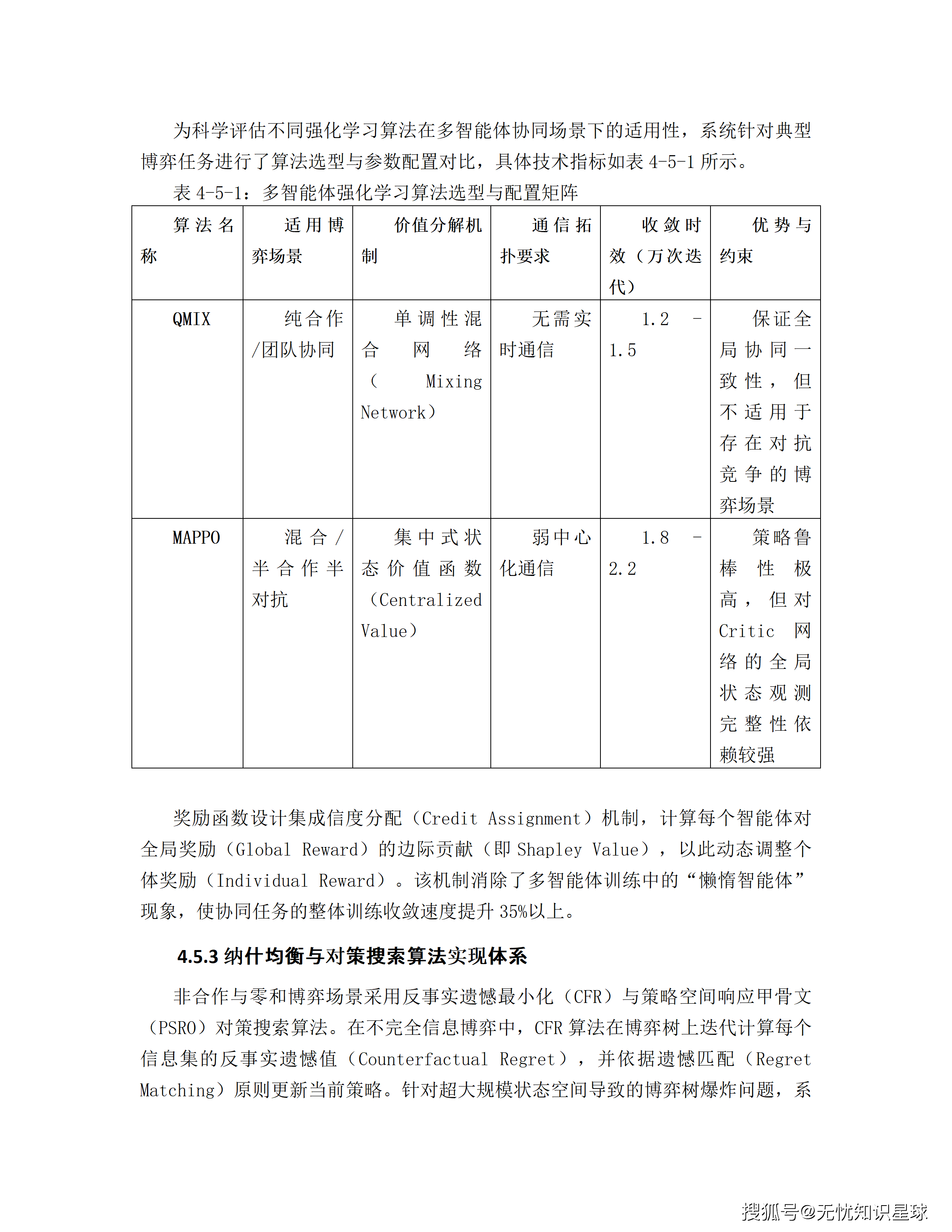导读:在电力现货市场深化改革与源网荷储协同互动的背景下,传统静态交易与调度模式难以应对市场高频波动,亟需提升决策时效性与收益空间。本项目致力于推动企业智能体落地,建设多Agent协同的电力交易与调度系统。主要内容包括部署负荷预测Agent、报价决策Agent及电力交易策略Agent,运用强化学习优化与博弈均衡求解技术,构建源网荷储协同的实时调度协同机制。项目旨在实现能源多Agent的高效运转,优化电力交易策略,提升实时调度决策效率,最大化集团综合效益。
纳什均衡在电力市场里的真实状态:它既不稳定,也不唯一
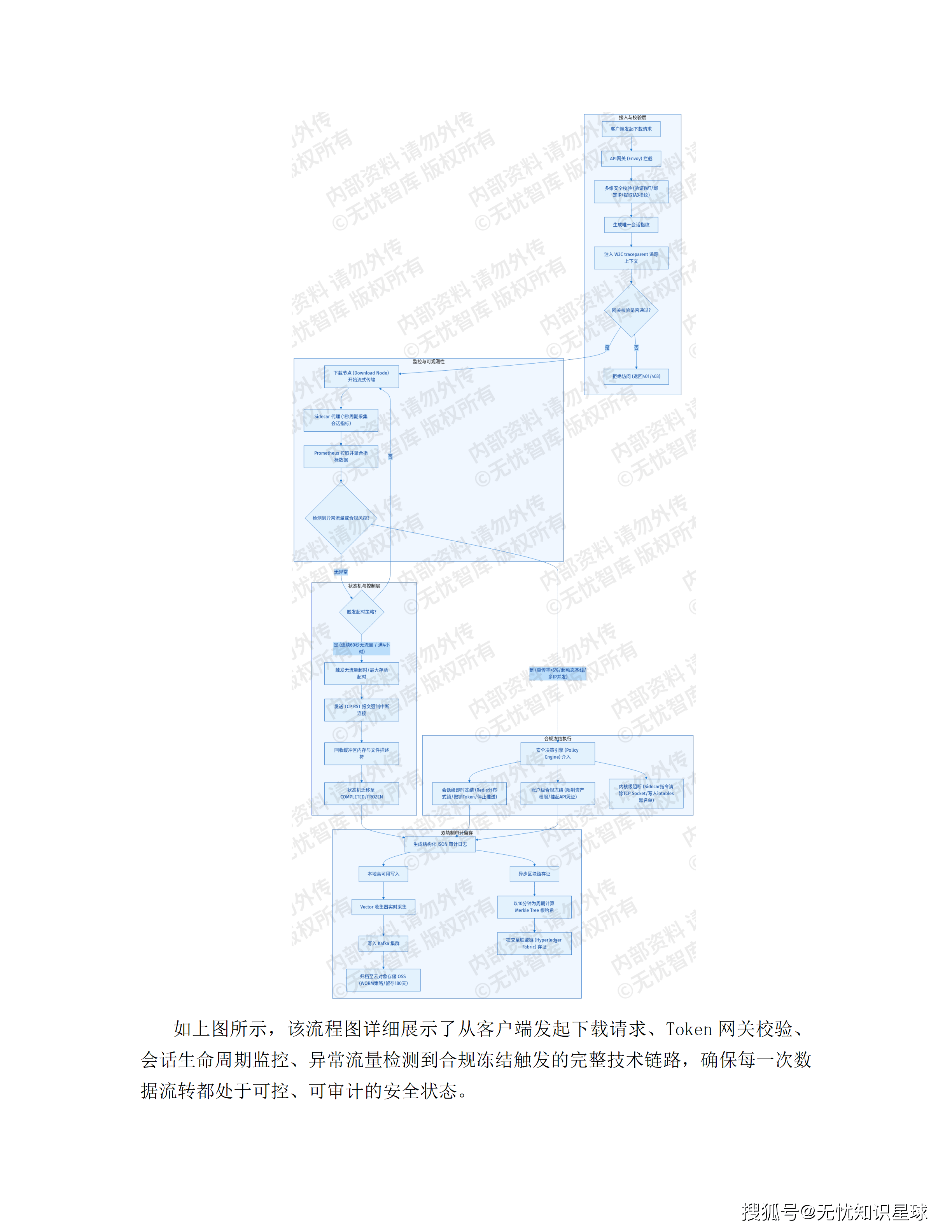
方案第4.2节花了相当篇幅描述报价决策Agent如何通过MADDPG(多智能体深度确定性策略梯度)进行博弈模拟,模拟对手报价行为,在1000次以上的蒙特卡洛树搜索中逼近纳什均衡。技术描述是准确的。
但这里有一个电力市场的结构性事实,这份方案没有提:电力现货市场的均衡,在绝大多数时候不是纳什均衡,而是一个受到监管约束、历史惯例、政治博弈共同塑造的"伪均衡"。
具体来说:在广东、山西等已经开市的现货试点市场里,市场主体的报价行为实际上受到三个约束的叠加------一是价格上下限管制(通常±价格帽),二是发改委和能监办的市场监察(报价偏离历史均值太多会被约谈),三是同一电网公司调度下的隐性协调(发电企业彼此之间知道谁有什么样的调峰义务,在某些场景下存在默契)。
在这三重约束下,所谓的"纳什均衡"更接近于一个被监管框架扭曲的局部最优解,而不是博弈论意义上的纯策略或混合策略均衡。当系统用历史出清数据训练对手行为模型时,它学到的其实是这个被扭曲的伪均衡------一旦市场规则发生变化(比如价格帽调整、新的市场主体准入、或者监管重点转移),历史数据拟合出来的对手模型就会立刻失效。
这不是算法设计的问题,而是电力现货市场本身的结构性特征:它是一个正在被设计中的市场,规则本身还在变化,没有稳定的均衡可以被学习。
国内某头部电力交易团队在2022年测试类似系统时,发现了一个令人尴尬的现象:系统在广东现货市场的历史数据上表现极好,均衡求解的收益比人工操作高出约3%;但当市场监管部门在2023年调整了偏差考核的计算规则后,系统延续历史策略的三个月里,连续触发新规则下的偏差考核,产生了明显的多余罚款。系统"学会"了旧规则,但没有能力识别规则已经改变。
方案里有一条非常合理的设计:当预测误差连续3个预测周期超过5%时,自动触发背景训练微调。但这个机制处理的是模型对市场数据分布漂移的自适应,不能处理规则本身的跳跃性变化------规则变化通常在某一天突然生效,没有渐进的数据信号可以被提前捕捉。能处理数据漂移但不能处理规则跳变的系统,在中国电力市场里是一个重大的脆弱性。
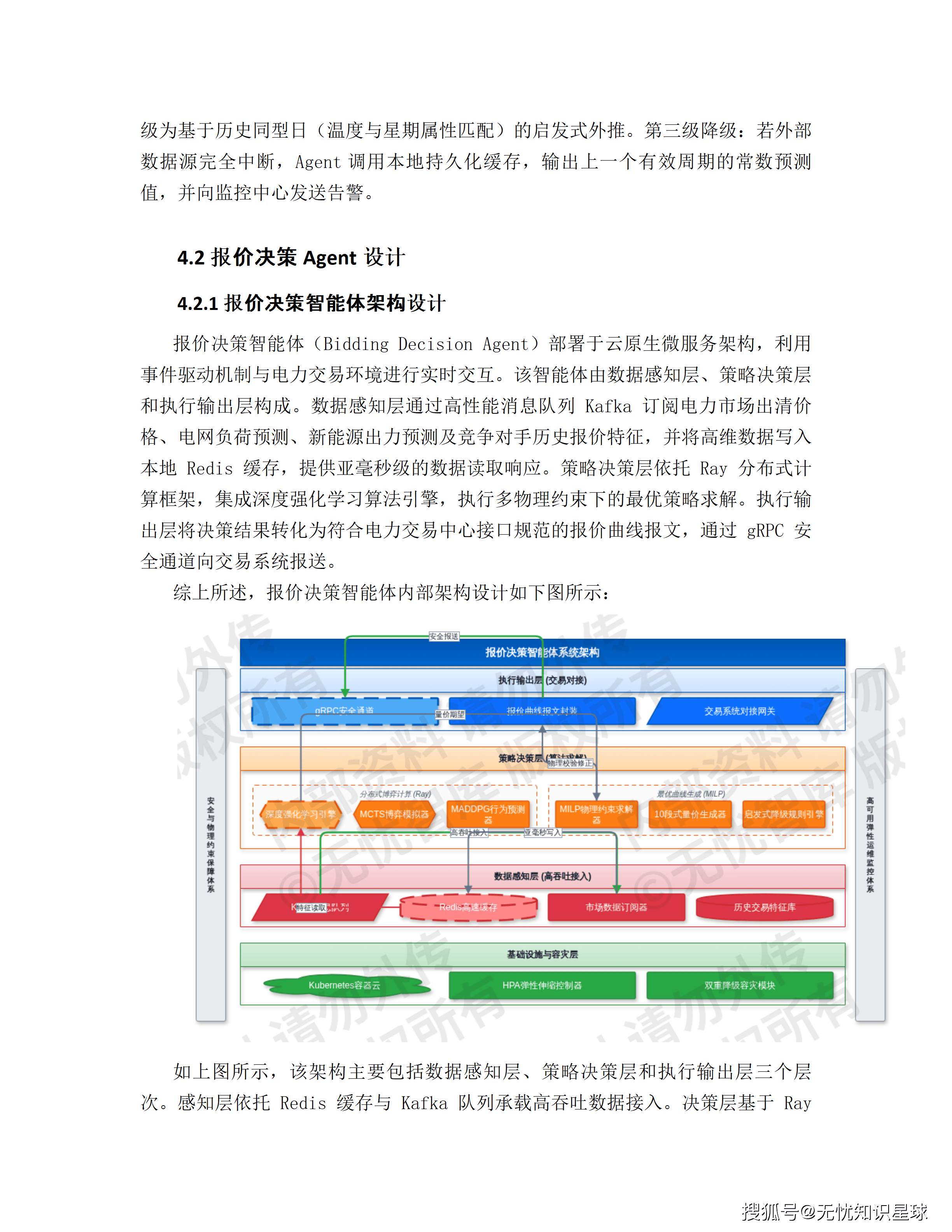
BDA报价决策Agent的降级策略:把最危险的情况处理得最随意
方案第4.2.3节描述了报价决策系统的两种降级策略:当算法推理时延超过500ms时,自动切换至"轻量级启发式规则算法";当物理约束校验失败时,调用MILP求解器进行二次修正。
这两条降级策略在常规故障场景下是合理的。但方案里有一处我认为设计明显不足的地方:当报价决策Agent在日前申报截止时间前30分钟仍未生成报价曲线时,TSA会自动锁定"昨日申报的基准报价单"作为保底申报。
这个设计乍看合理,但它隐含了一个危险假设:昨日的报价曲线今天还可以用。
在多数情况下,这个假设成立。但有几类市场场景下,沿用昨日报价会产生严重偏差:
场景一:前一天发生了重大天气事件(台风、寒潮),今日气象条件完全不同,负荷曲线与发电出力均发生大幅变化。 沿用昨日报价,可能导致日前申报电量与次日实际出力产生巨大偏差,触发高额偏差考核。
场景二:前一天系统本身因为数据问题或算法异常,生成了一份质量有问题的报价单,但通过了申报------那份报价单可能本身就是一个需要被纠正的错误,而降级策略会将这个错误延续到第二天。
场景三:市场在前一天收盘后发布了新的输电约束通知或临时检修计划,改变了今日的断面输电限额。 昨日的报价曲线不知道今天的网络约束,可能申报了在物理上无法实现的出力计划。
这三类场景在实际运营中都不罕见,但方案里把"沿用昨日报价"描述为一个"将漏报率控制为0%"的安全措施------漏报率确实是0,但错报的风险没有被提及。
把"不漏报"和"不出错"混为一谈,是交易策略系统设计里一个经典的概念偷换。 漏报的代价是被系统默认按零电价出清,损失是确定的;错报的代价是产生出力偏差,损失是浮动的,但在极端情况下可能超过漏报损失。方案里没有对这两种风险的量级进行过比较分析,直接把漏报率归零作为设计目标,这个选择值得质疑。
强化学习奖励函数的设计:文档里用了一个太容易出问题的简化
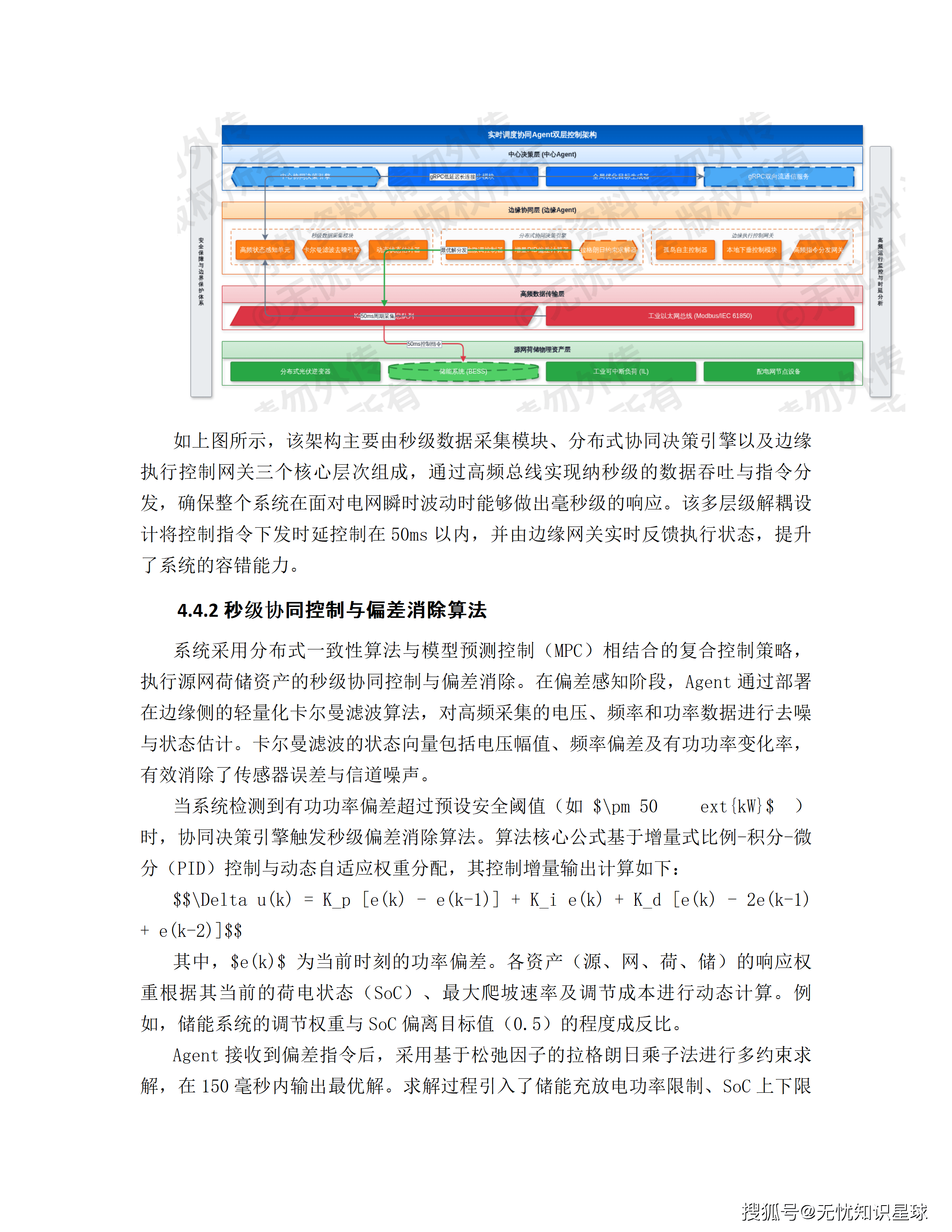
方案第4.4节的实时调度协同Agent,用了一个增量式PID控制与动态权重分配的混合策略,奖励函数描述为"由偏差惩罚与实时收益加权构成"。第4.3节的交易策略Agent里,日内滚动阶段用PPO算法,奖励函数同样是"偏差惩罚与实时收益加权"。
这个奖励函数设计在概念上是合理的,但它隐藏了一个工程实践中几乎必然出现的问题:偏差惩罚和实时收益之间的权重如何设定,没有任何说明。
这不是一个可以忽略的细节。奖励函数的权重设计,直接决定了Agent在"规避偏差考核风险"和"追求现货收益最大化"之间如何取舍。如果偏差惩罚权重设得太低,Agent会激进报价、追求高收益,但偏差考核费用可能侵蚀大部分增量收益;如果偏差惩罚权重设得太高,Agent会保守报价、大量留出裕量,名义上减少了偏差考核,但同时也放弃了大量可以赚取的现货价差收益。
在现实部署中,这个权重通常不是被"设计出来"的,而是被"调出来"的------在仿真环境里跑出结果,让交易主任看一眼觉得"这个收益还行,偏差也不多",然后拍板用这组参数上线。这个过程本身是有效的,但它意味着奖励函数的权重在本质上是一个反映管理层风险偏好的参数,而不是一个可以被工程化推导的最优值。
当管理层的风险偏好发生变化(比如集团今年目标是降低成本,明年目标变成扩大市场份额),奖励函数的权重需要跟着调整,但方案里没有提供任何关于"如何根据业务目标动态调整奖励函数权重"的机制设计。 这意味着系统上线后,每次业务目标调整都需要重新跑实验、重新训练模型------这不是不能做,但如果没有提前设计这个调整机制,它就会成为一个让运维团队头疼、让业务团队等待的摩擦点。
对比一下更成熟的做法:Jane Street、Citadel这类顶级量化机构在构建交易策略时,会把风险偏好参数(Risk Aversion Parameter)作为模型的一个可配置输入,允许运营团队在不重训模型的情况下在线调整系统的风险取舍倾向。这个设计让系统更容易适应业务目标的变化,也让非技术的业务决策者有了一个可以理解和操作的旋钮,而不是面对一个黑箱。
这份方案里没有这样的设计,虽然在技术上实现它并不复杂。
MADDPG在电力市场里的一个真实工程问题:对手模型的数据从哪里来
方案的报价决策Agent用MADDPG算法模拟博弈,"通过对历史交易数据的离线训练与在线增量学习,拟合出竞争对手的报价行为概率分布模型"。
这里有一个电力市场的特殊情况,方案里完全没有提及:在中国现货市场,竞争对手的实时报价数据,在申报窗口关闭前是保密的。 交易中心只公布出清结果(出清电量和出清价格),不公布每个参与者的具体申报曲线。
这意味着"拟合竞争对手的报价行为概率分布",能用的数据是:出清结果(只有聚合价格)、历史申报数据(有时延,且通常只是部分披露)、竞争对手的公开信息(装机规模、历史偏差统计)。
这些数据远不足以让MADDPG精确拟合对手的报价策略。实际上,在信息不完全的博弈环境下,MADDPG的对手模型学到的更可能是一个"市场整体统计规律"的近似,而不是针对特定竞争对手的精准预测。
这不是说MADDPG在这个场景下没有价值------它依然可以帮助系统形成合理的报价策略。但方案里把"模拟对手行为"的精度描述得过于具体("拟合出竞争对手的报价行为概率分布模型"),这个表述暗示了一个比实际可以实现的更高的精度水平。
在不完全信息博弈里,过度相信自己对对手策略的估计,往往比不做估计更危险。 一个认为自己已经准确估计了对手策略的系统,会产生过度自信的报价行为;而一个清楚知道自己对对手信息掌握有限的系统,会在策略设计里保留更多的鲁棒性裕量。
2023年山东电力现货市场有过一个典型案例:某发电集团的量化交易系统因为对竞争对手的行为模型过于自信,在一个周末的低负荷时段按照"预测对手会报高价"的逻辑也报了高价,结果多家对手同时报了低价,这家集团的机组在低负荷时段大量被压低出力,损失了本可以获得的辅助服务收益。
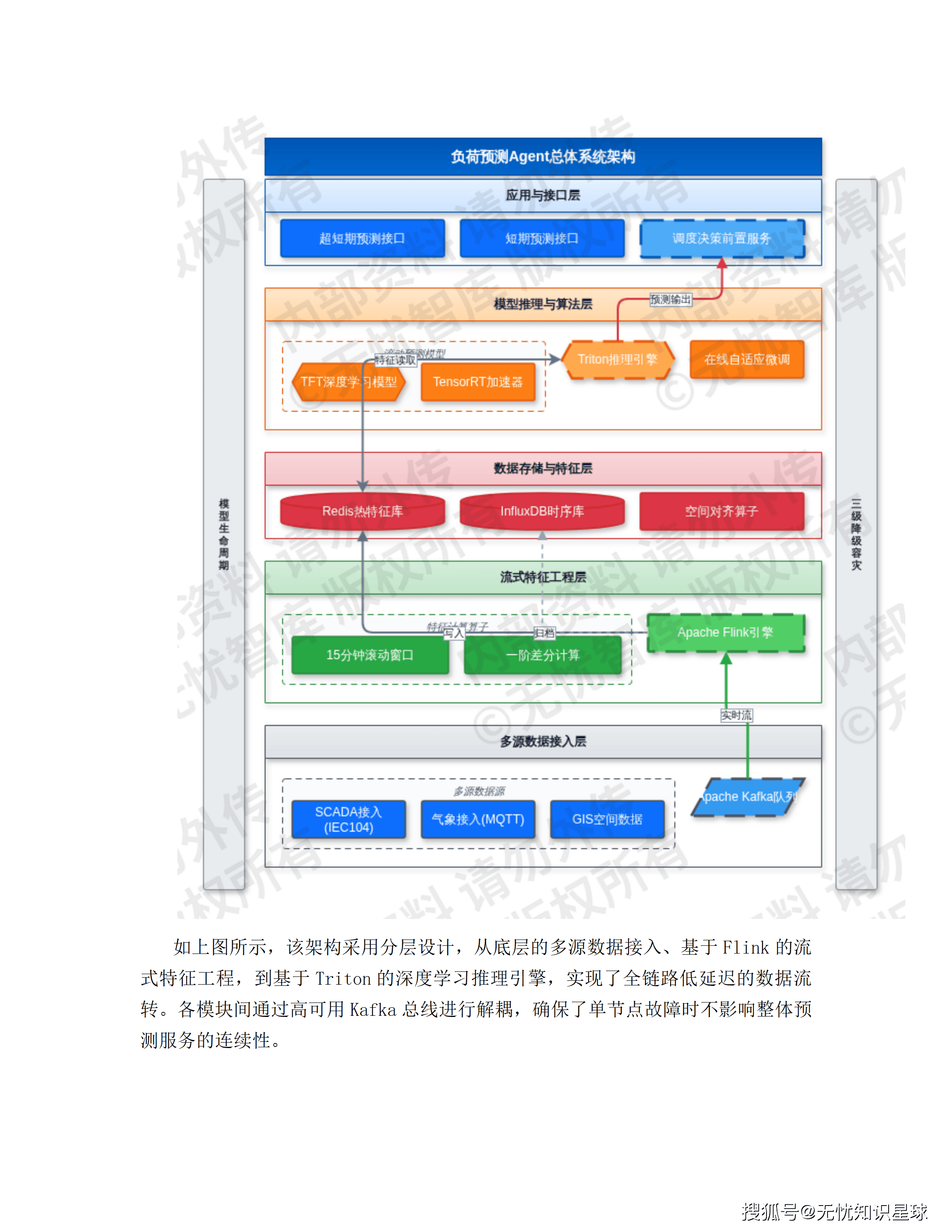
LFA负荷预测Agent的三级降级:设计是对的,但降级触发条件太粗
方案第4.1.2节的负荷预测Agent设计了三级降级:GPU故障降级到XGBoost、特征缺失降级到历史同型日外推、数据源完全中断时输出上一周期常数预测值。
这个三级降级的设计思路是正确的------在复杂系统里,优雅降级比强依赖可用性更重要,这是工程实践里的基本原则。
但降级的触发条件设计有一个我认为需要被认真讨论的问题:系统如何知道当前预测质量已经下降到需要降级的程度?
方案里的触发条件是基于系统状态的:GPU故障、Flink延迟超过1分钟、外部数据源中断。这些都是基础设施层面的可观测事件,容易被监控到。
但还有一类更难检测的质量下降:数据在物理上是通的,但数据本身的质量出了问题------气象API返回了一份在格式上合法、但气象预报数值有明显错误的数据;SCADA系统因为传感器故障返回了一批在正常范围内但完全不可信的功率读数;电动汽车充电桩数据因为采集系统bug出现了系统性偏移。
这类"数据通了但不可信"的场景,在工业系统里的发生频率,比"系统直接挂掉"高得多。检测它们需要的不是基础设施监控,而是数据质量监控------对输入数据的统计分布、异常比例、历史一致性进行持续检验。
在我接触过的几个能源集团数据中台项目里,数据质量监控的缺失是第一个在运营阶段被发现的问题。接入了几十个数据源,建了漂亮的数据血缘图,但没有一个持续运行的数据质量规则引擎来判断"现在接进来的数据是不是可以被用于决策"。
这份方案在技术架构上对数据接入做了很好的设计(Kafka分区、Flink流处理、InfluxDB持久化),但对数据质量治理这一层几乎没有提及。LFA的三级降级触发条件里,没有任何一条是"当输入数据质量指标下降到X阈值以下时"。
知识产权区块链存证:对一个工具在错误场景里的正确使用
方案第2.4节花了大量篇幅设计交易策略和预测模型的知识产权保护体系:SM4加密存储、SM3哈希确权、联盟链存证、可信执行环境(TEE)分发、DoD 5220.22-M安全销毁。这些技术选型每一个单独来看都是合理的。
但我想提一个在方案里完全没有被讨论的问题:在一个能源集团内部,谁是这个知识产权保护体系的对手方?
知识产权保护有意义,是因为存在泄露或盗用的风险。在这份方案的场景里,策略模型是集团内部研发的,部署在集团内部的信创服务器上,使用方也是集团内部的交易团队------整个生命周期都在同一个法律主体内。
在同一法律主体内部建设一套对抗级别的知识产权保护体系,实际上是在防自己人。 这不是没有道理的,确实存在内部人员离职后带走模型参数的风险。但如果这是主要风险,更直接的解决方案是人事管理规定和保密协议,而不是可信执行环境和联盟链存证。
这套保护体系真正有价值的场景是:集团把这个模型作为知识产权资产对外授权、或者参与第三方投资、或者在诉讼中需要证明技术所有权。在这些场景里,链上存证才有真正的法律意义。
但方案里没有说这个模型会被对外授权------它被描述为集团内部的运营工具。用对外授权级别的保护体系来保护内部工具,这个设计决策的成本和收益比,方案里没有被讨论。
把区块链存证写进方案,一方面是真实的安全需求,另一方面也有一个不需要明说的功能:在可研报告里增加技术亮点,让评审委员看到"融合区块链技术"这样的表述,有助于项目通过立项评审。这不是批评,这是项目申报材料的运作逻辑,几乎是行业惯例。但作为评估者,需要把这两层动机区分开来。
信创适配的真实代价:这份方案对兼容性问题的处理过于乐观
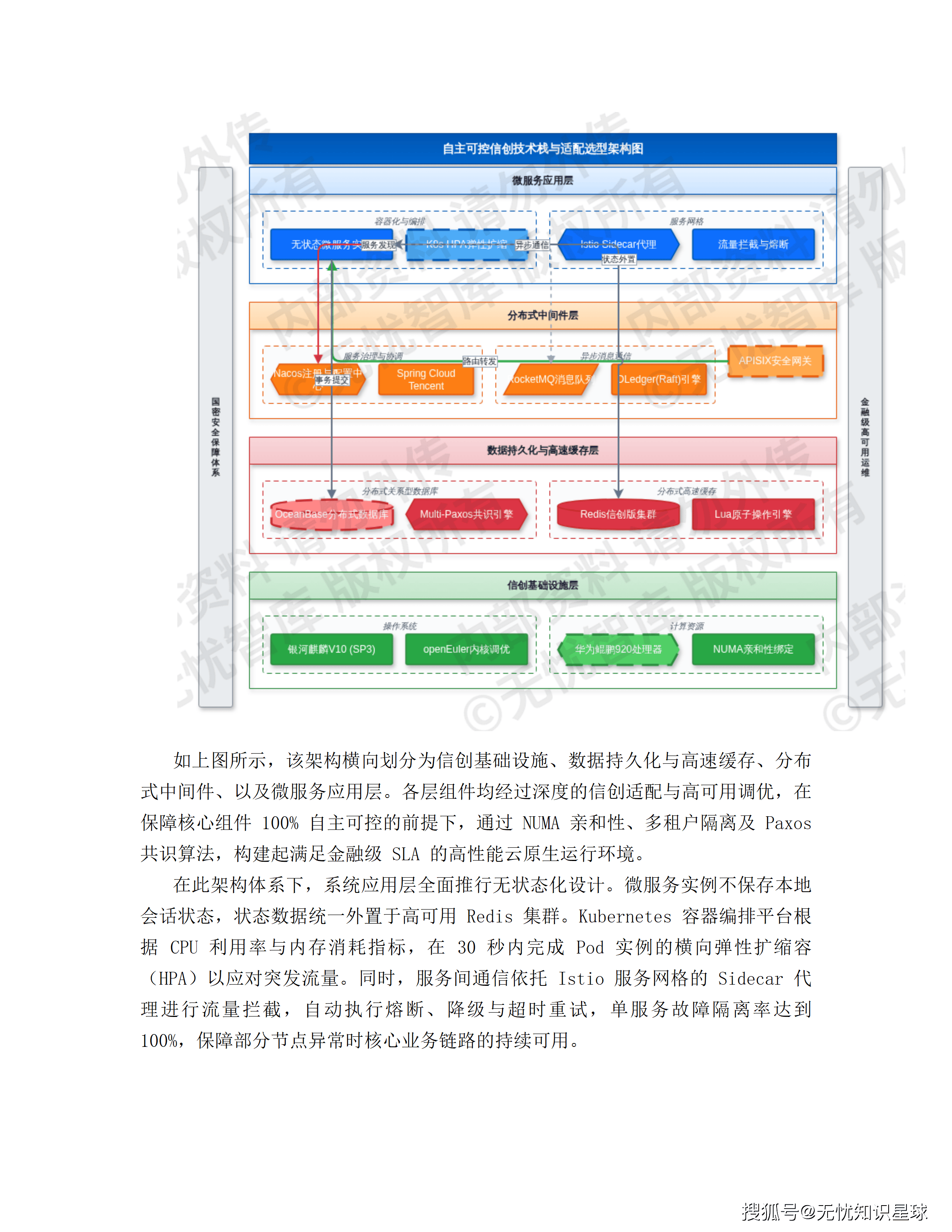
方案第3.2节描述了信创适配选型:华为鲲鹏920处理器、银河麒麟V10操作系统、OceanBase数据库、信创版Redis、RocketMQ消息队列。这套组合在国产化适配方向上是当前的主流选择。
但方案里有一个在实际项目中会产生大量摩擦的问题被轻描淡写了:多Agent强化学习和博弈均衡求解这些算法,依赖的Python生态(PyTorch、Ray、TensorRT、Triton Inference Server)和信创硬件之间的兼容性,到2025年依然存在大量边缘问题。
具体来说:TensorRT是NVIDIA针对CUDA架构的推理优化框架,它在鲲鹏ARM64架构上的支持是有限的------华为有自己的推理加速框架(MindSpore/TensorRT-like tools for Ascend),但它不是TensorRT,接口不兼容,性能特性也不同。方案里第4.1.2节提到"利用TensorRT进行FP16量化编译,单次预测推理延迟由120ms降至8ms"------这个数据在NVIDIA GPU上是可信的,但如果推理硬件换成了鲲鹏+昇腾NPU,这个优化路径需要被完全重写。
Ray分布式计算框架在ARM64平台上的支持,在2024年前也存在明显的稳定性问题,社区版本的多个核心功能在鲲鹏上需要额外的适配工作。方案第4.5.4节描述了基于Ray的分布式博弈训练框架,在正式采购信创服务器之前,如果没有做过专项的Ray on Kirin/Kunpeng适配验证,这个设计在上线前可能需要额外2-4个月的平台适配工作。
我见过的信创适配项目里,最常见的延期原因不是核心业务逻辑没写完,而是第三方依赖库在信创平台上跑不起来、跑起来性能不达标、或者版本锁定导致无法升级。 这些问题在方案设计阶段几乎无法被完整预估,因为信创生态的成熟度在不同组件之间差异极大。
方案里提到"建设周期12个月",如果严格执行全信创架构,又要使用Ray+TensorRT+PyTorch这套AI技术栈,12个月完成所有功能并达到性能验收标准,是一个技术上非常激进的估计。做过类似项目的团队都知道,仅信创适配这一项就可以吃掉2-3个月。
这套系统真正的战场:不是算法,是人机协同的边界设计
读完这整份方案,我认为它最重要的遗漏,是对"人在回路"(Human-in-the-Loop)设计的缺位。
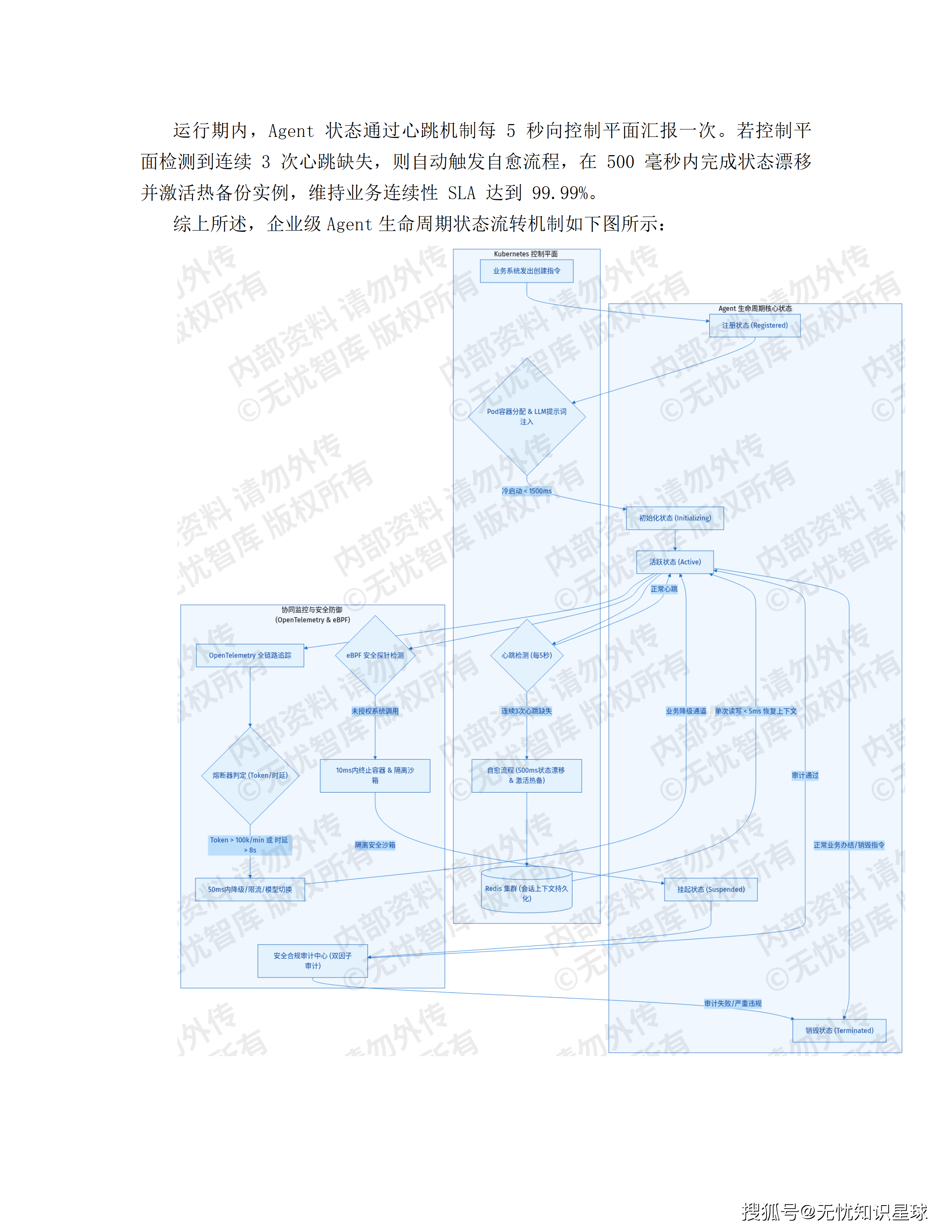
方案描述了四个Agent------LFA、BDA、TSA、RDA------以及它们之间如何通过Kafka消息总线进行事件驱动的协同,如何在故障时触发降级,如何保证SLA达到99.99%。这些技术设计是扎实的。
但系统在正常运行时,交易员看到的界面是什么?交易员在什么情况下可以覆盖Agent的决策?覆盖操作会不会影响Agent的训练数据?如果Agent在某次决策后被人工覆盖了,下次遇到类似情况,系统应该如何处理------继续按Agent的逻辑走,还是学习那次覆盖操作?
这些问题在方案里完全空缺。
这不是边缘问题,这是整个系统能不能在生产环境里存活的核心问题。 根据我在多个能源集团的咨询经验,自动化交易系统上线后的第一年里,人工干预的频率远比设计预期高------不是因为系统不好,而是因为决策者对系统的信任建立需要时间,而建立信任的过程需要足够多次"看着系统做决策,发现结果不错,逐渐放手"的正向循环。
如果系统的每一次人工干预都破坏了Agent的训练数据分布,那这个正向循环就不存在------系统越被干预,数据质量越差,系统越不可信,被干预越频繁。这就是本文开篇提到的那个失信螺旋。
解决这个问题的工程路径是明确的:把人工干预的操作记录下来,作为有标签的监督信号(而不是丢弃它),让系统能够区分"Agent的自主决策"和"人工覆盖后的修正决策",并从两类决策中学习不同的东西。同时,设计一套透明的解释机制,让交易员能够看到Agent为什么做出这个决策、这个决策在历史类似情况下的表现如何------这样的透明度,是让交易员愿意信任系统、减少干预频率的前提。
这些设计都不在方案里。方案里有精细的算法架构,有详尽的性能指标,但没有回答"在系统和业务团队之间,信任是如何建立的"这个问题。而这个问题,才是能源集团AI系统成功落地的第一关。
最后一件值得说的事:这份方案是写给谁看的
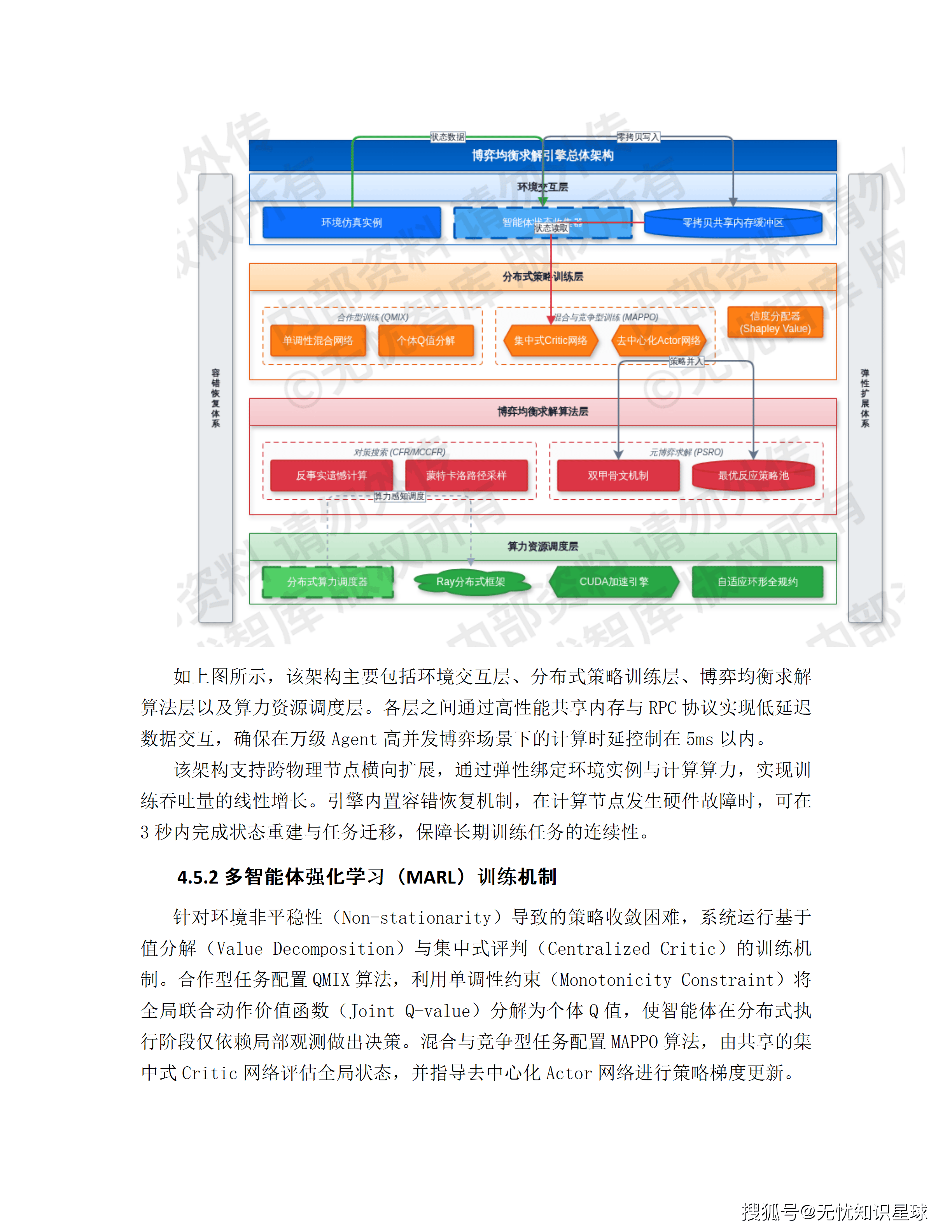
这份方案的技术深度是真实的------MADDPG、QMIX、MAPPO、CFR、PSRO、Shapley Value信度分配、TFT深度学习网络,每个技术选型背后都有工程逻辑,不是凑词汇。写这份方案的技术团队,对电力市场和多Agent强化学习都有认真的理解。
但这份方案是写给立项评审的。它的信息结构是为了通过评审而优化的:大量的技术细节建立专业性;完整的指标体系(TPS/QPS/SLA/RPO/RTO)建立可信度;收益预测(降低购电成本10%、减少二氧化碳排放15.3万吨)建立立项必要性。
一份写给立项评审看的方案,和一份写给工程团队作为实施依据的方案,在内容侧重上有结构性差异。 前者需要让非技术的评委看到技术可行;后者需要让工程师知道遇到问题时该怎么办。这份方案的整体风格是前者,但它需要后者的功能------因为系统最终是要被建出来、用起来的。
它遗漏的那些东西------奖励函数权重调整机制、人工干预数据处理策略、数据质量监控规则引擎、信创适配的真实工作量、降级策略对错报风险的量化比较------这些不是技术问题,而是工程落地问题。
技术问题在评审会议室里解决;工程落地问题在项目执行的第6个月、在系统第一次被人工干预的那个下午、在信创服务器送到机房发现Ray无法稳定运行的那个工单里解决。
这两种问题都是真实的,但只有一种被写进了这份方案。