前言
在上一篇文章中,我们主要介绍了 C++11 在语法层面的改进,这些特性提升了代码的表达能力与可读性。然而,C++11 更重要的变化并不止于此,它还从根本上改善了对象的传递方式与资源管理效率
在传统 C++ 中,对象在传递与返回过程中通常依赖拷贝操作,而这在涉及动态资源时往往带来较大的性能开销。为了解决这一问题,C++11 引入了右值引用与移动语义,使得资源可以在对象之间进行转移,从而避免不必要的拷贝。
本文将围绕这一核心展开,系统介绍左值与右值、右值引用、移动语义以及完美转发等关键内容
一. 左值与右值
在C++98标准中就已引入引用语法,而C++11新增了右值引用特性。自C++11起,原先的引用被明确称为左值引用。无论是左值引用还是右值引用,本质上都是为对象创建别名
1. 基本概念
在 C++ 中,判断一个表达式是左值还是右值,最简单、最直观的方法就是:判断是否有明确的内存地址
-
左值 (lvalue):指代一个持久存在的对象。它有明确的内存地址,你可以通过变量名访问它。比如变量、返回引用的函数调用、数组元素等
-
右值 (rvalue):通常是临时的、即将销毁的对象。它没有名字,你无法直接获取它的地址。比如字面量(42)、算术表达式(a + b)、返回值的函数调用(非引用返回)
左值是容器,右值是内容。左值可以在赋值号左边,也可以在右边;但右值通常只能在右边
值得一提的是,左值和右值的英文缩写分别是 lvalue 和 rvalue。传统观点认为它们分别代表 left value 和 right value 的缩写。在现代 C++ 中,lvalue 被重新解释为 locator value 的缩写,特指存储在内存中、具有明确地址并可获取地址的对象;而 rvalue 则被解释为 read value,表示可以提供数据值但不支持寻址的临时对象
2. 左值引用与右值引用
引用本质上是对象的别名。但在 C++11 之后,引用被细分成了两种:
- 左值引用 (T&):传统的引用方式。它只能绑定到左值上
cpp
// 合法的左值引用
int a = 10;
int& refA = a;
// 错误,左值引用不能绑定到右值
// int& refB = 10; - 右值引用 (T&&):C++11 引入的新特性。它专门用来绑定到右值上,用于捕获那些即将销毁的对象
cpp
// 绑定到字面量
int&& refC = 10;
// 错误, 右值引用不能直接绑定到左值
// int a = 10;
// int&& refD = a;
// 合法的常量左值引用, 可以绑定到右值
const int& refE = 10;const T&(常量左值引用)是一个万能引用,它既可以绑定左值,也可以绑定右值
3. 引用延长生命周期
这是一个非常微妙且重要的特性。通常情况下,一个临时对象(右值)在表达式结束后就会被销毁。但是:
如果使用一个右值引用或常左值引用去绑定这个临时对象,它的生命周期会被延长,直到这个引用的生命周期结束
cpp
{
// 1. 常左值引用延长临时对象生命周期
const int& ref1 = 100;
// 2. 右值引用延长临时对象生命周期
int&& ref2 = 200;
} // 这里 ref1, ref2 离开作用域,右值才会被销毁移动语义的实现基础在于对象生命周期的管理------只有确保对象不会立即被销毁,才能安全地转移其资源
4. 函数参数匹配规则
当多个重载版本并存时,编译器的优先级顺序如下:
1. 实参是左值:
-
优先匹配 f(T&)
-
如果没有 f(T&),匹配 f(const T&)
2. 实参是 const 左值:
- 只能匹配 f(const T&)
3. 实参是右值:
-
优先匹配 f(T&&)(这就是移动语义的入口!)
-
如果没有 f(T&&),匹配 f(const T&)
-
如果没有 f(const T&),匹配 f(T)(传值,产生拷贝)
cpp
// 1. 左值引用版本
void f(std::string& s) { std::cout << "f(T&): 绑定到左值\n"; }
// 2. 常左值引用版本(万能接收器,但优先级较低)
void f(const std::string& s) { std::cout << "f(const T&): 绑定到 const 左值或右值\n"; }
// 3. 右值引用版本(移动语义入口)
void f(std::string&& s) { std::cout << "f(T&&): 绑定到右值\n"; }
// 注:通常不会同时提供 f(T) 和上述引用版本,因为传值会产生二义性。
// 但在只有 f(T) 时,它能接收一切,代价是拷贝。
void test() {
std::string lval = "Lvalue";
const std::string clval = "Const Lvalue";
// 情况 A:实参是左值
f(lval); // 优先匹配 f(T&)
// 情况 B:实参是 const 左值
f(clval); // 只能匹配 f(const T&)
// 情况 C:实参是右值
f(std::string("Rvalue")); // 优先匹配 f(T&&)
}右值引用变量本身是左值
请看这个例子:
cpp
void process(int&& i) {
// 在这个函数内部,i 是一个右值引用
// 但 i 本身是一个左值
}
int main() {
process(10); // 10 是右值,匹配成功
}为什么 i 是左值?
-
i 有名字,我们可以通过 &i 取到它的地址
-
当函数内部将 i 作为右值使用时,多次调用可能导致资源被移动:首次调用可能转移资源所有权,后续调用时 i 将变为无效对象。
结论 :所有的具名变量都是左值,即使它的类型是右值引用(T&&)
二. 移动语义
在 C++11 之前,当需要传递对象(例如包含 100 万个元素的 vector)时,编译器通常只有拷贝一种手段
而深拷贝的代价 通常为:分配新内存 -> 把数据一个个复制过去 -> 释放旧内存。很多时候,我们拷贝的对象是一个临时对象(比如函数返回值)。这个对象在拷贝完之后马上就被销毁了
这种 "先复制后删除" 的操作方式在处理大规模数据时效率极低。能否直接接管原始数据的内存空间,避免不必要的复制过程?
1. 移动语义的核心思想
移动语义(Move Semantics)的核心可以用一个词概括:"资源窃取"
想象你要从旧房子搬到新房子:
-
拷贝语义:照着旧家具买一套一模一样的新的,然后把旧家具烧了
-
移动语义:直接把旧房子的钥匙交给新主人,旧主人净身出户
**在代码层面,移动就是:**把原对象的指针、资源句柄直接复制给新对象。并将原对象内部的指针置空,防止原对象析构时把我们刚抢过来的资源给释放了
2. 移动构造与移动赋值
为了实现上述逻辑,C++11 为类引入了两个新的成员函数:移动构造与移动赋值
移动构造函数 (Move Constructor)
本质上是一种特殊的构造函数,它的设计目标是接管一个即将销毁的对象的资源
-
参数要求 :第一个参数必须是该类类型的右值引用(T&&)
-
额外参数 :如果还有其他参数,它们必须拥有缺省值
通过右值引用转移源对象的资源(如堆内存指针),并将源对象内置的指针置空(防止析构时释放资源)
cpp
string(string&& s)
: _str(nullptr), _size(0), _capacity(0)
{
// 直接把对方的资源转移过来
swap(s);
}移动赋值运算符 (Move Assignment)
移动赋值运算符是 operator= 的重载版本,它与拷贝赋值运算符形成重载关系。其参数要求为:第一个参数必须是该类类型的右值引用
该运算符执行以下操作:
-
释放自己当前的旧资源(防止内存泄漏)
-
接管右值对象的资源
-
将右值对象置于一个可析构的安全状态(通常是置空)
cpp
// 移动赋值运算符 (T& operator=(T&&))
MyString& operator=(MyString&& other)
{
// 防止自赋值
if (this != &other) {
// 1. 释放自己当前的旧资源
delete _str;
// 2. 接管右值对象的资源
_str = other._str;
// 3. 将右值对象置于一个可析构的安全状
other._str = nullptr;
}
return *this;
}移动构造和移动赋值并非适用于所有类,它们主要适用于需要进行深拷贝的类(如 string,vector,list)
-
拷贝语义:需要开辟新空间、逐个复制元素。如果对象很大,效率极低
-
移动语义:仅仅是重新分配指针的控制权。不会增加内存负担,仅需调整指针的指向关系
对于只包含基本类型(如 int, double)的简单类,移动和拷贝的效果是一样的。其真正价值在于处理类持有的堆内存或系统资源时,能发挥事半功倍的效果
3. std::move
std::move 的源码其实非常简单,它的本质就是:static_cast<T&&>
它唯一的任务,就是无条件地将一个左值强制转换为右值引用类型。它不搬运任何一个字节的数据,也不释放任何内存
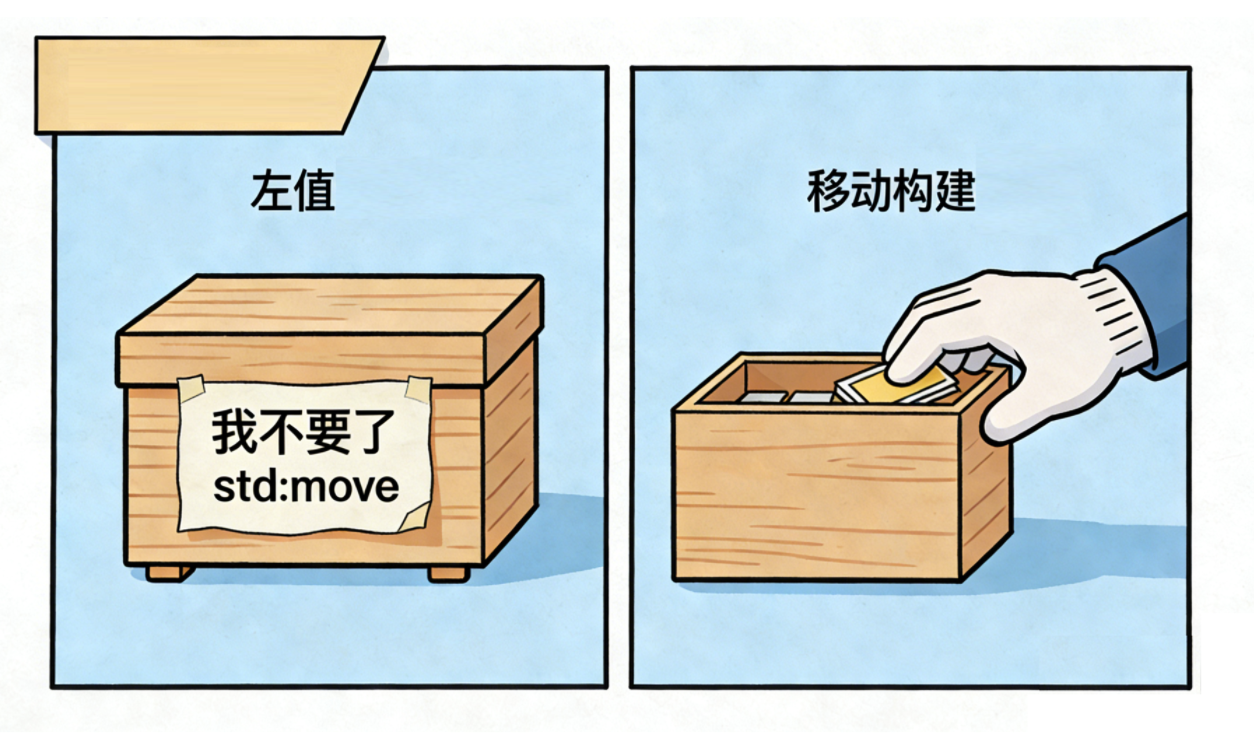
std::move 就像是一张 "弃权声明书"。 你有一个传家宝(左值变量),你给它贴上了一张纸条写着 "我不要了"。这张纸条就是 std::move。至于最后是谁来把它拿走(移动构造函数),那是别人的事,std::move 只负责贴纸条
由于 C++ 规定,所有具名变量都是左值
cpp
void func(string&& s) {
// 这里的 s 是一个右值引用,但它有名字,所以它是左值
// 如果需要把它继续传递给另一个需要右值的函数,必须再次使用 std::move(s)
string target = std::move(s);
}如果没有 std::move,我们就无法手动触发移动构造函数,编译器会因为安全考虑,默认去调用拷贝构造
从源码视角来看,我们可以这么理解 std::move
cpp
template <typename T>
typename remove_reference<T>::type&& move(T&& t) {
// 1. 无论 T 是什么引用,先去掉它的引用符号
// 2. 强转为右值引用类型 &&
return static_cast<typename remove_reference<T>::type&&>(t);
}1. remove_reference<T>::type (去引用化)
这是为了拿到最原始的类型
-
如果 T 是 int&,remove_reference<int&>::type 得到 int
-
如果 T 是 int&&,remove_reference<int&&>::type 得到 int。 目的是确保我们是在对一个纯粹的类型(如 int)进行操作,而不是在引用的基础上再加引用
2. static_cast<...&&>(t) (强制转换)
最后,给这个原始类型加上 &&。无论进来的 t 原本是什么身份,出去时统一变成右值引用
当一个变量使用 std::move 并将其传递给移动构造函数后,必须遵循一个重要原则:不要继续使用该变量的原始数据。被移动的对象将处于 "有效但未定义" 状态。此时你可以重新赋值或让它析构,但绝不能尝试读取其内容
三. 返回值与拷贝优化(RVO / NRVO)
在进入具体的编译器表现之前,我们需要明确一个基本原则:移动语义虽然快,但它依然有开销(指针赋值、置空)。如果能直接在目标位置构造对象,连移动都省了,才是极致的性能
场景 1:初始化
VS2019 debug 关闭优化
按照 C++ 标准的字面意思,当我们一个函数返回对象 (return str) 时,应该经历:
局部对象构造 -> 拷贝 / 移动给临时对象 -> 临时对象拷贝 / 移动给接收者。这种 "三连跳" 在处理大对象时会严重影响性能
我们可以在 linux 下使用 g++ test.cpp -fno-elideconstructors 来关闭优化
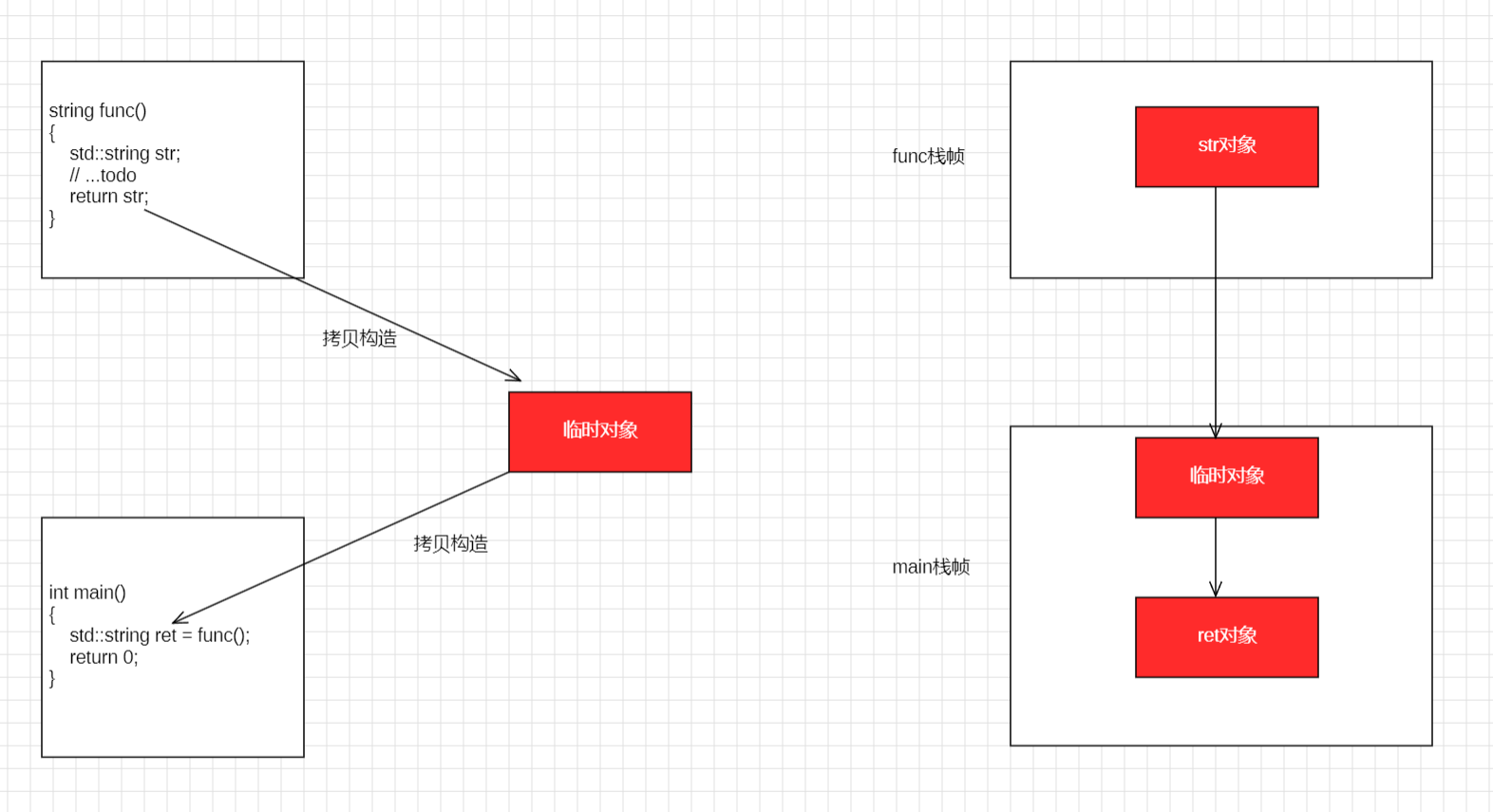
VS2019 debug 优化
在编译器优化场景下,连续的拷贝操作可合并为一次移动构造
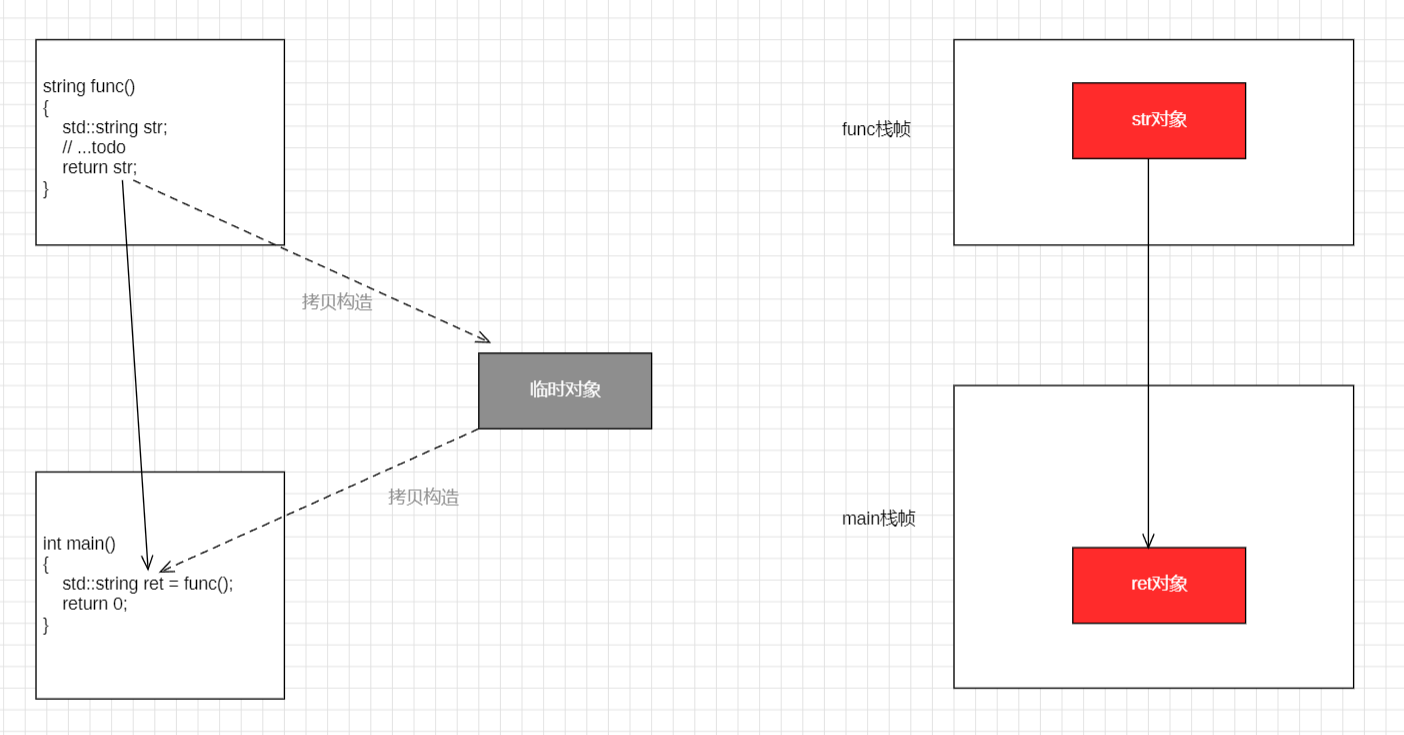
VS2019 release,VS2022 debug / release 的优化
编译器会将 局部对象 str 的构造 、str 拷贝构造临时对象 以及 临时对象拷贝构造 ret 这三个步骤合并,实现 原地构造
要深度理解这一优化,需要从栈帧的角度切入:编译器不再为函数内部的局部对象单独分配空间,而是直接在调用方(如 main 函数)预留的 ret 地址上进行初始化。这种跨越作用域的生命周期管理,彻底消除了中间过程的冗余开销
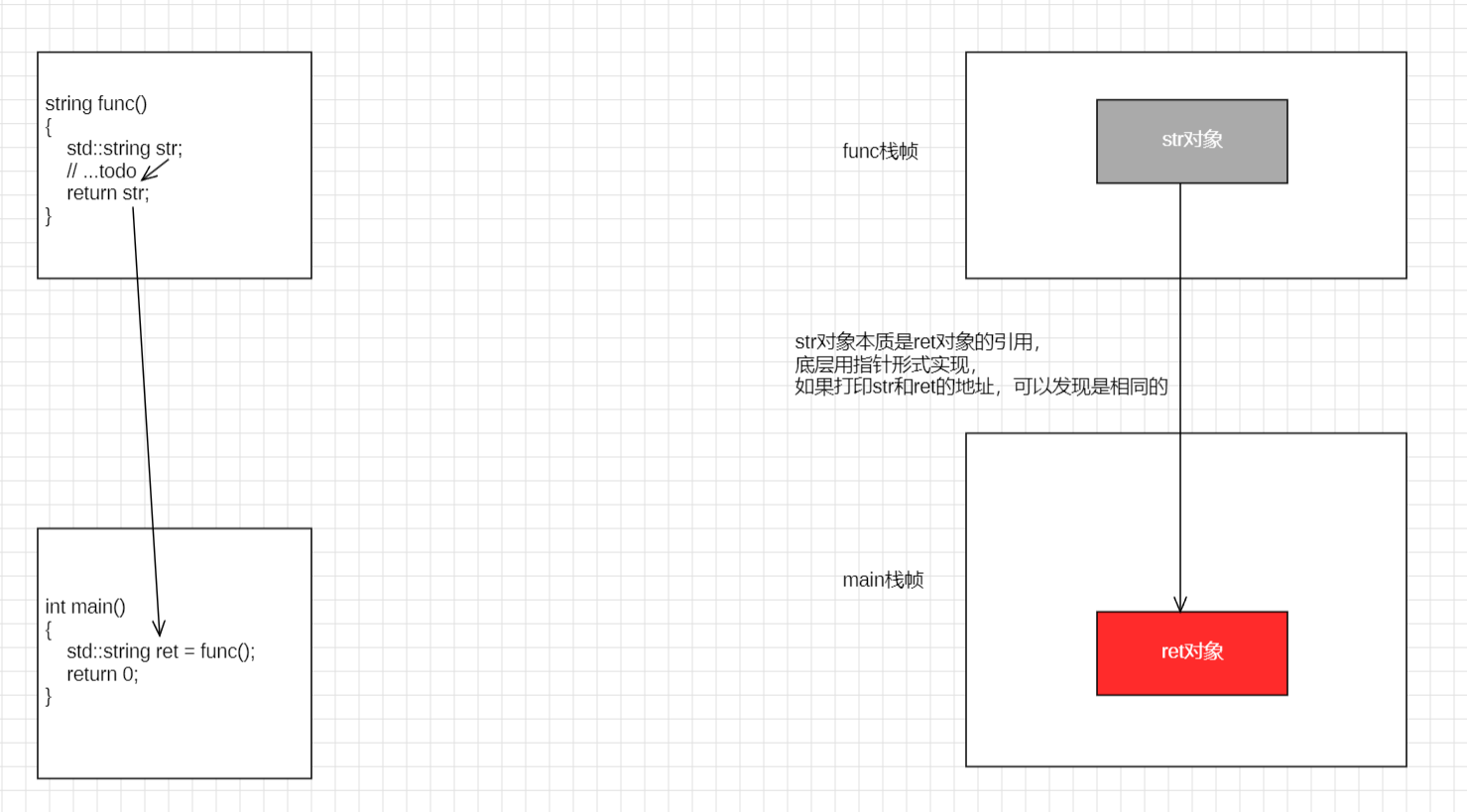
在编译器优化的干预下,局部对象 str 实际上成为了调用方 ret 对象的别名。从底层实现来看,编译器通过隐式传递指针的方式,让函数内部的操作直接作用于 main 函数预留的内存空间
验证这一点最直观的方法是打印两者的地址:你会发现 str 与 ret 的内存地址完全一致,这证明了它们在物理上指向同一块内存区域
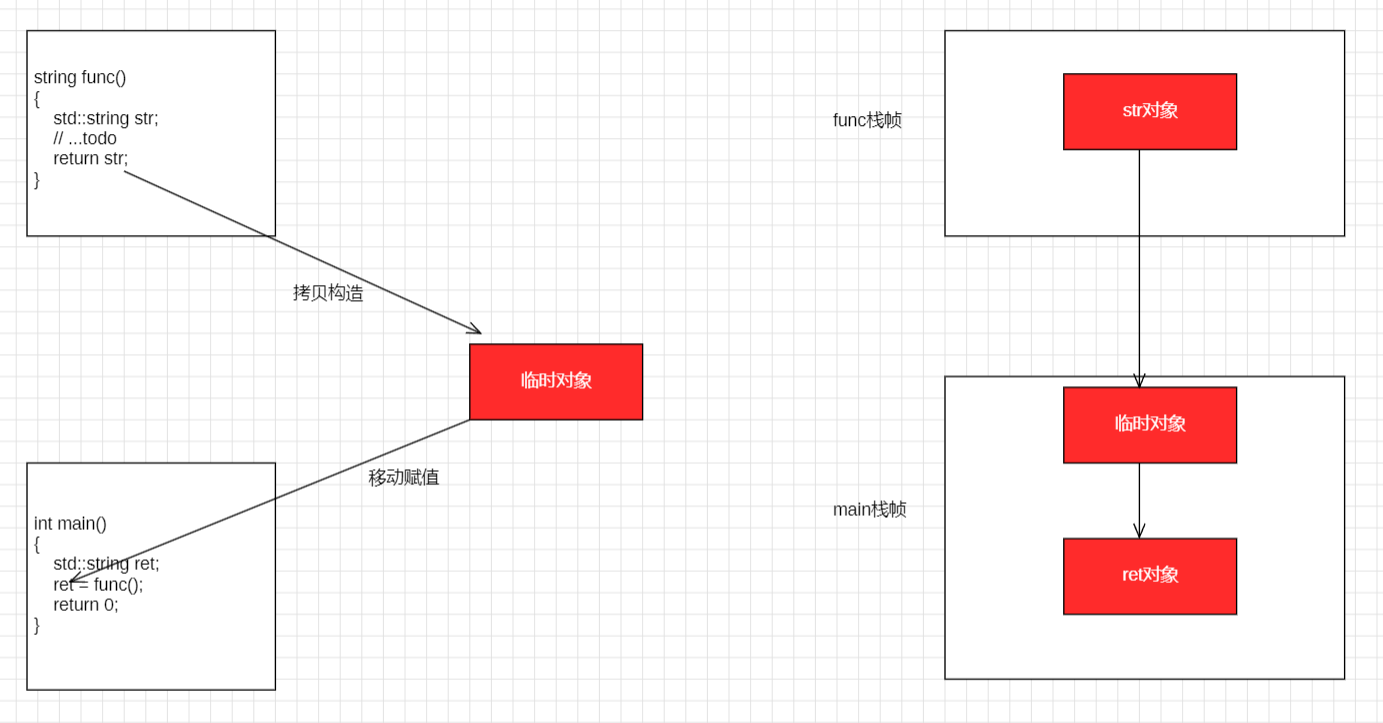
场景 2:先声明后赋值
VS2019 debug 关闭优化
由于 ret 已经存在,编译器无法直接在 ret 的地址上构造 str。它会先生成一个临时对象,然后调用 移动赋值运算符 (operator=),一次拷贝构造,一次移动赋值
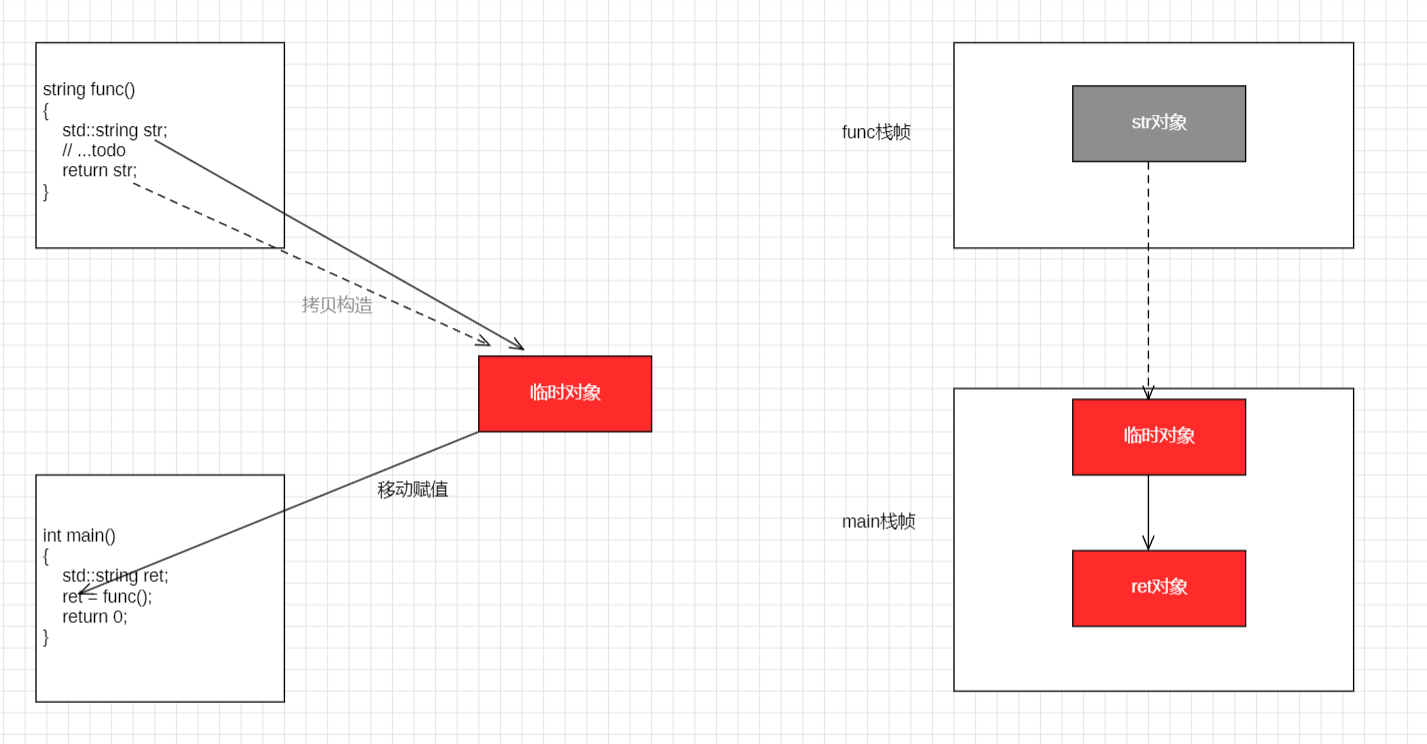
VS2019 release,VS2022 debug / release 的优化
由于接收对象 ret 已经存在,编译器无法执行 RVO。此时,编译器会执行 局部对象到临时对象的优化:它直接将函数内部的 str 视为临时对象
从底层实现看,str 此时充当了该临时对象的内存引用。通过观察运行结果可以发现:str 的析构行为发生在赋值操作之后。这有力地证明了 str 与临时对象共享同一块物理内存,并在赋值完成后才完成使命,实现了高效的资源移交
四. 右值引用在传参中的优化
如果拷贝无法被消除(例如我们需要将一个对象存入容器,或者在多个函数间传递数据),我们该如何利用右值引用来压榨性能
为了兼顾效率和安全性,现代 C++ 的标准库和高性能库通常会对写操作函数(如 push_back,insert)提供两个重载版本:
cpp
template<class T>
class list
{
// 触发拷贝构造
void push_back(const T& x) { insert(end(), x); }
// 触发移动构造
void push_back(T&& x) { insergt(end(), move(x)); }
}当你调用 push_back("hello") 时,"hello" 是右值,匹配版本 2。整个过程没有产生任何字符串的内存拷贝,只是指针的交换。这比 C++98 的 push_back(const string&) 快得多,因为即使是 const& 避免了传参时的拷贝,在 push_back 内部仍然需要执行一次深拷贝
示例演示
为便于演示,假设我们有一个标准的字符串包装类 string 并启用了打印功能,同时存在一个 std::list 类型的对象 lt
场景 1:传递左值
cpp
string s1("hello Bob");
lt.push_back(s1); s1 是一个具名变量,它是左值。编译器匹配到 const string& 版本。由于 s1 后面可能还要用,list 必须在底层节点中深拷贝一份 s1 的数据
输出示例:
cpp
string(char* str) // 构造 s1
string(const string& s) // 内部调用拷贝构造需要分配新内存 + 复制字符数据
场景 2:传递匿名对象(纯右值)
cpp
lt.push_back(string("hello Jack"));string("...") 是一个临时构造的匿名对象,由于它是右值,编译器将匹配到 string&& 版本。触发移动构造。list 的新节点直接转移走了这个临时对象的内存指针
输出示例:
cpp
string(char* str) // 构造临时对象
string(string&& s) // 内部调用移动构造
~string() // 析构临时对象代价极低。临时对象销毁时,它的指针已是 nullptr,不会误删数据
场景 3:隐式转换产生的右值
cpp
lt.push_back("hello Alice");这里传入的是 const char* 类型。为了匹配 push_back 函数,编译器会隐式构造一个 string 临时对象。而这个临时对象属于右值,将优先匹配 string&& 重载版本。与场景 2 类似,这种情况下会触发移动构造函数
输出示例:
cpp
string(char* str) // 构造临时对象
string(string&& s) // 内部调用移动构造
~string() // 析构临时对象这比 C++98 效率高得多,因为 C++98 即使产生了临时对象也只能走深拷贝
场景 4:强行转化的将亡值
cpp
lt.push_back(move(s1));s1 原本是左值,但经过 std::move(s1) 强制转换为右值后,匹配了 string&& 版本的构造函数。这会触发移动构造操作,导致 s1 的所有资源被完整转移
输出示例:
cpp
string(string&& s) // 内部调用移动构造在此之后,s1 变为空字符串。如果在后面执行打印操作,可能什么都印不出来
五. 值类别
在 C++98 中,我们只谈左值和右值。但在 C++11 中,为了更精细地描述对象的生命状态,标准引入了 glvalue 、xvalue 和 prvalue
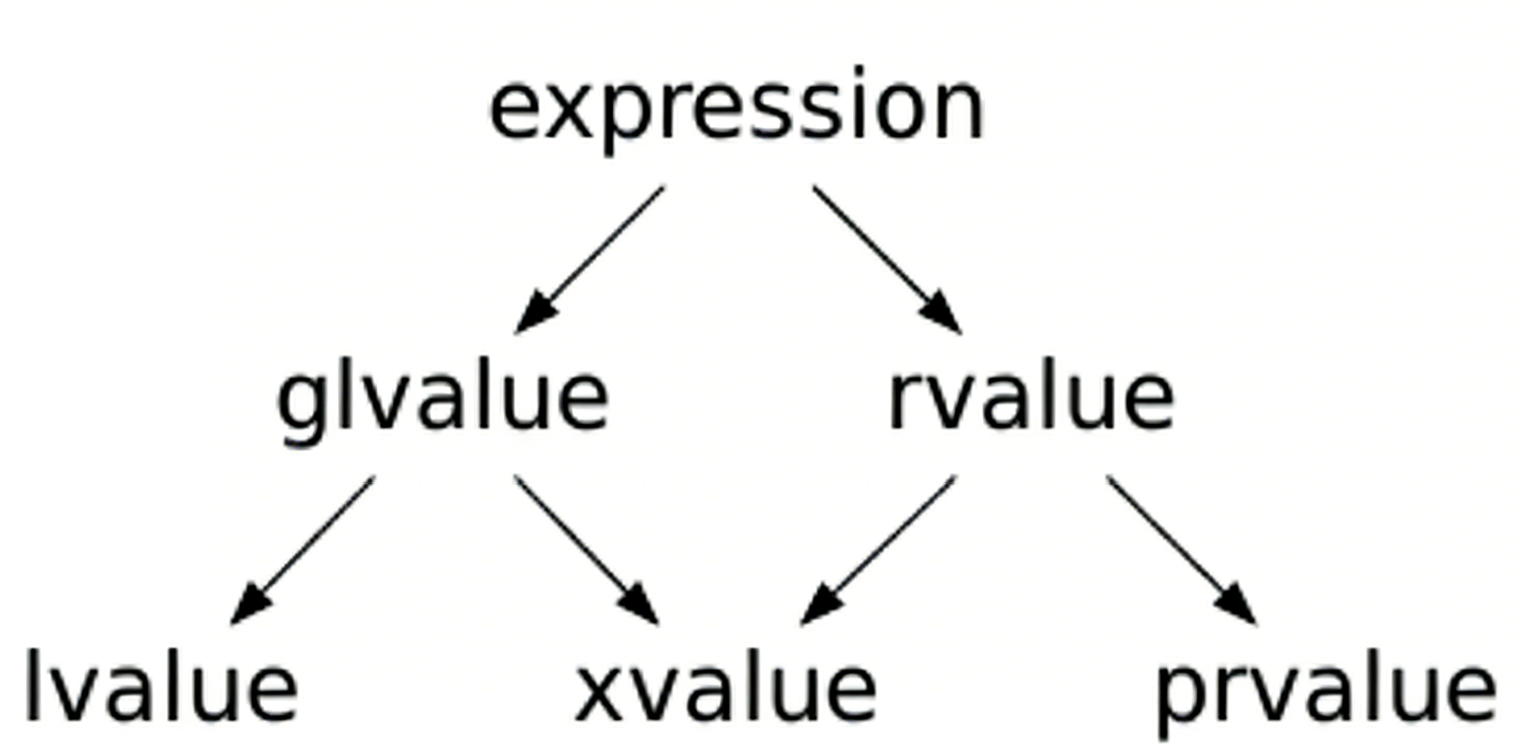
我们可以通过两个维度来定义一个表达式:
-
是否有身份:能不能通过地址、变量名找到它
-
是否可被移动:它的资源是不是可以被转移
1. 三种基本类别
1. 纯右值 (prvalue - pure rvalue)
这就是 C++98 中最传统的右值。它没有身份,通常是临时产生的。
-
字面量:42, true, nullptr
-
非引用返回的函数调用:str.substr(1, 2), a + b
-
后缀自增:a++(注意:++a 是左值,因为返回的是变量本身;a++ 返回的是一个临时副本,所以是纯右值)
-
Lambda 表达式
2. 将亡值 (xvalue - expiring value)
这是 C++11 新引入的概念。它既有身份 (你可以找到它),又可以被移动
通常通过 std::move(x) 或 static_cast<T&&>(x) 强制转化而来。它告诉编译器:"这个对象虽然还在内存里,但它马上就要死了(或者我不再需要它了),可以随便挪用它的资源。"
3. 左值 (lvalue)
传统的左值。有身份,但不可移动(除非你强转它)
常见有:变量名、函数名,返回左值引用的函数调用。前缀自增 ++a 等
2. 两个组合概念
为了方便描述规则,标准又把它们组合了一下:
-
泛左值 (glvalue) = lvalue + xvalue
- 核心属性:拥有身份(Identity)。只要是 glvalue,你就能取到它的地址
-
右值 (rvalue) = prvalue + xvalue
- 核心属性:可被移动(Moveable)。只要是 rvalue,就能匹配 T&& 参数的函数
为什么要分的这么细
你或许会疑惑:"需要这么复杂吗?"
这非常必要。以 C++17 的强制拷贝消除(Guaranteed Copy Elision)为例:
在 C++17 中,prvalue(纯右值)不再被视为一个完整的对象,而仅仅是一种初始化的手段。当你写 MyClass obj = MyClass(); 时,MyClass() 是一个 prvalue。在 C++17 下,它根本不会产生临时对象,而是直接作为 obj 的构造参数
如果没有这种精细的分类,编译器就很难在标准层面定义:什么时候该直接构造,什么时候该移动构造
六. 引用折叠与完美转发
1. 引用折叠
在 C++ 中,你不能直接写出引用的引用。比如下面这段代码是无法通过编译的:
cpp
int a = 10;
int& & ref = a; // 错误!编译器直接报错但是,在模板参数替换或者 using/typedef 过程中,这种情况会被动发生。为了让代码能跑通,编译器制定了四条折叠规则
-
左值引用 + 左值引用 -> 左值引用(T& & -> T&)
-
左值引用 + 右值引用 -> 左值引用(T& && -> T&)
-
右值引用 + 左值引用 -> 左值引用(T&& & -> T&)
-
右值引用 + 右值引用 -> 右值引用(T&& && -> T&&)
左值引用具有极强的传染性。 只要参与折叠的引用中有一个是左值引用,结果必为左值引用。只有两个全是右值引用,结果才是右值引用
2. 为什么需要引用折叠
引用折叠最核心的应用场景就在模板中。当我们写出 T&& 作为模板参数时,它就不再是单纯的右值引用了,而被称为万能引用
cpp
template<typename T>
void func(T&& param) { ... }这是 T 被推导为 int& 的唯一合法场景。这遵循 C++11 的 引用折叠规则:
- **当你传入一个左值 int a:**推导得出 T 的类型为 int&。此时 param 的类型变为 int& &&,根据规则2,最终折叠为 int&(即左值引用)
- **当你传入一个右值 10:**推导结果为 int 类型,param 的类型转为 int&&,最终得到右值引用 int&&
引用折叠的设计初衷是为了支持转发 。如果没有这套规则,我们就得为每个函数写两份模板:一个接收左值,一个接收右值。有了引用折叠,一个 T&& 就能同时兼容两种情况,并且通过类型推导,精确地捕捉到用户传进来的到底是什么类型
请注意,引用折叠只发生在特定的语境下:
-
模板参数推导(T&&)
-
auto 类型推导(auto&&)
-
typedef 或 using 别名
除此之外的普通代码里,你依然不能写 && &
3. 完美转发
当我们把一个右值传递给一个模板函数时,在函数内部这个参数会因为有了名字而退化成一个左值
cpp
void RealWork(int& x) { cout << "Left Value" << endl; }
void RealWork(int&& x) { cout << "Right Value" << endl; }
template<typename T>
void Wrapper(T&& param) {
// 无论你传进来的是左值还是右值,param 在这里都是左值
RealWork(param);
}
int main() {
Wrapper(10); // 10 是右值,但 Wrapper 内部会调用 RealWork(int&)
}可以发现,移动语义在传递过程中丢失了
为了解决这个问题,C++11 引入了 std::forward<T>(arg)。它的作用是:根据模板参数 T 的推导结果,决定将 arg 强转回左值还是右值
std::forward 的实现逻辑如下:
cpp
template <class _Ty>
_Ty&& forward(remove_reference_t<_Ty>& _Arg) noexcept {
// 将左值转发为左值或右值
return static_cast<_Ty&&>(_Arg);
}-
**remove_reference_t<_Ty>& _Arg:**不管传入的是什么,std::forward 的形参 _Arg 始终是一个左值引用。这是因为在函数内部,任何有名字的变量都是左值
-
**static_cast<_Ty&&>:**这是最核心的地方。它利用了引用折叠公式
当我们使用时:
cpp
template<typename T>
void Wrapper(T&& param) {
RealWork(std::forward<T>(param));
}-
传左值时:T 推导为 int&。forward<int&> 内部执行 static_cast<int& &&>。折叠后变成 int&。转发成功:左值依然是左值
-
传右值时:T 推导为 int。forward<int> 内部执行 static_cast<int&&>。转发成功:右值依然是右值
std::move 是无条件转右值,而 std::forward 是按需转右值
为什么必须显式指定 <_Ty>?
调用 std::move 不需要写模板参数,但调用 std::forward<T> 必须带着 <T>
这是因为 std::forward 无法通过函数参数 _Arg 自动推导出正确的 _Ty。_Arg 永远是左值引用,只有通过显式传递从万能引用那里拿到 _Ty,引用折叠机制才能正确判断出原始属性是左值还是右值
总结
C++11 引入的右值引用与移动语义,为语言赋予了 "所有权" 和 "效率" 的特质。本文的核心观点可概括为以下三点:
-
值类别: 左值是持久的 "房子",右值是临时的 "租客"。理解 prvalue 和 xvalue 的区别,是看懂编译器如何进行拷贝消除优化(RVO/NRVO)的前提
-
移动语义: 移动构造和移动赋值通过直接转移指针所有权而非复制数据,显著提升了性能。需要注意的是:必须添加 noexcept 声明,否则等容器将无法安全调用这些操作
-
转发机制: std::move 是无条件强制类型转换,而 std::forward 通过引用折叠机制,完美保持了参数在复杂调用链中的原始类型特性
理解右值引用不应机械记忆规则,而应从内存管理和对象生命周期的本质入手。当我们使用std::move 时,不仅是在编写代码,更是在执行一次资源所有权的正式移交
