目录
[一、Hugging Face](#一、Hugging Face)
一、Hugging Face
Hugging Face 是一家以开源AI工具闻名的公司,通过其平台和生态系统,简化了从模型使用到项目落地的全流程。
-
核心起点 :凭借 Transformers库 降低了BERT、GPT等预训练模型的使用门槛。
-
当前定位 :已发展为全面的 AI 开发生态系统。
-
支持领域:覆盖自然语言处理、计算机视觉、语音处理及多模态任务。
Hugging Face生态系统主要由Hugging Face Hub和工具链Libraries构成,其中Libraries:
1、模型加载
1.1、AutoModel类
transformers就是hugging face上提供的开源库,可以使用AutoModel的from_pretrained方法来加
载里面的模型。

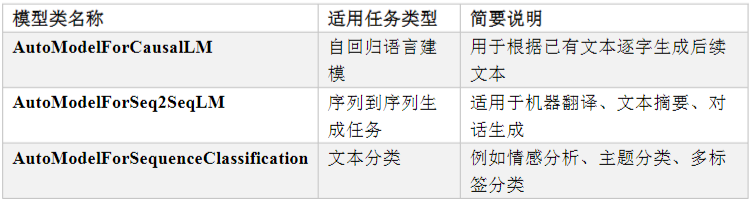
1.2、AutoModelForXXX类
AutoModelForXXX,这些类在模型主干的基础上,自动添加了适配任务的输出层(通常称为"任务
头"或TaskHead),使模型能够直接用于分类、命名实体识别、问答等标准NLP任务的训练与推
理,无需手动修改结构。

2、模型输入输出
各模型forward方法的定义,可查看Transformers库的API文档
3、Tokenizer
Hugging Face 的 Transformers 库中,每个预训练模型都配有专属的 Tokenizer,其核心作用是将原始文本转换为模型可读的格式化输入(如 input_ids、attention_mask)。
它集成了文本到张量的全流程处理,主要包括:
-
子词切分:将文本拆分为子词单元。
-
编码映射:将子词转换为对应的整数 ID。
-
添加特殊标记 :自动插入
[CLS]、[SEP]等符号。 -
截断与补齐:统一序列长度以构建批量输入。
-
生成辅助字段:创建 attention_mask 等模型所需的附加输入。
1.1、加载Tokenizer

1.2、使用Tokenizer


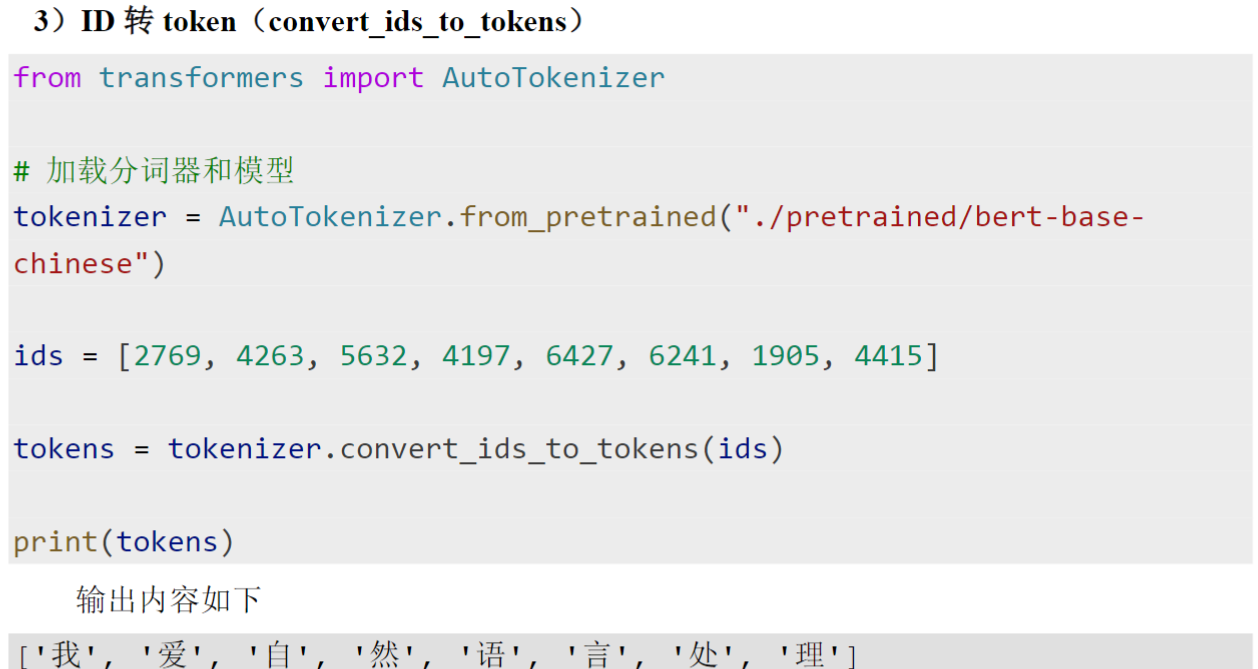
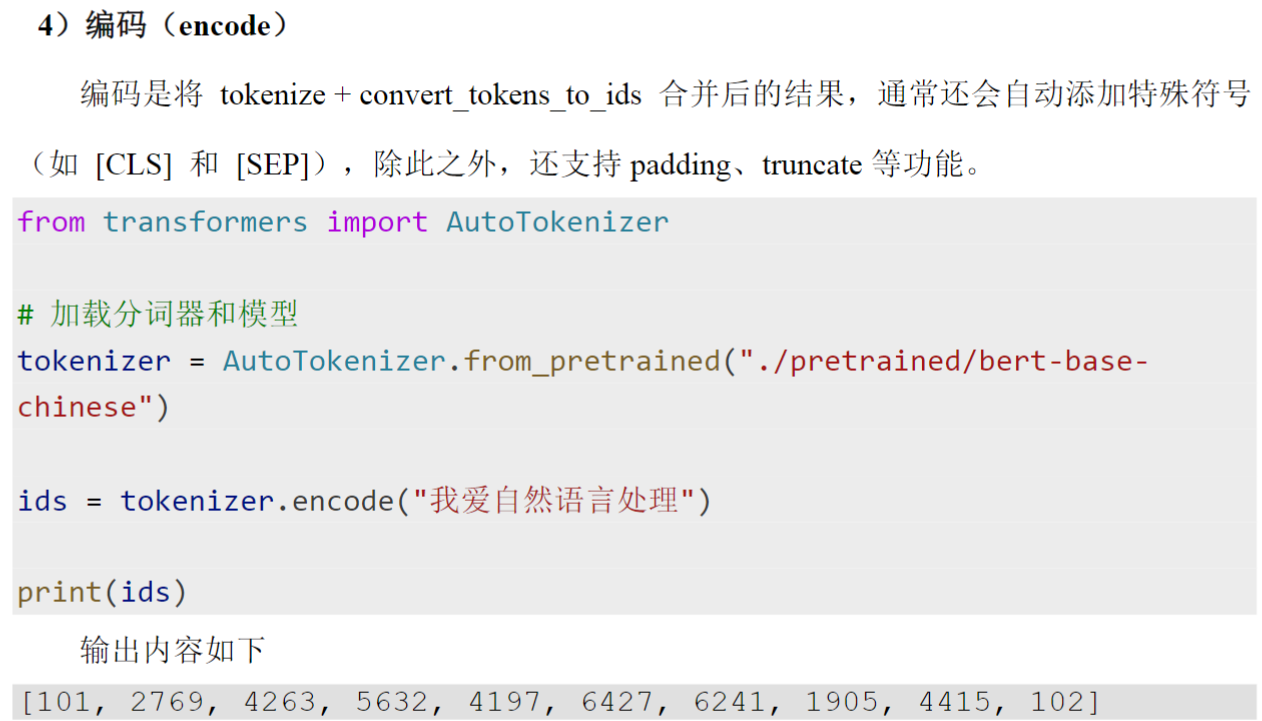


(6)tokenizer()方法(即__call__)
python
text = "我爱自然语言处理"
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-chinese")
inputs = tokenizer(text,padding = 'max_length',max_length=20,return_tensors='pt')
print(inputs)
{'input_ids': tensor([[ 101, 2769, 4263, 5632, 4197, 6427, 6241, 1905, 4415, 102, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])}
python
texts = ['我爱打篮球','我们一起成长','我爱自然语言处理']
inputs = tokenizer(texts,
return_tensors='pt',
padding = 'max_length',
max_length = 10,
truncation=True)
print(inputs)
{'input_ids': tensor([[ 101, 2769, 4263, 2802, 5074, 4413, 102, 0, 0, 0],
[ 101, 2769, 812, 671, 6629, 2768, 7270, 102, 0, 0],
[ 101, 2769, 4263, 5632, 4197, 6427, 6241, 1905, 4415, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}1.3、配合模型使用
python
texts = ['我爱打篮球','我们一起成长','我爱自然语言处理']
model_name = "google-bert/bert-base-chinese"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
inputs = tokenizer(
texts,
padding = True,
return_tensors='pt'
)
print(inputs)
with torch.no_grad():
outputs = model(
# input_ids = inputs['input_ids'],
# token_type_ids = inputs['token_type_ids'],
# attention_mask = inputs['attention_mask']
**inputs
)
print(outputs)4、Datasets
Datasets是Hugging Face推出的轻量级数据处理库,专注于NLP任务,简化模型训练中的数据加载与预处理。其核心优势包括:
-
加载灵活:支持本地文件(如CSV、JSON)与在线公开数据集;
-
结构直观:采用类似表格的结构,每条样本由多个字段组成;
-
集成高效:与Hugging Face模块(如tokenizer)无缝协作,快速构建模型输入;
-
功能实用:提供.map()批量处理、字段筛选、数据集划分(如train_test_split)等常用功能。
1.1、加载数据集

python
from datasets import load_dataset
file_path_train = "review_analysis_gru/data/processed/train.jsonl"
file_path_test = "review_analysis_gru/data/processed/test.jsonl"
dataset_dict = load_dataset(
'json',
data_files = {'test': file_path_test,
"train": file_path_train
},
)
print(dataset_dict)
DatasetDict({
test: Dataset({
features: ['label', 'review'],
num_rows: 12555
})
train: Dataset({
features: ['label', 'review'],
num_rows: 50218
})
})1.2、删除列

1.3、过滤行

1.4、划分数据集

1.5、编码数据
其中function函数要自己写


1.6、保存数据集

1.7、集成Dataloader

5、预训练模型案例
config
python
from pathlib import Path # 路径定义
# 定义项目根目录
ROOT_DIR = Path(__file__).parent.parent
# 数据目录
RAW_DATA_DIR = ROOT_DIR / "data" / "raw"
PROCESSED_DATA_DIR = ROOT_DIR / "data" / "processed"
# 模型目录
MODEL_DIR = ROOT_DIR / "models"
LOG_DIR = ROOT_DIR / "logs"
PRE_TRAINED_DIR = ROOT_DIR / "pretrained"
RAW_DATA_FILE = "online_shopping_10_cats.csv"
BEST_MODEL = "best.model.pt"
BERT_MODEL = "bert-base-chinese"
SEQ_LEN = 128
BATCH_SIZE = 16
EMBEDDING_SIZE = 128
HIDDEN_SIZE = 256
LEARNING_RATE = 1e-5
EPOCHS = 10preprocess
python
from config import *
from datasets import load_dataset, ClassLabel # 加载数据集
from transformers import AutoTokenizer
def preprocess(text):
print("--------开始数据预处理--------")
dataset = load_dataset('csv', data_files = str(RAW_DATA_DIR/RAW_DATA_FILE))['train']
# print(dataset)
# 去掉cat列,数据过滤
dataset = dataset.remove_columns(['cat'])
dataset = dataset.filter(lambda x : x['review'] is not None)
# print(dataset)
dataset = dataset.cast_column('label',ClassLabel(names = ['n','p']))
dataset_dict = dataset.train_test_split(test_size=0.2,stratify_by_column = 'label')
print(dataset_dict)
tokenizer = AutoTokenizer.from_pretrained(PRE_TRAINED_DIR/BERT_MODEL)
def batch_encode(example):
inputs = tokenizer(
example['review'],
padding = 'max_length',
max_length = 128,
truncation = True
)
inputs['labels'] = example['label']
return inputs
dataset_dict = dataset_dict.map(batch_encode,batched = True,remove_columns = ['label','review'])
dataset_dict.save_to_disk(PROCESSED_DATA_DIR)
print("--------数据预处理完成--------")
if __name__ == '__main__':
preprocess(())dataset
python
import torch
from torch.utils.data import DataLoader
from config import *
from datasets import load_from_disk
def get_dataloader(train = True):
path = str(PROCESSED_DATA_DIR / ('train' if train else 'test'))
dataset = load_from_disk(path)
dataset.set_format(type='torch')
dataloader = DataLoader(dataset,batch_size=BATCH_SIZE,shuffle=True)
return dataloader
if __name__ == "__main__":
train_dataloader = get_dataloader(train = True)
test_dataloader = get_dataloader(train = False)
for batch in train_dataloader:
for k,v in batch.items():
print(k,'→',v.shape)
break
input_ids → torch.Size([64, 128])
token_type_ids → torch.Size([64, 128])
attention_mask → torch.Size([64, 128])
labels → torch.Size([64])model
python
import torch
import torch.nn as nn
from transformers import AutoModel
from config import *
class ReviewAnalysisModel(nn.Module):
def __init__(self):
super().__init__()
self.bert = AutoModel.from_pretrained(PRE_TRAINED_DIR/BERT_MODEL)
self.linear = nn.Linear(in_features=self.bert.config.hidden_size,out_features=1)
def forward(self,input_ids,attention_mask,token_type_ids):
output = self.bert(input_ids,attention_mask,token_type_ids)
# 提取output中cls对应的输出隐状态
cls_hidden_state = output.pooler_output
result = self.linear(cls_hidden_state).squeeze(-1)
return result
if __name__ == "__main__":
model = ReviewAnalysisModel()
print(model)
ReviewAnalysisModel(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(21128, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0-11): 12 x BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
(linear): Linear(in_features=768, out_features=1, bias=True)
)train
python
import torch
from torch import nn, optim
from config import *
from dataset import get_dataloader
from model import ReviewAnalysisModel
from tqdm import tqdm
from torch.utils.tensorboard import SummaryWriter # 日志写入器
import time # 时间库
# 定义训练引擎函数,训练一个epoch,返回平均损失
def train_one_epoch(model, train_loader, loss,optimizer,device):
model.train()
total_loss = 0
for batch in tqdm(train_loader,desc='训练:'):
inputs = {k:v.to(device) for k,v in batch.items()}
targets = inputs.pop('labels').to(dtype = torch.float)
outputs = model(**inputs)
loss_value = loss(outputs, targets)
loss_value.backward()
optimizer.step()
optimizer.zero_grad()
total_loss += loss_value.item()
return total_loss / len(train_loader)
def train():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_loader = get_dataloader(train = True)
model = ReviewAnalysisModel().to(device)
# with open(MODEL_DIR/VOCAB_FILE,'r',encoding='utf-8') as f:
# vocab_list = [token.strip() for token in f.readlines()]
#
# model = InputMethodModel(vocab_size = len(vocab_list)).to(device)
loss = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(),lr = LEARNING_RATE)
writer = SummaryWriter(log_dir=LOG_DIR / time.strftime("%Y-%m-%d_%H-%M-%S"))
min_loss = float('inf')
for epoch in range(EPOCHS):
print('='*10,f'EPOCH:{epoch+1}','='*10)
this_loss = train_one_epoch(model, train_loader, loss,optimizer,device)
print("本轮训练损失:",this_loss)
writer.add_scalar('loss',this_loss,epoch+1)
if this_loss < min_loss:
min_loss = this_loss
torch.save(model.state_dict(),MODEL_DIR/BEST_MODEL)
print('模型保存成功!')
writer.close()
if __name__ == '__main__':
train()predict
python
import torch
from config import *
from model import ReviewAnalysisModel
from transformers import AutoTokenizer
def predict_batch(model,input):
model.eval()
with torch.no_grad():
output = model(**input)
batch_results = torch.sigmoid(output)
return batch_results.tolist() # 转换成列表返回
# def predict(text,model,id2word,word2id,k,device):
# tokens = jieba.cut(text)
# ids = [word2id.get(token, word2id.get(UNK_TOKEN)) for token in tokens]
def predict(text, model, tokenizer, device):
inputs = tokenizer(
text,
padding = 'max_length',
truncation = True,
max_length=SEQ_LEN,
return_tensors = 'pt'
)
inputs = {k:v.to(device) for k,v in inputs.items()}
result = predict_batch(model,inputs)
return result[0]
def run_predict():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tokenizer = AutoTokenizer.from_pretrained(PRE_TRAINED_DIR/BERT_MODEL)
# with open(MODEL_DIR/VOCAB_FILE,'r',encoding='utf-8') as f:
# vocab_list = [token.strip() for token in f.readlines()]
# id2word = {id:word for id,word in enumerate(vocab_list)}
# word2id = {word:id for id,word in enumerate(vocab_list)}
print("词表加载成功!")
model = ReviewAnalysisModel().to(device)
# model = InputMethodModel(vocab_size = len(id2word)).to(device)
model.load_state_dict(torch.load(MODEL_DIR/BEST_MODEL))
print("模型加载成功!")
print('欢迎使用文本情感分析模型!输入q或者quit退出...')
while True: # 核心,一个死循环
user_input = input('> ')
# 判断如果是q或quit直接退出
if user_input.strip() in['q','quit']:
print('欢迎下次再来!')
break
# 判断如果是空白,提示信息后继续循环
if user_input.strip() == '':
print('请输入有效内容!')
continue
result = predict(user_input, model, tokenizer, device)
if result > 0.5:
print(f"正向评价(置信度:{result})")
else:
print(f"负向评价(置信度{1 - result})")
if __name__ == '__main__':
# text = "我们公司"
# top5_tokens = predict(text)
# print(top5_tokens)
run_predict()evaluate
python
import torch
from config import *
from tqdm import tqdm
from model import ReviewAnalysisModel
from dataset import get_dataloader
from predict import predict_batch
# 验证逻辑,返回评价指标
def evaluate(model, dataloader, device):
correct_count = 0
total_count = 0
with torch.no_grad():
for batch in tqdm(dataloader,desc = '评估:'):
labels = batch.pop('labels').tolist()
inputs = {k:v.to(device) for k,v in batch.items()}
# 前向传播,得到预测概率
batch_results = predict_batch(model, inputs)
for target,result in zip(labels,batch_results):
total_count += 1
# 判断预测概率是否大于0.5
result = 1 if result > 0.5 else 0
if result == target:
correct_count += 1
return correct_count/total_count
# 评估主流程
def run_evaluate():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = ReviewAnalysisModel().to(device)
model.load_state_dict(torch.load(MODEL_DIR/BEST_MODEL))
print("模型加载成功!")
test_dataloader = get_dataloader(train = False)
acc = evaluate(model, test_dataloader, device)
print("评估结果:")
print('准确率:', acc)
if __name__ == '__main__':
run_evaluate()6、带任务头的模型实现
模型直接保存到目录文件下,然后模型加载直接去找目录

model = AutoModelForSequenceClassification.from_pretrained(MODEL_DIR).to(device)day12 10