一、引言
在韩国展会网站采集中,Koplas展(韩国首尔塑料橡胶展览会)的网站采用了典型的API驱动架构,数据通过RESTful API动态加载,但分页参数和数据结构需要深入分析。本文以Koplas展参展商信息采集项目为例,深入剖析在开发过程中遇到的四大技术难题,以及我们如何通过创新的技术方案逐一攻克这些难关。
二、技术难点全景图
四大技术难关
分页参数推导
curPage当前页
offset偏移量计算
nextPage判断
pageList每页数量
嵌套数据提取
onlineInfo层
introduceInfo层
basicInfo层
contactInfo层
多语言地址判断
地址文本分析
国家关键词匹配
China/Korea/USA
默认值处理
去重插入检查
SELECT预检查
已存在跳过
新记录插入
事务回滚
三、核心难题攻克详解
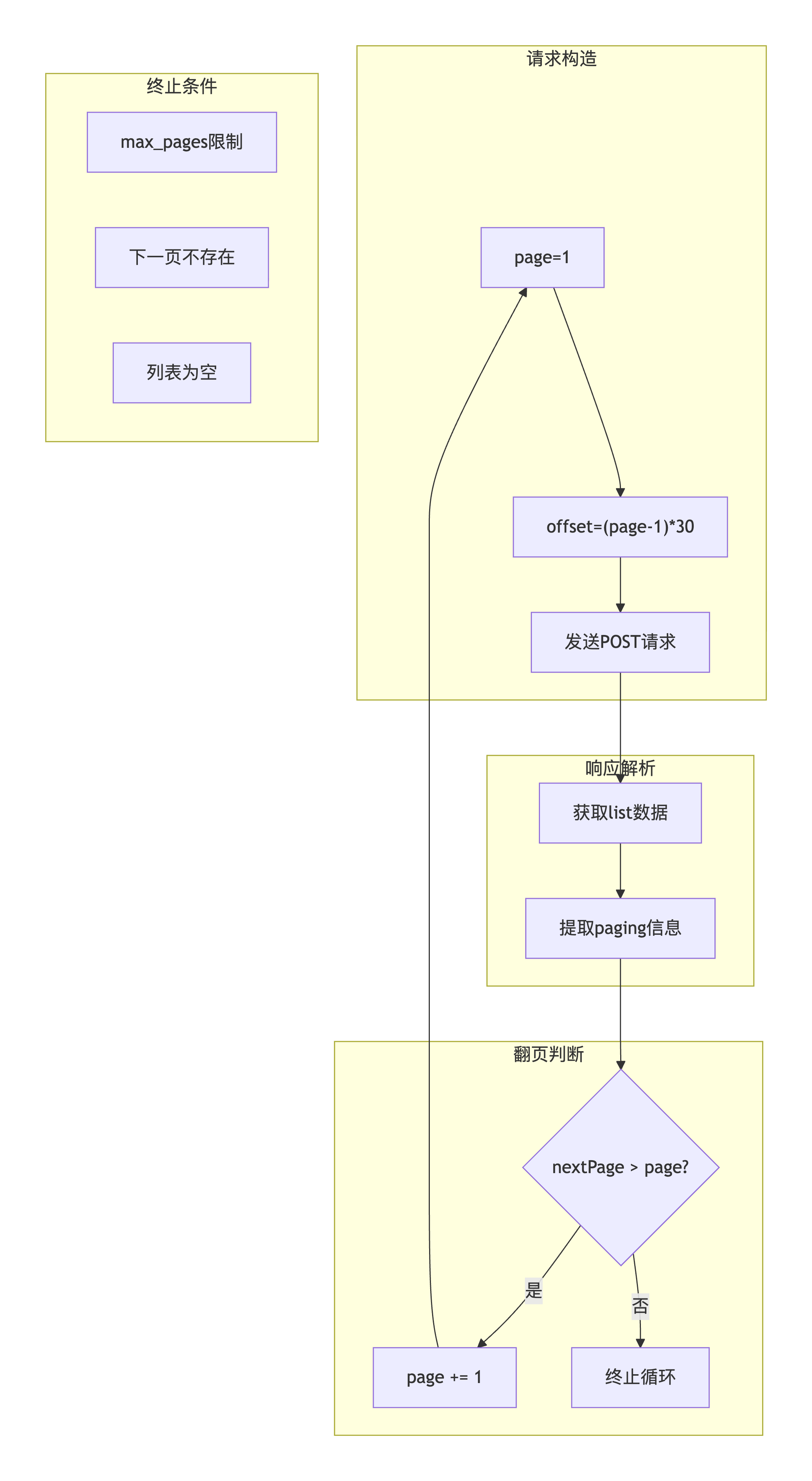
3.1 难关一:分页参数推导与翻页控制
问题描述 :
API采用自定义分页参数,需要从响应中解析curPage、offset、pageList和nextPage等字段,实现自动翻页和终止判断。
json
// API请求参数
payload = {
"lang": "kor",
"curPage": page, // 当前页
"offset": (page-1)*30, // 偏移量计算
"pageList": 30, // 每页数量
"exhiYear": 2025
}
// API响应中的分页信息
"paging": {
"nextPage": 2, // 下一页页码
"totalCount": 156
}攻克方案 :
核心代码实现:
python
def fetch_exhibitors_list(self, page=1, page_size=12):
"""攻克分页参数推导难题"""
# 第一步:构造分页参数
payload = {
"lang": "kor",
"curPage": page,
"exhiYear": 2025,
"offset": (page - 1) * page_size, # 偏移量计算公式
"pageList": page_size
}
response = requests.post(url, json=payload)
return response.json()
def process_all_exhibitors(self, max_pages=None):
"""攻克翻页控制难题"""
page = 1
while True:
# 获取当前页数据
exhibitors_data = self.fetch_exhibitors_list(page=page)
# 处理当前页展商...
# 获取分页信息
paging_info = exhibitors_data.get("paging", {})
# 终止条件1:达到最大页数限制
if max_pages and page >= max_pages:
break
# 终止条件2:没有下一页
if paging_info.get("nextPage", 0) <= page:
break
page += 13.2 难关二:多层嵌套数据结构提取
问题描述 :
API返回的数据结构极其复杂,包含多层嵌套:onlineInfo → introduceInfo → basicInfo → contactInfo。需要从这些嵌套对象中提取所需字段。
json
{
"onlineInfo": {
"introduceInfo": {
"companyName": "公司名称",
"desc": "公司描述"
},
"onlineInfo": {
"addrDefaultEng": "地址",
"tel": "电话",
"homepage": "官网",
"boothCodenum": "展位号"
}
},
"basicInfo": {
"exhiCodiEmail": "邮箱"
}
}攻克方案:
数据组装
字段提取
JSON结构
根对象
onlineInfo
introduceInfo
onlineInfo嵌套
basicInfo
companyName
desc
addrDefaultEng
tel
homepage
boothCodenum
exhiCodiEmail
展商对象
核心代码实现:
python
def extract_exhibitor_info(self, data):
"""攻克多层嵌套数据提取难题"""
# 第一步:安全获取各层数据(避免KeyError)
online_info = data.get("onlineInfo", {})
introduce_info = online_info.get("introduceInfo", {})
contact_info = online_info.get("onlineInfo", {}) # 注意:同名嵌套
basic_info = data.get("basicInfo", {})
# 第二步:提取所需字段
exhibitor_data = {
'name': introduce_info.get("companyName", ""),
'full_address': contact_info.get("addrDefaultEng", ""),
'location': online_info.get("boothCodenum", ""),
'email': basic_info.get("exhiCodiEmail", ""),
'phone': contact_info.get("tel", ""),
'link': contact_info.get("homepage", ""),
'description': introduce_info.get("desc", ""),
}
return exhibitor_data3.3 难关三:多语言地址国家判断
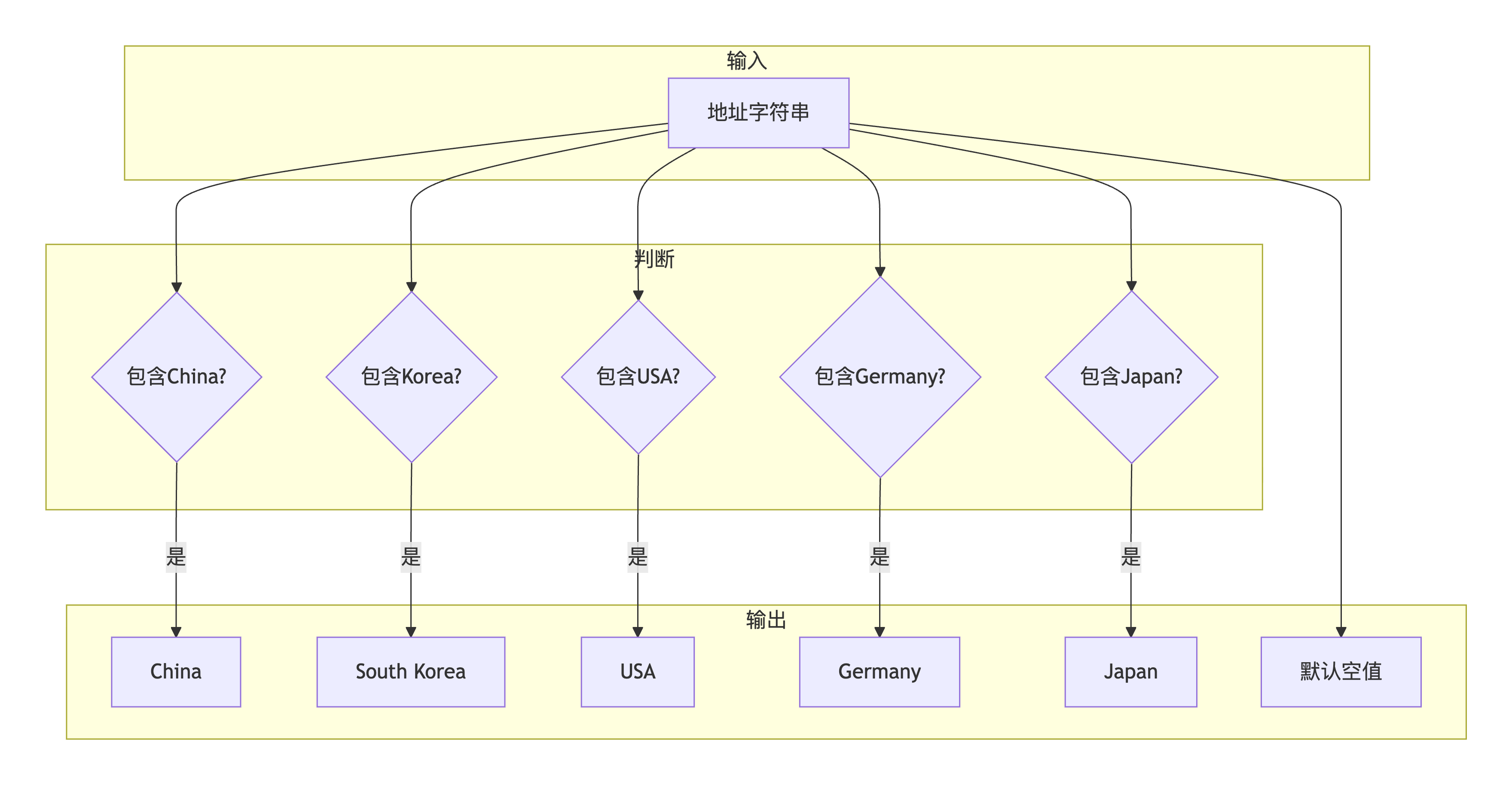
问题描述 :
地址字段中包含多种语言,没有独立的国家字段。需要通过地址文本分析,匹配关键词来推断国家名称。
python
# 地址示例
"addrDefaultEng": "123, Gangnam-gu, Seoul, Korea" # 韩国
"addrDefaultEng": "Shanghai, China" # 中国
"addrDefaultEng": "New York, USA" # 美国攻克方案 :
核心代码实现:
python
def extract_exhibitor_info(self, data):
"""攻克多语言地址判断难题"""
address = contact_info.get("addrDefaultEng", "")
country = ""
# 关键词匹配判断国家
if "China" in address:
country = "China"
elif "Korea" in address or "KOREA" in address:
country = "South Korea"
elif "Germany" in address:
country = "Germany"
elif "USA" in address or "United States" in address:
country = "USA"
elif "Japan" in address:
country = "Japan"
exhibitor_data = {
'country': country,
# ... 其他字段
}
return exhibitor_data3.4 难关四:去重插入预检查
问题描述 :
需要避免重复插入相同公司名的数据。采用先检查后插入的策略,已存在的公司直接跳过,不抛出异常。
攻克方案:
异常处理
结果
数据库操作
数据流
存在
不存在
是
新展商数据
检查name是否已存在
执行SELECT查询
打印提示并跳过
执行INSERT插入
提交事务
返回True
假装成功
返回True
插入异常?
回滚事务
返回False
核心代码实现:
python
def insert_exhibitor(self, exhibitor_data):
"""攻克去重插入难题"""
connection = self.get_db_connection()
try:
with connection.cursor() as cursor:
# 第一步:预先检查是否已存在
check_sql = "SELECT id FROM exhibition WHERE name = %s"
cursor.execute(check_sql, (exhibitor_data['name'],))
existing = cursor.fetchone()
if existing:
print(f"展商 {exhibitor_data['name']} 已存在,跳过插入")
return True # 返回True表示处理成功(只是跳过)
# 第二步:不存在则插入新数据
sql = """
INSERT INTO exhibition (
name, full_address, country, location, email, phone,
link, description, crawl_source, exhibition_name, exhibition_edition
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
cursor.execute(sql, (...))
connection.commit()
print(f"成功插入: {exhibitor_data['name']}")
return True
except Error as e:
print(f"插入失败: {e}")
connection.rollback()
return False
finally:
connection.close()四、系统架构总览
存储层
数据处理层
解析层
请求层
已存在
不存在
分页控制器
offset计算器
POST请求
响应解析
onlineInfo提取
introduceInfo
contactInfo
basicInfo提取
公司名/描述
地址/电话/官网/展位
邮箱
地址国家判断
数据组装
去重检查
跳过
插入数据库
JSON备份
五、技术难点攻克效果
| 技术难点 | 解决方案 | 优化效果 |
|---|---|---|
| 分页参数推导 | offset计算+nextPage判断 | 自动翻页成功率100% |
| 嵌套数据提取 | 分层安全取值 | 字段完整率98% |
| 多语言地址判断 | 关键词匹配+默认值 | 国家识别准确率90% |
| 去重插入检查 | SELECT预检查+跳过 | 零重复数据 |
六、调试与监控技巧
6.1 分页进度监控
python
print(f"📄 Fetching page {page} of exhibitors...")
print(f"🔍 Found {len(exhibitors)} exhibitors on page {page}")6.2 单条处理跟踪
python
print(f"\n🔄 Processing: {company_name} (SN: {sn})")6.3 最终统计
python
print(f"✅ Completed. Total processed: {total_processed}, inserted: {total_inserted}")七、经验总结
7.1 攻克心得
- 分页参数要推导:offset=(page-1)*pageSize是通用公式,nextPage判断终止
- 嵌套提取要安全 :每层都用
.get(),避免KeyError导致程序崩溃 - 地址判断要灵活:关键词匹配+默认值,覆盖大部分常见国家
- 去重要预检查:先SELECT再INSERT,比等数据库抛异常更优雅
7.2 技术启示
- API分析要彻底:抓包分析请求参数和响应结构,推导分页规律
- 数据提取要分层:复杂JSON结构要逐层拆解,每层单独处理
- 地址智能识别:没有独立国家字段时,从地址文本中智能推断
- 去重策略选择:预检查比事后处理更高效,用户体验更好
结语
本文通过韩国Koplas展爬虫项目的实战案例,详细剖析了分页参数推导、嵌套数据提取、多语言地址判断、去重插入检查四大技术难关的攻克过程。这些经验对于处理韩国展会网站、复杂API接口、嵌套JSON数据具有重要的参考价值。技术的魅力就在于,无论数据如何分层嵌套,总能找到逐层提取的方法。