[大语言模型入门精讲(全 5 章):从预训练到推理落地,小白也能懂的 LLM 核心技术](#大语言模型入门精讲(全 5 章):从预训练到推理落地,小白也能懂的 LLM 核心技术)
[第一章 预训练:LLM 的 "基础教育",打造通用语言能力](#第一章 预训练:LLM 的 “基础教育”,打造通用语言能力)
[1.1 预训练 NLP 模型:核心目标与两大步骤](#1.1 预训练 NLP 模型:核心目标与两大步骤)
[1.1.1 无监督、监督、自监督:三种预训练范式](#1.1.1 无监督、监督、自监督:三种预训练范式)
[1.1.2 预训练模型的 "就业适配":微调和提示](#1.1.2 预训练模型的 “就业适配”:微调和提示)
[1.3 示例:BERT------ 预训练模型的 "模范生"](#1.3 示例:BERT—— 预训练模型的 “模范生”)
[BERT 核心任务流程图](#BERT 核心任务流程图)
[BERT 的 "版本迭代"](#BERT 的 “版本迭代”)
[1.4 应用 BERT:从 "通用能力" 到 "具体任务"](#1.4 应用 BERT:从 “通用能力” 到 “具体任务”)
[1.5 章节核心要点](#1.5 章节核心要点)
[第二章 生成式模型:让 LLM"会说话、能创作" 的核心架构](#第二章 生成式模型:让 LLM“会说话、能创作” 的核心架构)
[2.1 大语言模型(LLM)简介:核心能力与架构](#2.1 大语言模型(LLM)简介:核心能力与架构)
[核心架构:仅解码器 Transformer](#核心架构:仅解码器 Transformer)
[2.1.2 训练 LLM:让模型 "学会说话"](#2.1.2 训练 LLM:让模型 “学会说话”)
[2.1.3 微调 LLM:从 "通用话痨" 到 "听话助手"](#2.1.3 微调 LLM:从 “通用话痨” 到 “听话助手”)
[2.1.4 对齐(Alignment):让模型 "好好说话"](#2.1.4 对齐(Alignment):让模型 “好好说话”)
[2.1.5 提示(Prompting):零代码调用 LLM 能力](#2.1.5 提示(Prompting):零代码调用 LLM 能力)
[2.2 大规模训练:把 "小模型" 变成 "大学霸"](#2.2 大规模训练:把 “小模型” 变成 “大学霸”)
[2.2.1 数据准备:给模型喂 "干净营养的饭"](#2.2.1 数据准备:给模型喂 “干净营养的饭”)
[2.2.2 分布式训练:集群算力 "协同训练"](#2.2.2 分布式训练:集群算力 “协同训练”)
[2.2.3 缩放定律:LLM 的 "成长公式"](#2.2.3 缩放定律:LLM 的 “成长公式”)
[2.3 长序列建模:让 LLM "读得懂长文章"](#2.3 长序列建模:让 LLM “读得懂长文章”)
[2.3.1 高效架构:精简注意力计算](#2.3.1 高效架构:精简注意力计算)
[2.3.2 缓存与记忆:复用计算结果](#2.3.2 缓存与记忆:复用计算结果)
[2.3 章节核心要点](#2.3 章节核心要点)
[第三章 提示工程:教 LLM"听懂话、会干活" 的核心技巧](#第三章 提示工程:教 LLM“听懂话、会干活” 的核心技巧)
[3.1 通用提示设计:四要素让 LLM 秒懂需求](#3.1 通用提示设计:四要素让 LLM 秒懂需求)
[示例:高质量提示 vs 低质量提示](#示例:高质量提示 vs 低质量提示)
[3.1.2 上下文学习:LLM 的 "学霸超能力"](#3.1.2 上下文学习:LLM 的 “学霸超能力”)
[3.2 进阶提示方法:让 LLM"会思考、能拆解"](#3.2 进阶提示方法:让 LLM“会思考、能拆解”)
[3.2.1 思维链(CoT):让 LLM "说清解题步骤"](#3.2.1 思维链(CoT):让 LLM “说清解题步骤”)
[3.2.2 问题分解:把 "大难题" 拆成 "小任务"](#3.2.2 问题分解:把 “大难题” 拆成 “小任务”)
[3.2.3 RAG + 工具使用:让 LLM"查资料、用工具"](#3.2.3 RAG + 工具使用:让 LLM“查资料、用工具”)
[3.3 提示优化:让提示 "更高效、更轻量"](#3.3 提示优化:让提示 “更高效、更轻量”)
[3.3.1 常见问题与优化技巧](#3.3.1 常见问题与优化技巧)
[3.3.2 提示长度缩减:小提示也能出高效结果](#3.3.2 提示长度缩减:小提示也能出高效结果)
[3.4 章节核心要点](#3.4 章节核心要点)
[第四章 对齐:让 LLM"听话、懂事、守规矩" 的调教技术](#第四章 对齐:让 LLM“听话、懂事、守规矩” 的调教技术)
[4.1 对齐的三大核心目标](#4.1 对齐的三大核心目标)
[4.2 指令对齐:让 LLM "听懂并执行指令"](#4.2 指令对齐:让 LLM “听懂并执行指令”)
[4.2.1 监督微调(SFT):指令对齐的基础](#4.2.1 监督微调(SFT):指令对齐的基础)
[4.2.2 高效微调:少数据也能出效果](#4.2.2 高效微调:少数据也能出效果)
[4.3 RLHF:让 LLM "符合人类偏好"](#4.3 RLHF:让 LLM “符合人类偏好”)
[4.4 改进的对齐技术:更高效、更稳定](#4.4 改进的对齐技术:更高效、更稳定)
[4.5 章节核心要点](#4.5 章节核心要点)
[第五章 推理:LLM 落地的 "最后一公里",让模型高效干活](#第五章 推理:LLM 落地的 “最后一公里”,让模型高效干活)
[5.1 推理的基本流程:预填充 + 解码(两阶段框架)](#5.1 推理的基本流程:预填充 + 解码(两阶段框架))
[5.1.3 解码算法:决定 LLM 的输出风格](#5.1.3 解码算法:决定 LLM 的输出风格)
[5.2 高效推理技术:让模型 "跑得更快、更省资源"](#5.2 高效推理技术:让模型 “跑得更快、更省资源”)
[5.2.1 核心优化手段](#5.2.1 核心优化手段)
[5.2.2 效率与效果的平衡](#5.2.2 效率与效果的平衡)
[5.3 推理时扩展:让 LLM "处理更复杂任务"](#5.3 推理时扩展:让 LLM “处理更复杂任务”)
[5.3.1 上下文扩展:处理超长文本](#5.3.1 上下文扩展:处理超长文本)
[5.3.4 生成 + 验证:让 LLM "不瞎编"](#5.3.4 生成 + 验证:让 LLM “不瞎编”)
[5.4 章节核心要点](#5.4 章节核心要点)
[全文总结:LLM 核心技术脉络](#全文总结:LLM 核心技术脉络)
前言
随着ChatGPT、LLaMA等大语言模型(LLM)的爆发,AI技术已全面渗透到工作、学习和生活的方方面面,从文案生成、代码编写到智能问答,LLM的应用无处不在。但对于AI初学者而言,面对"预训练""Transformer""RLHF"等专业术语,往往会陷入"看不懂、理不清、不会用"的困境,难以搭建起系统的LLM知识框架。
本文专为AI小白量身打造,摒弃晦涩难懂的公式推导和复杂理论堆砌,采用"通俗比喻+可视化图表+实战案例"的方式,从LLM的底层逻辑出发,层层拆解预训练、生成式模型、提示工程、对齐技术、推理优化五大核心模块,把抽象的技术原理转化为易懂的生活场景,帮助初学者快速入门,轻松掌握LLM的核心知识,打通从"了解"到"应用"的认知壁垒,为后续深入学习或实战落地打下坚实基础。
大语言模型入门精讲(全 5 章):从预训练到推理落地,小白也能懂的 LLM 核心技术
本文是面向 AI 初学者的大语言模型(LLM)入门系列,从底层逻辑到落地应用,用通俗比喻 + 可视化图表 + 实战案例,拆解预训练、生成式模型、提示工程、对齐技术、推理优化五大核心模块,帮你快速搭建 LLM 知识体系。
第一章 预训练:LLM 的 "基础教育",打造通用语言能力
核心比喻
预训练就像给模型 "打基础教育"------ 正如人类先学拼音、数学公式再解具体题目,AI 模型也需在海量数据中掌握语言通用规律(词语搭配、句子结构、基础逻辑),成为 "有潜力的通用型人才",而非直接学习某一特定任务。
1.1 预训练 NLP 模型:核心目标与两大步骤
预训练的核心目标:学习通用语言知识,而非直接落地任务(比如不直接训练 "翻译",而是先让模型懂语言逻辑)。
实现需两步:
基础训练:让模型在海量数据中 "学通用规律"(预训练过程); 任务适配:让 "有基础的模型" 学会具体技能(如情感分析、翻译)。
三种范式对比流程图
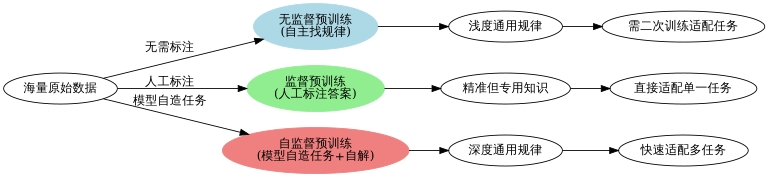
1.1.1 无监督、监督、自监督:三种预训练范式
预训练的核心是 "如何让模型高效学知识",三种主流范式的区别可通过 "教模型认水果" 理解:
表格
| 预训练方式 | 核心逻辑 | 通俗例子 | 核心优点 | 核心缺点 |
|---|---|---|---|---|
| 监督预训练 | 人给 "标准答案"(标注数据),模型模仿学习 | 给 1000 张标好 "苹果 / 橘子" 的图片,让模型记特征 | 学习精准、步骤简单 | 标注成本极高,通用性差 |
| 无监督预训练 | 无标准答案,模型自主挖掘数据规律 | 给 100 万张水果图,让模型自己总结 "红圆 = 一类,橘色带纹 = 另一类" | 数据成本低,易获取 | 学习规律浅,需后续二次训练 |
| 自监督预训练(主流) | 模型 "自己出题自己做",无人工标注 | 给水果图,模型遮住 "颜色 / 果柄",自己猜缺失部分 | 数据成本低 + 学习精准 | 需设计合理的 "自监督任务" |
1.1.2 预训练模型的 "就业适配":微调和提示
预训练后的模型是 "通用型人才",需通过两种方式适配具体任务:
表格
| 适配方式 | 核心逻辑 | 通俗例子 | 适用场景 |
|---|---|---|---|
| 微调(Fine-tuning) | 用少量标注数据 "专项补课",调整模型参数 | 预训练模型懂语言逻辑→给 1000 条标好 "积极 / 消极" 的句子→模型学会情感分析 | 任务固定、需高精度输出(如工业级情感分析) |
| 提示(Prompting) | 不调参数,直接给指令 / 示例,让模型用通用知识完成任务 | 直接对模型说 "判断这句话的情感:'我很喜欢这家餐厅'"→模型输出 "积极" | 快速验证、多任务切换(如临时写文案、解数学题) |
1.3 示例:BERT------ 预训练模型的 "模范生"
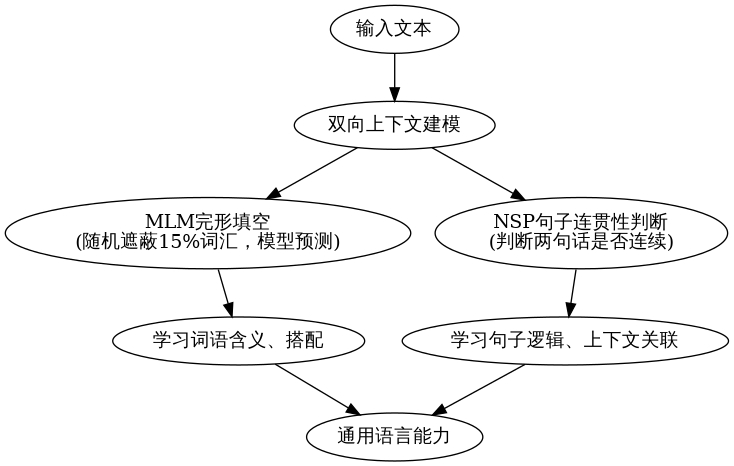
BERT(Google 2018 年推出)是 LLM 的 "祖师爷",彻底验证了 "自监督预训练 + 微调" 的有效性,其核心设计如下:
BERT 核心任务流程图
BERT 的 "版本迭代"
- BERT-base:轻量版(1.1 亿参数),训练快、适合普通设备;
- BERT-large:增强版(3.4 亿参数),效果更优但算力需求高;
- 高效精简版:DistilBERT(参数减半,速度快 2 倍)、ALBERT(共享参数,大幅瘦身);
- 多语言版:mBERT(支持 100 + 语言,一个模型搞定中英法日等)。
1.4 应用 BERT:从 "通用能力" 到 "具体任务"
通过微调给 BERT 加 "任务专属模块",即可落地不同场景:
- 文本分类:输入句子→BERT 提取特征→分类层输出 "积极 / 消极";
- 命名实体识别:输入句子→BERT 提取词特征→输出 "人名 / 地名 / 机构名";
- 问答系统:输入 "文章 + 问题"→BERT 定位答案位置→输出精准回答;
- 提示适配:直接发指令(如 "判断'今天真开心'的情感")→BERT 直接输出结果。
1.5 章节核心要点
- 自监督预训练是当前最优范式:兼顾 "低成本数据" 和 "精准学习";
- BERT 的核心创新:双向上下文建模 + MLM+NSP,让模型懂 "语境";
- 预训练的价值:一次训练,多任务复用,大幅降低任务适配成本。
第二章 生成式模型:让 LLM"会说话、能创作" 的核心架构
核心区别
上一章的 BERT 是 "理解型模型"(如判断情感、提取实体),而生成式模型是 "创作型人才"------ 能写文案、编故事、生成代码,核心代表就是 ChatGPT、LLaMA 等。
2.1 大语言模型(LLM)简介:核心能力与架构
核心能力
根据输入文本,逐词生成连贯、有逻辑的新文本(如输入 "写一句奶茶店宣传语"→输出 "大学旁奶茶店开业!买一送一,学生党冲!")。
核心架构:仅解码器 Transformer
Transformer 是 LLM 的 "骨架",分为编码器(Encoder)和解码器(Decoder):
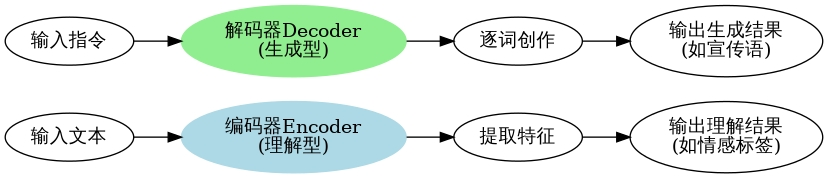
逐词生成逻辑:输入 "今天天气真"→模型计算下一个词概率("好" 60%、"热" 30%、"冷" 10%)→选概率最高的 "好"→再基于 "今天天气真好" 计算下一个词,循环直至生成完整文本。
2.1.2 训练 LLM:让模型 "学会说话"
训练核心是 "喂海量数据,学语言规律":
- 数据来源:书籍、网页、对话、代码(规模达几十亿~万亿 tokens);
- 核心任务:预测下一个词(Next Token Prediction);
- 学习目标:
- 词语搭配("公园"→"散步" 而非 "吃饭");
- 语法结构("我去公园" 而非 "公园去我");
- 基础常识("北京是中国首都")。
2.1.3 微调 LLM:从 "通用话痨" 到 "听话助手"
预训练后的 LLM 是 "什么都能说但可能答非所问" 的 "通用话痨",微调的作用是 "教它听指令":
- 训练数据:"指令 - 回答" 对(如 "问:写游记→答:......");
- 核心目标:让模型学会 "指令→正确输出" 的映射;
- 通俗比喻:从 "只会瞎聊的书生"→"能听懂需求的助手"。
2.1.4 对齐(Alignment):让模型 "好好说话"
对齐的核心是让模型输出 "符合人类价值观":
- 安全对齐:不生成暴力、违法、歧视内容;
- 价值对齐:诚实有用(不知道就说 "不知道",不瞎编);
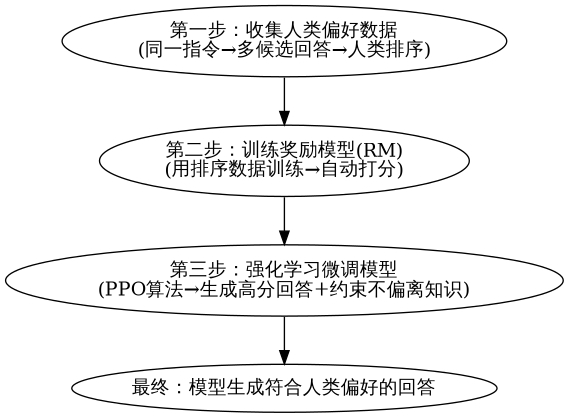
- 核心方法:RLHF(人类反馈强化学习),流程如下:
2.1.5 提示(Prompting):零代码调用 LLM 能力
无需修改模型参数,直接用 "指令 / 示例" 驱动模型:
- 示例 1(情感分析):
判断这句话的情感:"今天真开心"→情感:; - 示例 2(代码生成):
写一个Python函数,计算两个数的和; - 核心优势:灵活高效,一个模型适配 N 个任务。
2.2 大规模训练:把 "小模型" 变成 "大学霸"
2.2.1 数据准备:给模型喂 "干净营养的饭"
数据是 LLM 的 "粮食",质量决定模型上限:
- 核心步骤:
- 数据采集:网页、书籍、代码库、对话记录;
- 数据清洗:去重(避免复读)、去噪(过滤乱码 / 广告)、去敏感(删除违法 / 隐私内容);
- 数据格式化:切分为 token(如 "我今天去吃饭"→「我」「今天」「去」「吃饭」)+ 数字编码。
2.2.2 分布式训练:集群算力 "协同训练"
大模型参数达百亿 / 千亿级,单台机器扛不住,需分布式训练:
- 数据并行:多台机器训不同数据,同步梯度;
- 模型并行:多台机器分拆模型参数,协同计算;
- 流水线并行:多台机器分拆模型层,接力训练。
2.2.3 缩放定律:LLM 的 "成长公式"
核心规律:在合理范围内,模型参数、训练数据、算力越大,效果越好:
- 通俗理解:像学生学习 ------ 脑子越聪明(参数大)、读书越多(数据多)、刷题越久(算力足),成绩越好;
- 注意边界:无限放大并非一直有效,但当前技术阶段 "大就是好" 仍成立。
2.3 长序列建模:让 LLM "读得懂长文章"
核心痛点
原生 Transformer 的注意力计算量是O(n²)(n 为文本长度),1 万个词的计算量是 1 千个词的 100 倍,无法处理长文本(如整本书、长篇报告)。
2.3.1 高效架构:精简注意力计算
表格
| 优化方案 | 核心逻辑 | 通俗比喻 |
|---|---|---|
| 滑动窗口注意力 | 每个词只关注前后 N 个词 | 看书只看当前页,不翻整本书 |
| 稀疏注意力 | 只计算关键词对的注意力 | 聊天只和核心人物交流,不挨个聊 |
| 线性注意力 | 计算量从O(n²)→O(n) |
从 "逐个握手"→"集体问候",效率翻倍 |
2.3.2 缓存与记忆:复用计算结果
- KV 缓存:存储之前计算的 "键(Key)" 和 "值(Value)",生成新词时直接复用,不用重新计算;
- 长期记忆:把超长文本的早期内容存入 "记忆库",需要时检索,避免遗忘。
2.3 章节核心要点
- 生成式模型的核心是 "仅解码器 Transformer + 逐词生成";
- 大规模训练的关键:高质量数据 + 分布式算力 + 缩放定律;
- 长序列建模的核心:精简注意力 + 缓存复用,突破文本长度限制。
第三章 提示工程:教 LLM"听懂话、会干活" 的核心技巧
核心比喻
提示工程(Prompt Engineering)就像 "给超级学霸出考题"------ 不用改模型,只要指令写得清、逻辑给得明,就能让 LLM 精准完成任务。
3.1 通用提示设计:四要素让 LLM 秒懂需求
一个高质量提示需包含 4 个核心部分,缺一不可:
plaintext
提示Prompt = 指令(明确做什么) + 上下文(补充背景) + 输入数据(具体内容) + 输出格式(指定样式)示例:高质量提示 vs 低质量提示
表格
| 类型 | 提示内容 | 效果差异 |
|---|---|---|
| 低质量 | "写个文案" | 输出杂乱,不符合需求 |
| 高质量 | "写 30 字以内奶茶店开业文案,面向学生,突出买一送一,风格活泼,用感叹号结尾" | 输出精准:"大学旁奶茶店开业!买一送一,学生党速冲,甜到心坎里~" |
3.1.2 上下文学习:LLM 的 "学霸超能力"
无需训练,给几个 "例题" 就能让 LLM 学会新任务,三种常见形式:
- 零样本学习(Zero-shot):无例题,直接发指令(适合简单任务);
- 示例:
判断情感:"今天的电影真烂"→情感:;
- 少样本学习(Few-shot):给 2-5 个例题,模型模仿(适合复杂任务);
- 示例:
例题1:"我很开心"→积极;例题2:"我很生气"→消极;判断:"今天运气真好"→;
- 思维链学习(Chain-of-Thought):给例题 + 推理步骤(适合逻辑 / 数学题);
- 示例:
例题:小明有5个苹果,送2个,买3个→步骤:5-2=3,3+3=6→答案:6;问题:小红有8块糖,吃3块,妈妈给4块→。
3.2 进阶提示方法:让 LLM"会思考、能拆解"
基础提示能 "干活",进阶技巧能 "干好复杂活":
3.2.1 思维链(CoT):让 LLM "说清解题步骤"
核心逻辑:先输出推理过程,再给答案,避免 "瞎猜"。
- 示例:
问题:某奶茶店日均卖100杯,单价15元,原料成本5元/杯,房租8000元/月,求月利润。请一步步思考并解答。 - 模型输出:
步骤1:月营收=100杯×15元×30天=45000元;步骤2:月原料成本=100杯×5元×30天=15000元;步骤3:月总成本=15000+8000=23000元;步骤4:月利润=45000-23000=22000元→答案:22000元。
3.2.2 问题分解:把 "大难题" 拆成 "小任务"
核心逻辑:复杂任务拆分为多个子问题,逐个解决。
- 示例:
原问题:分析某奶茶店盈利情况→分解:1. 计算月营收;2. 计算月成本(原料+房租+人工);3. 计算月利润;4. 分析利润增长点。
3.2.3 RAG + 工具使用:让 LLM"查资料、用工具"
- RAG(检索增强生成):先检索外部知识库(如最新数据、企业文档),再生成答案,解决 "知识滞后";
- 示例:
帮我查2025年北京平均工资,基于官方数据回答;
- 示例:
- 工具使用:调用计算器、代码解释器、API 等,突破 LLM 能力边界;
- 示例:
用Python计算[1,3,5,7,9]的平均值和方差,输出代码+结果。
- 示例:
3.3 提示优化:让提示 "更高效、更轻量"
3.3.1 常见问题与优化技巧
表格
| 问题类型 | 原提示 | 优化后提示 |
|---|---|---|
| 模糊不清 | "分析这家店" | "分析某大学旁奶茶店月利润:日均销量 100 杯,单价 15 元,原料成本 5 元 / 杯,房租 8000 元 / 月" |
| 格式混乱 | "随便写" | "用分点列出 3 个奶茶店宣传语,每点不超过 20 字" |
| 逻辑复杂 | "帮我搞定这个分析" | "先算营收→再算成本→最后算利润→给出 3 条优化建议" |
3.3.2 提示长度缩减:小提示也能出高效结果
- 提炼核心:长篇背景→关键词(如 "大学旁奶茶店开业,面向学生做买一送一活动");
- 示例替代说明:不用写 "风格活泼",直接给示例 "学生党冲呀!买一送一超划算~";
- 关键词缩写:用 "情感分析" 替代 "判断这句话是积极、消极还是中性"。
3.4 章节核心要点
- 高质量提示 = 清晰指令 + 上下文 + 输入数据 + 输出格式;
- 进阶技巧核心:让 LLM"先思考(CoT)、拆任务(分解)、补知识(RAG)";
- 提示优化目标:用最少的文字,获取最精准的输出。
第四章 对齐:让 LLM"听话、懂事、守规矩" 的调教技术
核心比喻
如果说预训练是 "让模型会说话",提示是 "让模型听懂话",那对齐就是 "让模型好好说话"------ 把 "野孩子" 教成 "懂礼貌、守规矩、有价值" 的助手。
4.1 对齐的三大核心目标
对齐的本质是 "让 LLM 行为与人类意图一致":
- 有用(Useful):准确理解并完成指令(如写文案、解数学题);
- 无害(Harmless):不生成暴力、违法、歧视、误导性内容;
- 诚实(Honest):尊重事实,不编造信息,不知道就说 "不知道"。
4.2 指令对齐:让 LLM "听懂并执行指令"
4.2.1 监督微调(SFT):指令对齐的基础
- 核心逻辑:用 "指令 - 输出" 标注数据,让模型学会 "指令→正确回答";
- 示例数据:
指令:写30字奶茶店开业文案→输出:大学旁奶茶店开业!买一送一,学生党速冲,甜到心坎~; - 通俗比喻:给模型发 "习题集",让它反复刷题掌握解题规律。
4.2.2 高效微调:少数据也能出效果
针对普通人 / 小企业算力有限的问题,高效微调技术(LoRA、QLoRA)应运而生:
- 核心优势:只微调模型 1%-10% 的参数,用几百 - 几千条数据就能达到接近全量微调的效果;
- 通俗比喻:给学生 "重点补课",只补薄弱知识点,不用重新学整本书。
4.3 RLHF:让 LLM "符合人类偏好"
RLHF(人类反馈强化学习)是对齐的 "核心技术",完整流程如下:
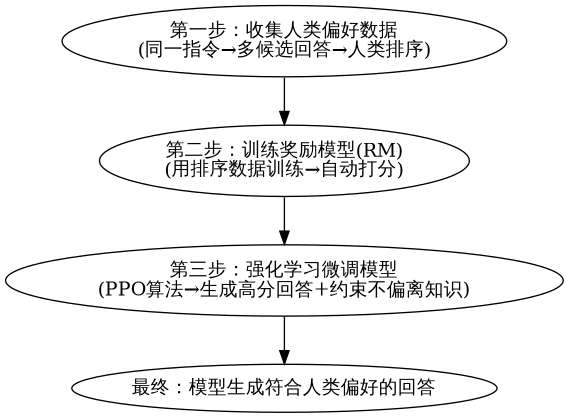
4.4 改进的对齐技术:更高效、更稳定
原版 RLHF 存在 "步骤多、成本高、不稳定" 的问题,改进方案如下:
表格
| 改进方案 | 核心逻辑 | 优势 |
|---|---|---|
| 直接偏好优化(DPO) | 跳过奖励模型,直接用 "优选回答 vs 落选回答" 训练 | 步骤简单、训练稳定、速度快 |
| 自动生成偏好数据 | 用强模型生成候选回答 + 排序,替代人工标注 | 降低标注成本,提升效率 |
| 逐步对齐 | 分阶段调教:先懂指令→再守安全→最后符合偏好 | 模型进步稳,不易 "学坏" |
| 推理时对齐 | 训练时不修改参数,推理时实时筛选最优回答 | 保留通用能力,避免过度对齐 |
4.5 章节核心要点
- 对齐的核心是 "让 LLM 符合人类价值观",而非单纯 "会执行指令";
- RLHF 是标准对齐方案,DPO 是更高效的替代方案;
- 对齐的平衡:既要 "听话",也要保留模型的通用能力和创造性。
第五章 推理:LLM 落地的 "最后一公里",让模型高效干活
核心比喻
如果说预训练是 "学知识",对齐是 "懂规矩",那推理(Inference)就是 "干农活"------ 用户提问后,模型逐词生成回复的全过程,核心目标是 "更快、更准、更省资源"。
5.1 推理的基本流程:预填充 + 解码(两阶段框架)
大模型生成文本是 "逐词生成",流程分为两步:
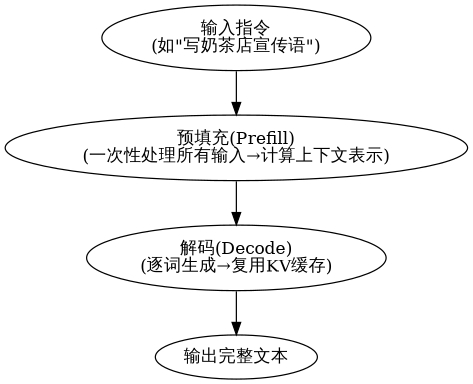
5.1.3 解码算法:决定 LLM 的输出风格
解码算法是 "模型选下一个词的规则",直接影响输出效果:
表格
| 解码算法 | 核心逻辑 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 贪心搜索 | 每次选概率最高的词 | 速度快、逻辑稳 | 输出死板、缺乏多样性 | 事实问答、摘要 |
| 束搜索(Beam Search) | 保留前 k 个概率最高的词,选整体最优 | 准确率高、连贯性好 | 速度慢、多样性差 | 机器翻译、专业文案 |
| 采样(Sampling) | 按概率随机选词 | 多样性强、有创造性 | 易跑题、逻辑乱 | 诗歌、故事创作 |
| Top-k/Top-p 采样 | 从概率前 k 个 / 累计概率 p 的词中随机选 | 平衡多样性和稳定性 | - | 日常对话、文案生成 |
5.2 高效推理技术:让模型 "跑得更快、更省资源"
5.2.1 核心优化手段
表格
| 优化方案 | 核心逻辑 | 效果提升 |
|---|---|---|
| KV 缓存 | 存储之前的 Key/Value,复用计算结果 | 速度提升 10-100 倍 |
| 批处理 | 打包多个用户请求一起计算 | 吞吐量提升 5-10 倍 |
| 并行化 | 数据 / 模型 / 张量并行,拆分计算任务 | 支持千亿参数模型推理 |
| 混合精度训练 | 用半精度(FP16)替代全精度(FP32) | 显存占用减少 50% |
5.2.2 效率与效果的平衡
高效推理的核心是 "取舍(Trade-off)":
- 缓存越大→速度越快,但显存占用越高;
- 批处理越大→吞吐量越高,但延迟越高;
- 并行化越复杂→算力利用越充分,但工程成本越高。
5.3 推理时扩展:让 LLM "处理更复杂任务"
5.3.1 上下文扩展:处理超长文本
- 滑动窗口:只关注最近 N 个词,避免超长文本计算爆炸;
- 分层处理:长文本→切块→总结每块→汇总整体结论(如整本书→章节总结→全书摘要);
- 位置编码外推:突破训练时的文本长度限制(如训练时支持 4k 词,推理时支持 16k 词)。
5.3.4 生成 + 验证:让 LLM "不瞎编"
核心逻辑:先输出推理过程,再验证正确性,提升复杂任务准确率。
- 示例(数学题):
步骤1:8-3=5;步骤2:5+4=9;验证:8-3+4=9,计算正确→答案:9。
5.4 章节核心要点
- 推理的核心流程:预填充(读懂输入)+ 解码(逐词生成);
- 高效推理的关键:KV 缓存 + 批处理 + 并行化;
- 推理扩展的目标:处理更长文本、更复杂任务,输出更准确。
全文总结:LLM 核心技术脉络
plaintext
预训练(打基础) → 生成式模型(会创作) → 提示工程(会听话) → 对齐技术(懂规矩) → 推理优化(高效干)本文通过 "比喻 + 图表 + 案例" 拆解 LLM 核心技术,从基础到进阶层层递进。如果需要某一模块的实战代码(如提示工程示例、RLHF 简化实现),或想深入了解某一技术细节(如 Transformer 架构、LoRA 微调),可以在评论区留言~
结尾
大道至简,繁难亦可拆解。至此,我们已经一同走完了从大语言模型基础原理到工程化落地的完整旅程。通过对预训练基础的夯实、生成架构的剖析、提示工程的巧思、对齐技术的校准以及推理优化的精进,我们相信你已经对 LLM 的底层逻辑有了通透的理解。
技术的价值在于应用,知识的终点在于创新。本文所涵盖的内容,是构建 LLM 能力大厦的基石,但绝非终点。未来的技术旅程中,或许你会遇到更复杂的微调场景、更庞大的算力挑战或是更前沿的模型架构。
愿此书能助你扬帆起航,在智能时代的深海中,不仅能看懂浪潮 ,更能驾驭浪潮,将所学转化为真正的生产力,创造出属于你的技术价值。