前言
在人工智能领域,GPT(Generative Pre-trained Transformer,生成式预训练Transformer)无疑是近年来最具影响力的技术突破之一。从2018年GPT-1的首次亮相,到ChatGPT引发全球AI热潮,再到GPT-4展现出令人惊叹的多模态能力,GPT系列模型一直在刷新我们对自然语言处理可能性的认知。本文将深入剖析GPT的架构设计,探讨其背后的核心原理,帮助读者建立对这一革命性技术的系统性理解。
GPT的成功并非偶然,而是建立在一系列精妙的技术创新之上。要理解GPT,我们首先需要回溯到它的"祖先"------Transformer架构,以及理解为什么这种架构能够成为现代大型语言模型的基础。
一、GPT与Transformer的历史渊源
1.1 Transformer的诞生
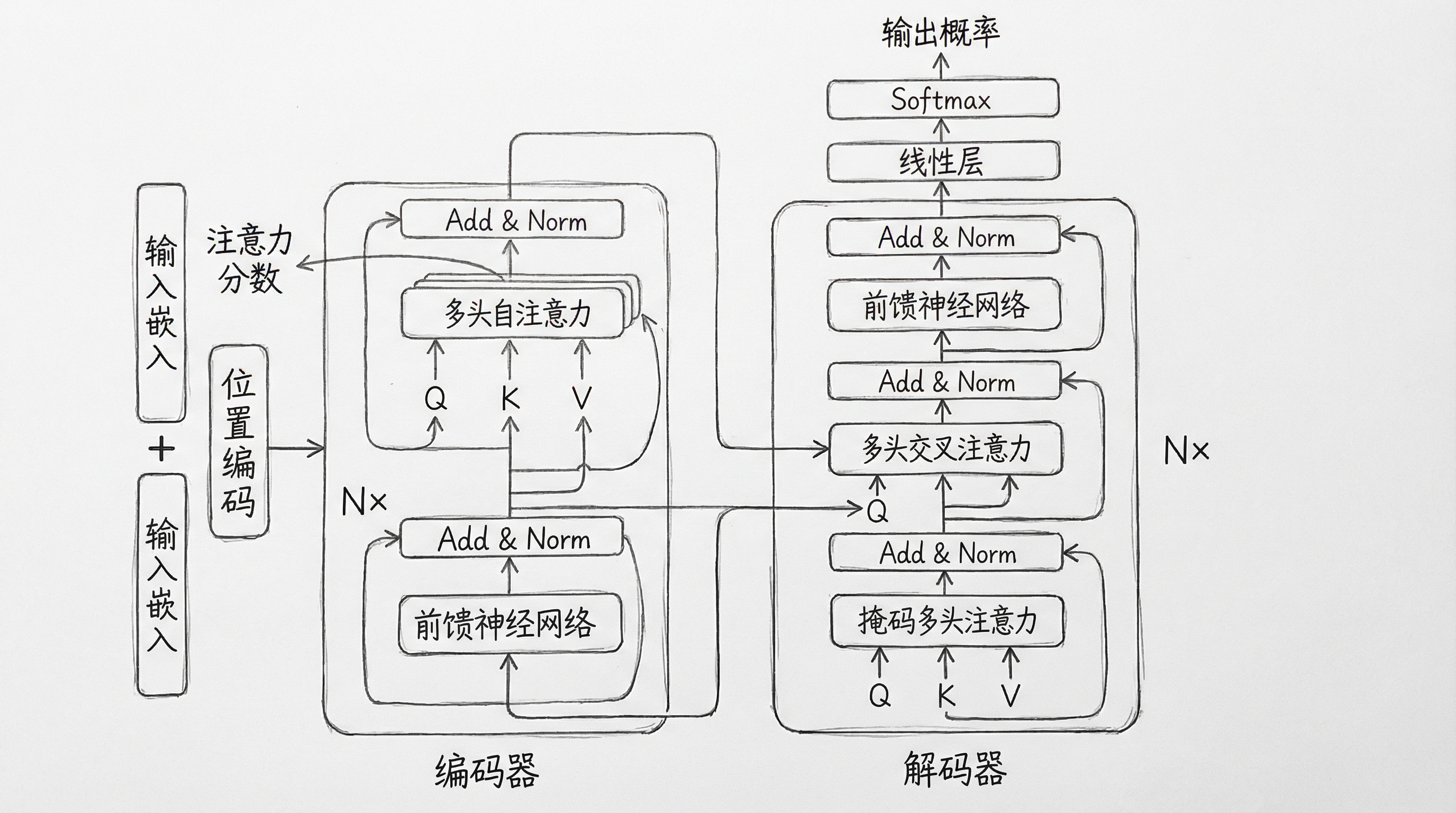
2017年,谷歌研究团队发表了具有里程碑意义的论文《Attention Is All You Need》,首次提出了Transformer架构。这篇论文的标题本身就昭示了其核心思想:摒弃传统的循环神经网络(RNN)和卷积神经网络(CNN),仅使用注意力机制(Attention Mechanism)来处理序列数据。这一架构的提出,彻底改变了自然语言处理领域的发展方向。
Transformer最初是为机器翻译任务设计的,其架构包含两个核心部分:编码器(Encoder)和解码器(Decoder)。编码器负责理解输入文本,将其转换为一系列上下文相关的表示;解码器则基于编码器的输出和已生成的内容,逐步生成目标文本。这种 Encoder-Decoder 的结构在后续的BERT模型中得到了进一步发展和优化。
1.2 GPT的诞生:专注于生成
然而,OpenAI的研究团队在开发GPT时选择了一条不同的道路。他们意识到,对于大多数实际应用场景(如写作助手、代码生成、对话系统等),我们更需要的是文本生成能力,而非理解后再翻译。于是,GPT采用了纯粹的解码器(Decoder-only)架构,专注于生成任务。
这一选择具有深远的影响。纯粹的解码器架构不仅更加简洁,而且特别适合自回归生成------即基于已有内容预测下一个词元的任务。更重要的是,这种架构天然支持少样本(Few-shot)和零样本(Zero-shot)学习,使模型能够在没有特定任务训练的情况下,通过简单的提示(Prompt)完成各种语言任务。
二、GPT架构核心组件详解
2.1 输入处理:词元化与嵌入
当我们向GPT输入一段文本时,系统首先需要将文本转换为模型可以处理的数字表示。这个过程涉及两个关键步骤:词元化(Tokenization)和嵌入(Embedding)。
GPT采用了子词词元化(Subword Tokenization)方法,将文本分解为较小的语言单元。与传统的词级分词不同,子词词元化能够有效处理未登录词(Out-of-Vocabulary,OOV)问题,同时保持合理的词表大小。例如,单词"unhappiness"可能被分解为"un"、"happi"、"ness"三个子词。
词元化后,每个词元通过嵌入矩阵映射为一个固定维度的向量。在GPT-3中,这个维度是12288维。如此高的维度虽然增加了计算成本,但为模型提供了足够丰富的表示空间,能够捕捉语言中的细微差别。
2.2 位置编码:赋予序列顺序感知能力
与Transformer原始论文中使用固定正弦/余弦函数生成位置编码不同,GPT选择了可学习的位置嵌入(Learned Positional Embeddings)。这意味着位置编码会被作为模型参数,在训练过程中自动学习最优的位置表示。
位置编码的维度与词元嵌入维度相同(GPT-3中为12288维),最终输入是词元嵌入与位置嵌入的逐元素相加。这种设计使得模型能够同时考虑词语的语义信息和位置信息,为后续的注意力计算奠定基础。
2.3 自注意力机制:GPT的核心
自注意力(Self-Attention)是Transformer架构的灵魂,也是GPT能够有效处理长序列的关键技术。理解自注意力机制,对于深入理解GPT至关重要。
自注意力的核心思想是:序列中的每个位置都可以"关注"序列中的所有其他位置,并根据相关性动态分配注意力权重。这种机制允许模型捕捉任意距离的依赖关系,解决了RNN中常见的长期依赖问题。
具体实现上,自注意力通过三个线性变换,将输入向量分别投影到Query(查询)、Key(键)和Value(值)三个空间。对于序列中的每个位置,我们使用其Query向量与所有位置的Key向量进行点积运算,得到原始注意力分数;然后通过Softmax函数归一化,得到最终的注意力权重;最后,用这些权重对Value向量进行加权求和,得到该位置的输出表示。
数学上,单头自注意力可以表示为:
Attention(Q, K, V) = softmax(QK^T / √d_k) V其中 dk 是Key向量的维度,除以 dk 是为了缩放点积结果,防止梯度消失。
2.4 多头注意力:多角度理解语言
GPT采用了多头注意力(Multi-Head Attention)机制,这是其表达能力强化的关键。多头注意力将上述的自注意力过程并行运行多次,每次使用不同的Query、Key、Value投影矩阵。
每个注意力头(Head)学习不同的注意力模式:有的头可能专注于捕捉主谓一致关系,有的关注指代消解,有的关注语义相似性,还有的可能捕捉词汇间的位置关系。这种分工合作的机制,使模型能够从多个角度同时理解语言的不同层面。
GPT-3使用了96个注意力头,配合96层Transformer解码器块,拥有惊人的1750亿参数。这种庞大的规模,是GPT-3展现出惊人能力的重要基础。
2.5 因果掩码:保证自回归生成
作为自回归生成模型,GPT必须确保生成第t个词时,只能看到位置1到t-1的信息,不能"窥视"未来。这通过引入因果掩码(Causal Mask)来实现。
因果掩码是一个上三角矩阵,将未来的注意力分数设置为负无穷大。经过Softmax归一化后,这些位置的注意力权重变为零,从而有效阻止了信息从未来位置流向当前位置。这种设计是GPT能够进行连贯文本生成的关键。
2.6 前馈神经网络:特征变换
每个Transformer块中,除了注意力层,还包含一个前馈神经网络(Feed-Forward Network,FFN)。这个FFN通常由两个线性变换组成,中间夹着一个非线性激活函数(GPT中使用GELU激活)。
FFN的作用是对注意力层的输出进行进一步的非线性变换,增强模型的表达能力。尽管FFN的计算量占比较大(约占整个Transformer计算量的三分之一),但实验表明,它对于模型性能至关重要,不可或缺。
2.7 残差连接与层归一化:训练稳定性
深层神经网络面临的一个核心挑战是梯度消失和梯度爆炸问题。GPT通过引入残差连接(Residual Connection)和层归一化(Layer Normalization)来有效缓解这一问题。
残差连接允许梯度直接流过网络,即使某些层的梯度较小,也不至于完全消失。层归一化则通过对每一层的激活值进行标准化,稳定了训练过程,加快了收敛速度。
在GPT的实现中,每个子层(注意力层和FFN)都使用了残差连接,并采用后层归一化(Post-Layer Normalization)策略,即先进行归一化,再通过残差连接。这种安排被认为是训练大型Transformer模型的最佳实践。
三、GPT的训练范式
3.1 预训练:自监督学习
GPT的训练分为两个阶段:预训练(Pre-training)和微调(Fine-tuning)。预训练阶段采用自监督学习,核心任务是"下一个词预测"(Next Token Prediction)。
具体而言,给定一个文本序列 w1,w2,...,wn,模型的任务是预测下一个词 wt+1,基于前t个词的条件概率 P(wt+1∣w1,...,wt)。这个任务看似简单,却蕴含着语言的本质规律------要准确预测下一个词,模型必须理解语法结构、语义关系、世界知识等各个方面。
预训练使用大规模的无标注文本语料库。GPT-3的训练数据涵盖了CommonCrawl、WebText、Books、Wikipedia等多个来源,总计约3000亿个词元。这种海量、多样化的训练数据,是模型获得广泛知识的重要来源。
3.2 微调:任务适配
预训练完成后,GPT模型已经具备强大的语言理解和生成能力。但要让它完成特定任务(如问答、分类、对话等),需要进行微调。
微调阶段使用任务相关的小规模标注数据。模型在预训练参数的基础上,继续训练,使模型适应特定任务的输出格式和评价标准。相比从头训练,微调大大减少了所需的标注数据量和计算资源。
3.3 上下文学习:GPT-3的创新
GPT-3带来了一个重要的范式创新:上下文学习(In-Context Learning)。这使得GPT-3能够在完全不进行参数更新的情况下,仅通过输入中的示例来完成新任务。
在上下文学习中,用户将任务描述和若干示例以自然语言的形式提供给模型。模型利用其强大的语言理解能力,从这些示例中推断出任务模式,并将其应用到新的输入上。这种能力使GPT-3展现出惊人的泛化性,被认为是通向通用人工智能的重要一步。
四、GPT家族的发展历程
4.1 GPT-1:开创性尝试
2018年,OpenAI发布了GPT-1,包含1.17亿参数。虽然规模相对较小,但它首次验证了"预训练+微调"范式的有效性。GPT-1在多种自然语言理解任务上取得了当时的最佳成绩,证明了大型语言模型的巨大潜力。
4.2 GPT-2:走向生成
GPT-2于2019年发布,将参数规模提升到15亿。OpenAI最初以"过于危险"为由拒绝完全开源,引发了广泛讨论。GPT-2展示了惊人的文本生成能力,能够写作风格多样的长文章,以至于人类难以区分其生成内容与人类写作的差异。
4.3 GPT-3:规模的力量
2020年发布的GPT-3将参数规模推升至1750亿,成为当时最大的语言模型之一。GPT-3证明了"规模法则"(Scaling Law)的有效性:随着模型规模、数据量和计算量的增加,模型能力呈现可预测的提升。
更重要的是,GPT-3展现的上下文学习能力,引发了对大型语言模型智能本质的新一轮思考。模型是否真正"理解"语言,还是仅仅在统计模式匹配?这些问题至今仍是AI研究的重要议题。
4.4 ChatGPT与GPT-4:走向应用
2022年11月,基于GPT-3.5的ChatGPT上线,以对话形式提供服务,迅速引爆全球AI热潮。ChatGPT展示了大型语言模型在交互式应用中的巨大潜力。
2023年3月,GPT-4发布,进一步提升了推理能力,并首次引入了多模态支持,能够处理图像输入。GPT-4在各专业和学术考试中表现出色,被视为大型语言模型发展的又一重要里程碑。
五、GPT架构的技术细节与代码实现
5.1 Transformer块的结构
GPT的基本构建单元是Transformer解码器块(Transformer Decoder Block),其结构可以概括为:
Input
↓
LayerNorm
↓
Multi-Head Self-Attention (with causal mask)
↓
Add & Norm (残差连接)
↓
LayerNorm
↓
Feed-Forward Network
↓
Add & Norm (残差连接)
↓
Output这个结构重复N次(GPT-3中N=96),最终通过一个线性层和Softmax输出下一个词元的概率分布。
5.2 简化代码实现
以下是GPT核心组件的简化PyTorch实现,展示了其架构设计的关键要素:
python
import torch
import torch.nn as nn
import math
class MultiHeadAttention(nn.Module):
"""多头注意力机制"""
def __init__(self, d_model, num_heads):
super().__init__()
self.num_heads = num_heads
self.d_k = d_model // num_heads
# Q, K, V 投影
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
batch_size, seq_len, d_model = x.size()
# 线性投影并分头
Q = self.W_q(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_k(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_v(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
# 注意力分数
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# 应用因果掩码(GPT核心特性)
causal_mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()
scores = scores.masked_fill(causal_mask, float('-inf'))
# Softmax归一化
attn_weights = torch.softmax(scores, dim=-1)
# 加权求和
attn_output = torch.matmul(attn_weights, V)
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return self.W_o(attn_output)
class FeedForward(nn.Module):
"""前馈神经网络"""
def __init__(self, d_model, d_ff):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.activation = nn.GELU()
def forward(self, x):
return self.linear2(self.activation(self.linear1(x)))
class TransformerBlock(nn.Module):
"""Transformer解码器块"""
def __init__(self, d_model, num_heads, d_ff):
super().__init__()
self.attention = MultiHeadAttention(d_model, num_heads)
self.feed_forward = FeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x):
# 注意力后残差连接
x = x + self.attention(self.norm1(x))
# FFN后残差连接
x = x + self.feed_forward(self.norm2(x))
return x
class GPT(nn.Module):
"""GPT模型"""
def __init__(self, vocab_size, d_model, num_heads, num_layers, max_seq_len):
super().__init__()
self.token_embedding = nn.Embedding(vocab_size, d_model)
self.position_embedding = nn.Embedding(max_seq_len, d_model)
self.blocks = nn.Sequential(*[
TransformerBlock(d_model, num_heads, d_model * 4)
for _ in range(num_layers)
])
self.norm = nn.LayerNorm(d_model)
self.linear = nn.Linear(d_model, vocab_size)
def forward(self, x):
batch_size, seq_len = x.size()
# 嵌入
token_emb = self.token_embedding(x)
pos_emb = self.position_embedding(torch.arange(seq_len, device=x.device))
x = token_emb + pos_emb
# 通过所有Transformer块
x = self.blocks(x)
x = self.norm(x)
# 预测下一个词
logits = self.linear(x)
return logits5.3 关键设计决策
GPT的架构设计包含多个关键决策,这些决策共同决定了模型的性能和应用特性:
使用GELU激活函数:不同于早期Transformer使用的ReLU,GPT采用GELU(Gaussian Error Linear Unit)作为激活函数。GELU在零点附近具有更平滑的过渡,能够产生更好的梯度流。
采用前置层归一化(Pre-Layer Norm):虽然标准Transformer使用后置层归一化,但GPT-3采用了前置层归一化加额外的归一化层,这种设计被证明在训练稳定性上表现更好。
旋转位置编码:GPT的后续版本引入了旋转位置编码(RoPE),取代了传统的可学习位置编码。RoPE通过旋转操作将位置信息融入词元表示,具有更好的外推能力,能够处理训练时未见过的更长序列。
六、GPT架构的优势与局限
6.1 核心优势
GPT架构之所以能够成为大型语言模型的主流选择,源于其多方面的优势:
并行计算能力:Transformer架构允许序列中的所有位置并行计算注意力,大大提升了训练和推理效率。相比RNN的顺序计算,Transformer能够充分利用现代GPU的并行计算能力。
长距离依赖捕捉:自注意力机制使模型能够直接建立序列中任意两个位置之间的关联,有效解决了长距离依赖问题。这对于理解复杂语言结构至关重要。
可扩展性:Transformer架构展现出良好的可扩展性,模型性能随规模增加呈现可预测的提升。这为通过增加模型规模来提升能力提供了可行路径。
多任务统一:单一GPT模型可以通过提示工程完成多种任务,无需为每个任务训练专门的模型。这种通用性大大简化了AI系统的开发部署。
6.2 固有局限
然而,GPT架构也存在一些固有的局限性:
计算成本高:自注意力的计算复杂度是O(n²),其中n是序列长度。对于长序列,计算和内存需求急剧增加。尽管出现了各种优化技术(如Sparse Attention、Linear Attention),但完全解决这个问题仍需架构创新。
缺乏显式记忆:GPT作为纯粹的自回归模型,缺乏显式的外部记忆机制。虽然可以通过上下文提供相关信息,但这限制了模型处理需要精确检索的任务。
幻觉问题:大型语言模型有时会生成看似合理但实际上错误或不存在的内容。这种"幻觉"现象源于模型的统计学习本质,在需要精确事实的应用中带来挑战。
上下文长度限制:尽管GPT-4 Turbo支持高达128K的上下文窗口,但相比人类能够处理的信息量,这仍然是一个限制。如何实现高效的长上下文建模仍是活跃的研究方向。
七、GPT技术的未来展望
7.1 架构演进
大型语言模型领域正在经历快速发展,多项架构创新正在推进这一领域的边界:
混合专家模型(Mixture of Experts):如GPT-4据传采用的MoE架构,通过条件激活部分专家网络,在保持模型规模的同时降低计算成本。
状态空间模型(State Space Models):如Mamba等新型架构,试图结合RNN和Transformer的优势,提供更高效的序列建模能力。
高效注意力机制:包括Flash Attention、Ring Attention等优化技术,正在使更长的上下文处理成为可能。
7.2 多模态扩展
GPT-4已经展示了处理图像输入的能力。未来的GPT架构预计将进一步扩展到视频、音频、代码执行结果等多种模态,实现真正的多模态智能系统。
7.3 持续学习与适应
如何使大型语言模型能够持续学习新知识,而不需要频繁的重新训练,是另一个重要研究方向。知识编辑、持续学习、模块化架构等技术正在探索中。
结语
GPT架构代表了人工智能领域的一项重大突破,它将Transformer的自注意力机制与大规模预训练范式相结合,创造出了具有惊人能力的语言模型。从GPT-1到GPT-4的发展历程,我们见证了"规模法则"的强大威力,也看到了架构创新的持续价值。
理解GPT的架构原理,不仅对于AI研究者和工程师至关重要,对于任何希望把握AI发展趋势的人都有重要意义。展望未来,GPT及其衍生技术将继续演进,推动人工智能向更高水平发展,深刻改变我们与机器交互的方式。
作为AI从业者或爱好者,深入理解GPT的核心原理,将帮助我们更好地应用这一技术,也为我们参与塑造AI未来奠定基础。希望本文能够为您的学习和研究提供有价值的参考。