导读
视觉语言模型(VLM)通常意味着大参数、大显存、大算力------GPT-4o、Gemini、Claude的视觉能力背后是数百亿甚至更大规模的模型。但如果你的场景是一台树莓派、一个工业摄像头、或者一个离线环境呢?
Moondream 给出了一个不同的答案:用 5 亿参数做视觉理解,4-bit 量化后运行内存仅需 816 MiB。这个由两位前 AWS 工程师创建的开源项目,目前在 GitHub 上获得约 9,500 星,提供了从 0.5B 到 9B(MoE 架构,2B 激活)的完整模型家族,覆盖图像描述、视觉问答、目标检测、OCR、计数、UI 元素定位等多项视觉能力。
更值得关注的是其最新的 Moondream 3 Preview:在 refcoco 系列视觉定位基准上,这个 2B 激活参数的模型得分超过了 GPT-5 和 Gemini 2.5-Flash。
本文将从模型架构、核心能力、性能数据、上手使用四个维度,介绍这个"小而强"的视觉语言模型项目。
一、Moondream 是什么?
Moondream 是一个开源视觉语言模型项目,官方定位是"a tiny vision language model that kicks ass and runs anywhere"(一个超小的视觉语言模型,性能强劲,随处可跑)。
项目基本信息:
| 维度 | 信息 |
|---|---|
| 开发团队 | M87 Labs(西雅图) |
| 创始人 | Vik Korrapati(CTO,前 AWS 9 年)、Jay Allen(CEO,前 AWS 7 年) |
| GitHub | github.com/vikhyat/moondream(约 9,500 stars) |
| 模型托管 | HuggingFace:vikhyatk/moondream2、moondream/moondream3-preview |
| 许可证 | Moondream 2B / 0.5B:Apache 2.0;Moondream 3 Preview:BSL 1.1,附加使用授权为禁止第三方托管服务(商业托管需联系 contact@m87.ai) |
| 在线体验 | moondream.ai/playground |
Moondream 的核心设计理念是效率优先:不追求参数规模,而是在极小的模型体积内最大化视觉理解能力,使 VLM 能够部署到边缘设备、移动端和资源受限的环境中。
二、模型家族:从 0.5B 到 9B MoE
Moondream 目前提供三个模型版本,覆盖从边缘部署到高性能推理的不同场景:
2.1 Moondream 0.5B:边缘设备的视觉理解
Moondream 0.5B 是一个 5 亿参数的紧凑模型,专为边缘设备优化。
| 配置 | 下载大小 | 运行内存 |
|---|---|---|
| 8-bit 量化 | 479 MiB | 996 MiB |
| 4-bit 量化 | 375 MiB | 816 MiB |
4-bit 量化下不到 1 GB 的运行内存,意味着它可以在树莓派级别的硬件上运行。官方列举的目标场景包括零售(库存管理、无人收银)、制造业(质量检测、缺陷检测)、交通(车流监控)和安防(异常检测、边缘隐私保护)。
2.2 Moondream 2B:通用视觉理解
Moondream 2B 是项目的主力模型,约 20 亿参数,适用于通用图像理解任务,包括图像描述、视觉问答和目标检测。
HuggingFace 模型 ID:vikhyatk/moondream2
2.3 Moondream 3 Preview:MoE 架构的跃升
Moondream 3 是项目的最新版本(Preview 状态),采用了细粒度稀疏混合专家(Mixture-of-Experts, MoE) 架构:
| 参数 | 数值 |
|---|---|
| 总参数量 | 9B |
| 激活参数量 | 2B(每个 token) |
| 专家数量 | 64 |
| 每 token 激活专家数 | 8 |
| 上下文长度 | 32K tokens(从 2K 扩展) |
| 默认训练上下文 | 4,096 tokens |
Moondream 3 从 Moondream 2(2B 稠密模型)通过 drop upcycling(一种从稠密模型初始化 MoE 模型的技术)初始化。训练过程中使用了负载均衡和路由正交性损失,并在后训练阶段禁用了负载均衡以避免灾难性遗忘。注意力机制方面引入了可学习温度缩放和 LSE(Log-Sum-Exp)抑制。
值得注意的是,Moondream 3 的强化学习后训练所消耗的计算量超过了初始预训练。
硬件要求: 目前需要 24GB 以上显存的 NVIDIA GPU。量化版本和 Apple Silicon 支持标注为"coming soon"。

模型家族对比图
三、核心能力:不止看图说话
Moondream 支持多项视觉理解任务:
图像描述(Captioning)
支持 Short 和 Long 两种模式。2025 年 3 月更新后,Long 模式生成的描述长度约为 Normal 模式的 2 倍。
视觉问答(VQA)
对图像内容进行开放式提问,支持场景理解、属性识别、关系推理等。
目标检测(Object Detection)
支持自然语言描述的目标检测查询,返回边界框坐标。COCO mAP(平均精度均值)在 2025 年 3 月更新中有大幅提升。
指向定位(Pointing)与计数(Counting)
定位图像中特定区域,返回 X/Y 坐标;对指定类别的对象进行计数。
OCR / 文本识别
识别和提取图像中的文字。2025 年 3 月更新在 OCRBench 上有改进,但官方提到对极小字体仍有不足。
UI 元素定位
识别界面截图中的 UI 组件(按钮、输入框等),适用于 UI 自动化测试场景。
结构化输出
支持以 JSON 等格式返回结果,便于程序化处理。图像标签(Image Tagging)功能可以返回图像中所有可见对象和特征的 JSON 数组。
四、性能表现:2B 激活参数 vs 大模型
Moondream 3 Preview 的官方文档提供了与 GPT-5、Gemini 2.5-Flash、Claude 4 Sonnet 的对比数据:
| 任务 | Moondream 3 Preview | GPT-5 | Gemini 2.5-Flash | Claude 4 Sonnet |
|---|---|---|---|---|
| refcoco(视觉定位基准) | 91.1 | 57.2 | 75.8 | 30.1 |
| refcoco+(视觉定位) | 81.8 | 46.3 | 70.2 | 23.4 |
| refcocog(视觉定位) | 88.6 | 49.8 | 75.1 | 26.2 |
| CountBenchQA(计数) | 93.2 | 89.3 | 81.2 | 90.1 |
| ChartQA(图表理解) | 86.6 | 85* | 79.5 | 74.3* |
| DocVQA(文档理解) | 88.3 | 89* | 94.2 | 89.5* |
| POPE(幻觉检测) | 89.0 | 88.4 | 88.1 | 84.6 |
数据来源:Moondream 官方文档(docs.moondream.ai),带 * 的数值为官方原始标注,可能来自不同评测条件
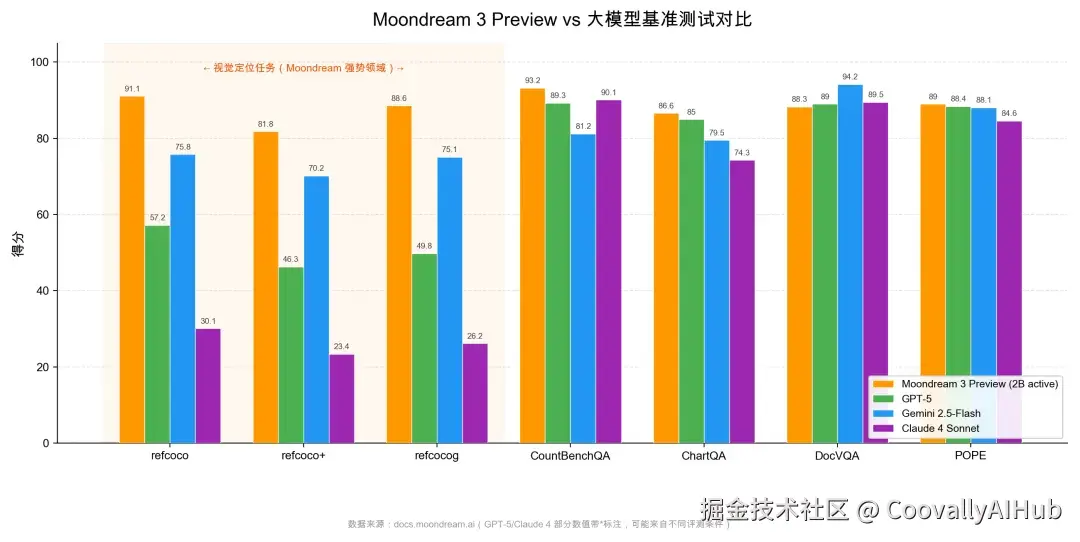
基准测试对比图
几个值得关注的点:
- 视觉定位(refcoco 系列)是 Moondream 3 的强势领域:refcoco 上 91.1 的得分大幅领先 GPT-5(57.2)和 Gemini 2.5-Flash(75.8),这是一个 2B 激活参数模型对数量级更大模型的显著优势
- 计数、图表理解、幻觉检测表现与大模型持平或略优
- 文档理解(DocVQA) 是相对弱项,落后于 Gemini 2.5-Flash 约 6 个百分点
推理速度
2025 年 3 月更新引入了 compile()优化,在 NVIDIA 3090 上将推理速度从 61.4 tok/s 提升至 123.4 tok/s,实现了约 2 倍加速。
五、上手使用:从安装到推理
5.1 云端 API(最快上手)
pip install moondream
ini
import moondream as md
from PIL import Image
model = md.vl(api_key="YOUR_API_KEY")
image = Image.open("path/to/image.jpg")
# 视觉问答
result = model.query(image, "What is in this image?")
print(result["answer"])
# 图像描述
caption = model.caption(image, length="normal")
print(caption["caption"])
# 目标检测
detections = model.detect(image, "person")
# 指向定位
points = model.point(image, "the red button")5.2 本地部署(Transformers)
arduino
pip install "transformers>=4.51.1" "torch>=2.7.0" "accelerate>=1.10.0" "Pillow>=11.0.0"
ini
from transformers import AutoModelForCausalLM
from PIL import Image
import torch
model = AutoModelForCausalLM.from_pretrained(
"vikhyatk/moondream2",
trust_remote_code=True,
dtype=torch.bfloat16,
device_map="mps"# 或 "cuda"
)
image = Image.open("path/to/your/image.jpg")
settings = {"temperature": 0.5, "max_tokens": 768, "top_p": 0.3}
# 图像描述
result = model.caption(image, length="short", settings=settings)
print(result)Moondream 3 Preview 的 HuggingFace 模型 ID 为 moondream/moondream3-preview,目前需要 24GB+ NVIDIA GPU。
六、总结:谁适合用 Moondream?
Moondream 的核心竞争力在于用极小的模型体积覆盖多项视觉理解能力,这使它在以下场景中具有独特价值:
- 边缘部署 / 离线环境:0.5B 模型 4-bit 量化后不到 1GB 内存,可在嵌入式设备上运行视觉理解任务
- 需要视觉定位能力的应用:refcoco 系列基准上的表现是其最突出的优势,适合需要精确定位图像中特定区域的场景(如 UI 自动化、机器人视觉)
- 成本敏感的批量图像处理:相比调用大模型 API,本地部署 Moondream 在大批量图像处理中的成本优势明显
- 快速原型验证:几行代码即可调用多项视觉能力(检测、问答、描述、OCR),适合快速验证视觉 AI 想法
需要注意的限制:
- Moondream 3 Preview 目前仅支持 24GB+ NVIDIA GPU,量化和 Apple Silicon 版本尚未发布
- 官方提到 Moondream 3 的推理速度"比预期更慢",仍在优化中
- 文档理解(DocVQA)等任务上与大模型仍有差距
- Moondream 3 Preview 采用 BSL 1.1 许可证,禁止第三方托管服务,商业托管需额外授权