README
由于本人电脑不行,只用cpu进行训练的,可谓速度慢得ym,当然如果你是30系列以上得显卡教程下面也是给出一个gpu训练的py代码;
一、可行性分析
约束条件
- 硬件:windows/macOS(Apple Silicon 或 Intel)
- 要求:不用现有大模型基座,从头训练
- 数据:只有你们的聊天记录
- 目标:命令行交互
现实挑战
坦诚地说,这个方案有较大局限性:
- 数据量问题:聊天记录通常只有几千到几万条,不足以从零训练一个有意义的语言模型(通常需要数十亿token)
- 算力问题:macOS 即使有 M 系列芯片,训练一个 transformer 模型也极其耗时
- 效果问题:小数据集 + 小模型 = 模型只会"背诵"而非"理解"
调整后的方案
建议采用 "小型Transformer + 针对性训练" 的方案:
- 不追求通用大模型,而是训练一个对话风格生成器
- 使用 GPT-2 级别的小模型(124M 参数)
- 在你们的聊天记录上进行针对性微调
二、技术方案设计
架构选择
模型:GPT-2 Small (124M 参数) 或 DistilGPT-2 (82M)
框架:PyTorch + Transformers
训练方式:从预训练权重开始,在聊天数据上继续训练目录结构
wx_ai_model/
├── data/
│ ├── raw/ # 原始聊天记录
│ ├── processed/ # 清洗后的数据
│ └── training/ # 训练集/验证集
├── src/
│ ├── preprocess.py # 数据清洗
│ ├── train.py # 训练脚本
│ ├── generate.py # 推理脚本
│ └── utils.py # 工具函数
├── models/ # 保存模型
├── checkpoints/ # 训练检查点
├── requirements.txt
└── README.md三、详细操作步骤
步骤 1:环境搭建
打开终端,执行以下命令:
bash
# 创建虚拟环境
python3 -m venv venv
source venv/bin/activate
# 安装依赖
pip install torch torchvision torchaudio
pip install transformers datasets
pip install numpy pandas
pip install tqdm创建 requirements.txt:
txt
#mac
# torch>=2.0.0
# torchvision>=0.15.0
# torchaudio>=2.0.0
# transformers>=4.30.0
# datasets>=2.12.0
# numpy>=1.24.0
# pandas>=2.0.0
# tqdm>=4.65.0
#window (test-nopass)
#torch==2.0.1
#torchvision==0.15.2
#torchaudio==2.0.2
#transformers==4.36.2
#datasets==2.16.1
#numpy==1.24.3
#pandas==2.1.4
#tqdm==4.66.1
# 深度学习框架
torch==2.0.1
torchvision==0.15.2
torchaudio==2.0.2
# Hugging Face 生态
transformers==4.36.2
datasets==2.16.1
accelerate==0.25.0
tokenizers==0.15.2
huggingface_hub==0.36.2
safetensors==0.7.0
# 数据处理
numpy==1.24.3
pandas==2.1.4
pyarrow==23.0.1
# 工具
tqdm==4.66.1
regex==2026.2.28
PyYAML==6.0.3
requests==2.32.5
packaging==26.0
filelock==3.25.2
# 网络相关
httpx==0.28.1
certifi==2026.2.25
urllib3==2.6.3
idna==3.11
# 进度美化
rich==14.3.3
click==8.3.1
# 其他依赖
python-dateutil==2.9.0.post0
six==1.17.0
typing_extensions==4.15.0
multiprocess==0.70.15
dill==0.3.7
fsspec==2023.10.0步骤 2:数据预处理
创建 src/preprocess.py:
python
import json
import re
from pathlib import Path
from typing import List, Dict, Tuple
import pandas as pd
from tqdm import tqdm
class ChatPreprocessor:
def __init__(self, data_path: str, output_path: str):
self.data_path = Path(data_path)
self.output_path = Path(output_path)
self.output_path.mkdir(parents=True, exist_ok=True)
def load_wechat(self, file_path: str) -> List[Dict]:
"""加载微信聊天记录(假设已导出为txt格式)"""
messages = []
current_sender = None
current_msg = []
with open(file_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
# 微信格式:2024-01-01 12:00:00 张三: 消息内容
match = re.match(r'(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}) (.+?): (.+)', line.strip())
if match:
# 保存上一条消息
if current_msg:
messages.append({
'sender': current_sender,
'content': ' '.join(current_msg)
})
# 开始新消息
timestamp, sender, content = match.groups()
current_sender = sender
current_msg = [content]
else:
# 续行
if current_msg:
current_msg.append(line.strip())
# 保存最后一条
if current_msg:
messages.append({
'sender': current_sender,
'content': ' '.join(current_msg)
})
return messages
def clean_message(self, text: str) -> str:
"""清洗单条消息"""
# 去除空白字符
text = text.strip()
# 去除特殊字符
text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9,。!?、;:""''()【】《》\s]', '', text)
# 去除过短消息
if len(text) < 2:
return None
return text
def build_conversations(self, messages: List[Dict],
your_name: str, their_name: str) -> List[Tuple[str, str]]:
"""构建对话对"""
conversations = []
i = 0
while i < len(messages) - 1:
# 检查是否是交替对话
if messages[i]['sender'] == your_name and messages[i+1]['sender'] == their_name:
user_msg = self.clean_message(messages[i]['content'])
ass_msg = self.clean_message(messages[i+1]['content'])
if user_msg and ass_msg:
conversations.append((user_msg, ass_msg))
i += 2
else:
i += 1
return conversations
def save_training_data(self, conversations: List[Tuple[str, str]]):
"""保存为训练格式"""
# 转换为 DataFrame
df = pd.DataFrame(conversations, columns=['user', 'assistant'])
# 保存为 JSON
with open(self.output_path / 'conversations.json', 'w', encoding='utf-8') as f:
json.dump(conversations, f, ensure_ascii=False, indent=2)
# 保存为训练格式(每行一个样本)
with open(self.output_path / 'train.txt', 'w', encoding='utf-8') as f:
for user, ass in conversations:
# 格式:用户: xxx\n助手: xxx\n\n
f.write(f"用户: {user}\n")
f.write(f"助手: {ass}\n\n")
print(f"保存了 {len(conversations)} 条对话")
print(f"示例:\n用户: {conversations[0][0][:50]}...\n助手: {conversations[0][1][:50]}...")
return df
# 使用示例
if __name__ == "__main__":
preprocessor = ChatPreprocessor(
data_path="./data/raw",
output_path="./data/processed"
)
# 加载你的聊天记录
messages = preprocessor.load_wechat("./data/raw/chat.txt")
# 构建对话(替换成你和对方的名称)
conversations = preprocessor.build_conversations(
messages,
your_name="你的昵称",
their_name="对方的昵称"
)
# 保存训练数据
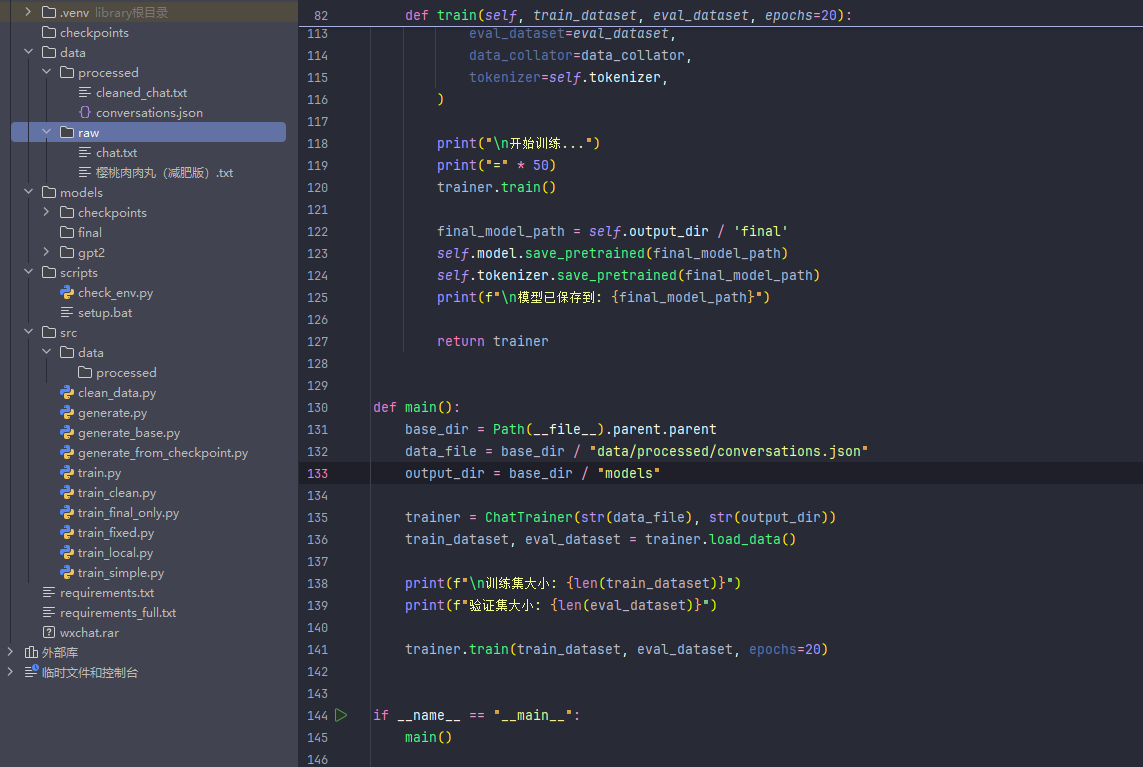
preprocessor.save_training_data(conversations)步骤 3:模型训练脚本
创建 src/train.py:
python
#!/usr/bin/env python3
"""
GPT-2 微调训练脚本
基于你们的聊天记录训练一个对话模型
"""
import json
import torch
from pathlib import Path
from transformers import (
GPT2LMHeadModel,
GPT2Tokenizer,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from datasets import Dataset
import os
class ChatTrainer:
def __init__(self, data_path: str, output_dir: str = "./models"):
self.data_path = Path(data_path)
self.output_dir = Path(output_dir)
self.output_dir.mkdir(parents=True, exist_ok=True)
# 检测设备
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {self.device}")
# 加载模型和分词器
print("加载 GPT-2 模型...")
self.model_name = "gpt2" # 使用 GPT-2 small (124M 参数)
self.tokenizer = GPT2Tokenizer.from_pretrained(self.model_name)
self.model = GPT2LMHeadModel.from_pretrained(self.model_name)
# 添加特殊 token
self.tokenizer.pad_token = self.tokenizer.eos_token
self.tokenizer.add_special_tokens({
'additional_special_tokens': ['<|user|>', '<|assistant|>']
})
self.model.resize_token_embeddings(len(self.tokenizer))
print(f"模型参数量: {self.model.num_parameters():,}")
def load_data(self):
"""加载并处理数据"""
print(f"加载数据: {self.data_path}")
with open(self.data_path, 'r', encoding='utf-8') as f:
conversations = json.load(f)
print(f"共 {len(conversations)} 条对话")
# 构建训练文本
texts = []
for user_msg, assistant_msg in conversations:
# 格式: <|user|>用户消息<|assistant|>助手消息<|endoftext|>
text = f"<|user|>{user_msg}<|assistant|>{assistant_msg}<|endoftext|>"
texts.append(text)
# Tokenize
def tokenize_function(examples):
return self.tokenizer(
examples['text'],
truncation=True,
padding='max_length',
max_length=256,
return_tensors='pt'
)
# 创建 Dataset
dataset = Dataset.from_dict({'text': texts})
tokenized_dataset = dataset.map(
tokenize_function,
batched=True,
remove_columns=['text']
)
# 分割训练集和验证集 (90% 训练, 10% 验证)
split_dataset = tokenized_dataset.train_test_split(test_size=0.1, seed=42)
return split_dataset['train'], split_dataset['test']
def train(self, train_dataset, eval_dataset, epochs=20):
"""开始训练"""
# 数据整理器
data_collator = DataCollatorForLanguageModeling(
tokenizer=self.tokenizer,
mlm=False, # GPT-2 是因果语言模型,不使用 MLM
)
# 训练参数
training_args = TrainingArguments(
output_dir=str(self.output_dir / 'checkpoints'),
overwrite_output_dir=True,
num_train_epochs=epochs,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
gradient_accumulation_steps=2,
warmup_steps=100,
logging_steps=50,
eval_steps=200,
save_steps=500,
eval_strategy="steps",
save_total_limit=3,
learning_rate=5e-5,
weight_decay=0.01,
fp16=False, # CPU 训练不支持 fp16
report_to='none', # 不向 wandb 报告
logging_dir=str(self.output_dir / 'logs'),
load_best_model_at_end=True,
metric_for_best_model="eval_loss",
greater_is_better=False,
)
# 创建 Trainer
trainer = Trainer(
model=self.model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=data_collator,
tokenizer=self.tokenizer,
)
# 开始训练
print("\n开始训练...")
print("=" * 50)
trainer.train()
# 保存最终模型
final_model_path = self.output_dir / 'final'
self.model.save_pretrained(final_model_path)
self.tokenizer.save_pretrained(final_model_path)
print(f"\n模型已保存到: {final_model_path}")
# 保存训练配置
config = {
'model_name': self.model_name,
'vocab_size': len(self.tokenizer),
'max_length': 256,
'num_conversations': len(train_dataset) + len(eval_dataset),
}
with open(self.output_dir / 'config.json', 'w', encoding='utf-8') as f:
json.dump(config, f, ensure_ascii=False, indent=2)
return trainer
def main():
# 配置路径
base_dir = r"C:\Users\Documents\Zlin\wxchat"
data_file = os.path.join(base_dir, "data/processed/conversations.json")
output_dir = os.path.join(base_dir, "models")
# 创建训练器
trainer = ChatTrainer(data_file, output_dir)
# 加载数据
train_dataset, eval_dataset = trainer.load_data()
print(f"\n训练集大小: {len(train_dataset)}")
print(f"验证集大小: {len(eval_dataset)}")
# 开始训练
trainer.train(train_dataset, eval_dataset, epochs=20)
if __name__ == "__main__":
main()步骤 4:命令行交互脚本
创建 src/generate.py:
python
# !/usr/bin/env python3
"""
对话测试脚本
加载训练好的模型并进行对话
"""
import torch
import os
from pathlib import Path
from transformers import GPT2LMHeadModel, GPT2Tokenizer
class ChatBot:
def __init__(self, model_path: str = "./models/final"):
self.model_path = Path(model_path)
# 检测设备
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {self.device}")
# 加载模型和分词器
print(f"加载模型: {self.model_path}")
self.tokenizer = GPT2Tokenizer.from_pretrained(str(self.model_path))
self.model = GPT2LMHeadModel.from_pretrained(str(self.model_path))
self.model.to(self.device)
self.model.eval()
print("模型加载完成!")
print(f"词汇表大小: {len(self.tokenizer)}")
def generate_response(self, user_input: str, max_length: int = 100, temperature: float = 0.8):
"""生成回复"""
# 格式化输入
prompt = f"<|user|>{user_input}<|assistant|>"
# Tokenize
inputs = self.tokenizer(prompt, return_tensors="pt").to(self.device)
# 生成回复
with torch.no_grad():
outputs = self.model.generate(
inputs["input_ids"],
max_new_tokens=max_length,
temperature=temperature,
do_sample=True,
top_k=50,
top_p=0.95,
pad_token_id=self.tokenizer.eos_token_id,
repetition_penalty=1.1,
)
# 解码回复
full_response = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
# 提取助手部分
if "<|assistant|>" in full_response:
response = full_response.split("<|assistant|>")[-1].strip()
else:
response = full_response[len(prompt):].strip()
# 清理回复
response = response.split("<|endoftext|>")[0].strip()
return response if response else "嗯..."
def chat(self):
"""交互式对话"""
print("\n" + "=" * 50)
print("对话模型已启动!")
print("输入 'quit' 或 'exit' 退出")
print("输入 '--temp 0.8' 调整温度(0.5-1.2)")
print("=" * 50 + "\n")
temperature = 0.8
while True:
try:
user_input = input("你: ").strip()
if not user_input:
continue
if user_input.lower() in ["quit", "exit"]:
print("再见!")
break
if user_input.startswith("--temp"):
try:
temperature = float(user_input.split()[1])
print(f"温度已调整为: {temperature}")
continue
except:
print("温度格式错误,使用 --temp 0.8")
continue
# 生成回复
response = self.generate_response(user_input, temperature=temperature)
print(f"TA: {response}")
except KeyboardInterrupt:
print("\n再见!")
break
except Exception as e:
print(f"错误: {e}")
def main():
base_dir = Path(__file__).parent.parent
model_path = base_dir / "models" / "final"
# 检查模型是否存在
if not model_path.exists():
print(f"错误: 模型不存在于 {model_path}")
print("请先完成训练")
return
# 启动聊天
bot = ChatBot(str(model_path))
bot.chat()
if __name__ == "__main__":
main()gup实现训练
python
#!/usr/bin/env python3
"""
GPU 优化训练脚本
自动检测并使用显卡,支持混合精度训练
"""
import json
import torch
import shutil
from pathlib import Path
from transformers import (
GPT2LMHeadModel,
GPT2Tokenizer,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from datasets import Dataset
class ChatTrainer:
def __init__(self, data_path: str, output_dir: str = "./models"):
self.data_path = Path(data_path)
self.output_dir = Path(output_dir)
self.output_dir.mkdir(parents=True, exist_ok=True)
# 检测 GPU
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.has_gpu = torch.cuda.is_available()
print(f"使用设备: {self.device}")
if self.has_gpu:
print(f"显卡: {torch.cuda.get_device_name(0)}")
print(f"显存: {torch.cuda.get_device_properties(0).total_memory / 1e9:.1f} GB")
# 加载本地模型
base_dir = Path(__file__).parent.parent
model_path = base_dir / "models" / "gpt2"
print(f"加载本地模型: {model_path}")
self.tokenizer = GPT2Tokenizer.from_pretrained(str(model_path))
self.model = GPT2LMHeadModel.from_pretrained(str(model_path))
# 添加特殊 token
self.tokenizer.pad_token = self.tokenizer.eos_token
self.tokenizer.add_special_tokens({
'additional_special_tokens': ['<|user|>', '<|assistant|>']
})
self.model.resize_token_embeddings(len(self.tokenizer))
# 如果有 GPU,将模型移到 GPU
if self.has_gpu:
self.model = self.model.to(self.device)
print(f"模型参数量: {self.model.num_parameters():,}")
# 根据显存调整 batch size
if self.has_gpu:
mem_gb = torch.cuda.get_device_properties(0).total_memory / 1e9
if mem_gb >= 24: # RTX 4090, A100
self.batch_size = 16
self.grad_accum = 2
elif mem_gb >= 12: # RTX 3060, 3080
self.batch_size = 8
self.grad_accum = 2
elif mem_gb >= 8: # GTX 1070, 1660
self.batch_size = 4
self.grad_accum = 4
else: # 小显存
self.batch_size = 2
self.grad_accum = 8
else:
self.batch_size = 4
self.grad_accum = 4
print(f"Batch size: {self.batch_size}")
print(f"Gradient accumulation: {self.grad_accum}")
def load_data(self):
print(f"加载数据: {self.data_path}")
with open(self.data_path, 'r', encoding='utf-8') as f:
conversations = json.load(f)
print(f"共 {len(conversations)} 条对话")
texts = []
for user_msg, assistant_msg in conversations:
text = f"<|user|>{user_msg}<|assistant|>{assistant_msg}<|endoftext|>"
texts.append(text)
def tokenize_function(examples):
return self.tokenizer(
examples['text'],
truncation=True,
padding='max_length',
max_length=128,
return_tensors='pt'
)
dataset = Dataset.from_dict({'text': texts})
tokenized_dataset = dataset.map(
tokenize_function,
batched=True,
remove_columns=['text']
)
split_dataset = tokenized_dataset.train_test_split(test_size=0.1, seed=42)
return split_dataset['train'], split_dataset['test']
def train(self, train_dataset, eval_dataset, epochs=20):
data_collator = DataCollatorForLanguageModeling(
tokenizer=self.tokenizer,
mlm=False,
)
training_args = TrainingArguments(
output_dir=str(self.output_dir / 'temp'),
overwrite_output_dir=True,
num_train_epochs=epochs,
per_device_train_batch_size=self.batch_size,
per_device_eval_batch_size=self.batch_size,
gradient_accumulation_steps=self.grad_accum,
warmup_steps=100,
logging_steps=50,
evaluation_strategy="steps",
eval_steps=200,
save_strategy="no",
learning_rate=5e-5,
weight_decay=0.01,
fp16=self.has_gpu, # GPU 时开启混合精度加速
report_to='none',
)
trainer = Trainer(
model=self.model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=data_collator,
tokenizer=self.tokenizer,
)
print("\n" + "=" * 60)
print("开始训练...")
print("=" * 60)
if self.has_gpu:
print(f"使用 GPU 加速训练,预计 10-30 分钟")
else:
print(f"使用 CPU 训练,预计 2-3 小时")
print()
trainer.train()
final_model_path = self.output_dir / 'final'
self.model.save_pretrained(final_model_path)
self.tokenizer.save_pretrained(final_model_path)
temp_dir = self.output_dir / 'temp'
if temp_dir.exists():
shutil.rmtree(temp_dir)
print(f"\n 模型已保存到: {final_model_path}")
return trainer
def main():
base_dir = Path(__file__).parent.parent
data_file = base_dir / "data/processed/conversations.json"
output_dir = base_dir / "models"
trainer = ChatTrainer(str(data_file), str(output_dir))
train_dataset, eval_dataset = trainer.load_data()
print(f"\n训练集大小: {len(train_dataset)}")
print(f"验证集大小: {len(eval_dataset)}")
trainer.train(train_dataset, eval_dataset, epochs=20)
if __name__ == "__main__":
main()步骤 5:运行脚本
创建一个主运行脚本 run.sh:
bash
#!/bin/bash
echo "=== 聊天AI训练系统 ==="
# 激活虚拟环境
source venv/bin/activate
# 检查数据是否存在
if [ ! -f "./data/raw/chat.txt" ]; then
echo "请将聊天记录放到 ./data/raw/chat.txt"
exit 1
fi
# 数据预处理
echo "步骤1: 预处理数据..."
python src/preprocess.py
# 训练模型
echo "步骤2: 训练模型(这可能需要几个小时)..."
read -p "是否开始训练?(y/n) " -n 1 -r
echo
if [[ $REPLY =~ ^[Yy]$ ]]; then
python src/train.py
fi
# 启动交互界面
echo "步骤3: 启动对话..."
python src/generate.py四、使用流程
-
准备数据 :将聊天记录导出为
./data/raw/chat.txt -
运行预处理:
bash
python src/preprocess.py- 开始训练:
bash
python src/train.py训练时间取决于数据量,几百条对话可能需要 1-2 小时
- 测试模型:
bash
python src/generate.py五、预期效果与限制
能达到的效果
- 学习对方的用词习惯和说话风格
- 能生成符合对话上下文的回复
- 记住一些特定的表达方式
局限性
- 模型较小,无法处理复杂推理
- 可能产生重复或不合逻辑的内容
- 只能基于训练数据中的模式进行回复
六、具体实现
1.数据准备:使用weflow实现微信聊天记录导出;
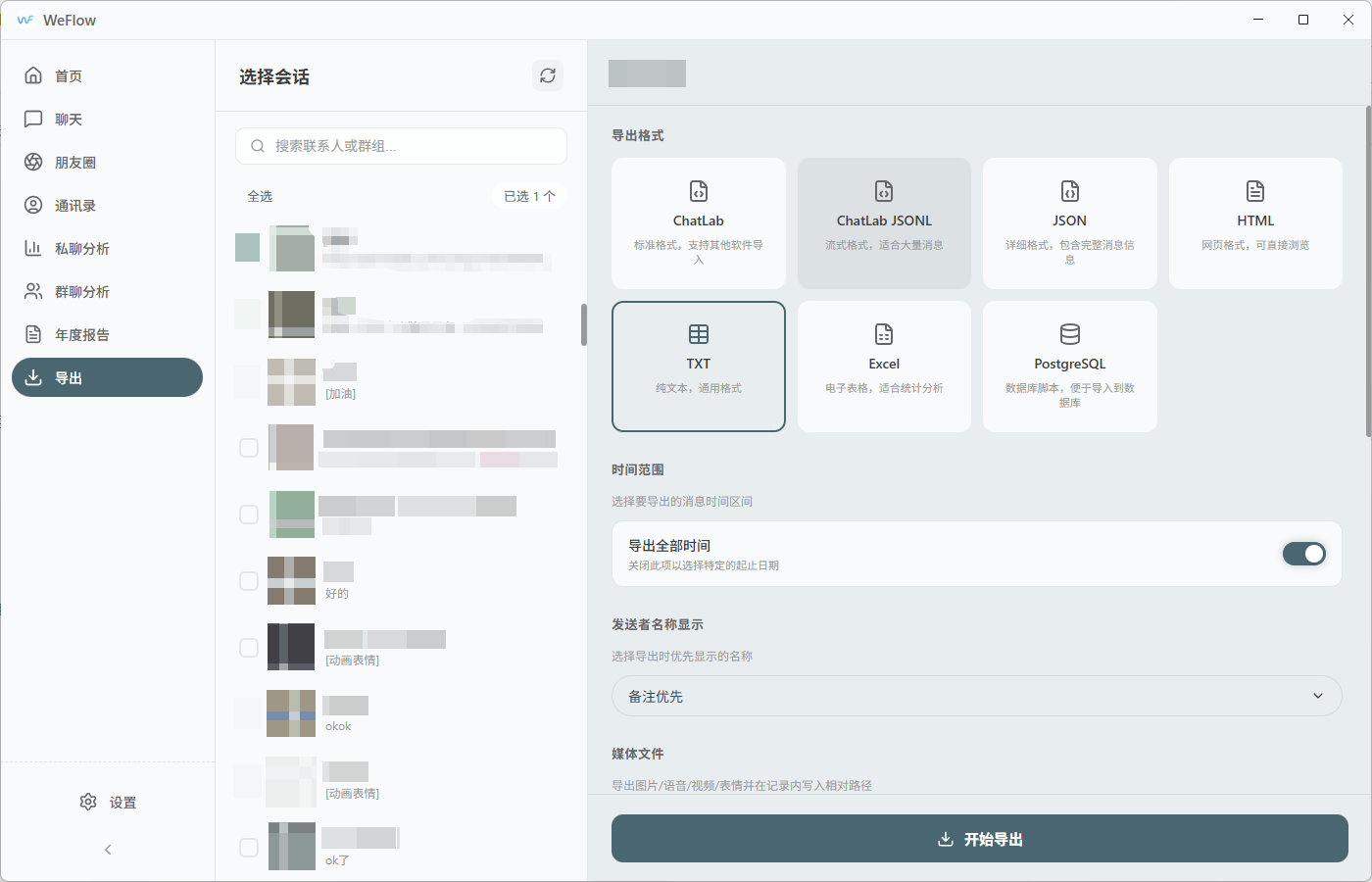
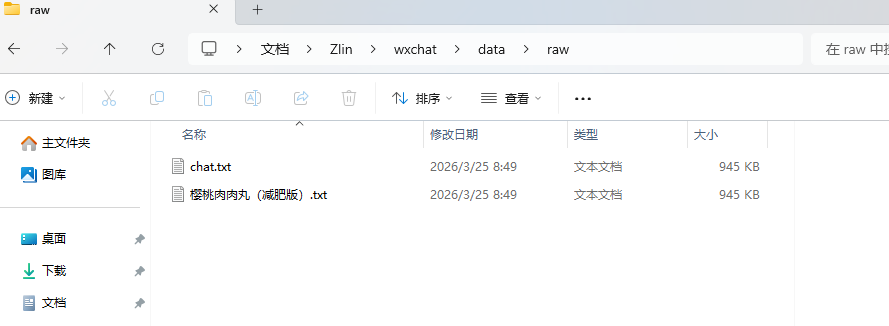
数据存放到data下的raw中,然后清洗数据
2.下载底模
source .venv/Scripts/activate
python --version
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
python -c "from modelscope.hub.snapshot_download import snapshot_download; snapshot_download('AI-ModelScope/gpt2', cache_dir='./models/gpt2', revision='master')"
ls -la models/gpt2/
ls -la models/gpt2/AI-ModelScope/gpt2/
mv models/gpt2/AI-ModelScope/gpt2/* models/gpt2/
rm -rf models/gpt2/AI-ModelScope models/gpt2/._____temp models/gpt2/.lock
ls -lh models/gpt2/ | grep -E "(pytorch_model|config|merges|vocab|tokenizer)"
3.一键训练
运行train.py(根据自己合适来选择)
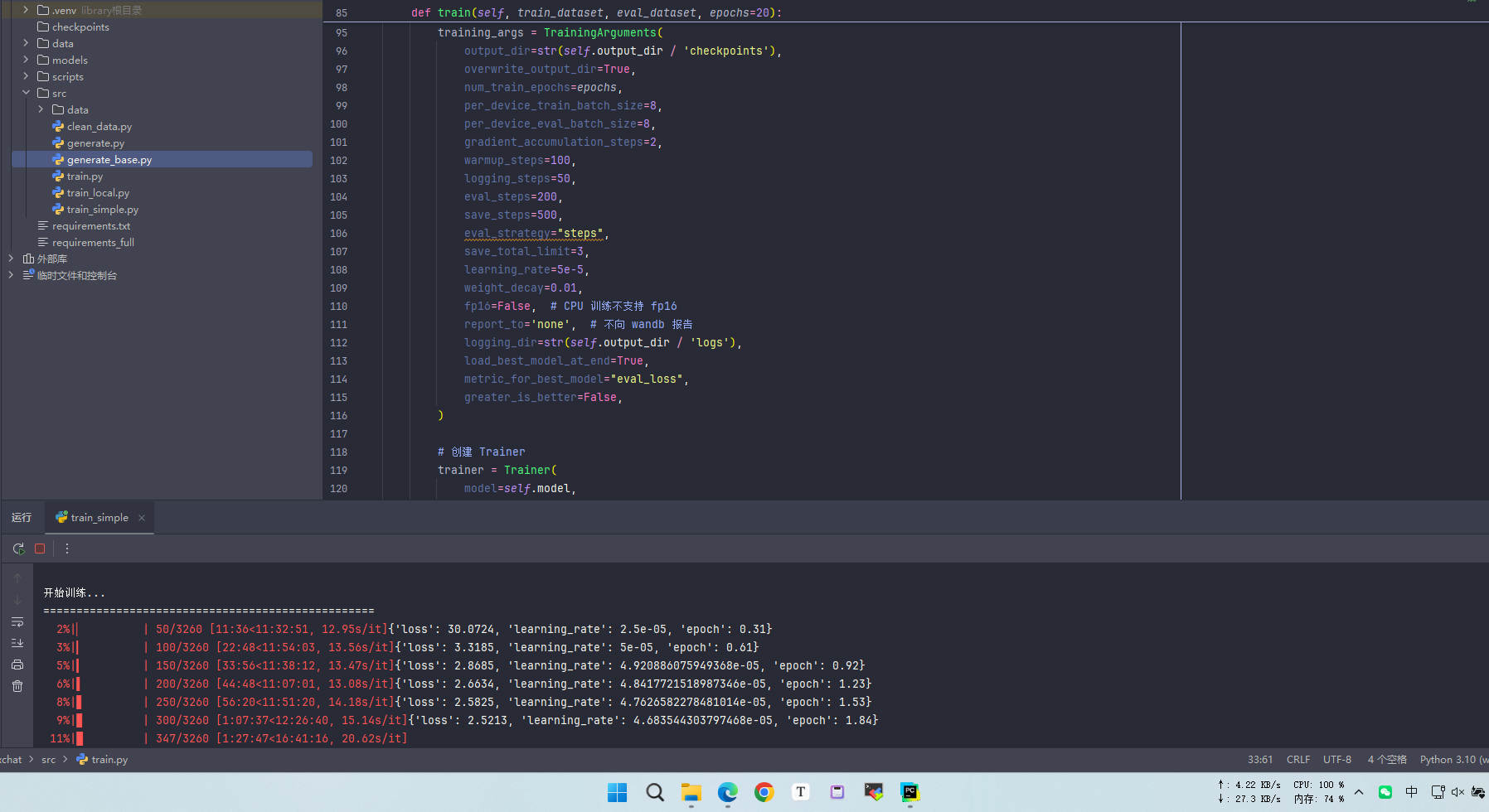
好吧,只是1200轮,3次ep,一样是胡言乱语
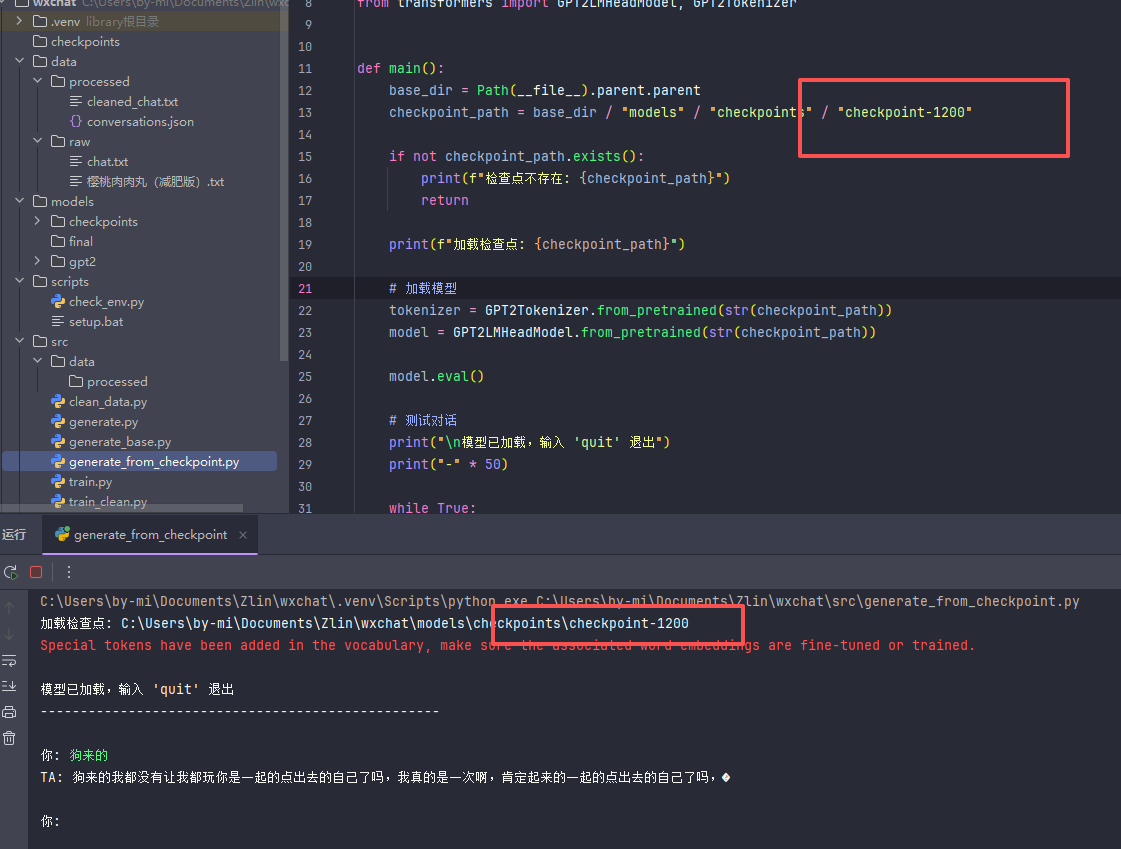
笑死我了,估计我这个朋友还不知道自己跟我的聊天记录被我用来测试了吧;
行吧,有空再给你完善了,让你是赛博飞升,为他我还专门开了ds的key密钥来测试一下;