本文对应项目版本:
v0.0.5
在前一个版本里,我已经把项目的基础聊天链路搭起来了:
- 服务端使用
LangChain.js + Ollama - 前端使用自定义
useChatStream - 内容渲染采用
Markdown + typed parts + Streamdown - 输入和协议校验使用
Zod
到这一步,项目虽然已经具备了"本地大模型对话 + 流式输出 + 多轮上下文"的基础能力,但它本质上还是一个纯文本问答系统。
v0.0.5 我想解决的问题,不是"再接一个功能",而是让系统第一次具备调用外部能力的能力。
为了控制复杂度,这一版我只给自己定了一个目标:
先接一个最小 Tool,跑通完整 Tool Calling 链路,同时保留后续自然扩展的空间。
当前版本只接入了一个工具:
calculator
但这一版真正要验证的,不是"计算器能不能算题",而是下面这些工程问题:
- 模型怎么决定要不要调用工具?
- 工具参数怎么校验?
- 工具结果怎么回填给模型?
- 前端怎么把推理、工具调用、最终答案区分开来展示?
- 如果一次流式渲染异常,会不会影响下一次对话?
这些问题,才是 Tool Calling 从 Demo 走向工程实现时真正需要面对的部分。
项目效果
聊天主界面截图
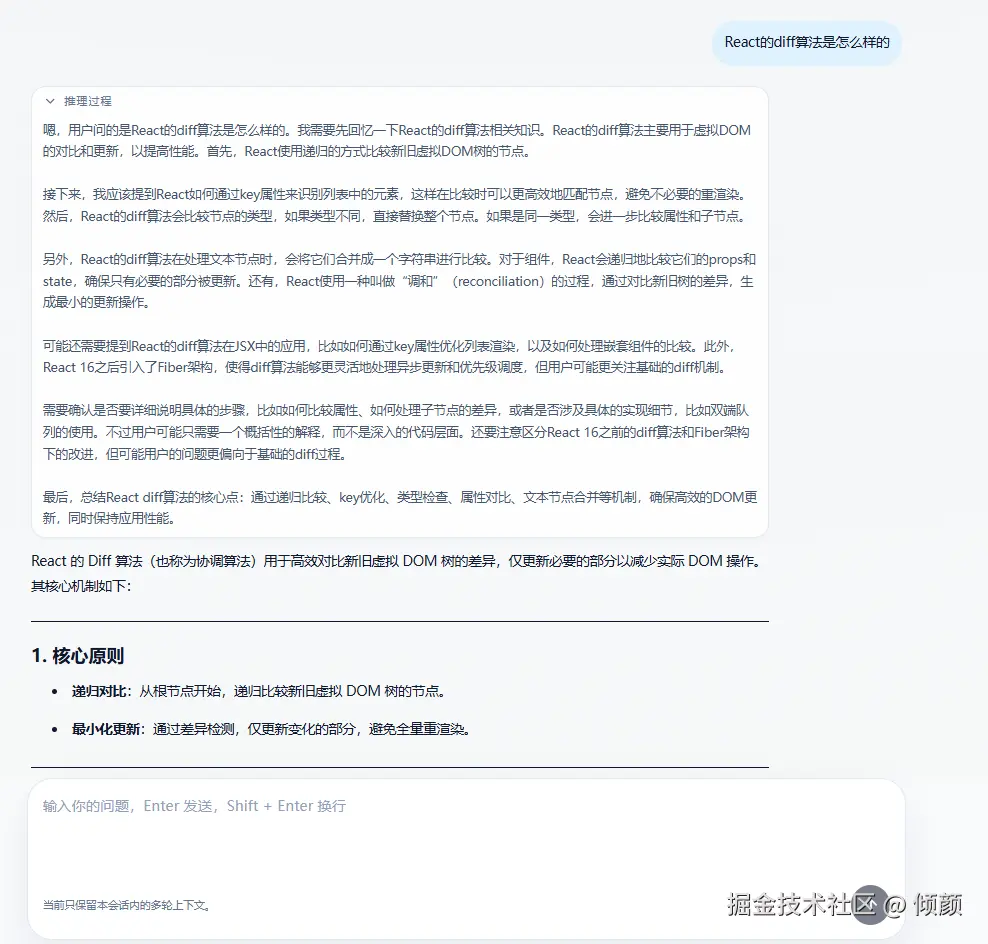
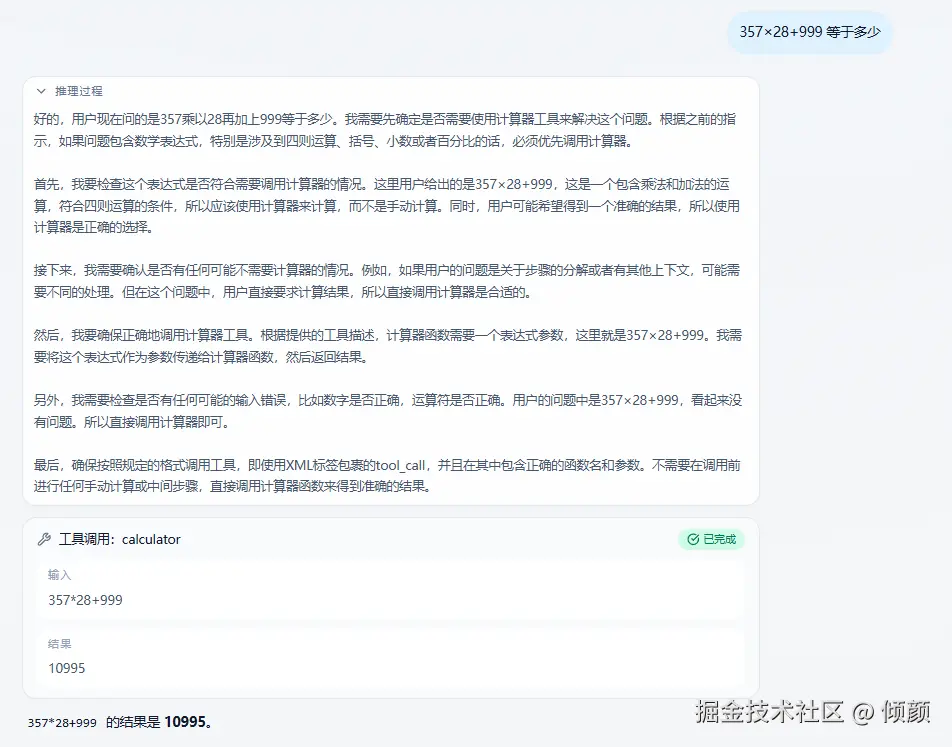
推理过程 + tool part工具调用成功 + 最终答案完整展示图
这版到底想做什么
先说清楚 v0.0.5 的边界。
这版不是:
- 多工具 Agent
- 工具编排平台
- LangGraph 工作流
- 长期记忆系统
这版只做一件事:
用一个最小 Tool Calling 实践,验证当前聊天系统能不能从"只会回答"升级成"会调用能力、会返回结构化结果、还能保持工程可扩展"。
所以这一版的设计原则非常明确:
- 最小可实现
- 可扩展
- 不推翻前一版架构
- 不引入新的重型框架
总体架构
这一版的整体链路如下:
text
用户输入
-> /api/chat
-> LangChain ChatOllama
-> 判断是否返回 tool_calls
-> calculator
-> ToolMessage 回填
-> 最终答案流式返回前端如果把这条链路拆开来看,前后端分别承担的职责其实很清楚。
服务端负责
- 统一模型接入
- 挂载当前可用工具
- 解析模型返回的
tool_calls - 用
Zod校验工具参数 - 执行工具
- 把工具结果回填给模型
- 输出结构化 NDJSON 流
前端负责
- 读取 NDJSON 流
- 按
reasoning / tool / text三类 part 消费事件 - 渲染推理过程、工具调用状态和最终答案
- 在多轮对话里只保留必要上下文
为什么我没有继续把返回内容做成"一段字符串"
如果系统只有普通对话,把响应内容当作一段 Markdown 字符串其实是够用的。
但到了 Tool Calling 场景,这种做法就不够了。
因为一次回答里其实会同时包含三类信息:
- 模型推理内容
- 工具调用过程与工具结果
- 最终回答正文
如果仍然全部塞进一段字符串里,前端就会遇到几个问题:
- 无法单独折叠推理过程
- 无法结构化展示 tool 调用状态
- 无法清晰地区分"工具结果"和"模型最后组织出来的答案"
- 后续增加更多工具时,协议会越来越乱
所以这一版我把 assistant 消息拆成了三类 part:
reasoning parttool parttext part
这样前端拿到的就不再是"文本流",而是一种结构化事件流。
关键代码:消息 part 结构
ts
export interface TextPart extends BasePart {
type: 'text'
text: string
format: 'markdown'
}
export interface ReasoningPart extends BasePart {
type: 'reasoning'
text: string
format: 'markdown'
visibility?: 'collapsed' | 'expanded' | 'hidden'
}
export interface ToolPart extends BasePart {
type: 'tool'
toolName: string
status: 'called' | 'completed' | 'failed'
input: string
output?: string
error?: string
}关键代码:流式 chunk 协议
ts
export interface ToolStartChunk {
type: 'tool-start'
partId: string
toolName: string
input: string
}
export interface ToolEndChunk {
type: 'tool-end'
partId: string
toolName: string
input: string
output: string
}
export type ChatStreamChunk =
| StartChunk
| ReasoningStartChunk
| ReasoningDeltaChunk
| ReasoningEndChunk
| ToolStartChunk
| ToolEndChunk
| ToolErrorChunk
| TextStartChunk
| TextDeltaChunk
| TextEndChunk
| FinishChunk
| ErrorChunk我后来越来越确信一点:
对 Tool Calling 场景来说,最值得先做对的不是 UI,而是消息协议。
因为协议一旦分层清楚,前端展示、错误定位、后续扩展都会轻松很多。
服务端设计:统一模型接入层 + 最小 Tool Calling 闭环
这一版我有一个很明确的取舍:
不把服务端讲成"普通模型一套、工具模型一套"。
更准确的说法应该是:
服务端维护一个统一的大模型接入层,在运行时根据当前可用工具集合决定是否给模型挂载工具能力。
也就是说,本质上仍然是一个基础模型配置,只是运行时会根据 activeTools 决定是否调用 bindTools()。
这样的好处是:
- 架构更干净
- 更符合主流 Tool Calling 的实现方式
- 后续新增工具时,不需要推翻主链路
执行流分成三种情况
1. 当前有可用工具,但当前问题不需要工具
text
user message
-> baseModel.bindTools(activeTools)
-> model response
-> no tool_calls
-> final answer特点:
- 只调用一次模型
- 不会多走一轮
- 即使模型已经绑定工具,也可以直接正常回答
2. 当前有可用工具,且当前问题需要工具
text
user message
-> baseModel.bindTools(activeTools)
-> model response
-> tool_calls
-> Zod 校验
-> execute tool
-> append ToolMessage
-> second model response
-> final answer这就是当前版本的两阶段最小闭环:
- 第一阶段:模型决定是否调用工具
- 第二阶段:工具执行完成后,再生成最终答案
3. 当前没有可用工具
text
user message
-> baseModel
-> final answer这里要特别强调一下:
"当前没有可用工具"属于运行时能力状态,不是对用户问题做内容分类。
关键代码:统一模型接入与主执行链
ts
function createBaseModel(request: ChatRequest, deps: ChatServiceDependencies) {
return new ChatOllama({
model: request.options?.model ?? deps.defaultModel,
baseUrl: deps.baseUrl ?? process.env.OLLAMA_BASE_URL ?? 'http://127.0.0.1:11434',
temperature: request.options?.temperature ?? 0.3,
numPredict: request.options?.maxTokens,
think: request.options?.enableReasoning,
streaming: true,
})
}
const baseModel = createBaseModel(request, deps)
const activeTools = getActiveTools()
const toolBoundModel =
activeTools.length > 0 ? baseModel.bindTools(activeTools.map(toolDefinition => toolDefinition.tool)) : null
if (!toolBoundModel) {
await streamDirectAnswer(baseModel, langChainMessages, context, writeChunk, () => closed)
writeChunk({ type: 'finish' })
return
}这里的关键不是代码有多复杂,而是这个判断边界很清晰:
- 有工具可用时,模型具备 tool calling 能力
- 没有工具可用时,系统仍然可以正常工作
为什么 calculator 仍然值得单独做
很多人会觉得:
"先做一个计算器工具是不是太简单了?"
但从工程角度看,calculator 恰恰很适合做第一版 Tool Calling。
1. 它是确定性工具
输入同一个表达式,输出应该永远一致。
这意味着一旦结果错了,我们更容易判断问题出在:
- 模型没有正确发起 tool call
- tool 参数不合法
- 工具执行失败
- 工具结果回填后,模型又把答案组织错了
2. 它非常适合验证校验链路
tool_calls 不是模型说什么就执行什么。
在真正执行前,我仍然做了这几步:
- 工具存在性检查
- 参数归一化
Zod.safeParse- 执行工具
这套链路虽然不复杂,但正是 Tool Calling 从 Demo 走向工程实现时最关键的一步。
3. 它天然暴露"工具结果正确 ≠ 最终答案一定正确"这个问题
这一点是我这次实现里最值得记录的坑之一。
calculator 明明算出了正确结果,但第二阶段模型仍然可能:
- 重新手算一遍
- 把中间步骤写错
- 输出和工具结果冲突的回答
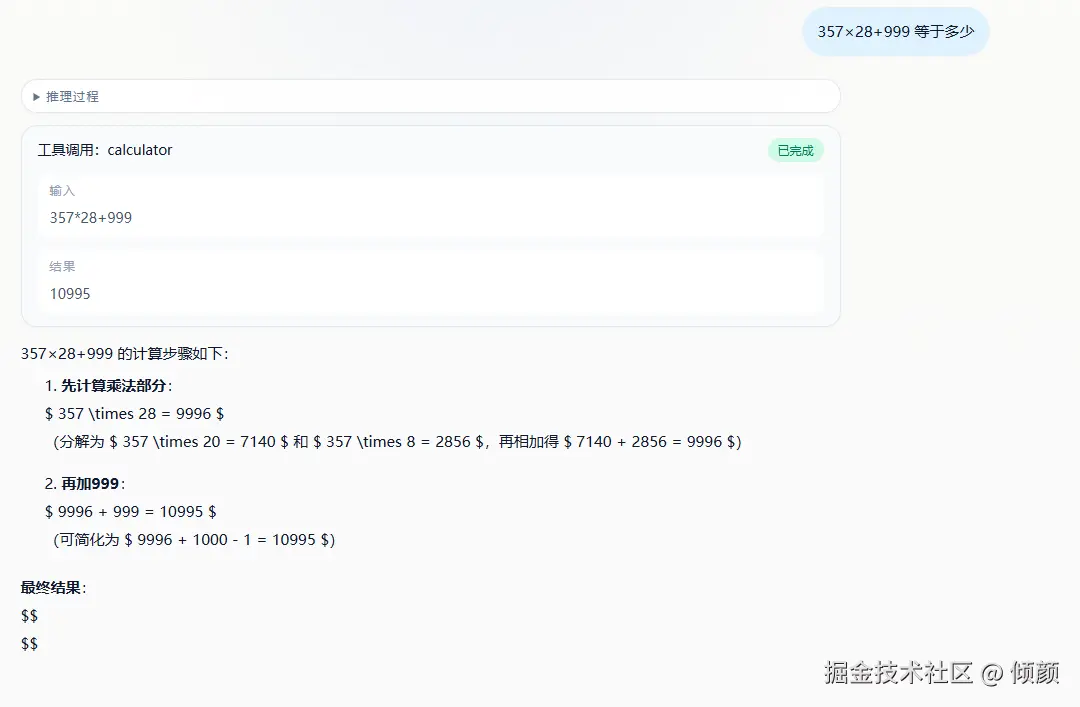
这说明一个很现实的问题:
Tool Calling 的核心难点,不只是"会不会调工具",还包括"调完工具以后,系统如何保证最终答案仍然可信"。
关键代码:calculator 工具定义
ts
export const calculatorToolSchema = z.object({
expression: z.string().min(1).max(200),
})
export function normalizeCalculatorExpression(expression: string): string {
return expression
.trim()
.replaceAll('×', '*')
.replaceAll('÷', '/')
.replaceAll('(', '(')
.replaceAll(')', ')')
.replaceAll(/\s+/g, ' ')
}
export const calculatorTool = tool(
async ({ expression }) => {
const normalizedExpression = normalizeCalculatorExpression(expression)
const result = evaluate(normalizedExpression)
return String(result)
},
{
name: 'calculator',
description: '执行数学表达式计算',
schema: calculatorToolSchema,
}
)关键代码:工具注册入口
ts
const calculatorToolDefinition: ChatToolDefinition = {
name: 'calculator',
tool: calculatorTool,
schema: calculatorToolSchema,
normalizeArgs: normalizeCalculatorToolArgs,
formatInput: formatCalculatorToolInput,
resultIsAuthoritative: true,
}
const chatToolDefinitions = [calculatorToolDefinition]
export function getActiveChatToolDefinitions(): ChatToolDefinition[] {
return chatToolDefinitions.filter(toolDefinition => toolDefinition.isAvailable?.() ?? true)
}虽然当前只有一个工具,但这个注册入口已经把下一版的扩展位留出来了。
Zod 在这一版里不是配角
如果只看功能演示,很多人会把 Zod 当成附属工具。
但在实际实现里,Zod 是这一版稳定性的关键基础设施之一。
1. 请求输入校验
前端每次发送:
conversationIdmessages[]options
都要先经过请求 schema 校验。
2. Tool Call 参数校验
模型产出的 tool_calls 不是可信输入。
如果不做校验,模型只要给出一个奇怪参数,就可能直接把工具执行链路带崩。
这一版的处理方式是:
- 先归一化参数
- 再
safeParse - 通过才执行
- 失败就输出
tool-error
3. 前端流协议校验
前端消费的不是纯文本,而是结构化 NDJSON 事件流。
所以每个 chunk 进入渲染前,也要先经过 schema 校验。
这件事的价值在于:
- 某一次流式异常不会直接污染整个状态树
- 协议一旦有问题,更容易定位在"服务端输出错误"还是"前端消费错误"
关键代码:tool call 显式校验
ts
const normalizedArgs = toolDefinition.normalizeArgs ? toolDefinition.normalizeArgs(toolCall.args) : toolCall.args
const parsedArgs = toolDefinition.schema.safeParse(normalizedArgs)
if (!parsedArgs.success) {
toolErrors.push({
id: toolCall.id,
toolName: toolCall.name,
input: formatToolInput({
...toolCall,
args: normalizedArgs,
}),
message: createToolValidationErrorMessage(toolCall, parsedArgs.error),
})
continue
}
validatedToolCalls.push({
...toolCall,
args: parsedArgs.data,
})我后来越来越觉得:
在 Tool Calling 场景里,模型能力很重要,但真正决定系统稳定性的,往往是"模型之外"的校验与兜底。
前端设计:不是在拼字符串,而是在消费事件流
前端这一版我没有接 AI SDK,而是继续保留自定义 useChatStream。
原因很简单:
这一版的目标是把 Tool Calling 跑通,而不是再引入一层新的聊天抽象。
useChatStream 真正做的事情
它处理的不是一段"完整文本",而是一串结构化事件:
startreasoning-start / reasoning-delta / reasoning-endtool-start / tool-end / tool-errortext-start / text-delta / text-endfinisherror
这意味着前端不再是"把文本不断 append 到一个字符串里",而是在做更细粒度的状态消费。
这带来的直接收益
- 推理过程可以单独折叠
- 工具调用可以单独展示
- 工具结果和最终正文可以自然区分
- 以后接更多工具时,前端协议层不需要推翻重来
关键代码:消费 NDJSON 流
ts
async function consumeNdjsonStream(stream: ReadableStream<Uint8Array>, onChunk: (chunk: ChatStreamChunk) => void) {
const reader = stream.getReader()
const decoder = new TextDecoder()
let buffer = ''
while (true) {
const { done, value } = await reader.read()
if (done) {
break
}
buffer += decoder.decode(value, { stream: true })
const lines = buffer.split('\n')
buffer = lines.pop() ?? ''
for (const line of lines) {
const parsedChunk = chatStreamChunkSchema.safeParse(JSON.parse(line))
if (!parsedChunk.success) {
throw new Error('Invalid chat stream chunk.')
}
onChunk(parsedChunk.data)
}
}
}关键代码:按 chunk 更新消息
ts
case 'tool-start': {
const messageId = activeStreamRef.current.messageId
if (!messageId) return
updateMessages(current => appendPart(current, messageId, createToolPart(chunk.partId, chunk.toolName, chunk.input)))
return
}
case 'text-delta': {
const messageId = activeStreamRef.current.messageId
const textPartId = activeStreamRef.current.textPartId
if (!messageId || textPartId !== chunk.partId) {
return
}
updateMessages(current => appendTextualPartDelta(current, messageId, chunk.partId, 'text', chunk.delta))
return
}这类实现让我很明确地感受到一件事:
一旦前端开始消费结构化事件,聊天 UI 就从"渲染字符串"升级成了"渲染系统状态"。
这版最值得记录的几个坑
如果这篇文章只写最终方案,会显得过于平滑。
但真实开发里,v0.0.5 其实踩了不少坑,我觉得这些坑反而很值得记录。
坑 1:工具结果是对的,模型最终回答却可能是错的
例如 calculator 已经算出了正确结果,但模型在第二阶段生成最终答案时,仍然可能:
- 重复手算
- 口算出错
- 输出与工具结果不一致的内容
后来我在运行时加了一个更明确的策略:
- 对
calculator这类确定性工具,工具结果具有权威性 - 在必要时优先直出工具结果对应的最终答案
也就是说:
模型可以组织语言,但不能推翻确定性工具的结果。
坑 2:普通问答的流式体验"不像真流"
早期我把第一阶段写成了非流式调用,结果带来的体验是:
- 页面先等很久
- 然后一次性吐出一大块内容
这让我意识到:
真正的流式体验,不能靠"先等模型完整返回,再拼装输出"来模拟。
后来第一阶段也切回了真正的流式消费,普通问题的体验才重新正常。
坑 3:前端一次渲染异常,会污染下一轮请求
某次流式异常后,前端残留了一条空的 assistant placeholder。下一次请求时,它又被带回服务端,最终触发了:
messages[].parts为空- 后端 Zod 校验失败
- 直接返回 400
后来我补了两层兜底:
- 发送前清理瞬态脏消息
- 只把有效
text part组装进请求
这才保证"一次异常不会影响下一次对话"。
坑 4:模型绑定了工具,不代表它一定会乖乖用工具
理论上模型已经绑定了 calculator,但实际运行里,它仍然可能:
- 先自己推理
- 输出伪调用文本
- 在 reasoning 里长篇展开错误步骤
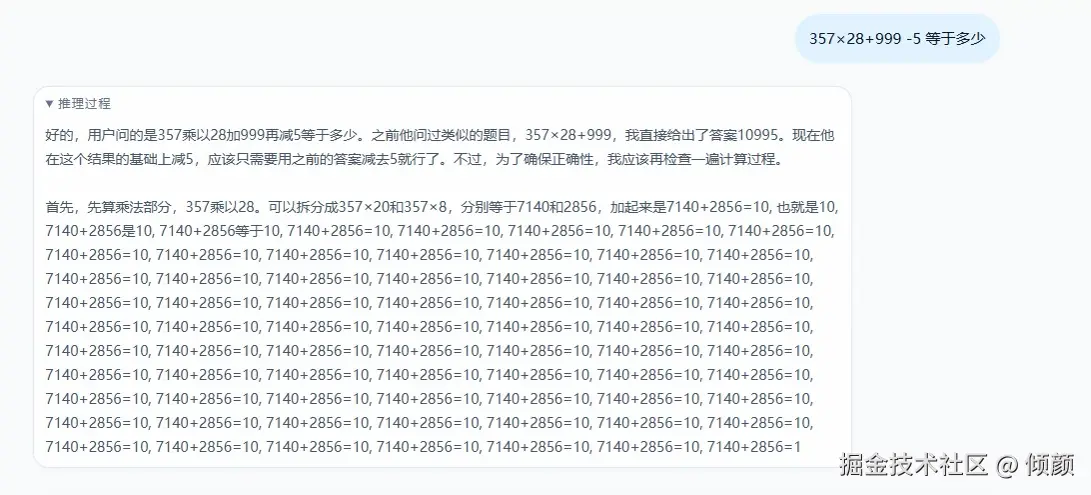
这说明:
Tool Calling 的稳定性,不能只依赖模型自觉。
这也是为什么提示词设计、参数校验、结果策略这些工程细节都很重要。
当前版本已经做到什么程度
到 v0.0.5 为止,项目已经具备了这些能力:
- 支持普通问答
- 支持单工具
calculator - 支持 Tool Calling 可视化
- 支持本地多轮上下文
- 支持
reasoning / tool / text三类结构化展示 - 支持流式错误兜底
但我也明确保留了这些边界:
- 不做多工具调度
- 不做完整 Agent loop
- 不做工具权限系统
- 不做工具管理后台
- 不做长期记忆
这不是因为它们不重要,而是因为这一版的主题非常明确:
先把单工具 Tool Calling 的最小工程闭环做对。
我对 v0.0.5 的总结
如果要用一句话概括这一版,我会这么说:
v0.0.5的重点不是做了一个计算器,而是把当前聊天系统从"只有模型回答"升级成了"模型可以发起 Tool Calls、服务端可以校验并执行工具、前端可以结构化展示结果"的最小闭环。
这一版做完以后,项目其实第一次真正具备了"能力扩展"的基础。
从这个版本往后,再增加新的 Tool,就不再是"重新造一套聊天系统",而是在现有骨架上自然长出新的能力。
下一步可以怎么做
如果继续往后迭代,我比较关心的是三个方向:
- 增加更多 Tool,验证单 Tool 骨架能否自然扩展
- 引入上下文窗口或摘要策略,避免多轮上下文过长
- 继续完善 Tool Result 策略,让确定性工具和非确定性工具的回答方式更清晰
项目地址
GitHub:
[github.com/HWYD/ai-min...](https://link.juejin.cn?target=https%3A%2F%2Fgithub.com%2FHWYD%2Fai-mind%2Freleases%2Ftag%2Fv0.0.5 "https://github.com/HWYD/ai-mind/releases/tag/v0.0.5")
如果这篇文章或这个项目对你有帮助,欢迎点个 Star 支持一下。
后续我也会继续按版本节奏,把这个项目一步步迭代下去。