文章目录
- [1. 二叉树(定义和静态实现)](#1. 二叉树(定义和静态实现))
- [1.1 二叉树的定义](#1.1 二叉树的定义)
- [1.2 特殊的⼆叉树](#1.2 特殊的⼆叉树)
- [1.2.1 满二叉树](#1.2.1 满二叉树)
- [1.2.2 完全⼆叉树](#1.2.2 完全⼆叉树)
- [1.3 ⼆叉树的存储](#1.3 ⼆叉树的存储)
- [1.3.1 顺序存储](#1.3.1 顺序存储)
- [1.3.2 链式存储(静态实现)](#1.3.2 链式存储(静态实现))
- [1.4 ⼆叉树的遍历](#1.4 ⼆叉树的遍历)
- [1.4.1 深度优先遍历](#1.4.1 深度优先遍历)
- [1.4.2 宽度优先遍历](#1.4.2 宽度优先遍历)
- [2. 堆(静态实现)](#2. 堆(静态实现))
- [2.1 定义](#2.1 定义)
- [2.2 堆的存储](#2.2 堆的存储)
- [2.3.1 向上调整算法](#2.3.1 向上调整算法)
- [2.3.2 向下调整建堆](#2.3.2 向下调整建堆)
- [2.3 堆的静态模拟实现](#2.3 堆的静态模拟实现)
- [2.3.1 创建](#2.3.1 创建)
- [2.3.2 插⼊](#2.3.2 插⼊)
- [2.3.3 删除栈顶元素](#2.3.3 删除栈顶元素)
- [2.3.4 堆顶元素](#2.3.4 堆顶元素)
- [2.3.5 堆的⼤⼩](#2.3.5 堆的⼤⼩)
- [3. 哈希表(静态实现)](#3. 哈希表(静态实现))
- [3.1 哈希表的概念](#3.1 哈希表的概念)
- [3.1.1 哈希表的定义](#3.1.1 哈希表的定义)
- [3.1.2 哈希函数](#3.1.2 哈希函数)
- [3.1.3 哈希冲突](#3.1.3 哈希冲突)
- [3.2 常⻅的哈希函数](#3.2 常⻅的哈希函数)
- [3.2.1 直接定址法](#3.2.1 直接定址法)
- [3.2.2 除留余数法](#3.2.2 除留余数法)
- [3.3 处理哈希冲突](#3.3 处理哈希冲突)
- [3.3.1 线性探测法](#3.3.1 线性探测法)
- [3.3.2 链地址法](#3.3.2 链地址法)
- [3.4 哈希表的模拟实现( 线性探测法)](#3.4 哈希表的模拟实现( 线性探测法))
- [3.4.1 创建](#3.4.1 创建)
- [3.4.2 哈希函数以及处理哈希冲突](#3.4.2 哈希函数以及处理哈希冲突)
- [3.4.3 添加元素](#3.4.3 添加元素)
- [3.4.4 查找元素](#3.4.4 查找元素)
- [3.5 哈希表的模拟实现(链地址法)](#3.5 哈希表的模拟实现(链地址法))
- [3.5.1 创建](#3.5.1 创建)
- [3.5.2 哈希函数](#3.5.2 哈希函数)
- [3.5.3 查找元素](#3.5.3 查找元素)
- [3.5.4 添加元素以及处理哈希冲突](#3.5.4 添加元素以及处理哈希冲突)
- 4.AVL树、红黑树
1. 二叉树(定义和静态实现)
1.1 二叉树的定义
二叉树是一种特殊的树型结构,它的特点是每个结点至多只有 2 棵子树(即二叉树中不存在度大于 2 的结点),并且二叉树的子树有左右之分,其次序不能任意颠倒。
二叉的意思是这种树的每一个结点最多只有两个孩子结点。注意这里是最多有两个孩子,也可能没有孩子或者是只有一个孩子。
注意:二叉树结点的两个孩子,一个被称为左孩子,一个被称为右孩子。其顺序是固定的,就像人的左手和右手,不能颠倒混淆。
1.2 特殊的⼆叉树
1.2.1 满二叉树
⼀棵⼆叉树的所有⾮叶⼦节点都存在左右孩⼦并且所有叶⼦节点都在同⼀层上,那么这棵树就称为满⼆叉树。
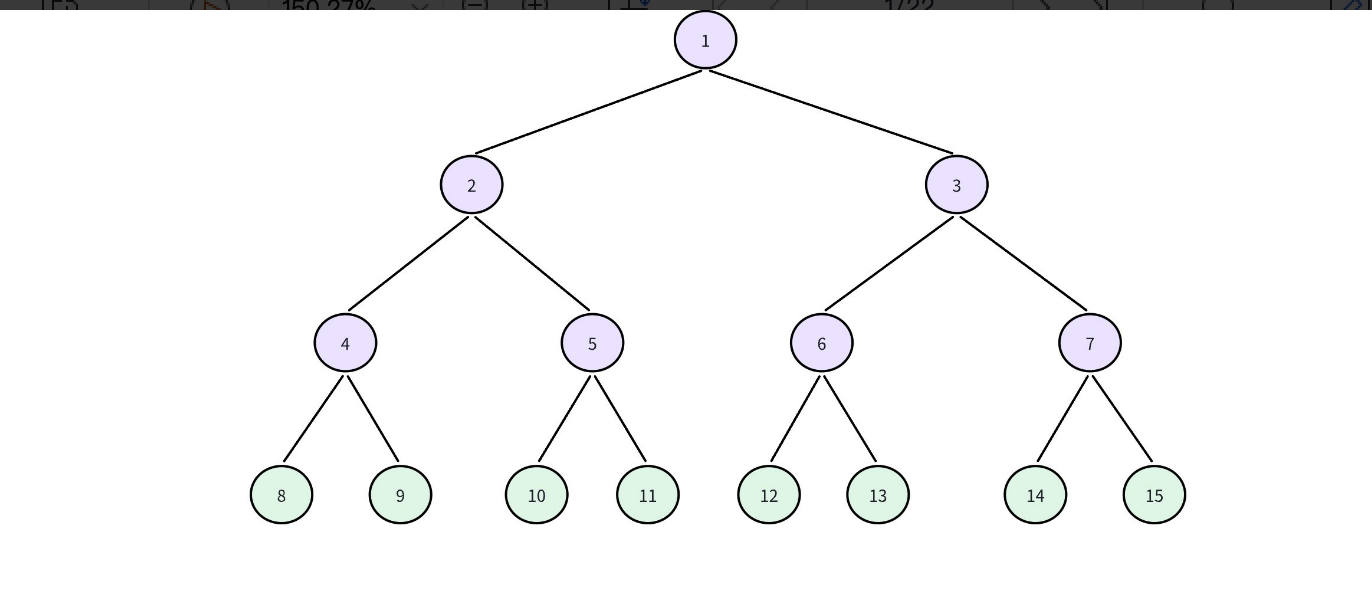
1.2.2 完全⼆叉树
对一棵树有 n 个结点的二叉树按层序编号,所有的结点的编号从 1~n。如果这棵树所有结点和同样深度的满二叉树的编号为从 1~n 的结点位置相同,则这棵二叉树为完全二叉树。
说白了,就是在满二叉树的基础上,在最后一层的叶子结点上,从右往左依次删除若干个结点,剩下的就是一棵完全二叉树。
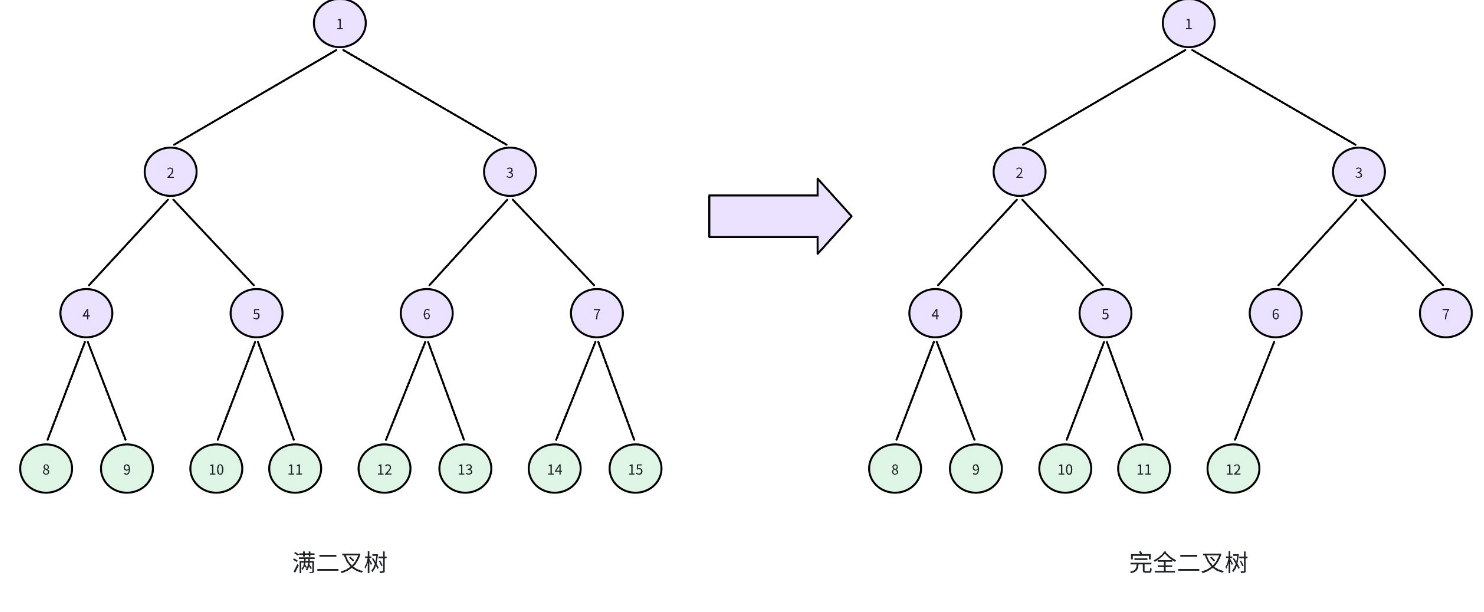
1.3 ⼆叉树的存储
在《树》的章节中,已经学过树的存储,二叉树也是树,也是可以用vector数组或者链式前向星来存储。仅需在存储的过程中标记谁是左孩子,谁是右孩子即可。
- 比如用 vector 数组存储时,可以先尾插左孩子,再尾插右孩子;
- 用链式前向星存储时,可以先头插左孩子,再头插右孩子。只不过这样存储下来,遍历孩子的时候先遇到的是右孩子,这点需要注意。
但是,由于二叉树结构的特殊性,我们除了用上述两种方式来存储,还可以用符合二叉树结构特性的方式:分别是顺序存储和链式存储。
1.3.1 顺序存储
顺序结构存储就是使用数组来存储。
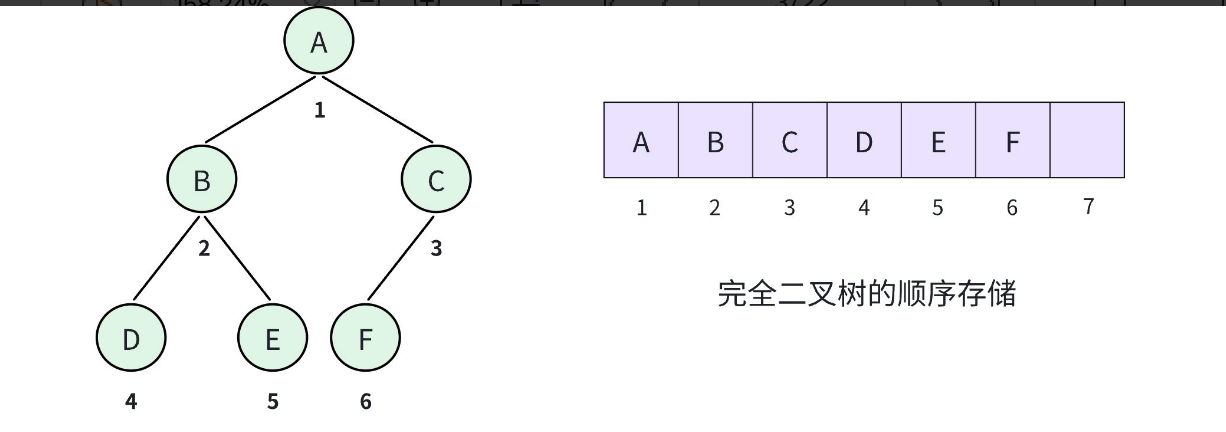
在完全二叉树以及满二叉树的性质那里,我们了解到:如果从根节点出发,按照层序遍历的顺序,由 1 开始编号,那么父子之间的编号是可以计算出来的。那么在存储完全二叉树的时候,就按照编号,依次放在数组对应下标的位置上,然后通过计算找到左右孩子和父亲:
结点下标为 (i):
- 如果父存在,父下标为 (i/2);
- 如果左孩子存在,左孩子下标为 (i \times 2);
- 如果右孩子存在,右孩子下标为 (i \times 2 + 1)。
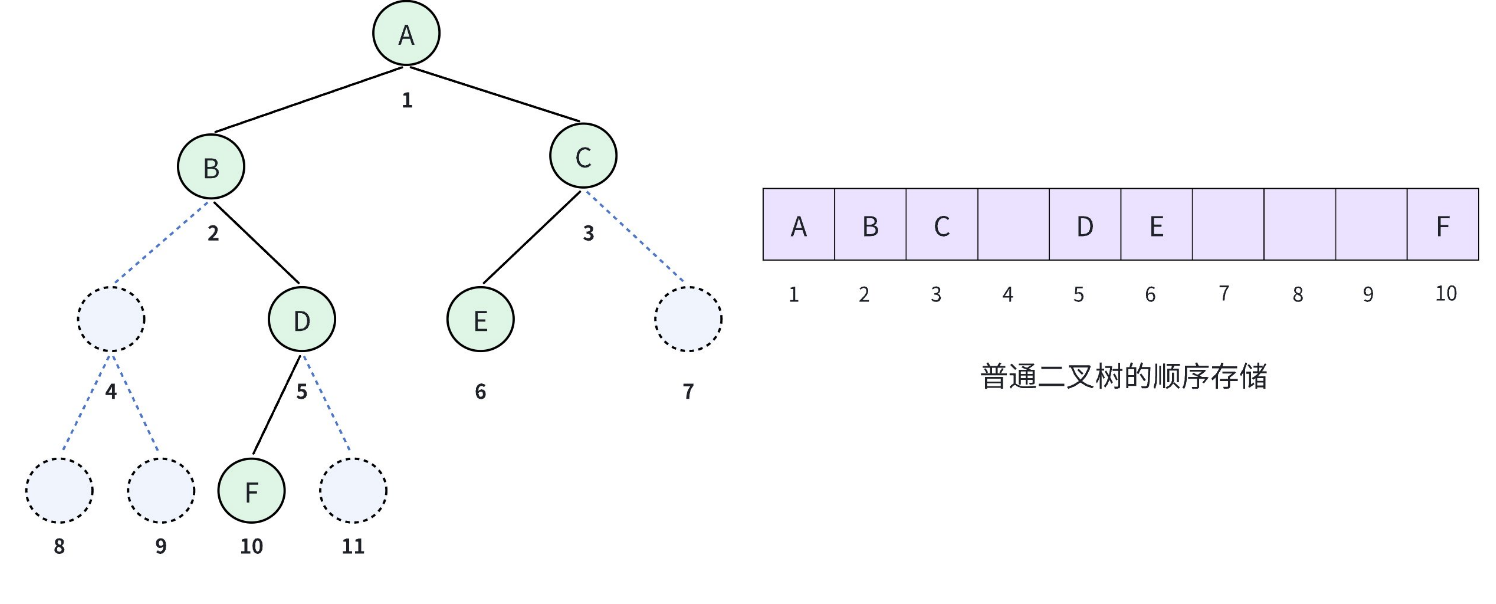
如果不是完全⼆叉树,也是可以⽤顺序存储。但是⾸先要先把这棵⼆叉树补成完全⼆叉树,然后再去
编号。不然就⽆法通过计算找到左右孩⼦和⽗亲的编号。
可以看到我们的二叉树其实只有 6 个节点,但是顺序存储却要分配 10 个空间,其中有 4 个空间都被浪费掉了。
如下图我们考虑一种极端的情况,一棵树右斜树,它只有 4 个节点,但是需要分配 (2^4 - 1) 个存储单元,这显然会对存储空间造成很大的浪费。所以,顺序存储结构一般只用于完全二叉树或满二叉树。
除非是完全二叉树,不然推荐以链式存储优先、
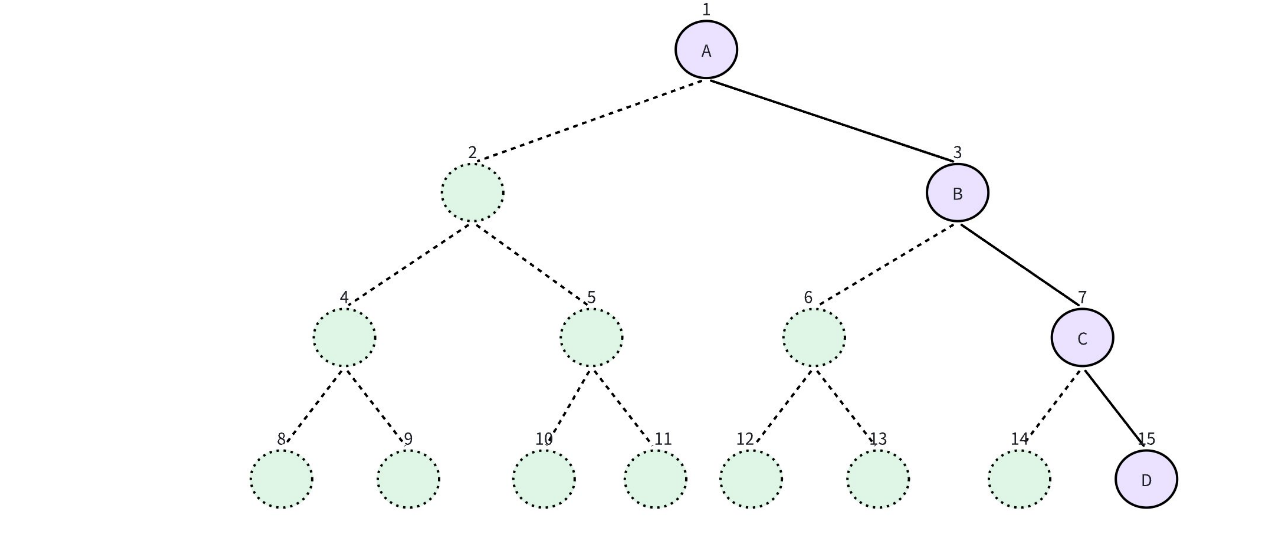
1.3.2 链式存储(静态实现)
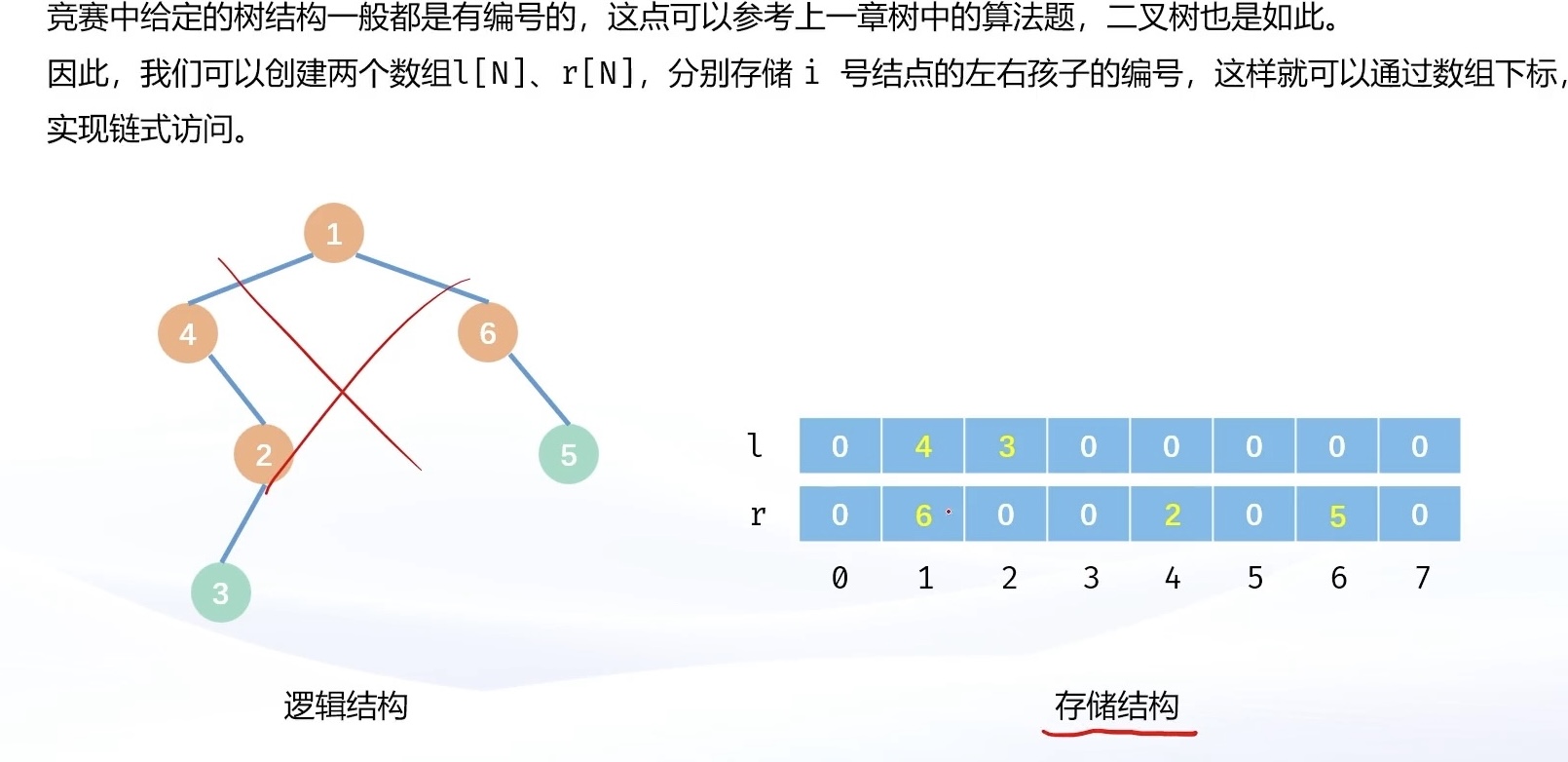
竞赛中给定的树结构一般都是有编号的,参考上一章的树结构。因此我们可以创建两个数组 l[N],r[N],其中 l[i] 表示结点号为 i 的结点的左孩子编号,r[i] 表示结点号为 i 的结点的右孩子编号。这样就可以把二叉树存储起来。
cpp
#include <iostream>
using namespace std;
const int N = 1e6 + 10;
int n;
int l[N], r[N];
int main()
{
cin >> n;
for(int i = 1; i <= n; i++)
{
// 存下 i 号结点的左右孩⼦
cin >> l[i] >> r[i];
}
return 0;
}1.4 ⼆叉树的遍历
1.4.1 深度优先遍历
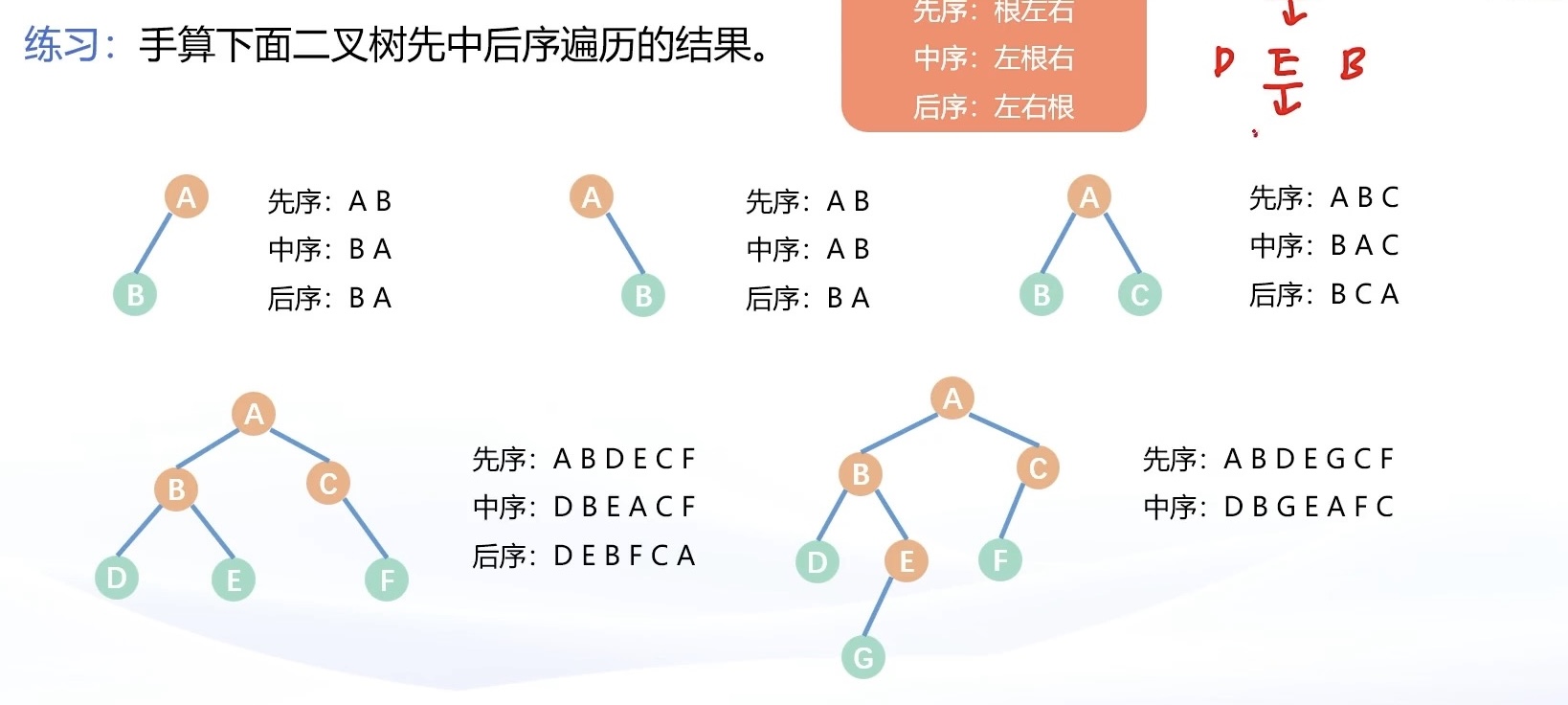
不同于常规树的深度优先遍历,二叉树因其独特的性质可以划分成三种深度优先遍历:先序遍历,中序遍历,和后序遍历。其中,三种遍历方式的不同在于处理根节点的时机。
对于一棵二叉树而言,整体可以划分成三部分:根节点 + 左子树 + 右子树:
- 先序遍历的顺序为:根 + 左 + 右;
- 中序遍历的顺序为:左 + 根 + 右;
- 后序遍历的顺序为:左 + 右 + 根。
cpp
#include<iostream>
using namespace std;
int n;//结点个数
const int N =1e6+10;
int l[N],r[N];
//前序遍历
void dfs1(int p)//p为根结点
{
if(p==0)
{
return;
}
cout<<p<<" ";
dfs1(l[p]);
dfs(r[p]);
}
//中序遍历
void dfs2(int p)//p为根结点
{
if(p==0)
{
return;
}
dfs1(l[p]);
cout<<p<<" ";
dfs(r[p]);
}
//后续遍历
void dfs3(int p)
{
if(p == 0)
{
return;
}
dfs3(l[p]);
dfs3(r[p]);
cout << p << " ";
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++)
{
cin >> l[i] >> r[i];
}
dfs1(1); // 先序遍历
cout << endl;
dfs2(1); // 中序遍历
cout << endl;
dfs3(1); // 后序遍历
cout << endl;
return 0;
}1.4.2 宽度优先遍历
利用队列,太简单了就直接写代码了
cpp
#include <iostream>
#include <queue>
using namespace std;
const int N = 300;
int n;
int l[N], r[N];
void bfs()
{
queue<int> q;
q.push(1);
while(q.size())
{
int tmp=q.fornt();
q.pop();
cout<<tmp<<" ";
if(l[tmp]) push(l[tmp]);
if(r[tmp]) push(r[tmp]);
}
cout<<endl;
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++)
{
cin >> l[i] >> r[i];
}
bfs();
return 0;
}2. 堆(静态实现)
2.1 定义
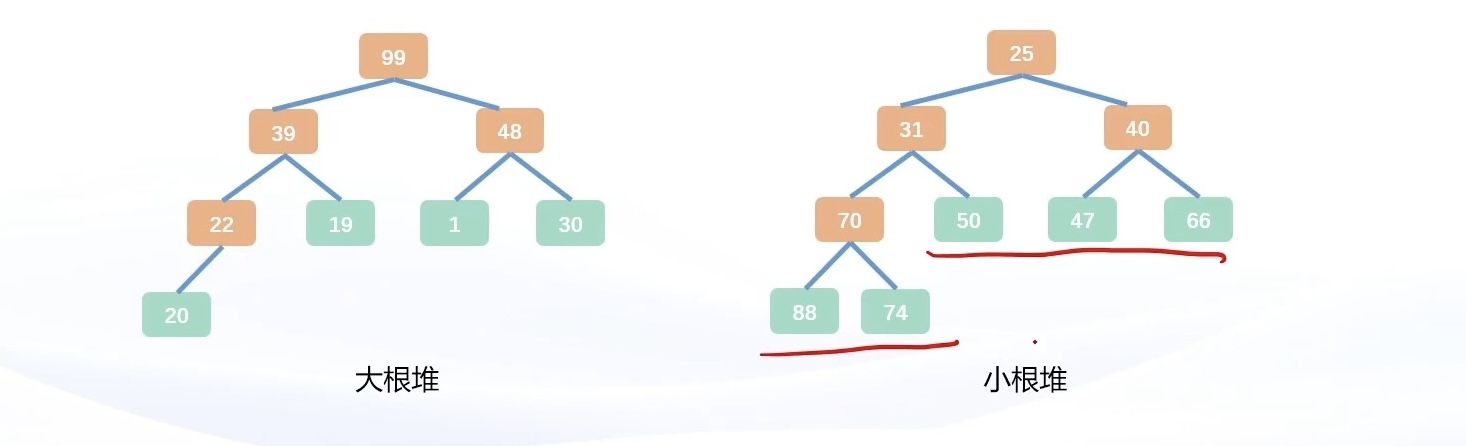
堆(heap),是一棵有着特殊性质的完全二叉树,可以用来实现优先级队列(priority queue)。
堆需要满足以下性质:
- 是一棵完全二叉树;
- 对于树中每个结点,如果存在子树,那么该结点的权值大于等于(或小于等于)子树中所有结点的权值。
如果根结点大于等于子树结点的权值,称为大根堆;反之,称为小根堆。
2.2 堆的存储
由于堆是一个完全二叉树,因此可以用一个数组来存储。
结点下标为 i i i:
- 如果父存在,父下标为 i / 2 i/2 i/2;
- 如果左孩子存在,左孩子下标为 i × 2 i \times 2 i×2;
- 如果右孩子存在,右孩子下标为 i × 2 + 1 i \times 2 + 1 i×2+1。
一般给我们的是一组数,这组数按照给出的顺序还原成二叉树之后,并不是一个堆结构。此时如果想将这组数变成堆的话,有两种操作:
- 用数组存下来这组数,然后把数组调整成一个堆;
- 创建一个堆,然后将这组数依次插入到堆中。
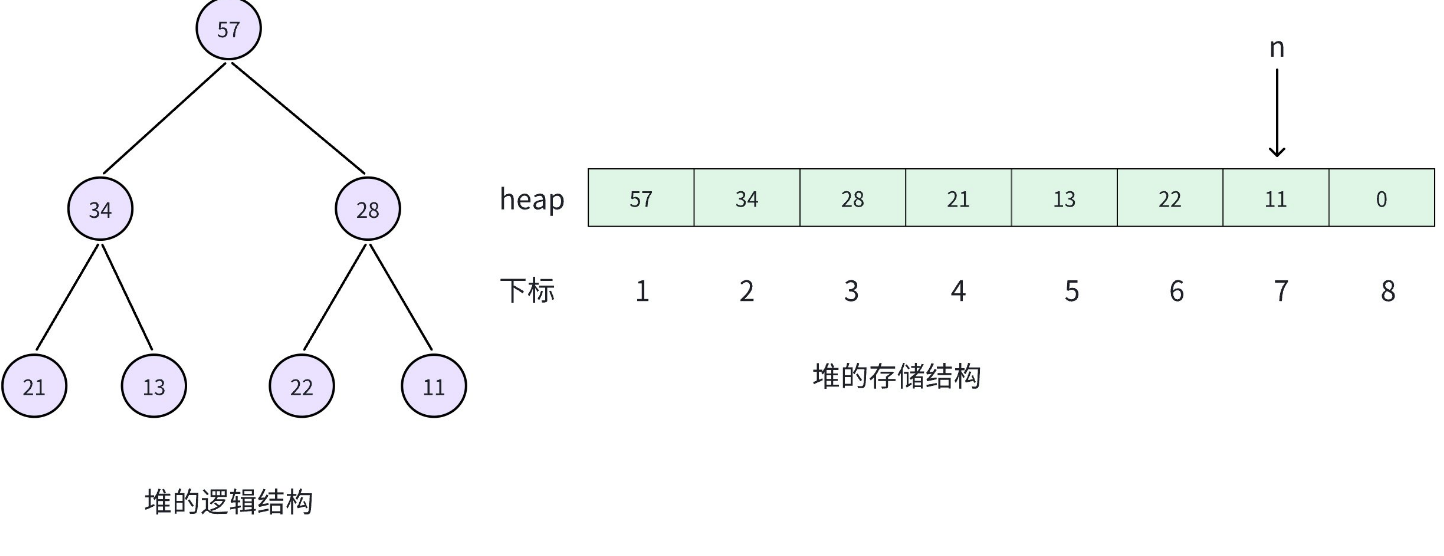
2.3.1 向上调整算法
cpp
int n; // 标记堆的⼤⼩
int heap[N]; // 存堆 - 默认是⼀⼤根堆
// 向上调整算法
void up(int child)
{
int parent = child / 2;
// 如果⽗结点存在,并且权值⽐⽗结点⼤
while(parent >= 1 && heap[child] > heap[parent])
{
swap(heap[child], heap[parent]);
// 交换之后,修改下次调整的⽗⼦关系,注意顺序不能颠倒
child = parent;
parent = child / 2;
}
}2.3.2 向下调整建堆
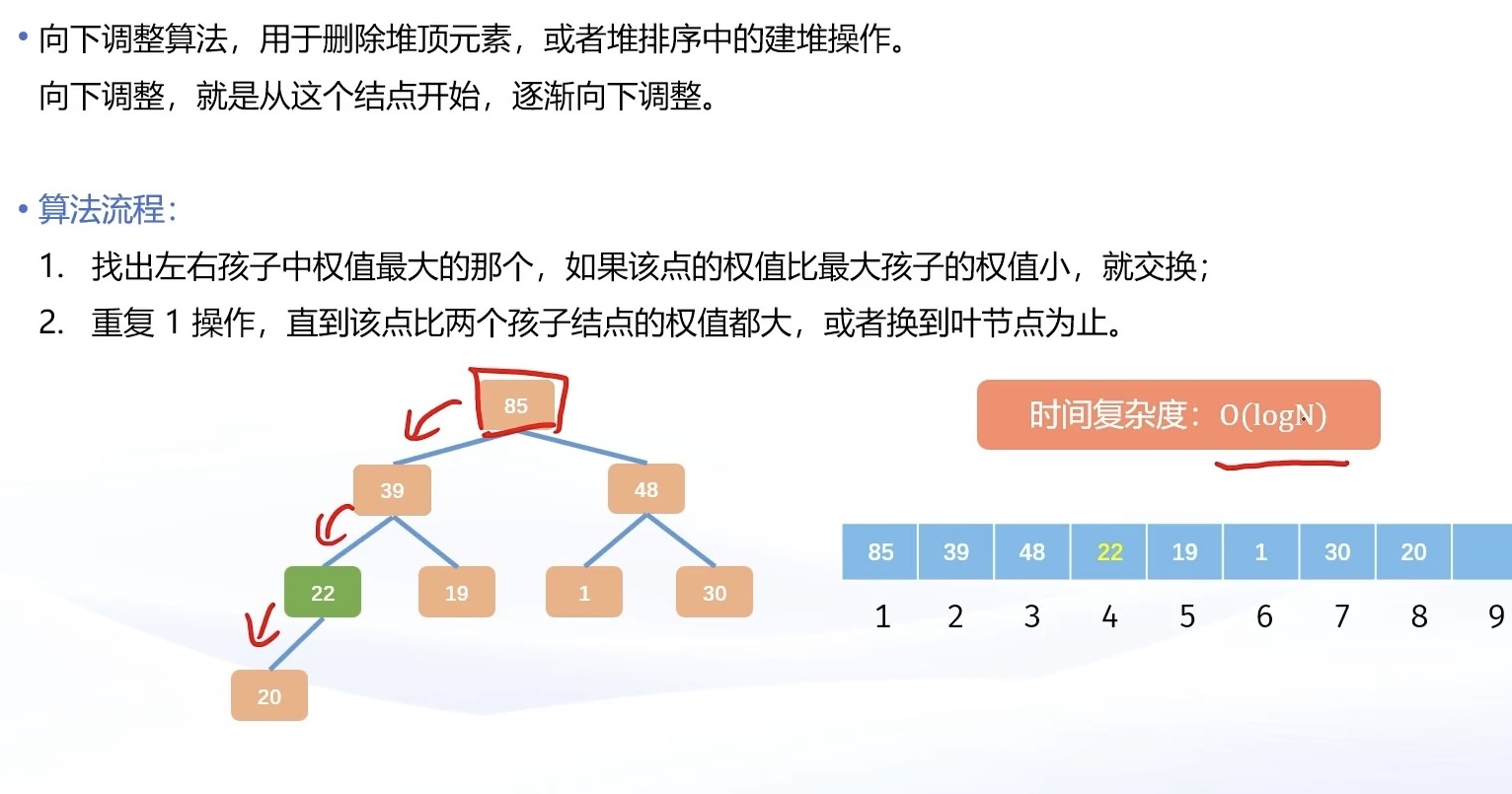
cpp
int n; // 标记堆的⼤⼩
int heap[N]; // 存堆 - 默认是⼀⼤根堆
// 向下调整算法
void down(int parent)
{
int child = parent * 2;
while(child <= n) // 如果还有孩⼦
{
// 找出两个孩⼦谁是最⼤的
if(child + 1 <= n && heap[child + 1] > heap[child]) child++;
// 最⼤的孩⼦都⽐我⼩,说明是⼀个合法的堆
if(heap[child] <= heap[parent]) return;
swap(heap[child], heap[parent]);
// 交换之后,修改下次调整的⽗⼦关系,注意顺序不能颠倒
parent = child;
child = parent * 2;
}
}2.3 堆的静态模拟实现
2.3.1 创建
- 创建一个足够大的数组充当堆;
- 创建一个变量 n,用来标记堆中元素的个数。
cpp
const int N = 1e6 + 10;
int n; // 标记堆的⼤⼩
int heap[N]; // 存堆 - 默认是⼀⼤根堆2.3.2 插⼊
把新来的元素放在最后⼀个位置,然后从最后⼀个位置开始执⾏⼀次向上调整算法即可。
cpp
// 向上调整算法
void up(int child)
{
int parent = child / 2;
// 如果⽐⽗结点⼤
while(parent >= 1 && heap[child] > heap[parent])
{
swap(heap[child], heap[parent]);
child = parent;
parent = child / 2;
}
}
// 插⼊
void push(int x)
{
// 把该元素放在最后
heap[++n] = x;
// 执⾏⼀次向上调整算法
up(n);
}2.3.3 删除栈顶元素
- 将栈顶元素和最后一个元素交换,然后 n--,删除最后一个元素;
- 从根节点开始执行一次向下调整算法即可。
cpp
// 向下调整算法
void down(int parent)
{
int child = parent * 2;
while(child <= n) // 如果还有孩⼦
{
// 找出两个孩⼦谁是最⼤的
if(child + 1 <= n && heap[child + 1] > heap[child]) child++;
// 最⼤的孩⼦都⽐我⼩,说明是⼀个合法的堆
if(heap[child] <= heap[parent]) return;
swap(heap[child], heap[parent]);
parent = child;
child = parent * 2;
}
}
// 删除
void pop()
{
// 把第⼀个元素与最后⼀个元素交换
swap(heap[1], heap[n]);
n--;
// 执⾏⼀次向下调整算法
down(1);
}2.3.4 堆顶元素
下标为 1 位置的元素,就是堆顶元素。
cpp
// 堆顶元素
int top()
{
return heap[1];
}2.3.5 堆的⼤⼩
n 的值。
cpp
// 堆的⼤⼩
int size()
{
return n;
}3. 哈希表(静态实现)
3.1 哈希表的概念
3.1.1 哈希表的定义
哈希表(hash table),又称散列表,是根据关键字直接进行访问的数据结构。
哈希表建立了一种关键字和存储地址之间的直接映射关系,使每个关键字与结构中的唯一存储位置相对应。理想情况下,在散列表中进行查找的时间复杂度为 (O(1)),即与表中的元素数量无关。因此哈希表是一种存储和查找非常快的结构。
3.1.2 哈希函数
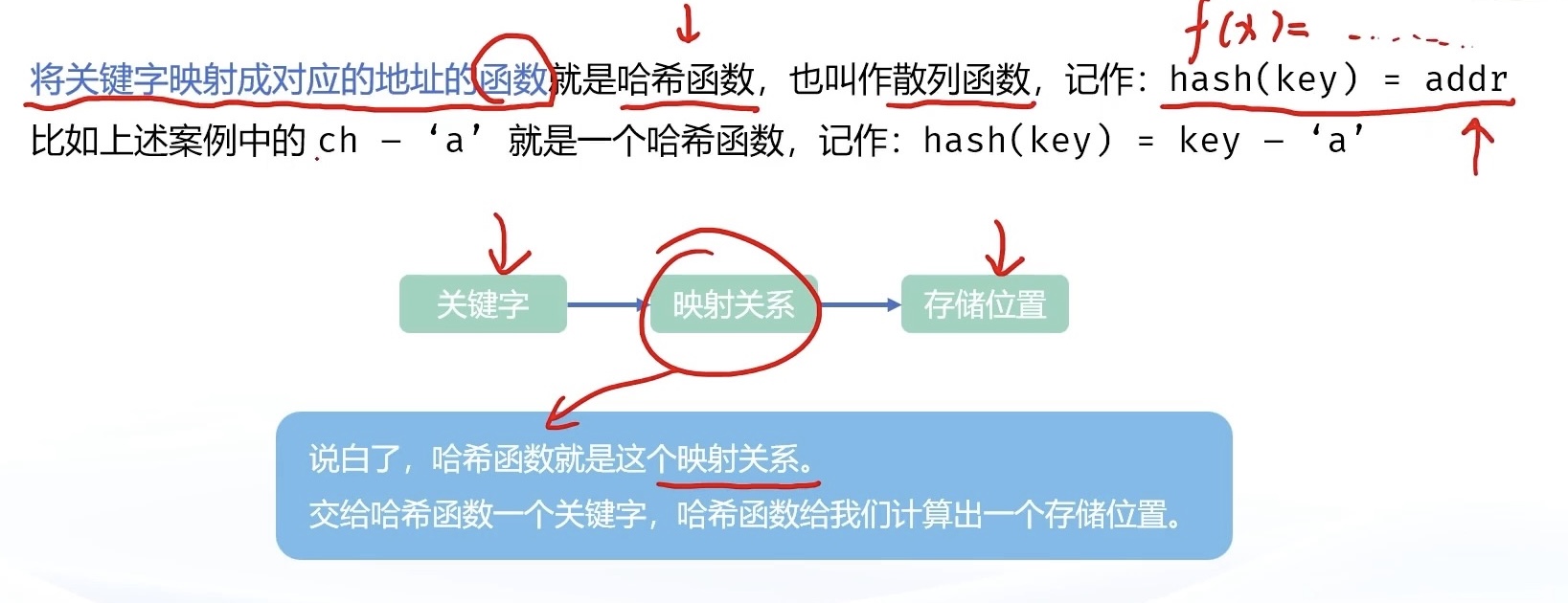
将关键字映射成对应的地址的函数就是哈希函数 ,也叫作散列函数,记为 Hash(key) = Addr。
哈希函数的本质也是一个函数,它的作用是,你给它一个关键字,它给你一个该关键字对应的存储位置。
3.1.3 哈希冲突
哈希函数可能会把两个或两个以上的不同关键字映射到同一地址,这种情况称为哈希冲突 (也称散列冲突)。起冲突的不同关键字,称它们为同义词。
由此可见,设计一个优秀的哈希表,不仅需要设计一个好的哈希函数,也要能够处理哈希冲突。那么,学习哈希表的重点就是设计哈希函数 和处理哈希冲突 。

3.2 常⻅的哈希函数
3.2.1 直接定址法
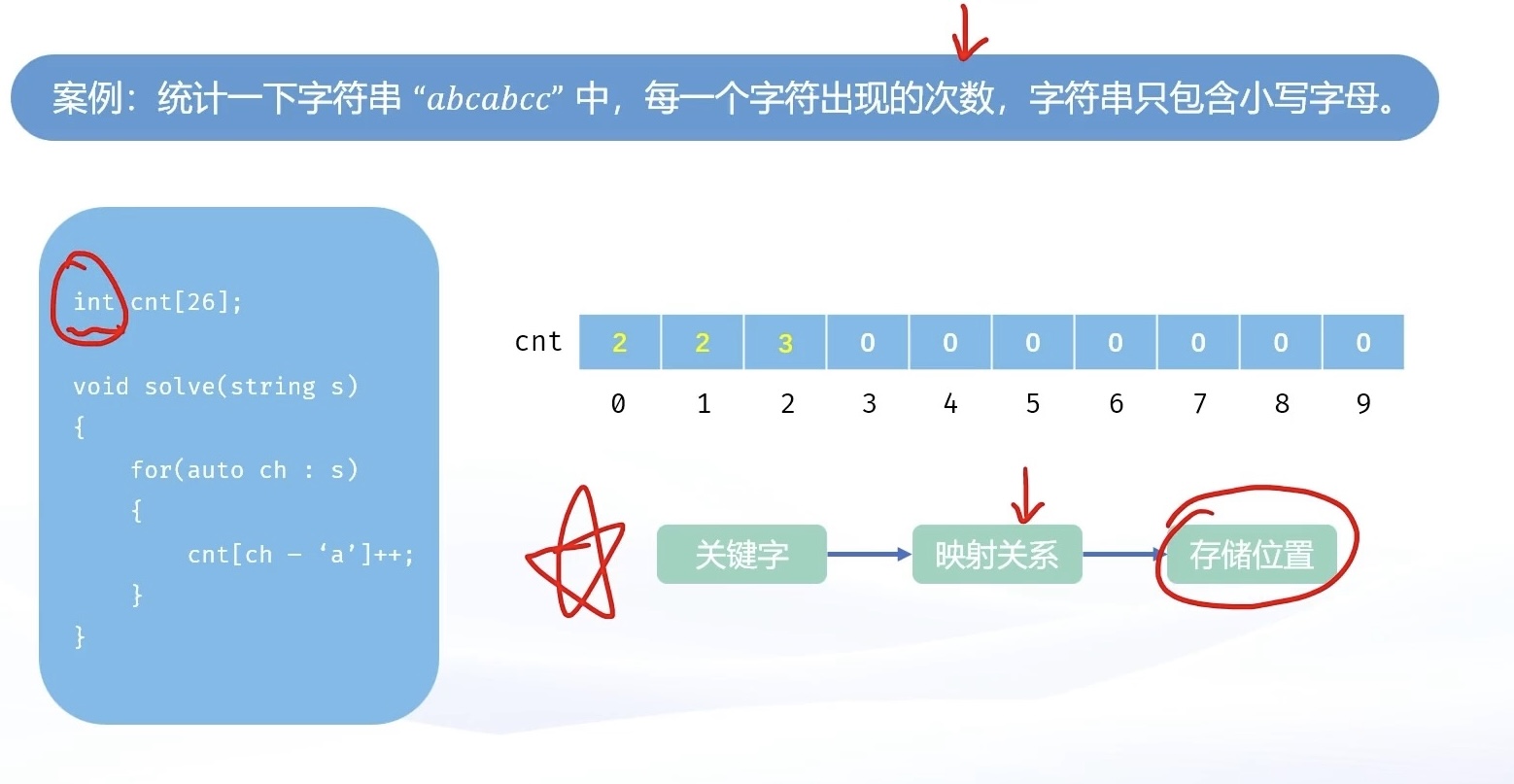
第一个案例中,统计字符串中,小写字符出现的次数使用的方法,就是直接定址法 。
直接取关键字的某个线性函数值为散列地址,散列函数是:

其中 (a) 与 (b) 为常数。这种方式计算比较简单,适合关键字的分布基本连续的情况,但是若关键字分布不连续,空位较多,则会造成存储空间的浪费。
3.2.2 除留余数法
哈希冲突那里的案例,所用的哈希函数就是除留余数法。
除留余数法,顾名思义,假设哈希表的大小为 M M M,那么通过 key 除以 M M M 的余数 作为映射位置的下标,也就是哈希函数为:
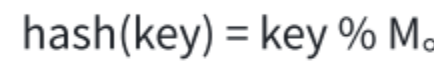
因此,这种方法的重点就是选好模数 M M M。
- 建议 M M M 取不太接近 2 2 2 的整数次幂的一个质数(素数)。(具体原理可以参考算法导论里面的证明,选素数可以让分布更均匀,进而减少冲突。)
3.3 处理哈希冲突
有时候哈希表⽆论选择什么哈希函数都⽆法避免冲突,那么插⼊数据时,如何解决冲突呢?主要有两种⽅法,线性探测法和链地址法。
3.3.1 线性探测法
从发⽣冲突的位置开始,依次线性向后探测,直到寻找到下⼀个没有存储数据的位置为⽌,如果⾛到哈希表尾,则回绕到哈希表头的位置。

3.3.2 链地址法
链地址法中所有的数据不再直接存储在哈希表中,哈希表中存储⼀个指针,没有数据映射这个位置时,这个指针为空,有多个数据映射到这个位置时,我们把这些冲突的数据链接成⼀个链表,挂在哈希表这个位置下⾯。

3.4 哈希表的模拟实现( 线性探测法)
3.4.1 创建

cpp
#include <iostream>
#include <cstring>
using namespace std;
// N 是质数 如果最大值是10 我们一般10*2 找最近的质数
const int N = 23, INF = 0x3f3f3f3f;
int h[N]; // 哈希表
// 先把哈希表中所有元素初始化成⼀个不会出现的值
void init()
{
memset(h, 0x3f, sizeof h);
}
int main()
{
init();
return 0;
}3.4.2 哈希函数以及处理哈希冲突


cpp
// 哈希函数 f(x) 返回 x 映射的位置
int f(int x)
{
// 经典操作:模 加 模
int idx = (x % N + N) % N; // 为了避免出现负数
// 处理冲突
while(h[idx] != INF && h[idx] != x)
{
idx++; // 线性探测
if(idx == N) idx = 0; // 如果⾛到头了,就拐个弯
}
return idx;
}3.4.3 添加元素
通过哈希函数找到合适的位置,然后放上去即可
cpp
// 添加元素
void insert(int x)
{
int idx = f(x); // 哈希函数计算位置
h[idx] = x;
}3.4.4 查找元素
通过哈希函数找到映射位置,看看⾥⾯的值是不是 x
cpp
// 查找元素
bool find(int x)
{
int idx = f(x);
return h[idx] == x;
}3.5 哈希表的模拟实现(链地址法)
3.5.1 创建
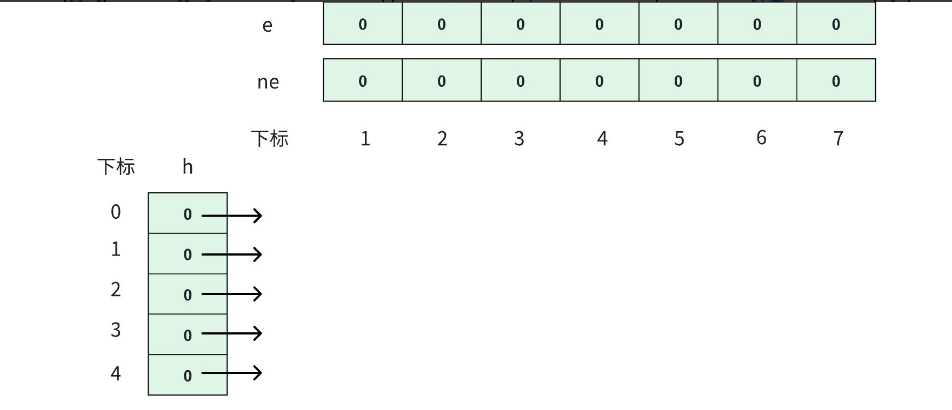
实现方式与树的链式向前星一模一样~ 实现可以 参考以前的博客
本质就是用数组模拟链表。
cpp
#include <iostream>
#include <cstring>
using namespace std;
const int N = 23;
int h[N]; // 哈希表
int e[N], ne[N], id; // 链表⾥⾯的⼀个⼀个结点3.5.2 哈希函数
cpp
// 哈希函数
int f(int x)
{
return (x % N + N) % N;
}3.5.3 查找元素
- 先计算 (x) 对应的哈希值;
- 在哈希值所在的链表中查找。
cpp
// 查找元素
bool find(int x)
{
int idx = f(x); // 哈希值
// 遍历 idx 的链表
for(int i = h[idx]; i; i = ne[i])
{
if(e[i] == x) return true;
}
return false;
}3.5.4 添加元素以及处理哈希冲突
- 先判断是否已经在哈希表中;
- 如果不在,就头插在哈希值所对应的链表后。
cpp
// 添加元素+哈希冲突
void insert(int x)
{
if(find(x)) return; // 如果找到了,就不添加了
int idx = f(x);
// 头插在 idx 后⾯
id++;
e[id] = x;
ne[id] = h[idx];
h[idx] = id;
}4.AVL树、红黑树
⚠️:在算法竞赛中 并不直接要求AVL树和红黑树的实现 直接使用
set、map等容器就行了 如果想学习他们的实现 可以看博主以前的博客(对C++要求比较高)
https://blog.csdn.net/Fcy648/article/details/155989612?spm=1011.2415.3001.5331【AVL树】
https://blog.csdn.net/Fcy648/article/details/156424145?spm=1011.2415.3001.5331【红黑树】