一、背景介绍
在使用Flink计算引擎进行大数据实时加工处理的实际落地过程中,面对复杂多变的实时业务需求,如何选择合适的技术链路与组件选型成为了普遍存在的痛点与难点。不同业务场景对数据处理的时效、存储模型、查询能力有着截然不同的要求,而技术选型的合理性直接决定了系统的性能、可扩展性、维护成本与业务价值。
我们作为大数据实时技术支撑的角色,在日常用户咨询、方案讨论、组件选型过程中,经常会遇到以下用户痛点:
- 全链路架构不清晰:从数据源、计算引擎到存储层的选型缺乏基本认识,不了解常用的数据链路与组件选型,导致无从下手。
- 维表选型混乱:维表关联是实时计算的核心环节,但多数团队缺乏标准化的维表存储选型原则,经常不分场景全都使用一种维表选型。
- 场景与技术错配:如用 HBase 承载复杂查询(不支持 SQL)、用 Hudi 支撑大规模数据点查(性能瓶颈)等。
基于我们日常测试与生产的Flink实时计算支撑与实践,本文结合 Flink、Kafka、HBase、Hudi 等主流组件能力,梳理出一套覆盖全链路、多场景的实时技术方案选型准则,为大家提供参考。
二、不同需求场景的技术方案选型
在实时计算链路中,我们通常以 Flink 为核心引擎,消费 CDC 工具(如 Canal/FlinkCDC)或源系统写入 Kafka 的实时数据,经清洗、转换、维表关联后,写入对应存储介质供下游业务使用。
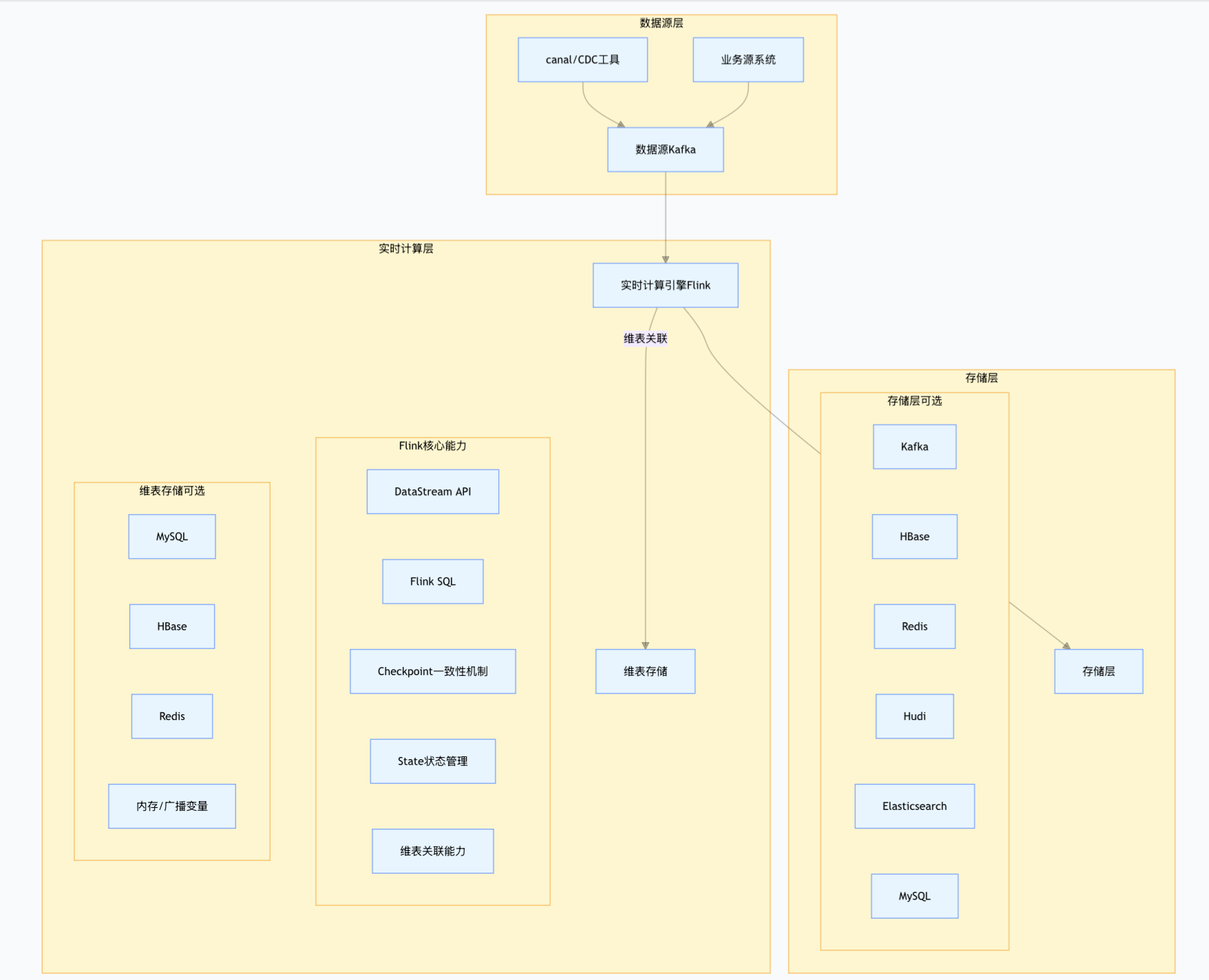
1.实时数据流转
-
特征:构建实时数据管道,供下游系统(如另一个数据平台)实时消费。
-
数据时效:秒级。
-
典型场景:实时通知、实时营销、实时风控等。
-
技术链路:
源系统 -> Kafka -> Flink (ETL) -> Kafka -> 下游消费
Kafka以其分布式、高吞吐、低延迟的消息队列特性,作为实时数据管道的事实标准组件,承接源系统 / CDC 的实时数据统一入口,Flink对数据进行清洗、过滤、格式转换、Enrich 等处理,通过 Checkpoint 保证数据一致性,将处理后的数据写入新 Topic,供下游多个业务系统实时消费。
2.实时服务点查
-
特征:根据主键(RowKey)对结果表数据进行毫秒级查询,支持高并发随机读写。
-
数据时效:秒级。
-
典型场景:用户画像、用户标签实时查询、订单详情实时查询。
-
技术链路:
源系统 -> Kafka -> Flink -> HBase -> API接口查询
HBase 是基于 LSM 树(Log-Structured Merge-Tree)的分布式数据库,专为海量数据(TB/PB级)下的随机读写而生。Flink对数据进行清洗、聚合、标签计算,关联维表后写入 HBase,对外提供毫秒级主键点查能力。
3.实时湖分析
-
特征:支持全量 + 增量处理,支持数据实时更新,支持数据回溯和修正,兼容批处理分析。
-
数据时效:分钟级。
-
典型场景:实时湖仓 ETL、数据湖实时更新、全量数据准实时分析。
-
技术链路:
源系统 -> Kafka -> Flink -> Hudi -> Spark/Trino/OLAP
Hudi作为数据湖仓一体框架,实现了流批存储一体,支持全量 + 增量数据的存储、更新、时间旅行(数据回溯)。当业务需要对历史数据进行修正或需要分钟级延迟的数据分析时,Hudi 是优于传统 Hive 的选择。Flink 写入 Hudi 能确保数据的新鲜度,而 Trino、Spark或OLAP 则用于后续的分析查询。
4.全文检索 / 日志分析场景
-
特征:支持复杂的全文搜索、模糊查询,秒级响应。
-
数据时效:十秒级(一般refresh会在十秒级,时效与性能的综合考虑)。
-
典型场景:日志分析、应用搜索、内容推荐。
-
技术链路:
源系统 -> Kafka -> Flink -> Elasticsearch -> API接口查询
Elasticsearch 基于倒排索引(Inverted Index)技术,擅长处理文本搜索。作为分布式全文检索引擎,支持全文检索、多维度实时分析、高吞吐写入,是日志分析、全文检索的事实标准。Flink 实时清洗后写入 ES,利用 ES 的 _searchAPI 可以快速进行全文检索与聚合分析。
5.实时缓存服务
-
特征:超低查询延迟(亚毫秒级)、极高访问频率。
-
数据时效:秒级。
-
典型场景:热点数据缓存、实时排行榜、实时推荐、商品详情缓存。
-
技术链路:
源系统 -> Kafka -> Flink -> Redis -> CLI/Jedis
Redis作为内存数据库,支持亚毫秒级延迟(数据规模受限于内存限制,一般千万级以内)、高并发读写,是热点数据缓存、排行榜场景的标准选型。Flink 的实时计算能力支持排行榜、热点数据的实时聚合,保证数据的实时性。
6.报表展示/多表查询
-
特征:多表 join 查询、事务性操作、报表展示(百万级以内数据规模)
-
数据时效:秒级。
-
典型场景:报表展示、维度数据存储、实时运营报表。
-
技术链路:
源系统 -> Kafka -> Flink -> MySQL -> JDBC查询
MySQL 作为关系型数据库,拥有成熟的 ACID 事务支持和 SQL 优化器。对于报表展示场景,如果数据量在百万级且需要多表关联(如事实表关联多张维度表),MySQL 的标准 SQL 支持度最好。虽然单机 MySQL 难以支撑海量数据,但对于 BI 报表的结果存储或小规模维度库,它是最佳选择。
7.小结
上述六种技术链路是我们在日常生产中主要使用的,业内也有很多其他的选型方案,比如Flink直接对接OLAP、FlinkCDC直连两端等,这些都是在特定背景下孕育而生,存在即合理。随着技术栈的不断迭代演进,我们在实际的链路选型中都应该遵循以下原则:
- 场景匹配原则:技术选型必须匹配业务场景的时效、数据规模、查询需求。
- 生态兼容原则:选型组件需与现有技术栈(如 Flink、Kafka)深度兼容。
- 可扩展性原则:选型组件需支持水平扩展,应对业务增长。
- 维护成本原则:选型组件需有成熟的社区、运维工具,降低长期维护成本。
三、维表组件选型
在实时计算中,维表关联是最常见的业务逻辑之一。由于 Flink 处理的是流式数据,通常需要从外部存储中查询维度信息(如用户信息、商品详情)进行补全。不同维表引擎在数据量、查询延迟和复杂度上表现迥异。
1.维表选型分析
以下是业内四种主流维表(Redis、MySQL、HBase、内存)的维度对比:
| 维度 | Redis | MySQL | HBase | 内存(广播变量) |
|---|---|---|---|---|
| 查询复杂度 | 不支持复杂 SQL | 支持复杂 SQL | 不支持复杂 SQL | 不支持复杂 SQL |
| 查询延迟 | 亚毫秒级 | 百毫秒级 | 百毫秒级 | 微秒级 |
| 数据规模 | GB 级 | GB 级 | PB 级 | MB 级 |
| 适用场景 | 热数据缓存,高频读 | 小维度表,需 Join 逻辑 | 海量大维表,点查 | 极小维表,广播变量 |
2.维表选型推荐
- 维表 < 1G 且更新不频繁:选择内存维表 + 广播变量,广播变量会将维表分发到所有 TaskManager 的内存中,实现微秒级查询延迟,适合小数据量、低更新的维表。
- 维表 < 5G 且更新频繁:选择MySQL,MySQL 支持事务、高频更新、复杂 SQL,适合需要频繁更新、多表关联的小数据量维表。
- 维表 < 20G 且查询延迟毫秒级:选择Redis,Redis 为内存数据库,毫秒级延迟,适合高并发、低延迟的维表点查场景。
- 通用方案 / 大数据量维表:选择HBase,HBase 支持 PB 级数据存储、分布式扩展,是维表的通用兜底选型,适合大数据量、对延迟要求不极致的场景。
四、总结与展望
实时场景技术方案的选型,本质上是在吞吐量、延迟、数据规模、查询复杂度与资源成本之间做权衡。
- 链路层面:我们确立了以 Kafka为总线,Flink为核心引擎,根据不同下游场景选择 HBase(海量点查)、Redis(极速缓存)、ES(全文检索)、Hudi(湖仓一体)、MySQL(报表事务)的标准化链路。
- 维表层面:明确了 内存(小数据)、MySQL(需SQL/中等数据)、Redis(极低延迟)、HBase(通用/海量数据)的四象限选型模型。
随着技术的发展,实时场景的选型也在不断演进,未来主要呈现以下趋势:
- 流式湖仓一体化:未来的实时方案将不再区分"热存储"和"冷存储",通过 湖存储直接支持分钟级的数据新鲜度和强大的更新能力(paimon/fluss等)。
- 计算引擎统一:未来选型时,可能更倾向于使用一套引擎(如 Flink)解决流、批、维表关联的全场景问题,降低运维复杂度。
- Serverless 化:云原生趋势下,Kafka、HBase、Redis 等组件将逐步被云厂商的 Serverless 版本替代。架构师的选型重点将从"组件运维"转向"业务逻辑与成本模型"的匹配。
- AI 与实时计算融合:AI 模型与实时计算结合,实现实时推荐营销、实时风控的智能化升级。