背景
我的场景: 目前我已经通过semantic_feature_extractor_v3提取到了128维的语义特征,另外也通过main_workflow_v2提取到了128维的程序级的图嵌入。
**我的目标:**融合128维的语义特征+128维的程序级图嵌入,然后再重新输入下游的模型做监督分类。
根据我的场景需求,下游做监督分类时应该采用那些机器学习/深度学习模型较好呢?因为我后面要做对比实验的。
1. 语义特征提取 (128维)
文件: semantic_feature_extractor_v3.py
特征构成:
- 敏感函数频次特征: 32维 (8类×4特征)
- 攻击模式特征: 48维 (12类×4特征)
- 路径配置特征: 24维 (6类×4特征)
- 混淆检测特征: 24维 (6类×4特征)
2. 结构特征提取 (128维图嵌入)
文件: main_workflow_v2.py
两阶段GNN训练:
- 阶段1: CFG-GNN (函数级, 256维→128维)
- 阶段2: FCG-GNN (程序级, 128维→128维)
3. 监督分类任务 (256维融合特征)
文件: fusion_classifier_models.py
融合方式: 语义特征(128维) + 图嵌入(128维) = 256维支持模型: 逻辑回归、SVM、随机森林、XGBoost、LightGBM、MLP、BiLSTM、Transformer、ResNet-1D、融合模型
代码debug记录
1.加载数据
X, y, file_paths ← load_fusion_features(fusion_dir,label_file)
- X:特征列表,
- y:标签列表,
- file_path:特征文件名列表。 'malicious_0'、'malicious_1'、...
**注意:**load_fusion_features()函数实现过程使用了path.Path()方法,具体语法请见附录2!
2.划分数据集+标准化
2.1 分层划分数据集,默认打乱顺序
训练集+验证集 :测试集 = 0.8:0.2,random_state=42,stratify=y分层划分,shuffle=true(默认) ↓
↓ 注意:在所有数据集的0.8的比例下,再划分训练集和验证集
训练集:验证集 = 0.75*0.8:0.25*0.8 = 0.6:0.2
总之,训:验:测 = 0.6:0.2:0.2
X_temp, X_test, y_temp, y_test = train_test_split(
X, y, test_size,random_state, stratify=y
)
注意: 在 scikit-learn 的
train_test_split函数中,shuffle参数的默认值是True。因此,原代码虽然没有显式写出shuffle=True,但实际上默认已经进行了打乱。
2.2 标准化
划分完数据集后,再进行标准化,标准化(在训练集上fit,然后transform所有集合)
记住:
- 训练集: fit + transform ✓
- 验证集: transform ✓
- 测试集: transform ✓
正确的做法:
先划分数据集,然后仅在训练集上拟合 StandardScaler ,最后用这个拟合好的 scaler 来转换训练集、验证集和测试集。
有关StandardScaler()函数的用法请见附录3!
3.运行传统ML模型
相关机器学习知识点讲解
1. 数据集划分的作用
训练集:用于模型学习参数(如权重)。
验证集:用于模型选择、超参数调优,避免直接在测试集上调参导致信息泄露。
测试集:最终评估模型泛化能力,仅使用一次。
2. 特征标准化
为什么需要标准化?
逻辑回归、SVM 等模型依赖于特征间的尺度,如果特征数值范围差异大,会导致模型偏向数值大的特征,且梯度下降收敛慢。标准化使每个特征均值为0、标准差为1,消除量纲影响。
为什么树模型不需要标准化?
决策树基于特征值划分节点,不关心特征的绝对尺度,因此标准化对树模型无影响。
为什么在训练集上 fit,再 transform 验证/测试集?
防止数据泄露:验证/测试集应模拟未知数据,必须使用训练集计算出的均值和标准差进行转换,而不能使用自身统计量。
哪些模型需要标准化?哪些不需要?请见附录4!!!
3. 评估指标(二分类)
准确率(Accuracy) :
(TP+TN)/(TP+TN+FP+FN),整体正确率,但类别不平衡时可能误导。精确率(Precision) :
TP/(TP+FP),预测为正例的样本中实际为正的比例。召回率(Recall) :
TP/(TP+FN),实际为正例的样本中被正确预测的比例。F1分数:精确率和召回率的调和平均数,综合衡量。
AUC(Area Under the ROC Curve):模型区分正负类的能力,不受阈值影响,对不平衡数据更鲁棒。
4. 工厂模式
ClassifierFactory隐藏了模型创建的细节,使代码易于扩展:添加新模型只需修改工厂,无需改动主流程。5. 异常处理
- 使用
try-except避免单个模型失败导致整个程序崩溃,增强鲁棒性。
潜在 Bug 与优化建议
SVM 无法输出概率
代码中 SVM 参数未设置
probability=True,而evaluate方法中计算 AUC 需要调用predict_proba。后果 :运行到 SVM 时,
classifier.evaluate(X_test, y_test)内部若调用predict_proba会抛出AttributeError,被except捕获后跳过 SVM,但用户可能误以为 SVM 不可用。修复 :在 SVM 参数字典中添加
'probability': True,或确保evaluate在无法获取概率时使用其他方式(如决策函数计算 AUC)------但决策函数与概率尺度不同,通常不直接用于 AUC,因此建议启用probability=True。依赖库缺失
如果环境中未安装
xgboost或lightgbm,ClassifierFactory创建模型时会抛出ImportError,被捕获后跳过。虽然程序继续运行,但用户可能未察觉缺失。优化:在日志中明确提示缺失的库,或提前检查依赖。
输出目录可能不存在
results_file = Path(output_dir) / 'ml_comparison_results.json',若output_dir目录不存在,写入文件会失败。修复 :在函数开头添加
Path(output_dir).mkdir(parents=True, exist_ok=True)。验证集未用于模型选择
代码中验证集仅用于记录指标,未参与任何超参数调整。如果目的是最终对比,可以直接在测试集上评估,无需验证集。但保留验证集可观察模型在验证集上的表现,辅助判断过拟合。
无 Bug,但可优化:可考虑使用验证集进行简单超参数搜索(如网格搜索),提升模型性能。
评估指标未考虑分类阈值
精确率、召回率、F1 依赖于默认阈值 0.5。如果类别极不平衡,默认阈值可能不是最优。但 AUC 不受阈值影响,可作为主要参考。
优化:可额外输出最佳阈值下的指标,或绘制 PR 曲线。
数据类型问题
如果
y不是整数,某些模型可能要求标签为整数。通常从文件加载后应为 int。检查 :确保
y_train等为整数类型(np.int64或int)。优化建议
增加模型保存
使用
joblib.dump保存训练好的模型,便于后续部署或继续分析。并行训练
如果模型较多且耗时,可使用
joblib.Parallel或concurrent.futures并行训练,但注意内存占用。更详细的日志
记录每个模型的训练时间、验证集指标,方便对比。
超参数调优
使用
GridSearchCV或RandomizedSearchCV在验证集上自动搜索最佳参数,而不是固定参数。处理类别不平衡
如果标签不平衡,可在模型参数中设置
class_weight='balanced'(逻辑回归、SVM、随机森林支持),或在评估时使用宏平均/加权平均。验证指标可视化
保存结果后,可自动生成柱状图对比各模型在测试集上的指标,就像原脚本中
visualize_results所做的那样。异常处理细化
区分依赖缺失错误和模型训练错误,给出更具体的提示。
这行代码比较有意思:
classifier = ClassifierFactory.create_classifier(model_name, **params)
这行代码中ClassifierFactory类对象 并未实例化,就直接调用**create_classifier方法,**为啥能这样?
原因是:
@staticmethod:声明该方法是静态方法,可以直接通过类名调用(如ClassifierFactory.create_classifier(...)),无需创建工厂实例。适合作为工具方法。具体学习请见附录5!
3.0 分类器基类
面向对象设计原则:基类定义了统一接口,子类实现具体逻辑,使得评估代码可以复用,且易于扩展新模型。
-
继承 :
LogisticRegressionClassifier继承自BaseClassifier,可以复用基类中定义的通用属性和方法(如name、scaler、logger等),体现了面向对象的代码复用思想。 -
多态 :所有分类器类都实现相同的接口(
fit、predict、predict_proba),使得工厂模式可以统一创建和调用。
python
class BaseClassifier:
"""分类器基类"""
def __init__(self, name: str):
self.name = name
self.model = None
self.scaler = StandardScaler()
self.is_fitted = False
def fit(self, X: np.ndarray, y: np.ndarray) -> None:
"""训练模型"""
raise NotImplementedError
def predict(self, X: np.ndarray) -> np.ndarray:
"""预测"""
raise NotImplementedError
def predict_proba(self, X: np.ndarray) -> np.ndarray:
"""预测概率"""
raise NotImplementedError
def evaluate(self, X: np.ndarray, y: np.ndarray) -> Dict[str, float]:
"""评估模型"""
y_pred = self.predict(X)
y_proba = self.predict_proba(X)
metrics = {
'accuracy': accuracy_score(y, y_pred),
'precision': precision_score(y, y_pred, zero_division=0),
'recall': recall_score(y, y_pred, zero_division=0),
'f1': f1_score(y, y_pred, zero_division=0),
'auc': roc_auc_score(y, y_proba[:, 1]) if y_proba.shape[1] > 1 else 0.0
}
return metrics3.1 逻辑回归分类器
(1)类定义与初始化
python
class LogisticRegressionClassifier(BaseClassifier):
"""逻辑回归分类器"""class LogisticRegressionClassifier(BaseClassifier):定义一个名为LogisticRegressionClassifier的类,它继承自BaseClassifier(基类)。这意味着它将继承基类的属性和方法,例如可能已经定义了name和scaler等。
python
def __init__(self, max_iter: int = 1000, random_state: int = 42, use_scaler: bool = True):
super().__init__("Logistic Regression")
self.model = LogisticRegression(max_iter=max_iter, random_state=random_state)
self.use_scaler = use_scaler-
__init__方法:构造函数,在创建类的实例时自动调用。 -
参数:
-
max_iter:逻辑回归的最大迭代次数,默认为 1000。用于控制优化算法的迭代上限,防止不收敛时无限运行。 -
random_state:随机种子,默认为 42,用于确保结果可复现(逻辑回归中的求解器可能涉及随机性,如sag、saga)。 -
use_scaler:布尔值,指示是否在训练和预测前对特征进行标准化。
-
- 调用父类的构造函数 :将模型名称
"Logistic Regression"传递给BaseClassifier。父类可能会将该名称存储在self.name中,也可能做一些其他初始化(如创建日志记录器)。
- 创建逻辑回归模型实例 :使用
sklearn.linear_model.LogisticRegression,并传入用户指定的max_iter和random_state。这是真正执行分类的核心对象。
- 保存标准化标志 :将参数
use_scaler保存为实例变量,以便在fit、predict等方法中判断是否需要标准化。
(2)fit 方法:训练模型
python
def fit(self, X: np.ndarray, y: np.ndarray) -> None:
"""训练模型"""
if self.use_scaler:
X_scaled = self.scaler.fit_transform(X)
else:
X_scaled = X
self.model.fit(X_scaled, y)
self.is_fitted = True
logger.info(f"{self.name} 训练完成")fit方法 :用于训练模型。接收特征矩阵X和标签向量y,均为 NumPy 数组。
标准化处理:
- 如果
self.use_scaler为True,则调用self.scaler.fit_transform(X)对训练集进行拟合(计算均值和标准差)并转换数据。 - 如果为
False,则直接使用原始数据X。(外部数据已经标准化,模型内部不再需要重复标准化(防止数据泄露)) self.scaler是从哪里来的?是从父类BaseClassifier继承而来。父类在__init__中创建了一个StandardScaler实例,并赋值给self.scaler。
模型训练:
- 调用逻辑回归模型的
fit方法 :使用标准化后的(或原始的)特征和标签训练模型。训练完成后,模型参数(如权重和截距)被保存在self.model内部。
- 设置拟合标志 :标记模型已经训练过。这个标志可能用于后续操作(如
predict前检查模型是否已训练),提高代码的健壮性。
- 记录日志 :使用全局的
logger输出训练完成信息。self.name是在父类构造函数中设置的。
(3)评估模型
python
def evaluate(self, X: np.ndarray, y: np.ndarray) -> Dict[str, float]:
"""评估模型"""
y_pred = self.predict(X)
y_proba = self.predict_proba(X)
metrics = {
'accuracy': accuracy_score(y, y_pred),
'precision': precision_score(y, y_pred, zero_division=0),
'recall': recall_score(y, y_pred, zero_division=0),
'f1': f1_score(y, y_pred, zero_division=0),
'auc': roc_auc_score(y, y_proba[:, 1]) if y_proba.shape[1] > 1 else 0.0
}
return metrics
accuracy_score(y, y_pred)
准确率 :正确预测的样本数占总样本数的比例。公式:
(TP + TN) / (TP + TN + FP + FN)。适用性:直观易懂,但在类别不平衡时可能掩盖模型对少数类的表现。
计算 :
accuracy_score直接比较y_pred和y的相等性。
precision_score(y, y_pred, zero_division=0)
精确率 :在所有预测为正类的样本中,实际为正类的比例。公式:
TP / (TP + FP)。含义 :衡量模型预测正类的"纯度"。如果精确率低,说明模型误报较多。
zero_division=0 :当分母为 0(即没有预测为正类的样本)时,返回 0 而不是抛出错误。这是防止除零异常的安全措施。
recall_score(y, y_pred, zero_division=0)
召回率 :在所有实际为正类的样本中,被正确预测为正类的比例。公式:
TP / (TP + FN)。含义 :衡量模型找出正类的能力。召回率低说明漏报较多。
f1_score(y, y_pred, zero_division=0)
F1 分数 :精确率和召回率的调和平均数。公式:
2 * (precision * recall) / (precision + recall)。作用 :**综合衡量精确率和召回率,尤其适用于不平衡分类。**当两者之一为 0 时,F1 也为 0。
roc_auc_score(y, y_proba[:, 1]) if y_proba.shape[1] > 1 else 0.0
AUC(ROC 曲线下面积) :衡量模型区分正负类的能力。AUC 值越接近 1,模型性能越好。
计算 :
roc_auc_score需要真实标签和预测概率(通常是正类的概率)。这里取y_proba[:, 1]即正类的概率。条件判断 :
if y_proba.shape[1] > 1 else 0.0是为了防止在意外情况下(如某些模型只输出一列概率)出错。对于二分类逻辑回归,y_proba通常有两列,所以条件为真。为什么 AUC 不需要设置阈值:AUC 评估的是模型对所有可能阈值的综合表现,不依赖于 0.5 这个固定阈值,因此能更全面地反映模型性能。
首先,我们先看一下**y_pred = self.predict(X)**的具体实现:
python
def predict(self, X: np.ndarray) -> np.ndarray:
"""预测"""
if self.use_scaler:
X_scaled = self.scaler.transform(X)
else:
X_scaled = X
return self.model.predict(X_scaled)-
作用 :调用当前分类器对象的
predict方法,对输入特征矩阵X进行预测,得到每个样本的类别标签 (通常是 0 或 1)。 -
如何工作 :在
LogisticRegressionClassifier中,predict方法首先会根据use_scaler决定是否对X进行标准化(使用训练时拟合好的scaler),然后调用 self.model.predict(X_scaled)。model 是 sklearn 的 LogisticRegression 实例,其 predict 方法返回的是硬分类结果(即概率大于 0.5 的类别)。 -
(注意:这里只调用
transform,不重新拟合,符合机器学习规范)。 -
为什么需要这一步 :要计算准确率、精确率等指标,我们必须知道模型对每个样本的预测类别 ,才能与真实标签
y进行比较。
再看一下**y_proba = self.predict_proba(X)**的具体实现:
python
def predict_proba(self, X: np.ndarray) -> np.ndarray:
"""预测概率"""
if self.use_scaler:
X_scaled = self.scaler.transform(X)
else:
X_scaled = X
return self.model.predict_proba(X_scaled)-
作用 :调用
predict_proba方法,得到每个样本属于各个类别的概率估计 。对于二分类,输出形状为 (n_samples, 2),第一列是类别 0 的概率,第二列是类别 1 的概率。 -
在逻辑回归中的实现 :逻辑回归本身输出的是对数几率,通过 sigmoid 函数转换为概率。sklearn 的 LogisticRegression 提供了 predict_proba 方法,直接返回概率。
LogisticRegressionClassifier的predict_proba同样先处理标准化,然后调用self.model.predict_proba(X_scaled)。 -
为什么需要概率 :AUC(ROC 曲线下面积)需要预测概率而不是硬分类结果,因为它依赖于不同的分类阈值。精确率、召回率等则可以直接使用硬分类结果。
OK,我们来总结一下逻辑回归模型的从创建->训练->评估的全过程:
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, confusion_matrix
1.模型创建:
self.model = LogisticRegression(max_iter=max_iter, random_state=random_state)
2.模型训练:(注意:输入模型进行训练+预测,需要标准化之后的X_scaled)
self.model.fit(X_scaled, y)
3.模型评估:
y_pred = self.model.predict(X_scaled) # 得到每个样本的类别标签(通常是 0 或 1)
y_proba =self.model.predict_proba(X_scaled) # 得到每个样本属于各个类别的概率估计, 对于二分类,输出形状为 (n_samples, 2),第一列是类别 0 的概率,第二列是类别 1 的概率。
metrics = {
'accuracy': accuracy_score(y, y_pred),
'precision': precision_score(y, y_pred, zero_division=0),
'recall': recall_score(y, y_pred, zero_division=0),
'f1': f1_score(y, y_pred, zero_division=0),
'auc': roc_auc_score(y, y_proba:, 1) if y_proba.shape1 > 1 else 0.0
}
什么是逻辑回归模型请见附录7!
此处我有个2个疑问:
pythonlogger.info(f"训练 {model_name}...") classifier = ClassifierFactory.create_classifier(model_name, **params) classifier.fit(X_train, y_train) # 评估 train_metrics = classifier.evaluate(X_train, y_train) val_metrics = classifier.evaluate(X_val, y_val) test_metrics = classifier.evaluate(X_test, y_test) results[model_name] = { 'train': train_metrics, 'val': val_metrics, 'test': test_metrics } logger.info(f"{model_name} - Test Acc: {test_metrics['accuracy']:.4f}, " f"F1: {test_metrics['f1']:.4f}, AUC: {test_metrics['auc']:.4f}")(1)在我的代码中可以看到,我在分类器训练时只对训练集做了训练,但是我在评估模型时分别对训练集、验证集、测试集都进行了评估。
**据我所知:**如果仅将数据集划分为训练集+测试集的方式时,正确的做法是在训练集上训练,然后再测试集上评估即可,这种方式是最简单的。
如果将数据集划分为训练集+验证集+测试集的方式时,我能确定的是仅在训练集上训练模型,但是我不明白为什么要分别在训练集、验证集、测试集上都评估一遍呢?这样是正确的做法吗?有什么好处?目的是为了啥?
解答请见附录8!
(2)一般情况下对于深度学习分类器来看,在模型训练阶段我们需要记录每轮训练损失和验证损失的,最后选取最低验证损失的模型做为最佳模型并在测试集上进行评估的。
但是为啥这里我们同样也是划分了训练集+验证集+测试集,但是却并未记录训练损失和验证损失呢?而是分别在训练集、验证集、测试集上都评估一遍。为啥深度学习与传统机器学习的模型训练评估上做法不一样呢?
解答请见附录9!
3.2 SVM分类器 (RBF核)
(1)类定义与初始化
- 继承自
BaseClassifier:复用基类中的通用属性和方法(如name、scaler、is_fitted、evaluate等),保持接口统一。
python
class SVMClassifier(BaseClassifier):
"""SVM分类器 (RBF核)"""
python
def __init__(self, C: float = 1.0, gamma: str = 'scale', random_state: int = 42, use_scaler: bool = True):
super().__init__("SVM (RBF)")
self.model = SVC(kernel='rbf', C=C, gamma=gamma, probability=True, random_state=random_state)
self.use_scaler = use_scaler-
构造函数,接收四个常用参数,并设置默认值:
-
C:正则化参数的倒数,控制对误分类的惩罚强度。 -
gamma:RBF 核的系数,控制单个样本的影响范围。 -
random_state:随机种子,用于可重复性(SVM 的概率估计涉及随机性)。 -
use_scaler:是否对特征进行标准化(SVM 对特征尺度敏感)。
-
-
调用父类构造函数,传入模型名称
"SVM (RBF)",父类可能初始化self.name、self.scaler = StandardScaler()、self.is_fitted = False等。
-
创建
sklearn.svm.SVC实例,配置如下:-
kernel='rbf':使用径向基函数(RBF)核,将特征映射到高维空间,处理非线性问题。 -
C=C:正则化参数,默认 1.0。 -
gamma=gamma:核系数,可以是数值或'scale'、'auto'。 -
probability=True:启用概率估计(训练后可通过predict_proba输出概率,但会增加训练时间)。 -
random_state=random_state:保证概率估计的可复现性。
-
- 保存标准化标志,供
fit、predict等方法使用。
sklearn.svm.SVC模型构建详解请见附录10!
(2)fit 方法:训练模型
这部分就完全与3.1逻辑回归分类器一样了,代码走的同一个fit()方法。
- 为什么标准化? SVM 试图最大化间隔,特征尺度会影响距离计算。标准化可确保所有特征对决策边界的贡献平等,并加速收敛。
(3)评估模型
同3.1逻辑回归分类器,代码走的同一个evaluate()方法。
注意:
- 无论是逻辑回归分类器还是SVM分类器,评估的时候都是对训练集+验证集+测试集都分别评估了一遍,目的请见附录8!
- 无论是模型训练、还是模型验证+模型测试,输入的都是标准化后的特征。(在训练集上fit,然后transform所有集合)
OK,我们来总结一下SVM模型的从创建->训练->评估的全过程:
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, confusion_matrix
1.模型创建:
self.model = SVC(kernel='rbf', C=C, gamma=gamma, probability=True, random_state=random_state)
2.模型训练:(注意:输入模型进行训练+预测,需要标准化之后的X_scaled)
self.model.fit(X_train_scaled, y_train)
3.模型评估:
y_pred = self.model.predict(X_scaled) # 得到每个样本的类别标签(通常是 0 或 1)
y_proba =self.model.predict_proba(X_scaled) # 得到每个样本属于各个类别的概率估计, 对于二分类,输出形状为
(n_samples, 2),第一列是类别 0 的概率,第二列是类别 1 的概率。metrics = {
'accuracy': accuracy_score(y, y_pred),
'precision': precision_score(y, y_pred, zero_division=0),
'recall': recall_score(y, y_pred, zero_division=0),
'f1': f1_score(y, y_pred, zero_division=0),
'auc': roc_auc_score(y, y_proba:, 1) if y_proba.shape1 > 1 else 0.0
}
相关机器学习知识点1. 支持向量机(SVM)基本原理
核心思想:在高维空间中找到一个超平面,使得不同类别之间的间隔(margin)最大化。
数学形式 :对于线性可分数据,SVM 寻找满足
且
软间隔 :引入松弛变量
2. 核技巧(Kernel Trick)
作用:将数据映射到高维特征空间,使原本线性不可分的问题变得线性可分,而无需显式计算映射。
RBF 核 :
参数
'scale'表示'auto'表示3. 概率输出
- SVM 原本输出的是决策函数值(距离超平面的有符号距离),不直接提供概率。通过设置
probability=True,SVM 会在训练后额外拟合一个 Platt 缩放模型(sigmoid 函数)将决策值映射为概率。这会增加训练时间,但得到概率可用于计算 AUC 或调整阈值。4. 特征标准化的重要性
- SVM 依赖于特征间的内积或距离,如果特征尺度差异大,大尺度特征会主导距离计算,导致决策边界偏向它们。标准化可以消除量纲影响,使每个特征对决策的贡献更均衡。
3.3 随机森林分类器
(1)类定义与初始化
python
class RandomForestClassifier_(BaseClassifier):
"""随机森林分类器"""
def __init__(self, n_estimators: int = 100, max_depth: int = 20, random_state: int = 42):
super().__init__("Random Forest")
self.model = RandomForestClassifier(
n_estimators=n_estimators,
max_depth=max_depth,
random_state=random_state,
n_jobs=-1
)- 定义一个名为
RandomForestClassifier_的类,继承自基类BaseClassifier。基类提供了统一接口(如fit、predict、evaluate)和一些公共属性(name、scaler、is_fitted)。
-
构造函数,接收三个常用超参数并设置默认值:
-
n_estimators:随机森林中决策树的数量,默认 100。 -
max_depth:每棵树的最大深度,默认 20。 -
random_state:随机种子,确保结果可复现。
-
- 调用父类的构造函数,传入模型名称
"Random Forest"。父类会初始化self.name,可能还会初始化self.scaler(虽然这里不用)和self.is_fitted = False。
-
创建
sklearn.ensemble.RandomForestClassifier实例,并传入参数:-
n_estimators、max_depth、random_state保持用户指定值。 -
n_jobs=-1:使用所有可用的 CPU 核心进行并行训练,加速模型构建。
-
-
注意:这里没有传入 use_scaler 参数,因为随机森林作为树模型,不需要特征标准化 (特征尺度不影响决策树的分裂)。
(2)fit 方法:训练模型
python
def fit(self, X: np.ndarray, y: np.ndarray) -> None:
"""训练模型"""
self.model.fit(X, y)
self.is_fitted = True
logger.info(f"{self.name} 训练完成")-
fit方法直接调用底层随机森林模型的fit方法,传入原始特征X和标签y。由于树模型不依赖特征尺度,无需标准化。 -
训练完成后,将
self.is_fitted置为True,并记录日志。
(3)评估模型
python
def predict(self, X: np.ndarray) -> np.ndarray:
"""预测"""
return self.model.predict(X)- 直接调用底层模型的
predict方法,返回类别预测。
python
def predict_proba(self, X: np.ndarray) -> np.ndarray:
"""预测概率"""
return self.model.predict_proba(X)- 直接调用底层模型的
predict_proba方法,返回每个样本属于各个类别的概率。随机森林通过投票或平均各棵树的概率来得到最终概率。
python
def get_feature_importance(self) -> np.ndarray:
"""获取特征重要性"""
return self.model.feature_importances_返回随机森林的特征重要性数组。这是基于每棵树分裂时特征带来的不纯度减少(如基尼系数或信息增益)的加权平均,反映了每个特征对分类的贡献程度。
OK,我们来总结一下随机森林模型的从创建->训练->评估的全过程:
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, confusion_matrix
1.模型创建:
self.model = RandomForestClassifier(
**n_estimators=n_estimators, #**随机森林中决策树的数量
**max_depth=max_depth, #**每棵树的最大深度
**random_state=random_state, #**随机种子,确保结果可复现
**n_jobs=-1 #**使用所有可用的 CPU 核心进行并行训练,加速模型构建
)
2.模型训练:(注意:树模型不依赖特征尺度,训练与预测前X无需标准化。)
self.model.fit(X_train, y_train)
3.模型评估:
y_pred = self.model.predict(X) # 得到每个样本的类别标签(通常是 0 或 1)
y_proba =self.model.predict_proba(X) # 得到每个样本属于各个类别的概率估计, 对于二分类,输出形状为
(n_samples, 2),第一列是类别 0 的概率,第二列是类别 1 的概率。特征重要性数组 = self.model.feature_importances_
metrics = {
'accuracy': accuracy_score(y, y_pred),
'precision': precision_score(y, y_pred, zero_division=0),
'recall': recall_score(y, y_pred, zero_division=0),
'f1': f1_score(y, y_pred, zero_division=0),
'auc': roc_auc_score(y, y_proba:, 1) if y_proba.shape1 > 1 else 0.0
}
关机器学习知识点1. 随机森林(Random Forest)原理
集成学习:随机森林是 Bagging(Bootstrap Aggregating)的代表算法,通过构建多个决策树并综合它们的预测结果来提高准确性和鲁棒性。
构建过程:
对于每棵树,从原始训练集中有放回地抽样(bootstrap)生成一个子数据集。
在每棵树的每个节点分裂时,随机选择一部分特征(通常为
每棵树完整生长,不剪枝(或限制深度、叶子节点样本数等)。
预测方式:分类任务中,采用多数投票;回归任务中,取平均值。
2. 为什么随机森林不需要特征标准化?
决策树的分裂是基于特征值的排序和比较,不涉及距离计算或线性组合,因此特征的绝对大小或分布不影响分裂结果。标准化对树模型无效,甚至可能丢失信息(例如特征的物理含义)。
3. 参数含义
n_estimators:树的数量。越多通常效果越好,但计算成本线性增加,且边际收益递减。
max_depth:限制树的深度,防止过拟合。较深的树可能过拟合,较浅的树可能欠拟合。
random_state:控制 bootstrap 抽样和特征选择的随机性,确保结果可复现。
n_jobs=-1:并行训练,加快速度。4. 特征重要性
- 随机森林可以输出特征重要性,它基于所有树中每个特征带来的平均不纯度减少(或分裂次数)来衡量。这对于特征选择和理解数据非常有帮助。
随机森林分类器详解请见附录11!!
3.4 XGBoost分类器
python
class XGBoostClassifier_(BaseClassifier):
"""XGBoost分类器"""
def __init__(self, n_estimators: int = 100, max_depth: int = 6,
learning_rate: float = 0.1, random_state: int = 42):
super().__init__("XGBoost")
self.model = xgb.XGBClassifier(
n_estimators=n_estimators,
max_depth=max_depth,
learning_rate=learning_rate,
random_state=random_state,
n_jobs=-1,
eval_metric='logloss'
)(1)类定义与初始化
- 定义
XGBoostClassifier_类,继承自基类BaseClassifier。基类提供了统一的接口和公共属性(如name、scaler、is_fitted)。
-
构造函数,接收四个常用超参数,并设置默认值:
-
n_estimators:提升轮数(树的数量),默认 100。 -
max_depth:每棵树的最大深度,默认 6。 -
learning_rate:学习率(步长收缩),默认 0.1。 -
random_state:随机种子,确保结果可复现。
-
- 调用父类构造函数,传入模型名称
"XGBoost",父类会初始化self.name、self.is_fitted等。
-
创建
xgb.XGBClassifier实例,并传入参数:-
n_estimators、max_depth、learning_rate、random_state保持用户指定值。 -
n_jobs=-1:使用所有 CPU 核心进行并行训练,加速模型构建。 -
eval_metric='logloss':指定评估指标为对数损失,用于验证集监控(如果提供eval_set)。
-
-
注意:XGBoost 作为树模型,不需要特征标准化 。
(2)fit 方法:训练模型
python
def fit(self, X: np.ndarray, y: np.ndarray,
eval_set: Optional[Tuple[np.ndarray, np.ndarray]] = None) -> None:
"""训练模型"""
if eval_set is not None:
X_eval, y_eval = eval_set
self.model.fit(X, y, eval_set=[(X_eval, y_eval)], verbose=False)
else:
self.model.fit(X, y, verbose=False)
self.is_fitted = True
logger.info(f"{self.name} 训练完成")-
fit 方法增加了可选的 eval_set 参数,用于传入验证集(特征和标签),以便在训练过程中监控验证集上的 eval_metric。
-
如果提供了
eval_set,则调用fit时传入eval_set=[(X_eval, y_eval)],XGBoost 会在每轮迭代后计算验证集上的指标并记录(可用于早停或监控)。 -
如果没有提供,则直接训练,不进行验证监控。
-
verbose=False关闭训练过程中的详细输出,保持日志整洁。 -
训练完成后,设置
self.is_fitted = True并记录日志。
(3)评估模型
python
def predict(self, X: np.ndarray) -> np.ndarray:
"""预测"""
return self.model.predict(X)- 直接调用底层模型的
predict方法,返回类别预测。
python
def predict_proba(self, X: np.ndarray) -> np.ndarray:
"""预测概率"""
return self.model.predict_proba(X)- 直接调用底层模型的
predict_proba方法,返回每个样本属于各类别的概率。
python
def get_feature_importance(self) -> np.ndarray:
"""获取特征重要性"""
return self.model.feature_importances_- 返回 XGBoost 的特征重要性数组。XGBoost 的特征重要性可以基于
weight(特征被用作分裂的次数)、gain(平均增益)、cover(平均覆盖度)等,默认是weight。
import xgboost as xgb
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, confusion_matrix
1.模型创建:
self.model = xgb.XGBClassifier(
**n_estimators=n_estimators, #**提升轮数(树的数量),默认 100。
**max_depth=max_depth, #**每棵树的最大深度,默认 6。
**learning_rate=learning_rate, #**学习率(步长收缩),默认 0.1。
**random_state=random_state, #**随机种子,确保结果可复现。
**n_jobs=-1, #**使用所有 CPU 核心进行并行训练,加速模型构建。
eval_metric='logloss' # 指定评估指标为对数损失,用于验证集监控(如果提供
eval_set=True)。)
2.模型训练:(注意:树模型不依赖特征尺度,训练与预测前X无需标准化。)
self.model.fit(X_train, y_train)
3.模型评估:
y_pred = self.model.predict(X) # 得到每个样本的类别标签(通常是 0 或 1)
y_proba =self.model.predict_proba(X) # 得到每个样本属于各个类别的概率估计, 对于二分类,输出形状为
(n_samples, 2),第一列是类别 0 的概率,第二列是类别 1 的概率。特征重要性数组 = self.model.feature_importances_
metrics = {
'accuracy': accuracy_score(y, y_pred),
'precision': precision_score(y, y_pred, zero_division=0),
'recall': recall_score(y, y_pred, zero_division=0),
'f1': f1_score(y, y_pred, zero_division=0),
'auc': roc_auc_score(y, y_proba:, 1) if y_proba.shape1 > 1 else 0.0
}
相关机器学习知识点1. XGBoost 是什么?
XGBoost(eXtreme Gradient Boosting)是一种基于**梯度提升决策树(GBDT)**的优化算法,它通过迭代地添加决策树来拟合前一轮的残差,从而逐步减小损失函数。XGBoost 在 GBDT 的基础上引入了正则化、二阶泰勒展开、并行计算、缺失值处理等优化,使其在速度和精度上表现优异,成为 Kaggle 竞赛和工业界最常用的算法之一。
2. 核心参数含义
n_estimators:提升迭代次数,即树的数量。越多通常效果越好,但可能过拟合,且训练时间增加。
max_depth:树的最大深度。控制模型复杂度,过深易过拟合,过浅可能欠拟合。
learning_rate(也称eta):每棵树的贡献权重,通常与n_estimators配合使用。较小的学习率需要更多的树来达到相同效果,但泛化能力更好。
eval_metric:验证集评估指标。'logloss'是对数损失,适用于二分类;也可用'error'(分类错误率)、'auc'等。
n_jobs:并行线程数,-1表示使用所有 CPU 核心。
random_state:随机种子,保证可复现性。3. 为什么树模型不需要标准化?
决策树和基于树的集成方法(如随机森林、XGBoost)通过特征值的大小关系进行分裂,不涉及距离计算,因此特征的绝对尺度不影响分裂结果。标准化不仅不必要,还可能丢失特征的原始含义。
4. 验证集监控与早停
在
fit中传入eval_set,XGBoost 会在每轮迭代后计算指定指标。可以结合early_stopping_rounds参数(当前代码未设置)实现早停:若验证集指标连续early_stopping_rounds轮不提升,则停止训练,并恢复最佳模型。这有助于防止过拟合,并节省训练时间。
5. 特征重要性
XGBoost 提供了多种特征重要性计算方式:
weight:特征被用作分裂的次数。
gain:使用特征分裂带来的平均增益(信息增益)。
cover:特征分裂时覆盖的样本数量加权平均。通过
get_feature_importance可以分析哪些特征对模型贡献最大。xgboost.XGBClassifier详细学习请见附录12!!
3.5 LightGBM分类器
(1)类定义与初始化
python
class LightGBMClassifier_(BaseClassifier):
"""LightGBM分类器"""
def __init__(self, n_estimators: int = 100, max_depth: int = 6,
learning_rate: float = 0.1, random_state: int = 42):
super().__init__("LightGBM")
self.model = lgb.LGBMClassifier(
n_estimators=n_estimators,
max_depth=max_depth,
learning_rate=learning_rate,
random_state=random_state,
n_jobs=-1,
verbose=-1
)-
定义一个名为
LightGBMClassifier_的类,继承自基类BaseClassifier,保持与实验框架一致的接口。 -
构造函数接收四个常用超参数,并设置默认值:
-
n_estimators:提升迭代次数(树的数量),默认 100。 -
max_depth:树的最大深度,默认 6。注意:LightGBM 的max_depth与 XGBoost 类似,但它的默认生长策略是leaf-wise,深度限制可能与其他框架略有不同。 -
learning_rate:学习率(步长收缩),默认 0.1。 -
random_state:随机种子,确保结果可复现。
-
- 调用父类构造函数,传入模型名称
"LightGBM"。父类会初始化self.name、self.scaler(虽然 LightGBM 不需要标准化)、self.is_fitted = False等。
-
创建
lightgbm.LGBMClassifier实例,并传入参数:-
n_estimators、max_depth、learning_rate、random_state保持用户指定值。 -
n_jobs=-1:使用所有 CPU 核心进行并行训练。 -
verbose=-1:设置日志输出级别为 -1,表示关闭所有 LightGBM 内部日志(静默模式),避免在控制台输出大量训练信息。
-
-
LightGBM 同样是基于树的模型,不需要特征标准化 。
(2)fit 方法:训练模型
这部分完全同XGBoost分类器的训练过程相同!
-
fit方法接收特征X、标签y,以及可选的验证集eval_set(特征和标签的元组)。 -
如果提供了
eval_set,则将其包装成列表传入eval_set参数,LightGBM 会在每轮迭代后计算验证集上的默认指标(如二分类的logloss或auc),并可用于早停或监控。 -
如果没有提供,则直接训练。
(3)评估模型
这部分完全同XGBoost分类器的评估过程相同!
python
def predict(self, X: np.ndarray) -> np.ndarray:
"""预测"""
return self.model.predict(X)- 直接调用底层模型的
predict方法,返回类别预测(0 或 1)。
python
def predict_proba(self, X: np.ndarray) -> np.ndarray:
"""预测概率"""
return self.model.predict_proba(X)- 直接调用底层模型的
predict_proba方法,返回概率矩阵,形状为(n_samples, 2)。
python
def get_feature_importance(self) -> np.ndarray:
"""获取特征重要性"""
return self.model.feature_importances_- 返回 LightGBM 的特征重要性数组。LightGBM 默认使用
split次数(即特征被用作分裂的次数)作为重要性,也可以通过设置importance_type参数改变(如gain表示平均增益)。
import lightgbm as lgb
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, confusion_matrix
1.模型创建:
self.model = lgb.LGBMClassifier(
**n_estimators=n_estimators, #**提升迭代次数(树的数量),默认 100。
max_depth=max_depth, # 树的最大深度,默认 6。注意:LightGBM 的
max_depth与 XGBoost 类似,但它的默认生长策略是leaf-wise,深度限制可能与其他框架略有不同。**learning_rate=learning_rate, #**学习率(步长收缩),默认 0.1。
**random_state=random_state, #**随机种子,确保结果可复现。
**n_jobs=-1, #**使用所有 CPU 核心进行并行训练
**verbose=-1 #**设置日志输出级别为 -1,表示关闭所有 LightGBM 内部日志(静默模式),避免在控制台输出大量训练信息。
)
2.模型训练:(注意:树模型不依赖特征尺度,训练与预测前X无需标准化。)
self.model.fit(X_train, y_train)
3.模型评估:
y_pred = self.model.predict(X) # 得到每个样本的类别标签(通常是 0 或 1)
y_proba =self.model.predict_proba(X) # 得到每个样本属于各个类别的概率估计, 对于二分类,输出形状为
(n_samples, 2),第一列是类别 0 的概率,第二列是类别 1 的概率。特征重要性数组 = self.model.feature_importances_
metrics = {
'accuracy': accuracy_score(y, y_pred),
'precision': precision_score(y, y_pred, zero_division=0),
'recall': recall_score(y, y_pred, zero_division=0),
'f1': f1_score(y, y_pred, zero_division=0),
'auc': roc_auc_score(y, y_proba:, 1) if y_proba.shape1 > 1 else 0.0
}
LightGBM 相关机器学习知识点1. LightGBM 是什么?
LightGBM(Light Gradient Boosting Machine)是由微软开源的梯度提升框架,与 XGBoost 类似,也是一种基于决策树的集成学习算法。它在训练速度和内存效率上进行了大量优化,尤其适合大规模数据。
2. LightGBM 的核心特点
基于直方图的算法:将连续特征离散化为直方图桶,大大减少了内存消耗和计算复杂度。
Leaf-wise 生长策略 :大多数 GBDT 实现采用 level-wise 生长(按层生长),而 LightGBM 采用 leaf-wise 生长,每次从当前所有叶子中找到分裂增益最大的叶子进行分裂。这可以更快地降低损失,但容易过拟合,因此通常需要限制
max_depth或使用num_leaves来控制。支持类别特征 :可以直接输入类别特征,无需 one-hot 编码,通过
categorical_feature参数指定。并行学习:支持特征并行和数据并行,加速训练。
处理缺失值:自动学习缺失值的最佳分裂方向。
3. 常用参数详解
n_estimators:提升迭代次数,即树的数量。
max_depth:树的最大深度,用于控制过拟合。注意 leaf-wise 生长时,深度限制可能不如num_leaves有效。
learning_rate:学习率,通常与n_estimators配合调整。
num_leaves:每棵树的最大叶子数,是控制模型复杂度的关键参数,默认 31。通常num_leaves小于
min_child_samples/min_child_weight:叶子节点所需的最小样本数/权重和,用于防止过拟合。
subsample/bagging_fraction:训练每棵树时对样本的采样比例,用于增加随机性。
colsample_bytree/feature_fraction:训练每棵树时对特征的采样比例。
reg_alpha、reg_lambda:L1/L2 正则化系数。
n_jobs:并行线程数。
verbose:控制日志输出级别,-1 表示静默,0 表示仅输出警告,1 表示输出基本信息。4. 为什么 LightGBM 不需要特征标准化?
与所有基于树的模型一样,LightGBM 只关心特征值的相对顺序,不涉及距离计算,因此特征的尺度不影响分裂结果,标准化非必需。
有关LigtGBM分类器的学习请见附录13!!
4.运行深度学习模型
函数签名
def run_dl_comparison(X_train: np.ndarray, y_train: np.ndarray,
X_val: np.ndarray, y_val: np.ndarray,
X_test: np.ndarray, y_test: np.ndarray,
output_dir: str = './results',
epochs: int = 50, batch_size: int = 32) -> dict:-
功能:运行多个深度学习模型(MLP、BiLSTM、Transformer、ResNet1D)的对比实验。
-
参数:
-
X_train, y_train:训练集特征和标签(NumPy 数组,已标准化)。 -
X_val, y_val:验证集特征和标签。 -
X_test, y_test:测试集特征和标签。 -
output_dir:保存结果和模型的目录。 -
epochs:最大训练轮数。 -
batch_size:批大小。
-
-
返回:字典,键为模型名称,值为测试集指标和训练历史。
-
日志和输出目录准备
logger.info("\n" + "="*80)
logger.info("深度学习模型对比")
logger.info("="*80)Path(output_dir).mkdir(parents=True, exist_ok=True)
-
打印醒目标题,标记深度学习对比开始。
-
确保输出目录存在,若不存在则递归创建(
parents=True),且不因已存在而报错(exist_ok=True)。
Path对象的用法可见附录2!!
2. 获取输入维度
input_dim = X_train.shape[1]
logger.info(f"输入特征维度: {input_dim}")- 从训练集特征中获取特征数量,用于定义模型输入层大小。
3. 转换为 PyTorch 张量
X_train_t = torch.tensor(X_train, dtype=torch.float32)
y_train_t = torch.tensor(y_train, dtype=torch.long)
X_val_t = torch.tensor(X_val, dtype=torch.float32)
y_val_t = torch.tensor(y_val, dtype=torch.long)-
将 NumPy 数组转换为 PyTorch 张量。
-
特征使用
float32类型(深度学习常用精度),标签使用long类型(分类交叉熵损失要求)。
记住:在深度学习中最常用的是
torch.float32和torch.long(int64)!Python、NumPy和PyTorch的默认数据类型对比(整数+浮点数)请见:
https://blog.csdn.net/m0_59777389/article/details/154386670?spm=1011.2415.3001.5331
的章节4部分

4. 创建 DataLoader
train_dataset = TensorDataset(X_train_t, y_train_t)
val_dataset = TensorDataset(X_val_t, y_val_t)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size)-
TensorDataset将特征和标签包装成数据集,便于按索引取样本。 -
DataLoader负责批量加载数据:-
batch_size:每批样本数。 -
shuffle=True:训练集打乱顺序,增加随机性,防止模型记住样本顺序。 -
验证集不需要打乱,因此
shuffle=False(默认)。
-
有关torch.utils.data.TensorDataset的用法请见 LSTM模型做分类任务2(PyTorch实现)这篇博客的第5节! 或者附录14的介绍!
5. 定义待比较的深度学习模型
dl_models = [
('mlp', {'hidden_dims': [512, 256, 128]}),
('bilstm', {'hidden_dim': 128, 'num_layers': 2}),
('transformer', {'d_model': 128, 'nhead': 4, 'num_layers': 2}),
('resnet1d', {'num_blocks': 3})
]-
每个元组包含模型名称和参数字典。
-
这些参数将传递给
ClassifierFactory.create_dl_model,用于实例化具体模型。
6. 遍历每个模型
results = {}
for model_name, params in dl_models:
try:
logger.info(f"\n训练 {model_name}...")
# 创建模型
model = ClassifierFactory.create_dl_model(model_name, input_dim=input_dim, **params)
# 训练
trainer = DeepLearningTrainer(model, learning_rate=0.001)
history = trainer.fit(train_loader, val_loader, epochs=epochs, patience=15)
# 评估(使用批处理避免内存溢出)
test_pred, test_proba = trainer.predict(X_test, batch_size=batch_size)
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
test_metrics = {
'accuracy': float(accuracy_score(y_test, test_pred)),
'precision': float(precision_score(y_test, test_pred, zero_division=0)),
'recall': float(recall_score(y_test, test_pred, zero_division=0)),
'f1': float(f1_score(y_test, test_pred, zero_division=0)),
'auc': float(roc_auc_score(y_test, test_proba[:, 1]))
}
results[model_name] = {
'test': test_metrics,
'history': history
}
logger.info(f"{model_name} - Test Acc: {test_metrics['accuracy']:.4f}, "
f"F1: {test_metrics['f1']:.4f}, AUC: {test_metrics['auc']:.4f}")
# 保存模型
model_path = Path(output_dir) / f'{model_name}_best_model.pth'
trainer.save_model(str(model_path))
except Exception as e:
logger.error(f"训练 {model_name} 时出错: {e}")
import traceback
traceback.print_exc()
continue-
创建模型:通过工厂方法创建指定模型,传入输入维度和参数字典。
-
创建训练器 :
DeepLearningTrainer封装了训练循环,学习率设为 0.001。 -
训练 :调用
trainer.fit,传入训练和验证 DataLoader,最大轮数epochs,早停耐心值patience=15。返回训练历史(每轮损失等)。 -
预测:用训练好的模型对测试集进行预测(批处理避免内存不足),得到预测类别和概率。
-
计算指标 :使用 sklearn 的指标函数计算准确率、精确率、召回率、F1 和 AUC。注意
zero_division=0防止除零错误。 -
存储结果:将测试指标和历史存入字典。
-
保存模型 :调用
trainer.save_model保存最佳模型(通常早停时保存的最佳模型)。 -
异常处理:如果某个模型训练失败,记录错误并跳过,继续下一个模型。
相关机器学习知识点
1. 深度学习训练流程
数据准备:将原始数据转换为张量,用 DataLoader 批量加载,训练时打乱顺序增加随机性。
模型定义:根据任务选择合适的神经网络架构(MLP、LSTM、Transformer、ResNet)。
损失函数与优化器 :通常分类任务用交叉熵损失,优化器如 Adam(
DeepLearningTrainer内部可能默认使用 Adam)。训练循环:每个 epoch 遍历训练集,前向传播、计算损失、反向传播、更新参数。每个 epoch 后在验证集上评估,监控过拟合。
早停 :当验证集损失连续
patience轮不再下降时停止训练,并恢复最佳模型参数,防止过拟合。2. 评估指标
准确率:预测正确的比例,但类别不平衡时可能误导。
精确率:预测为正类的样本中实际为正的比例,衡量误报情况。
召回率:实际为正类的样本中被正确预测的比例,衡量漏报情况。
F1 分数:精确率和召回率的调和平均,综合衡量。
AUC:ROC 曲线下面积,衡量模型区分正负类的能力,不受分类阈值影响。
3. PyTorch 数据加载机制
TensorDataset和DataLoader是 PyTorch 中常用的数据加载方式,适合小数据集。对于大数据集,通常使用自定义 Dataset 类。
DataLoader支持多线程预加载,num_workers参数可加速,但此处未设置(默认 0),可能成为瓶颈。4. 模型保存
通常保存最佳模型(验证损失最低的 epoch)的参数,以便后续部署或继续训练。
.pth文件存储模型状态字典(state_dict)。
Bug 分析
未加载最佳模型进行预测
trainer.fit返回history,但trainer.predict使用的是训练结束时的模型还是早停恢复的最佳模型?这取决于DeepLearningTrainer的实现。如果它内部实现了早停并加载最佳模型,则预测正确;否则可能使用最后一轮模型,导致评估结果不是最优的。建议 :检查
DeepLearningTrainer的fit方法,确保它保存了最佳模型并在predict中使用该模型。或者在fit后显式加载最佳模型再预测。验证集评估未在训练循环外进行
- 当前代码只在训练循环内部通过
trainer.fit监控验证损失,但在训练结束后没有单独对验证集进行评估并保存指标。如果希望输出验证集指标(如之前传统 ML 那样),此处缺少。不过最终只关心测试集,问题不大,但不利于分析过拟合。未指定设备(GPU/CPU)
代码中没有将模型和数据移动到 GPU 的语句,可能默认使用 CPU,训练会很慢。
DeepLearningTrainer内部可能自动检测 GPU,但最好显式设置。建议:在训练器中添加设备参数,或确保模型和数据能自动迁移。
from sklearn.metrics导入位置
- 在循环内导入 sklearn 函数,每次都会重复导入,虽然不影响功能但稍显低效。建议移至文件顶部。
数据类型假设
- 假设标签是
long,但y_test可能是整数数组,转换没问题。但注意分类数必须与模型输出一致(二分类)。缺失值处理
- 特征数据已标准化,但未检查是否存在 NaN 或 Inf,可能导致训练失败。
内存问题
trainer.predict(X_test, batch_size)使用批处理避免内存溢出,但如果X_test非常大,仍需注意显存或内存限制。批处理大小应与训练一致。
0.DeepLearningTrainer类
(1) __init__ 方法
def __init__(self, model: nn.Module, device: str = 'cuda' if torch.cuda.is_available() else 'cpu',
learning_rate: float = 0.001, weight_decay: float = 1e-5):-
构造函数,接收模型、设备、学习率和权重衰减。
-
device默认自动选择 GPU(如果可用),否则 CPU。self.model = model.to(device) self.device = device self.optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay) self.criterion = nn.CrossEntropyLoss() self.history = {'train_loss': [], 'val_loss': [], 'val_acc': []} self.best_model_state = None -
将模型移动到指定设备(GPU/CPU),并保存设备信息。
-
使用 Adam 优化器,传入模型参数、学习率和 L2 正则化系数
weight_decay。 -
交叉熵损失函数,适用于多分类(包括二分类),内部结合了 Softmax。
-
history:记录训练过程中的损失和验证准确率。 -
best_model_state:用于保存验证损失最低时的模型参数(CPU 上的副本),以便早停后恢复。
(2)train_epoch 方法
def train_epoch(self, train_loader: DataLoader) -> float:
"""训练一个epoch"""
self.model.train()
total_loss = 0.0-
设置模型为训练模式(启用 Dropout 等)。
-
初始化总损失。
for X_batch, y_batch in train_loader: X_batch = X_batch.to(self.device) y_batch = y_batch.to(self.device) -
遍历 DataLoader,将数据移动到设备。
self.optimizer.zero_grad() outputs = self.model(X_batch) loss = self.criterion(outputs, y_batch) loss.backward() # 梯度裁剪,防止梯度爆炸 torch.nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=1.0) self.optimizer.step() total_loss += loss.item() -
清零梯度,前向传播得到 logits,计算损失,反向传播。
-
梯度裁剪,限制梯度的最大范数,防止梯度爆炸导致训练不稳定。
-
更新参数,累加当前 batch 的损失值。
return total_loss / len(train_loader) -
返回当前 epoch 的平均训练损失。
梯度爆炸是啥?为啥梯度裁剪能防止梯度爆炸?如何裁剪的?请见附录15!
(3)validate 方法
def validate(self, val_loader: DataLoader) -> Tuple[float, float]:
"""验证"""
self.model.eval()
total_loss = 0.0
correct = 0
total = 0-
设置模型为评估模式(关闭 Dropout 等)。
-
初始化损失和正确计数。
with torch.no_grad(): for X_batch, y_batch in val_loader: X_batch = X_batch.to(self.device) y_batch = y_batch.to(self.device) outputs = self.model(X_batch) loss = self.criterion(outputs, y_batch) total_loss += loss.item() _, predicted = torch.max(outputs.data, 1) total += y_batch.size(0) correct += (predicted == y_batch).sum().item() -
禁用梯度计算,加快推理并节省内存。
-
对每个 batch 计算损失和预测,累加正确数。
avg_loss = total_loss / len(val_loader) accuracy = correct / total return avg_loss, accuracy
返回平均验证损失和准确率。
(4)fit 方法
def fit(self, train_loader: DataLoader, val_loader: DataLoader,
epochs: int = 50, patience: int = 10) -> Dict[str, List]:
"""训练模型"""
best_val_loss = float('inf')
patience_counter = 0-
初始化最佳验证损失和早停计数器。
for epoch in range(epochs): train_loss = self.train_epoch(train_loader) val_loss, val_acc = self.validate(val_loader) self.history['train_loss'].append(train_loss) self.history['val_loss'].append(val_loss) self.history['val_acc'].append(val_acc) -
每个 epoch 训练并验证,记录指标。
if (epoch + 1) % 10 == 0: logger.info(f"Epoch {epoch+1}/{epochs} - Train Loss: {train_loss:.4f}, " f"Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.4f}") -
每 10 个 epoch 打印一次进度(避免日志过多)。
# 早停并保存最佳模型 if val_loss < best_val_loss: best_val_loss = val_loss patience_counter = 0 # 保存最佳模型状态 self.best_model_state = {k: v.cpu().clone() for k, v in self.model.state_dict().items()} else: patience_counter += 1 if patience_counter >= patience: logger.info(f"早停触发,在epoch {epoch+1}") # 恢复最佳模型 if self.best_model_state is not None: self.model.load_state_dict(self.best_model_state) logger.info("已恢复最佳模型权重") break -
如果验证损失下降,则更新最佳损失,重置计数器,并保存模型状态(复制到 CPU 防止 GPU 内存变化)。
-
如果验证损失未改善,计数器加一,达到耐心值则早停,并恢复最佳模型权重,退出循环。
return self.history -
返回训练历史。
我的代码这里保存最佳模型的代码是:self.best_model_state = {k: v.cpu().clone() for k, v in self.model.state_dict().items()}、在此之前我保存最佳模型的代码都是:torch.save(model.state_dict(), model_save_path)、
这两种写法有啥不一样的地方?self.best_model_state = {k: v.cpu().clone() for k, v in self.model.state_dict().items()}这行代码里的k, v到底是什么?
请见附录16!!!
(5)evaluate方法
def evaluate(self, test_loader: DataLoader) -> Dict[str, float]:
"""评估模型(计算完整指标)"""
self.model.eval()-
将模型设置为评估模式(关闭 Dropout 等)。
-
返回类型为字典,键为指标名,值为浮点数。
all_preds = [] all_proba = [] all_labels = []
初始化三个空列表,分别用于存储所有样本的预测类别、预测概率和真实标签。
with torch.no_grad():
for X_batch, y_batch in test_loader:
X_batch = X_batch.to(self.device)
y_batch = y_batch.to(self.device)-
使用
torch.no_grad()禁用梯度计算,减少内存消耗并加速推理。 -
遍历测试集 DataLoader,每次获取一个 batch 的特征
X_batch和标签y_batch,并将其移动到指定设备(CPU 或 GPU)。outputs = self.model(X_batch) proba = torch.softmax(outputs, dim=1).cpu().numpy() pred = np.argmax(proba, axis=1) -
前向传播,得到 logits(形状
(batch_size, num_classes))。 -
对 logits 应用 Softmax 函数,将其转换为概率分布(形状同上),并转换为 NumPy 数组,同时将数据移至 CPU。
-
取每个样本概率最大的类别作为预测结果(对于二分类,若概率大于 0.5 则预测为 1,否则为 0)。
all_preds.append(pred) all_proba.append(proba) all_labels.append(y_batch.cpu().numpy()) -
将当前 batch 的预测类别、概率和真实标签(转为 NumPy 并移至 CPU)分别添加到列表中。
y_true = np.concatenate(all_labels) y_pred = np.concatenate(all_preds) y_proba = np.concatenate(all_proba) -
将所有 batch 的结果沿轴 0 拼接,得到整个测试集上的完整真实标签、预测类别和预测概率。
metrics = { 'accuracy': float(accuracy_score(y_true, y_pred)), 'precision': float(precision_score(y_true, y_pred, zero_division=0)), 'recall': float(recall_score(y_true, y_pred, zero_division=0)), 'f1': float(f1_score(y_true, y_pred, zero_division=0)), 'auc': float(roc_auc_score(y_true, y_proba[:, 1])) } return metrics -
使用 sklearn 的评估函数计算准确率、精确率、召回率、F1 分数和 AUC(对于二分类,取正类的概率列
y_proba[:, 1])。 -
zero_division=0避免在分母为零(如没有预测为正类的样本)时产生警告或错误。 -
将所有指标转换为 Python 浮点数并返回。

1.MLPClassifier 类
此时的训练器结构如下:

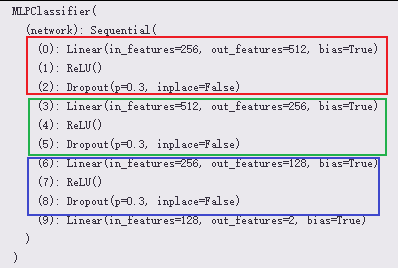
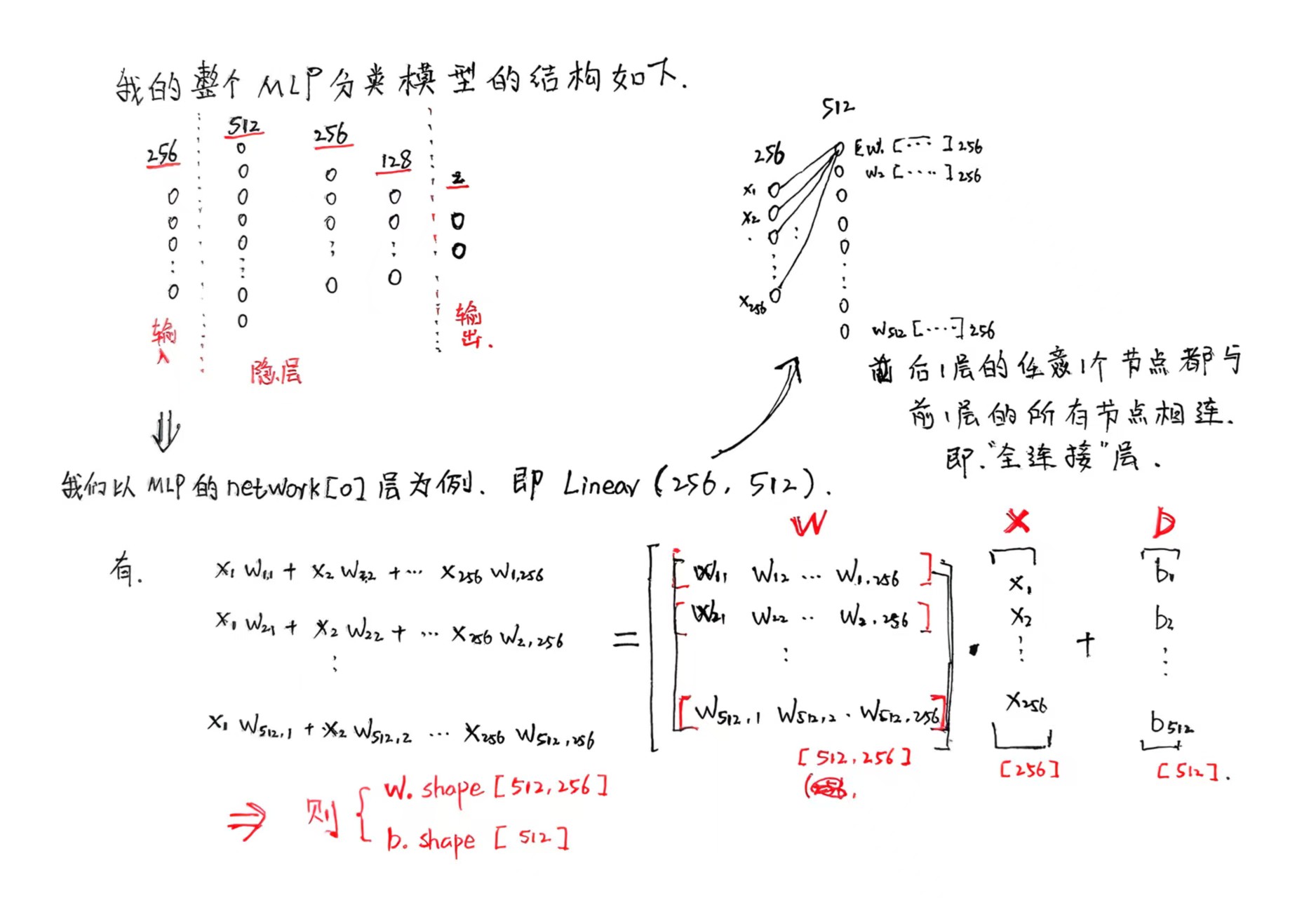
经过我查看发现确定跟我推理的一致,如下:

节点特征X变化过程:(batch_size=16)
x shape: (batch_size, input_dim) = **(16,256)#**原始输入
↓
MLPClassifier(
(network): Sequential(
(0): Linear(in_features=256, out_features=512, bias=True)
(1): ReLU()
(2): Dropout(p=0.3, inplace=False)
(3): Linear(in_features=512, out_features=256, bias=True)
(4): ReLU()
(5): Dropout(p=0.3, inplace=False)
(6): Linear(in_features=256, out_features=128, bias=True)
(7): ReLU()
(8): Dropout(p=0.3, inplace=False)
(9): Linear(in_features=128, out_features=2, bias=True)
)) # 3层的一个MLP分类模型
↓
outputs = (16,2) → loss = self.criterion(outputs, y_batch) # 求批次平均损失(每一轮进行一次训练+验证,进行epochs轮)
↓ 评估(只进行一轮)
torch.softmax(outputs, dim=1).cpu().numpy()
↓
proba = (16,2)# 转换为概率分布
↓
np.argmax(proba, axis=1)
↓
pred = (16,) # 获取概率最大的索引
(1)类定义与初始化
class MLPClassifier(nn.Module):
"""多层感知机分类器"""
def __init__(self, input_dim: int = 256, hidden_dims: List[int] = None, dropout: float = 0.3):
super().__init__()-
继承
nn.Module:这是 PyTorch 中所有神经网络模块的基类,提供参数管理、训练/评估模式切换等功能。 -
构造函数参数:
-
input_dim:输入特征维度,默认 256。 -
hidden_dims:隐藏层维度列表,若为None则使用默认[512, 256, 128]。 -
dropout:Dropout 概率,默认 0.3,表示随机丢弃 30% 的神经元输出。if hidden_dims is None: hidden_dims = [512, 256, 128]
-
若未提供隐藏层结构,则使用默认的三层结构:512 → 256 → 128 神经元。
layers = []
prev_dim = input_dim
for hidden_dim in hidden_dims:
layers.append(nn.Linear(prev_dim, hidden_dim))
layers.append(nn.ReLU())
layers.append(nn.Dropout(dropout))
prev_dim = hidden_dim-
循环构建隐藏层:
-
nn.Linear(prev_dim, hidden_dim):全连接层,将输入从prev_dim维映射到hidden_dim维。 -
nn.ReLU():激活函数 ReLU(max(0, x)),引入非线性,使网络能学习复杂模式。 -
nn.Dropout(dropout):Dropout 层,在训练时以概率dropout随机将神经元输出置零,防止过拟合。测试时自动不生效。
-
-
每层之后更新
prev_dim为当前层输出维度,作为下一层的输入维度。layers.append(nn.Linear(prev_dim, 2)) # 二分类 -
最后添加输出层:
Linear(prev_dim, 2),输出 2 个 logit(分别对应类别 0 和 1),因为没有激活函数,后续损失函数会结合 Softmax 使用。self.network = nn.Sequential(*layers) -
将所有层封装进
nn.Sequential容器,简化前向传播。
(2)forward 方法
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""前向传播"""
return self.network(x)- 直接调用
self.network(x),即按顺序执行所有层,输出未归一化的 logits。
相关机器学习知识点
1. 多层感知机(MLP)
也称为全连接神经网络,由输入层、若干隐藏层和输出层组成。
每个隐藏层通过权重矩阵和偏置将输入线性变换,再经过非线性激活函数,使得网络能够逼近任意非线性函数(通用近似定理)。
2. 激活函数:ReLU
公式:
ReLU(x) = max(0, x)。优点:计算简单,缓解梯度消失,使部分神经元输出稀疏,有利于训练。
缺点:可能导致神经元"死亡"(输出恒为 0),可通过合理初始化或 Leaky ReLU 缓解。
3. Dropout
训练时以概率
p随机丢弃神经元(置零),相当于每次训练不同的子网络,增强泛化能力。测试时,所有神经元参与计算,但输出需乘以
(1-p)(PyTorch 自动处理,无需手动调整)。4. 输出层与损失函数
二分类输出通常用 2 个神经元,配合
CrossEntropyLoss,该损失函数内部会自动应用 Softmax 将 logits 转换为概率,并计算交叉熵。也可以输出单个神经元,用
BCEWithLogitsLoss,但代码中输出 2 个神经元更通用。5. 神经网络训练流程
前向传播:
output = model(x)计算损失:
loss = criterion(output, y)反向传播:
loss.backward()更新参数:
optimizer.step()清零梯度:
optimizer.zero_grad()
学到这里,我重新总结一下什么是多层感知机MLP,请见附录17!!
2.BiLSTMClassifier类
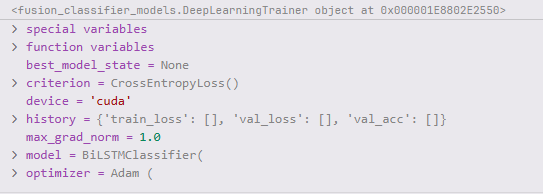

BiLSTMClassifier模型结构:
BiLSTMClassifier(
(lstm): LSTM(8, 128, num_layers=2, batch_first=True, dropout=0.3, bidirectional=True) # lstm层(单层+双向)(attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
) # 多头注意力层
(fc): Sequential(
(0): Linear(in_features=256, out_features=128, bias=True)
(1): ReLU()
(2): Dropout(p=0.3, inplace=False)
(3): Linear(in_features=128, out_features=2, bias=True)
) # 分类头(全连接层)
)
节点特征X在前向传播中的变化过程:x shape: (batch_size, input_dim) = **(16,256)#**原始输入
↓
x.view(batch_size, self.seq_len, self.feature_per_step) # 重塑形状了
将 256 维特征均匀分成 32 个时间步,每个时间步有 8 个特征,构成一个"伪序列"。
↓
x_reshape = = (16,32,8)
↓ 输入
LSTM(8, 128, num_layers=2, batch_first=True, dropout=0.3, bidirectional=True) # 1层lstm双向
↓
lstm_out :(batch_size, seq_len, hidden_dim*2) = (16,32,256)
每个时间步的隐藏状态是前向和后向 LSTM 隐藏状态的拼接,因此维度翻倍为 256。
↓
MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
) # 注意力机制层
作用:让每个时间步根据所有时间步的信息重新加权,增强上下文表示。
↓
attn_out = (16,32,256)
↓
attn_out.mean(dim=1) # 全局平均池化层
对序列维度
dim=1取平均,将序列压缩为一个向量。↓
pooled:(batch_size, hidden_dim*2) = (16,256)
↓
Sequential(
(0): Linear(in_features=256, out_features=128, bias=True)
(1): ReLU()
(2): Dropout(p=0.3, inplace=False)
(3): Linear(in_features=128, out_features=2, bias=True)
) # 全连接层(二分类)
最终输出是 logits(未归一化),形状
(16, 2)。
↓output = (16,2)
↓
后面再做模型训练+验证、还是评估,处理国臣就都一样了,请见1.MLPClassifer类
(1)类定义与初始化
class BiLSTMClassifier(nn.Module):
"""BiLSTM分类器 - 用于序列特征处理
注意:BiLSTM需要将256维特征reshape为序列形式,这可能破坏特征的原始含义。
对于融合特征,建议优先使用MLP或Transformer。
"""-
定义一个名为
BiLSTMClassifier的类,继承自nn.Module。 -
注释明确指出:BiLSTM 要求将输入特征重构成序列,这可能会破坏原始特征的结构化信息,因此对于融合特征(可能是无序的),MLP 或 Transformer 更合适。
def __init__(self, input_dim: int = 256, hidden_dim: int = 128, num_layers: int = 2, dropout: float = 0.3, seq_len: int = 32): super().__init__() -
构造函数接收参数:
-
input_dim:输入特征维度,默认 256。 -
hidden_dim:LSTM 隐藏层维度,默认 128。 -
num_layers:LSTM 层数,默认 2。 -
dropout:Dropout 概率,默认 0.3。 -
seq_len:序列长度,即将input_dim划分成多少个时间步,默认 32。# 将256维特征reshape为序列形式 # 将256维分成seq_len个时间步,每步feature_per_step维 self.seq_len = seq_len self.feature_per_step = input_dim // self.seq_len if input_dim % self.seq_len != 0: raise ValueError(f"input_dim ({input_dim}) 必须能被 seq_len ({self.seq_len}) 整除")
-
-
计算每个时间步的特征维度:
feature_per_step = input_dim / seq_len(整数除法)。 -
检查输入维度是否能被
seq_len整除,如果不能则抛出异常,因为无法均匀分割。self.lstm = nn.LSTM( input_size=self.feature_per_step, hidden_size=hidden_dim, num_layers=num_layers, bidirectional=True, dropout=dropout if num_layers > 1 else 0, batch_first=True ) -
定义双向 LSTM 层:
-
input_size:每个时间步的输入特征数 =feature_per_step。 -
hidden_size:隐藏状态维度 =hidden_dim。 -
num_layers:LSTM 层数。 -
bidirectional=True:双向 LSTM,输出维度变为hidden_size * 2。 -
dropout:除最后一层外,层间 dropout。如果num_layers为 1,则 dropout 设为 0(无意义)。 -
batch_first=True:输入和输出的形状为(batch, seq_len, features)。self.attention = nn.MultiheadAttention( embed_dim=hidden_dim * 2, num_heads=4, dropout=dropout, batch_first=True )
-
-
定义多头自注意力层:
-
embed_dim:输入特征的维度,即 LSTM 输出的维度(双向 LSTM 输出为hidden_dim * 2)。 -
num_heads=4:4 个注意力头,embed_dim必须能被num_heads整除。 -
dropout:注意力权重的 dropout。 -
batch_first=True:输入形状为(batch, seq_len, embed_dim)。self.fc = nn.Sequential( nn.Linear(hidden_dim * 2, 128), nn.ReLU(), nn.Dropout(dropout), nn.Linear(128, 2) # 二分类 )
-
-
定义全连接分类器:
-
第一层线性层:将注意力输出的聚合特征(维度
hidden_dim * 2)映射到 128。 -
ReLU 激活。
-
Dropout(概率
dropout)。 -
输出层:线性映射到 2 个神经元(二分类的 logits)。
-
(2)forward 方法
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""前向传播"""
# x shape: (batch_size, input_dim)
batch_size = x.size(0)
# Reshape为序列形式
x = x.view(batch_size, self.seq_len, self.feature_per_step)-
获取 batch 大小。
-
将输入从
(batch, input_dim)重塑为(batch, seq_len, feature_per_step),模拟一个序列。# LSTM lstm_out, _ = self.lstm(x) # (batch_size, seq_len, hidden_dim*2) -
将重塑后的序列输入 LSTM,得到输出
lstm_out(形状(batch, seq_len, hidden_dim*2)),忽略隐藏状态和细胞状态。# 注意力机制 attn_out, _ = self.attention(lstm_out, lstm_out, lstm_out) -
使用自注意力:查询、键、值都来自 LSTM 输出
lstm_out。输出attn_out形状与输入相同(batch, seq_len, hidden_dim*2)。# 全局平均池化 pooled = attn_out.mean(dim=1) # (batch_size, hidden_dim*2) -
对序列长度维度(dim=1)进行平均池化,将每个样本的序列信息压缩为一个向量。
-
.mean(dim=1):是 PyTorch 张量的mean方法,用于计算平均值。参数dim=1指定沿着第 1 个维度(索引从 0 开始)进行平均。
池化层的作用请见附录19!!!
# 分类
output = self.fc(pooled)
return output- 将池化后的向量通过全连接分类器,得到 logits(形状
(batch, 2))。
相关机器学习知识点
1. 为什么将一维特征视为序列?
BiLSTM 本用于处理序列数据(如文本、时间序列),但此处将 256 维融合特征强行分成 32 个时间步,每步 8 维。这是一种特征重组的尝试,意图让模型捕捉特征间的"局部依赖"。然而,融合特征通常是无序的,这种重组可能破坏特征的原始语义,因此注释中已提示"可能破坏特征的原始含义"。
2. 双向 LSTM
LSTM 是循环神经网络的一种,能捕捉序列中的长期依赖。
双向 LSTM 包含前向和后向两个方向,能利用每个时间步的上下文信息,输出维度为
hidden_size * 2。对于序列任务(如文本),双向 LSTM 效果往往优于单向。
3. 多头自注意力(Multi-head Self-Attention)
注意力机制可以动态地为序列中不同位置赋予不同权重,捕捉全局依赖。
多头注意力让模型从多个子空间学习不同的关系。
在此处,自注意力应用于 LSTM 的输出,相当于让模型关注序列中重要的时间步。
4. 池化(Pooling)
- 全局平均池化将序列压缩为一个固定长度的向量,保留每个时间步的信息平均值。也可用最大池化或加权和。
5. 分类头
- 全连接层将压缩后的特征映射到 2 个 logits,供交叉熵损失使用。
潜在 Bug 与优化建议
input_dim必须能被seq_len整除
- 代码已做检查,这是正确的。但如果用户传入的
seq_len不是input_dim的因数,程序会报错,需要用户自行调整。LSTM 的 dropout 参数
- 当
num_layers > 1时,dropout才有效。代码中已处理:dropout=dropout if num_layers > 1 else 0,正确。注意力层的维度必须能被
num_heads整除
- 默认
hidden_dim=128,则embed_dim=256,num_heads=4,256 能被 4 整除,没问题。但若用户更改hidden_dim导致embed_dim不能被 4 整除,MultiheadAttention会报错。建议在初始化时检查并提示。池化方式单一 (可选优化项)
- 平均池化简单,但可能丢失重要信息。有时最大池化或注意力池化更佳。
前向传播中没有显式设置
attn_mask和key_padding_mask
- 当序列长度固定时,一般不需要,但如果有填充,需要掩码。
返回的输出是 logits,未经过 softmax
- 这是正确的,因为交叉熵损失内部会应用 softmax。但使用
predict方法时,需要自行 softmax 转换概率(你的DeepLearningTrainer.predict已做)。未考虑序列方向与特征顺序
- 将 256 维特征按序分成 32 段,每一段的 8 个特征被当作同一时间步的多维输入。这种分法假设特征在原始向量中的相邻位置具有局部相关性,但融合特征可能不具备这种性质,因此可能效果不佳。
BiLSTMClassifier训练完之后,模型会把学到的知识存哪几个变量里,有哪些重要的模型属性和方法需要我们知道?
这个
BiLSTMClassifier结合了双向长短期记忆网络(BiLSTM)和多头注意力机制(MultiheadAttention),是一个处理时序或序列关联特征的经典架构。在模型训练完成后,它学到的"知识"(可学习的参数)分布在三个核心的网络层组件中。
一、 知识具体存在了哪里?
你可以通过
model.state_dict()查看到所有的参数,它们主要被归类在这三个部分:1.
self.lstm(双向 LSTM 权重)
存储了什么: LSTM 内部包含了复杂的门控机制(输入门、遗忘门、输出门和细胞状态)。这里存储了用于计算这些门的权重矩阵(
weight_ih和weight_hh)和偏置(bias_ih和bias_hh)。知识的意义: 因为你设置了
bidirectional=True,模型不仅保存了从左到右读取序列的参数,还保存了一套从右到左读取序列的独立参数(带有_reverse后缀)。这部分参数学到了**"如何结合过去和未来的特征来理解当前时间步的信息"**。2.
self.attention(多头注意力矩阵)
存储了什么: 主要是 Query (Q)、Key (K)、Value (V) 的输入投影矩阵(
in_proj_weight和in_proj_bias),以及多头合并后的输出投影矩阵(out_proj.weight和out_proj.bias)。知识的意义: LSTM 虽然能捕捉时序,但对长序列容易遗忘。注意力机制的参数学到了**"在做最终分类决定时,序列中的哪几个时间步最重要,应该被赋予更高的权重"**。
3.
self.fc(分类头)
存储了什么:
nn.Sequential内部两个nn.Linear层的权重(weight)和偏置(bias)。知识的意义: 它学会了如何将经过 LSTM 提取、Attention 加权、并经过全局池化(
mean)后的高维浓缩特征,降维并映射到最终的两个类别上。
二、 必须掌握的核心属性与方法
针对这个特定的结构,在日常使用和部署时,有以下几个关键点需要特别注意:
1. 极其重要的状态切换(防雷点)
model.eval()与 Dropout:在你的代码中,
nn.LSTM(如果num_layers > 1)、nn.MultiheadAttention以及self.fc都使用了dropout。在模型训练完进入测试、验证或部署推理阶段时,必须 调用model.eval()。如果不调用,Dropout 会继续在推理时随机丢弃神经元,导致你对同一条数据的多次预测结果不一样。2. 形状相关的实例属性
你在
__init__中定义的这两个属性,决定了数据在网络中流动的命脉:
self.seq_len
self.feature_per_step用途: 你的
forward方法高度依赖这两个属性来进行x.view(...)。在处理外部数据时,随时打印这两个属性,可以帮助你排查张量形状重塑(Reshape)时可能出现的维度不匹配报错。3. 隐含的状态管理 (隐藏状态 Hidden States)
关于
lstm_out, _ = self.lstm(x):那个被你用
_忽略掉的返回值,包含了 LSTM 最后一个时间步的隐藏状态(Hidden State)和细胞状态(Cell State)。
- 注意: 你的模型设计为每次前向传播都将序列作为一个完整的独立事件处理(这是大多数分类任务的默认做法)。但如果是需要持续处理连续数据流(比如实时语音识别),你可能需要将上一次的
_保存下来,作为下一次self.lstm(x, previous_states)的初始输入。4. 提取注意力权重进行可解释性分析
对于带有
MultiheadAttention的分类器,业务方经常会问:"模型为什么判断它是正类?"
self.attention的返回值: 在你的代码attn_out, _ = self.attention(...)中,第二个返回值其实是注意力权重矩阵(Attention Weights) 。如果在推理时你需要解释模型,可以将代码修改为attn_out, attn_weights = self.attention(...)并将其返回,从而可以画出热力图,看看模型在分类时究竟"盯"着序列的哪一部分。
想要真正搞懂LSTM的模型参数+输入输出请见本人另一篇文章:《LSTM核心参数与输入输出解读》
有关多头自注意力的了解请见附录18!!!
3.TransformerClassifier类
模型结构如下:
TransformerClassifier(
(embedding): Linear(in_features=8, out_features=128, bias=True) # 嵌入层(transformer): TransformerEncoder(
(layers): ModuleList(
(0-1): 2 x TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True)
)
(linear1): Linear(in_features=128, out_features=512, bias=True)
(dropout): Dropout(p=0.3, inplace=False)
(linear2): Linear(in_features=512, out_features=128, bias=True)
(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.3, inplace=False)
(dropout2): Dropout(p=0.3, inplace=False)
)
)
) # Transformer层
(fc): Sequential(
(0): Linear(in_features=128, out_features=64, bias=True)
(1): ReLU()
(2): Dropout(p=0.3, inplace=False)
(3): Linear(in_features=64, out_features=2, bias=True)
) # 分类头
)
节点特征X在前向传播中的变化过程:x shape = (batch_size, input_dim) = **(16,256)#**原始输入
↓
x.view(batch_size, self.seq_len, self.feature_per_step) # 重塑形状了
将 256 维特征均匀分成 32 个时间步,每个时间步有 8 个特征,构成一个"伪序列"。
↓
x_reshape = (16,32,8)
↓
nn.Linear(self.feature_per_step, d_model) # 将8维映射到d_model维
↓
x_enbedding = (batch_size, seq_len, d_model) =(16,32,128)
↓
self.pos_encoding = nn.Parameter(torch.randn(1, seq_len, d_model)) # 可学习的位置编码
x = x + self.pos_encoding # 广播机制自动处理batch维度
↓
x_input = (16,32,128)
↓ 输入
nn.TransformerEncoder(encoder_layer, num_layers=num_layers) # Transformer编码器(这里是2层堆叠)
↓
x_out = (batch_size, seq_len, d_model) = (16,32,128)
↓
x.mean(dim=1) # 全局平均池化
↓
x_out_mean = (batch_size, d_model) = (16,128)
↓
Sequential(
(0): Linear(in_features=128, out_features=64, bias=True)
(1): ReLU()
(2): Dropout(p=0.3, inplace=False)
(3): Linear(in_features=64, out_features=2, bias=True)
) # 二分类头(全连接)
↓
output = (16,2)
↓
后面再做模型训练+验证、还是评估,处理国臣就都一样了,请见1.MLPClassifer类
有关Transformer 编码器的学习请见附录21 !
(1)类定义与初始化
class TransformerClassifier(nn.Module):
"""Transformer分类器"""-
定义一个名为
TransformerClassifier的类,继承自nn.Module,用于序列分类。def __init__(self, input_dim: int = 256, d_model: int = 128, nhead: int = 4, num_layers: int = 2, dropout: float = 0.3): super().__init__() -
构造函数接收参数:
-
input_dim:输入特征维度(默认 256)。 -
d_model:Transformer 内部使用的特征维度(默认 128)。 -
nhead:多头注意力的头数(默认 4)。 -
num_layers:Transformer 编码器层数(默认 2)。 -
dropout:Dropout 概率(默认 0.3)。self.seq_len = 32 self.feature_per_step = input_dim // self.seq_len
-
-
固定序列长度
seq_len = 32,将输入特征均匀分割成 32 个时间步。 -
feature_per_step为每个时间步的特征数 =input_dim // seq_len。如果input_dim不能被 32 整除,则这里会丢失余数(整数除法向下取整),造成信息丢失。这是一个潜在 bug。# 线性投影到d_model维 self.embedding = nn.Linear(self.feature_per_step, d_model) -
一个线性层,将每个时间步的特征(
feature_per_step维)映射到d_model维。这是 Transformer 输入前的投影,通常称为嵌入层。# Transformer编码器 encoder_layer = nn.TransformerEncoderLayer( d_model=d_model, nhead=nhead, dim_feedforward=d_model * 4, dropout=dropout, batch_first=True ) self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=num_layers) -
创建单层 Transformer 编码器层:
-
d_model:输入/输出维度。 -
nhead:注意力头数,d_model必须能被nhead整除。 -
dim_feedforward:前馈网络维度,通常为d_model * 4。 -
dropout:层内 dropout。 -
batch_first=True:输入形状为(batch, seq, features)。
-
-
用
nn.TransformerEncoder堆叠num_layers个编码器层。# 分类头 self.fc = nn.Sequential( nn.Linear(d_model, 128), nn.ReLU(), nn.Dropout(dropout), nn.Linear(128, 2) # 二分类 ) -
分类头:先线性映射到 128 维,ReLU 激活,Dropout,最后输出 2 个 logits(二分类)。
(2)forward 方法
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""前向传播"""
batch_size = x.size(0)
# Reshape为序列形式
x = x.view(batch_size, self.seq_len, self.feature_per_step)-
获取 batch 大小。
-
将输入
x(形状(batch, input_dim))重塑为(batch, seq_len, feature_per_step)。 -
分割成序列是为了利用 Transformer 捕捉特征内部的结构化依赖,但前提是特征本身具有序列结构。对于无结构融合特征,MLP 往往更合适。
# 嵌入 x = self.embedding(x) # (batch_size, seq_len, d_model) -
对每个时间步的特征进行线性变换,映射到
d_model维。# Transformer x = self.transformer(x) # (batch_size, seq_len, d_model) -
通过 Transformer 编码器堆栈,输出形状不变
(batch, seq_len, d_model)。# 全局平均池化 x = x.mean(dim=1) # (batch_size, d_model) -
对序列维度求平均,得到每个样本的全局向量
(batch, d_model)。# 分类 output = self.fc(x) return output -
通过分类头得到 logits,形状
(batch, 2)。
相关机器学习知识点
1. Transformer 编码器结构
Transformer 由 Vaswani 等人在 2017 年提出,核心是自注意力机制。一个 Transformer 编码器层包含:
多头自注意力:让每个位置关注序列中所有位置。
前馈网络:两个线性层 + 激活函数(通常 ReLU)。
残差连接 + 层归一化:稳定训练。
2. 为什么需要位置编码?
Transformer 本身是置换不变 的,即不关心输入顺序。对于序列数据,必须加入位置编码 来注入位置信息。PyTorch 的
TransformerEncoderLayer默认不会自动添加位置编码 ,需要用户自己加。本代码中没有添加位置编码,这是一个严重缺陷。3. 序列分类常见做法
取最后一时间步的输出(常与 CLS token 结合)。
全局平均/最大池化(如本例)。
引入可学习的分类 token(如 BERT 的
[CLS])。4. 维度分割的合理性
将 256 维特征均匀分成 32 个时间步,每个时间步 8 维。这种做法隐含假设:相邻的 8 维特征在语义上相关,形成"时间步"。但对于融合特征(可能是无序的),这种假设不一定成立,可能破坏特征结构。但代码注释中已提醒"对于融合特征,建议优先使用 MLP 或 Transformer",所以此处是为了演示 Transformer 在序列任务中的应用。
潜在 Bug 与优化建议
未添加位置编码
Transformer 需要位置信息,否则无法区分序列顺序。由于特征被分割成序列,顺序可能有意义(例如按特征顺序)。缺失位置编码会严重限制模型性能。
修复 :在
embedding之后添加可学习的位置编码或正弦位置编码。输入维度不能被 seq_len 整除时数据丢失
feature_per_step = input_dim // self.seq_len是整数除法。如果input_dim % self.seq_len != 0,余数被丢弃,造成信息丢失。建议 :添加校验,若不能整除则抛出异常或调整
seq_len。固定 seq_len=32
- 限制了灵活性。更好的做法是将
seq_len作为构造参数,并自动计算feature_per_step,若不能整除则报错或调整。未处理分类头中的
d_model与nhead的整除性
- 若
d_model % nhead != 0,nn.TransformerEncoderLayer会报错。可以在初始化时检查并提示。分类头中线性层维度硬编码为 128
- 可以根据
d_model动态设置,如d_model // 2或可配置。缺乏适当的初始化
- 默认线性层使用 Kaiming 初始化,但对 Transformer 来说,常见的是 Xavier 初始化。但影响不大。
未设置
src_key_padding_mask
- 如果输入序列长度相同(固定),无需掩码。但若未来支持变长,需要处理。
分类头最后的线性层直接输出 2 个 logits
- 正确,因为交叉熵损失期望原始 logits。
从TransformerClassifier分类器模型的构建来看,Transformer也跟LSTM类似它们的input_x都是需要基于时间步的,所以都会先把原始输入batch_X(16,256)重塑成x_reshape(16,32,8)。接着再经过一个nn.Linear()线性映射到(16,32,128),然后再输入到Transformer编码器。
我的3个疑问如下:
1.为什么在输入nn.TransformerEncoderLayer()之前需要添加线性投影到d_model维,如果不加投影直接把d_model参数改成8不就行了?
2.Transformer 本身是置换不变的,即不关心输入顺序,对于序列数据,必须加入位置编码来注入位置信息。但是我目前的代码并未添加位置编码啊,为什么要添加位置编码,如何添加?在我的目前代码的基础上应该如何修改?
3.既然Transformer 本身是置换不变的,即不关心输入顺序。为什么不直接将我的原始特征数据batch_X(16,256)直接输入nn.TransformerEncoderLayer()呢?还先维度分割为3D的序列特征干嘛呢?反正我的原始数据本来就是2D的融合特征(无序的),并不是3D的序列数据啊。
解答请见附录20!!!
4.ResNet1DClassifier类

# 第一个残差块的内部结构:
# 第二个残差块的内部结构:
ResidualBlock1D(
(conv1): Conv1d(64, 128, kernel_size=(3,), stride=(1,), padding=(1,))
(bn1): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv1d(128, 128, kernel_size=(3,), stride=(1,), padding=(1,))
(bn2): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(dropout): Dropout(p=0.3, inplace=False)
(shortcut): Sequential(
(0): Conv1d(64, 128, kernel_size=(1,), stride=(1,), bias=False)
(1): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
# 第三个残差块的内部结构:
ResidualBlock1D(
(conv1): Conv1d(128, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(bn1): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(bn2): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(dropout): Dropout(p=0.3, inplace=False)
(shortcut): Sequential(
(0): Conv1d(128, 256, kernel_size=(1,), stride=(1,), bias=False)
(1): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
节点特征X在前向传播中的变化过程:x shape = (batch_size, input_dim) = **(16,256)#**原始输入
↓
x.view(batch_size, seq_len, feature_per_step) # 重塑形状了
将 256 维特征均匀分成 32 个时间步,每个时间步有 8 个特征,构成一个"伪序列"。
↓
x_reshape = (16,32,8)
↓
x.transpose(1, 2) # 转置操作
↓ 因为
Conv1d期望输入形状为(batch, channels, length)x_tra = (batch_size, feature_per_step, seq_len) = (16,8,32)
↓ 初始卷积(使用更大的kernel提取初始特征)
self.conv1 = nn.Conv1d(self.feature_per_step, 64, kernel_size=7, stride=1, padding=3, bias=False) # 经过第一个卷积(批归一化+激活)
self.bn1 = nn.BatchNorm1d(64)
self.relu = nn.ReLU(inplace=True)
↓
x = (16,64,32)
↓ 进入残差块1(每个块内部都有 skip connection)
ResidualBlock1D(
out = conv1(x) # 第一层卷积(64, 64)
out = bn1(out) # 批归一化
out = relu(out) # 激活
if dropout: out = dropout(out) # Dropout
out = conv2(out) # 第二层卷积(64, 64)
out = bn2(out) # 批归一化
out = out + shortcut(identity) # 残差连接
out = relu(out)# 激活
)
↓
x = (16,64,32)
↓ 进入残差块2
ResidualBlock1D(
out = conv1(x) # 第一层卷积(64, 128)
out = bn1(out) # 批归一化
out = relu(out) # 激活
if dropout: out = dropout(out) # Dropout
out = conv2(out) # 第二层卷积(128, 128)
out = bn2(out) # 批归一化
out = out + shortcut(identity) # 残差连接
out = relu(out)# 激活
)
↓
x = (16,128,32)
↓ 进入残差块3
ResidualBlock1D(
out = conv1(x) # 第一层卷积(128, 256)
out = bn1(out) # 批归一化
out = relu(out) # 激活
if dropout: out = dropout(out) # Dropout
out = conv2(out) # 第二层卷积(256, 256)
out = bn2(out) # 批归一化
out = out + shortcut(identity) # 残差连接
out = relu(out)# 激活
)
↓
x = (16,256,32)
↓ 加个分类头(全连接)
Sequential(
(0): AdaptiveAvgPool1d(output_size=1) # 全局平均池化 (16,256,32)变为(16,256,1)
(1): Flatten(start_dim=1, end_dim=-1) # 拍平为(16,256)
(2): Linear(in_features=256, out_features=128, bias=True) # 映射为(16,128)
(3): ReLU() # 激活
(4): Dropout(p=0.3, inplace=False) # Dropout
(5): Linear(in_features=128, out_features=2, bias=True) # 映射为(16,2)
)
↓
output = (16,2)
这里我有一个疑问,init()中每一个残差块的结构定义与forword()中网络的执行过程不一致,为什么forword过程要按照这个顺序进行呢?请你解释原因?请见附录23!!!
(1)类定义与初始化
class ResNet1DClassifier(nn.Module):
"""ResNet-1D分类器
改进:
1. seq_len 可配置
2. 输入维度校验
3. 残差块数量可配置
"""-
定义一个名为
ResNet1DClassifier的类,继承自nn.Module。这是一个用于处理一维序列(如时间序列、特征序列)的残差网络。def __init__(self, input_dim: int = 256, num_blocks: int = 3, dropout: float = 0.3, seq_len: int = 32): super().__init__() -
构造函数参数:
-
input_dim:输入特征维度(默认 256)。 -
num_blocks:残差块数量(默认 3),范围限制在 1-5。 -
dropout:Dropout 概率(默认 0.3)。 -
seq_len:序列长度(默认 32),即将输入特征分割成多少个时间步。# 参数校验 if input_dim % seq_len != 0: raise ValueError(f"input_dim ({input_dim}) 必须能被 seq_len ({seq_len}) 整除。" f"当前余数为 {input_dim % seq_len}") if num_blocks < 1 or num_blocks > 5: raise ValueError(f"num_blocks 应在 1-5 之间,当前值为 {num_blocks}")
-
-
校验输入维度是否能被
seq_len整除,否则无法均匀分割,会导致信息丢失。 -
限制残差块数量在 1-5 之间,防止过深或过浅。
self.seq_len = seq_len self.feature_per_step = input_dim // self.seq_len -
保存序列长度和每个时间步的特征数。例如
input_dim=256,seq_len=32,则feature_per_step=8。# 初始卷积 self.conv1 = nn.Conv1d(self.feature_per_step, 64, kernel_size=3, padding=1) self.bn1 = nn.BatchNorm1d(64) -
第一个卷积层:输入通道数为
feature_per_step,输出通道数为 64,卷积核大小为 3,padding 为 1 保持长度不变。 -
批归一化(BatchNorm1d)对输出进行归一化,稳定训练。
# 动态创建残差块 block_configs = [ (64, 64, 3), (64, 128, 3), (128, 256, 3), (256, 512, 3), (512, 512, 3) ] -
预定义 5 个残差块的配置,每个元组为
(in_channels, out_channels, kernel_size)。 -
设计思路:前几个块逐步增加通道数(64→128→256→512),后两个块保持 512 维,增强特征抽象。
self.blocks = nn.ModuleList([ self._make_block(*block_configs[i]) for i in range(num_blocks) ]) -
使用
nn.ModuleList动态创建num_blocks个残差块,每个块由_make_block方法生成。# 获取最后一个块的输出通道数 final_channels = block_configs[num_blocks - 1][1] -
根据选择的残差块数量,获取最后一个块的输出通道数,用于后续分类头。
# 分类头 fc_hidden_dim = max(final_channels // 2, 64) self.fc = nn.Sequential( nn.AdaptiveAvgPool1d(1), nn.Flatten(), nn.Linear(final_channels, fc_hidden_dim), nn.ReLU(), nn.Dropout(dropout), nn.Linear(fc_hidden_dim, 2) # 二分类 ) -
分类头:
-
AdaptiveAvgPool1d(1):自适应平均池化,将长度维度压缩为 1,输出形状(batch, final_channels, 1)。 -
Flatten():展平为(batch, final_channels)。 -
线性层将
final_channels映射到fc_hidden_dim(取final_channels // 2,至少 64)。 -
ReLU、Dropout。
-
最后一层线性映射到 2 个 logits(二分类)。
def _make_block(self, in_channels: int, out_channels: int, kernel_size: int) -> nn.Module: """创建残差块""" return nn.Sequential( nn.Conv1d(in_channels, out_channels, kernel_size, padding=kernel_size//2), nn.BatchNorm1d(out_channels), nn.ReLU(), nn.Conv1d(out_channels, out_channels, kernel_size, padding=kernel_size//2), nn.BatchNorm1d(out_channels) )
-
-
定义一个残差块,包含两个卷积层(每个卷积后接 BN),中间用 ReLU 激活。
-
注意 :这个实现没有包含残差连接,只是两个卷积的堆叠,这不是标准的残差块!标准的残差块应该将输入加到输出上,这里缺失了。这是一个严重的设计缺陷。
(2)forward 方法
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""前向传播"""
batch_size = x.size(0)
# Reshape为序列形式
x = x.view(batch_size, self.seq_len, self.feature_per_step)
x = x.transpose(1, 2) # (batch_size, feature_per_step, seq_len)-
将输入
(batch, input_dim)重塑为(batch, seq_len, feature_per_step),然后转置为(batch, feature_per_step, seq_len),因为Conv1d期望输入形状为(batch, channels, length)。# 初始卷积 x = self.conv1(x) x = self.bn1(x) x = torch.relu(x) -
经过第一个卷积、BN、ReLU,输出形状
(batch, 64, seq_len)。# 残差块 for block in self.blocks: x = block(x) -
依次通过每个残差块。注意每个块内部没有残差连接,只是两个卷积的串联。
# 分类 output = self.fc(x) return output -
通过分类头得到 logits,形状
(batch, 2)。
相关机器学习知识点
1. 残差网络(ResNet)的核心思想
问题:深层网络容易发生梯度消失或退化,导致训练困难。
解决方案 :引入残差连接 ,让网络学习输入与输出的差值,即
H(x) = F(x) + x。这样梯度可以直接流过恒等映射,使得网络可以堆叠更多层。标准残差块结构:
x -> conv -> bn -> relu -> conv -> bn -> add(x) -> relu。有关残差连接的知识点请见《python结构特征提取(2)》的附录5!
2. 1D 卷积
用于处理一维序列数据(如时间序列、信号、文本特征序列)。
卷积核沿长度方向滑动,提取局部特征。与 2D 卷积类似,但只在单一维度上操作。
2D卷积操作请自行学习CNN入门实战--图像识别分类任务
3. 批归一化(BatchNorm)
对每个通道在 batch 维度上进行归一化,使激活值稳定在均值为 0、方差为 1 的分布。
加速收敛,允许使用更高学习率,有一定正则化效果。
4. 自适应池化
AdaptiveAvgPool1d(1)将任意长度的序列压缩为长度为 1 的向量,输出形状(batch, channels, 1),再通过Flatten得到(batch, channels)。这样分类头与输入序列长度解耦,允许模型处理不同长度的输入(虽然这里长度固定)。
潜在 Bug 与优化建议
残差块缺少残差连接
_make_block只包含两个卷积,没有将输入加到输出上。这导致网络不是真正的 ResNet,而是普通的卷积块堆叠,无法利用残差学习的优势。修复 :在
_make_block中,需要判断输入通道和输出通道是否一致,若不匹配则需通过 1×1 卷积调整维度,然后加上输入。未处理通道数变化时的残差连接
当
in_channels != out_channels时,无法直接相加,需要用 1×1 卷积投影输入到相同维度。当前代码完全没有考虑,会导致维度不匹配。残差块中的激活位置
标准 ResNet 通常在加法之后再应用 ReLU,而不是在第二个 BN 之后直接结束。你的块中第二个 BN 后没有激活,也没有残差加法。
正确的残差块结构应该是:
def _make_block(self, in_channels, out_channels, kernel_size):
shortcut = nn.Conv1d(in_channels, out_channels, kernel_size=1) if in_channels != out_channels else nn.Identity()
return nn.Sequential(
nn.Conv1d(in_channels, out_channels, kernel_size, padding=kernel_size//2),
nn.BatchNorm1d(out_channels),
nn.ReLU(),
nn.Conv1d(out_channels, out_channels, kernel_size, padding=kernel_size//2),
nn.BatchNorm1d(out_channels),
# 残差加法
lambda x: x + shortcut(x), # 注意需要用自定义模块,这里仅为示意
nn.ReLU()
)由于
nn.Sequential不支持自定义加法,通常需要写成class ResidualBlock(nn.Module)来手动实现forward。输入维度校验
目前检查了整除,但未检查
seq_len是否合理(如过大或过小)。可以添加建议值。
final_channels可能过小当
num_blocks=1时,final_channels=64,分类头fc_hidden_dim = max(64//2,64) = 64,合理。当num_blocks=5时,final_channels=512,fc_hidden_dim=256,也合理。分类头中
AdaptiveAvgPool1d(1)后紧接Flatten正确,但可简化为
nn.AdaptiveAvgPool1d(1)后直接squeeze(-1)或view(batch_size, -1)。没有显式设置
dropout在分类头中已正确使用。
附录
1.检查python文件的语法是否正确
# 在命令行中输入这行shell
python -m py_compile xxx.py && echo "✓ 语法检查通过"2.pathlib.Path()函数语法
Path() 是 Python 标准库 pathlib 模块中的一个类,用于以面向对象的方式操作文件系统路径 。它比传统的 os.path 模块更直观、更现代。
基本用法
python
from pathlib import Path
# 创建 Path 对象
p = Path("some/path") # 相对路径
p = Path("/absolute/path") # 绝对路径
p = Path("C:/Windows") # Windows 路径(自动处理分隔符)常用方法
-
exists():判断路径是否存在(文件或目录)。 -
is_dir():判断是否为目录。 -
is_file():判断是否为文件。 -
mkdir():创建目录(可带parents=True创建父目录)。 -
glob(pattern):使用通配符匹配路径下的文件(返回生成器)。 -
name:获取路径的最后一部分(文件名或目录名)。 -
stem:获取文件名(不含后缀)。 -
suffix:获取文件后缀。 -
resolve():返回绝对路径。
运算符支持
- 用
/连接路径:Path("dir") / "subdir" / "file.txt"。
3.sklearn.preprocessing.StandardScaler()
在机器学习中,标准化(Standardization) 是一种常见的数据预处理方法,目的是将不同尺度的特征缩放到相同的范围,通常使每个特征的均值为0、标准差为1。这样做可以避免某些特征因为数值范围大而在模型中占据主导地位,同时也能加快梯度下降等优化算法的收敛速度。
为什么要在训练集上 fit,然后对验证集和测试集只进行 transform?
核心原因是防止数据泄露(Data Leakage),保证模型评估的真实性。
-
训练集 :我们通过
fit_transform计算训练集的均值和标准差,并用这些统计量将训练数据标准化。这个过程相当于让模型"学习"训练数据的分布。 -
验证集和测试集 :我们只使用训练集计算出的均值和标准差进行
transform,而不是重新计算自己的统计量。这是因为验证集和测试集模拟的是模型在生产环境中遇到的新数据------我们无法预知这些新数据的均值和标准差。如果让验证集或测试集也参与拟合,就相当于提前"偷看"了它们的信息,这样评估出的模型性能会过于乐观,无法反映模型在真实未知数据上的表现。
简单来说:训练集的统计量代表了模型从训练数据中学到的"世界规律",验证集和测试集也必须用同样的规律来转换,才能公平地检验模型。
fit_transform() 和 transform() 的区别
-
fit_transform(X):先计算X的统计量(如均值、标准差),然后用这些统计量对X进行转换,并返回转换后的数据。这是一个**"拟合+转换"** 的快捷操作,通常只用于训练集。(fit作用的是StandardScaler()对象参数,而transform作用的是数据) -
transform(X):直接使用已经拟合好的统计量对X进行转换,不重新计算。通常用于验证集、测试集以及新数据。
形象地理解:
-
fit就像制作一把尺子,这把尺子是根据训练数据的分布"量身定做"的。 -
transform就是用这把现成的尺子去测量其他数据(验证集、测试集),而不是为每个新数据集都重新做一把尺子。
示例:
python
from sklearn.preprocessing import StandardScaler
# 假设我们有训练集、验证集、测试集
scaler = StandardScaler()
# 对训练集:拟合+转换
X_train_scaled = scaler.fit_transform(X_train)
# 对验证集和测试集:仅转换(使用训练集的统计量)
X_val_scaled = scaler.transform(X_val)
X_test_scaled = scaler.transform(X_test)如果不这样做会怎样?
如果对整个数据集(包括验证集、测试集)统一进行 fit_transform,那么验证集和测试集的分布信息就提前泄露到了标准化过程中,后续模型评估结果会偏高,无法反映真实泛化能力。
4.哪些模型需要标准化?
标准化 :将特征缩放到均值为0、标准差为1。公式:
x' = (x - μ) / σ。需要标准化的模型:
线性模型(逻辑回归、线性SVM):模型输出是特征的线性组合,特征的尺度直接影响权重和梯度,标准化可加速收敛并提高模型性能。
基于距离的模型(KNN、K-Means):特征尺度决定距离计算中的权重,标准化能避免大尺度特征主导。
神经网络:输入层通常需要标准化以加速训练。
不需要标准化的模型:
树模型(决策树、随机森林、梯度提升树):分裂节点时只考虑特征值的大小关系,不关心绝对尺度,因此标准化对结果无影响。
朴素贝叶斯:基于概率,对特征分布有假设,一般不要求标准化。
在机器学习中,特征标准化(Standardization)是指将特征缩放到均值为0、标准差为1的过程。是否需要对特征进行标准化,主要取决于模型的工作原理和对特征尺度的敏感程度。下面分类说明:
✅ 需要标准化的模型
这些模型通常依赖于特征之间的尺度一致性,如果不进行标准化,可能会导致模型性能下降或训练不稳定。
1. 线性模型与广义线性模型
-
例如:线性回归、逻辑回归、线性SVM(支持向量机)、感知机。
-
原因:模型输出是特征的线性加权和,特征的尺度直接影响权重的大小。如果某个特征的数值范围很大,它将在损失函数中占据主导地位,导致模型偏向该特征,同时梯度下降收敛变慢。标准化后所有特征处于同一量级,有助于模型学习到更合理的权重。
- 基于距离的模型
-
例如:K近邻(KNN)、K-Means聚类、层次聚类。
-
原因:这些模型依赖样本间的距离(如欧氏距离)进行判断。如果特征尺度不同,数值范围大的特征会主导距离计算,而小尺度特征的信息被淹没。标准化使每个特征对距离的贡献相等。
3. 神经网络与深度学习
-
例如:多层感知机(MLP)、卷积神经网络(CNN)、循环神经网络(RNN)。
-
原因:神经网络的输入层通常需要标准化,因为激活函数(如sigmoid、tanh)在输入值过大或过小时会进入饱和区,导致梯度消失。标准化还能加速梯度下降的收敛。
- 主成分分析(PCA)
- 原因:PCA寻找最大方差方向,如果特征尺度不同,方差大的特征会被优先考虑,导致主成分被大尺度特征主导。标准化后每个特征方差相同,PCA才能真实反映数据结构。
- 正则化模型
-
例如:Lasso回归、Ridge回归、弹性网络。
-
原因:正则化项(L1/L2)惩罚权重大小,如果特征尺度不同,惩罚效果会不一致,无法公平地约束所有特征。标准化后正则化才能真正实现特征选择或收缩。
❌ 不需要标准化的模型
这些模型对特征尺度不敏感,或者其内部机制已经处理了尺度问题。
- 树模型
-
例如:决策树、随机森林、梯度提升树(GBDT、XGBoost、LightGBM、CatBoost)。
-
原因:树模型通过特征值的大小比较进行节点分裂,只关心特征的相对顺序,不关心绝对数值。因此,特征的缩放不会改变分裂点的位置,也不会影响模型结构。
- 朴素贝叶斯
- 原因:朴素贝叶斯基于概率计算,特征的条件概率通常用高斯分布等建模,虽然理论上特征尺度影响分布的参数估计,但实际中模型对尺度不敏感,且标准化可能破坏原有的概率假设(如伯努利朴素贝叶斯要求特征为0/1)。通常不要求标准化,但若使用高斯朴素贝叶斯,标准化有助于数值稳定性,但不是必须。
- 基于规则或排名的模型
-
例如:排名算法(如LambdaMART)、关联规则挖掘。
-
原因:这些模型依赖特征间的比较或排序,而非具体数值,因此尺度不影响结果。
- 某些集成模型(如投票、平均)
- 如果基模型本身对尺度不敏感(如树模型),则无需标准化;但如果集成中包含敏感模型(如SVM),仍需对相应部分标准化。
💡 注意事项
-
标准化应在训练集上拟合(fit),再转换验证集和测试集,防止数据泄露。
-
标准化并不是唯一的数据缩放方式,还有**归一化(Min-Max Scaling)**等,选择哪种取决于模型和分布。
-
当不确定模型是否需要标准化时,可以先尝试标准化,因为大多数情况下它无害且可能带来好处。但对于树模型,标准化是完全不必要的,反而可能增加计算开销。
5.@staticmethod 是什么?有什么作用?
@staticmethod 是 Python 中的装饰器 ,用于将类中的方法定义为静态方法 。静态方法与普通函数几乎没有区别,只是它被定义在类的内部,可以通过类名或实例直接调用,但不会自动传入 self 或 cls 参数。
静态方法的特点:
-
不依赖实例状态 :静态方法无法访问实例属性或调用其他实例方法,因为它没有 self 参数。
-
不依赖类状态 :静态方法也无法访问类属性或调用其他类方法,因为它没有 cls 参数。
-
调用方式 :可以通过
类名.方法名()或实例.方法名()调用,但通常建议使用类名调用,更符合其语义。 -
作用 :静态方法主要用于将与类相关的工具函数 或工厂函数组织在类的命名空间下,提高代码的可读性和模块化。
为什么要在 ClassifierFactory 中使用 @staticmethod?
在 ClassifierFactory 中,create_classifier 方法被定义为静态方法,因为:
-
该方法不需要访问任何实例属性(工厂本身不需要存储状态)。
-
它只需要根据传入的参数返回对应的分类器对象,纯粹是一个工具函数。
-
通过静态方法,我们可以直接通过
ClassifierFactory.create_classifier(...)调用,无需创建工厂实例,简化了调用。
示例对比:
python
class MyClass:
def instance_method(self):
print("实例方法,可以访问 self")
@classmethod
def class_method(cls):
print("类方法,可以访问 cls")
@staticmethod
def static_method():
print("静态方法,不能访问 self 或 cls")
# 调用
MyClass.static_method() # 直接通过类调用
obj = MyClass()
obj.static_method() # 也可以通过实例调用与其他方法的区别
| 方法类型 | 第一个参数 | 能访问什么 | 用途 |
|---|---|---|---|
| 实例方法 | self |
实例属性和方法、类属性和方法 | 操作实例数据 |
| 类方法 | cls |
类属性和方法、可创建实例 | 工厂方法、操作类状态 |
| 静态方法 | 无 | 不能直接访问类或实例,但可以通过类名引用 | 工具函数、与类相关的独立逻辑 |
6.什么是工厂模式?有什么好处?如何设计工厂模式?
工厂模式的定义:
工厂模式 是一种创建型设计模式,它提供了一种创建对象的最佳方式 。在工厂模式中,我们不直接使用 new 关键字(在 Python 中是直接调用类构造函数)创建对象,而是通过一个工厂类或方法来负责对象的创建。这样,客户端(调用方)只需要告诉工厂需要什么类型的对象,而不需要关心对象的具体创建细节。
工厂模式的核心思想是:将对象的创建和使用分离 。
工厂模式的好处:
-
解耦
客户端代码不再依赖具体的类,只需依赖工厂和产品接口(如果有)。当需要更换产品类型时,只需修改工厂参数,无需修改客户端逻辑。
-
扩展性(开闭原则)
当需要添加新的产品类型时,只需扩展工厂(添加新的分支或新的工厂子类),而无需修改现有客户端代码。这符合"对扩展开放,对修改封闭"的设计原则。
-
集中管理创建逻辑
所有对象的创建逻辑都集中在工厂中,便于统一控制(如参数校验、缓存、日志记录、对象池管理)。
-
降低代码重复
如果创建对象的过程很复杂(需要多个步骤、依赖配置等),将创建逻辑提取到工厂中,可以避免在多个地方重复相同的代码。
-
增强可测试性
在单元测试中,可以轻松地用模拟对象替换工厂返回的真实对象,方便隔离测试。
工厂模式的三种常见实现:
根据复杂程度,工厂模式通常分为三种:
① 简单工厂(Simple Factory)------ 静态工厂
-
结构:一个工厂类,包含一个静态方法,根据参数返回不同的产品实例。
-
优点:简单直观,适合产品种类较少且不频繁变化的场景。
-
缺点 :当添加新产品时,需要修改工厂类的代码(增加
if分支),违反了开闭原则。 -
示例 :
ClassifierFactory就是典型的简单工厂。
python
class ClassifierFactory:
@staticmethod
def create_classifier(model_name, **kwargs):
if model_name == 'logistic_regression':
return LogisticRegressionClassifier(**kwargs)
elif model_name == 'svm':
return SVMClassifier(**kwargs)
elif model_name == 'random_forest':
return RandomForestClassifier(**kwargs)
else:
raise ValueError(f"Unknown model: {model_name}")
# 客户端使用
classifier = ClassifierFactory.create_classifier(model_name, **params)② 工厂方法(Factory Method)
-
结构 :定义一个创建对象的抽象接口(通常是一个抽象基类),但让子类决定实例化哪个具体类。即:将对象的创建延迟到子类中。
-
适用场景:当客户端不知道它需要创建哪一个具体类,或者希望子类来指定创建的对象时。
-
优点:符合开闭原则,新增产品只需新增一个工厂子类,无需修改现有工厂。
-
缺点:每增加一个产品,就需要增加一个对应的工厂子类,类数量可能膨胀。
python
from abc import ABC, abstractmethod
class ClassifierFactory(ABC):
@abstractmethod
def create_classifier(self, **kwargs):
pass
class LogisticRegressionFactory(ClassifierFactory):
def create_classifier(self, **kwargs):
return LogisticRegressionClassifier(**kwargs)
class SVMFactory(ClassifierFactory):
def create_classifier(self, **kwargs):
return SVMClassifier(**kwargs)
# 客户端使用
factory = LogisticRegressionFactory()
classifier = factory.create_classifier(C=1.0)③ 抽象工厂(Abstract Factory)
-
结构 :提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
-
适用场景:当系统需要创建多个产品族,且产品之间有关联时(例如 GUI 工具包中的按钮、文本框、窗口)。
-
优点:保证客户端始终使用同一产品族中的对象,易于交换产品族。
-
缺点:扩展新产品族困难,需要修改抽象工厂接口。
python
from abc import ABC, abstractmethod
# 抽象工厂
class GUIFactory(ABC):
@abstractmethod
def create_button(self):
pass
@abstractmethod
def create_checkbox(self):
pass
# 具体工厂 - Windows风格
class WindowsFactory(GUIFactory):
def create_button(self):
return WindowsButton()
def create_checkbox(self):
return WindowsCheckbox()
# 具体工厂 - Mac风格
class MacFactory(GUIFactory):
def create_button(self):
return MacButton()
def create_checkbox(self):
return MacCheckbox()静态工厂我看懂了,但是后面这两个工厂模式我没看太懂!由于时间原因,点到为止,先不做过深的学习了,后面有时间了或再碰到的话可以进一步学习一下!!!
如何设计工厂模式?------ 以你的 ClassifierFactory 为例
你的代码已经实现了一个简单工厂,设计步骤如下:
-
定义产品接口(或基类)
所有分类器类都应继承自同一个基类
BaseClassifier,保证它们有统一的方法(如fit、predict、evaluate)。 -
创建具体产品类
如
LogisticRegressionClassifier、SVMClassifier等,它们实现具体的算法逻辑。 -
创建工厂类
提供一个静态方法
create_classifier,根据参数返回相应的产品实例。 -
客户端调用
直接通过
ClassifierFactory.create_classifier(model_name, **params)获取分类器对象,然后调用其方法,无需关心具体是哪个类。
优化建议(向工厂方法模式演进)
如果未来需要支持更多模型,且希望避免修改工厂类,可以改用工厂方法模式:
-
将
ClassifierFactory定义为抽象基类,包含抽象方法create_classifier。 -
为每个模型创建一个具体的工厂子类,实现
create_classifier返回对应的产品。 -
客户端根据所需模型选择对应的工厂子类。
但简单工厂在大多数机器学习实验脚本中已经足够,因为模型列表相对固定,且修改工厂类的成本很低。
总结:
-
@staticmethod是一种将普通函数组织在类中的方式,用于不依赖类或实例状态的工具方法。 -
工厂模式 通过封装对象创建逻辑,实现客户端与具体类的解耦,提高代码的可维护性和扩展性。简单工厂适合快速实现,工厂方法和抽象工厂则适用于更复杂、更灵活的场景。
在你的代码中,ClassifierFactory 就是一个简单工厂的典型应用,它让我们可以方便地通过名称创建不同的分类器,同时通过 use_scaler 和 **kwargs 灵活传递参数。理解这些概念,能帮助你写出更清晰、更易扩展的代码。
7.逻辑回归(Logistic Regression)
是什么 :一种广义线性模型,用于二分类(也可扩展到多分类)。它通过 Sigmoid 函数将线性组合
w^T x + b映射到 0,1 区间,输出为正类的概率。损失函数:通常使用对数损失(Log Loss),通过最大似然估计求解参数。
优化算法 :
sklearn中可选多种求解器,如lbfgs、sag、saga等。max_iter控制迭代次数,防止不收敛。为什么需要标准化 :逻辑回归对特征尺度敏感,因为特征的尺度会影响权重的更新速度和最终结果。标准化可以加速收敛,并使得不同特征的权重具有可比性。(注意:在训练集上fit,然后transform所有集合)
逻辑回归(Logistic Regression)是一种经典的分类算法 ,尽管名字里有"回归",但它主要用于解决二分类问题 (也可推广到多分类)。它的核心思想是:利用线性回归的输出来表示样本属于某一类别的对数几率,再通过 Sigmoid 函数将其映射为概率。
下面我将从三个方面详细讲解:
-
逻辑回归的基本原理(模型在做什么)
-
模型的内部结构(数学形式)
-
sklearn.linear_model.LogisticRegression的常用参数及含义
一、逻辑回归到底在做什么?
假设我们有一个二分类任务,标签 y ∈ {0,1}。逻辑回归的目标是:给定特征 x,预测 y=1的概率 P(y=1|x)。
1. 线性部分
首先,对特征进行线性组合:
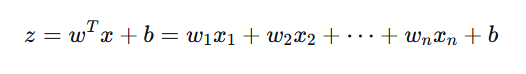
其中 w 是权重向量,b 是偏置(截距),z 的取值范围是 (-∞, +∞)。
这里的Z本质上是一个得分(Score):
- 如果 Z 很大,模型觉得 y=1 的可能性很高;
- 如果 Z 很大且为负,模型觉得 y=0 的可能性很高;
- 如果 Z 接近 0,模型觉得处于"五五开"的边界。
但问题在于,Z的取值在正负无穷之间,而概率必须在0,1之间,所以我们需要一个"转换器"。
2. Sigmoid 函数(逻辑函数)
将 z 输入到 Sigmoid 函数 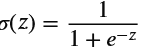 中,将实数映射到 (0,1) 区间,得到概率估计:
中,将实数映射到 (0,1) 区间,得到概率估计:
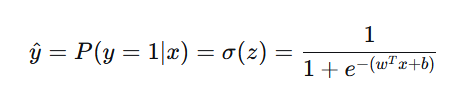
Sigmoid 函数的特点:
- 当Z很大时(正无穷),sigmoid(Z)接近 1
- 当Z很小时(负无穷),sigmoid(Z)接近 0
- 当Z=0时,sigmoid(Z)=0.5
3. 决策边界
当 时,预测为正类(1);否则为负类(0)。决策边界对应
,即
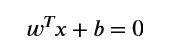
这是一个线性超平面。因此,尽管逻辑回归的名字里有"回归"二字,且使用了非线性的 Sigmoid 函数,但它本质上是一个线性分类器。
4. 损失函数(对数损失)
逻辑回归不直接使用均方误差(MSE),而是采用对数损失(Log Loss,又称交叉熵损失):
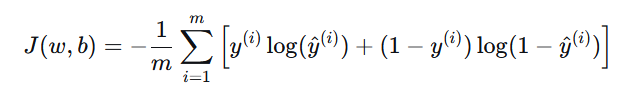
为什么用这个函数?
- 衡量准确性:当预测值
- 便于优化:这个损失函数是凸函数(Convex Function),这意味着它没有局部最优解,只有一个全局最小值,非常适合用数学方法找到最优参数。
5. 训练过程
训练的目标就是通过各种手段找到让损失函数 J(w,b) 最小的一组参数w 和 b。
- **优化算法:**常用的有梯度下降法(Gradient Descent)或拟牛顿法(如 L-BFGS)等。
- **防止过拟合:**为了让模型在未知数据上表现更好,通常会加入正则化项(L1 或 L2),通过惩罚过大的权重来控制模型的复杂度。
二、模型内部结构(数学形式)
逻辑回归模型可以总结为:
-
输入 :特征向量
-
线性变换 :
-
非线性激活 :
-
输出:类别概率(二分类)
训练后,模型内部保存了:
-
权重向量
coef_(形状(n_features,)或对于多分类(n_classes, n_features)) -
截距
intercept_(形状(1,)或对于多分类(n_classes,))
对于多分类,sklearn 默认使用一对多(OvR) 策略:为每个类别训练一个二分类器,最后选择概率最高的类别;也可使用多项式逻辑回归(softmax) ,此时权重矩阵形状为 (n_classes, n_features)。
逻辑回归模型训练完之后,模型会把学到的知识存哪几个变量里,有哪些重要的模型属性需要我们知道?
在逻辑回归模型(以最常用的 Scikit-Learn 为例)训练完成后,模型学到的"知识"主要存储在两个核心变量中,它们决定了模型如何进行预测:
coef_(系数/权重) :
- 本质 :对应特征的权重向量(
)
- 意义:反映了每个特征对预测结果的影响方向和程度。正值表示正相关,负值表示负相关。
intercept_(截距) :
- 本质:偏置项(b)。
- 意义:当所有特征输入都为 0 时,决策边界的基准值。
其他重要的模型属性
除了上述核心参数,以下属性对于理解模型状态也非常关键:
classes_:训练集里的类别标签 (比如[0, 1]或['cat', 'dog'])。模型在预测时,索引顺序就是按照这个数组来的。n_features_in_:模型训练时接触到的特征总数。feature_names_in_:如果你的输入是 Pandas DataFrame,它会记录特征的名称,方便你核对权重对应的是哪个变量。n_iter_:模型达到收敛实际运行的迭代次数 。如果这个值等于你设置的最大迭代次数(max_iter),通常意味着模型还没跑完就停了,结果可能不准。
三、sklearn.linear_model.LogisticRegression 常用参数详解
LogisticRegression 提供了丰富的参数,下面解释最常用的几个:
1. penalty:正则化类型
-
取值 :
'l1','l2','elasticnet','none' -
默认 :
'l2' -
作用:添加正则化项,防止过拟合。
-
'l1':L1 正则化,会使得一些权重变为0,产生稀疏解,适合特征选择。 -
'l2':L2 正则化,权重收缩但不为零,最常用。 -
'elasticnet':同时使用 L1 和 L2,需要配合l1_ratio参数。 -
'none':无正则化,可能过拟合。
-
2. C:正则化强度的倒数
-
取值 :正浮点数,默认
1.0 -
含义 :
C越小,正则化越强(惩罚越重);C越大,正则化越弱,模型越倾向于拟合训练数据。- 例如
C=0.1表示较强的正则化,C=10表示较弱。
- 例如
-
与
penalty配合 :C乘以损失项,即目标函数为C * J(w) + penalty。
3. solver:优化算法(求解器)
-
取值 :
'lbfgs','liblinear','newton-cg','newton-cholesky','sag','saga' -
默认 :
'lbfgs' -
选择指南:
-
对于小数据集,
'liblinear'是个不错的选择,它支持 L1 正则化。 -
对于多分类问题,
'lbfgs'或'newton-cg'表现良好。 -
对于大规模数据集,
'sag'和'saga'(随机平均梯度)更快,'saga'还支持 L1 正则化。 -
'lbfgs'是默认值,适用于大多数情况。
-
-
注意 :某些求解器不支持特定的
penalty,例如'liblinear'支持 L1 和 L2,'saga'支持所有,'lbfgs'支持 L2 和 none。
4. max_iter:最大迭代次数
-
取值 :整数,默认
100 -
作用:优化算法迭代的上限。如果训练未收敛,可适当增大该值。
5. multi_class:多分类策略
-
取值 :
'auto','ovr','multinomial' -
默认 :
'auto' -
含义:
-
'ovr':一对多(One-vs-Rest),为每个类别训练一个二分类器。 -
'multinomial':多项式逻辑回归(softmax),直接输出多类别概率,此时损失函数变为多类交叉熵。要求求解器支持(如'lbfgs','sag','saga')。 -
'auto':当数据是二分类或求解器支持'multinomial'时自动选择'multinomial',否则选'ovr'。
-
6. class_weight:类别权重
-
取值 :字典或
'balanced',默认None -
作用:用于处理类别不平衡。给少数类更高的权重,使模型更关注它们。
-
'balanced':自动根据样本频率计算权重,n_samples / (n_classes * np.bincount(y))。 -
也可以手动传入字典,例如
{0: 0.5, 1: 2.0}。
-
7. random_state:随机种子
-
取值 :整数,默认
None -
作用 :当求解器涉及随机性(如
'sag','saga','liblinear')时,设置随机种子以确保结果可复现。
8. tol:容忍度
-
取值 :浮点数,默认
1e-4 -
作用 :优化停止的阈值。当损失下降小于
tol时,认为收敛,停止迭代。
9. fit_intercept:是否拟合截距
-
取值 :布尔值,默认
True -
作用 :是否包含偏置项 b。如果数据已经中心化(均值为0),可设为
False。
10. intercept_scaling:截距缩放(仅当 solver='liblinear' 有效)
- 作用:用于调整截距的正则化强度,一般保持默认值1。
四、代码示例与解释
python
from sklearn.linear_model import LogisticRegression
# 创建逻辑回归模型,使用 L2 正则化,C=1.0,求解器 lbfgs,最大迭代 200
model = LogisticRegression(penalty='l2', C=1.0, solver='lbfgs', max_iter=200, random_state=42)
# 训练模型
model.fit(X_train, y_train)
# 查看权重和截距
print("权重系数:", model.coef_)
print("截距:", model.intercept_)
# 预测概率
proba = model.predict_proba(X_test)
# 预测类别
pred = model.predict(X_test)五、总结
-
逻辑回归本质是一个线性模型 + Sigmoid 激活,输出概率,用于分类。
-
损失函数为对数损失,训练即最小化该损失。
-
sklearn的LogisticRegression提供了丰富的参数来控制正则化、优化算法、多分类策略等,以适应不同场景。 -
常用参数如
penalty,C,solver,max_iter需要根据数据规模和问题性质进行选择。
掌握这些,你就能够灵活运用逻辑回归,并理解其背后的原理。
8.为什么分别在训练集、验证集、测试集上都评估一遍?
在机器学习模型开发中,将数据集划分为训练集、验证集和测试集是一种标准做法。你观察到代码中对这三个集合都进行了评估,这不仅是正确的,而且是非常有益的。
一、三个集合各自的作用
1. 训练集(Training Set)
-
用途:用于训练模型,即通过优化算法更新模型的参数(例如逻辑回归的权重)。
-
评估训练集 :计算模型在训练集上的表现,主要目的是检查模型是否已经充分学习了训练数据。如果训练集上的指标(如准确率)很低,说明模型可能欠拟合(未能捕捉数据中的模式);如果训练集上的指标非常高,而验证集/测试集上的指标明显偏低,则提示模型可能过拟合(过度记忆了训练集中的噪声和细节)。
2. 验证集(Validation Set)
-
用途:用于模型选择、超参数调优、以及监控训练过程(如早停)。验证集不参与参数更新,但我们会根据它在验证集上的表现来调整模型结构、学习率、正则化强度等。
-
评估验证集:通过观察验证集上的指标,我们可以判断模型在未见数据上的泛化能力。验证集上的表现是调整模型的重要依据,帮助我们选择性能最佳的模型版本。
3. 测试集(Test Set)
-
用途 :用于最终评估模型的泛化能力。测试集在整个开发过程中应仅使用一次,即在所有模型选择和调优完成后,最后用测试集来评估最终模型的真实性能。
-
评估测试集:得到模型在完全未见数据上的表现,作为模型部署或论文报告的依据。
二、为什么对三个集合都进行评估?
在代码中,训练完成后立即对三个集合都调用 evaluate,目的是获取模型在当前状态下的完整性能快照。这种做法有以下几个好处:
1. 诊断模型的拟合状态(过拟合 vs. 欠拟合)
通过比较训练集、验证集和测试集的指标,我们可以快速判断模型处于何种状态:
| 情况 | 训练集指标 | 验证集/测试集指标 | 诊断 |
|---|---|---|---|
| 理想 | 高 | 高 | 模型泛化良好 |
| 欠拟合 | 低 | 低 | 模型容量不足,或训练不充分 |
| 过拟合 | 很高 | 明显低于训练集 | 模型记忆了训练数据,泛化能力差 |
| 数据泄露 | 高 | 异常高 | 可能验证/测试数据被无意中用于训练 |
例如,如果训练集准确率接近 1.0,而验证集准确率只有 0.8,说明模型过拟合了,需要采取正则化、增加数据量或简化模型等措施。
2. 验证集用于模型选择和调优
在代码中,虽然当前没有显式使用验证集进行调优(如网格搜索),但记录了验证集指标,以便后续分析。如果我们后续需要调整超参数,就可以参考验证集上的表现,而不会污染测试集。如果不记录验证集指标,我们就失去了判断模型是否过拟合的基准。
3. 测试集作为最终标准
测试集上的指标是最终报告的值。但在开发过程中,我们往往需要多次实验,如果每次都看测试集,就可能无意中根据测试集调整模型,导致测试集信息泄露。因此,通常只会在最终阶段才看测试集,而中间过程主要依赖验证集。不过,在实验脚本中一次性评估所有集合,可以方便地输出对比表格,让开发者一目了然。
4. 检查数据分布一致性
如果训练集、验证集、测试集上的指标差异很大,可能提示数据划分存在问题(例如分布不一致),或者验证集/测试集太小导致评估不稳定。这种对比有助于发现数据层面的问题。
三、这样做是否正确?
是的,这是正确的做法,只要遵循以下原则:
-
模型只在训练集上训练(你的代码正是如此)。
-
验证集和测试集不参与训练,仅用于评估。
-
不能根据测试集的表现反过来调整模型,否则测试集就变成了验证集,失去了其最终评估的意义。
在你的代码中,训练完成后一次性对三个集合进行评估,相当于打印了一份"诊断报告",这对于调试和理解模型非常有用。但是请注意,如果在多次实验中都观察测试集指标,并根据它来修改模型,就相当于将测试集信息泄露到了模型选择过程中。因此,在实际开发中,应该仅在最终选定模型后,才使用测试集一次,而中间的模型比较应该基于验证集。
在你的脚本中,因为是一次性运行所有模型并输出结果,且没有根据测试集反馈进行迭代调整,所以这样做是安全的,并且能让你直观地对比各模型的表现。
四、相关知识点拓展
1. 为什么不能只用测试集?
如果只用测试集评估,你只能知道最终模型的表现,但无法诊断模型训练过程中的问题,也无法指导模型改进。没有验证集,你可能会陷入反复调整模型并反复用测试集验证的陷阱,导致测试集信息间接影响模型,最终评估结果过于乐观。
2. 验证集的另一种用法:早停(Early Stopping)
在深度学习训练中,我们常常在每个 epoch 后评估验证集,当验证集指标不再提升时停止训练,以防止过拟合。这就是利用验证集进行动态模型选择。
3. 交叉验证(Cross-Validation)
当数据量较小时,为了更稳定地评估模型,可以使用交叉验证,将训练集进一步划分为多个小训练集和验证集,多次训练取平均。这相当于更充分地利用数据。
4. 评估指标的局限性
仅仅观察准确率、F1 等数值是不够的,还需要结合业务场景理解。例如,在恶意代码检测中,召回率(检出率)可能比精确率更重要,因为漏报的代价更高。评估时,我们需要关注那些与业务目标最相关的指标。
五、总结
-
对训练集、验证集、测试集都进行评估,是为了全面了解模型的拟合状态和泛化能力。
-
训练集指标反映模型的学习程度,验证集指标指导模型选择和调优,测试集指标提供最终的性能基准。
-
这种做法正确且有益,但需注意测试集只能用于最终一次性评估,避免信息泄露。
-
在你的代码中,一次性输出三个集合的指标,有助于快速对比模型、诊断问题,是机器学习实验的良好实践。
通过这样的评估,你不仅能知道模型"好不好",还能知道"为什么好"或"为什么不好",从而更有针对性地改进模型。
9.传统机器学习与深度学习在训练评估流程上的区别
一、深度学习为什么要记录每轮损失并早停?
深度学习模型(如MLP、LSTM、Transformer)通常采用迭代优化算法 (如SGD、Adam)进行训练,每轮(epoch)更新一次参数。随着训练轮数增加,模型在训练集上的损失会逐渐下降,但在验证集上的损失可能先下降后上升,这就是过拟合的典型表现。
为了获得泛化能力最强的模型,我们通常:
-
在每个epoch结束后计算验证集上的损失(或指标)。
-
当验证损失连续若干轮不再下降(甚至上升)时,停止训练(早停,early stopping)。
-
保存验证损失最低的那个epoch的模型参数(最佳模型),而不是最后一轮的参数。
这样做的好处:避免模型在训练后期过度拟合训练数据,从而在未知数据上表现更好。
二、传统机器学习为什么通常不这样做?
传统机器学习模型(如逻辑回归、SVM、随机森林、XGBoost)的训练方式有所不同:
-
逻辑回归、线性SVM :使用凸优化,通过梯度下降或拟牛顿法迭代求解,但通常迭代到收敛为止,且往往有正则化防止过拟合。在sklearn中,它们直接调用
.fit()一次性完成训练,中间过程不暴露每轮损失,但我们可以通过设置max_iter和tol控制收敛条件,本质上也是迭代优化。 -
随机森林、XGBoost、LightGBM :基于决策树的集成方法,训练过程是逐棵树添加,也可以监控验证集指标进行早停(如XGBoost的
early_stopping_rounds)。但在你的代码中,你使用的是固定参数(如n_estimators=100),并未启用早停,因此相当于直接训练完整集成。
关键区别:
-
深度学习对过拟合更敏感,训练时间长,因此需要动态监控和早停。
-
传统机器学习模型要么收敛稳定(逻辑回归),要么有内置的正则化和收敛控制,且训练较快,因此常见做法是直接训练完成后评估测试集,或通过交叉验证调参。
但在严谨的对比实验中,传统机器学习也可以(也应该)使用验证集进行早停或调参 ,例如对XGBoost设置early_stopping_rounds。你的代码中固定参数,可以视为一种基线对比,没有充分利用验证集进行模型选择。
三、你的代码中深度学习部分是如何处理的?
在run_dl_comparison函数中,你使用了DeepLearningTrainer类,并传入了patience=15,这表明训练过程中会监控验证损失,并在15轮不改善时停止。训练完成后,trainer.fit返回history(包含每轮损失),然后你调用trainer.predict对测试集进行预测。
关键问题是:trainer.predict使用的是最终模型 还是验证损失最低的最佳模型 ?这取决于DeepLearningTrainer的实现。如果该类在训练过程中保存了最佳模型(通常通过patience和save_best参数控制),那么predict应该使用那个最佳模型。如果它没有保存最佳模型,而只是用了最后一轮的模型,那么评估结果可能不是最优的,且与深度学习的最佳实践不符。
假设DeepLearningTrainer实现了早停并加载最佳模型(这是常见做法),那么你的代码是合理的:它使用最佳模型对训练集、验证集、测试集分别评估,输出三个集合上的指标,以便诊断过拟合。
四、为什么对三个集合都进行评估?
无论传统还是深度学习,在最终评估时同时对训练集、验证集、测试集进行评估都有重要意义:
-
训练集指标:反映模型对训练数据的拟合程度。如果训练集指标远高于验证集/测试集,说明过拟合;如果训练集指标也很低,说明欠拟合。
-
验证集指标:在深度学习训练中用于早停和模型选择,这里验证集指标可以验证最终最佳模型在未见数据(但参与过早停决策)上的表现。
-
测试集指标:最终泛化能力的基准,仅在最后使用一次。
在对比实验中,输出三个指标可以帮助你快速比较不同模型的过拟合倾向。例如,如果一个模型训练集准确率接近1.0,但验证集/测试集较低,说明它过拟合严重,可能不适合部署。
五、你的做法是否正确?
基本正确,但需要注意以下几点:
-
确保深度学习部分使用的是最佳模型 :检查
DeepLearningTrainer的实现,确认它在训练过程中保存了验证损失最低的模型,并在预测时加载该模型。如果它没有这样做,你应该修改代码,在训练结束后加载最佳模型再进行评估。 -
验证集不能用于调参后再次评估:在你的代码中,深度学习模型使用了验证集进行早停(即模型选择),然后又在同一验证集上评估,这会导致验证集上的指标略微乐观(因为模型是依据该验证集选出的),但它仍然是合理的,因为最终我们更关注测试集。在理想情况下,如果你还有额外的调参(如学习率搜索),应该再分出一部分数据作为验证集2,或者使用交叉验证。不过对于当前实验,仅做一次早停,问题不大。
-
传统机器学习模型没有利用验证集:你使用了固定参数,没有基于验证集调优,这相当于只比较了默认参数下的表现。如果想更公平地与深度学习比较,可以对传统模型也进行简单的超参数搜索(如网格搜索),并用验证集选择最佳参数,然后再评估测试集。
六、总结
-
深度学习需要监控验证损失并早停,因为训练过程容易过拟合。
-
传统机器学习也可以这样做,但很多实现默认不开启,需要手动配置。
-
你的代码对三个集合都评估,是一种诊断模型拟合状态的好习惯。
-
关键是确保深度学习评估时使用的是早停后的最佳模型,而不是最后一轮模型。
如果你能确认DeepLearningTrainer正确保存了最佳模型,那么你的实验设计是合理且符合机器学习最佳实践的。希望这解答了你的疑惑!
10.SVM支持向量机
一、SVM 是什么?它要做什么?
支持向量机是一种监督学习算法 ,主要用于分类 (也可用于回归,即 SVR)。其核心思想是:在特征空间中找到一个超平面,将不同类别的样本分开,并且使得离超平面最近的样本点(即支持向量)到超平面的距离(间隔)尽可能大。
直观理解:
想象二维平面上有两类点(用圆圈和叉表示),我们希望画一条直线将它们分开。SVM 的目标不是随便一条能分开的线,而是找到一条线,使得它离两侧最近的点都尽可能远。这条线就是最大间隔超平面 。那些离超平面最近的点(决定了间隔宽度)就是支持向量。
二、SVM 的核心概念
1. 线性可分与硬间隔(Hard Margin)
假设数据完全线性可分,我们希望找到一个超平面 ,使得对于所有样本
,有:
-
若
-
若
这等价于。此时,两类之间的间隔 (margin)为
。最大化间隔等价于最小化
。
简单来说,它的逻辑是:
- 确定边界 :通过约束条件
- 量化间距 :推导出几何间隔(Geometric Margin)为
- 转化问题 :为了让间隔最大,我们转而寻求
关键点:硬间隔极其依赖"完全线性可分"这一假设。如果数据中存在哪怕一个噪点,模型可能就无解。
2. 软间隔(Soft Margin)与正则化参数 C
现实数据往往有噪声或线性不可分。软间隔 SVM 引入松弛变量 ,允许一些样本违反间隔约束:
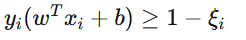
目标函数变为:
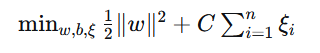
软间隔让 SVM 从"理想主义"转向了"实用主义"。
这里的核心权衡在于那个
在实际操作中,调节
3. 核技巧(Kernel Trick)
当数据在原始特征空间线性不可分时,我们可以将其映射到更高维空间,使其变得可分。但显式计算映射可能非常复杂。核技巧允许我们在低维空间直接计算高维空间的内积,从而隐式地进行映射。
常用的核函数:
-
线性核 :
-
多项式核 :
-
RBF 核(高斯核) :
-
Sigmoid 核 :
RBF 核是最常用的,因为它可以逼近任意形状的决策边界,且参数少。
这就是 SVM 的"降维打击"策略------不求真的搬运数据,只求算出在高维空间的距离感。
关于这几种核函数,有几个实战中的细节值得注意:
- 线性核(Linear) :虽然最简单,但在特征维度远大于样本数(如文本分类、基因序列)时效率最高,且不容易过拟合。
- RBF 核(高斯核) :它的核心在于
- 计算优势 :核技巧的精妙之处在于,我们不需要知道映射函数
具体长什么样,只需要定义好内积运算规则。这避开了"维度灾难",让算法能处理理论上无限维的空间。
至此,你已经梳理了 SVM 的三大支柱:最大间隔 、对偶/软间隔 、核技巧。
4. 支持向量(Support Vectors)
训练完成后,只有那些位于间隔边界上或间隔内部的样本点(即 的样本)才影响决策边界,这些点称为支持向量。其他远离边界的点对模型无贡献。这使得 SVM 模型具有稀疏性,且对非支持向量的噪声不敏感。
这正是SVM(支持向量机) 名称的由来,也是它最迷人的地方:极简主义。
在模型训练完成后,你可以删掉 90% 甚至更多的非支持向量数据,而最终生成的决策边界(分类线)完全不会改变。这种特性带来了几个实战优势:
- 鲁棒性:只要远离边界的"深腹地"样本不变成边界点,即便它们有轻微抖动或噪声,模型也稳如泰山。
- 内存友好:预测时,模型只需要存储那一小部分"骨干"样本(支持向量),而不是整个数据集。
- 稀疏解 :在对偶问题中,绝大多数样本对应的拉格朗日乘子
特别提醒 :
在硬间隔 下,支持向量只在边界上;但在软间隔下,所有被"宽容"掉的、落在间隔带内部甚至分错边的点,也通通被视为支持向量。
三、sklearn.svm.SVC 常用参数详解
python
from sklearn.svm import SVC
model = SVC()1. C:惩罚参数(默认 1.0)
-
含义:软间隔中的正则化系数,控制对误分类的惩罚强度。C 越大,训练集准确率越高,但可能过拟合;C 越小,间隔越大,泛化能力可能更好,但可能欠拟合。
-
取值:正浮点数。
2. kernel:核函数类型(默认 'rbf')
-
可选值:
-
'linear':线性核, -
'poly':多项式核, -
'rbf':高斯径向基核, -
'sigmoid':Sigmoid 核, -
也可以传入自定义核函数(可调用对象)
-
3. gamma:核函数系数(对 'rbf', 'poly', 'sigmoid' 有效)
-
含义:单个样本的影响半径。gamma 越大,决策边界越弯曲,模型复杂度高(易过拟合);gamma 越小,边界越平滑,模型简单(易欠拟合)。
-
取值:
-
'scale'(默认): -
'auto': -
正浮点数:用户自定义。
-
4. degree:多项式核的阶数(默认 3)
- 仅在
kernel='poly'时有效,表示多项式核的
5. coef0:核函数中的独立项(默认 0.0)
- 仅在
kernel='poly'或'sigmoid'时有效,对应公式中的 r。
6. probability:是否启用概率估计(默认 False)
- 作用 :若为 True,训练后会使用 Platt 缩放将决策值转换为概率,之后可用
predict_proba方法输出概率。这会增加训练时间。
7. shrinking:是否使用启发式收缩(默认 True)
- 布尔值,表示是否使用收缩技巧来加速训练。通常保持默认。
8. tol:容忍度(默认 1e-3)
- 优化算法停止的阈值,当损失函数下降小于
tol时认为收敛。
9. cache_size:核缓存大小(默认 200,单位 MB)
- 指定为核函数计算分配的内存大小,适当增大可加速训练。
10. class_weight:类别权重(默认 None)
- 用于处理不平衡数据。可设为
'balanced',根据样本频率自动调整权重,或传入字典{class_label: weight}。
11. decision_function_shape:决策函数形状(默认 'ovr')
-
对于多分类:
-
'ovr':一对多(one-vs-rest),为每个类别训练一个二分类器,决策函数输出形状(n_samples, n_classes)。 -
'ovo':一对一(one-vs-one),训练(n_samples, n_classes*(n_classes-1)//2),然后通过投票得到最终类别。但SVC内部默认使用'ovr'的决策函数形式,实际多分类策略由multi_class参数控制(但SVC的multi_class参数已弃用,统一用decision_function_shape控制输出形状,实际分类时仍用 libsvm 的一对一策略?这里有点复杂,但用户通常不需要关心,保持默认即可。)
-
12. random_state:随机种子(默认 None)
- 当启用概率估计时,用于随机数生成,保证结果可复现。
四、SVM 模型内部结构(数学形式)
训练完成后,SVC 对象内部存储了以下重要属性:
-
support_:支持向量的索引。 -
support_vectors_:支持向量的特征值(形状(n_sv, n_features))。 -
n_support_:每个类别的支持向量个数。 -
dual_coef_:对偶系数,即 -
intercept_:决策函数中的截距
当你用 Python 的
scikit-learn训练完模型(比如model.fit(X, y)),模型会把学到的知识存进这几个变量里:
support_(索引) :这是个"名单"。它记录了训练集中哪些样本点成为了支持向量(即那些离边界最近、最关键的点)。比如它告诉你:第 5、12、88 号样本是支持向量。support_vectors_(坐标) :这是那些支持向量的具体数值。模型不再关心其他成千上万的点,只把这几个关键点的坐标存下来。n_support_(计数):一个简单的统计。比如它会告诉你:第一类里有 10 个支持向量,第二类里有 12 个。dual_coef_(权重
intercept_(偏移量
决策函数(对于二分类):
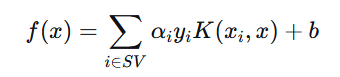
-
-
-
最终分类结果由
对于概率输出,probability=True 会在训练后额外拟合一个逻辑回归模型将映射为概率。
(测相似度) :当进来一个新样本
(汇总):把所有支持向量给出的分数全部加起来。
- +b(修正):最后加上偏移量,得到最终得分。
最后结果:
- 如果算出来的得分
- 如果得分
这张图的核心意义在于:SVM 是一个非常"节省内存"的模型。 它在做预测时,不需要回看所有的原始数据,只需要带着那几个支持向量 和对应的权重系数,就能通过这个数学公式快速算出结论。
SVM支持向量机训练完之后,模型会把学到的知识存哪几个变量里,有哪些重要的模型属性需要我们知道?与集成学习(树模型)存储成百上千棵树不同,SVM(支持向量机) 的"知识"非常精简。它不存储原始数据,而是只保留那些决定分类边界的关键点------支持向量。
在 Scikit-learn 的
SVC模型执行完fit后,知识主要存在以下核心变量中:1. 核心产出(边界在哪里?)
support_vectors_: 这是模型最核心的"知识"。它存储了所有被选为支持向量的样本点。只有这些点决定了超平面的位置,删除其他非支持向量的样本,模型完全不会改变。support_: 存储支持向量在原始训练集中的索引。n_support_: 每个类别分别有多少个支持向量。例如[10, 12]表示第一类有10个,第二类有12个。3. 模型元数据
classes_: 训练集中的类别标签。fit_status_: 如果为0表示拟合成功;如果为1则表示可能没有收敛(通常需要增加max_iter)。
总结对比
- 树模型:存的是"IF-THEN"的逻辑路径(森林)。
- SVM:存的是"少数关键样本点"及其权重(支持向量)。
如果你发现
support_vectors_的数量占了训练集的很大比例,通常意味着模型过拟合 了,或者参数C设得太小。

五、总结
-
SVM 的目标:找到最大间隔超平面,提高泛化能力。
-
软间隔参数 C:平衡间隔宽度与误分类点数。
-
核函数与 gamma:解决非线性问题,gamma 控制模型复杂度。
-
概率输出:通过 Platt 缩放获得,但会增加训练时间。
-
模型内部:仅依赖支持向量,具有稀疏性和鲁棒性。
11.随机森林分类器
随机森林是一种基于集成学习的监督学习算法,它通过构建多个决策树并将它们的预测结果进行综合(投票或平均)来提高模型的准确性和鲁棒性。它由Leo Breiman在2001年提出,是目前最常用、最强大的机器学习算法之一。
一、随机森林在做什么?
随机森林的核心思想是:"三个臭皮匠,顶个诸葛亮"。它通过组合多个弱学习器(决策树)来构建一个强学习器。具体来说:
-
训练阶段 :构建大量的决策树,每棵树都在原始训练集的一个随机子集 (有放回抽样)上训练,并且在每个节点分裂时,只考虑随机选择的特征子集。这种随机性使得每棵树都略有不同,从而降低模型整体的方差。
-
预测阶段 :对于分类任务,每棵树输出一个类别,随机森林通过多数投票决定最终类别;对于回归任务,则取各棵树输出的平均值。
随机森林既能处理分类问题,也能处理回归问题(对应 RandomForestRegressor)。它继承了决策树的优点(如可解释性、处理混合类型数据、无需特征标准化),同时通过集成学习克服了决策树容易过拟合的缺点。
二、模型内部结构
随机森林的内部结构可以看作是一个决策树的集合。每个决策树本身是一个二叉树结构,内部节点代表对某个特征的测试(例如"特征A是否大于0.5"),叶子节点代表一个类别(或回归值)。
训练过程(以分类为例):
-
Bootstrap抽样 :从原始训练集(大小为N)中有放回 地随机抽取N个样本,形成一个新的训练子集(称为bootstrap样本)。这个过程会使得大约1/3的样本未被抽中,这些样本称为袋外数据(Out-of-Bag, OOB),可用于评估模型。
-
构建决策树:
-
在树的每个节点,随机从所有特征中选出
max_features个特征(通常取 )。
)。 -
根据某种指标(如基尼不纯度或信息增益),从这组特征中选择最优特征进行分裂。
-
重复上述过程,直到满足停止条件(如达到最大深度、叶子节点样本数小于阈值等)。通常不进行剪枝,让树充分生长。
-
-
重复 :对每一棵树重复步骤1-2,生成指定数量(
n_estimators)的树。
预测过程:
-
输入一个新样本,让它通过每一棵树,得到每棵树的预测类别。
-
收集所有树的预测结果,进行多数投票,票数最高的类别作为最终输出。
要把随机森林 说明白,最简单的办法是把它想象成一场"专家评审会"。
你可以把随机森林看作是一个评审委员会 ,而里面的每一棵"决策树"都是一位专家。
1. 训练过程:如何培养这些专家?
- Bootstrap 抽样(给专家发不同的卷子):
如果你给所有专家看一模一样的资料,他们的见解就会趋同。为了让他们有不同的视角,我们从原始资料里"有放回地乱翻"出一叠资料给专家 A,再乱翻出一叠给专家 B。因为是随机抽,有的资料会被重复抽到,有的则没被抽到(袋外数据)。这样每个专家学到的东西就略有不同。- 构建决策树(限制专家的视野):
在每个专家分析问题时,我们不让他看所有的指标(特征)。比如有10个指标,我们随机选3个让他挑。这样是为了防止某个"明星指标"遮盖了其他有用信息的价值。专家会根据这几个指标,像玩"20个问题"游戏一样,不断通过"是/否"来做判断,直到得出结论。- 重复:
我们重复培养出 100 个甚至 1000 个这样背景略有不同的专家。2. 预测过程:如何得出最终结论?
- 投票制:
当有一个新病人(新样本)需要诊断时,我们让这 100 个专家都看一遍。
- 专家 1 说:是感冒。
- 专家 2 说:是过敏。
- 专家 3 说:是感冒。
- ......
最后数一数,如果 80 个专家说感冒,20 个说过敏,那随机森林的最终结论就是:感冒。
为什么这样做有效?
- 防止跑偏(鲁棒性): 单个专家可能会因为钻牛角尖(过拟合)而犯错,但一帮视角不同的专家集体犯同一个错误的可能性很低。
- 不用剪枝: 因为有了"集体决策",我们允许每个专家把问题钻研得很深(树长得很茂盛),不需要限制他们。
简单总结: 随机森林就是"用随机的方式让专家各具特色,再用投票的方式消除个人偏见。"
训练完之后,模型会把学到的知识存哪几个变量里,有哪些重要的模型属性需要我们知道?Random Forest (并行集成)、XGBoost 和 LightGBM(串行提升)。
相比于 Boosting 算法通过残差迭代,随机森林(Random Forest) 的"知识"分布更加均匀且独立。模型执行完
fit后,核心信息主要存在以下变量中:1. 核心产出(模型把树藏在哪?)
estimators_: 这是随机森林最重要的属性。它是一个列表,里面按顺序存储了你训练出来的 所有决策树实例 (DecisionTreeClassifier对象)。你可以通过model.estimators_[0]访问第一棵树,甚至可以用export_graphviz单独把它画出来。feature_importances_: 基于 Gini 不纯度下降(Gini Importance)计算的特征重要性。由于森林是由多棵独立的树组成的,这个值是所有树特征重要性的平均值。oob_score_: 如果你在初始化时设置了oob_score=True,这个变量会存储利用"袋外数据"(没参与训练的那 1/3 数据)计算出的验证得分。这相当于自带了一个交叉验证结果。2. 模型结构与元数据
n_features_in_: 训练时输入的特征总数。feature_names_in_: 训练数据的特征名称(如果输入是 DataFrame)。classes_: 分类任务中的类别标签(例如[0, 1]或['cat', 'dog'])。3. 随机森林的"特殊点"
与 XGBoost/LightGBM 不同,随机森林的知识是横向平铺的:
- 独立性 :你可以并行地提取
estimators_中的每一棵树进行分析,它们之间没有先后依赖关系。- 森林属性 :通过
model.base_estimator_可以看到构建森林所用的基学习器模板(默认是深度不限的决策树)。
深度思考 :由于随机森林的树通常长得非常深(不剪枝),它的
estimators_会占用巨大的内存。
三、为什么随机森林效果好?
-
降低方差:由于每棵树在不同数据子集和特征子集上训练,它们的预测误差具有一定的独立性。通过平均(或投票),可以显著降低模型的方差,同时保持偏差较低。
-
抗过拟合:即使个别树过拟合,集成后的结果也不容易过拟合。
-
处理高维数据:随机特征选择使得算法在高维特征空间中依然高效,并且可以输出特征重要性。
四、sklearn.ensemble.RandomForestClassifier 常用参数详解
RandomForestClassifier 提供了丰富的参数来控制模型的行为,理解它们对于调优模型至关重要。
1. n_estimators(整数,默认=100)
-
随机森林中决策树的数量。
-
通常树越多,模型性能越好,但计算时间和内存消耗也会增加。当树的数量增加到一定程度后,性能提升会趋于平缓。
2. max_depth(整数或None,默认=None)
-
每棵树的最大深度。如果为None,则节点会一直分裂直到所有叶子都是纯净的(或包含少于
min_samples_split个样本)。 -
限制深度可以防止过拟合,尤其在数据量大时。
3. min_samples_split(整数或浮点数,默认=2)
-
内部节点再分裂所需的最小样本数。如果为整数,表示绝对数量;如果为浮点数,则表示占训练样本总数的比例。
-
增大该值可以防止过拟合,使树结构更简单。
4. min_samples_leaf(整数或浮点数,默认=1)
-
叶子节点所需的最小样本数。同样可以是整数或浮点数。
-
限制叶子节点的最小样本数可以平滑模型,避免学习到噪声。
5. max_features(整数、浮点数、字符串或None,默认='sqrt')
-
寻找最佳分裂时考虑的特征数量。
-
如果是整数,表示直接指定数量。
-
如果是浮点数,表示占总特征数的比例。
-
如果是字符串:
'sqrt'表示 ;
;'log2'表示 ;
;'auto'同'sqrt';None表示使用所有特征。
-
-
较小的值能增加树之间的差异性,降低过拟合,但可能降低单棵树的性能。
6. bootstrap(布尔值,默认=True)
- 是否使用bootstrap抽样。如果为False,则每棵树使用整个数据集训练(此时所有树相同,失去随机性,不推荐)。
7. oob_score(布尔值,默认=False)
- 是否使用袋外数据(未被抽中的样本)来评估模型。如果为True,训练后会计算出袋外得分(
oob_score_),可作为模型泛化能力的一个无偏估计,尤其当数据量较小时有用。
8. random_state(整数或RandomState实例,默认=None)
- 控制bootstrap抽样和特征选择的随机性。设置固定值可以确保结果可复现。
9. n_jobs(整数,默认=None)
- 并行训练和预测使用的CPU核心数。
-1表示使用所有可用的核心。
10. class_weight(字典、'balanced'或None,默认=None)
- 用于处理类别不平衡。
'balanced'会根据样本频率自动调整权重,使得少数类的权重更高。也可以手动传入字典,如{0: 1, 1: 10}。
11. warm_start(布尔值,默认=False)
- 如果为True,再次调用
fit时会保留已有的树并添加新的树,而不是重新训练。这可用于增量学习或调整n_estimators。
12. ccp_alpha(非负浮点数,默认=0.0)
- 最小成本复杂度剪枝参数。用于后剪枝,值越大剪枝越强(树越简单)。需要配合
max_depth等使用。
13. max_samples(整数或浮点数,默认=None)
- 如果
bootstrap=True,可以设置每个bootstrap样本的大小。如果是整数,表示样本数;如果是浮点数,表示占训练集的比例。这可以控制每棵树使用的数据量,进一步增加随机性。
五、随机森林的额外功能
1. 特征重要性(Feature Importance)
-
训练完成后,可以通过
model.feature_importances_获取每个特征的重要性。计算方式是基于所有树中,该特征在分裂时带来的平均不纯度减少 (如基尼系数的减少)的加权和。值越高,特征越重要。 -
这为特征选择提供了有力依据。
2. 袋外得分(Out-of-Bag Score)
- 如果设置
oob_score=True,模型会利用袋外数据(未被当前树使用的样本)来评估该树的性能,最终得到整个模型的袋外得分(存储在oob_score_中)。这个得分可以近似替代交叉验证,节省时间。
六、随机森林的优缺点
优点:
-
可以处理高维数据,且无需特征选择(特征重要性可辅助)。
-
不需要特征标准化。
-
能够处理非线性关系。
-
抗过拟合能力强。
-
可以输出概率(
predict_proba)。 -
可解释性较好(特征重要性)。
缺点:
-
模型规模较大,占用内存多,预测速度相对较慢(尤其是树多时)。
-
对于某些噪声较大的数据,可能仍然过拟合(但比单棵树好)。
-
模型内部机制不如单棵决策树直观。
七、使用示例
python
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
# 生成示例数据
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
# 创建随机森林分类器
rf = RandomForestClassifier(
n_estimators=100,
max_depth=10,
min_samples_split=5,
max_features='sqrt',
random_state=42,
n_jobs=-1
)
# 训练
rf.fit(X, y)
# 预测
y_pred = rf.predict(X[:5])
# 概率预测
y_proba = rf.predict_proba(X[:5])
# 特征重要性
importances = rf.feature_importances_12.XGBoost分类器
一、XGBoost 是什么?它在做什么?
XGBoost 的全称是 eXtreme Gradient Boosting (极致梯度提升)。它是一种基于 Boosting 思想的集成学习算法,可以通俗地理解为一种"三人行,必有我师"的迭代优化过程。
- 核心任务:XGBoost 的核心任务是通过构建一系列相互依赖的决策树,来准确地预测目标值(如分类标签)。
-
工作流程:
-
启动 :先用一个简单的模型(比如一棵很浅的决策树)对数据进行预测,此时预测肯定有误差,这个误差被称为残差。
-
迭代优化 :接下来,第二棵树不是去学习原始数据,而是去学习第一棵树犯的错误(残差),目的是弥补第一棵树的不足。
-
持续改进:第三棵树再去学习前两棵树组合后仍然存在的残差,依此类推。每一棵新树都是为了"修正"前面所有树的集体错误。
-
-
最终输出 :将所有树的预测结果累加起来,就得到了最终的强预测模型。这个过程就像一位经验丰富的工匠,不断地打磨和修正自己的作品,直到满意为止。
二、XGBoost 的内部结构(它是如何做到"极致"的?)
XGBoost 在传统的梯度提升决策树(GBDT)基础上,做了一系列精妙的优化,这也是它名字中"极致"的由来。
- 二阶泰勒展开 :在优化目标函数时,传统 GBDT 只用到了一阶导数信息(梯度)。而 XGBoost 通过二阶泰勒展开,同时利用了一阶导数和二阶导数(海森矩阵)。这相当于在寻找最优解时,不仅知道了下山的方向(梯度),还知道了地形的曲率(二阶导),从而能更精确、更快速地找到最低点。
- 加入正则化项 :为了防止模型过于复杂而导致过拟合,XGBoost 在目标函数中显式地加入了正则化项。这个惩罚项会控制树的复杂度(比如叶子节点的数量和叶子节点上的权重),让模型在追求高精度的同时,保持简洁和稳定。
- 自动处理缺失值:XGBoost 能够自动学习出缺失值的处理方向。在训练时,它会将缺失值分别放入左右子树计算损失,选择损失减少更优的方向作为默认方向,这使得我们在处理含有缺失值的数据时非常方便。
训练完之后,模型会把学到的知识存哪几个变量里,有哪些重要的模型属性需要我们知道?
以下是开发者最需要关注的几个核心属性:
与 LightGBM 类似,XGBoost 的核心知识也封装在底层的 C++ Booster 对象中,但它的属性命名稍微有些不同:
1. 核心产出(模型存储了什么?)
get_booster(): 这是最重要的入口。XGBoost 的所有树结构、权重、分裂点都存在这个Booster对象里。feature_importances_: 默认返回特征的增益(Gain),即该特征在分裂时带来的损失函数下降总量。best_iteration: 如果开启了早停(Early Stopping),它会记录验证集效果最好时对应的树棵数。best_score: 记录最优迭代时的验证集评分(如mlogloss或auc)。2. 模型关键属性
n_features_in_: 训练时输入的特征总数(Scikit-learn 兼容属性)。feature_names_in_: 记录训练时的特征名称。如果报错"特征顺序不一致",通常要来检查这个变量。intercept_或base_score: 模型预测的初始值(通常是 0.5)。模型所有的树都是在这个"地基"上通过残差累加的。3. 如何"暴力"提取这些知识?
如果你想看每一棵树长什么样,XGBoost 提供了非常直观的工具:
get_dump(): 将所有决策树导出成文本格式,你可以看到每一层if (feature < threshold) then leaf1 else leaf2的逻辑。trees_to_dataframe(): 这是一个神器,它把所有树的节点(分裂特征、阈值、叶子节点权重)全部转成一个 Pandas 表格,非常适合做模型解释。evals_result(): 如果你在fit时传入了eval_set,这个变量会记录每一轮迭代后验证集的误差变化曲线。
对比建议 :XGBoost 的
feature_importances_有五种计算方式(Weight, Gain, Cover, Total_Gain, Total_Cover),而 LightGBM 默认只有两种。
三、xgboost.XGBClassifier 常用参数详解
在你的 XGBoostClassifier_ 类中,已经设置了几个最核心的参数。下面我将分类介绍更多常用参数,帮助你更灵活地调优模型。
1. 常规/通用参数
| 参数 | 含义与作用 | 我的代码 |
| n_estimators | 提升轮数,即要建立的决策树(弱学习器)的数量 。通常,树越多模型效果越好,但会增加计算时间并有过拟合风险。 | n_estimators=100 |
| learning_rate | 学习率 ,控制每棵树的贡献权重 。一个较小的学习率会让模型更加稳健,但需要更多的树(n_estimators)来达到同等效果。 | learning_rate=0.1 |
| n_jobs | 使用 CPU 的并行线程数。设置为 -1 可以使用所有核心,极大加速训练 。 | n_jobs=-1 |
| random_state | 随机数种子,用于确保结果的可复现性 。 | random_state=42 |
verbosity |
控制训练过程中日志信息的详细程度(0: 静默模式,3: 调试模式)。你在代码中通过 verbose=False 在 fit 方法里关闭了输出。 |
(通过 verbose=False 控制) |
|---|
2. 模型/树结构参数
| 参数 | 含义与作用 | 我的代码 |
| max_depth | 树的最大深度 。深度越大,模型越复杂,能捕捉到更精细的模式,但也更容易过拟合。 | max_depth=6 |
| min_child_weight | 子节点所需的最小样本权重和 。可以理解为防止模型学习到过于特殊的样本,值越大,模型越保守。 | (未设置,使用默认值1) |
gamma |
分裂所需的最小损失减少量 。只有当一次分裂带来的损失下降大于这个值时,节点才会分裂。gamma 值越大,算法越保守,相当于正则化项。 |
(未设置,使用默认值0) |
|---|
3. 学习任务参数
| 参数 | 含义与作用 | 我的代码 |
| objective | 指定学习任务的目标函数。对于二分类,常用 'binary:logistic' ,会输出概率 。XGBClassifier 默认会根据 y 自动选择。 | (未显式设置,由类自动处理) |
| eval_metric | 评估指标 ,用于验证集 。在你的代码中设为 'logloss',即对数损失,用于二分类问题的评估 。 | eval_metric='logloss' |
scale_pos_weight |
正负样本权重平衡 。在正负样本极不平衡时(例如信用卡欺诈检测),可以设置为 sum(negative_samples) / sum(positive_samples),让模型更关注少数类。 |
(未设置,处理不平衡数据时很重要) |
|---|
4. 防止过拟合的参数
| 参数 | 含义与作用 | 我的代码 |
| subsample | 训练每棵树时,对训练集的采样比例 。设置为 0.8,意味着每棵树随机使用 80% 的数据进行训练,增加了随机性,有助于防止过拟合。 | (未设置,使用默认值1) |
| colsample_bytree | 训练每棵树时,对特征的采样比例 。与随机森林类似,只使用一部分特征来构建每棵树,能有效降低过拟合。 | (未设置,使用默认值1) |
| reg_alpha | L1 正则化项系数 。L1 正则化可以使一些特征权重变为0,起到特征选择的作用,让模型更稀疏。 | (未设置,使用默认值0) |
| reg_lambda | 随L2 正则化项系数 。L2 正则化会限制权重的平方和,防止权重过大,是防止过拟合的常用手段。 | (未设置,使用默认值1) |
early_stopping_rounds |
早停轮数 。在训练时,如果模型在验证集上的表现在连续 early_stopping_rounds 轮内都没有提升,训练就会提前终止,并返回最佳模型,非常实用。 |
(你已经在 fit 方法中预留了 eval_set,只需添加此参数即可实现) |
|---|
四、结合你的代码,有哪些可以优化的地方?
你在 XGBoostClassifier_ 类中的实现非常清晰,特别是预留了 eval_set 接口,这为后续优化提供了极大的便利。结合上面的知识点,可以这样优化:
- 启用早停 (
early_stopping_rounds) :这是最推荐的一步。在你的fit方法中,可以增加early_stopping_rounds参数,并将其传递给底层的self.model.fit()。同时,建议保存训练过程中的历史指标,方便后续分析。
python
def fit(self, X, y, eval_set=None, early_stopping_rounds=None):
# ...
if eval_set is not None:
self.model.fit(X, y, eval_set=[eval_set],
early_stopping_rounds=early_stopping_rounds,
verbose=False)
# 训练后可以访问训练历史
self.evals_result_ = self.model.evals_result()
# ...-
处理类别不平衡 :从你之前提供的指标来看,数据是平衡的,所以暂时不需要。但如果将来遇到不平衡数据,
scale_pos_weight是一个非常有用的参数。 -
调整模型复杂度:如果你发现模型有轻微过拟合(训练集指标远高于验证集),可以尝试:
-
降低
max_depth(比如从 6 降到 4)。 -
引入
subsample(比如设为 0.8) 或colsample_bytree(比如设为 0.8)。 -
适当增大
reg_lambda或reg_alpha。
-
五、总结
xgboost.XGBClassifier 是一个基于梯度提升决策树的强大分类器,它通过迭代地添加树来"纠正"前序树的错误,并利用二阶导数 和正则化等技术实现了精度和泛化能力的"极致"平衡。
它的核心参数可以分为控制模型结构(如 max_depth)、学习过程(如 learning_rate, n_estimators)、防止过拟合(如 subsample, reg_alpha)以及处理特定任务(如 scale_pos_weight)几大类。理解这些参数,能让你更好地驾驭这个算法,构建出更优秀的模型。
13.LigtGBM分类器
一、LightGBM 是什么?它要做什么?
LightGBM(Light Gradient Boosting Machine)是微软开源的梯度提升决策树(GBDT)框架,与 XGBoost 类似,也是一种基于决策树的集成学习算法。它的核心目标是在不降低精度的情况下,大幅提升训练速度和降低内存消耗,特别适合处理大规模数据。
核心创新点:
-
基于直方图的算法 :将连续特征离散化为直方图桶(bins),减少了计算分裂点时的复杂度,内存占用从原来的
O(数据量 * 特征数)降到O(桶数 * 特征数)。 -
GOSS(Gradient-based One-Side Sampling,基于梯度的单边采样):
-
传统 GBDT 训练时,所有样本都参与计算梯度。
-
GOSS 的思想是:梯度大的样本(训练不足的样本)更重要,全部保留;梯度小的样本(训练较好的样本)随机采样一部分,并乘以一个常数来补偿信息损失。这大大减少了计算量。
-
-
EFB(Exclusive Feature Bundling,互斥特征捆绑):
-
在高维稀疏数据中,很多特征不会同时非零(例如 One-hot 编码后的特征)。
-
EFB 将这些互斥特征捆绑成一个新的特征,从而降低特征维度,加速训练。
-
-
Leaf-wise 生长策略:
-
传统 GBDT 实现(如 XGBoost 的默认模式)采用 level-wise 生长:按层生长,同一层所有节点都分裂。
-
LightGBM 采用 leaf-wise 生长:每次从当前所有叶子中,找到分裂增益最大的叶子进行分裂,然后继续。
-
这种方式可以更快地降低损失,但容易过拟合,因此通常需要限制
max_depth或使用num_leaves来控制。
-
二、模型内部结构
LightGBM 的内部结构可以看作是一个决策树的集合 。但与随机森林的并行构建不同,这些树是串行构建的,每棵树都试图纠正前面所有树的残差。
训练过程(fit 到底在做什么?)
假设我们有训练数据 ,LightGBM 的
fit 过程大致如下:
-
初始化:建立一个初始的弱学习器(通常是一个常数,即所有样本的初始预测值,比如对数几率)。
-
迭代训练 (
n_estimators轮):-
计算当前模型对每个样本的负梯度(即残差方向,对于分类任务是对数损失函数的负梯度)。
-
用这些负梯度作为新的目标值,训练一棵新的决策树。
-
分裂节点时:
-
使用直方图算法找到最优分裂点。
-
可能采用 GOSS 采样(只使用部分样本)。
-
可能采用 EFB 处理稀疏特征。
-
-
新树的目标是拟合当前模型的残差。
-
将新树的预测结果乘以学习率 (
learning_rate),加到原有模型上。
-
-
最终输出:所有树的预测结果累加,得到最终模型。
fit 方法不仅做这些,还会:
- 如果提供了
eval_set,会在每轮迭代后计算验证集上的指标(如logloss或auc),用于监控或早停。
- 如果设置了
early_stopping_rounds,当验证集指标连续多轮不再提升时,训练提前终止,并恢复到最佳模型。
训练完之后,模型会把学到的知识存哪几个变量里,有哪些重要的模型属性需要我们知道?
以下是开发者最需要关注的几个核心属性:
1. 核心产出(模型知识)
booster_: 这是最核心的变量,存储了底层的Booster对象(C++ 实现)。所有的树结构、分裂阈值、增益值都封装在这里。feature_importances_: 模型学到的"特征重要性"。默认是特征在所有树中被用来分裂的次数 (split),也可以设置为特征带来的总增益 (gain)。best_iteration_: 如果你使用了early_stopping,这个属性会记录模型表现最好(验证集误差最小)的那一轮迭代次数。后续predict默认会使用这个最优状态。best_score_: 存储验证集在最优迭代时的具体评估指标值(如auc或logloss)。2. 结构与特征信息
feature_name_: 训练时输入的特征名称。如果输入是 DataFrame,它会自动记录列名。这对于模型部署时检查特征顺序是否一致非常重要。n_features_: 模型训练时使用的特征总数。objective_: 确认模型最终使用的损失函数(如binary,multiclass或regression)。3. 如何查看"具体的知识"?
如果你想"透视"模型具体是怎么分类的,可以使用以下方法提取隐藏在变量里的信息:
to_json()/dump_model():
通过model.booster_.dump_model(),你可以得到一个包含所有树结构的巨大字典。里面详细记录了每一棵树的每个节点:在哪根特征分裂 、分裂点(threshold)是多少 、左/右子树是什么。trees_to_dataframe():
将所有树的结构转换为一个 Pandas DataFrame,方便你搜索特定特征在哪些层级起到了关键作用。
三、lightgbm.LGBMClassifier 常用参数详解
根据你的代码和官方文档,我将常用参数分类说明:
1. 核心参数
| 参数 | 含义与作用 | 你的代码 |
|---|---|---|
n_estimators |
提升迭代轮数,即构建的决策树数量。越多模型越复杂,但可能过拟合 | n_estimators=100 |
learning_rate |
学习率,控制每棵树对最终结果的贡献权重。较小的学习率需要更多的树来达到相同效果,但泛化能力更好 | learning_rate=0.1 |
max_depth |
树的最大深度。默认 -1 表示不限制。Leaf-wise 生长下,深度可能不如 num_leaves 有效,但仍可用于限制复杂度 |
max_depth=6 |
num_leaves |
每棵树的最大叶子节点数 ,是控制模型复杂度的关键参数。默认 31。通常 num_leaves 应小于 |
(未设置,默认 31) |
n_jobs |
并行线程数,-1 表示使用所有 CPU 核心 |
n_jobs=-1 |
random_state |
随机种子,确保结果可复现 | random_state=42 |
verbose / silent |
控制日志输出级别。verbose=-1 或 silent=True 可关闭大部分输出 |
verbose=-1 |
2. 模型复杂度控制(防止过拟合)

3. 训练行为参数

4. fit 方法中的常用参数
5. 训练后属性
训练完成后,模型会提供以下常用属性:
feature_importances_:特征重要性数组(基于importance_type的设置)。
-
evals_result_:如果传入了eval_set,这里会保存训练过程中每轮的指标变化。 -
best_iteration_:如果启用了早停,这里保存最佳迭代轮数。 -
best_score_:最佳迭代轮数时的验证集分数。
四、结合你的代码进行分析
在你的 LightGBMClassifier_ 类中:
-
你设置了
n_estimators=100,max_depth=6,learning_rate=0.1,n_jobs=-1,verbose=-1。 -
fit方法支持传入eval_set,但没有设置早停 和自定义eval_metric,因此会训练满 100 轮,并使用默认的logloss作为验证集指标。 -
get_feature_importance返回的是默认的split重要性(特征被使用的次数)。
可以优化的地方
-
启用早停 :在
fit方法中增加early_stopping_rounds参数,并传递给底层模型,防止过拟合。 -
支持自定义
eval_metric:允许用户传入想要的验证指标(如'auc')。 -
保存训练历史 :训练后可以将
self.model.evals_result_保存为属性,方便绘图分析。 -
暴露更多超参数 :如
num_leaves、min_child_samples、subsample、reg_alpha等,让用户可以根据数据规模调整。 -
支持
importance_type选择 :在get_feature_importance中增加参数,允许用户选择'split'或'gain'。
五、总结
-
LGBMClassifier是一个高效的梯度提升分类器,通过直方图算法、GOSS、EFB 和 leaf-wise 生长策略,实现了快速训练和低内存占用。 -
fit过程是串行构建决策树,每棵树拟合当前模型的负梯度,逐步减少损失。 -
常用参数 包括控制迭代轮数的
n_estimators、控制学习速率的learning_rate、控制树复杂度的max_depth/num_leaves,以及防止过拟合的min_child_samples、subsample、reg_alpha等。 -
理解这些参数,能让你更好地调优 LightGBM 模型,充分发挥其性能。
14.torch.utils.data.TensorDataset()
**TensorDataset**是PyTorch提供的一个便捷的数据集类,用于将多个张量(tensors)包装成一个数据集。它要求所有张量的第一个维度(样本数量维度)大小相同。
经过TensorDataset(X_train_t, y_train_t)的包装之后,就变成了如下图:
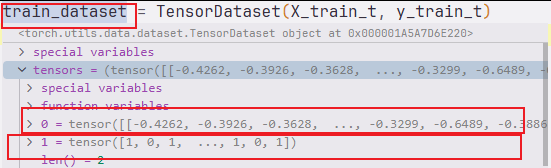
之前我们使用的都是Dataset,通过自定义一个MyDataset类(必须继承 DataSet ),并重写__init__、getitem、__len__三个方法,从而实现数据集的封装。
TensorDataset VS Dataset的区别?
torch.utils.data.TensorDataset 是PyTorch提供的一个便捷的数据集类,用于将多个张量(tensors)包装成一个数据集。它要求所有张量的第一个维度(样本数量维度)大小相同。
参数:
- *tensors (Tensor): 可以传入多个张量,这些张量第一个维度必须大小相同。(通常用于包装特征张量(X)和标签张量(y))
返回值:
- 返回一个TensorDataset对象,可以通过索引访问,返回对应位置的各个张量的元素组成的元组。
与torch.utils.data.Dataset的区别:
torch.utils.data.Dataset是一个抽象类 ,用户需要继承这个类并实现__getitem__和__len__方法来创建自定义数据集。
TensorDataset是Dataset的一个子类,它已经实现了这些方法,适用于多个张量的简单情况。它提供了一种快速创建数据集的方式,而不需要自己编写Dataset类。
使用方式:
首先导入所需的库:torch 和 torch.utils.data.TensorDataset。
准备数据张量,确保每个张量的第一个维度相同。
使用这些张量创建TensorDataset实例。
可以将这个TensorDataset实例传递给DataLoader,以便进行批处理、打乱数据等操作。
# 1.简单情况 - 直接使用TensorDataset
X = torch.tensor([[1, 2], [3, 4], [5, 6]], dtype=torch.float32) y = torch.tensor([0, 1, 0]) dataset = TensorDataset(X, y)# 2.自定义Dataset:
from torch.utils.data import Dataset class MyDataset(Dataset): def __init__(self, X, y): self.X = X self.y = y def __len__(self): return len(self.X) def __getitem__(self, idx): return self.X[idx], self.y[idx] # 使用自定义Dataset dataset = MyDataset(X, y)
TensorDataset:适合数据已经是张量形式的简单场景,使用方便
自定义Dataset:适合需要复杂数据处理、数据增强或非张量数据的场景

torch.utils.data.TensorDataset 是 PyTorch 中用于将多个张量包装成一个数据集的工具类。它的主要作用是方便地将特征和标签等数据组合在一起,供 DataLoader 使用,从而简化数据加载过程。
一、TensorDataset 的作用
-
组合张量:将多个形状相同(至少在第一个维度上)的张量组合成一个数据集。每个样本是这些张量在相同索引处的元素组成的元组。
-
与
DataLoader配合 :包装后的数据集可以直接传给DataLoader,实现批量读取、打乱、多线程加载等操作。 -
简化代码 :当数据已经以张量形式存在时,无需自定义
Dataset类,直接使用TensorDataset即可快速创建数据集。
二、参数
TensorDataset 的构造函数接收可变数量的张量作为参数:
TensorDataset(*tensors)*tensors:一个或多个张量(torch.Tensor)。所有张量在第一个维度(通常是样本维度)上的长度必须相同。每个张量可以有不同的形状(例如特征可以是二维,标签可以是一维),但样本数必须一致。
三、返回值
返回一个 Dataset 对象(具体是 TensorDataset 实例),该对象支持索引操作和 len() 函数。
-
通过索引
dataset[i]可以获取第i个样本,返回一个元组,元组中的每个元素对应传入张量的第i个元素。 -
len(dataset)返回数据集的样本数量(即张量第一个维度的大小)。
四、基本用法示例
import torch
from torch.utils.data import TensorDataset, DataLoader
# 创建示例数据:100个样本,每个样本5个特征
features = torch.randn(100, 5) # 特征张量
labels = torch.randint(0, 2, (100,)) # 标签张量(二分类)
# 包装成数据集
dataset = TensorDataset(features, labels)
# 查看数据集大小
print(len(dataset)) # 输出: 100
# 获取第一个样本
sample = dataset[0]
print(sample) # 输出: (tensor([...]), tensor(...))
# 使用 DataLoader 批量加载
dataloader = DataLoader(dataset, batch_size=16, shuffle=True)
for batch_x, batch_y in dataloader:
print(batch_x.shape, batch_y.shape) # torch.Size([16, 5]) torch.Size([16])五、注意事项
-
维度匹配 :所有张量的第一个维度长度必须相等,否则会抛出
ValueError。 -
数据类型 :张量的数据类型可以不同(例如特征用
float32,标签用long),但通常要符合模型要求。 -
内存占用 :
TensorDataset直接存储原始张量,不会复制数据,因此内存效率较高。 -
适用于小数据集 :对于非常大的数据集(如图像),通常使用自定义
Dataset从磁盘动态加载,以避免内存不足。TensorDataset更适合数据已全部加载到内存的场景。
六、与 DataLoader 结合的优势
-
自动批处理 :通过
DataLoader的batch_size参数自动划分批次。 -
打乱数据 :设置
shuffle=True可在每个 epoch 前打乱数据顺序,有助于训练。 -
多进程加载 :通过
num_workers参数启用多进程加速数据加载(但注意在 Windows 环境下可能需要特殊处理)。
总之,TensorDataset 是 PyTorch 中一个简单实用的工具,尤其适合快速搭建实验流程。
15.梯度爆炸 & 梯度裁剪?
一、什么是梯度爆炸?
在神经网络训练中,我们通过反向传播计算损失函数对每个参数的梯度,然后用梯度更新参数(比如通过 SGD 或 Adam)。梯度的值决定了参数更新的方向和步长。
梯度爆炸指的是:在反向传播过程中,梯度变得非常大(比如数值超过 1e8 甚至变成无穷大)。这会导致参数更新一步"跳"得太远,使得损失突然变成 NaN(无穷大),模型再也无法恢复。
为什么会发生梯度爆炸?
-
网络过深:梯度在多层之间连乘,如果每一层的梯度都大于 1,那么从输出层到输入层的梯度会指数级增长。
-
初始化不当:如果权重初始化太大,前向传播的输出容易饱和,反向传播的梯度也大。
-
学习率太大:即使梯度正常,学习率过大也会让参数"跃过"最优区域,导致后续梯度异常。
-
损失函数陡峭:某些损失曲面局部非常陡峭,梯度自然很大。
梯度爆炸的后果
-
参数更新后,loss 突然变成 NaN。
-
模型无法收敛,训练失败。
-
即使没到 NaN,也会导致训练极其不稳定,震荡严重。
二、梯度裁剪是什么?如何裁剪?
梯度裁剪就是在梯度更新之前,对梯度的大小进行限制,防止它超过某个阈值。
常见方法:
-
按范数裁剪(norm clipping) :计算所有参数的梯度向量的 L2 范数,如果范数超过阈值
max_norm,则等比例缩放所有梯度,使范数等于max_norm。 -
按值裁剪(value clipping) :将每个梯度单独限制在一个区间内,比如
[-1, 1],但这种方法会改变梯度方向,一般较少用。
你的代码中使用的就是按范数裁剪:
torch.nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=1.0)-
model.parameters()返回模型中所有需要梯度的参数。 -
clip_grad_norm_会计算这些参数梯度的总体 L2 范数(将所有梯度展平后求平方和再开方)。 -
如果该范数 > 1.0,则每个梯度都乘以
1.0 / 当前范数,使总范数变为 1.0。 -
如果范数本来就 ≤ 1.0,则不做任何操作。
例如,假设当前梯度的 L2 范数是 5.0,裁剪后所有梯度都会除以 5,使范数变成 1.0。这样就保证了更新步长不会过大。
三、为什么要进行梯度裁剪?
- 防止梯度爆炸
直接切断梯度爆炸的后果,使训练能继续进行。
- 允许使用更大的学习率
如果不裁剪,学习率稍大就可能炸掉;有了裁剪,可以放心使用稍大的学习率,加速收敛。
- 提高训练稳定性
尤其在循环神经网络(RNN、LSTM)中,时间步数多时梯度非常容易爆炸。梯度裁剪几乎是 RNN 训练的标配。
- 保护优化器状态
像 Adam 这类自适应优化器,如果遇到异常大的梯度,它的动量状态也会被污染,导致后续训练效果变差。裁剪可以避免这种污染。
四、裁剪发生在哪一步?
在标准训练循环中,梯度计算的顺序是:
-
optimizer.zero_grad()# 清空梯度 -
outputs = model(X_batch)# 前向传播 -
loss = criterion(outputs, y_batch) -
loss.backward()# 反向传播,计算梯度 -
梯度裁剪(可选) # 现在梯度已算好,还未更新参数
-
optimizer.step()# 用裁剪后的梯度更新参数
因此,梯度裁剪放在 backward() 之后、step() 之前,确保更新时使用的是被限制过的梯度。
五、总结
-
梯度爆炸是梯度值过大导致训练崩溃的现象。
-
梯度裁剪通过限制梯度的范数或值域来防止爆炸。
-
你代码中的
clip_grad_norm_是 PyTorch 提供的实用函数,能有效稳定训练,让模型更容易收敛。 -
虽然你的数据集已经表现很好,但加入梯度裁剪是一种稳健的做法,特别是在处理更深网络或更复杂数据时非常必要。
16.保存最佳模型的两种方式对比
在之前本人的另一篇博客:https://mp.csdn.net/mp_blog/creation/editor/158431130
的附录11,我学会了PyTorch 中模型保存的常见方式:
1. 仅保存状态字典(推荐)
torch.save(model.state_dict(), 'model.pth')2. 保存整个模型
torch.save(model, 'model.pth')3. 保存检查点(Checkpoint)用于恢复训练
checkpoint = {
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
...
}
torch.save(checkpoint, 'checkpoint.pth')但是在**0.DeepLearningTrainer 类这个章节的(4)fit 方法中,**也是仅保存状态字典,代码写法却是:self.best_model_state = {k: v.cpu().clone() for k, v in self.model.state_dict().items()}
一、两种保存方式的区别
1. torch.save(model.state_dict(), model_save_path)
-
作用 :将模型的状态字典(
state_dict)保存到磁盘文件 (通常以.pth或.pt结尾)。 -
用途:持久化存储模型,便于以后重新加载(如部署、继续训练、分享等)。
-
特点:
-
只保存参数,不保存模型结构,加载时需要先实例化模型再调用
load_state_dict。 -
文件可以永久保存,不占用内存。
-
2. self.best_model_state = {k: v.cpu().clone() for k, v in self.model.state_dict().items()}
-
作用 :将模型当前的最佳状态字典深拷贝到内存变量
self.best_model_state中,并强制将每个参数张量转移到 CPU 上。 -
用途:在训练过程中,用于早停(Early Stopping)时恢复最佳模型权重。避免因后续训练继续更新参数而丢失最佳状态。
-
特点:
-
内存中保存,不写入磁盘。
-
对每个参数张量进行了
cpu().clone(),确保独立副本,与模型当前的参数解耦。
-
二、拆解字典推导式
self.best_model_state = {k: v.cpu().clone() for k, v in self.model.state_dict().items()}1. self.model.state_dict()
-
返回一个
OrderedDict,键是模型参数的名字(如'network.0.weight'、'network.0.bias'),值是对应的参数张量(torch.Tensor)。 -
这些张量默认在模型所在的设备(GPU 或 CPU)。
2. .items()
- 返回字典的键值对迭代器,每次迭代返回一个
(key, value)元组。
3. for k, v in ...
-
依次取出每个键(参数名)和值(参数张量)。
-
这里
k是字符串,v是张量。
4. v.cpu().clone()
-
v.cpu():将张量v从当前设备(如 GPU)转移到 CPU 内存。 -
.clone():创建张量的深拷贝,在内存中开辟新空间,复制所有数据。 -
这一步保证了
self.best_model_state中的张量是独立的副本,且位于 CPU 上,不会因为后续模型训练(在 GPU 上)而改变。
5. 外层字典 {k: ... for k, v in ...}
- 用推导式构建一个新字典,键保持原参数名,值变为经过
cpu().clone()处理后的张量。
为什么不能直接赋值 self.best_model_state = self.model.state_dict()?
-
直接赋值只是引用,
self.model.state_dict()中的张量与模型参数共享内存,后续训练会修改它们,导致保存的"最佳状态"被覆盖。 -
即使使用
.copy()方法(浅拷贝),也只会复制字典结构,内部的张量依然是引用,同样会被修改。 -
必须通过
clone()创建独立的张量副本。
为什么需要 .cpu()?
- 如果不转移到 CPU,张量仍留在 GPU 显存中。当模型在 GPU 上继续训练时,显存可能被占用;而且早期保存的张量可能与后续计算冲突。转移到 CPU 可释放显存,并确保即使模型切换设备也能正确加载(加载时再移回 GPU)。
三、关于 load_state_dict 的设备匹配问题(重要 Bug 检查) 本人已修正
在 fit 方法的早停恢复部分,代码是:
if self.best_model_state is not None:
self.model.load_state_dict(self.best_model_state)
logger.info("已恢复最佳模型权重")这里有一个潜在的设备不匹配问题:
-
模型
self.model可能在 GPU 上(如果device='cuda')。 -
而
self.best_model_state中的张量被强制转移到了 CPU (通过.cpu())。 -
load_state_dict要求传入的 state_dict 中的张量与模型参数所在设备一致,否则会报错。
解决方案
在加载前,将 self.best_model_state 中的张量移回模型所在设备:
# 恢复最佳模型前,将 state_dict 移到当前设备
if self.best_model_state is not None:
device_state = {k: v.to(self.device) for k, v in self.best_model_state.items()}
self.model.load_state_dict(device_state)
logger.info("已恢复最佳模型权重")四、两种写法的总结对比
| 方面 | torch.save 保存到磁盘 |
{k: v.cpu().clone() ...} 保存到内存 |
|---|---|---|
| 存储位置 | 磁盘文件 | 内存变量 |
| 作用 | 持久化保存模型 | 训练过程中临时保存最佳状态 |
| 是否深拷贝 | 是(写入文件即深拷贝) | 是(显式 clone) |
| 设备 | 默认保持原设备(可指定 CPU) | 强制转移到 CPU |
| 加载方式 | model.load_state_dict(torch.load(path)) |
model.load_state_dict(best_state)(需先处理设备) |
| 适用场景 | 部署、断点续训、模型分享 | 早停、模型选择 |
五、进一步理解 state_dict
-
state_dict是 PyTorch 中存储模型参数(及优化器状态)的标准字典。 -
它只包含可训练参数(
nn.Parameter)和注册的缓冲区(如 BatchNorm 的 running mean),不包含模型结构。 -
因此保存
state_dict是轻量且推荐的模型保存方式。
在你的代码中,self.best_model_state 保存的是最佳 epoch 的模型参数副本,之后早停时恢复,确保最终使用的是验证损失最低的模型。
六、最终建议
-
在早停恢复时,记得将 CPU 上的 state_dict 移回模型所在设备。
-
如果模型较大,将 state_dict 复制到 CPU 会占用额外内存,但通常是可接受的。
-
如果想在训练结束后保存最终的最佳模型,可以调用
torch.save(self.best_model_state, 'best_model.pth'),将内存中的最佳状态保存到磁盘。
通过理解这两种保存方式的区别,你可以更灵活地管理模型状态,避免因设备不匹配或引用问题导致的错误。
17.多层感知机MLP
MLP(Multi-Layer Perceptron,多层感知机)是一种前馈人工神经网络,它通过多个全连接层(线性层)和非线性激活函数来学习输入特征与输出标签之间的复杂映射关系。它是最基础的深度学习模型之一,也是理解神经网络原理的起点。
一、MLP 是什么?它在做什么?
MLP 的核心任务 :根据输入特征 预测输出
(分类或回归)。对于二分类问题,输出是一个概率值(或 logit),通过阈值或 Softmax 得到最终类别。
工作流程(以前向传播为例):
-
输入层:接收特征向量
-
隐藏层:一个或多个全连接层,每个神经元对输入进行线性组合
-
输出层:最后一层通常是线性层(对于分类,输出维度为类别数),其输出被称为 logits(未归一化的分数)。之后,结合损失函数(如交叉熵)内部进行 Softmax 转换为概率,并与真实标签计算损失。
训练目标:通过反向传播算法不断调整网络的权重和偏置,使得损失函数最小化,从而使模型在训练数据上预测更准确,并期望泛化到新数据。
二、MLP 的常用参数(以你定义的 PyTorch 类为例)
在你的 MLPClassifier 类中,主要参数如下:
| 参数 | 含义与作用 |
|---|---|
input_dim |
输入特征的维度,即每个样本的特征数。默认 256。 |
hidden_dims |
一个列表,指定每个隐藏层的神经元数量。例如 [512, 256, 128] 表示三个隐藏层,分别有 512、256、128 个神经元。如果为 None,则使用默认值。 |
dropout |
Dropout 概率,范围 0~1。在训练时,每个隐藏层后的 Dropout 会以概率 dropout 随机将部分神经元输出置零,从而防止过拟合。测试时自动禁用。 |
除了这些,一个完整的 MLP 通常还涉及:
-
激活函数:ReLU、Sigmoid、Tanh 等。你使用了 ReLU,它是最常用的选择。
-
输出层激活:对于二分类,常用 Softmax(配合 CrossEntropyLoss)或 Sigmoid(配合 BCEWithLogitsLoss)。你的代码输出层是线性层,没有激活,这是正确的,因为损失函数内部会处理。
-
权重初始化:PyTorch 的线性层默认使用 Kaiming 均匀初始化,适合 ReLU。
-
优化器 :外部通过
DeepLearningTrainer传入 Adam,学习率、权重衰减等也在那里配置。
在 scikit-learn 的 MLPClassifier 中,常用参数包括:
-
hidden_layer_sizes:元组,如(100, 50)表示两个隐藏层。 -
activation:激活函数,如'relu'、'logistic'。 -
solver:优化器,如'adam'、'sgd'。 -
alpha:L2 正则化系数。 -
learning_rate:学习率。 -
batch_size:批大小。 -
max_iter:最大迭代次数。
三、MLP 模型的内部结构
MLP 的内部结构由以下几部分构成:
-
输入层:神经元个数等于特征维度,每个神经元对应一个特征。输入层不参与运算,只是数据的入口。
-
隐藏层:
-
每个隐藏层由多个神经元组成,每个神经元与前一层的所有神经元全连接(即全连接层 或线性层)。
-
每个线性层后紧跟一个激活函数,引入非线性。没有激活函数的线性层堆叠仍是线性的,无法逼近复杂函数。
-
可选地,可以在激活函数后添加 Dropout 或 BatchNorm 等正则化技术。
-
-
输出层:
- 对于二分类,输出层有 2 个神经元(或 1 个神经元配合 sigmoid),输出 logits。通过 Softmax 转为概率后,选择概率高的类别作为预测结果。
数学形式(以一层为例):
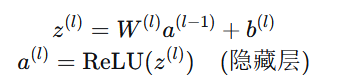
其中 是前一层的输出,
是权重矩阵,
是偏置向量。
四、fit 过程到底在做什么?
fit 方法(对应 DeepLearningTrainer.fit)执行的是神经网络的训练过程,通常包含以下步骤:
-
初始化:将模型参数(权重和偏置)随机初始化。
-
迭代训练(多个 epoch):
-
对于每个 epoch:
-
将训练数据分成小批量(batch)。
-
对于每个 batch:
-
前向传播:输入 batch 数据,通过网络得到预测输出(logits)。
-
计算损失:用损失函数(如交叉熵)比较预测与真实标签。
-
反向传播:计算损失对每个参数的梯度。
-
梯度裁剪(可选):限制梯度范数,防止爆炸。
-
优化器更新:根据梯度更新参数(如 Adam 的动量、学习率等)。
-
-
完成一个 epoch 后,在验证集上评估模型(前向传播,计算损失和准确率)。
-
记录训练损失、验证损失、验证准确率。
-
早停检查 :如果验证损失连续
patience轮未下降,则停止训练,并恢复验证损失最低时的模型参数。
-
-
-
返回训练历史:包含每轮的损失和准确率,便于后续分析。
核心优化原理:通过梯度下降法最小化损失函数,使得模型在训练数据上的预测误差逐渐减小。反向传播利用链式法则高效计算梯度,优化器则根据梯度调整参数。
五、补充:MLP 的优缺点
| 优点 | 缺点 |
|---|---|
| 可以逼近任意连续函数(通用近似定理)。 | 对高维数据容易过拟合,需要大量数据和正则化。 |
| 结构简单,易于理解和实现。 | 无法捕捉输入中的局部结构(如图像中的空间关系)。 |
| 适合处理固定长度的向量输入。 | 训练可能较慢,且超参数敏感。 |
六、总结
-
MLPClassifier 是一个全连接神经网络,通过多个线性层 + 非线性激活函数来学习输入到输出的映射。
-
其核心参数包括输入维度、隐藏层结构、Dropout 概率、激活函数类型等。
-
内部结构由输入层、若干隐藏层、输出层构成,每层通过权重矩阵和偏置实现线性变换,再经激活函数引入非线性。
-
fit过程通过前向传播、计算损失、反向传播、优化器更新参数,并利用早停和验证集监控防止过拟合,最终得到一个能较好泛化的模型。
MLPClassifier 训练完之后,模型会把学到的知识存哪几个变量里,有哪些重要的模型属性和方法需要我们知道?
在 PyTorch 中,理解模型训练后把"知识"存在了哪里,是进阶模型部署、调试和微调的第一步。对于你写的这个
MLPClassifier,模型学到的"知识"(即权重 Weights 和 偏置 Biases )实际上保存在self.network这个容器里的各个nn.Linear(全连接层)中。像nn.ReLU和nn.Dropout只是操作逻辑,它们本身不包含任何可以通过训练改变的参数。
一、 知识究竟存在了哪里?
在你的代码中,所有的层被打包进了
self.network = nn.Sequential(*layers)。模型训练完成后,知识就存在里面的Linear层中。你可以通过以下几种方式来查看或提取这些知识:
1.
state_dict()(最常用的"知识库")这是 PyTorch 中最推荐的访问模型参数的方式。它会返回一个 Python 字典,将每一层的名字映射到它的参数张量(Tensor)上。
用途: 保存模型、加载模型、或者查看具体的参数数值。
示例代码:
model = MLPClassifier() # 打印模型里都存了哪些"知识"变量 print(model.state_dict().keys()) # 输出类似于: odict_keys(['network.0.weight', 'network.0.bias', 'network.3.weight', ...])2.
parameters()和named_parameters()这是一个迭代器,包含模型中所有需要被梯度更新的张量。
用途: 主要是交给优化器(Optimizer)去更新这些参数。
示例代码:
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)3. 直接访问具体层属性
如果你想单独拿出第一层的权重,你可以像操作列表一样剥开
self.network:
示例代码:
# 假设 network[0] 是你 append 的第一个 nn.Linear first_layer_weights = model.network[0].weight first_layer_biases = model.network[0].bias
二、 必须掌握的关键属性和方法
作为一个 PyTorch 开发者,除了你重写的
__init__和forward,这个模型继承自nn.Module,天生自带以下几个极为重要的方法:1. 状态切换方法 (极其重要,特别是因为你有 Dropout)
model.train()
作用: 将模型设置为训练模式 。此时,你的
nn.Dropout会随机丢弃神经元,以防止过拟合。时机: 每次开始训练的 epoch/batch 之前调用。
model.eval()
作用: 将模型设置为评估/推理模式 。此时,
nn.Dropout会失效(所有神经元都会参与计算),确保你对同一条数据的预测结果是确定且稳定的。时机: 在验证集测试、或者最终将模型部署去预测新数据之前,必须 调用它。忘记调用
eval()是新手最容易犯的错误,会导致预测结果不准且每次都变化。2. 核心计算方法
model(x)
- 作用: 这是调用模型推理的正确姿势。虽然你在代码里定义了
forward(x),但在实际使用时,千万不要直接写model.forward(x)。直接使用model(x),PyTorch 在内部会自动调用forward,并帮你处理好诸如注册钩子(Hooks)等底层逻辑。3. 设备转移方法
model.to(device)
作用: 将模型的所有参数(知识)从 CPU 搬到 GPU 上(或者反过来)。
示例:
model.to(torch.device('cuda:0'))4. 梯度控制方法
model.zero_grad()
- 作用: 清空模型中所有参数的梯度。在每次反向传播计算新梯度之前调用(通常用
optimizer.zero_grad()替代,效果差不多)。
总结一下:
你定义的
MLPClassifier就像一个精密的黑盒,state_dict()是打开黑盒提取知识的钥匙,而train()和eval()则是控制这个黑盒工作状态的开关。你接下来是打算了解如何将这些学到的知识保存到本地硬盘(生成
.pth文件),还是想看看**如何冻结其中某几层的参数来进行微调(Fine-tuning)**呢?我可以为你提供相应的代码示例。
18.多头自注意力
自注意力机制详解:attn_out, _ = self.attention(lstm_out, lstm_out, lstm_out) 在做什么? 这行代码是多头自注意力(Multi-head Self-Attention) 的应用。让我们从基础开始,一步步理解它。
一、注意力机制的核心思想
注意力机制模仿人类认知:当处理大量信息时,我们会聚焦于关键部分 ,忽略次要细节。在深度学习中,它通过查询(Query) 、键(Key) 、值(Value) 三个向量实现:
-
查询(Q):代表"我关注什么"的请求。
-
键(K):代表"我有什么信息"的标签。
-
值(V):代表"实际信息内容"。
计算步骤:
-
计算每个查询与所有键的相似度(通常用点积)。
-
对相似度进行缩放和 Softmax,得到注意力权重。
-
用权重加权求和所有值,得到输出。
公式:
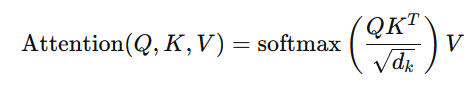
其中 是缩放因子,防止点积过大导致梯度消失。
二、什么是"自注意力"(Self-Attention)?
当 Q、K、V 都来自同一个输入序列 时,就称为自注意力 。它的作用是让序列中的每个元素根据其他元素的信息更新自己的表示,从而捕捉长距离依赖关系。
例如,在文本中,单词"它"可以通过自注意力找到它指代的名词;在序列特征中,某个时间步可以关注到其他时间步的重要模式。
在你的代码中:
attn_out, _ = self.attention(lstm_out, lstm_out, lstm_out)-
三个参数都是
lstm_out(形状为(batch, seq_len, hidden_dim*2)),即 LSTM 输出的序列。 -
这相当于让序列中的每个时间步查询其他所有时间步的键,并聚合它们的值,从而产生新的上下文增强表示。
三、多头注意力(Multi-Head Attention)
nn.MultiheadAttention 实现了多头机制:将 Q、K、V 分别投影到多个子空间,分别计算注意力,然后将结果拼接起来。这样做可以让模型从不同角度(不同表示子空间)关注信息,提高表达能力。
参数:
-
embed_dim:输入维度(即hidden_dim*2)。 -
num_heads=4:将embed_dim均分为 4 个头,每个头处理embed_dim/4维。 -
dropout:注意力权重的 dropout。 -
batch_first=True:输入形状为(batch, seq_len, embed_dim)。
输出 attn_out 与输入形状相同,_ 是注意力权重矩阵(通常不关心)。
四、为什么在这里使用自注意力?
在 BiLSTMClassifier 中:
-
输入特征被重塑为序列
(batch, seq_len, feature_per_step)。 -
经过双向 LSTM 后,输出
lstm_out已经包含了序列的上下文信息(前向+后向)。 -
再应用自注意力,让模型进一步学习序列中哪些时间步对最终分类更重要。例如,某些时间步可能携带更强的判别信息,自注意力会给予更高权重。
这种组合(LSTM + 自注意力)常用于序列分类,LSTM 捕捉局部时序,自注意力捕捉全局依赖。
五、代码中的后续处理
pooled = attn_out.mean(dim=1) # 全局平均池化
output = self.fc(pooled)-
将自注意力输出在序列维度上取平均,得到每个样本的固定长度向量。
-
通过全连接层映射到 2 个类别 logits。
六、注意力机制的优缺点
优点:
-
能够捕捉任意距离的依赖,不受序列长度限制。
-
计算可以高度并行化(相对于 RNN 的串行)。
-
多头机制增强了表示能力。
缺点:
-
计算复杂度与序列长度的平方成正比(
-
需要大量数据训练。
七、总结
-
代码中的
self.attention(lstm_out, lstm_out, lstm_out)是多头自注意力 ,作用是对 LSTM 输出的序列进行上下文增强,使每个时间步能够聚合其他时间步的信息。 -
它利用了注意力机制的核心思想(Q、K、V 同源),让模型自主决定哪些位置更重要。
-
最终输出经过池化和分类,完成对序列的分类任务。
通过理解这行代码,你已掌握了自注意力在序列建模中的基本应用,这是 Transformer、BERT 等现代模型的核心组件。
19.全局平均池化层
一、语法层面
pooled = attn_out.mean(dim=1)-
attn_out:是一个 PyTorch 张量(Tensor),形状为(batch_size, seq_len, hidden_dim*2)。在你的例子中,batch_size=16,seq_len=32,hidden_dim*2=256,所以形状是(16, 32, 256)。 -
.mean(dim=1):是 PyTorch 张量的mean方法,用于计算平均值。参数dim=1指定沿着第 1 个维度(索引从 0 开始)进行平均。 -
结果 :
pooled是一个新的张量,形状为(batch_size, hidden_dim*2),即(16, 256)。
二、什么是"全局平均池化"?
在深度学习中,全局平均池化 是一种将整个序列(或图像特征图)压缩成一个向量的操作。它通过对某个维度取平均 来实现。这里,dim=1 对应的是"序列长度"维度(seq_len),因此是对每个样本的所有时间步取平均。
数学公式
对于给定的样本 ,
attn_out[i, :, :] 是一个形状为 (seq_len, hidden_dim*2) 的矩阵。对该矩阵在 seq_len 维度上求平均:
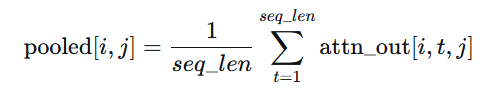
其中 遍历特征维度(
hidden_dim*2)。
直观理解
假设你有一个句子(32 个词),每个词用一个 256 维的向量表示。全局平均池化后,你得到整个句子的一个 256 维向量,它是所有词向量对应维度的平均值。这样,每个样本就被压缩成一个固定长度的向量,可以输入到后续的全连接层进行分类。
三、为什么叫"全局"?
"全局"意味着不考虑空间位置,对整个序列或整个特征图进行聚合。相对地,局部池化(如 MaxPool2d)是在局部窗口内池化,保留空间结构。而全局池化直接将整个区域压缩成一个值。
四、代码中为什么用平均池化?
-
简单有效:平均池化计算简单,能够保留序列的整体信息。
-
避免参数:相比注意力池化或 RNN 的最后一步输出,平均池化不需要额外参数。
-
正则化效果:平均池化相当于对所有时间步一视同仁,可以防止模型过分依赖某些特定位置,减轻过拟合。
五、维度变化图示
attn_out 形状: (16, 32, 256)
│
│ mean(dim=1)
▼
pooled 形状: (16, 256)
每个样本从 32×256 的矩阵变为 256 维的向量,即用 32 个时间步的均值来表示该样本。
六、其他池化方式
全局平均池化是其中一种,还可以使用:
-
全局最大池化 :
pooled = attn_out.max(dim=1)[0] -
注意力池化:通过学习权重对时间步加权平均。
七、总结
这行代码实现了全局平均池化 ,将 attn_out 中每个样本的序列维度(seq_len)通过平均压缩为一个向量,为后续分类层提供固定长度的特征表示。它是序列分类模型中常见的过渡操作,简单且有效。
全局平均池化:从二维到一维的例子
为了让你直观理解"对 dim=1 取平均"的含义,我们用一个简单的数值例子演示。
场景设定
假设我们有一个序列,包含 3 个时间步 (seq_len=3),每个时间步的特征维度是 2 (hidden_dim*2=2)。也就是说,attn_out 的形状是 (3, 2)------这里暂时忽略批量维度,先看单个样本。
张量内容(手动设定):
attn_out = [
1.0, 2.0, # 时间步 1
3.0, 4.0, # 时间步 2
5.0, 6.0 # 时间步 3
]
操作
pooled = attn_out.mean(dim=0) # 这里 dim=0 对应时间步维度(因为形状是 (3,2))
注意:在完整模型中,输入形状是 (batch, seq_len, features),我们取 dim=1。此处为了简化,我们将 attn_out 视为 (seq_len, features),所以取 dim=0。
计算过程
对时间步维度(索引 0)取平均:
-
对于第一个特征维度(列 0):
(1.0 + 3.0 + 5.0) / 3 = 9.0 / 3 = 3.0 -
对于第二个特征维度(列 1):
(2.0 + 4.0 + 6.0) / 3 = 12.0 / 3 = 4.0
得到结果:
pooled = 3.0, 4.0
可视化
时间步 → 特征1 特征2
1 1.0 2.0
2 3.0 4.0
3 5.0 6.0
↓ 沿时间步平均 ↓
结果: 3.0 4.0
扩展到批量
如果有一个批量大小为 2 的数据(batch_size=2),则 attn_out 形状为 (2, 3, 2)。执行 pooled = attn_out.mean(dim=1) 后,每个样本独立平均,结果形状为 (2, 2),其中每行是对应样本的全局平均向量。
为什么叫"全局"?
因为操作覆盖了整个序列长度,没有局部窗口,所以是"全局"池化。
通过这个例子,你应该能清楚地看到:全局平均池化将每个样本在序列维度上的所有值进行平均,压缩成固定长度的向量,保留了每个特征维度上的整体信息,丢弃了时间顺序的具体位置信息。
20.TransformerClassifier的3个疑问
1. 为什么需要线性投影到 d_model 维?为什么不直接把 d_model 改成 8?
你的理解没错:理论上可以直接将每个时间步的特征维度 feature_per_step(例如 8)作为 d_model,这样就不需要额外的线性投影层。但在实际设计中,使用投影层有以下好处:
-
灵活性 :
d_model可以独立于输入特征维度选择。Transformer 内部的计算复杂度与d_model有关,较大的d_model能提供更强的表示能力。如果你想让模型容量更大,可以通过投影层将低维输入(如 8 维)映射到高维(如 128 维),从而利用 Transformer 的强大表达能力。 -
与位置编码维度匹配 :位置编码通常也使用
d_model维,若d_model很小,位置编码的区分度也弱。 -
模块化:将特征维度与 Transformer 内部维度解耦,方便调整模型大小。
如果你确信 8 维足够,确实可以直接将 d_model 设为 8,省略线性投影。但此时 Transformer 的每一层都在 8 维空间中运算,表达能力有限。通常建议 d_model 至少在 64~512 之间,因此保留投影层是更常见的设计。
2. 为什么必须添加位置编码?如何添加?
Transformer 本身是置换不变的 ,意味着如果不加位置信息,模型无法区分 (x1, x2, x3) 和 (x3, x2, x1),会把序列当作无序集合处理。这对于时间序列、文本等顺序重要的任务是不可接受的。
在你的代码中,将 256 维特征分割成 32 个时间步,每个时间步的 8 维特征来源于原始特征向量的连续段。这些段之间可能存在顺序依赖(例如特征按某种语义排列),因此需要位置编码来告诉模型每个时间步在序列中的位置。
如何添加位置编码?
有两种常用方式:
① 可学习的位置编码
在 __init__ 中定义一个 nn.Parameter:
self.pos_embedding = nn.Parameter(torch.randn(1, self.seq_len, d_model))在 forward 中,将嵌入后的输出加上位置编码:
x = self.embedding(x) # (batch, seq_len, d_model)
x = x + self.pos_embedding # 广播相加② 固定正弦位置编码 (Transformer 原论文方式)
可以预先计算一个固定的位置编码矩阵,不参与训练。实现可参考 torch.nn.Transformer 官方示例。
3. 为什么不直接输入 2D 特征,而要先分割成 3D 序列?
Transformer 的输入要求是 序列形式 :(batch, seq_len, d_model)。原始特征 (batch, input_dim) 是向量,不是序列。直接输入 Transformer 无法处理,因为:
-
nn.TransformerEncoder期望输入至少为 3 维,第 1 维是序列长度。 -
若强行将
(batch, input_dim)视为(batch, 1, input_dim),那么seq_len=1,自注意力会退化(每个位置只关注自己),相当于一个简单的 MLP 加上残差连接,失去了序列建模的意义。
为什么还要分割成序列?
这是一种特征工程 策略:假设原始 256 维特征向量可以按语义分组,每组(如 8 维)形成一个"时间步",组与组之间存在局部关联。这种分块方式将无序特征转化为有序序列,从而能够利用 Transformer 捕捉组间的交互关系。**如果特征本身没有这样的结构,强行分割反而可能破坏信息。**因此代码注释中已提醒"对于融合特征,建议优先使用 MLP 或 Transformer"(指直接使用 MLP 或把特征作为整体用 Transformer 的序列长度 1 的形式,但后者效果通常不如 MLP)。
替代方案:
-
保持
seq_len=1,将(batch, input_dim)视为单步序列,但此时自注意力无效,等同于 MLP(因为有embedding和fc)。实际可以简化为 MLP。 -
使用 Transformer 处理向量的一种方式是加一个可学习的
clstoken,把整个特征当作一个"词"的嵌入,但这样仍是单步序列,收益有限。
结论:分割成序列是为了利用 Transformer 捕捉特征内部的结构化依赖,但前提是特征本身具有序列结构。对于无结构融合特征,MLP 往往更合适。
21.Transformer 编码器
1. 什么是 Transformer 编码器?
Transformer 编码器是 Transformer 模型的核心组件之一,由多个相同的 编码器层 (TransformerEncoderLayer)堆叠而成。每一层都包含两个主要子层:
-
多头自注意力 (Multi-head Self-Attention) # 请见附录18的内容
-
前馈网络(Feed-Forward Network, FFN)
每个子层之后都接有 残差连接 (Residual Connection)和 层归一化(Layer Normalization)。
输入序列经过编码器后,每个位置都会获得一个融合了全局信息的向量,从而可以用于分类、生成等任务。
TransformerEncoder的内部结构如下:
(transformer): TransformerEncoder (
(layers): ModuleList((0-1): 2 x TransformerEncoderLayer( # 2层TransformerEncoder
#多头自注意力
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True)
)# 前馈神经网络
(linear1): Linear(in_features=128, out_features=512, bias=True)
(dropout): Dropout(p=0.3, inplace=False)
(linear2): Linear(in_features=512, out_features=128, bias=True)# 层归一化
(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)# Dropout
(dropout1): Dropout(p=0.3, inplace=False)
(dropout2): Dropout(p=0.3, inplace=False)
)
)
)
2. 内部结构:一个编码器层(TransformerEncoderLayer)
一个典型的编码器层结构(以你的代码为例)如下:
输入 x (shape: batch, seq_len, d_model=128)
│
▼
┌──────────────────────────────────────────────┐
│1. 多头自注意力(MultiheadAttention) │
│ - 计算 Q, K, V(都是 x) │
│ - 缩放点积注意力 → 注意力权重 → 加权求和 │
│ - 输出形状不变 (batch, seq_len, d_model) │
└──────────────────────────────────────────────┘
│
+─── 残差连接:x = x + attn_out
│
▼
┌──────────────────────────────────────────────┐
│ 2. 层归一化(LayerNorm) │
│ - 对每个样本、每个位置的特征维度归一化 │
└──────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────┐
│ 3. 前馈网络(FFN) │
│ - 两个线性层 + 激活函数(通常是 ReLU) │
│ - 隐藏维度一般为 d_model * 4(这里 512) │
└──────────────────────────────────────────────┘
│
+─── 残差连接:x = x + ffn_out
│
▼
┌──────────────────────────────────────────────┐
│4. 第二个层归一化(LayerNorm) │
│ - 输出形状 (batch, seq_len, d_model) │
└──────────────────────────────────────────────┘
│
▼
输出到下一层或最终输出
3. 特征经过编码器的过程到底在做什么?
假设你的输入是 (16, 32, 128),即 16 个样本,每个样本是一个长度为 32 的序列,每个位置是一个 128 维的向量(已加入位置编码)。经过编码器层,每个位置的向量会被更新:
-
自注意力:每个位置会"关注"序列中所有其他位置(包括自己),根据它们的重要性加权求和,从而把其他位置的信息融入到自己中。这相当于让每个时间步都能看到整个序列的上下文,捕捉长距离依赖。
-
前馈网络:对每个位置独立地进行非线性变换,增强表示能力(类似于 MLP)。
-
残差连接 + 层归一化:帮助梯度顺利传播,训练更稳定。
形象比喻 :
想象你有一组人(32 个位置),每个人(向量)一开始只知道自己的特征。在自注意力中,大家互相交流(交换信息),每个人获得一份"会议纪要"(融合了所有人观点的摘要)。然后每个人再根据自己的理解和这份纪要,独立思考(前馈网络),得到更成熟的见解。经过多层这样的循环,最终每个人都掌握了整个团队的信息。
4. 为什么需要多层?
一层自注意力已经能让每个位置看到全局信息,但多层能逐步抽象出更高级的特征。例如,第一层可能捕捉局部关系,第二层可以组合这些局部关系形成更全局的模式,类似于卷积网络的深层提取语义。
5. 你的代码中的细节
-
d_model=128,每个注意力头head_dim = 128 / 4 = 32。 -
前馈网络中间维度
dim_feedforward = d_model * 4 = 512。 -
两层编码器堆叠,输出形状仍是
(16, 32, 128)。 -
之后你使用 全局平均池化 将序列压缩为一个向量(16,128),再通过分类头输出 2 类 logits。
6. 为什么必须加位置编码?
因为自注意力是置换不变的,即如果打乱序列顺序,输出也会相应打乱,但每个位置的输出内容不变。这导致模型无法区分"第一个词"和"第二个词"。位置编码就是给每个位置注入一个独特的标识,让模型能够利用顺序信息。
你的实现中使用了可学习的位置编码,会在训练中自动调整,使模型能正确利用位置关系。
7. 总结
-
nn.TransformerEncoder是一个由多个相同编码器层堆叠而成的模块,每一层通过自注意力和前馈网络实现全局信息交互与非线性变换。 -
输入序列经过编码器后,每个位置的向量都融合了全序列的信息,并逐步抽象,最终可被用于分类等任务。
-
位置编码是必不可少的组件,用于引入序列顺序信息。
-
编码器的层数、注意力头数、隐藏维度等超参数可根据任务调整。
通过你的代码和上述解释,你应该能够理解 Transformer 编码器是如何处理序列数据,并为分类任务提取有效特征的。
TransformerClassifier训练完之后,模型会把学到的知识存哪几个变量里,有哪些重要的模型属性和方法需要我们知道?这是一个非常棒的进阶问题!相比于你之前的
MLPClassifier,这个TransformerClassifier结构要复杂得多。模型学到的"知识"分布得更加广泛,也包含了一些 PyTorch 中非常经典的高级参数定义方式。在这个模型中,学到的知识(也就是可以通过反向传播更新的参数)主要分布在四个核心区域。
一、 知识究竟存在了哪里?
和 MLP 一样,最全的知识库依然是
model.state_dict()。如果你打印它,会看到成百上千个键值对。具体来说,知识被分类存放在了以下几个你定义的组件中:1.
self.embedding(线性嵌入层)
存了什么: 这里存的是一个
nn.Linear层的weight和bias。知识的意义: 它学会了如何将你原始的一小段特征(
feature_per_step)投影到 Transformer 能够理解的高维空间(d_model)中。2.
self.pos_encoding(位置编码 ------ 重点注意!)
存了什么: 这是一个显式定义的
nn.Parameter。它没有藏在任何现成的网络层(比如 Linear)里,而是直接作为一个张量(Tensor)注册到了模型中。知识的意义: Transformer 本身没有序列的先后概念(它像一个词袋)。这个变量学会了为序列中的每一个位置(0 到 seq_len-1)加上一个特定的"位置指纹",让模型知道"谁在前面,谁在后面"。
3.
self.transformer(核心编码器矩阵)
存了什么: 这是整个模型最"庞大"的知识库。你定义了
num_layers=2,所以这里面有两层编码器。每层包含:
自注意力权重 (Self-Attention): 用于计算 Query、Key、Value 的投影矩阵(
in_proj_weight/in_proj_bias)以及输出投影矩阵。它们决定了模型在看序列某一部分时,应该"把注意力集中在其他哪些部分"。前馈网络权重 (Feedforward): 每层内部的两个线性层参数,用于进一步提取非线性特征。
LayerNorm 权重: Transformer 内部大量使用了层归一化(Layer Normalization),这里面包含了可学习的缩放参数
4.
self.fc(分类头)
存了什么: 也就是你定义的
nn.Sequential里面的两个nn.Linear层的权重和偏置。知识的意义: 它学会了如何把 Transformer 提取出的全局特征汇总,并最终投票决定输入属于哪个类别(2 分类)。
二、 必须掌握的核心属性与方法
除了你在 MLP 中已经接触过的基础方法外,针对这个 Transformer 模型,以下几点尤为重要:
1. 状态切换方法 (针对 LayerNorm 和 Dropout)
model.train()和model.eval()
- 在 Transformer 中,调用
eval()变得更加致命且重要 。因为你的模型不仅包含nn.Dropout,其内部的nn.TransformerEncoder还包含了大量的 Layer Normalization。如果不切换到eval()模式进行测试,LayerNorm 会继续使用当前 batch 的统计数据,导致你的预测结果极不稳定。2. 自定义的结构属性 (用于调试和校验)
你在
__init__中定义了几个非常好的实例属性,它们在后续处理数据时非常有用:
model.seq_len: 序列长度(例如 32)。
model.feature_per_step: 每个时间步的特征维度。
model.d_model: Transformer 内部的隐藏层维度。用途: 如果你在推理时发现张量形状报错,随时打印这些属性,核对你传入的
x.shape是否符合(batch_size, input_dim),以确保它能被正确reshape。3. 参数查看与冻结方法
因为 Transformer 参数量通常较大,有时候我们只想要微调(Fine-tune)分类头,而冻结前面的编码器。
查看某层参数:
model.pos_encoding或model.transformer.layers[0].self_attn.in_proj_weight冻结知识(示例代码):
# 冻结 transformer 编码器的所有知识 for param in model.transformer.parameters(): param.requires_grad = False # 此时如果交给优化器,只有 embedding, pos_encoding 和 fc 会被更新
对于这类序列模型,我们经常需要把它的内部"黑盒"打开,看看它到底在关注什么。
需要我为你演示如何修改这部分代码,把 Transformer 内部的"注意力权重矩阵 (Attention Weights)"提取出来,从而可视化模型做决定时"到底看了序列的哪一部分"吗?
22.多头自注力 + 前馈网络是啥?
一、多头自注意力(Multi-Head Self-Attention)
1. 自注意力(Self-Attention)的基本思想
自注意力的目标是:让序列中的每个位置都能根据所有位置的信息更新自己的表示 。它的核心是查询(Query)、键(Key)、值(Value) 机制。
假设输入序列 X 形状为 (batch, seq_len, d_model)。对于每个位置,我们生成三个向量:
-
查询 Q:代表"我关注什么"。
-
键 K:代表"我有什么信息可以让你关注"。
-
值 V:代表"我实际提供的信息内容"。
通过计算每个查询与所有键的相似度(通常用点积),得到注意力权重,然后用这些权重加权求和所有值,得到输出。
计算公式:
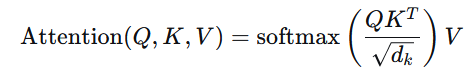
其中 是键的维度(通常等于
d_model / num_heads),缩放因子 防止点积过大导致梯度消失。
2. 为什么是"自"注意力?
因为 Q、K、V 都来自同一个输入 X。也就是说,每个位置都在关注序列中的其他位置(包括自己),从而捕捉全局依赖关系。
3. 多头(Multi-Head)的意义
单头注意力只能从一种角度学习关系。而多头 将 d_model 分成多个头(例如 4 个头,每个头维度 d_k = d_model / 4 = 32),每个头独立计算注意力,然后将所有头的输出拼接起来,再经过一个线性投影。
好处:
-
每个头可以关注不同的关系模式(例如有的头关注相邻位置,有的头关注远处位置)。
-
增加了模型的表达能力,且计算可并行。
在你的代码中:
self_attn = MultiheadAttention(embed_dim=128, num_heads=4, ...)- 输入
(16, 32, 128),经过多头注意力后输出仍是(16, 32, 128)。
二、前馈网络(Feed-Forward Network, FFN)
1. 结构
FFN 是一个简单的两层全连接网络,通常结构为:
Linear(d_model, d_ff) → ReLU → Linear(d_ff, d_model)中间维度 d_ff 通常设为 d_model * 4(你的代码中是 512)。
2. 作用
-
对每个位置独立地进行非线性变换(参数在不同位置共享)。
-
类似于对每个时间步应用一个 MLP,增强特征表示,引入非线性。
-
虽然自注意力已经融合了全局信息,但仍是线性组合,FFN 增加了模型的非线性能力,让网络能拟合更复杂的函数。
3. 为什么是"前馈"?
因为它在每个时间步独立运算,不涉及序列间的交互,只是对每个向量做映射。
三、它们在编码器层中如何协同工作?
一个完整的 TransformerEncoderLayer 包括:
输入 x (batch, seq_len, d_model)
│
├─> 多头自注意力 ──> + (残差) ──> 层归一化 ──> FFN ──> + (残差) ──> 层归一化 ──> 输出-
残差连接 :
x = x + attention_output,让梯度能直接流过,解决深层网络退化问题。 -
层归一化:对每个样本的每个位置的特征进行归一化,稳定训练。
整体作用:每个位置在自注意力中融合全序列信息,再通过 FFN 进行非线性变换,得到更丰富的表示。多层堆叠后,能逐步提取高层语义。
四、总结:它们到底做了什么?有什么用?
| 组件 | 做什么 | 有什么用 |
|---|---|---|
| 多头自注意力 | 每个位置关注所有位置,计算加权求和,融合全局上下文。 | 捕捉长距离依赖,让模型知道哪些位置重要。 |
| 前馈网络 | 对每个位置独立进行非线性变换(MLP)。 | 增强特征的非线性表达能力,增加模型容量。 |
在你的 TransformerClassifier 中,经过两层编码器后,每个时间步的向量都包含了全局信息,再通过全局平均池化得到整个序列的表示,最后分类。这样的设计让模型能够有效处理序列数据(即使是将特征强行分割成的"伪序列"),并利用位置编码学习顺序关系。
理解这两个核心组件,你就掌握了 Transformer 的精髓。
23.init()模型结构定义顺序 ≠ forword()网络执行顺序
残差块1的内部结构定义:
ResidualBlock1D(
(conv1): Conv1d(64, 64, kernel_size=(3,), stride=(1,), padding=(1,))
(bn1): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv1d(64, 64, kernel_size=(3,), stride=(1,), padding=(1,))
(bn2): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(dropout): Dropout(p=0.3, inplace=False)
(shortcut): Sequential()
)
forword()中的网络执行过程:
out = conv1(x)
out = bn1(out)
out = relu(out)
if dropout: out = dropout(out)
out = conv2(out)
out = bn2(out)
out = out + shortcut(identity) # 残差连接
out = relu(out)
完全正确!你的观察非常敏锐。在 PyTorch 中,网络的实际执行顺序完全由 forward 函数决定 ,而不是由 __init__ 函数中定义的顺序,或者模型 print() 出来的结构列表决定的。
__init__ 就像是你在厨房里"准备食材和厨具"(注册网络层),而模型打印出来的结构只是你厨房清单的罗列;forward 才是真正的"菜谱",它规定了食材下锅的确切顺序。
你代码中的 forward 顺序是经典的 ResNet v1(标准残差网络) 的标准实现。以下是每一层为什么必须按照这个特定顺序排列的深度剖析:
1. 第一阶段:基础特征提取与激活
代码: out = self.conv1(x) -> self.bn1(out) -> self.relu(out)
-
先
Conv(卷积): 这是主路径的第一步,负责从输入信号中提取新的特征映射。 -
再
BatchNorm(批归一化): 为什么 BN 必须在 ReLU 之前? 因为卷积层的输出通常会有偏移和分布不均。如果在激活之前进行归一化,可以将数据强行拉回到均值为 0、方差为 1 的正态分布附近。这样可以确保数据在进入 ReLU 时,有很大一部分落在激活区(大于 0 的区域),有效缓解梯度消失问题,并加速模型收敛。 -
后
ReLU(激活函数): 引入非线性。此时网络已经获取了经过标准化且被非线性筛选过的特征。
2. 第二阶段:正则化
代码: out = self.dropout(out)
- 为什么放在这里? Dropout 的作用是随机让一部分神经元失活,以防止过拟合。放在第一个 ReLU 之后,意味着我们对"已经初步提取并激活的特征"进行随机掩码,迫使下一层不要过度依赖特定的特征组合,增强模型的泛化能力。
3. 第三阶段:残差映射生成(最关键的非直觉设计)
代码: out = self.conv2(out) -> self.bn2(out) (注意:这里没有 ReLU!)
-
再次
Conv和BatchNorm: 进一步提取更高级的特征映射,也就是我们要学的残差 -
为什么这里绝对不能紧跟
ReLU?(核心考点)残差块的目标是学习映射
这种修改量有时需要增加某些特征的强度(正值),有时需要减弱或抵消某些特征(负值)。如果我们在
bn2后面立马加上ReLU,那么
4. 第四阶段:特征融合与最终激活
代码: out += self.shortcut(identity) -> self.relu(out)
-
先相加 (
+=): 将主路径学到的修改量identity畅通无阻地流向更深层。 -
最后
ReLU: 相加完成后,我们需要为整个残差块的输出引入最终的非线性,然后再传递给下一个残差块。
总结来说: 这个顺序保证了特征在每次线性变换后都能得到规范化,保留了残差分支表达负数域的能力,同时也确保了信号能够通过捷径(Shortcut)稳定地前向和反向传播。
这是何恺明团队在 2015 年提出的经典设计。后来他们团队在 2016 年又提出了一种改进方案,被称为 "Pre-activation ResNet"(预激活残差网络,ResNet v2),将 BN 和 ReLU 的位置挪到了卷积之前。
为什么 ResidualBlock1D 的 forward 顺序要这样设计?
你给出的 ResidualBlock1D 的 forward 顺序是:
out = conv1(x)
out = bn1(out)
out = relu(out)
if dropout: out = dropout(out)
out = conv2(out)
out = bn2(out)
out = out + shortcut(identity) # 残差连接
out = relu(out)
这是 标准 ResNet 残差块 的经典顺序。下面我解释每一步的设计意图。
1. 核心思想:学习残差
残差网络的目标是让网络学习 输入与输出的差值 ,即
其中 F(x) 是主路径需要学习的残差函数。这样做的好处是:当 F(x)接近 0 时,网络可以轻松实现恒等映射,避免深层网络退化。
你的 forward 顺序中,主路径正是 F(x):
-
conv1+bn1+relu+conv2+bn2→ 得到F(x)。 -
然后加上 短连接
shortcut(x)(即恒等映射或维度匹配投影),得到H(x)。 -
最后再经过一次
relu,让输出保持非线性。
2. 为什么第二个卷积后不加激活,而是先加残差再激活?
在标准 ResNet 论文(He et al., 2016)中,残差块的设计是:
y = F(x, {Wi}) + x
其中 F 通常由 两个卷积层 组成,且只在第一个卷积后使用激活,第二个卷积后直接输出,不加激活。这样做的原因:
-
让恒等映射(shortcut)传递时不被激活函数阻断 。
如果第二个卷积后也加了激活(比如 ReLU),那么输出就是
relu(F(x) + x)。此时即使F(x)=0,输出也是relu(x),不再是恒等映射,破坏了"让网络容易学习恒等"的设计初衷。 -
梯度流动更顺畅 。
在反向传播时,
out = out + identity这条分支会直接将梯度传递给输入,不经过任何非线性,有助于解决深层网络的梯度消失问题。
因此,先相加,后激活 是残差块的标准结构。
3. Dropout 放在哪里?
你在第一个激活后、第二个卷积前添加了 dropout。这是一种常见做法:
-
在第一个卷积后、第二个卷积前加入 dropout,可以对中间特征进行正则化,防止过拟合。
-
如果放在第二个卷积后(即残差相加前),效果类似,但可能会影响残差连接的稳定性。通常放在两个卷积之间是合理的。
4. shortcut 的作用
-
当
in_channels == out_channels时,shortcut是nn.Identity(),直接将输入x传递过来,实现恒等映射。 -
当
in_channels != out_channels时,使用1×1卷积调整通道数,并加上 BN,确保相加时维度一致。 -
shortcut的 BN 是可选的,但加入 BN 能保持数值稳定性。
5. 如果顺序颠倒会怎样?
假设你把第二个卷积后的 BN 和 ReLU 放在相加之后,比如:
out = conv2(out)
out = bn2(out)
out = out + identity
out = relu(out) # 这个没问题
但如果把 relu 放在相加之前:
out = conv2(out)
out = bn2(out)
out = relu(out) # 错误的顺序
out = out + identity
此时残差连接变成了 relu(F(x)) + x,破坏了恒等映射,并且梯度会受 ReLU 的饱和区影响,训练难度增加。
6. 总结:为什么这个顺序是"标准"的?
-
符合 ResNet 原文设计:确保模型可以轻松学习恒等映射,避免梯度消失。
-
保持梯度直接流动:残差连接不经过任何非线性,让信息可以直达深层。
-
模块化易扩展:每个残差块独立,且与预定义的 shortcut 配合,可以轻松堆叠成更深网络。
因此,你的 ResidualBlock1D 中的 forward 顺序是经过深思熟虑的,遵循了残差网络的经典设计原则。理解这个顺序,你就能更好地掌握 ResNet 的精髓。
24.nn.Conv1d()操作
nn.Conv1d 详解:从参数到内部计算
nn.Conv1d 是 PyTorch 中用于一维卷积的层,常用于处理序列数据(如时间序列、文本特征序列、音频信号等)。下面我们以你提供的示例为例,深入理解它的每个参数和内部工作原理。
一、nn.Conv1d 的常用参数
self.conv1 = nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)以你的代码为例:
nn.Conv1d(self.feature_per_step, 64, kernel_size=7, stride=1, padding=3, bias=False)1. in_channels(输入通道数)
-
含义 :输入数据的通道数,即特征的数量。对于一维卷积,输入形状为
(batch_size, in_channels, length)。告诉卷积层,输入数据的每个时间步(或序列中的每个位置)包含多少个特征。如果你处理的是单声道音频,通道数就是 1;如果是股票数据(开盘、收盘、最高、最低),通道数可能是 4。 -
示例中 :
self.feature_per_step(例如 8)表示每个时间步有 8 个特征,所以输入通道数为 8。
2. out_channels(输出通道数)
-
含义 :卷积核的个数,也就是输出特征图的数量。每个卷积核学习一种不同的特征模式。这是你期望这层网络提取出的特征数量(也就是卷积核的数量)。设置为 64,意味着这层网络会用 64 种不同的视角去观察输入数据,最后输出 64 张特征图。
-
示例中 :
64,表示输出有 64 个通道。
3. kernel_size(卷积核大小)
-
含义 :卷积核在长度维度上的尺寸。例如
kernel_size=7表示卷积核覆盖 7 个连续的时间步。定义了卷积核的"视野"范围(专业术语叫感受野 )。7代表每次观察连续的 7 个时间步长的数据。较大的卷积核能捕捉更宏观的趋势,较小的捕捉局部细节。 -
作用:决定感受野的大小。较大的卷积核可以捕捉更长的依赖关系。
4. stride(步长)
-
含义 :卷积核在输入上滑动的步长。默认 1。卷积核每次滑动的距离。
stride=1表示一格一格地滑动,扫描非常细致;如果stride=2,则每次跳过一格,这会使输出的序列长度减半(起到下采样的作用)。 -
示例中 :
stride=1表示每次移动 1 个时间步,输出长度与输入长度大致相同(在合适 padding 下)。
5. padding(填充)
-
含义 :在输入序列的两端填充多少零。填充可以控制输出长度,防止边界信息过快丢失。为什么这么做? 主要是为了控制输出的长度 。当
kernel_size=7且stride=1时,如果不填充,由于边缘数据无法凑齐 7 个,输出序列会变短。设置padding=3(左右各补 3 个零),刚好可以抵消边缘损失,使输入和输出序列的长度保持一致。 -
计算公式 :输出长度
L_out = floor((L_in + 2*padding - kernel_size) / stride) + 1。 -
示例中 :
padding=3,kernel_size=7,步长 1,则输出长度 =(L_in + 2*3 - 7)/1 + 1 = L_in,即输入输出长度相同(称为 same padding)。
6. dilation(膨胀系数)
-
含义:卷积核元素之间的间隔。默认为 1,即标准卷积。膨胀卷积可以扩大感受野而不增加参数量。
-
示例中:未设置,默认为 1。
7. groups(分组卷积)
-
含义:将输入通道分组,每组独立卷积,减少参数量。默认为 1。
-
示例中:未设置,默认 1,即普通卷积。
8. bias(偏置)
-
含义 :是否添加可学习的偏置项。是否在计算结果上加上一个常数偏移量。因为你在代码中紧接着使用了
BatchNorm1d,而 BN 层的标准化操作会直接抵消掉卷积层偏置的作用,所以设置为False可以省去无意义的计算和显存开销。 -
示例中 :
bias=False,表示不使用偏置。通常后面会接 BatchNorm,所以可以省去偏置。
二、nn.Conv1d 的内部结构
nn.Conv1d 本身是一个线性层 ,其核心是一个可学习的权重张量 (形状为 (out_channels, in_channels, kernel_size))和一个可选的偏置张量 (形状 (out_channels,))。在初始化时,这些参数会被随机初始化(默认使用 He 初始化或 Kaiming 初始化),并在训练过程中通过反向传播更新。
内部没有复杂的子模块,它只是封装了卷积运算。
三、Forward 过程中具体做了什么操作?
当数据进入 nn.Conv1d 时,它的内部会执行一个动态的**滑动窗口相乘求和(内积)**操作。
当输入张量 x(形状 (batch_size, in_channels, L_in))通过 nn.Conv1d 时,内部执行以下步骤:
-
准备权重: 内部初始化了 64 个相互独立的卷积核,每个卷积核的尺寸为
(in_channels, 7)。 -
对齐与相乘: 第 1 个卷积核对准输入序列的开头(包含前 7 个时间步的所有通道)。它将自己身上的权重与这块数据对应位置的数值逐个相乘。
-
求和汇聚: 将所有乘积结果加在一起,得到一个标量数值。这个数值就代表了这 7 个时间步里,是否包含了该卷积核想要寻找的某种特征模式。
-
滑动: 卷积核按照步长(
stride=1)向右滑动一格,重复上述乘加操作,直到滑过整个序列。这样,第 1 个卷积核就生成了一条新的一维特征序列。 -
多线程并行: 64 个卷积核同时(或依次)扫过输入数据,最终生成 64 条特征序列,叠在一起拼成了最终的输出张量。
-
生成输出 :所有滑动位置的结果组成输出特征图,形状为
(batch_size, out_channels, L_out)。
数学表示 (对于单个输出通道 o 和输出位置 t):
其中:
-
C是输入通道数(in_channels) -
K是卷积核大小(kernel_size) -
s是步长(stride) -
p是填充(padding),使得索引有效。
通俗理解:卷积核就像一个滑动窗口,每次从输入中提取一块区域,与核做点积,生成一个数值。不同的卷积核提取不同的局部特征。
为了让你更直观地理解这个滑动计算过程,我为你生成了一个交互式的一维卷积演示器。你可以直观地看到它是如何通过相乘和求和来提取特征的:
请让GeminiAI生成......
四、输入和输出的形状要求
输入形状: 必须是 3D 张量,格式为 (Batch_Size, Channels, Sequence_Length)
-
PyTorch 要求 :
(batch_size, in_channels, L_in),其中batch_size是批量大小,in_channels是输入通道数(特征数),L_in是序列长度(时间步数)。 -
如果你有形状
(batch, L_in, in_channels)的数据,需要使用x.transpose(1, 2)转换为(batch, in_channels, L_in)。
输出形状: 格式为 (Batch_Size, Out_Channels, Out_Sequence_Length)
- 给定输入长度
L_in,输出长度L_out由公式计算:
- 在你的示例中(
kernel_size=7, padding=3, stride=1, dilation=1),若输入长度L_in,则输出长度L_out = L_in(即 same padding)。
输出形状:(batch_size, out_channels, L_out)。
五、为什么卷积神经网络(CNN)有效?
-
局部连接:每个神经元只连接输入的一小块区域,减少参数数量。
-
权值共享:同一个卷积核在整个输入上滑动,检测相同的特征模式,大幅降低参数量。
-
平移不变性:特征在输入中的位置改变,输出也会相应平移,但特征检测能力不变。
-
层次特征:浅层提取边缘、纹理等低级特征,深层组合成更高级的语义特征。
六、结合你的 ResNet1D 示例
在你的 ResNet1DClassifier 中,输入特征 (batch, 256) 先被重塑为 (batch, seq_len=32, feature_per_step=8),然后转置为 (batch, 8, 32) 作为卷积的输入。
第一层卷积:
self.conv1 = nn.Conv1d(8, 64, kernel_size=7, stride=1, padding=3, bias=False)-
输入形状:
(batch, 8, 32) -
输出形状:
(batch, 64, 32)(因为 padding=3, kernel_size=7,长度不变) -
作用:将 8 个特征通道映射为 64 个特征通道,并用 7 的大核提取长距离依赖。
七、总结
-
nn.Conv1d的参数控制卷积核的形状、滑动方式、填充等,直接影响输出尺寸和感受野。 -
内部执行的是滑窗点积操作,通过学习卷积核权重来提取局部特征。
-
输入必须是
(batch, in_channels, length)格式,输出为(batch, out_channels, new_length)。 -
卷积层是构建 CNN 的基础,理解其原理有助于设计更有效的网络结构。