引言
最近在 AI 工程圈很火的 "Harness Engineering" ,翻译过来可以是AI"驾驭工程",它的来源大致是这样的:Mitchell Hashimoto 在 2026 年 2 月初用这个词来描述自己使用 AI agent 的方法;随后 OpenAI 在 2 月 11 日发布了《Harness engineering: leveraging Codex in an agent-first world》;紧接着 Martin Fowler 在 2 月 17 日写了专门的解读,把它归纳成更清晰的工程框架。
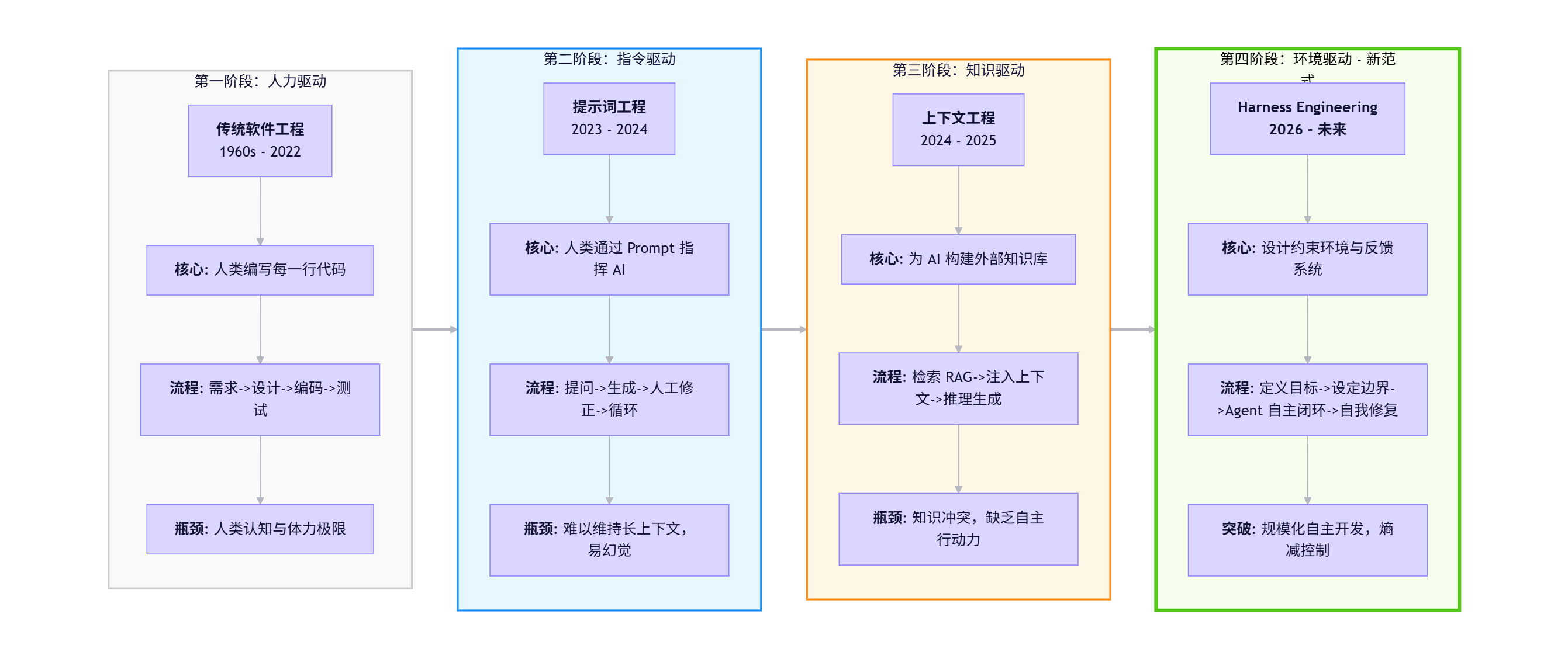
那到底什么是Harness Engineering?那我们首先了解一下软件工程范式的演进, 就慢慢清晰了**。**
1、软件工程范式演进
大家都知道,软件工程范式已经经历了三次演进:
(1)第一代:传统软件工程(1960s - 2020s):
| 特征 | 描述 |
|---|---|
| 核心 | 人类编写代码,机器执行 |
| 方法论 | 瀑布模型 → 敏捷开发 → DevOps → 云原生 |
| 工程师角色 | 代码生产者、系统架构师 |
| 关键问题 | 如何让人类更高效地写代码、协作、部署 |
这是人类中心主义的软件工程------一切围绕"人类写代码"展开。
(2)第二代:Prompt Engineering(2022 - 2023)
| 特征 | 描述 |
|---|---|
| 核心 | 通过优化提示词让 AI 输出更好结果 |
| 方法论 | 提示词技巧、Few-shot、Chain of Thought |
| 工程师角色 | 提示词设计师 |
| 关键问题 | 如何让 AI 理解我的意图 |
这是指令驱动的范式------"人类下指令,AI 执行单次任务",也是目前程序员和普通人用的最多的。
(3)第三代:Context Engineering(2024 - 2025)
| 特征 | 描述 |
|---|---|
| 核心 | 给 AI 提供正确的上下文/知识 |
| 方法论 | RAG、知识库、长上下文管理 |
| 工程师角色 | 知识架构师 |
| 关键问题 | 如何让 AI 有足够的知识做决策 |
这是知识驱动的范式------"人类提供知识,AI 基于知识执行",这是目前企业都在做的东西。
(4)第四代:Harness Engineering(2026 - )
| 特征 | 描述 |
|---|---|
| 核心 | 设计约束环境、反馈循环、控制系统 |
| 方法论 | 架构约束、自动化审查、熵管理、自我修复 |
| 工程师角色 | 环境设计师、系统约束师 |
| 关键问题 | 如何让 AI 在复杂长周期任务中稳定可靠 |
这是环境驱动的范式------"人类设计环境,AI 在约束下自主工作",这是目前AI时代的新范式!
总结如下:
2、什么是Harness Engineering?(what)
核心定义:"人类掌舵,智能体执行"。
Harness Engineering(驾驭工程)是在智能体优先的世界中构建软件的全新工程范式。工程师的主要工作不再是编写代码,而是: 设计环境、 明确意图和构建反馈回路。使 AI 智能体(如 Codex)能够可靠地自主工作。
关键数据(OpenAI 内部实验):
| 指标 | 数据 |
|---|---|
| 时间跨度 | 5 个月 |
| 代码量 | 约 100 万行 |
| 人工编写代码 | 0 行 |
| 团队规模 | 3 人 → 7 人 |
| Pull Request 数量 | 约 1,500 个 |
| 人均吞吐量 | 每天 3.5 个 PR |
| 效率提升 | 约为手工编写的 1/10 时间 |
3、为什么会出现Harness Engineering?(why)
当然是解决痛点!!!
| 维度 | 传统软件工程痛点 | Prompt/Context Engineering 痛点 | Harness Engineering 解决方案 |
|---|---|---|---|
| 生产效率 | 人类每天工作≤8小时,手写代码速度慢 | AI 生成快但需人工逐行审查,瓶颈在人类 | 智能体自主工作,人类睡眠时间也能运行(单次>6小时) |
| 认知负荷 | 人类同时处理任务数量有限 | 需持续跟踪 AI 输出,精神消耗大 | 工程师设计环境,智能体自主闭环,人类只做关键决策 |
| 代码规模 | 大项目需数百人年,扩展性差 | 长任务易失控,无法维持万行以上代码 | 5 个月 100 万行代码,3-7 人团队即可完成 |
| 知识管理 | 文档分散(Google Docs/聊天记录),智能体无法访问 | 大型 AGENTS.md 立即腐烂,变成陈旧规则坟场 | docs/ 结构化目录 + 渐进式披露 + doc-gardening 智能体自动维护 |
| 代码质量 | 人工 Code Review 耗时,标准不一致 | 幻觉严重,不良模式在代码库中传播数天/数周 | 自定义 linter + 品味不变式 + 黄金原则编码到系统中 |
| 技术债务 | 累积后痛苦一次性解决,像高息贷款 | 每周五花 20% 时间清理"AI 残渣",不可扩展 | 循环清理流程 + 后台 Codex 任务扫描偏差 + 自动发起重构 PR |
| 架构约束 | 数百人团队才采用分层架构,小团队无规范 | 无约束导致架构漂移,速度随规模下降 | 早期强制分层架构(Types→Config→Repo→Service→Runtime→UI) |
| 合并流程 | 严格阻塞合并门,等待成本低 | 测试失败无限期阻碍,智能体高吞吐量下等待成本高 | 减少阻塞,后续重跑解决,纠错成本低 |
| 可观测性 | 日志/指标需人工查询分析 | 智能体无法直接读取应用状态 | 本地可观测性堆栈,Codex 可用 LogQL/PromQL 直接查询 |
| 调试能力 | 人工复现 bug,录制演示视频耗时 | 智能体无法访问运行中应用 | 接入 Chrome DevTools 协议,处理 DOM 快照、截图,自动录制视频 |
| 反馈循环 | 发现问题→人工修复→再测试,周期长 | 单次交互,无持续反馈机制 | 智能体审查循环 + 自动化修复 + 仅在需要判断时交人工 |
| 人类角色 | 工程师=代码生产者,可替代性强 | 工程师=提示词调优师,技能碎片化 | 工程师=环境设计师,专注系统/架构/杠杆,价值放大 |
3.1 突破人类认知与体力极限
"我们唯一真正稀缺的资源:人类的时间和注意力"
传统软件工程中,人类是代码的生产者,受限于:
- ⏱️ 工作时间(每天 8 小时)
- 🧠 认知负荷(同时处理的任务数量有限)
- ✍️ 编写速度(手写代码效率瓶颈)
Harness Engineering 让智能体在人类睡眠时间也能持续工作(单次运行超过 6 小时)。
3.2 传统工程规范失效
| 传统规范 | 智能体高吞吐量下的问题 |
|---|---|
| 严格合并门禁 | 等待成本高,纠错成本低 |
| 人工代码审查 | 人类 QA 能力成为瓶颈 |
| 文档存储在外部 | 智能体无法访问(Google Docs、聊天记录) |
| 技术债务累积 | 漂移不可避免,需持续清理 |
"在低吞吐量环境中,这样做是不负责任的。而在这里,这通常是正确的选择。"
3.3 解决熵增与代码漂移
智能体会复现代码库中已存在的模式------包括不均衡或不够理想的模式。
问题:
- 😓 人类每周五花 20% 时间清理"AI 残渣"→ 不可扩展
- 📉 不良模式在代码库中传播数天或数周
解决:
- 将"黄金原则"编码到代码库中
- 建立循环清理流程(类似垃圾回收)
- 每天发现并解决不良模式
3.4 规模化构建复杂软件
"构建软件仍然需要纪律,但纪律更多地体现在支撑结构上,而不是代码上。"
随着智能体在软件生命周期中占比增加,设计环境、反馈回路和控制系统变得越发重要。
4、 如何实现 Harness Engineering?(how)
OpenAI 的做法很像"把工程系统做成 agent 可读、可验证、可自我修正的机器"。具体包括:
- 用 Codex 从空仓库开始生成项目骨架;
- 把仓库知识作为系统事实来源;
- 让 AGENTS.md、docs、CI、格式化规则、测试和观测一起工作;
- 要求 agent 先本地自审,再请求额外审查,再循环修正直到通过。
Martin Fowler 进一步把实现归为三类:上下文工程 (给对信息)、架构约束 (用规则和测试限制错误空间)、垃圾回收/熵管理(持续清理文档与结构的漂移)。
4.1 上下文工程:让系统对智能体"可读"
目标: 将知识转化为智能体可直接理解、验证和操作的系统事实。
核心实践:
1、从空仓库开始,构建结构化知识图谱
- 用 Codex 生成项目骨架: 从空白 Git 仓库开始,通过 Codex 自动生成初始项目结构(如目录布局、基础代码、配置文件)。
- 标准化知识存储:
docs/目录: 所有文档(如架构图、API 规范、业务规则)以机器可读格式(Markdown、代码注释、YAML)存储在仓库中,而非外部系统(如 Google Docs)。AGENTS.md: 定义智能体的行为规则、权限、协作流程,作为智能体的"操作手册",持续更新并纳入版本控制。- 代码即文档: 将业务逻辑和"黄金原则"编码到代码库中(如常量、枚举、注释),而非依赖外部说明。
2、渐进式披露与情境绑定
- 智能体仅访问当前任务所需的上下文(如相关文档、代码片段、历史 PR),避免信息过载。
- 通过工具链将任务上下文自动注入智能体的执行环境。
效果: 智能体可自主定位、理解并验证任务所需的所有信息,无需人工解释。
4.2 架构约束:限制错误空间,确保"可验证"
目标: 通过规则和测试定义清晰边界,强制智能体在安全框架内操作。
核心实践:
- 分层架构与模块化设计
- 强制采用分层架构(如 Types → Config → Repo → Service → Runtime → UI),每层定义明确的职责和接口。
- 模块间通过契约(如类型定义、接口规范)通信,降低耦合性。
- 代码静态检查与动态验证
- 自定义 Linter: 编写针对业务场景的静态代码检查规则(如命名规范、安全最佳实践、架构合规性)。
- 品味不变式(Coding Taste Invariants): 将代码风格、设计模式等主观偏好编码为可自动验证的规则。
- 单元测试 + 集成测试: 覆盖所有关键路径,确保智能体生成的代码不破坏现有功能。
- 可观测性集成: 将 LogQL、PromQL 等查询能力嵌入系统,使智能体可实时访问应用状态和指标,验证结果正确性。
- 智能体操作权限控制
- 定义智能体可修改的代码范围(如特定目录、文件类型)。
- 关键操作(如数据库修改、生产环境部署)需人工审批。
效果: 通过规则和测试构建"安全区",智能体生成的代码必须经过验证才能合并,大幅降低错误风险。
4.3 熵管理:持续"自我修正",对抗系统漂移
目标: 主动检测和修复系统中的技术债务、知识陈旧、架构漂移问题,保持系统健康。
核心实践:
- 循环清理流程:
- 后台 Codex 任务扫描: 定期运行 Codex 扫描代码库,自动检测:
- 冗余代码、死代码。
- 不符合"黄金原则"的代码模式(如反模式、低效实现)。
- 文档与代码不一致问题。
- 自动发起重构 PR: 对于可自动修复的问题(如格式问题、简单重构),直接由 Codex 提交 PR,多数在 1 分钟内即可由人类或另一智能体审查合并。
- 垃圾回收机制:
- 文档治理(Doc Gardening): 智能体自动更新过时文档,清理无效注释,保持
docs/与代码同步。 - 架构漂移检测: 持续监控代码依赖关系、分层架构合规性,发现违规立即触发修复任务。
- 智能体自我改进循环
- 本地自审与循环修正:
i. 智能体生成代码后,先通过本地 Linter、单元测试进行自验证。
ii. 若未通过,根据反馈自动修正并重新验证,循环迭代直至通过。
iii. 若无法自修正,则提交初步结果并请求额外审查,人类提供指导后再次循环。
- 从错误中学习: 记录智能体的失败案例,将其转化为新的验证规则或训练数据。
效果: 系统具备"自我清洁"能力,技术债务和架构问题在产生之初即被消除,避免累积爆发。
4.4 工作流闭环:智能体自主,人类掌舵
将上述机制整合为端到端流程:
- 任务接收
- 人类定义高价值目标(如功能开发、bug 修复)。
- 智能体执行
- 获取任务上下文 → 生成代码/修复方案 → 本地验证(测试、Linter)→ 自修正 → 提交 PR。
- 人类审查(仅关键节点)
- 对高风险或复杂变更进行最终审批,提供战略方向或仲裁冲突。
- 系统反馈
- 监控指标(如 PR 通过率、错误率),动态调整约束规则或上下文信息。
- 持续优化
- 将人类反馈注入智能体模型,提升后续任务质量。
核心原则: 智能体负责"如何做",人类负责"做什么"和"何时干预"。
💡 总结: OpenAI 通过将系统构建为 "智能体可理解的自治机器" ,实现了从"人写代码"到"人设计系统,智能体进化系统"的范式转变。上下文工程 解决"理解"问题,架构约束 解决"正确性"问题,熵管理 解决"可持续性"问题,三者结合使智能体能够可靠、自主、持续地构建和维护复杂软件系统。