深度解读 LangChain 的 Deep Agents:生产级智能体引擎的架构与工程哲学 🚀
Deep Agents 是 LangChain 生态中的核心生产级组件📦,其定位已超越传统智能体框架的范畴,进化成一个高度工程化的"智能体执行环境(Agent Harness)"⚙️。它通过系统化封装任务规划、上下文管理、持久化、安全沙箱等核心能力🔒,将大模型(LLM)的"智能"转化为可稳定执行长周期、多步骤任务的可靠引擎。Deep Agents 的设计哲学凝练为一句核心目标:**"让智能体的执行过程可观测、可控制、可改进"**✨。这一理念使其成为复杂生产环境中自动化工作流与决策支持系统的理想基石,彻底重塑了智能体技术的工程化边界。
一、核心定位:从"智能体框架"到"生产级 Harness" 🎯
1. 重新定义智能体的工程化边界
传统智能体框架(如 ReAct)聚焦于单次交互的"思考-行动"循环🔄,在面对复杂任务时,常因上下文爆炸、状态丢失、执行不可控等问题陷入困境。
Deep Agents 将开发范式从 Prompt Engineering(提示工程)升维至 Harness Engineering(执行环境工程):构建包含规划、执行、监控、优化的完整执行环境🌐,而非仅依赖模型的单次推理能力。这一跨越使智能体从"单步执行者"进化为"任务指挥官"👨✈️。
2. Harness Engineering 范式的核心体现
Deep Agents 代表 AI Agent 开发的范式转变------从 Prompt Engineering(优化单次交互)到 Harness Engineering(构建执行环境):
- Model(模型):负责思考决策(输入 Token,输出 Token)。
- Harness(执行环境):包裹模型的系统化设施,决定任务如何稳定执行,包括规划工具、文件 I/O、安全护栏、状态管理等。
- 核心公式:Agent = Model + Harness。Deep Agents 的核心目标是将 LLM 的"非确定性智能"转化为可稳定执行长链路任务的引擎2。
二、技术架构与核心组件 🏗️
Deep Agents 以 LangGraph 为基座,融合流式处理、状态持久化与图化执行引擎能力,核心组件构成其技术骨架。
整体架构概览
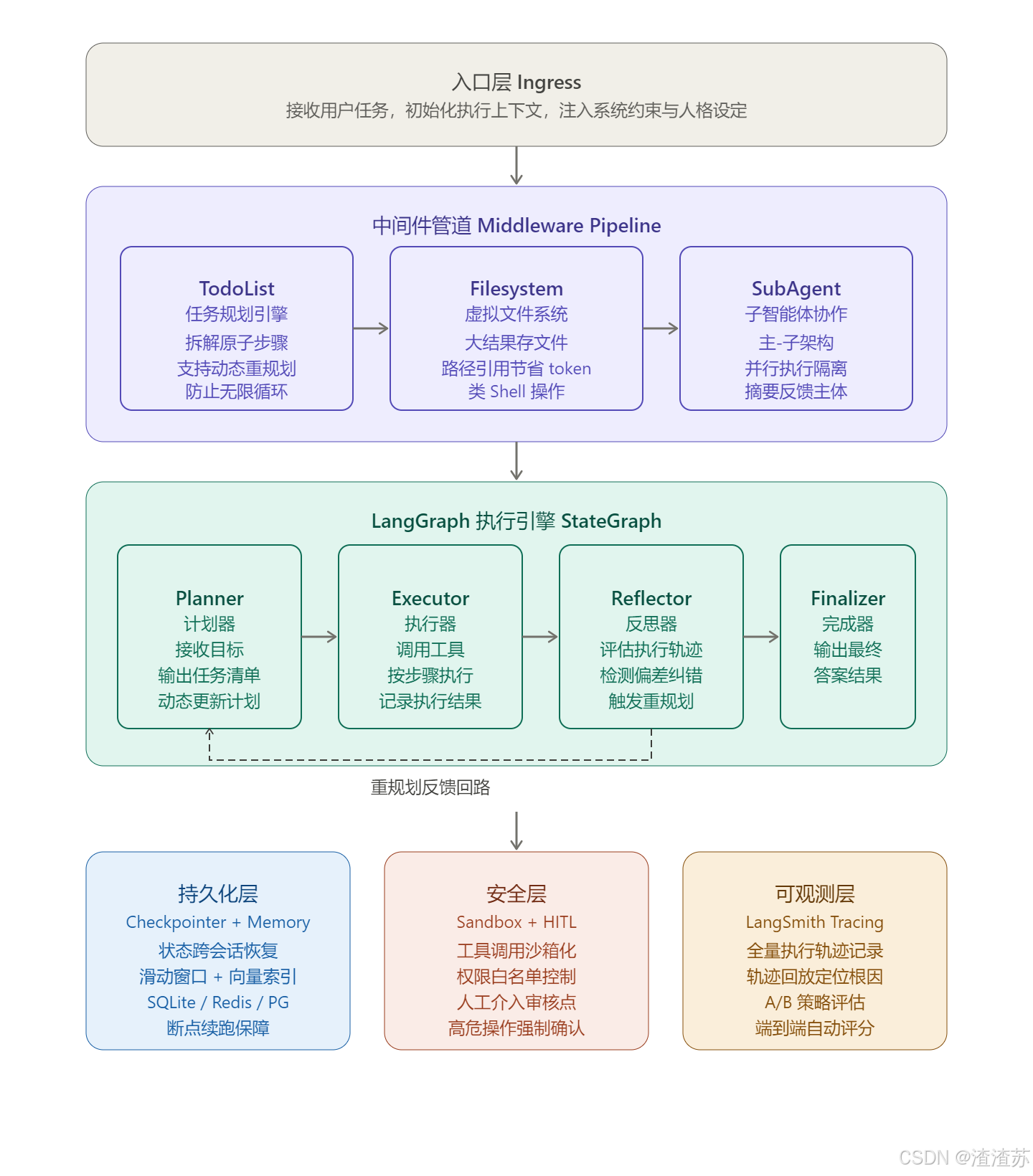
整个架构分为四层:入口层 负责接收任务与初始化上下文📥;中间件管道 对任务进行预处理与能力增强;LangGraph 执行引擎 承担核心推理与状态驱动;底部基础设施层提供持久化、安全与可观测性保障,四层协同构成完整的"智能体执行环境"。
中间件管道的运行机制
Deep Agents 将各核心能力封装为可插拔的 **Middleware(中间件)**🔌,通过统一的管道协议串联执行。每个中间件遵循"拦截-增强-透传"模式:
python
# 中间件管道装配示例
agent = DeepAgent(
llm=llm,
middlewares=[
TodoListMiddleware(max_steps=20), # 任务规划中间件
FilesystemMiddleware(backend="memory"), # 虚拟文件系统中间件
SubAgentMiddleware( # 子智能体中间件
sub_agents={"researcher": research_agent}
),
],
checkpointer=SqliteSaver("agent_state.db"), # 持久化检查点
tracer=LangSmithTracer(project="prod-agent") # 追踪中间件
)这种设计的核心优势在于关注点分离:每个中间件独立维护自己的状态与逻辑,组合时互不干扰,便于单独测试、替换或扩展。
① 任务规划引擎(TodoList Middleware)📋
强制智能体在行动前生成结构化任务清单(TodoList),将复杂目标拆解为可验证的原子步骤,避免"拍脑袋决策"。支持动态规划调整🔁:执行失败或信息不足时,智能体可自动推倒重来,重新规划后续步骤,实现"计划自适应"。
内部数据结构示例:
python
TodoList = {
"steps": [
{"id": 1, "action": "搜索2025年新能源销量数据", "status": "done"},
{"id": 2, "action": "搜索2026年Q1-Q3数据", "status": "done"},
{"id": 3, "action": "预测2026年全年数据", "status": "pending"}, # 动态插入
{"id": 4, "action": "计算增长率", "status": "pending"},
],
"current_step": 3,
"replanning_count": 1 # 记录重规划次数,防止无限循环
}② 虚拟文件系统(Filesystem Middleware)📁
破解上下文窗口限制难题:工具调用产生的大结果(如搜索文档、代码文件)自动存储为文件,智能体仅保留轻量级路径引用,大幅释放内存💾。支持 ls/read/write/edit_file 等类 Shell 操作,无缝对接本地、云或内存存储,工具输出自动摘要化,降低上下文资源占用。
上下文节省原理:
未使用 Filesystem:
[完整搜索结果 12,000 tokens] + [完整网页内容 8,000 tokens] = 消耗 20,000 tokens
使用 Filesystem:
[路径引用: /results/search_1.txt] + [路径引用: /results/page_2.txt] = 仅消耗 ~50 tokens③ 子智能体协作(SubAgent Middleware)👥
采用"主-子"架构:主智能体统筹全局,子智能体专攻垂直领域(如数据分析、代码生成),形成"分工协作网络"。子智能体拥有独立上下文与工具集,支持并行执行⚡,结果以摘要形式反馈主智能体,彻底杜绝上下文污染,提升执行效率。
主智能体 (Orchestrator)
├── 子智能体 A:数据采集(含 Tavily 搜索工具)
├── 子智能体 B:代码执行(含 Python REPL 工具) ←── 并行执行
└── 子智能体 C:报告撰写(含文档生成工具)
↓ 各子任务结果摘要汇总
主智能体整合最终答案④ 上下文管理与持久化 💽
通过智能摘要与分块策略,对长对话历史进行无损压缩。技术上采用滑动窗口 + 向量索引 双轨机制📊:近期 N 轮对话保留原文(精确记忆),更早的历史压缩为语义向量(模糊记忆),按需检索。跨会话状态通过 Checkpointer 序列化到持久存储(SQLite / Redis / PostgreSQL),确保长期任务"记忆不丢失",历史经验始终在线。
⑤ 安全与权限控制 🔐
工具调用全程沙箱化(如 Shell 命令受限执行),防止越权操作,为系统安全加装"防护锁"。内置"人工介入点"(Human-in-the-loop)🙋,敏感操作必经人工审核,实现"机器效率"与"人类控制"的平衡。权限模型采用工具级白名单机制:
python
# 权限配置示例
tool_permissions = {
"web_search": PermissionLevel.AUTO, # 自动执行
"read_file": PermissionLevel.AUTO, # 自动执行
"write_file": PermissionLevel.CONFIRM, # 需人工确认
"execute_shell": PermissionLevel.BLOCK, # 默认禁用
"db_write": PermissionLevel.CONFIRM, # 需人工确认
}⑥ 生产级追踪与评估(集成 LangSmith)📈
所有执行生成完整"生产轨迹"(Production Trace),每一步输入、输出、工具调用、状态变更全程留痕。结合 LangSmith 进行行为评估、端到端测试与自动评分,支持:
- 轨迹回放:精确复现任意历史执行过程,定位异常根因
- A/B 评估:对比不同 Planner 策略的任务完成率与 Token 消耗
- 自动评分:基于自定义评估标准(如答案准确性、步骤精简度)批量打分,质量把控如"数据仪表盘"
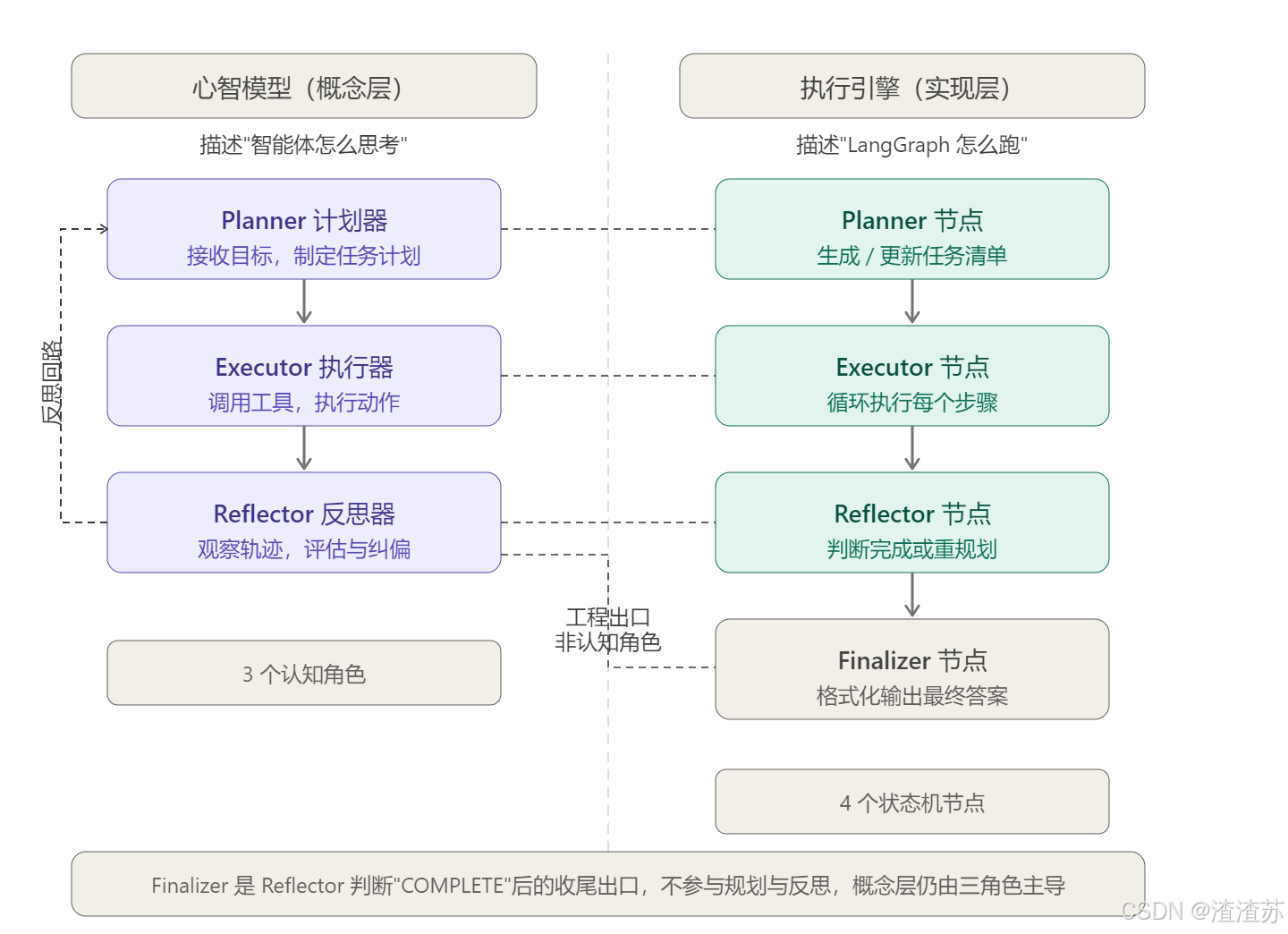
三、心智模型:三位一体的协作体系 🧠
Deep Agents 的智能内核由三个角色紧密协作驱动:
+-----------+ +-----------+ +-----------+
| Planner | ---> | Executor | ---> | Reflector |
| (计划器) | | (执行器) | | (反思器) |
+-----------+ +-----------+ +-----------+
^ | |
| v |
+-------- 共享记忆 & 状态 -----------+- Planner(计划器):接收总目标,输出可执行的任务清单。计划并非一成不变,而是可根据反馈动态更新。
- Executor(执行器):严格按计划步骤调用工具、执行动作,并记录执行结果,确保"指令落地"✅。
- Reflector(反思器):全程观察执行轨迹,评估进展。若发现偏差,可决定继续执行、修改计划或请求人工介入,实现"元认知"层面的自我纠偏🔍。
这一设计将智能体的"自我监控"能力显式化------它不仅是"执行者",更是时刻审视"执行是否正确"的"思考者"。
Finalizer 为工程实现中的输出节点,不参与规划与反思决策,概念层仍由 Planner / Executor / Reflector 三角色主导。
四、执行引擎:状态驱动的有向图 🧭
Deep Agent 的执行本质是一个状态机 。通过 LangGraph 的 StateGraph,精确定义节点与状态转换:
python
# 定义状态类型
class DeepAgentState(TypedDict):
objective: str
plan: List[str] # 当前计划(步骤列表)
step_index: int # 当前执行步骤索引
execution_history: List[str] # 执行历史记录
reflection_notes: str
final_answer: str
# 构建状态图
graph = StateGraph(DeepAgentState)
graph.add_node("planner", planner)
graph.add_node("executor", executor)
graph.add_node("reflector", reflector)
graph.add_node("finalizer", finalizer)
graph.set_entry_point("planner")
# 定义状态转换规则
graph.add_edge("planner", "executor")
graph.add_conditional_edges(
"executor",
lambda s: "reflector" if s["step_index"] >= len(s["plan"]) else "executor",
{"reflector": "reflector", "executor": "executor"},
)
graph.add_conditional_edges(
"reflector",
lambda s: "finalizer" if "COMPLETE" in s["reflection_notes"] else "planner",
{"finalizer": "finalizer", "planner": "planner"},
)
app = graph.compile()此逻辑赋予智能体"弹性执行"能力:计划执行完毕可重新规划,甚至彻底调整目标,实现动态适应复杂环境。
五、杀手级特性:动态规划与智能调节 ⚙️
Deep Agents 颠覆传统智能体"一股脑执行"的模式,践行"计划即上下文"理念:
- 层级分解:计划支持多级嵌套🌳。例如,"撰写市场研究报告"可被拆解为"收集数据"、"分析竞品"、"撰写摘要"------而"收集数据"步骤又可进一步触发子规划,形成"计划树"。
- 动态重规划:若某步骤连续失败(如工具报错、信息缺失),Reflector 将触发 Planner 重新生成后续计划,而非机械重复。
- 滑动窗口记忆:执行历史作为长期记忆源,通过压缩、摘要与向量库索引,实现跨会话经验复用,真正"吃一堑,长一智"📚。
- 人工在环控制 :可在任意节点配置
interrupt_before="executor",强制代理在执行高风险操作前暂停,等待人工审批。
六、实战案例:构建"深度研究"市场分析师 📊
以"对比2025 vs 2026年全球新能源汽车销量趋势,并给出投资建议"任务为例,使用 langchain-deepagents 的构建流程如下:
python
# 1. 配置基础组件
llm = ChatOpenAI(model="gpt-4.1", temperature=0) # 选择大模型
tools = [
TavilySearchResults(max_results=3), # 搜索引擎工具
CalculatorTool() # 计算器工具
]
# 2. 定义系统约束与人格
system_message = """
你是一个经验丰富的市场分析师。面对复杂问题时:
1. 先制定分步计划,每一步需可验证。
2. 执行后仔细检查结果,若信息不足或计划偏差,立即修正。
3. 最终报告需包含:清晰逻辑、关键数据、3条投资建议。
"""
# 3. 实例化 Deep Agent
agent = DeepAgent(
llm=llm, tools=tools, system_message=system_message,
max_iterations=25, # 设置最大执行步数
planning_interval=3, # 每3步重新评估计划
enable_reflection=True,
verbose=True # 开启调试日志
)
# 4. 发起任务
result = agent.invoke({"objective": "对比2025年和2026年全球新能源汽车销量趋势,并给出3条投资建议"})
# 5. 获取最终报告
print(result["final_answer"])底层心智轨迹解析:
- 生成初始计划:搜索2025销量 → 搜索2026销量 → 计算增长率 → 分析驱动因素 → 生成建议
- 执行前两步获取数据。
- 第3步触发 Reflection:发现2026年数据仅到Q3,信息不完整 → 修改计划,插入"预测全年销量"步骤并调用预测工具。
- 补充数据后完成增长率计算与建议撰写。
- Reflection 确认信息充分、逻辑闭环,标记任务完成(COMPLETE)✅。
整个过程犹如一位分析师在草稿纸上反复推敲、修正,最终输出严谨报告,展现了 Deep Agents "思考-行动-反思"的闭环能力。
七、与传统 ReAct Agent 的根性差异 ⚖️
| 维度 | ReAct Agent | Deep Agents |
|---|---|---|
| 决策粒度 | 单步思考-行动 | 基于全局计划的步骤集执行 |
| 计划可见性 | 仅存于当前推理链 | 显式计划状态,支持动态修改 |
| 失败处理 | 重试或终止 | 重新规划、跳过或降级策略 |
| 记忆机制 | 依赖对话上下文 | 短期(执行历史)+ 长期(向量化记忆) |
| 可干预性 | 难以中断内部循环 | 每个图节点可挂载人工中断点 |
核心差异总结:ReAct 是"摸着石头过河"🌊,Deep Agents 则是"手持地图动态导航"🗺️,兼具全局视野与灵活应变能力。
八、局限与生产级最佳实践 💡
- 成本管理 💰:每次 Planning 和 Reflection 均消耗 Token。建议通过
planning_interval控制频率,并在简单任务中自动降级为轻量 ReAct 模式。 - 防过度规划 :简单任务可能因过度分析而低效。可配置工具
return_direct=True,使执行器直接跳过复杂规划。 - 调试与优化 :强制集成 LangSmith 进行轨迹回放,清晰定位计划变更触发原因,优化执行路径。
- 安全加固:涉及高危工具(如数据库写入)时,必须插入人工确认步骤,避免自动化风险。
九、适用场景与选型指南 📋
优先使用 Deep Agents 的场景(满足以下任意2条)
- 复杂长周期任务 ⏳:需多步骤(>10步)、迭代反思(如自动化报告生成)。
- 上下文敏感型任务:工具返回结果巨大(如长文档、搜索数据),超出 LLM 窗口(8k/32k)。
- 子任务隔离需求:需独立权限/工具集(如代码执行需沙箱,数据分析需专用库)。
- 生产级可靠性要求:需持久化、断点续跑、人机协作、错误重试(如金融风控)。
- 长期记忆依赖:需跨会话保存用户偏好、历史交互或知识积累(如客户支持助手)。
不建议场景(选择 LangChain 基础 Agent 或 LangGraph 更高效)
- 简单问答/单步工具调用:如聊天机器人、天气查询。
- 确定性流程:步骤固定且无动态分支的流水线任务。
- 轻量原型验证:无需持久化/沙箱的快速 PoC 开发。
成功案例 📌
- GTM 销售智能体:整合 Salesforce、Gong 数据,自动处理线索,转化率提升 200%。依赖文件系统管理长周期对话,子 Agent 并行研究客户背景。
- 金融风控系统:5 个子 Agent 协作网络在 8 分钟内完成传统 2 小时的风险评估,通过上下文隔离避免信息干扰。
十、未来演进蓝图 🚀
- 性能革命:通过 Rust 等底层技术重构引擎,降低资源消耗,提升吞吐量。
- 元认知进化:融合强化学习优化规划策略,或基于历史轨迹自动学习最佳执行模式。
- 多智能体协作网络:支持联邦学习、辩论式协作等复杂拓扑,扩展群体智能边界。
- MCP 工具生态融合:深化第三方工具标准支持,打造更开放的工具互操作生态。
十一、总结 📝
Deep Agents 是 LangChain 对"生产级智能体工程化"的深度实践,通过系统化的 Harness 设计,实现了三大突破:
- 从"单次推理"到"长周期任务执行"的范式革命。
- 工程化破解上下文爆炸、状态管理、可靠性等核心痛点。
- 为复杂 AI 应用提供可观测、可调试、可优化的标准化执行框架。
对于需长期运行、多角色协作、高可靠性的企业级智能体应用,Deep Agents 不仅提供技术架构,更树立了工程方法论标杆,是智能体工程领域的重要里程碑。