核心原则
1.最长运行时间:可以在线修改配置无需重启。
2.可扩展:使用事件驱动模型(libev)每个现成可以处理上千个并发。
3.协议感知:proxy SQL对MySQL和PostgreSQL的协议有很深的理解能力(该技术能在网络协议层面直接操作)。实现数据库的流量路由以及SQL改写。
4.可修复:集成了监控,并且可以自动剔除不正常的后端数据库节点。
线程模型
Proxy SQL使用的是多线程模型,每个线程都可以处理制定的任务,从而避免资源竞争和保持稳定性。
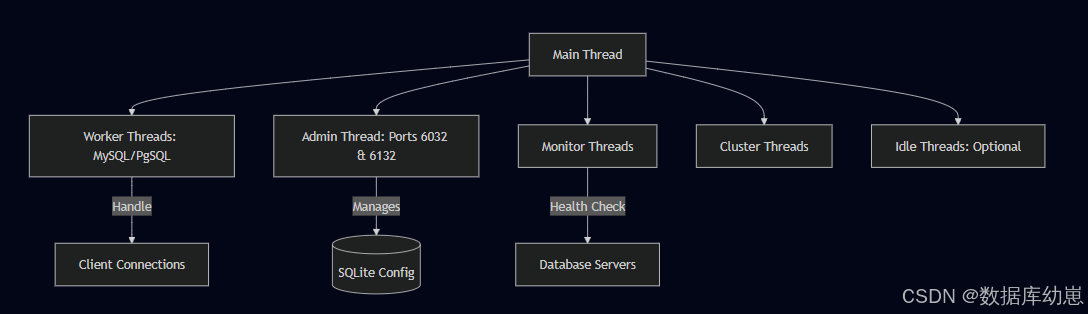
线程类型
MySQL Worker Threads:处理客户端大量的流量,包括验证,查询解析以及结果返回。
PgSQL Worker Threads:处理postgresql协议的专有的一个线程。
Admin Thread:管理proxy SQL的管理接口,支持MySQL(默认端口6032)和PostgreSQL(默认端口6132)的网络协议。
Monitor Threads:持续的在后端服务进行健康检查(ping,connection测试,replication lag)。
Cluster Threads: 在Proxy SQL集群的各个阶段中进行同步。核心组件
连接池(hostgroups管理)
proxy SQL组将后端服务都添加至hostgroups中,每一个hostgroups维护他自己的连接池。
-
Multiplexing(多路复用):允许多个前端的会话共享后端少量的连接(这些后端的连接是复用的,不是一个前端会话过来,就创建一个后端的数据库连接)。
-
延迟感知:自动将会话路由到相应最快的server中。
-
复制跟踪:通过监控后端server的read_only的状态来分发读写的流量(或者请求)。
2.查询处理器(query proceesor)
查询处理器是proxy SQL的核心。对于每一个query,proceesor都会做如下工作:
routing:决定哪个hostgroup处理这个query。
rewriting:SQL需要做哪些修改(比如是否为索引添加hints等)。
caching:内存中是否有可用的结果缓存。
blocking:处于安全规则,这个query是否应该被拒绝。
3.query digest system
proxy SQL会通过归一化的一个value对每一个query生成一个唯一的一个fingerprint(指纹)。【就是将类似的SQL去掉具体字段值之后,生成一个唯一的一个值。来代表此类query。比如select * from t1 where id=1被抽象为select * from t1 where id=?】。这可以使得proxy SQL搞高效的基于查询类型(或者被抽象后的查询模板)统计跟踪和匹配而不是根据具体的数据进行匹配。
数据流:查询的生命周期(在proxy SQL中的生命周期)
下图展示了一个query如何在proxy SQL和后端的数据库系统中的执行过程:
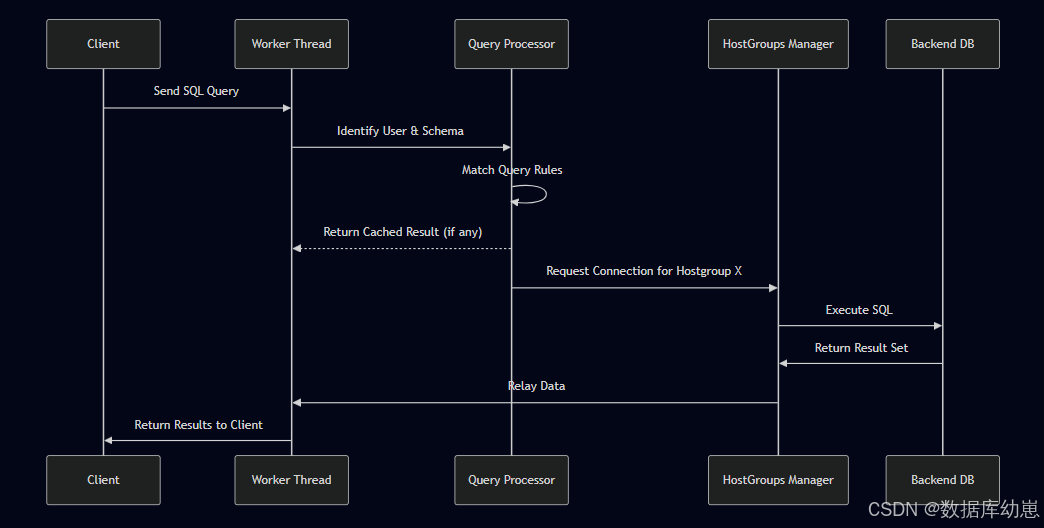
从客户端发送一个SQL到worker线程,worker线程进行验证以及schema的验证后,query处理器开始匹配查询规则。然后在请求连接hostgroup组。hostgroups管理器将SQL丢给后端数据库系统进行执行,执行完成后将结果返回给hostgroups管理器,然后在返回给worker线程,最后在返回给客户端。
性能优化
无锁统计Lock-Free statistics
proxy SQL的统计和counter(计数器)使用的是本地线程存储。这就允许worker线程更新统计信息指标的时候不用申请全局锁。确保CPU核数对性能的影响是线性的。
内存管理
proxy SQL继承了jemalloc确保高效的内存分配以及减少碎片的产生。这是proxy SQL长时间运行处理大量数据的关键。
编译正规缓存(compiled regex caching)
查询匹配模式会被编译并且保存在内存中。proxy SQL支持RE2和PCRE的上千条规则的高速模式匹配引擎。
持久性和集群
多层配置
所有的配置都存储在内部的SQLlite数据库中。允许事务更新(事务一致性)。确保持久化(disk)和运行状态(runtime)是分开的。
P2P Clustering
proxy SQL集群使用的是点对点的基于同步的模型。节点配置版本会在整个集群中进行比较配置文件的版本确保不会出现单点故障(由于单个节点的故障导致集群异常)。