PyTorch实战(38)------深度学习模型可解释性
0. 前言
在本专栏中,我们已经构建了多种深度学习模型来完成不同任务,包括手写数字分类器、图像描述生成器和情感分类器等。虽然我们已经掌握如何使用 PyTorch 训练和评估这些模型,但对其内部的预测机制仍缺乏清晰认知。模型可解释性 (Model Interpretability) 或可解释人工智能 (Explainable AI) 正是致力于回答以下核心问题:"模型为何做出特定预测?"或者说:"模型从输入数据中识别了哪些特征导致该预测结果?" 当这些模型应用于医疗、金融等关键领域时,此类问题的答案尤为重要。
1. PyTorch 模型可解释性
本节,将基于手写数字分类模型,深入剖析其内部工作机制,解释模型对特定输入做出预测的原因,使用 PyTorch 代码解构模型。通过本节学习,将掌握解构深度学习模型内部运作的关键技能。以这种方式深入了解模型有助于理解模型的预测行为逻辑。运用本节的实践经验,能够使用 PyTorch 解读自定义的深度学习模型。
在本节中,我们将使用 PyTorch 解构一个训练好的手写数字分类模型,来深入了解其工作原理。具体而言,我们将重点分析该模型卷积层的细节,以理解模型从手写数字图像中学到的视觉特征。我们将观察卷积滤波器/核 (convolutional filters/kernels) 及其生成的特征图 (feature maps)。这些细节有助于我们理解模型如何处理输入图像并做出预测。
2. 训练手写数字分类器
首先,我们快速回顾训练手写数字分类模型的步骤。完成这些步骤后,我们将得到一个具有良好分类准确率的卷积神经网络 (Convolutional Neural Network, CNN) 模型。
(1) 首先,导入相关库:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np(2) 接下来,定义模型架构:
python
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.cn1 = nn.Conv2d(1, 16, 3, 1)
self.cn2 = nn.Conv2d(16, 32, 3, 1)
self.dp1 = nn.Dropout(0.10)
self.dp2 = nn.Dropout(0.25)
self.fc1 = nn.Linear(4608, 64) # 4608 is basically 12 X 12 X 32
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
x = self.cn1(x)
x = F.relu(x)
x = self.cn2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dp1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dp2(x)
x = self.fc2(x)
op = F.log_softmax(x, dim=1)
return op(3) 然后,定义模型的训练和测试流程:
python
def train(model, device, train_dataloader, optim, epoch):
model.train()
for b_i, (X, y) in enumerate(train_dataloader):
X, y = X.to(device), y.to(device)
optim.zero_grad()
pred_prob = model(X)
loss = F.nll_loss(pred_prob, y) # nll is the negative likelihood loss
loss.backward()
optim.step()
if b_i % 10 == 0:
print('epoch: {} [{}/{} ({:.0f}%)]\t training loss: {:.6f}'.format(
epoch, b_i * len(X), len(train_dataloader.dataset),
100. * b_i / len(train_dataloader), loss.item()))
def test(model, device, test_dataloader):
model.eval()
loss = 0
success = 0
with torch.no_grad():
for X, y in test_dataloader:
X, y = X.to(device), y.to(device)
pred_prob = model(X)
loss += F.nll_loss(pred_prob, y, reduction='sum').item() # loss summed across the batch
pred = pred_prob.argmax(dim=1, keepdim=True) # us argmax to get the most likely prediction
success += pred.eq(y.view_as(pred)).sum().item()
loss /= len(test_dataloader.dataset)
print('\nTest dataset: Overall Loss: {:.4f}, Overall Accuracy: {}/{} ({:.0f}%)\n'.format(
loss, success, len(test_dataloader.dataset),
100. * success / len(test_dataloader.dataset)))(4) 接着,定义训练和测试数据集加载器:
python
# The mean and standard deviation values are calculated as the mean of all pixel values of all images in the training dataset
train_dataloader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1302,), (0.3069,))])), # train_X.mean()/256. and train_X.std()/256.
batch_size=32, shuffle=True)
test_dataloader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1302,), (0.3069,))
])),
batch_size=500, shuffle=True)(5) 接下来,实例化模型并定义优化器调度:
python
device = torch.device("cpu")
model = ConvNet()
optimizer = optim.Adadelta(model.parameters(), lr=0.5)(6) 最后,启动模型训练循环,模型训练 20 个 epoch:
python
for epoch in range(1, 10):
train(model, device, train_dataloader, optimizer, epoch)
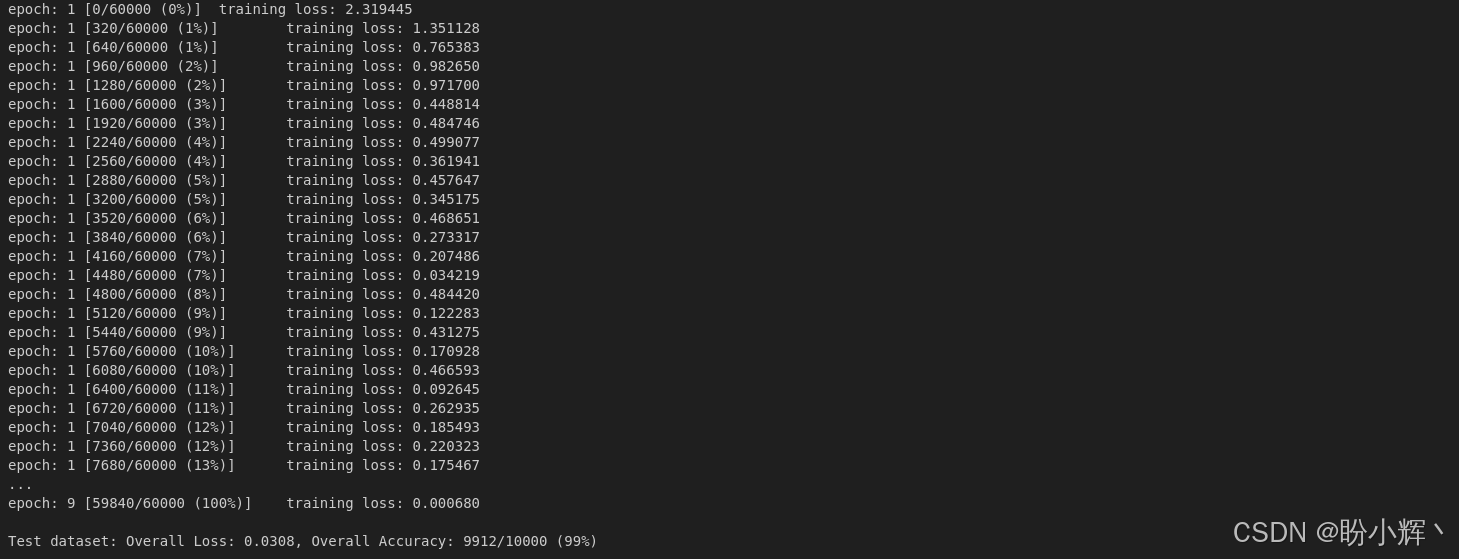
test(model, device, test_dataloader)输出结果如下所示:
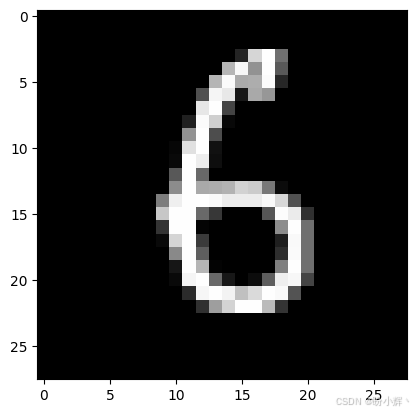
(7) 最后,在一张样本测试图像上测试训练好的模型,加载测试图像:
python
test_samples = enumerate(test_dataloader)
b_i, (sample_data, sample_targets) = next(test_samples)
plt.imshow(sample_data[0][0], cmap='gray', interpolation='none')
plt.show()输出结果如下所示:
(8) 然后,使用这个样本测试图像进行模型预测:
python
print(f"Model prediction is : {model(sample_data).data.max(1)[1][0]}")
print(f"Ground truth is : {sample_targets[0]}")输出结果如下所示:
python
Model prediction is : 6
Ground truth is : 6我们已经训练完成一个手写数字分类模型,并用它对样本图像进行了推理预测。接下来,我们深入探究这个训练后模型的内部结构,特别是分析模型学习到的卷积核特征。
3. 可视化模型卷积核
在本节中,我们将逐步查看训练好模型中的卷积层,并观察模型在训练过程中学习到的卷积核。通过这种分析,我们可以理解卷积层如何处理输入图像,各层提取的特征类型以及特征提取的演变过程。
(1) 首先,获取模型中所有层的列表:
python
model_children_list = list(model.children())
convolutional_layers = []
model_parameters = []
model_children_list输出结果如下所示:

可以看到,模型中有两个卷积层,均采用 3x3 尺寸的卷积核。第一个卷积层使用了 16 个卷积核,而第二个卷积层使用了 32 个。本节中重点关注可视化卷积层,因为卷积层的工作原理在视觉上更容易理解。但我们也可以用类似方法探索全连接层等其它层的权重分布。
(2) 接下来我们提取模型中的卷积层,并将它们存储在一个单独的列表中:
python
for i in range(len(model_children_list)):
if type(model_children_list[i]) == nn.Conv2d:
model_parameters.append(model_children_list[i].weight)
convolutional_layers.append(model_children_list[i])在此过程中,我们还保存了每个卷积层学习到的权重参数。
(3) 可视化卷积层学习到的卷积核。首先分析第一层的 16 个 3x3 卷积核,可视化这些卷积核:
python
plt.figure(figsize=(5, 4))
for i, flt in enumerate(model_parameters[0]):
plt.subplot(4, 4, i+1)
plt.imshow(flt[0, :, :].detach(), cmap='gray')
plt.axis('off')
plt.show()输出结果如下所示:
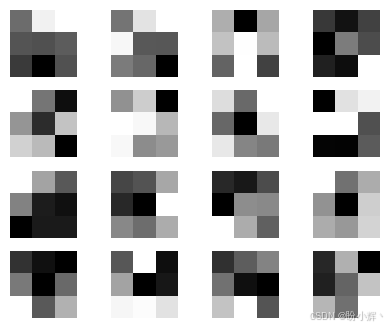
首先可以观察到,所有学习到的卷积核都呈现出差异化特征,这是一个良好的训练迹象。这些卷积核内部通常包含对比鲜明的数值分布,使其能够在图像卷积过程中提取不同类型的梯度特征。在模型推理时,这 16 个卷积核会独立作用于输入的灰度图像,生成 16 张不同的特征图,我们将在下一小节中对这些特征图进行可视化。
(4) 采用相同方法,我们可以可视化第二卷积层的 32 个卷积核。只需调整前一步代码中的层索引即可:
python
plt.figure(figsize=(5, 8))
for i, flt in enumerate(model_parameters[1]):
plt.subplot(8, 4, i+1)
plt.imshow(flt[0, :, :].detach(), cmap='gray')
plt.axis('off')
plt.show()输出结果如下所示:

通过可视化可以看到,第二卷积层的 32 个卷积核同样呈现出差异化特征分布,其内部数值对比鲜明,旨在从图像中提取多层次的梯度特征。这些卷积核作用于第一卷积层的输出特征图,因此能够生成更高级别的特征表示。
在典型的多层 CNN 架构中,深层卷积层的设计目标正是通过这种层级递进的特征提取,逐步构建能够表征复杂视觉元素的特征------例如人脸中的鼻子、道路上的交通灯等高级语义特征。接下来,我们将观察这些卷积核在给定输入上运算时产生的实际输出特征图。
4. 可视化特征图
在本节中,我们将通过一个手写数字样本图像,逐层展示各卷积层的输出特征。对于不同的层,我们期望输出能捕捉到图像的不同视觉特征,例如边缘、颜色、曲线和圆形等。
(1) 首先需要收集各卷积层的输出特征图:
python
per_layer_results = [convolutional_layers[0](sample_data)]
for i in range(1, len(convolutional_layers)):
per_layer_results.append(convolutional_layers[i](per_layer_results[-1]))需要注意,我们采用逐层前向传播的方式,确保第 n 个卷积层的输入严格来自第 (n-1) 个卷积层的输出特征图。这种级联处理方式保持了 CNN 层级特征传递的特性。
(2) 可视化两个卷积层生成的特征图。首先展示第一卷积层的输出:
python
plt.figure(figsize=(5, 4))
layer_visualisation = per_layer_results[0][0, :, :, :]
layer_visualisation = layer_visualisation.data
print(layer_visualisation.size())
for i, flt in enumerate(layer_visualisation):
plt.subplot(4, 4, i + 1)
plt.imshow(flt, cmap='gray')
plt.axis("off")
plt.show()输出结果如下所示:

数字 (16, 26, 26) 代表第一个卷积层的输出维度。样本图像的大小是 (28, 28),卷积核的大小是 (3, 3),由于没有使用填充。因此,最终的特征图大小是 (26, 26)。由 16 个卷积核产生了 16 个特征图,所以整体输出维度为 (16, 26, 26)。
如图所示,每个滤波器都从输入图像中提取出独特的特征图。此外,每个特征图代表图像中的不同视觉特征。例如,左上角的特征图呈现像素值反转效果,而右下角的特征图则代表边缘检测特征。
这 16 个特征图随后传递到第二个卷积层,在该层,32 个卷积核分别对这 16 个特征图进行卷积,生成 32 个新的特征图,接下来查看这些特征图。
(3) 通过调整上一步中代码的索引,可视化第二卷积层的 32 张特征图:
python
plt.figure(figsize=(5, 8))
layer_visualisation = per_layer_results[1][0, :, :, :]
layer_visualisation = layer_visualisation.data
print(layer_visualisation.size())
for i, flt in enumerate(layer_visualisation):
plt.subplot(8, 4, i + 1)
plt.imshow(flt, cmap='gray')
plt.axis("off")
plt.show()输出结果如下所示:

与之前 16 个特征图相比,这 32 个特征图明显呈现出更复杂的特征模式。它们不再局限于简单的边缘检测,这是因为其输入已是第一卷积层提取的抽象特征,而非原始像素图像。
在该模型架构中,两个卷积层之后连接着两个线性层,其参数规模分别为 (4608×64) 和 (64×10)。虽然线性层权重也具备可视化价值,但面对如此庞大的参数量(特别是 4608×64),仅通过视觉分析难以有效理解,因此我们将把本节的视觉分析限制在卷积层的权重上。
小结
在本节中,我们探讨了如何用 PyTorch 解释深度学习模型的决策机制。具体而言,我们重点分析了卷积神经网络模型卷积层的细节,以理解模型从手写数字图像中学到的视觉特征。我们将观察卷积滤波器/核 (convolutional filters/kernels) 及其生成的特征图 (feature maps)。这些细节有助于我们理解模型如何处理输入图像并做出预测。
系列链接
PyTorch实战(1)------深度学习(Deep Learning)
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络
PyTorch实战(8)------图像描述生成
PyTorch实战(9)------从零开始实现Transformer
PyTorch实战(10)------从零开始实现GPT模型
PyTorch实战(11)------随机连接神经网络(RandWireNN)
PyTorch实战(12)------图神经网络(Graph Neural Network,GNN)
PyTorch实战(13)------图卷积网络(Graph Convolutional Network,GCN)
PyTorch实战(14)------图注意力网络(Graph Attention Network,GAT)
PyTorch实战(15)------基于Transformer的文本生成技术
PyTorch实战(16)------基于LSTM实现音乐生成
PyTorch实战(17)------神经风格迁移
PyTorch实战(18)------自编码器(Autoencoder,AE)
PyTorch实战(19)------变分自编码器(Variational Autoencoder,VAE)
PyTorch实战(20)------生成对抗网络(Generative Adversarial Network,GAN)
PyTorch实战(21)------扩散模型(Diffusion Model)
PyTorch实战(22)------MuseGAN详解与实现
PyTorch实战(23)------基于Transformer生成音乐
PyTorch实战(24)------深度强化学习
PyTorch实战(25)------使用PyTorch构建DQN模型
PyTorch实战(26)------PyTorch分布式训练
PyTorch实战(27)------自动混合精度训练
PyTorch实战(28)------PyTorch深度学习模型部署
PyTorch实战(29)------使用TorchServe部署PyTorch模型
PyTorch实战(30)------使用TorchScript和ONNX导出通用PyTorch模型
PyTorch实战(31)------在Android上部署PyTorch模型
PyTorch实战(32)------在iOS上构建PyTorch应用
PyTorch实战(33)------使用fastai进行快速原型开发
PyTorch实战(34)------基于PyTorch Lightning的跨硬件模型训练
PyTorch实战(35)------使用PyTorch Profiler分析模型推理性能
PyTorch实战(36)------PyTorch自动机器学习
PyTorch实战(37)------使用Optuna搜索最优超参数