🔍 ElasticSearch 搜索相关性详解
(含评分机制 + 自定义策略 + 多字段优化)
搜索的核心价值在于精准匹配用户意图 ,而相关性(Relevance) 是衡量搜索质量的黄金标准。ElasticSearch(ES)通过科学的评分机制量化文档与查询的匹配程度,并支持灵活的自定义策略与多字段优化方案,全方位提升搜索体验。
本文系统拆解 ES 相关性原理、默认评分算法(BM25)、五大自定义评分策略及多字段搜索优化方法,配套思维导图建议,助力开发者快速掌握并落地相关性调优技巧。
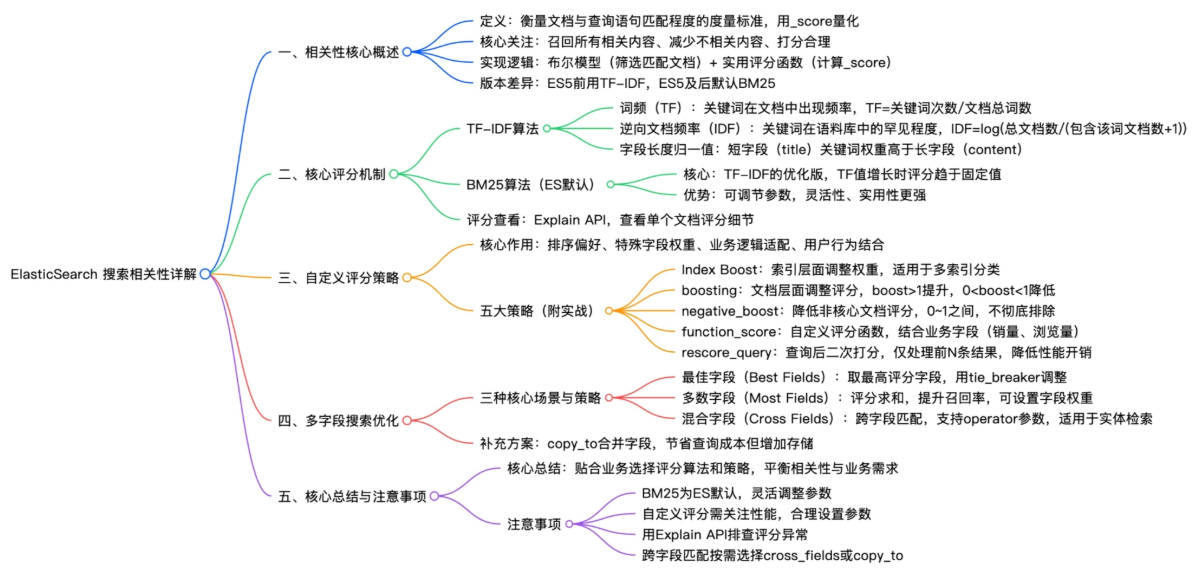
一、搜索相关性核心概述
1.1 什么是搜索相关性?
- 相关性 :描述文档与查询语句匹配程度的度量,由
_score字段体现。 - 评分越高 → 排名越靠前 → 越符合用户需求
💡 核心目标:
- 找全(Recall):不漏掉相关内容
- 找准(Precision):不过多返回无关内容
- 打分合理 :符合业务预期
✅ 示例:查询 "JAVA 多线程设计模式" → 同时包含三个关键词的文档(ID=2,3)应获得更高评分,优先展示。
1.2 相关性实现逻辑
ES 采用 "布尔模型 + 实用评分函数" 双阶段机制:
- 过滤阶段(Boolean Model:筛选出匹配查询条件的文档集合;
- 评分阶段(Scoring Function): 计算
_score并排序。
📌 评分函数演进:
- ES 5 之前:基于 TF-IDF
- ES 5+(默认):Okapi BM25 算法(更平滑、可调参、抗高频词干扰)
二、核心评分机制详解:TF-IDF vs BM25
2.1 TF-IDF(传统算法)
由三部分构成:
| 因子 | 说明 | 公式 |
|---|---|---|
| 词频(TF) | 词在文档中出现频率 | TF = 词出现次数 / 文档总词数 |
| 逆文档频率(IDF) | 词在整个语料库中的稀有程度 | IDF = log(总文档数 / (含该词文档数 + 1)) |
| 字段长度归一化(Norm) | 短字段中关键词权重更高 | 自动计算,索引时存储 |
⚠️ 缺陷:TF 越高,评分无限增长 → 容易被"堆词"文档操控
2.2 BM25(ES 默认算法)
BM25 是 TF-IDF 的现代优化版,核心改进:
- 引入 饱和函数:TF 增长到一定程度后,评分趋于平稳
- 支持 可调参数 (
k1,b):k1:控制词频对评分的影响强度(默认 1.2)b:控制字段长度归一化的力度(默认 0.75)
✅ 优势:更抗噪声、更贴合真实语义、更适合长尾分布数据
2.3 调试工具:Explain API
用于查看单个文档的评分细节,定位异常。
GET /test_score/_explain/2{"query":{"match":{"content":"elasticsearch"}}}返回结果包含:
- 每个 term 的 TF/IDF/norm 值
- 最终
_score计算过程
🛠️ 建议:所有相关性调优前,先用 Explain 分析基线行为
三、自定义评分策略(5 大核心方法)
💡 默认评分适用于通用场景,但业务场景千差万别,需自定义打分逻辑。
3.1 Index Boost:索引级权重
适用场景:跨多个索引搜索,需按业务分类设置优先级(如 A 类 > B 类 > C 类)
POST my_index_100*/_search{"indices_boost":[{"my_index_100a":1.5},{"my_index_100b":1.2},{"my_index_100c":1.0}]}✅ 效果:相同匹配下,A 类文档排名更高
3.2 Field Boost:字段级权重
适用场景:标题比正文更重要(如电商商品名、新闻标题)
{"query":{"bool":{"should":[{"match":{"title":{"query":"apple ipad","boost":4}}},{"match":{"content":{"query":"apple ipad","boost":1}}}]}}}🔑 关键:
boost > 1提升权重,0 < boost < 1降低权重
3.3 Negative Boost:降权非核心内容
适用场景 :不希望完全排除,但要降低排名(如排除"苹果派"但保留"苹果手机")
{"query":{"boosting":{"positive":{"match":{"content":"apple"}},"negative":{"match":{"content":"pie"}},"negative_boost":0.2}}}📌
negative_boost ∈ (0, 1)→ 匹配 negative 的文档评分 × 该值
3.4 Function Score:自定义评分函数(最强大)
适用场景:融合业务指标(销量、点击率、时效性等)
{"query":{"function_score":{"query":{"match_all":{}},"script_score":{"script":{"source":"_score * (doc['sales'].value + doc['visitors'].value)"}}}}}⚠️ 注意:
- 需开启
script.painless.inline_score: true- 性能开销大,慎用于高并发场景
3.5 Rescore Query:二次打分(精度优化)
适用场景 :对 Top-N 结果精细化重排,避免全量重算
{"rescore":{"query":{"rescore_query":{"match":{"title":"MySQL"}},"query_weight":0.7,"rescore_query_weight":1.2},"window_size":50}}✅ 优势:仅对前 50 条重打分,兼顾性能与精度
四、多字段搜索优化策略
实际业务常需在 title + body + author 等多字段中检索。ES 提供三种策略:
| 策略 | 逻辑 | 适用场景 |
|---|---|---|
| Best Fields | 取最高分字段为主 | 字段语义重叠(如博客标题/正文) |
| Most Fields | 累加所有匹配字段评分 | 提升召回率(如多分词器索引) |
| Cross Fields | 跨字段拼接匹配 | 实体检索(人名、地址、图书信息) |
4.1 Best Fields(最佳字段)
-
使用
dis_max或multi_match+type: best_fields -
通过
tie_breaker微调其他字段贡献(0~1){"query":{"multi_match":{"type":"best_fields","query":"Brown fox","fields":["title","body"],"tie_breaker":0.2}}}
✅ 效果:主匹配字段主导,次要匹配辅助
4.2 Most Fields(多数字段)
-
适用于同义扩展 或多分析器索引
-
常配合字段权重(
title^10){"mappings":{"properties":{"title":{"type":"text","analyzer":"english","fields":{"std":{"type":"text","analyzer":"standard"}}}}}}
{"query":{"multi_match":{"type":"most_fields","query":"barking dogs","fields":["title^10","title.std"]}}}
🎯 目标:提升召回率,覆盖更多变体表达
4.3 Cross Fields(混合字段)
-
将多个字段视为一个逻辑字段进行匹配
-
支持
operator: "and"强制所有词命中{"query":{"multi_match":{"type":"cross_fields","query":"湖南常德","operator":"and","fields":["province","city"]}}}
💡 替代方案:使用
copy_to合并字段(如full_address),但增加存储成本
五、总结与最佳实践
✅ 核心结论
| 维度 | 关键点 |
|---|---|
| 评分机制 | ES 默认使用BM25,优于 TF-IDF |
| 自定义评分 | 5 种策略覆盖 90% 业务场景:Index Boost→Field Boost→Negative Boost→Function Score→Rescore |
| 多字段搜索 | 按场景选型:竞争 →best_fields 召回 →most_fields 实体 →cross_fields |
| 调试手段 | 必用 Explain API 分析评分构成 |
⚠️ 注意事项
- BM25 参数可调 :通过
similarity自定义k1/b,但需充分测试; - Function Score 性能敏感:避免复杂脚本,考虑预计算业务分;
- Rescore Window Size:不宜过大(通常 50~200),否则失去性能优势;
- Copy_to vs Cross Fields :
copy_to:查询快,存储高,适合静态字段cross_fields:灵活,查询稍慢,适合动态组合
🧠 配套建议
绘制 ES 相关性优化思维导图,涵盖以下模块:
搜索相关性├── 评分机制(BM25 / TF-IDF)
├── 调试工具(Explain API)
├── 自定义策略(5种)
└── 多字段优化(3种模式 + 参数调优)📌 记住:没有"最好"的相关性,只有"最适合业务"的相关性。