文章目录
- 零、前置代码准备
- 一、编译器驱动程序(从文本到机器码)
- [二 、 可重定位目标文件](#二 、 可重定位目标文件)
- 三、符号和符号表
- 四、符号解析和静态库(编译时合并拷贝,运行时无独立依赖)
- 五、静态库解析
- 六、重定位
- 七、动态库(运行时共享引用,延迟绑定节省资源)
零、前置代码准备
cpp
// swap.cc
int global_init_var = 10;
int global_uninit_var;
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
cpp
// main.cc
extern int global_inint_var;
void swap(int *a, int *b);
int main()
{
int a = 10, b = 20;
swap(&a, &b);
return global_inint_var;
}一、编译器驱动程序(从文本到机器码)
在终端敲下的 g++ main.cc swap.cc -o app,这个 g++ 本质上不是一个单一的编译器,而是一个"驱动程序"(Driver)。它就像一个包工头,内部依次调用了四个独立的工具来完成工作:
-
预处理器 (cpp) :
g++ -E处理#开头的指令,纯文本替换:展开#include、宏替换、处理条件遍历、删除注释,注意:模板实例化不在预处理阶段 -
编译器 (cc1plus) :
g++ -S,将 C++ 翻译成汇编语言,.i文件翻译成.s文件,经理词法分析(拆分成token流)、语法分析(构建AST抽象语法树)、语义分析(类型检查),并给予AST进行常量折叠、内联等优化。注意:模板实例化在这个阶段 -
汇编器 (as) :
g++ -c,将汇编语言翻译成机器码,二进制文件.o -
链接器 (ld):将多个机器码文件打包成可执行文件。
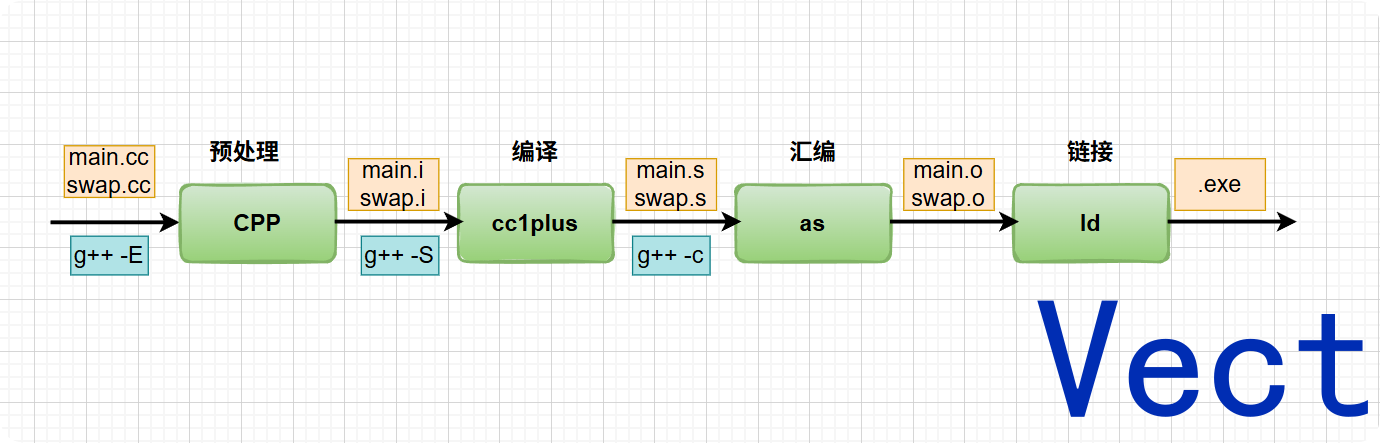
可以加-v参数来看具体动作:g++ -v main.cc swap.cc -o app
区分编译错误和链接错误:
- 编译错误:语法错误(少写分号、类型不匹配等)
- 链接错误:语法没问题,在最后打包时,找不到某个函数的具体实现
这样设计是为了解耦和复用 ,汇编器as和链接器ld可以为各种语言服务
二 、 可重定位目标文件
用g++ -c swap.cc -o swap.o生成了目标文件,是什么东西?
swap.o是一个可重定位目标文件 ,在Linux下,它的底层格式是ELF(Executable and Linkable Format)
可重定位的意思是:这个文件里面的代码和数据,还没有被分配到最终的内存绝对地址。所有的地址都是从0开始的相对偏移量
ELF文件像一个抽屉柜,把不同的数据放在不同的段(Section)
.text代码段:机器指令(swap函数的代码).data:已初始化 的全局变量和静态变量(比如global_init_var).rodata只读数据段:只读数据(比如printf里的字符串常量).bss:未初始化 (或初始化为0)的全局变量和静态变量(比如global_uninit_var)
注意:怎么区分.bss和.data?
.bss是better save space,所以.bss是占位
注意:局部变量存在哪里?栈帧中
使用readelf -h swap.o命令(-h只显示头部信息)就可以查看ELF Header的结构,ELF Header位于ELF文件的第0字节处 ,操作系统拿到文件的第一件事,就是直接读取前64字节(64位)的ELF头
bash
vect@VM-0-11-ubuntu:~/CppRepo/Link$ readelf -h swap.o
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 584 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 12
Section header string table index: 11- Magic魔数:确认文件类型,前16字节
7F 45 4C 46,ASCII码就是\x7f E L F,明确是ELF文件 - Machine机器类型:标明具体的机器:我这台是x86-64的
- Type文件类型:REL可重定位,DYN共享目标文件,EXEC可执行程序
- Entry point入口地址:程序运行的第一条指令的虚拟内存地址(
.o这里还没分配)
ELF头是链接器和装载器的工作起点,每次只用先读64字节,就能完成平台校验、架构校验、提取入口地址,不符合条件就直接踢掉,十分高效
使用readelf -S swap.o命令(-S打印整个表的信息)就可以查看swap.o的内部结构
bash
vect@VM-0-11-ubuntu:~/CppRepo/Link$ readelf -S swap.o
There are 12 section headers, starting at offset 0x248:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040
0000000000000031 0000000000000000 AX 0 0 1
[ 2] .data PROGBITS 0000000000000000 00000074
0000000000000004 0000000000000000 WA 0 0 4
[ 3] .bss NOBITS 0000000000000000 00000078
0000000000000004 0000000000000000 WA 0 0 4
[ 4] .comment PROGBITS 0000000000000000 00000078
000000000000002c 0000000000000001 MS 0 0 1
[ 5] .note.GNU-stack PROGBITS 0000000000000000 000000a4
0000000000000000 0000000000000000 0 0 1
[ 6] .note.gnu.pr[...] NOTE 0000000000000000 000000a8
0000000000000020 0000000000000000 A 0 0 8
[ 7] .eh_frame PROGBITS 0000000000000000 000000c8
0000000000000038 0000000000000000 A 0 0 8
[ 8] .rela.eh_frame RELA 0000000000000000 000001c8
0000000000000018 0000000000000018 I 9 7 8
[ 9] .symtab SYMTAB 0000000000000000 00000100
0000000000000090 0000000000000018 10 3 8
[10] .strtab STRTAB 0000000000000000 00000190
0000000000000037 0000000000000000 0 0 1
[11] .shstrtab STRTAB 0000000000000000 000001e0
0000000000000067 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
D (mbind), l (large), p (processor specific)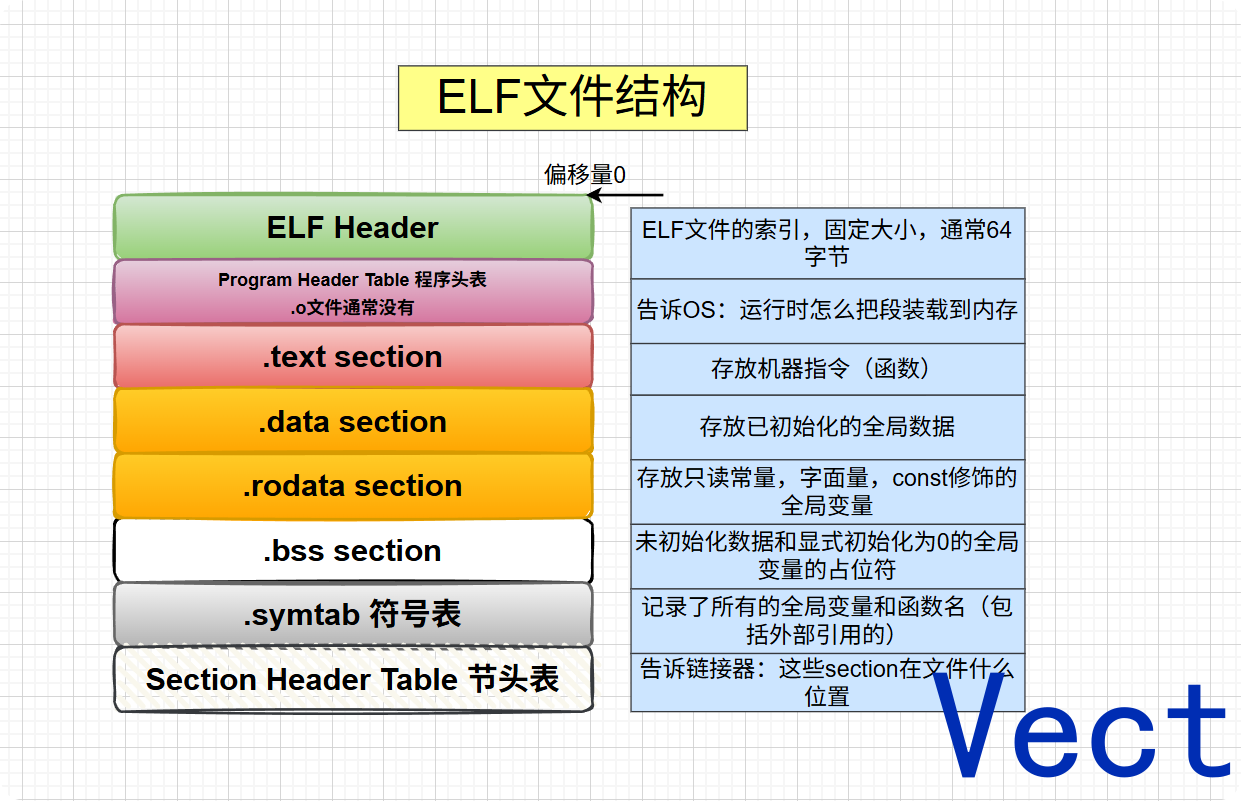
为什么要把机器码和数据分开存放呢?
- 保证数据安全:代码段只读防止篡改,数据段可读可写
- 提高缓存命中率:CPU有独立的数据缓存和指令缓存,分开可以提高CPU缓存命中率
- 节省内存:运行同一个程序的多个副本(比如开了多个终端),在内存中共享同一份
.text代码段,只需要为每个进程拷贝独立的数据段就行
根据上面的理由,就可以回答这个问题:如果我把 global_uninit_var 定义为一个非常大的数组 int global_uninit_var[1000000];,它会占用编译出来的 swap.o 文件的磁盘空间吗?为什么 Linux 底层要单独设计一个 .bss 段,而不是把所有全局变量都塞进 .data 段?
如果定义
int global_uninit_var[1000000];,它在编译出来的.o文件和可执行文件中,几乎不占用任何磁盘空间!.bss(Block Started by Symbol)段在 ELF 文件中只是一个"占位符" 。它只在 ELF 头部记录了这个变量需要多少字节,而不会在磁盘上真存 1000000 个 0。直到程序运行、OS 装载时,才会真正在虚拟内存中分配这块空间并清零
三、符号和符号表
在链接器(ld)眼里只有符号(Symbol)
-
什么是符号? 全局变量名、函数名的统一抽象
注意:局部变量不是符号,存在栈上管理,链接器看不到
-
什么是符号表? 编译器在生成
.o文件时,会在ELF中检疫章表,记录定义了哪些符号(我有啥?)和引用了哪些外部符号(我缺啥?)
使用readelf -s产看符号表:
bash
vect@VM-0-11-ubuntu:~/CppRepo/Link$ readelf -s main.o
Symbol table '.symtab' contains 7 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS main.cc
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1 .text
3: 0000000000000000 88 FUNC GLOBAL DEFAULT 1 main
4: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND _Z4swapPiS_
5: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND global_init_var
6: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND __stack_chk_fail符号根据出现在文件什么位置分为三类:
- 全局符号: 我定义的,别人也能用
- 外部符号: 我用到的,定义在别人那里
- 局部符号: 带
static属性的C函数和全局变量,注意:这和函数里的局部变量不一样!函数里的局部变量在栈上,链接器看不到!
符号根据是否初始化分为两类:
- 强符号: 已初始化的全局变量和函数定义
- 弱符号: 未初始化的全局变量
而链接器有三大霸王条款:
- 一山不容二虎: 不允许有多个同名强符号同时存在 ,否则报错
multiple definition- 恃强凌弱: 一个强符号遇到一个or多个弱符号,链接器无视弱符号 ,所有对该符号的引用全部指向强符号的地址
- 摆烂人格: 如果全是弱符号,链接器随机挑选一个作为最终地址
看个案例:
cpp
// weak.cc
__attribute__((weak)) double x; // 弱符号
void assign() { x = 3.14159; } // 以为操作的是weak.cc里的double
cpp
// strong_weak_singal.cc
#include <iostream>
// 定义两个强符号,在.data中连续存放
int x = 10;
int y = 20;
extern void assign(); // 外部函数
int main()
{
std::cout << "==== 前:x = " << x << ", y = " << y << std::endl;
assign();
std::cout << "==== 后:x = " << x << ", y = " << y << std::endl;
return 0;
}运行 g++ strong_weak_singal.cc weak.cc -o singal:
txt
vect@VM-0-11-ubuntu:~/CppRepo/Link$ ./singal
==== 前:x = 10, y = 20
==== 后:x = -266631570, y = 1074340345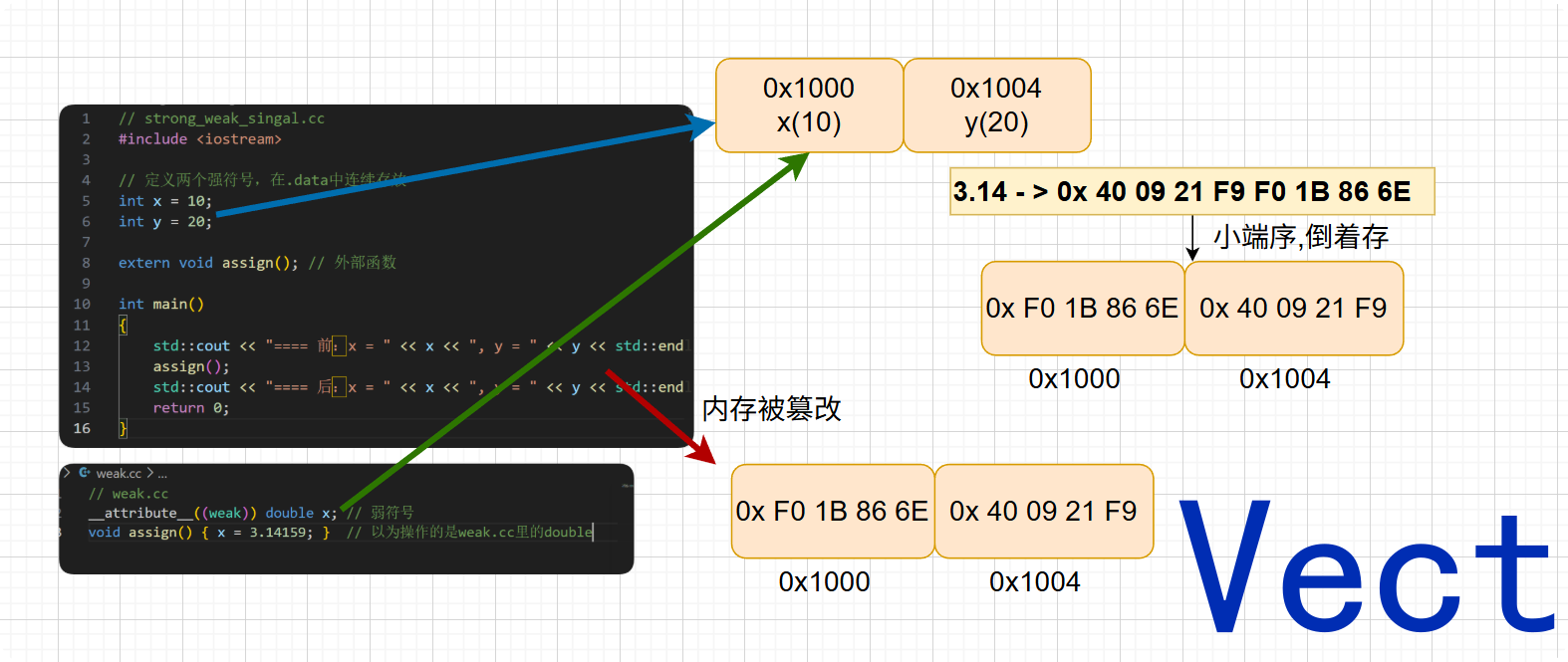
double x是弱符号,没开空间,int x是强符号,已经开好了4字节空间,并且链接器指向了强符号x的地址空间,而函数操作和强符号同名的弱符号x,直接操作int x这块地址了,造成了底层二进制数据错乱,还把int y的4字节空间也给占了
使用nm swap.o main.o可以看到:
txt
vect@VM-0-11-ubuntu:~/CppRepo/Link$ nm swap.o main.o
swap.o:
0000000000000000 D global_init_var
0000000000000000 B global_uninit_var
0000000000000000 T _Z4swapPiS_
main.o:
U global_init_var
0000000000000000 T main
U __stack_chk_fail
U _Z4swapPiS_U:未定义
D:已定义在数据段
T:已定义在代码段
为了支持函数重载,C++编译器会把参数类型编码进符号名,如果在C++中调用C编写的库,必须加上extern "C",否则会出未定义的错误
四、符号解析和静态库(编译时合并拷贝,运行时无独立依赖)
符号解析
链接器拿着所有的.o文件的符号表,把每个标记为U(我需要的)的符号,精确匹配到一个且仅有一个标记为T或D(我提供的)的全局符号。如果还有U匹配不到,报错undefined reference,如果找到两个强符号,报错multiple definition
如果在main.cc里调用了 printf、malloc、strlen,要怎么链接?
静态库的制作和使用
不可能是g++ main.o /usr/lib/printf.o /usr/lib/malloc.o /usr/lib/strlen.o ... -o app太费时间了所以有了静态库:一个包含了一大堆.o文件的压缩包,Linux里后缀为.a,并且在包的开头建一张全局符号索引表,方便链接器快速查找
手动建一个静态库:
cpp
// add.cc
int add(int a, int b) { return a + b; }
// sub.cc
int sub(int a, int b) { return a - b; }
// main.cc
extern int add(int a, int b);
int main() {
int res = add(10, 5); // 只有 add,没用到 sub
return 0;
}-
编译出可重定位目标文件
bashvect@VM-0-11-ubuntu:~/CppRepo/Link/static$ g++ -c add.cc -o add.o && g++ -c sub.cc -o sub.o && g++ -c main.cc -o main.o -
打包静态库
bashvect@VM-0-11-ubuntu:~/CppRepo/Link/static$ ar rcs libmatc.a add.o sub.or代表插入文件,c代表创建库,s代表生成符号索引表 -
查看压缩文件内容
bashvect@VM-0-11-ubuntu:~/CppRepo/Link/static$ ar -t libmatc.a add.o sub.o怎么看依赖关系?
nm -s:bashvect@VM-0-11-ubuntu:~/CppRepo/Link/static$ nm -s libmatc.a Archive index: _Z3addii in add.o _Z3subii in sub.o add.o: 0000000000000000 T _Z3addii sub.o: 0000000000000000 T _Z3subii静态库设计的意义:
空间复用和按需提取
如果
main.o只产生了一个U add,没用到sub,链接器拿着main.o去libmath.a库里找的时候,只会找满足需求的add.o,拷贝到最终的可执行程序中!
五、静态库解析
在命令行敲下:g++ main.cc libmath.a libadvanced.a -o app时,链接器划分三个集合,按照从左向右的顺序扫描:
- **集合E(Executable):**最终要合并进可执行文件里的
.o文件集合 - 集合U(Unresolved): 遇到的,还没有找到定义的未解析符号
- 集合D(Defined): 当前已经扫描到并提取出来的已定义符号
所以明确规定:调用方必须写在依赖库的左边!
那么就有个问题:
假设我不仅有一个 libmath.a,我还有一个别人写的 libadvanced.a,这两个静态库里都包含 了一个名叫 math_add.o 的文件,里面都提供了一个强符号 int add(int, int)。 如果我的 main.cc 里面调用了 add(1, 2),并且我用这样的命令去编译: g++ main.cc libmath.a libadvanced.a -o app
- 不会报重定义的错误,从左向右扫描,找到依赖之后,后面的就无需查抄了
- 最终
app里用到的是libmath.a库里的add
六、重定位
当链接器把所有的.o文件合并到一起,放到集合E中后,还会有两步操作:
section合并
由于每个.o文件都是从地址0x0开始的,链接器不能把他们直接堆在一起,否则地址全部冲突了
-
合并同类: 链接器把所有
.o文件的.text的合并,同时对.data和.bss执行相同的操作(如果有重复的就只合并一个,剩下的丢弃)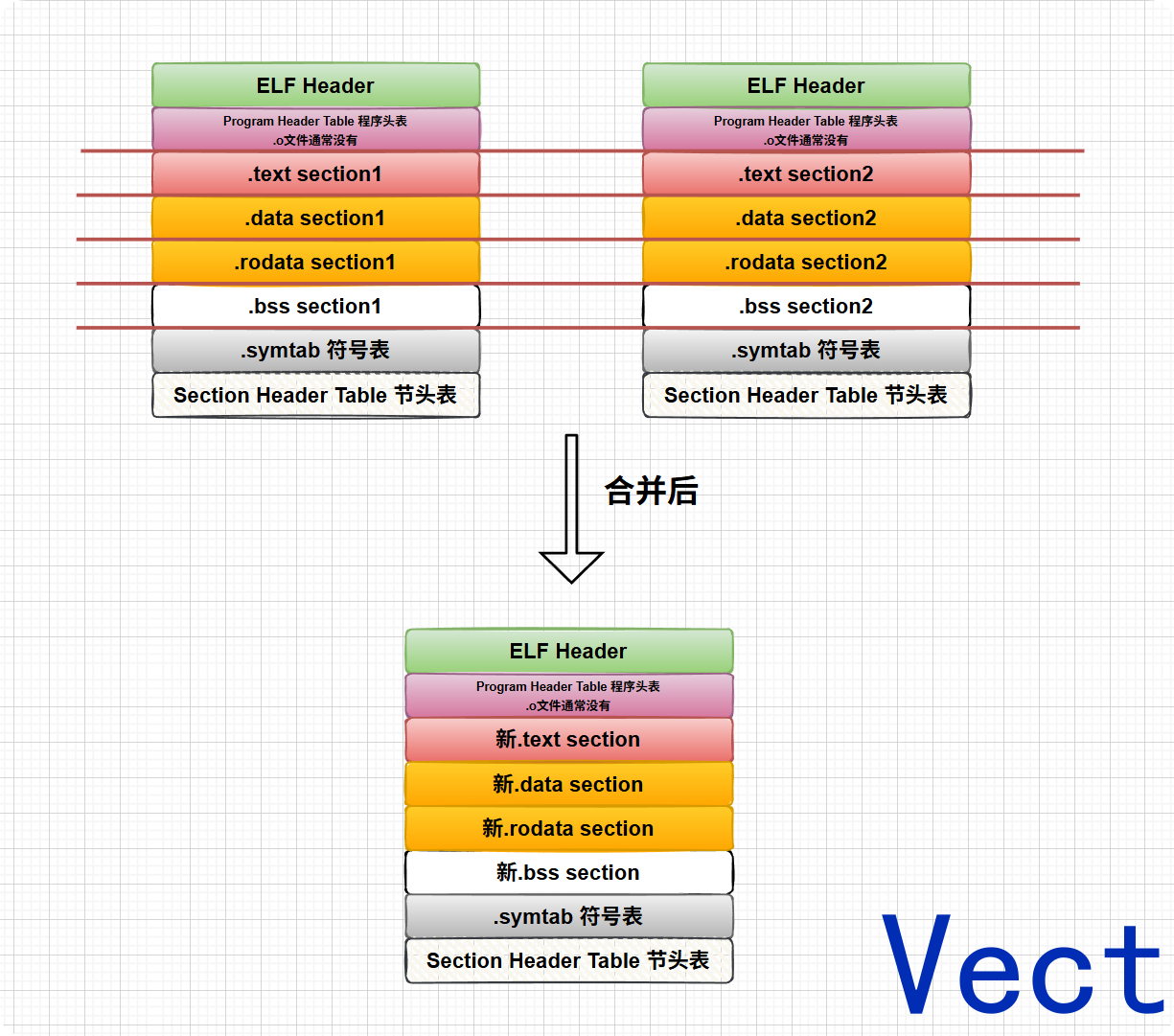
-
分配绝对地址: 合并完成后,链接器根据OS的规则(程序通常从
0x 40 00 00开始 ),分配最终的虚拟内存地址 -
符号地址落定: section的基地址确定,section里的每个函数、每个全局变量的最终绝对地址也就能被计算出来
符号解析和指令重定位
修改section里的旧地址,链接器查阅rel.text(记录.text里有哪些指令的地址需要被修改)和.rel.data(记录.data里有哪些指针的地址需要被修改)这两张表
- 表里有三个核心信息:
- Offset偏移量: 具体在哪个字节的位置
- Symbol符号: 这个位置需要填入哪个符号的真实地址
- Type(重定位类型): 怎么计算这个地址?
- 开始具体步骤:
- 遍历重定位表,获取需要修改的字节偏移位置、目标符号和重定位规则
- 取真地址:去符号表中查出目标符号被分配的虚拟内存地址
- 覆盖:根据规则运算,把算出来的真实地址覆盖掉原来的占位地址
利用readelf -r查看重定位表:
bash
vect@VM-0-11-ubuntu:~/CppRepo/Link/static$ readelf -r main.o
Relocation section '.rela.text' at offset 0x180 contains 1 entry:
Offset Info Type Sym. Value Sym. Name + Addend
000000000017 000400000004 R_X86_64_PLT32 0000000000000000 _Z3addii - 4
Relocation section '.rela.eh_frame' at offset 0x198 contains 1 entry:
Offset Info Type Sym. Value Sym. Name + Addend
000000000020 000200000002 R_X86_64_PC32 0000000000000000 .text + 0还可以利用反汇编objump -d看机器码:
bash
vect@VM-0-11-ubuntu:~/CppRepo/Link/static$ objdump -d main.o
main.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 48 83 ec 10 sub $0x10,%rsp
c: be 03 00 00 00 mov $0x3,%esi
11: bf 02 00 00 00 mov $0x2,%edi
16: e8 00 00 00 00 call 1b <main+0x1b>
1b: 89 45 fc mov %eax,-0x4(%rbp)
1e: b8 00 00 00 00 mov $0x0,%eax
23: c9 leave
24: c3 ret只需要关注第十六行:16: e8 00 00 00 00 call 1b <main+0x1b>
e8是x86架构CPU规定的机器码,意思是调用函数
00 00 00 00:编译器留下的假地址,占位
七、动态库(运行时共享引用,延迟绑定节省资源)
动态库原理
相对于静态库的拷贝代码到可执行文件,对于内存是一种负担
而动态库是物理内存共享的
在操作系统底层,无论开了多少个C++程序,动态库在物理内存条上永远只有一份.text的拷贝
- 如果程序A装载了动态库,并在代码段里填上了程序A的地址
- 那共享同一块内存的程序B怎么办?程序B读到A的地址,一运行跳到A就乱了!
所以,动态库的代码段绝对不能修改(不能包含绝对地址)
那么动态库如何调用?怎么找地址?
任何问题都可以通过加一个中间层解决
动态库链接引入两个表:
GOT(全局偏移表,Global Offset Table)---->数据段里存地址的格子
这张表在数据段
.data里,数据段是每个进程私有的、可读可写的,GOT本质是一个存放外部函数绝对地址的指针数组。PLT(过程链接表,Procedure Linkage Table)--->代码中转站
这张表在代码段
.text,是一堆"跳板指令",只读的、共享的
延迟绑定机制:不到代码真正执行的那一刻,绝不去寻找函数真实的地址
假设在一个for循环里,连续两次调用动态库里的add()函数
- 第一次调用:开荒
- 中转查表: 代码跳到PLT,PLT去GOT找地址
- 发现假地址: 此时GOT里存的是假地址,指向链接器
- 查找地址: 唤醒底层的动态链接器 ,寻找
add的地址 - 回填真地址: 动态链接器找到
add的真实地址后,把真实地址覆盖掉原理在GOT里的假地址 ,执行add
- 第二次调用: O ( 1 ) O(1) O(1)速查
- 中转查表: 代码跳到PLT,PLT去GOT找地址
- 跳转执行: 此时GOT里的地址是真实的地址 ,直接跳转到
add执行
动态库制作和使用
创建动态库本质上就是告诉编译器两件事:
-
生成的机器码必须是"位置无关"的(不准包含绝对地址)。
-
不要把它打包成普通的执行文件或静态归档,而是封装成遵循 ELF 规范的共享对象(Shared Object,后缀为
.so)
准备三个简单文件:
cpp
// add.h
int add(int a, int b);
// add.cc
#include "add.h"
int add(int a, int b) { return a + b; }
// main.cc
#include <iostream>
#include "add.h"
int main() {
std::cout << "10 + 20 = " << add(10, 20) << std::endl;
return 0;
}-
创建动态库
.sobashg++ -fPIC -shared add.cc -o libadd.so-fPIC(Position Independent Code):告诉编译器,生成位置无关代码-shared:告诉链接器,我要生成的是动态共享库,不是可执行文件
-
链接动态库
bashg++ main.cc -L. -ladd -o app-L.:告诉链接器,"请在当前目录 (.)下寻找我要依赖的库"。(默认只找/usr/lib等系统目录)-ladd:告诉链接器要链接的库名。注意 Linux 的潜规则:砍掉前缀lib和后缀.so,libadd.so写成add即可
-
🔥运行报错
bashvect@VM-0-11-ubuntu:~/CppRepo/Link/dyna$ ./app ./app: error while loading shared libraries: libadd.so: cannot open shared object file: No such file or directory刚才用
-L.只是告诉了**编译期的链接器(ld)去哪里找库。但是!当程序真正跑起来的时候,接管它的是**运行期的动态装载器(ld-linux.so)!**装载器极其死板,它默认只会去系统的/lib和/usr/lib目录下找.so文件,根本不知道libadd.so还在当前的测试文件夹里三种解决方案:
-
环境变量法:临时告诉装载器增加一个查找路径
bashvect@VM-0-11-ubuntu:~/CppRepo/Link/dyna$ export LD_LIBRARY_PATH=$(pwd):$LD_LIBRARY_PATH vect@VM-0-11-ubuntu:~/CppRepo/Link/dyna$ ./app 10 + 20 = 30 -
硬编码:在编译
app时,把库的路径刻在ELF文件头里bashvect@VM-0-11-ubuntu:~/CppRepo/Link/dyna$ g++ main.cc -L. -ladd -Wl,-rpath=. -o app vect@VM-0-11-ubuntu:~/CppRepo/Link/dyna$ ./app 10 + 20 = 30 -
系统配置:把
.so拷贝到/usr/lib路径下bashvect@VM-0-11-ubuntu:~/CppRepo/Link/dyna$ sudo cp libadd.so /usr/lib/ && sudo ldconfig # 第二个是刷新缓存 [sudo] password for vect: vect@VM-0-11-ubuntu:~/CppRepo/Link/dyna$ ./app 10 + 20 = 30
-