链接:【机器学习大模型-多模态】原理及实操串讲,最好的多模态大模型教程来了,1小时讲透多模态大模型,看完全面理解!机器学习-计算机视觉-人工智能_哔哩哔哩_bilibili
1、clip
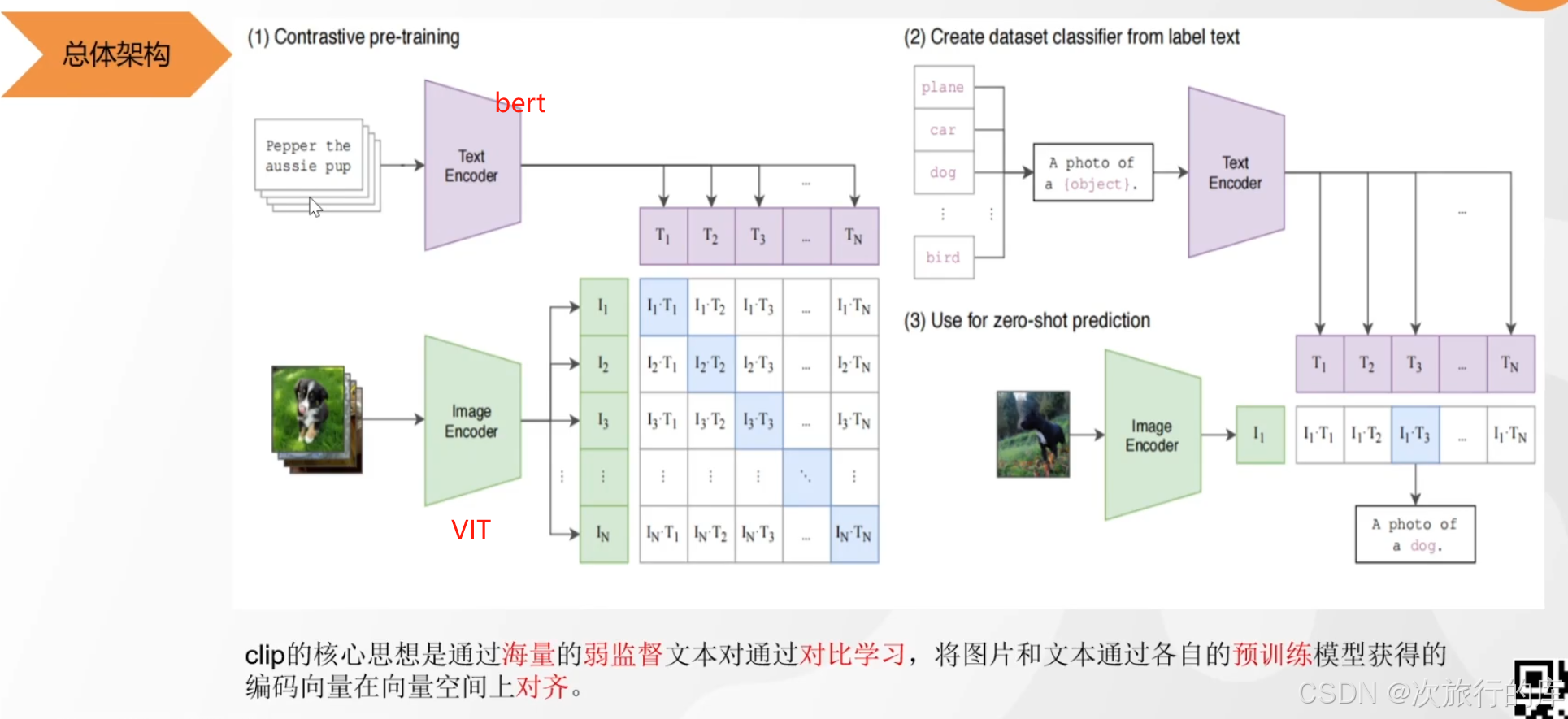
1、原始数据网页爬取来的,有噪声,没有进行处理,是弱对齐
2、只有对角线是对齐的,是正样本,其余为负样本。
2、blip
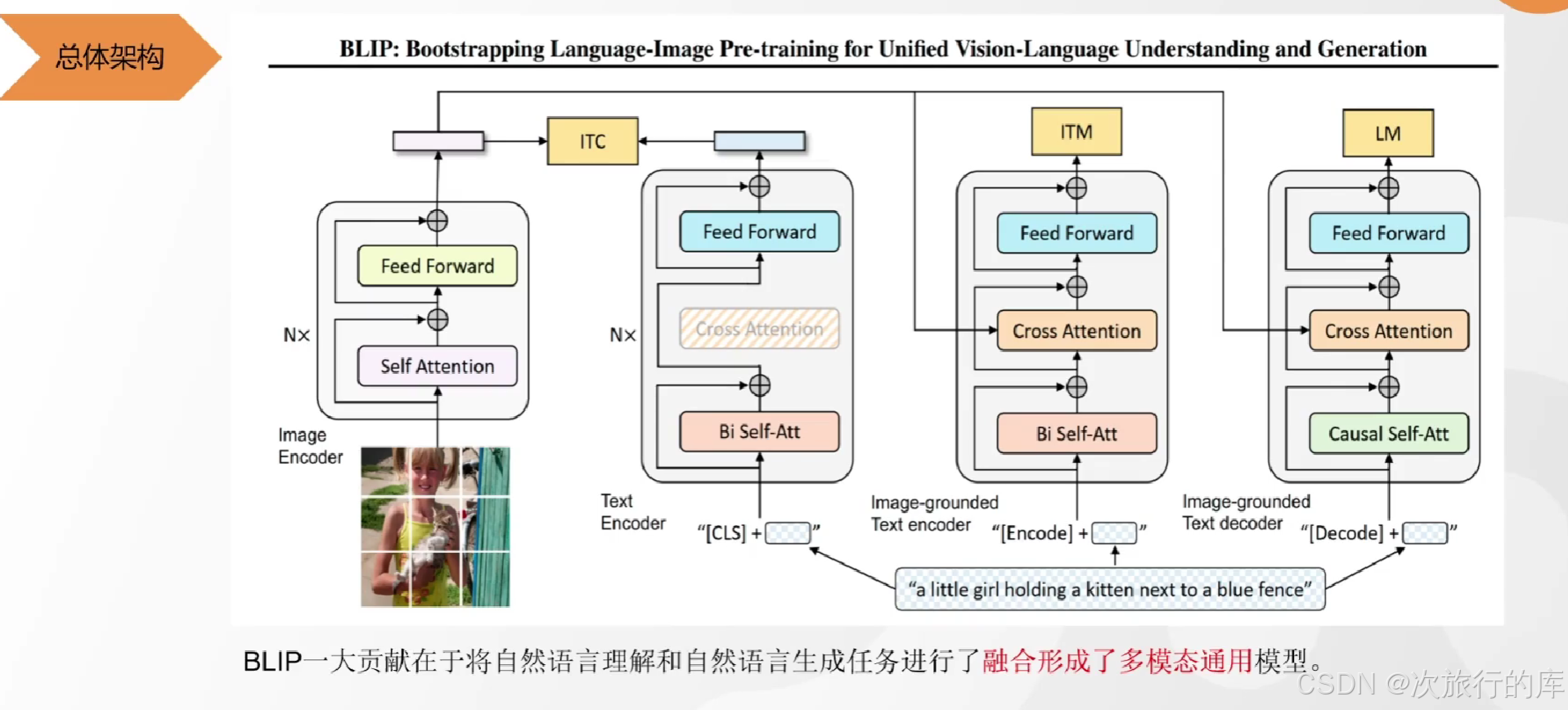
1、相对于clip,增加了自然语言生成能力。
2、先给图片分块编码器得到包含图片特征的向量
3、三塔模型。结构相似的模型跑了三次,颜色相同的模块共享参数。
4、cross attention?
5、ITC(对比学习)
6、ITM(二分类任务)最重要的是构建负样本,如果负样本太过于简单,比如图是小女孩,文字描述是一个动物,那么对于模型来说太过于简单,它能力得不到提高。那么解决办法有,把分类错误的样本整理为负样本,因为分错了说明是比较难的。
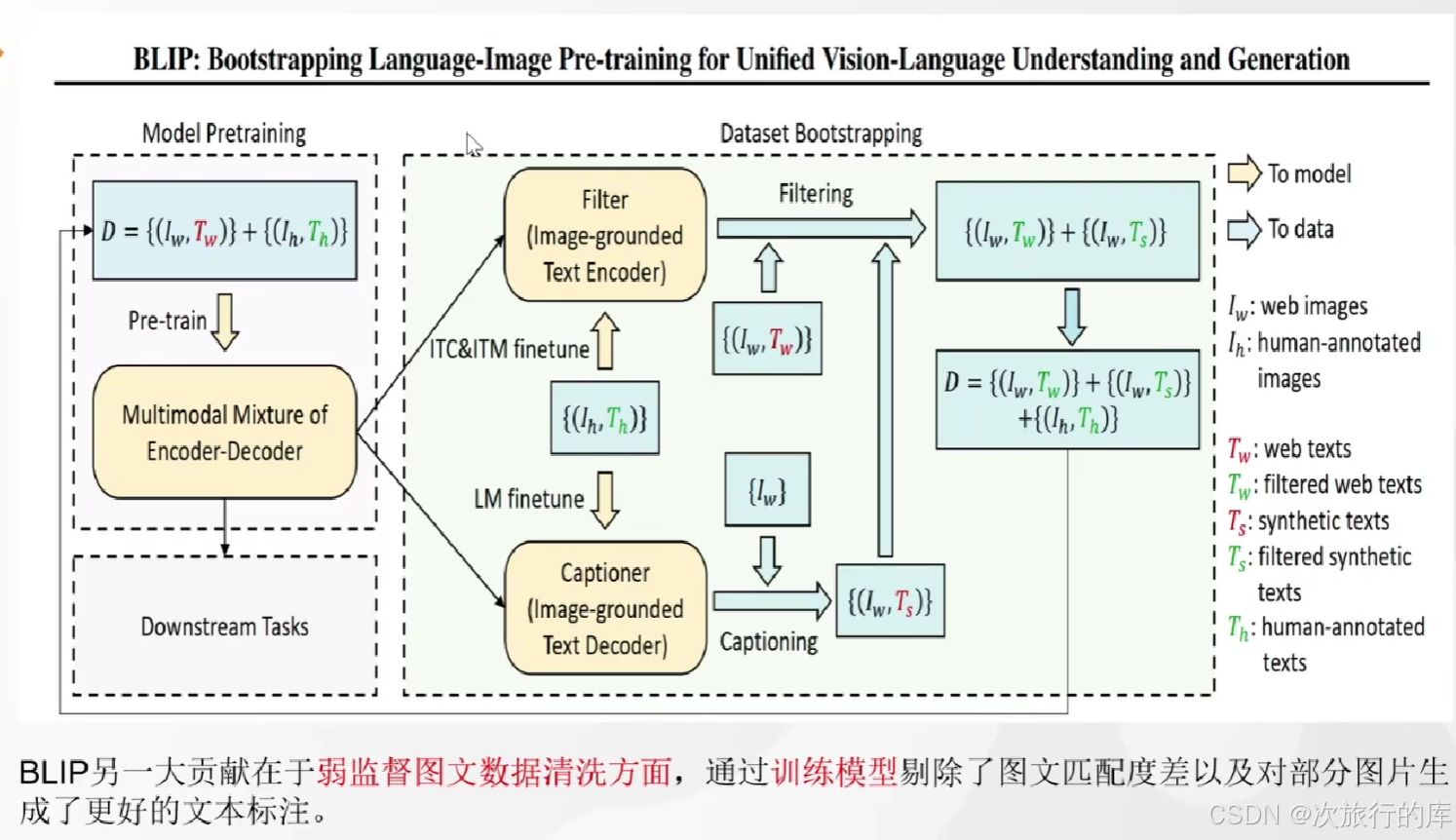
下图是bootstrap对于弱监督数据的一个清洗。
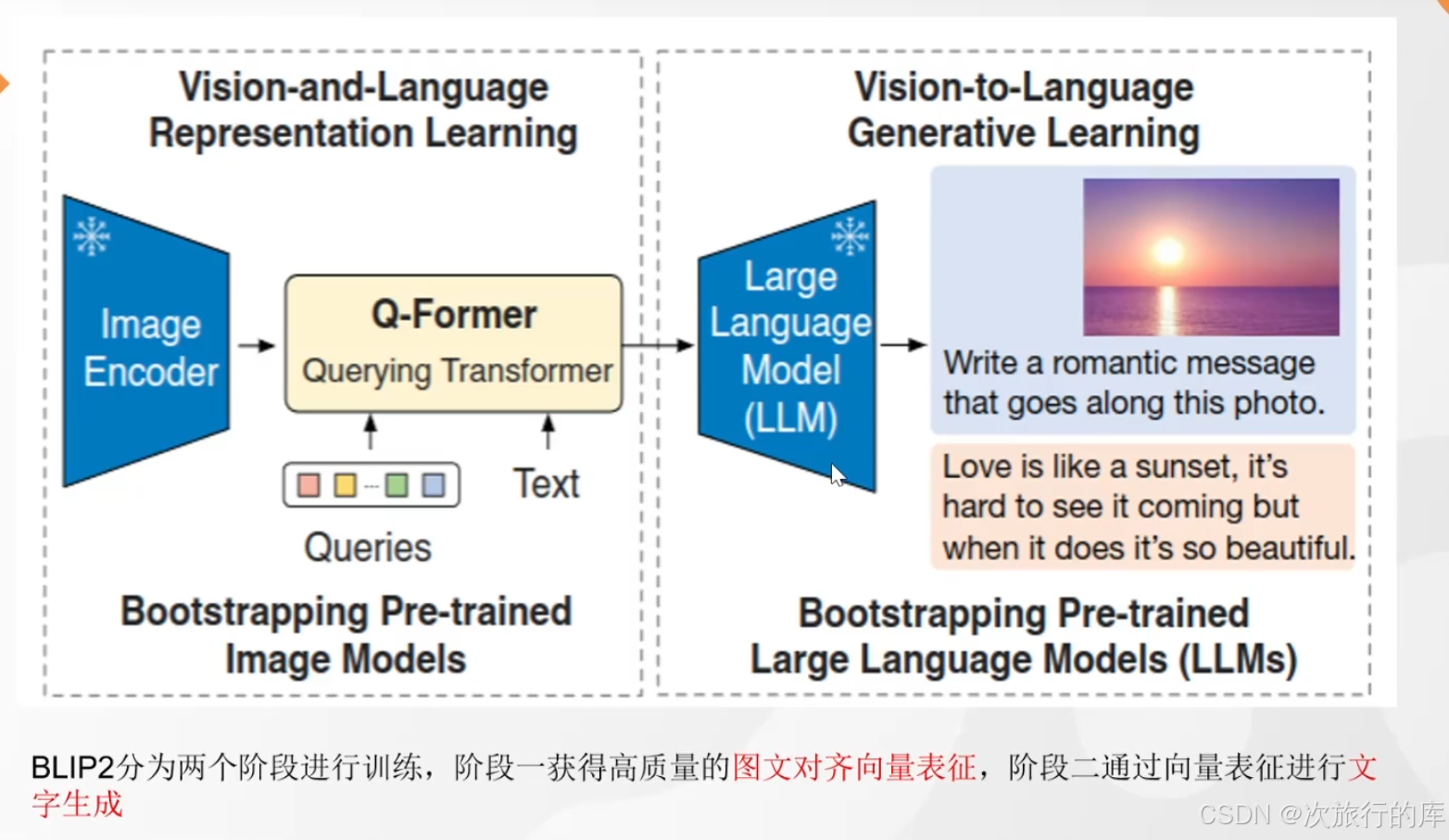
3、blip2
4、visualglm支持图像、中英文的多模态对话模型解读与本地化部署
5、VideoGLaMM
mbzuai-oryx/VideoGLaMM: A Large Multimodal Model for Pixel-Level Visual Grounding in Videos
VideoGLaMM 是一种大型视频多模态视频模型,能够实现像素级视觉接地。该模型响应来自用户的自然语言查询,并在其生成的文本响应中交织时空对象掩码,以提供对视频内容的详细理解。VideoGLaMM 无缝连接三个关键组件:大型语言模型 (LLM);双视觉编码器;以及时空像素解码器。双视觉编码器分别提取空间和时间特征,这些特征共同传递给 LLM 以输出富含空间和时间线索的响应。这可以通过对我们提出的基准接地对话生成 (GCG) 数据集进行端到端训练来实现,该数据集具有 38k 视频 QA 三元组、87k 对象和 671k 细粒度掩码。