目录
1、说说什么是Redis
Redis(Remote Dictionary Server) 是一个使用 C 语言编写的,开源的(BSD许可)高性能非关系型 (NoSQL)的键值对数据库。它主要的特点是把数据放在内存当中,相比直接访问磁盘的关系型数据库,读写速度会快很多,基本上能达到微秒级的响应。
2、Redis有哪些数据类型?
Redis 支持五种基本数据类型,分别是字符串(String)、列表(List)、哈希(HASH)、集合(SET)和有序集合(ZSET)。
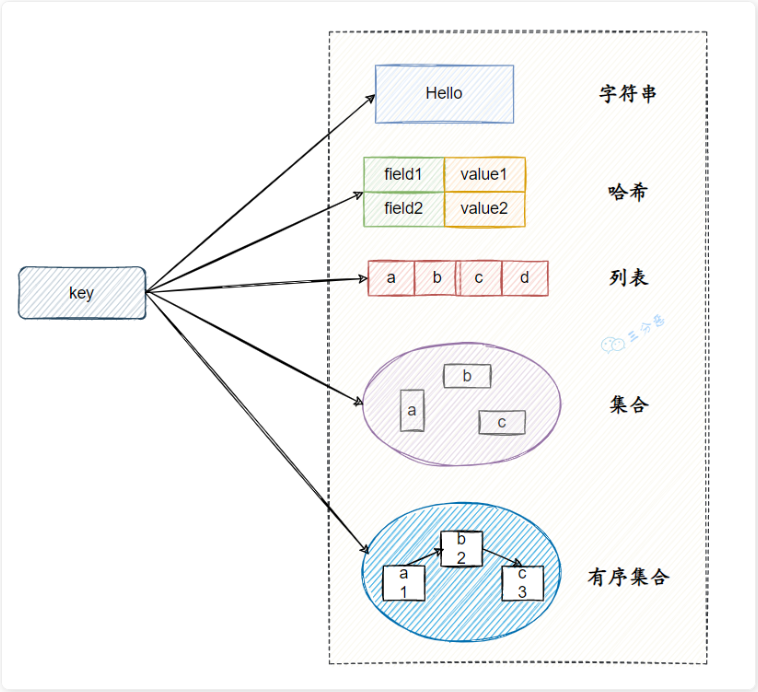
另外,还有三种扩展数据类型,分别是用于位级操作的 Bitmap、用于基数估算的 HyperLogLog、支持存储和查询地理坐标的 GEO。
3、Redis使用场景
缓存: 将热点数据放到内存中,设置内存的大使用量以及淘汰策略来保证缓存的命中率。比如保存token。使用缓存功能时,需要注意经典的缓存系统设计问题(穿透、击穿、雪崩),另一类是与业务逻辑紧密相关的业务缓存问题(数据一致性、缓存粒度等)。以及持久化、数据过期策略、淘汰策略等。
分布式锁:使用 Redis 自带的 SETNX 命令或者 Redisson 实现分布式锁,除此之外,还可以使用官方提供的 RedLock 分布式锁实现。确保同一时间只有一个节点可以持有锁;为了防止出现死锁,可以给锁设置一个超时时间,到期后自动释放;并且最好开启一个监听线程,当任务尚未完成时给锁自动续期。
**计数器:**使用 Redis 的原子操作(如 INCR 和 DECR)可以对 String 进行自增自减运算,从而实现计数器功能。Redis 这种内存型数 据库的读写性能非常高,很适合存储频繁读写的计数量。
消息队列(发布/订阅功能):List 是一个双向链表,可以通过 lpush 和 rpop 写入和读取消息,不过最好使用Kafka、RabbitMQ等消息中间件。
**延迟队列:**通过 Redis 的 ZADD 和 ZRANGEBYSCORE 命令可以实现基于时间的任务调度,例如延迟消息发送、定时任务等。
4、Redis有哪些持久化方式?
主要有两种,RDB 和 AOF。RDB 通过创建时间点快照来实现持久化,AOF 通过记录每个写操作命令来实现持久化。
RDB 持久化机制可以在指定的时间间隔内将 Redis 某一时刻的数据保存到磁盘上的 RDB 文件中,当 Redis 重启时,可以通过加载这个 RDB 文件来恢复数据。
AOF 通过记录每个写操作命令,并将其追加到 AOF 文件来实现持久化,Redis 服务器宕机后可以通过重新执行这些命令来恢复数据。
5、说说缓存穿透、缓存击穿、缓存雪崩
缓存穿透 :查询的数据在缓存和数据库中都不存在,就会导致每次请求都查数据库,造成数据库短时间内承受大量请求而崩掉。
解决方案:
1、缓存空数据,查询返回的数据为空,仍把这个空结果进行缓存。{key:1, value:null}
2、使用布隆过滤器:在查询缓存前,先用布隆过滤器判断数据是否存在,若判定不存在则直接拦截请求。
**缓存击穿:**是指某个热点数据缓存过期时,大量请求就会穿透缓存直接访问数据库,导致数据库瞬间承受的压力巨大。缓存击穿是指缓存中没有但数据库中有的数据。
解决方案:
1、加互斥锁:当缓存失效时,只允许一个线程去查询数据库并回写缓存,其他线程等待。
2、逻辑过期:缓存不设置物理过期时间,而是在值内部存储逻辑过期时间。查询时若发现逻辑过期,则异步更新数据,当前请求仍返回旧值。
**缓存雪崩:**是指缓存同一时间大量的缓存key同时失效,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。和缓存雪崩不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
1、添加随机过期时间:为不同的缓存Key设置过期时间加上一个随机值,避免同时失效。
2、利用Redis集群提高服务的可用性:哨兵模式、集群模式
3、采用多级缓存:结合本地缓存(如Caffeine)和分布式缓存(如Redis),即使一级缓存失效,另一级仍可提供保护。
6、Jedis和Redisson有什么区别?
Jedis是Redis的Java实现的客户端,其API提供了比较全面的Redis命令的支持;Redisson实现了分布式和可扩展的Java数据结构,和Jedis相比,功能较为简单,不支持字符串操作,不支持排序、事务、管道、分区等Redis特性。
Redisson的宗旨是促进使用者对Redis的关注分离,从而让使用者能够将精力更集中地放在处理业务逻辑上。