一 、4bit量化参数解释
这是我们在hugging face里进行4 bit 量化加载的配置文件。
之前我们讲的量化方法都是线性量化的方法,也就是在量化前的浮点数和量化后的整数之间是满足线性关系的。换一种不太准确的说法,就是对于量化后的每个整数值,都有同样多的浮点数的值映射到它上面。
对于神经网络,一般参数值都是符合均值为零的正态分布的,也就是零附近的参数会很多,但是极大和极小的值很少。如果我们均匀分配本来就不多的,量化后的整数值就有些浪费。我们能不能在原始浮点型数值密集的地方多分配一些,量化后的整数值密度小的地方少分配一些,这样就能减少量化带来的误差。基于这个思想,我们把一个正态分布根据累计概率密度分为16个区域。因为4bit量化后的整数有16个,可以看到越靠近零值分配的整数越密集,越远离零值分配的整数就越稀疏。
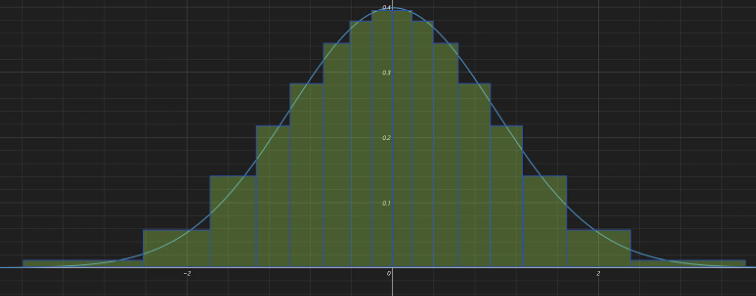
那么我们如何做量化呢?比如对于分配了整数14的这个区间,我们可以求出它的区间的起始点和终点对应的X的值。如果输入的X值在1.73和2.26之间,我们就把它量化为14。对于反量化14,我们就取这个区间对应的平均值1.995。
但是有两个问题,第一个问题是对于正态分布X是从负的无穷大到正的无穷大,反量化时我们没有办法求最后一个区间的均值。那么解决办法就是我们做一个截断,QLoRA里对两边都各舍弃了,累计概率密度0.0322917。
第二个问题,对于0,不论它归属于左边的7还是右边的8,它反量化后都不再是零了。但是零在深度学习里是有特殊意义的。比如对于padding,RELU函数等,我们需要对零值来做特殊处理。那么我们就把零值单独拿出来,让它占4比特量化中16个整数的一个,那么还有15个值可以分配,然后就按正态分布累计概率密度给正数均匀分配8个,负数分配7个。我们得到所有的X之后,除以它们最大的绝对值,归一化到-1和1之间,最终我们就有了这张表。
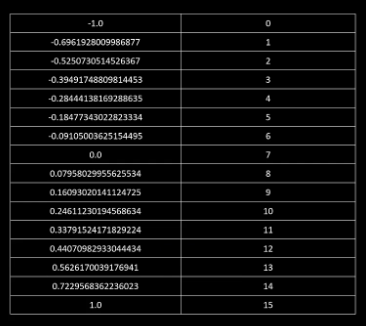
左边是真实的浮点数,七个负数,八个正数,一个零,一共16个。它们之间并不是线性等分的,但是正数部分和负数部分分别都是按照正态分布累积概率密度等分的,这就是Normal float 4比特,简称NF4。NF4并不是用来做计算的,还是专门对符合正态分布的数据进行量化用的。
有了Normal float 4对应的16个值,我们看一下具体如何用它来进行量化和反量化。我们有一组原始的浮点数1.532,-0.823、0.412、0.232。首先除以它们里面最大的绝对值,也就是1.532。1.532就是缩放因子scale,我们需要保存,因为反量化时需要。归一化后,我们进行Normal float 4的查表和哪个值最接近,就取这个值对应的index作为量化后的int 4的值。第一个是1,对应的index是15,第二个值是-0.537,它和-0.525最接近,对应的index是2,所以它量化后的int 4的值就是2。同样对剩余的两个数进行处理,就得到了量化后的int 4的表示值15、2、10、9。
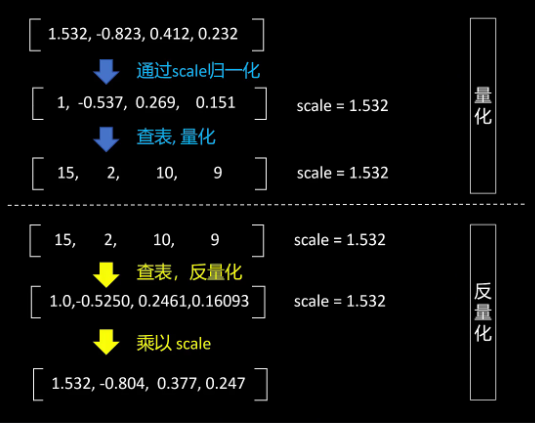
下面我们再看一下如何进行反量化。第一步是通过查表找出这个int 4的值对应的浮点数。比如第一个是15,它对应的浮点数是1.0。第二个是2,它对应的浮点数是-0.52507。同理,查出剩下的两个数,最后再乘以scale就得到了反量化后的值。可以看到量化和反量化后还是有一些量化误差的。
二、QLoRA&双重量化
分块量化可以有效地应对异常值,提高量化精度。QLoRA, 量化时进行了分块量化,每64个值作为一个块,这样的话每个块里有64个数,每个数量化后占四位,一共有256位。但每个block独立量化都需要保存一个float 32位的scale的值。这样因为这个32位的scale值额外占用量化后的12.5%的显存,这怎么解决呢?那就继续对这个32位的scale值进行量化,量化都是对一组数进行的,我们就把256个block的scale值进行一次巴比特的量化,这样额外占用的显存就从12.5%降低到了3.174%,这就叫做双重量化。双重量化减少了显存的占用,但是反量化时需要进行两次反量化,首先对scale值进行反量化,然后对tensor的值进行反量化。

最后需要注意的是,Normal float 4和其他数据类型不同,它并不是用来进行浮点数的表示和计算用的。它设计的目的就是对符合正态分布的数据进行int四量化的。所以量化后的int 4的值并不能参与计算,只能反量化后才可以进行计算。这也就是为什么在bits and bites int 4量化配置里,我们需要配置计算类型了。