一、引言
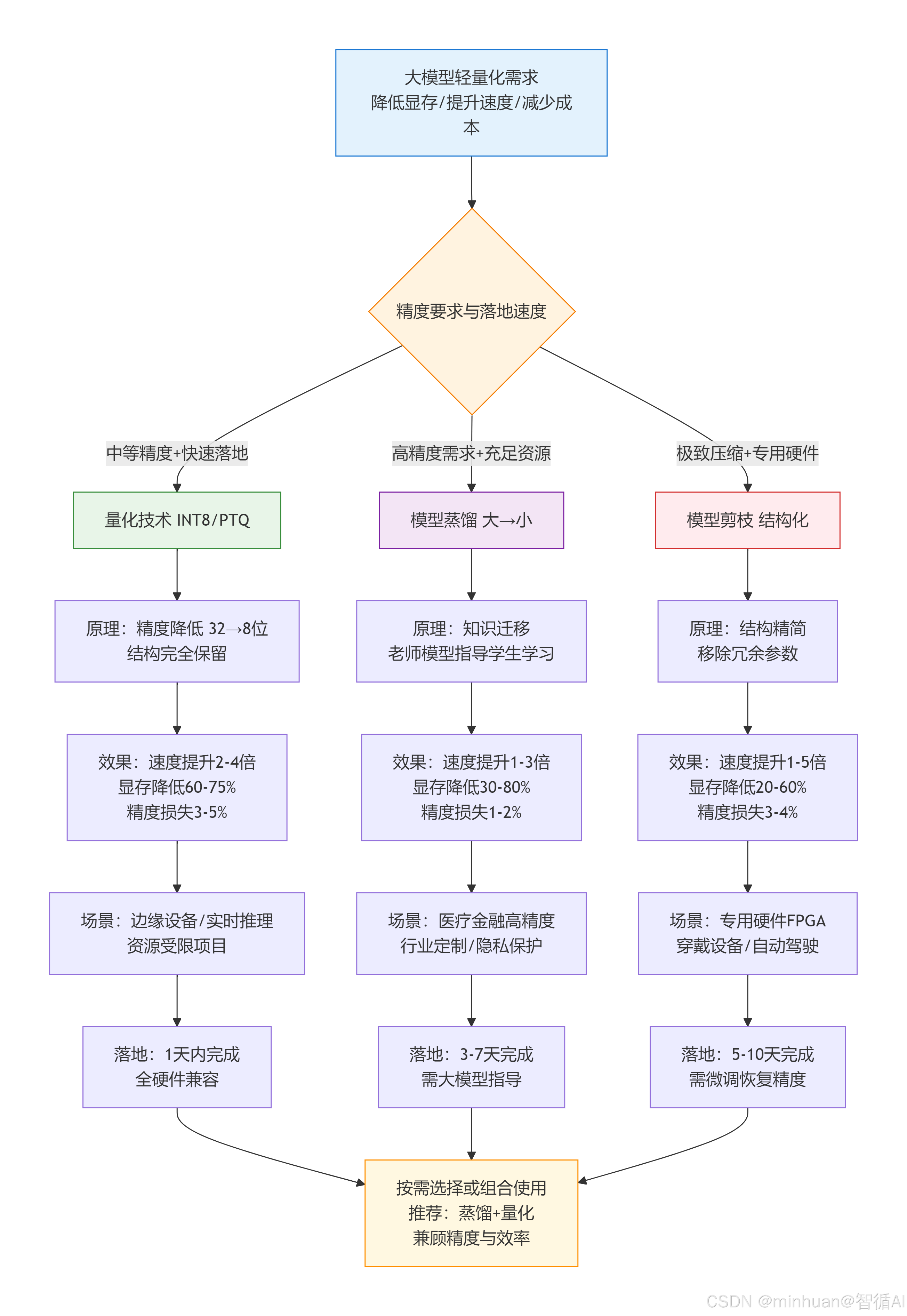
如今大模型越来越火,不管是企业做业务落地,还是我们作为个人开发者上手体验,都绕不开一个核心问题:大模型虽强,但太笨重,动辄几十上百GB显存占用,普通硬件跑不动,推理延迟还高,根本没法适配边缘设备、实时场景这些实际需求。这时候,轻量化技术就成了破局关键,而量化、蒸馏、剪枝都是最常用的三种方案。但我们又该怎么抉择,哪种合适,或怎么去理解三者的差别,每种方式的存在肯定有它独特的道理和最适用的场景,尽管它们各有侧重,没有绝对的优劣,但对于技术优化选型而言,选对了能少走很多弯路,选错了要么精度崩了,要么落地成本翻倍。今天我们就把它们放在一起拆解对比,就算不分伯仲,我们也要看清每种技术的适配场景、落地门槛和效果边界,明白不同需求该选哪种方案。
大模型轻量化不是越复杂越好,而是适配才最优。不用盲目追求高精度或极致压缩,结合自己的硬件条件、落地周期和精度需求做选择,甚至组合使用,才能在成本、速度和效果之间找到平衡。下面我们就从概念、差异、代码到选型,一步步把这三种技术做通俗易懂的分解,充分理解三者的差异、核心逻辑和使用配置细节。
二、核心基础概念
1. 量化
1.1 核心定义
量化是通过降低模型参数和激活值的数值精度,减少存储字节数与计算开销的技术。大模型默认采用 32 位浮点数(FP32)存储参数,每个参数占 4 字节,量化通过将其转换为低精度格式(如 FP16、INT8、INT4),实现显存占用和计算量的成比例降低,且不改变模型结构。
通俗比喻:如同将一张 1600 万像素的高清图,压缩为 200 万像素的标清图,画面细节略有损失,但存储体积大幅减小,且不改变图片的整体构图,相较而言,模型的参数量减少,但对应模型结构不变。
1.2 核心分类
**训练后量化(Post-Training Quantization, PTQ):**是在模型训练完成后直接进行的量化方法。它不对模型结构或训练过程做任何修改,而是利用少量(通常几百个)无标签的校准数据,统计激活值的分布(如最小/最大值、直方图等),从而确定合适的量化参数(如缩放因子和零点)。权重通常直接从浮点(如 FP32)转换为整型(如 INT8)。
这种方法的主要优点包括:
-
- 无需重新训练模型:直接对已训练好的浮点模型进行量化,节省大量训练资源和时间。
-
- 实现简单、上手快:多数深度学习框架(如 PyTorch、TensorFlow Lite)提供开箱即用的 PTQ 工具,可快速在一天内完成部署。
-
- 仅需少量校准数据:通常几百个无标签样本即可估计激活范围,不依赖完整训练集。
-
- 显著提升推理速度:权重和激活转为 INT8 后,可利用硬件加速,降低延迟与功耗。
-
- 减小模型体积:FP32 → INT8 可将模型大小压缩约 4 倍,利于端侧部署,如手机、IoT 设备。
-
- 适用于大多数通用模型:对 CNN、Transformer 等主流架构有良好支持。
**量化感知训练(Quantization-Aware Training, QAT):**是在训练阶段就引入量化模拟操作,将前向传播中的权重和激活"假装"量化为低比特形式(实际仍用浮点计算),使模型在训练过程中学会补偿量化带来的信息损失。训练完成后,再将模型真正转换为低精度格式(如 INT8)用于推理。
这种方法的主要优点包括:
-
- 精度损失极小:通过在训练中模拟量化噪声,模型能主动适应低比特表示,通常精度下降 <1%~2%,甚至可媲美原始浮点模型。
-
- 更适合敏感任务:在医疗、金融、自动驾驶等高精度要求场景中表现更可靠。
-
- 支持更低比特量化:如 INT4、INT2 等极端压缩方案,通常只有 QAT 能维持可用精度。
-
- 优化量化参数更合理:缩放因子、零点等可在训练中学习或微调,而非仅依赖统计估计。
-
- 提升硬件部署上限:在专用 AI 芯片(如 TPU、NPU)上可充分发挥低精度计算的性能优势,同时保持高准确率。
-
- 兼容复杂模型结构:对包含残差连接、注意力机制、归一化层等的模型更具鲁棒性。
**动态量化(Dynamic Quantization):**是一种在模型推理阶段应用的量化技术,其核心思想是:模型参数(如权重)在部署前被静态地量化为低比特表示(如 INT8),而激活值则在推理过程中根据每一批输入数据的分布动态地进行量化和反量化。
这种方法的主要优点包括:
-
- 无需校准数据集:因为激活值的量化范围(如最小值、最大值或缩放因子)是在运行时根据当前输入动态确定的,所以不需要提前使用校准数据来统计激活分布。
-
- 保留较高精度:由于每次推理都能根据实际激活值调整量化参数,避免了因固定量化范围导致的精度损失,尤其适用于激活值范围变化较大的模型,如 Transformer 中的注意力机制。
-
- 提升推理速度与能效:权重以低比特形式存储和计算,减少了内存带宽需求和计算量,同时利用硬件对 INT8 等低精度运算的加速支持,显著提升推理效率。
1.3 适用场景
- 边缘设备部署场景:手机、嵌入式设备、无人机、智能摄像头等显存/算力有限的设备。例如:将 LLaMA-7B 模型用 INT8 量化后,可在一般显卡或手机端本地运行,无需依赖云端调用。
- 实时推理场景:智能客服、实时翻译、语音助手等对延迟要求高的场景。量化后推理速度可提升 2-4 倍,能将延迟从数百毫秒降至百毫秒内,保障用户体验。
- 预算有限场景:中小公司、个人开发者无高端 GPU 资源,需用普通硬件跑大模型。量化可节省 60%-75% 显存,无需额外购置算力设备,大幅降低部署成本。
- 高并发场景:电商秒杀、直播弹幕分析等高并发推理需求,量化后单卡可承载的并发量提升 2-3 倍,无需扩容硬件即可应对流量峰值。
2. 模型蒸馏
2.1 核心定义
蒸馏是一种知识迁移技术,通过高精度大模型"老师模型"指导轻量化小模型"学生模型"训练,让小模型学习大模型的隐性知识,最终实现"小模型精度接近大模型,速度和显存远超大模型"的效果。
传统小模型训练仅学习"硬标签"(如文本分类的"0/1"类别),而蒸馏让学生模型同时学习老师模型的"软标签"(如预测"类别 1"的概率 92%、"类别 0"的概率 8%),软标签中包含大模型对数据的深层理解(如"语义相似性"),这是蒸馏精度优于直接训练小模型的核心原因。
通俗比喻:如同大学教授(老师模型)给小学生(学生模型)讲课,教授不仅告诉学生"标准答案"(硬标签),还讲解"解题思路和逻辑"(软标签),让小学生在知识储备有限的情况下,也能达到接近教授的解题准确率。
2.2 核心分类
**逻辑蒸馏(Logits Distillation):**是最经典、最基础的知识蒸馏形式,利用教师模型输出的 logits(即 softmax 前的原始分数)作为"软标签",引导学生模型学习更平滑、信息更丰富的输出分布,而不仅限于硬标签(如 one-hot 编码),常配合温度缩放(Temperature Scaling)使用,使教师输出更柔和,便于学生学习。
- 优点:实现简单,只需在损失函数中加入对教师 logits 的 KL 散度或均方误差项;计算开销小。
- 适用任务:文本分类、情感分析、回归预测等输出维度固定且结构简单的任务。
- 局限性:仅传递最终决策信息,无法传递模型内部的语义结构或中间推理过程。
**特征蒸馏(Feature Distillation):**特征蒸馏不再只关注最终输出,而是让学生模型模仿教师模型在中间某一层(或多层)的特征表示(如 CNN 的卷积特征图、Transformer 的隐藏状态)。通常通过最小化两者特征之间的 L2 距离、余弦相似度或注意力图差异来实现。需对齐教师与学生的特征维度,可通过投影层或适配器,否则难以直接比较。
- 优点:能传递更丰富的语义和结构知识,尤其适合需要空间/时序建模的任务。
- 适用任务:图像分类/检测(如 ResNet → MobileNet)、语音识别、复杂 NLP 任务(如机器翻译、对话生成、摘要)。
- 典型方法:FitNets、AT(Attention Transfer)、PKD(Patient Knowledge Distillation)等。
**自蒸馏(Self-Distillation):**自蒸馏是一种无需外部教师模型的蒸馏策略。它利用同一个模型的不同部分(如深层 vs 浅层、主干 vs 分支、不同训练阶段的快照)互为师生:例如用深层输出指导浅层,或用完整模型指导其剪枝/量化后的子模型。
- 优点:节省资源,无需额外大模型;可作为正则化手段提升模型泛化能力;适合边缘设备或资源受限场景。
- 适用场景:模型压缩、无预训练大模型可用时的性能提升、训练稳定性优化。
- 局限性:由于"老师"本身能力有限,知识上限受原模型约束,精度提升通常不如强教师模型带来的传统蒸馏显著。
2.3 适用场景
- 高精度轻量化场景:医疗影像分析、金融风险预测、法律文书分类等对精度要求极高(不能接受 >2% 精度损失)的场景。例如:将 GPT-4 的医疗知识蒸馏到 BERT 小模型,可在基层医院辅助诊断,精度接近大模型,且能本地部署保障数据隐私。
- 大模型替代场景:用小模型替代超大模型降低成本。例如:用蒸馏后的 7B 模型替代 65B 模型,显存占用降低 80%,推理速度提升 3 倍,精度仅损失 1%-2%,可广泛用于内容生成、语义检索等业务。
- 行业定制化场景:将通用大模型的知识与行业数据结合,蒸馏为行业专用小模型。例如:将通用 LLMs 与金融数据结合,蒸馏出金融领域小模型,既保留通用语义能力,又具备行业专业知识,部署在银行内网使用。
- 隐私保护场景:政务、医疗等数据敏感场景,无法将数据上传至云端大模型训练,可先在本地训练大模型,再蒸馏为小模型部署,既保障数据隐私,又实现轻量化。
3. 模型剪枝
3.1 核心定义
剪枝是通过识别并移除模型中的冗余参数/结构,实现模型精简的技术。大模型中存在大量权重接近 0 的参数,这些参数对模型输出影响极小(如同大树的枯枝),剪枝后模型参数数量减少,结构更简洁,从而降低显存占用、提升推理速度。
剪枝的核心是"保留关键参数、移除冗余参数",需通过"参数重要性评估"(如权重绝对值、L2 范数)判断哪些参数可移除,且剪后需微调模型,恢复因剪枝损失的部分精度。
通俗比喻:如同给大树修剪枝叶,剪掉枯萎、冗余的枝条(权重接近 0 的参数),保留粗壮的主枝和健康枝叶(关键参数),让大树(模型)生长更高效,同时不影响整体形态(核心能力)。
3.2 核心分类
**结构化剪枝(Structured Pruning):**以规则的结构单元为单位进行裁剪,如移除整个神经元、删除完整的卷积核、剪掉整个注意力头或前馈层、甚至直接删减整层网络
结构化剪枝的优点:
- 剪枝后模型仍为稠密、规则的张量结构,可直接被主流框架(PyTorch/TensorFlow)和硬件(CPU/GPU/NPU)高效执行;
- 无需特殊稀疏计算库,部署简单、推理加速显著(如 FLOPs 和内存带宽同步下降);
- 是工业界模型压缩与边缘部署的首选方案。
结构化剪枝的缺点:
- 因强制按"块"删除,可能误剪重要但数值较小的参数,精度损失通常高于非结构化剪枝;
- 对剪枝策略敏感,需结合敏感度分析或迭代微调。
**非结构化剪枝(Unstructured Pruning):**非结构化剪枝逐元素地移除权重,只保留绝对值较大的参数,其余置零,形成高度稀疏的权重矩阵。
非结构化剪枝优点:
- 极大保留模型容量,精度损失极小;
- 理论压缩率高,可达 90%以上的参数移除;
- 适合探索模型冗余性的科研实验。
非结构化剪枝缺点:
- 剪枝后权重呈不规则稀疏模式,常规 GPU/CPU 无法有效跳过零值计算;
- 需依赖专用稀疏加速硬件或软件库,通用部署困难;
- 实际推理速度提升有限,甚至可能变慢。
**混合剪枝:**结合结构化与非结构化剪枝,保精度对核心层做非结构化剪枝,提速度对非核心层做结构化剪枝。
混合剪枝的优点:
- 在精度与推理速度之间取得较好平衡;
- 可针对不同模块定制剪枝策略,更符合实际模型结构特性。
混合剪枝的缺点:
- 实现复杂:需设计多粒度剪枝策略、协调不同剪枝方式的训练流程;
- 需要精细调参和模块重要性评估,工程成本高;
- 目前缺乏统一框架支持,多用于高端定制化场景。
3.3 适用场景
- 专用硬件部署场景:需适配 FPGA、ASIC 等专用芯片的场景,这类芯片对模型结构要求严格,结构化剪枝可精简模型结构,适配芯片的计算架构,提升硬件利用率。例如:剪枝后的 ResNet 模型,可部署在智能摄像头的 ASIC 芯片中,实现实时目标检测。
- 极致压缩场景:需将模型压缩到极小体积的场景,如物联网设备、可穿戴设备,显存仅几十 MB。例如:将 10 亿参数模型剪至 1 亿参数,体积缩小 90%,可部署在智能手表中实现语音交互。
- 模型冗余度高的场景:大模型训练时为避免过拟合,通常设计冗余结构(如多层卷积、多注意力头),剪枝可移除这些冗余结构,让模型更紧凑。例如:BERT 模型的注意力头存在冗余,剪去 30% 注意力头后,精度损失极小,速度提升明显。
- 低延迟极致需求场景:自动驾驶、工业控制等对延迟要求极高(毫秒级)的场景,剪枝可精简计算步骤,推理速度提升 3-5 倍,满足实时控制需求。
三、核心差异对比
1. 核心原理
- 量化(INT8,PTQ) 的核心是降低模型参数的数值精度,将原本使用 32 位浮点数(FP32)表示的权重和激活值,转换为 8 位整数(INT8)甚至更低比特格式。这一过程不改变模型结构,仅压缩数据表示方式,从而减少存储占用和计算量。
- 模型蒸馏(如 BERT-large → BERT-base) 则是一种知识迁移方法:利用一个性能强大但体积庞大的"教师模型"生成软标签或中间层特征,指导一个更小的"学生模型"学习其行为。学生模型通过模仿教师的输出分布或深层语义表示,获得接近大模型的能力。
- 模型剪枝(以结构化剪枝、30% 比例为例) 直接移除模型中冗余的部分。结构化剪枝会按单元删除,比如整个卷积核、注意力头或神经元,使网络变得更轻、更紧凑。这不仅减少了参数数量,也简化了计算图。
2. 精度损失
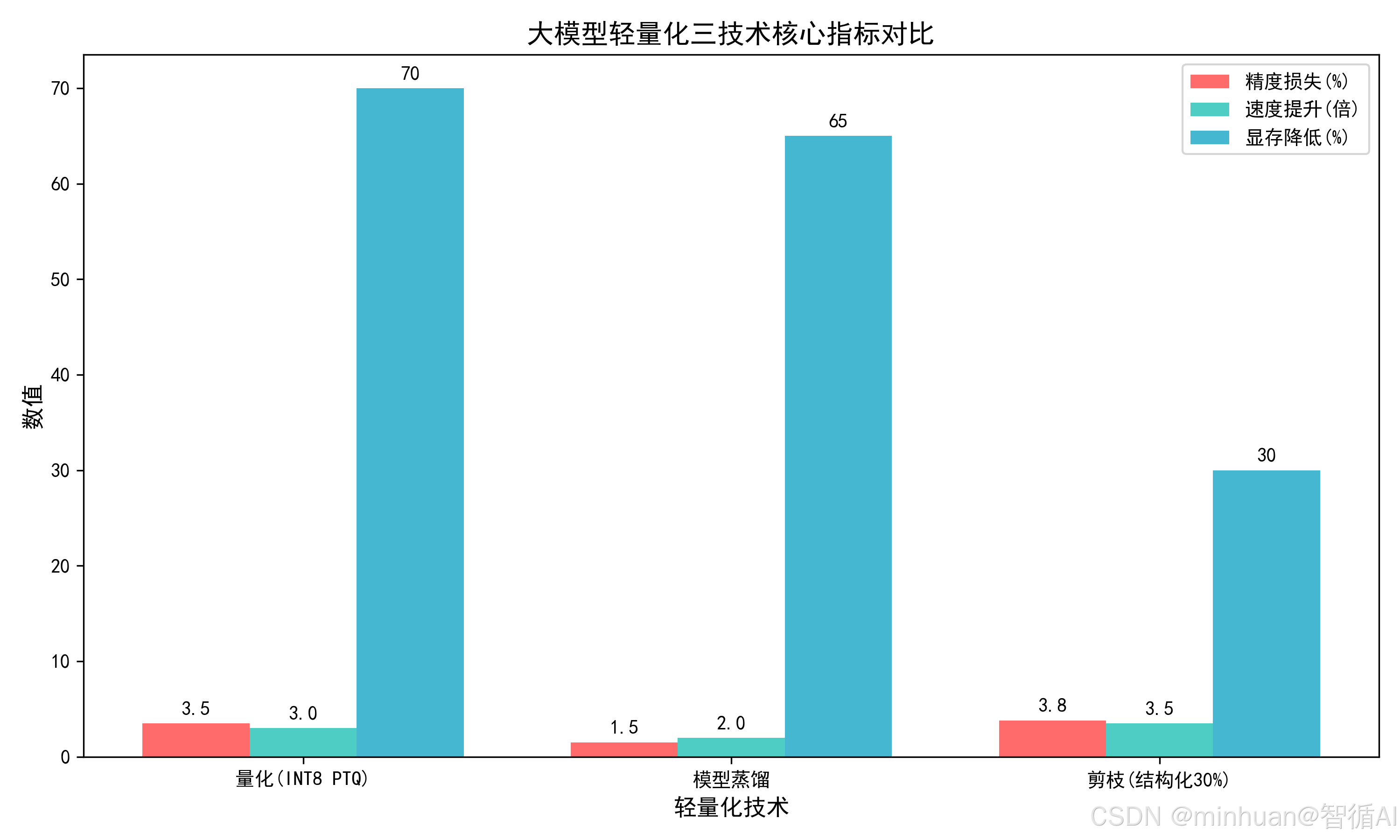
- 量化在训练后量化(PTQ)模式下通常带来 3%--5% 的精度下降;若采用量化感知训练(QAT),可将损失控制在 2% 以内,但极低精度(如 INT4)可能影响复杂语义任务的表现。
- 蒸馏的精度损失最小,一般仅为 1%--2%。特别是当同时蒸馏 logits 和中间特征时,学生模型能高度逼近教师模型的性能,是高精度轻量化场景的首选。
- 结构化剪枝在剪掉 30% 的结构后,初始精度损失约为 5%--8%,但通过后续微调可收窄至 3%--4%。非结构化剪枝虽能实现更低的精度损失(<3%),但因部署困难,工业界较少采用。
3. 推理速度提升
- 量化可带来 2--4 倍的推理加速,效果高度依赖硬件对低精度运算的支持,如 NVIDIA GPU;
- 蒸馏的速度提升主要来自学生模型本身的缩小,通常可实现 1--3 倍加速。模型越小,加速越明显,但上限受限于学生架构的设计。
- 剪枝的提速幅度最灵活:1--5 倍不等,取决于剪枝比例和方式。结构化剪枝因输出仍为规则张量,能被通用硬件高效执行,加速效果显著;而非结构化剪枝因稀疏性难以被常规硬件利用,实际提速有限。
4. 显存与存储占用
- 量化节省最为显著:INT8 相比 FP32 可减少 75% 的存储空间,INT4 甚至可达 87.5%,同时大幅降低运行时显存需求。
- 蒸馏的压缩率取决于学生模型规模。例如从 BERT-large(约 330M 参数)蒸馏到 BERT-base(110M),可节省 约 60%--70% 的存储;若进一步压缩到 Mini/BERT-Tiny,节省可达 80%。
- 剪枝在 30% 剪枝比例下,通常降低 25%--30% 的参数量和存储;若剪至 50%,可节省 40%--50%。但相比量化,其存储压缩效率略低。
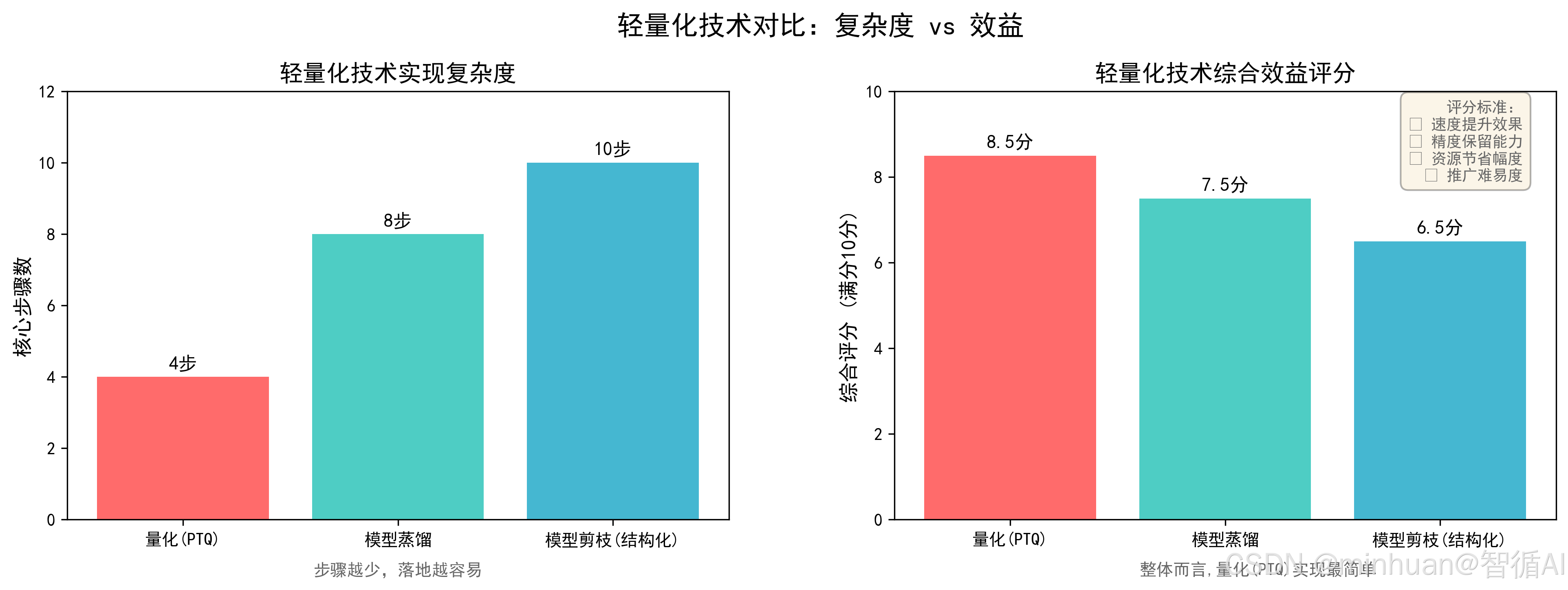
5. 实现难度与落地周期
- 量化最容易上手。主流框架(如 PyTorch、TensorFlow Lite)提供一键式 PTQ 工具,简单可在一天内完成部署,无需训练经验。
- 蒸馏需要加载教师模型、设计蒸馏损失函数(如 KL 散度 + 特征对齐)、调整温度参数等,通常需 3--7 天,适合具备基础训练能力的团队。
- 剪枝实现最复杂。需评估各层或参数的重要性(如基于梯度、权重幅值或敏感度分析),进行多轮剪枝与微调,并验证硬件兼容性,完整流程常需 5--10 天。
6. 硬件友好度
- 量化对硬件极其友好。几乎所有现代 CPU、GPU 和 AI 加速芯片都原生支持 INT8 推理,无需特殊配置。
- 蒸馏产出的是标准稠密模型,完全兼容现有硬件生态,部署无障碍。
- 剪枝则分情况:结构化剪枝输出规则网络,可直接在通用硬件上高效运行;而非结构化剪枝产生的稀疏模型,只有在支持稀疏计算的专用硬件上才能发挥优势,否则可能反而变慢。
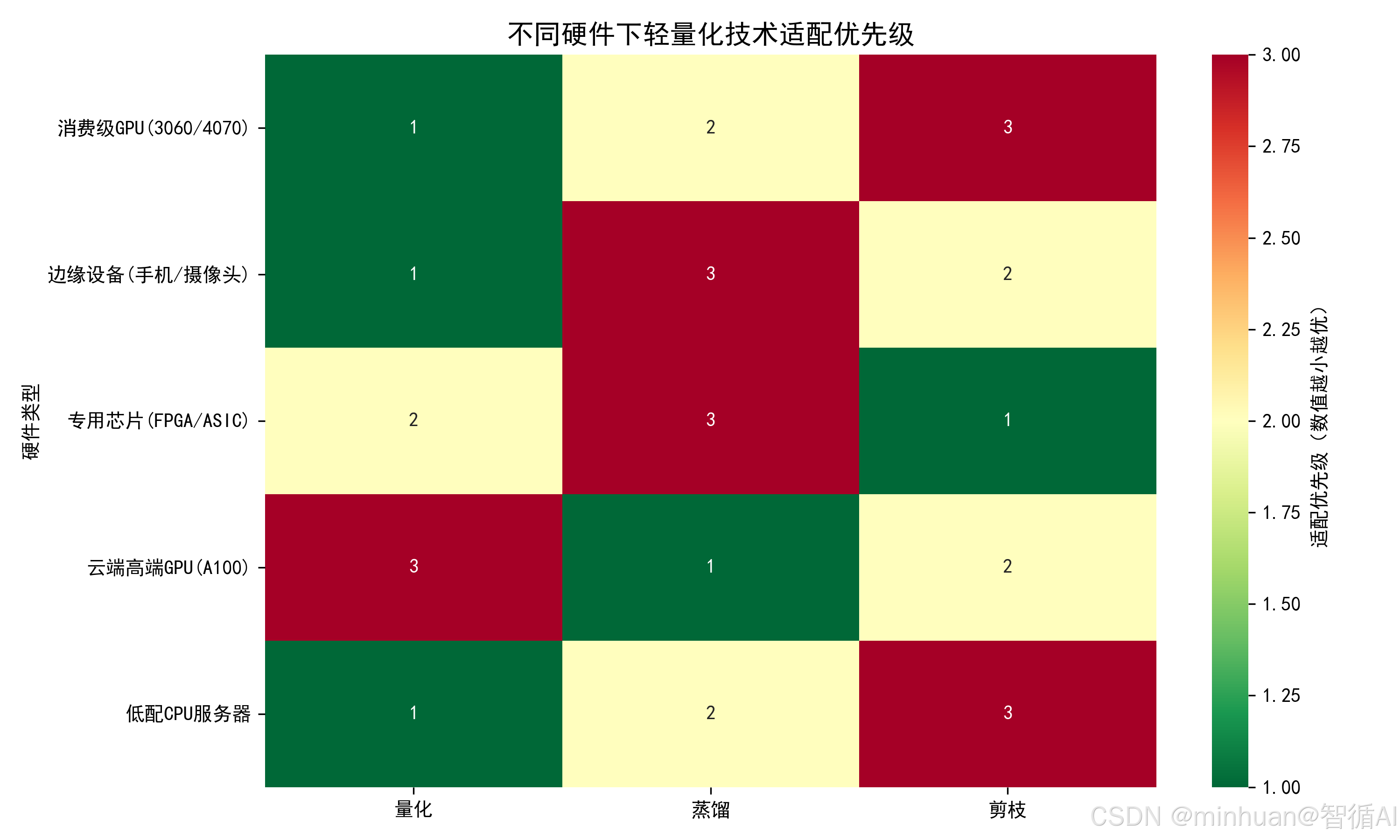
7. 核心优势与劣势
- 量化的优势在于快速、低成本、全平台兼容,是工业界轻量化的第一选择;但其劣势是精度损失无法完全避免,尤其在低比特下可能影响模型语义理解能力。
- 蒸馏的最大亮点是精度保持极佳,能让小模型拥有接近大模型的能力,特别适合对准确率敏感的业务;但缺点是依赖高质量教师模型,且学生模型大小不能无限压缩。
- 剪枝能真正精简模型结构,在资源极度受限的设备(如 IoT 终端)上具有不可替代的价值;但其挑战在于剪枝策略设计复杂,微调成本高,且非结构化方案难以落地。
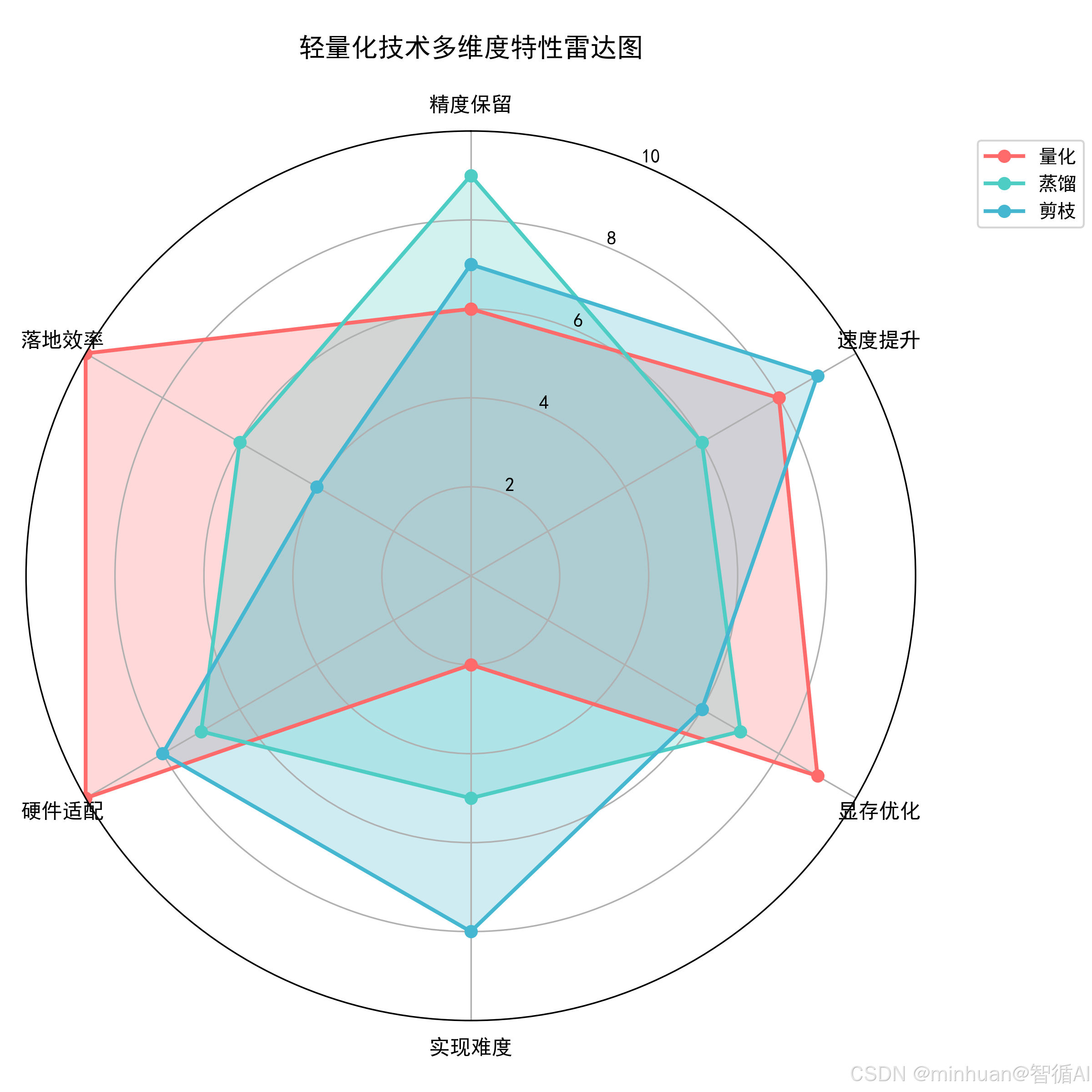
四、示例实现差异
分别对应三者量化方式的场景示例,对最重要的配置部分做详细说明;
1. 训练后量化 PTQ
采用 PyTorch 动态量化,针对全连接层进行 INT8 量化,无需重新训练,短时间内可完成,精度损失控制在 3%-5%,适合快速部署。
python
import torch
import torch.nn as nn
from transformers import BertForSequenceClassification, BertTokenizer
# 1. 加载预训练模型和分词器
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model.eval() # 量化前需切换至评估模式,避免训练状态干扰
# 2. 配置动态量化参数(INT8量化,仅量化全连接层)
quantized_model = torch.quantization.quantize_dynamic(
model,
{nn.Linear}, # 指定要量化的层类型(BERT核心权重集中在全连接层)
dtype=torch.qint8, # 量化精度:INT8(比FP32节省75%显存)
inplace=False
)
# 3. 保存量化模型(体积仅为原始模型的1/4左右)
torch.save(quantized_model.state_dict(), "quantized_bert.pth")
# 加载量化模型(需先初始化模型结构,再加载量化权重)
# quantized_model.load_state_dict(torch.load("quantized_bert.pth"))
# 4. 量化模型推理测试
text = "This is a test sentence for quantized model inference."
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad(): # 推理时关闭梯度计算,节省显存
outputs = quantized_model(**inputs)
logits = outputs.logits
pred = torch.argmax(logits, dim=1).item()
print(f"量化模型推理结果:类别 {pred}")
print(f"量化模型显存占用:{torch.cuda.memory_allocated() / 1024**2:.2f} MB")量化突出的重点:
- 1. 采用动态量化(Dynamic Quantization)
- 动态量化是 PyTorch 提供的一种仅在推理时对激活值动态量化、权重提前静态量化的策略。
- 特别适合 NLP 模型(如 BERT、LSTM),因为其激活值范围在不同输入间变化大,动态确定量化参数(scale/zero_point)能更好保留信息。
- 优势:无需校准数据集,实现简单,精度损失小(通常 <3%)。
- 2. 仅量化全连接层(nn.Linear)
- BERT 的计算密集部分主要集中在 Transformer 中的 Linear 层(如 QKV 投影、FFN 等)。
- 代码中通过 {nn.Linear} 明确指定只对 Linear 层量化,跳过 Embedding、LayerNorm 等不适合量化的模块。 原因:
- Embedding 层是查表操作,量化会破坏词向量语义;
- LayerNorm 对数值敏感,INT8 可能导致分布偏移。
- 3. 使用 qint8(有符号 INT8)
- dtype=torch.qint8 表示使用 8 位有符号整数(范围 -128 ~ 127),这是 NLP 模型动态量化的标准选择。
- 相比 quint8(无符号),qint8 更适合包含负值的权重和激活,如 BERT 输出 logits。
- 4. 显存与模型体积显著压缩
- FP32 → INT8,理论存储减少 75%(4 字节 → 1 字节);
- 实际保存的 quantized_bert.pth 文件大小约为原始 BERT-base 的 1/4,约100MB 。
2. 模型蒸馏示例
以 BERT-large(老师模型,高精度)蒸馏到 BERT-base(学生模型,轻量化)为例,核心是让学生学习老师的软标签知识,精度损失控制在 1%-2%,适配高精度轻量化场景。
python
import torch
import torch.nn as nn
import torch.optim as optim
from transformers import BertForSequenceClassification, BertTokenizer, Trainer, TrainingArguments
from datasets import Dataset # 用于构建简单数据集
# 超参数配置(蒸馏核心参数)
TEMPERATURE = 5 # 温度系数,控制软标签平滑度(2-10为常用范围)
ALPHA = 0.3 # 硬标签损失权重,软标签权重为 1-ALPHA
EPOCHS = 3
BATCH_SIZE = 8
# 1. 加载老师模型(大模型,仅用于推理输出软标签)和学生模型(小模型,需训练)
teacher_model = BertForSequenceClassification.from_pretrained("bert-large-uncased", num_labels=2)
student_model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
teacher_model.eval() # 老师模型固定参数,不参与训练
# 2. 构建简单数据集(实际场景替换为真实业务数据)
data = {
"text": ["I love this movie", "This movie is terrible", "Great film", "Worst experience ever"],
"label": [1, 0, 1, 0] # 硬标签(真实类别)
}
dataset = Dataset.from_dict(data)
# 数据预处理函数
def preprocess_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=128)
tokenized_dataset = dataset.map(preprocess_function, batched=True)
# 3. 定义蒸馏损失函数(硬标签损失 + 软标签损失)
class DistillationLoss(nn.Module):
def __init__(self):
super().__init__()
self.hard_loss = nn.CrossEntropyLoss() # 硬标签损失(真实类别)
self.soft_loss = nn.KLDivLoss(reduction="batchmean") # 软标签损失(老师输出)
def forward(self, student_logits, teacher_logits, labels):
# 软标签计算(老师输出经温度缩放后归一化)
teacher_soft = torch.softmax(teacher_logits / TEMPERATURE, dim=-1)
# 学生输出经温度缩放后取对数(适配KL散度输入)
student_soft = torch.log_softmax(student_logits / TEMPERATURE, dim=-1)
# 总损失 = 硬标签损失*ALPHA + 软标签损失*(1-ALPHA)*温度平方(补偿缩放影响)
loss = ALPHA * self.hard_loss(student_logits, labels) + \
(1 - ALPHA) * self.soft_loss(student_soft, teacher_soft) * (TEMPERATURE ** 2)
return loss
# 4. 自定义训练循环(简化版,实际可使用Trainer封装)
loss_fn = DistillationLoss()
optimizer = optim.Adam(student_model.parameters(), lr=2e-5)
for epoch in range(EPOCHS):
student_model.train()
total_loss = 0.0
for batch in tokenized_dataset.iter(batch_size=BATCH_SIZE):
# 转换为张量并移动到设备(CPU/GPU)
inputs = {k: torch.tensor(v).to("cpu") for k, v in batch.items() if k != "text"}
labels = inputs.pop("label")
# 老师模型输出软标签(关闭梯度计算)
with torch.no_grad():
teacher_logits = teacher_model(**inputs).logits
# 学生模型输出
student_logits = student_model(**inputs).logits
# 计算损失并反向传播
loss = loss_fn(student_logits, teacher_logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() * batch["label"].__len__()
avg_loss = total_loss / len(tokenized_dataset)
print(f"Epoch {epoch+1}/{EPOCHS}, Average Loss: {avg_loss:.4f}")
# 5. 保存蒸馏后的学生模型
torch.save(student_model.state_dict(), "distilled_bert.pth")蒸馏突出的重点:
- 1. 经典的知识蒸馏框架
- 同时利用 硬标签(真实标签)和 软标签(教师模型输出) 进行训练;
- 通过 温度缩放平滑教师输出的概率分布,使学生能学到更丰富的类别间关系,如猫和狗比猫和汽车更相似。
- 2. 教师-学生架构清晰分离
- 教师模型(BERT-large):仅用于推理,eval() 模式 + torch.no_grad(),参数完全冻结;
- 学生模型(BERT-base):可训练,结构更小,目标是逼近教师性能。
- 这是蒸馏成功的关键前提:教师必须比学生更强、更可靠。
- 3. 损失函数设计符合标准实践
- 总损失 = α × 硬损失 + (1−α) × 软损失 × T²
- 其中 T²(温度平方)补偿 是 Hinton 原文提出的校正项,用于平衡 KL 散度在高温下的梯度衰减。
关键细节配置:
- 1. 温度系数 TEMPERATURE = 5
- 属于常用范围(2--10);
- 温度过低 → 软标签接近 one-hot,失去蒸馏意义;
- 温度过高 → 所有类别概率趋同,信息模糊;
- T=5 能有效揭示教师对负类别的"信心程度",适合分类任务。
- 2. 损失权重 ALPHA = 0.3
- 表示 30% 依赖真实标签,70% 依赖教师软标签;
- 若任务标签噪声大,可降低 ALPHA(如 0.1);
- 若教师不可靠或学生过小,可提高 ALPHA(如 0.5)以稳定训练。
- 3. KL 散度使用 reduction="batchmean"
- 这是 PyTorch 中正确实现知识蒸馏 KL Loss 的方式;
- 避免使用默认的 "mean"(会除以 num_classes),导致梯度尺度错误。
- 4. 学生与教师使用不同 BERT 变体
- 教师:bert-large-uncased(24 层,336M 参数)
- 学生:bert-base-uncased(12 层,110M 参数)
- 构成典型的由大到小蒸馏对,压缩率达到约67%,速度提升显著。
3. 模型剪枝示例
采用结构化剪枝(按列剪枝,保留模型结构完整性,适配硬件部署),剪掉 30% 冗余权重,剪后通过微调恢复精度,适合专用硬件与极致压缩场景。
python
import torch
import torch.nn.utils.prune as prune
from transformers import BertForSequenceClassification, BertTokenizer
# 1. 加载预训练模型和分词器
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
# 2. 选择剪枝目标层(BERT编码器第1-3层的全连接层,可扩展至所有层)
target_layers = [
model.bert.encoder.layer[i].output.dense for i in range(3) # 选取前3层全连接层
]
# 3. 结构化剪枝:剪掉每层30%的权重(按列剪枝,即移除整个神经元)
prune_ratio = 0.3
for layer in target_layers:
# ln_structured:按L2范数判断权重重要性,dim=1表示按列剪枝(结构化剪枝核心)
prune.ln_structured(
layer,
name="weight", # 剪枝参数名(权重)
amount=prune_ratio,
n=2, # 用L2范数评估权重重要性
dim=1
)
# 4. 移除剪枝掩码,固化剪枝后的模型结构(剪枝后必须执行,否则权重会恢复)
for layer in target_layers:
prune.remove(layer, "weight")
# 5. 剪枝后微调(恢复精度,简化版,实际需用数据集训练)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)
loss_fn = nn.CrossEntropyLoss()
model.train()
# 模拟微调(实际替换为真实数据集训练5-10轮)
text = "This is a fine-tuning sentence for pruned model."
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
labels = torch.tensor([1])
for _ in range(5):
outputs = model(**inputs)
loss = loss_fn(outputs.logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"微调损失: {loss.item():.4f}")
# 6. 保存剪枝后的模型
torch.save(model.state_dict(), "pruned_bert.pth")
# 7. 剪枝模型推理测试
model.eval()
with torch.no_grad():
outputs = model(**inputs)
pred = torch.argmax(outputs.logits, dim=1).item()
print(f"剪枝模型推理结果:类别 {pred}")
print(f"剪枝后模型参数数量(粗略):{sum(p.numel() for p in model.parameters()) / 1e6:.2f} M")剪枝突出的重点:
- 1. 采用结构化剪枝
- 使用 prune.ln_structured(..., dim=1),按列(dim=1)剪枝,即移除整个神经元,对应全连接层的输出通道。
- 这是典型的结构化剪枝:剪掉的是完整的"单元",而非零散权重。
- 优势:剪枝后模型仍为稠密张量,可被标准硬件(CPU/GPU)高效执行,适合工业部署。
- 对比:若用 prune.random_unstructured,会生成稀疏矩阵,难以加速。
- 2. 聚焦 BERT 的关键可剪枝模块
- 选择 model.bert.encoder.layeri.output.dense(即 FFN 中的第二个全连接层)作为目标。
- 这是 BERT 中参数最密集、计算量最大的部分之一(FFN 占 Transformer 层约 2/3 参数),剪此处收益高。:
- 仅剪前 3 层(可扩展至全部 12 层),体现渐进式剪枝策略,避免一次性大幅破坏模型能力。
- 3. 基于 L2 范数的重要性评估
- n=2 表示使用 L2 范数衡量权重重要性:
- 对每个神经元(列),计算其权重向量的 L2 范数;
- 范数小 → 贡献弱 → 优先剪掉。
- 这是结构化剪枝中最常用且有效的重要性准则,比随机剪枝更保精度。
- 4. 显式固化剪枝结果(prune.remove)
- 剪枝操作默认通过"掩码(mask)"实现,不真正删除参数;
- 调用 prune.remove(layer, "weight") 后,永久移除被剪权重,缩小实际参数量。
- 这是部署前必须执行的关键步骤,否则模型体积未减小;推理时仍计算被剪部分(因底层仍是完整张量)。
- 5. 包含剪枝后微调(Fine-tuning)
- 剪枝会破坏模型原有分布,导致精度骤降;
- 代码通过 5 轮模拟微调(虽数据极少,仅为示意)展示恢复精度的必要性。
- 实际场景中,微调 3--10 个 epoch 是标准流程。
关键细节配置:
- 1. 剪枝粒度:dim=1 的含义
- 在 nn.Linear(in_features, out_features) 中:weight.shape = (out_features, in_features) dim=1
- prune.ln_structured(..., dim=1) 表示对 weight 张量的第 1 维(即 in_features 维度)做归约,然后剪整列。
- 但实际效果是:移除输出通道(即神经元),因为剪的是"列"(每列对应一个输出神经元的全部输入连接)。
- 更准确地说:dim=1 导致按"输出神经元"为单位剪枝,符合结构化剪枝目标。
- 提示:若想剪输入通道(影响上一层输出),应作用于下一层的 dim=0。
- 2. 剪枝比例 prune_ratio = 0.3
- 每层剪掉 30% 的神经元,属于中等强度剪枝;
- 实验表明,BERT 的 FFN 层可承受 30%--50% 结构化剪枝而不崩溃;
- 超过 50% 通常需更强微调或知识蒸馏辅助。
- 3. 微调配置合理性
- 使用小学习率 lr=1e-5与 BERT 微调一致,避免破坏预训练知识;
- 虽然示例数据仅 1 条,但展示了完整微调流程框架,实际只需替换为真实 DataLoader。
- 4. 模型保存方式正确
- torch.save(model.state_dict(), ...) 保存的是固化后的参数,因已调用 prune.remove;
- 加载时无需特殊处理,可直接用于推理。
- 5. 参数量统计有效
- 最终打印 sum(p.numel() for p in model.parameters()) 反映真实参数量(已去除被剪部分);
- 若未调用 prune.remove,此值将仍为原始大小,造成误判。
4. 对比选型建议
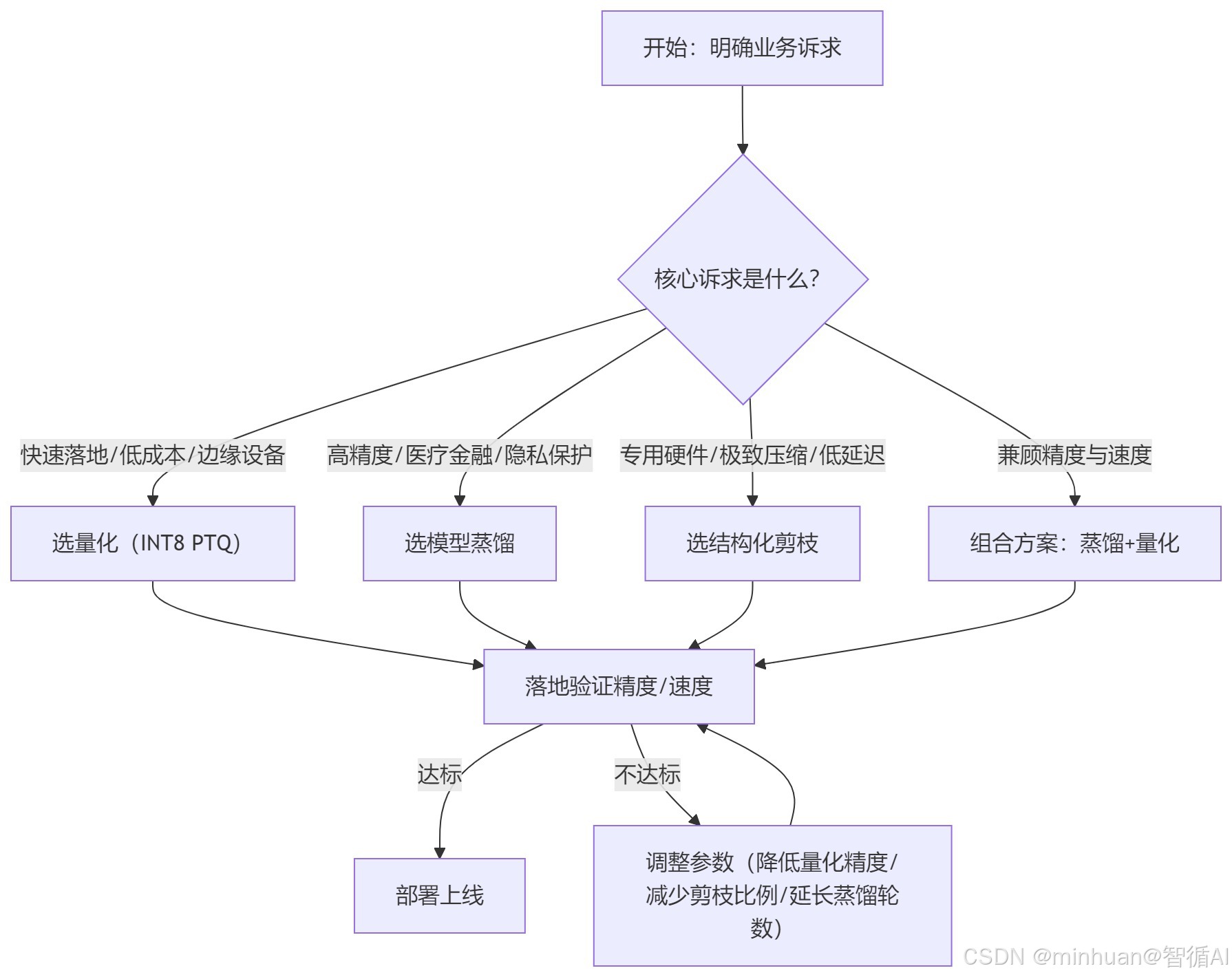
-
- 快速落地、预算有限 → 优先选量化(PTQ);
-
- 高精度需求、可接受中等落地周期 → 优先选蒸馏;
-
- 专用硬件部署、极致压缩 → 优先选结构化剪枝;
-
- 兼顾精度与速度 → 采用"蒸馏+量化"组合,蒸馏保精度,后量化提速度。
五、总结
其实大模型轻量化就这三种核心玩法,大家可以根据自己的需求选,不用盲目追求复杂方案。量化是最适合新手入门的,不用重新训练,几小时就能搞定,显存直接省七成多,边缘设备、预算有限的情况选它准没错,就是精度会略有损失,日常业务完全能接受。如果对精度要求特别高,比如医疗、金融场景,就选蒸馏,虽然要用到大模型当"老师",耗时也久一点,但小模型能学到大模型的精髓,精度损失控制在2%以内,速度还能提3倍。
剪枝就适合有专用硬件、想极致压缩模型的场景,能精简模型结构,但难度最高,剪完还得微调恢复精度,初次接触不建议一开始就试。最推荐的还是组合模式,先蒸馏保精度,再量化提速度,兼顾效果和效率。总的来说,快速落地选量化,高精度需求选蒸馏,极致压缩选剪枝,根据自己的硬件、周期和精度容忍度挑,就能少走很多弯路,这三种方案基本能覆盖大部分轻量化场景了。