《大模型微调技术:Lora、QLora》
- 《大模型微调技术:Lora、QLora》
- 一、LoRA技术深度解析与实践
-
- [2.1 什么是Lora微调?](#2.1 什么是Lora微调?)
- [2.2 LoRA 微调所应用在模型哪些层?](#2.2 LoRA 微调所应用在模型哪些层?)
- 三、QLoRA技术深度解析与实践
-
- [3.1 什么是QLoRA?](#3.1 什么是QLoRA?)
- [3.2 NF4数据类型详解](#3.2 NF4数据类型详解)
- [3.3 双重量化技术](#3.3 双重量化技术)
- [3.4 分页优化器原理](#3.4 分页优化器原理)
一、LoRA技术深度解析与实践
2.1 什么是Lora微调?
- 💡 一句话定义:LoRA(Low-Rank Adaptation,低秩自适应)是一种参数高效微调(PEFT)技术,它通过冻结预训练模型权重,仅在旁路注入可训练的低秩矩阵,用极小的参数量(通常 <1%)实现大模型的任务适配。
LoRA是一种参数高效的微调方法。神经网络包含很多全连接层,其借助于矩阵乘法得以实现,然而,很多全连接层的权重矩阵都是满秩的。当针对特定任务进行微调后,模型中权重矩阵其实具有很低的本征秩(intrinsic rank),因此通过引入低秩矩阵来调整预训练模型的权重。
LoRA(论文:LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS),该方法的核心思想就是通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
LoRA 假设权重更新的过程中也有一个较低的本征秩,对于预训练的权重参数矩阵 (d 为上一层输出维度,k 为下一层输入维度),使用低秩分解来表示其更新:
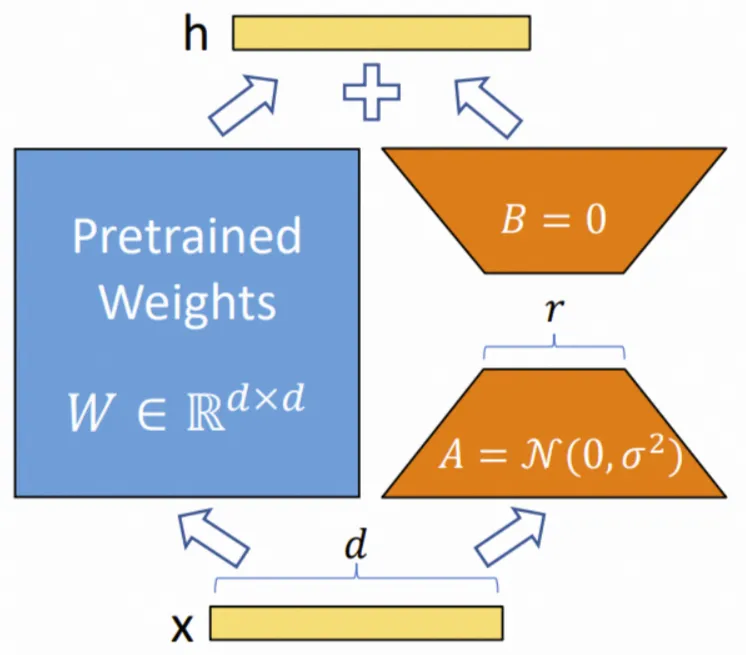
可训练层维度和预训练模型层维度一致为d,先将维度d通过全连接层降维至r,再从r通过全连接层映射回d维度,其中,r<<d,r是矩阵的秩,这样矩阵计算就从d x d变为d x r + r x d,参数量减少很多。
由于训练方法简单、需要的参数量低、训练后模型效果较好,LoRA成为最常用的模型微调方法。多篇论文的实验发现,在众多数据集上LoRA在只训练极少量参数(Rank=8或者16)的前提下,最终在性能上能和全参微调匹配,甚至在某些任务上优于全参微调。
2.2 LoRA 微调所应用在模型哪些层?
LoRA 的核心思想 :在原始预训练语言模型(PLM)的基础上,为涉及矩阵乘法的模块添加一个低秩"旁路"。这个旁路由两个小矩阵 A 和 B 组成,其中:
- A 负责将输入维度从
d降维到r(低秩维度) - B 负责将维度从
r升维回d
最终的输出等价于原始权重输出加上旁路的低秩增量 (A × B),从而用极少的参数模拟模型所需的"本征秩"(intrinsic rank)。
在 Transformer 中的应用
LoRA 技术通常作用于注意力机制的四个权重矩阵:Wq、Wk、Wv、Wo ,同时冻结 MLP 模块的全部参数 ,不参与微调。 同时也会应用在FFN层。
消融实验表明,同时对 Wq 和 Wv 进行 LoRA 调优能获得最佳效果。
默认配置 :目前主流的 LoRA 实现(如 Hugging Face PEFT、Swift 等)默认微调的模块是 q_proj、k_proj、v_proj 。
下面是一段典型的 LoRA 训练日志输出:
bash[INFO:swift] target_modules: ['q_proj', 'k_proj', 'v_proj']
通过仅训练这些低秩矩阵,LoRA 在几乎不增加推理延迟的前提下,极大降低了微调的资源开销,已成为大模型高效微调的主流方案。
在前向传播过程中,一个 LoRA 模块的输出形式如下:
h = W 0 x + ( α r ) B A x h = W_0 x + \left( \frac{\alpha}{r} \right) B A x h=W0x+(rα)BAx
W₀ 表示被冻结的原始权重矩阵;
x 是模块的输入;
A 和 B 是低秩可训练矩阵,秩为 r;
α / r 是一个缩放因子,用于控制 A 和 B 对最终输出的影响程度。
这个缩放因子是 LoRA 成功应用的关键之一。其作用是调节低秩更新在模型输出中的比重,确保即使使用较小的 rank 也能对模型产生足够的影响,同时避免梯度过大导致训练不稳定。
三、QLoRA技术深度解析与实践
3.1 什么是QLoRA?
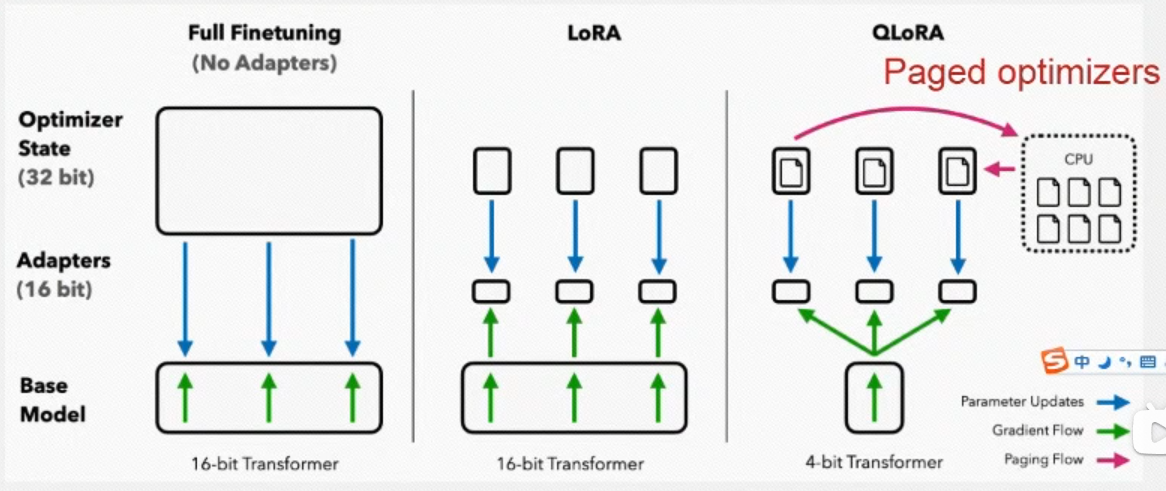
QLoRA的核心创新在于同时应用了量化技术和低秩适应(LoRA)方法,形成了一种"双重优化"策略。具体来说,QLoRA通过以下方式实现高效微调:
1、模型参数量化 :将预训练模型的权重从32位或16位浮点数量化为4位精度
2、低秩适应更新 :通过反向传播梯度到小型的低秩适配器,而非直接更新量化后的模型参数
3、创新数据类型 :使用专为正态分布权重设计的NF4(NormalFloat 4-bit)数据类型
4、双重量化 :对量化常量本身也进行量化,进一步减少内存占用
5、分页优化器:使用内存分页技术管理训练过程中的内存峰值
这些创新使得QLoRA能够在单个消费级GPU(如48GB显存)上微调65B参数规模的模型,同时保持接近16位精度微调的性能水平。
3.2 NF4数据类型详解
NF4(NormalFloat 4-bit)是QLoRA引入的一种创新数据类型,专为量化服从正态分布的模型权重而设计。与传统的整数量化(如Int4)和浮点量化(如FP4)相比,NF4具有以下优势:
信息论最优性:理论上是对正态分布权重的最优量化方式
精度损失最小:在保持4位精度的同时,最小化量化误差
对称范围:取值范围关于零对称,适合表示权重分布
NF4的设计基于信息论原理,其量化范围经过精心选择,确保在有限的4位表示中保留尽可能多的权重分布信息。这使得QLoRA在极低的内存占用下仍能维持模型性能。
3.3 双重量化技术
双重量化(Double Quantization)是QLoRA的另一项重要创新,其工作原理如下:
第一次量化:将原始32位浮点权重量化为4位精度(使用NF4数据类型)
存储量化常量:记录第一次量化过程中使用的缩放因子(scaling factor)和零点偏移(zero point)
第二次量化:将这些量化常量本身也进行量化,通常从32位降至8位
这种双重量化策略可以进一步减少约0.375%的内存占用。虽然看似微不足道,但在处理数百亿参数的模型时,这一节省累积起来相当可观。更重要的是,由于量化常量本身的数量远小于模型权重,第二次量化引入的误差对整体性能几乎没有影响。
3.4 分页优化器原理
训练大型语言模型时,内存使用通常会出现突发峰值,特别是在梯度检查点(gradient checkpointing)过程中。这些峰值往往会导致内存溢出错误,即使平均内存使用量低于硬件限制。
QLoRA引入的分页优化器(Paged Optimizer)解决了这一问题:
内存分页:将优化器状态分为固定大小的页面
GPU-CPU统一内存:利用NVIDIA统一内存技术,实现CPU和GPU之间的自动页面迁移
按需交换:当GPU内存不足时,将不活跃的页面自动交换到CPU内存
训练连续性:避免因内存峰值导致的训练中断
分页优化器的实现基于操作系统的虚拟内存分页思想,使得即使在有限的GPU显存下,也能稳定地训练超大规模模型。
【注释】梯度检查点(Gradient Checkpointing):是一种在深度学习训练中广泛使用的显存优化技术,它通过以计算时间换取显存空间的策略,解决了训练大模型时显存不足(OOM, Out of Memory)的难题。
🎯 核心原理:用时间换空间
在深度学习模型的训练过程中,显存的主要消耗者之一是前向传播(Forward Pass)时产生的中间激活值(Activations)。为了在反向传播(Backward Pass)时计算梯度,传统方法会保存所有层的激活值,这导致显存占用随模型深度线性增长。
梯度检查点技术打破了这一规则,其核心思想是:
前向传播时"少存":不保存所有中间层的激活值,而是有选择地只保存部分关键节点(称为"检查点")的激活值。
反向传播时"重算":当反向传播需要用到某个非检查点层的激活值时,程序会从最近的检查点开始,重新执行一次该段的前向计算,临时生成所需的激活值。
简单来说,这项技术通过牺牲额外的计算时间(重算),大幅降低了对显存空间的需求(少存)。
【参考文章】