一、课前小知识
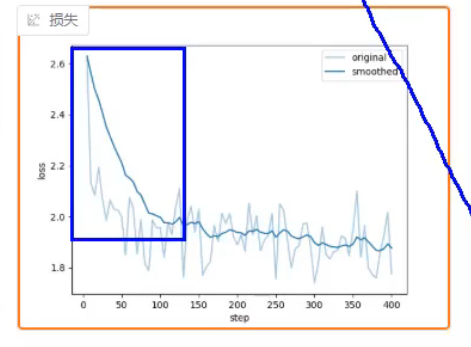
loss图
一开始的下降证明,模型的能力和你输入的数据集存在较大差异(模型处理结果<数据)
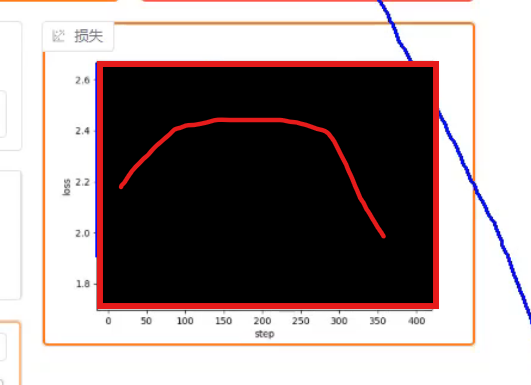
有时候会出现上升的趋势,这证明模型和你的数据集类似(模型处理结果 约等于 数据集)
loss理论可以一直向下但是不能等于0,
当数据出现溢出的时候,loss会直接等于0,然后模型会崩溃loss会突增,然后变成一条直线
这个时候模型就废了
模型生成结果判断
客观评价一般是查看回答与标准答案之间的相似度
在业务场景中,模型的回答达到了甲方的要求,就可以停下来了
模型训练优化
显存计算
XB * 16 = Y bit =>> ZGB
其中,Z就是显存大小
7B * 16 => 13GB
计算过程:
参数总量:7 × 10⁹ = 7,000,000,000 个
总位数:7,000,000,000 × 16 = 112,000,000,000 位(即112 Gbit)
转换为吉字节(GB):1 GB = 8,589,934,592 位(基于1 GB = 2³⁰字节,1字节=8位)
显存大小 Z = 112,000,000,000 ÷ 8,589,934,592 ≈ 13.04 GB



什么是量化
pytorch默认的是F32位,数据类型
大模型为了节约内存,基本上都采用F16
精度损失
模型在量化、打包、跨平台之后,精度总会有一些损失

二、LoRA与QLoRA
LoRA:LoRA 是一种用于微调大型语言模型的技术,通过低秩近 似方法降低适应数十亿参数模型(如 GPT-3)到特定任务或领域。
QLoRA :QLoRA 是一种高效的大型语言模型微调方法,它显著降 低了内存使用量,同时保持了全 16 位微调的性能。它通过在一个 固定的、4 位量化的预训练语言模型中反向传播梯度到低秩适配 器来实现这一目标。
三、QLoRA微调量化操作
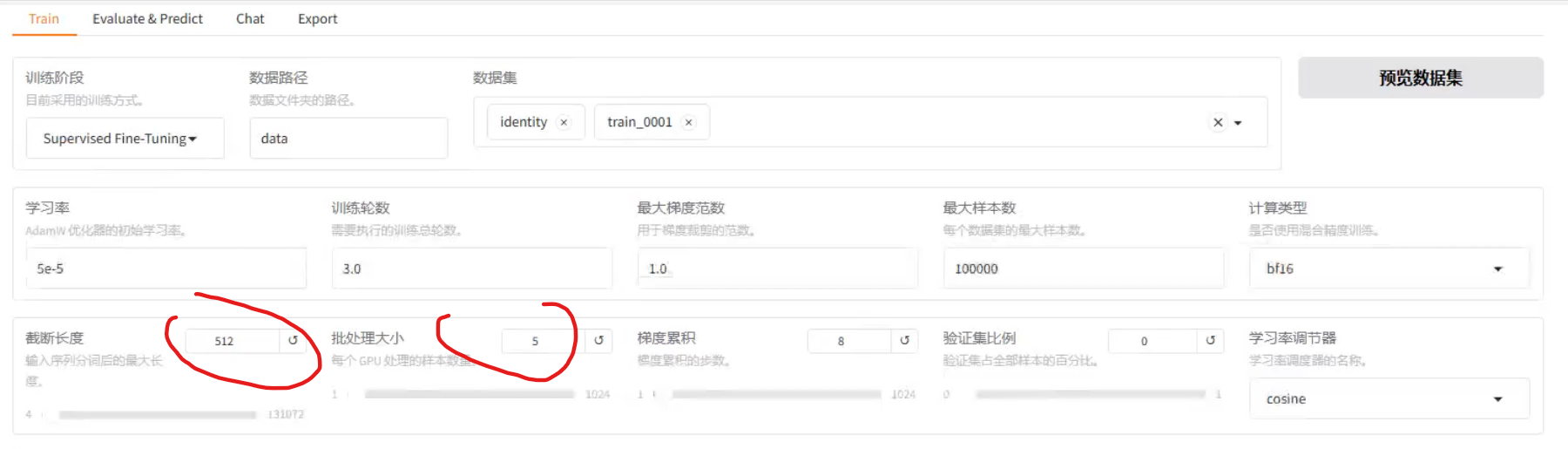
1、训练量化
如果用,就极致,直接选择4
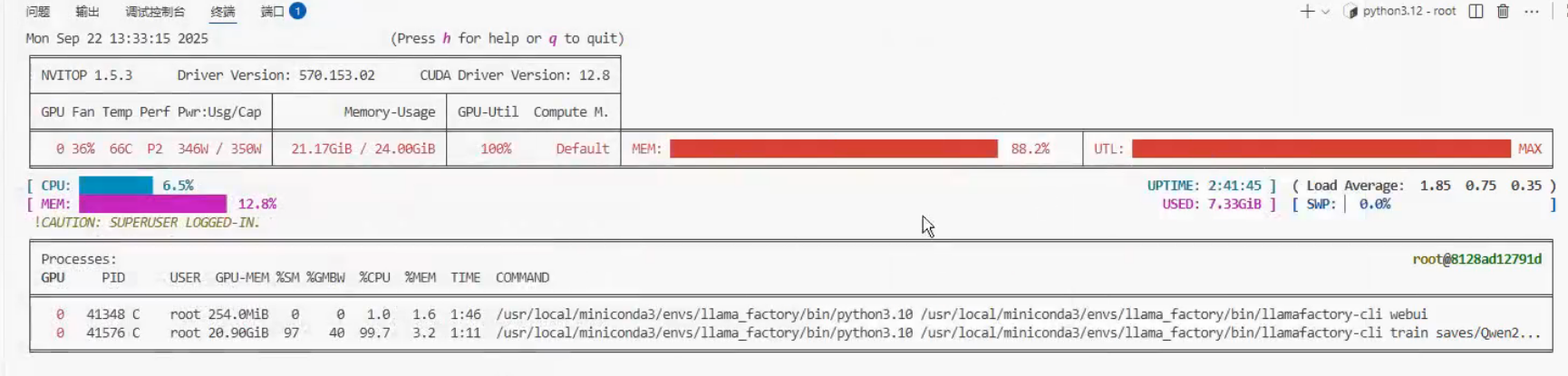
不启用训练量化
显存占用,88%
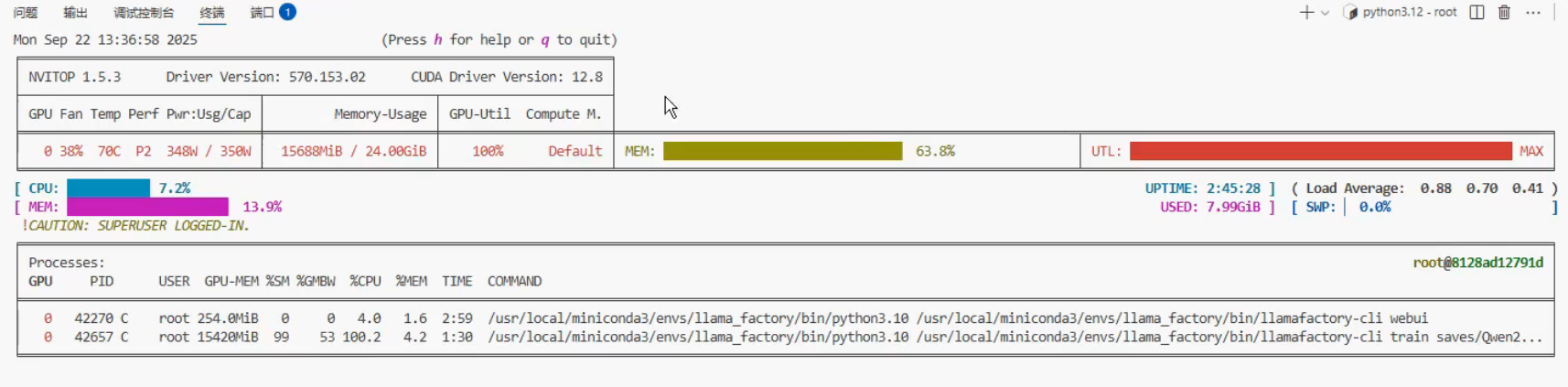
启用量化显存占用,64%
2、LoRA参数设置
得通过实验确定具体参数
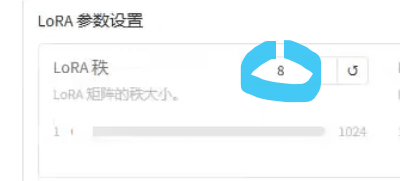
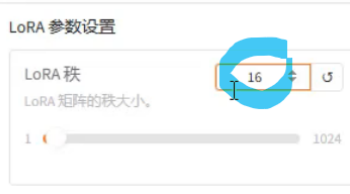
秩
范围是8-32,建议给到16
数据规模越大,秩越大
秩,越小B+A矩阵参与训练的参数越少


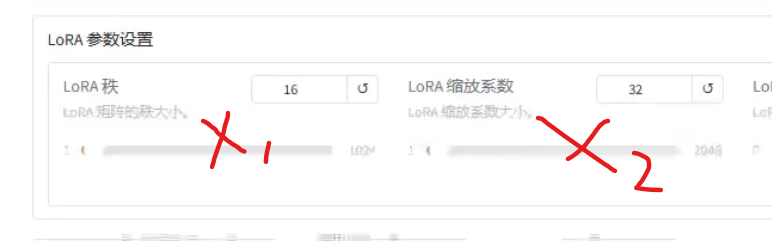
缩放系数
有着明确的关系,二倍,x2 = 2*x1
四、什么是GGUF
1、GGUF与GGML

2、为什么用GGUF
在传统的Deep Learning Model开发中大多使用PyTorch来进行开发,但因为在部署时会面临相依Lirbrary太多、版本管理的问题才有了GGML、GGMF、GGJT等格式,而在开源社群不停的迭代后GGUF就诞生了。
GGUF实际上是基于GGJT的格式进行优化的,并解决了GGML当初面临的问题,包括:
1)可扩展性:轻松为GGML架构下的工具添加新功能,或者向GGUF模型添加新Feature,不会破坏与现有模型的兼容性。
2)对mmap(内存映射)的兼容性:该模型可以使用mmap进行加载(原理解析可见参考),实现快速载入和存储。(从GGJT开始导入,可参考GitHub)
3)易于使用:模型可以使用少量代码轻松加载和存储,无需依赖的Library,同时对于不同编程语言支持程度也高。
4)模型信息完整:加载模型所需的所有信息都包含在模型文件中,不需要额外编写设置文件。
5)有利于模型量化:GGUF支持模型量化(4位、8位、F16),在GPU变得越来越昂贵的情况下,节省vRAM成本也非常重要。
五、 将hf模型转换为GGUF
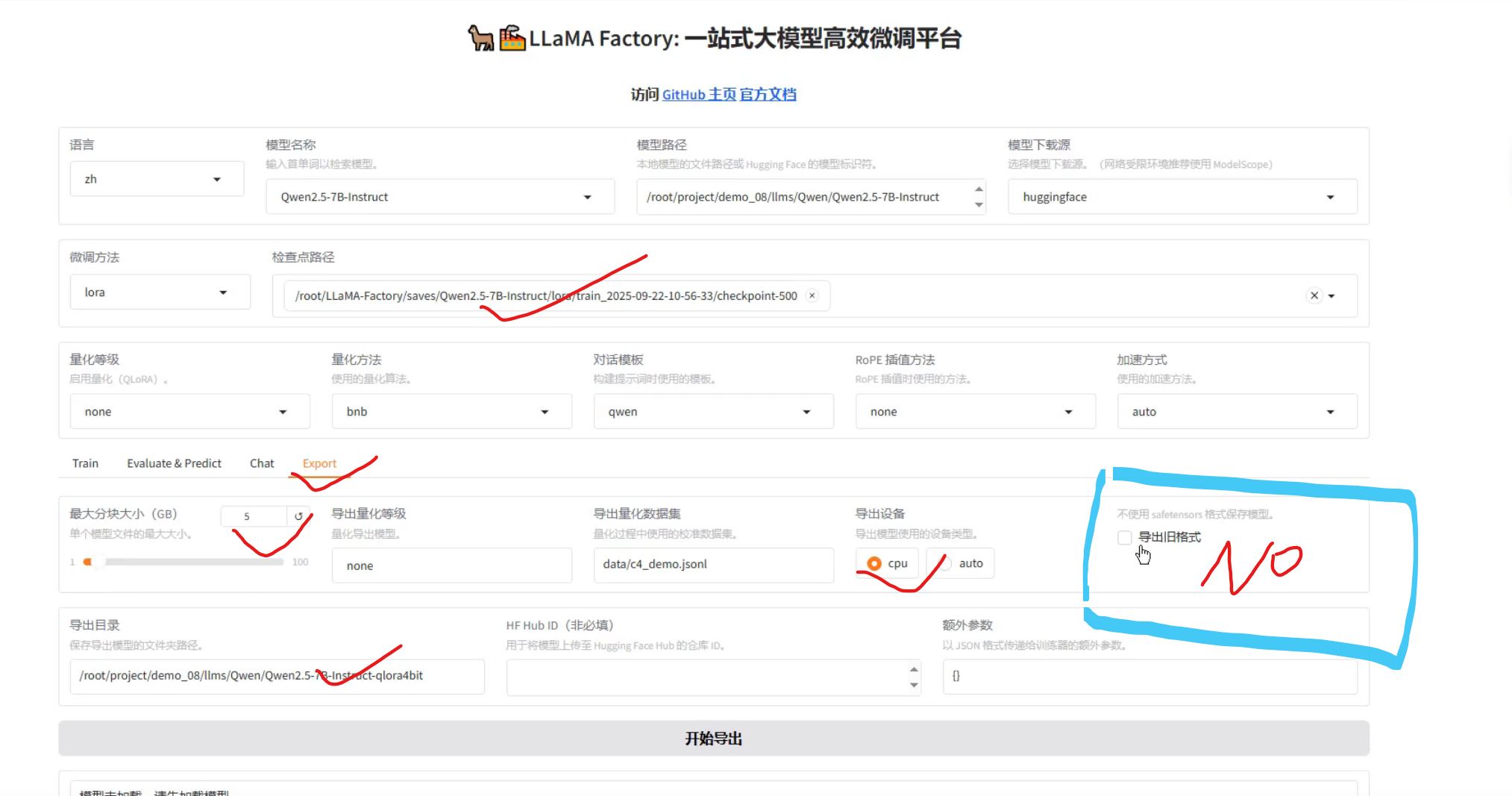
1、打包
分块:限制单个文件的大小
开始导出、完成如下

2、需要用llama.cpp仓库的convert_hf_to_gguf.py脚本来转换
建议创建一个独立的conda环境,python=3.12
git clone https://github.com/ggerganov/llama.cpp.git
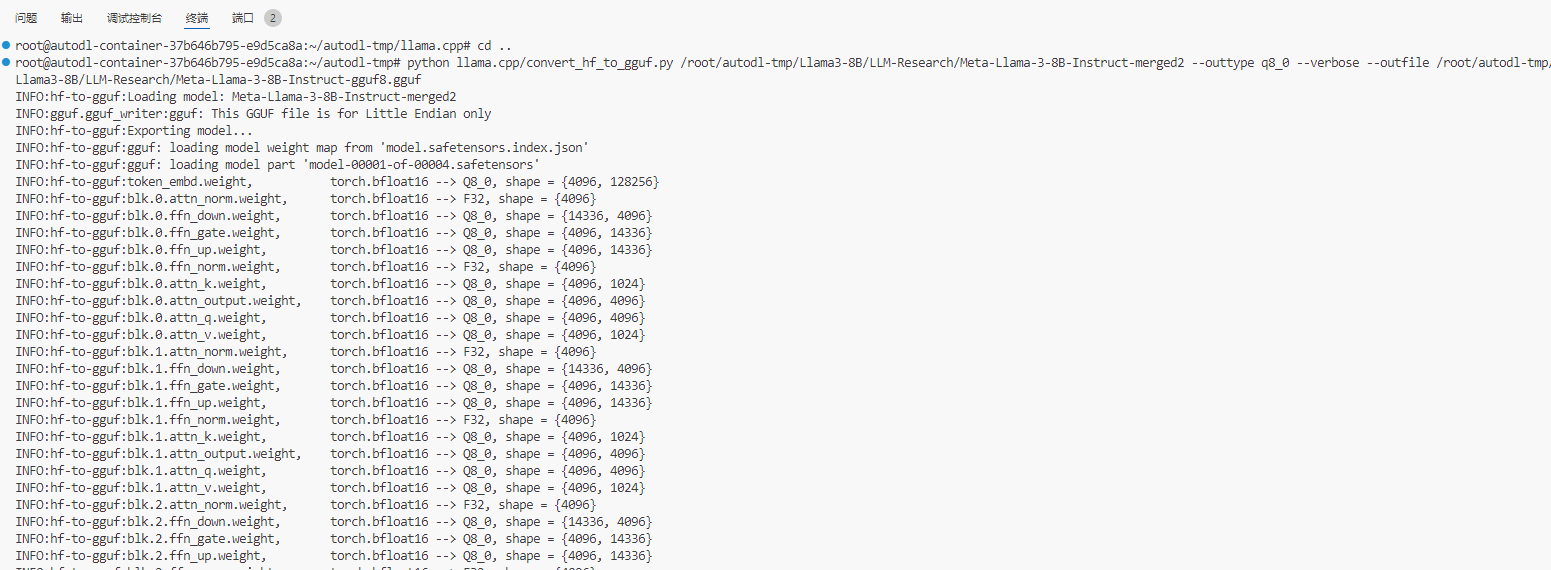
pip install -r llama.cpp/requirements.txt 3、 执行转换
# 如果不量化,保留模型的效果 python llama.cpp/convert_hf_to_gguf.py ./Meta-Llama-3-8B-Instruct --outtype f16 --verbose --outfile Meta-Llama-3-8B-Instruct-gguf.ggufpython llama.cpp/convert_hf_to_gguf.py #命令
./Meta-Llama-3-8B-Instruct #打包好的模型绝对路径
--outtype f16 #类型
--verbose --outfile Meta-Llama-3-8B-Instruct-gguf.gguf #保存的目录,要带后缀.gguf
# 如果需要量化(加速并有损效果),直接执行下面脚本就可以 python llama.cpp/convert_hf_to_gguf.py ./Meta-Llama-3-8B-Instruct --outtype q8_0 --verbose --outfile Meta-Llama-3-8B-Instruct-gguf_q8_0.gguf

转换后的模型
六、 使用ollama运行gguf
1 安装ollama
curl -fsSL https://ollama.com/install.sh | sh2 创建ModelFile
复制模型路径,创建名为"ModelFile"的meta文件,内容如下
#GGUF文件路径
FROM /root/autodl-tmp/Llama3-8B/LLM-Research/Meta-Llama-3-8B-Instruct-gguf8.gguf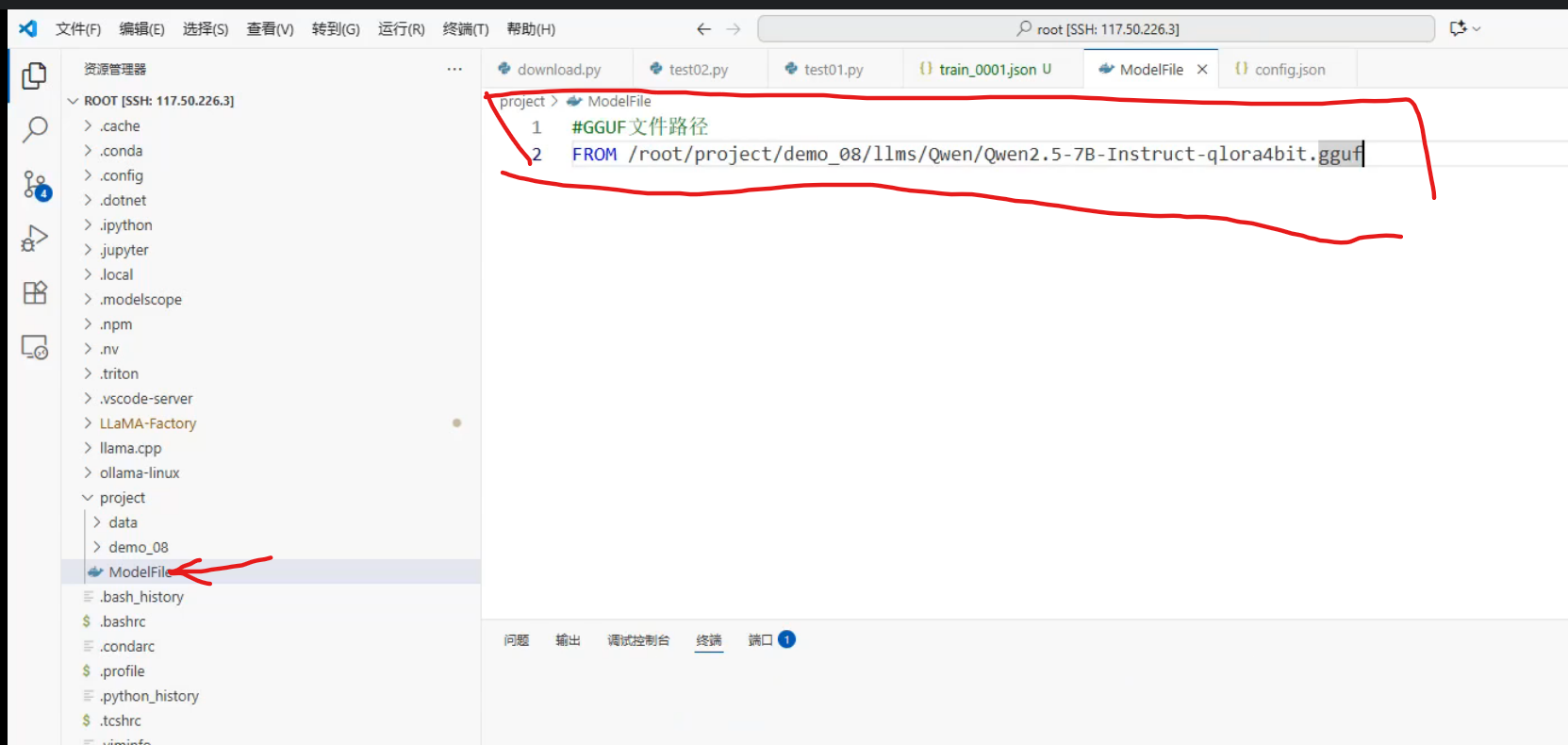
3 启动ollama服务
ollama serve4 创建自定义模型
使用ollama create命令创建自定义模型
llama-3-8B-Instruct #定义的名称
ollama create llama-3-8B-Instruct --file ./ModeFile 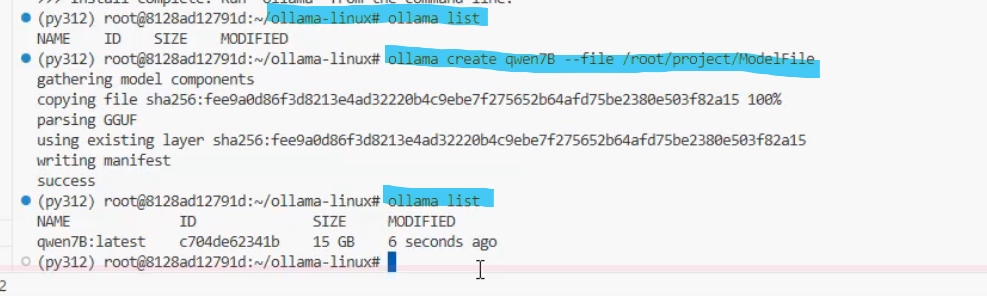
5 运行模型:
ollama run llama-3-8B-Instruct 
