大模型微调技术完全指南:从原理到实践的系统性入门(2026 版)

文章目录
- [大模型微调技术完全指南:从原理到实践的系统性入门(2026 版)](#大模型微调技术完全指南:从原理到实践的系统性入门(2026 版))
-
- 本文结构
- [1. 什么是大模型微调?先建立正确的心智模型](#1. 什么是大模型微调?先建立正确的心智模型)
-
- 一句话定义
- 关键类比
- 成本差异有多大?用数字说话
- [微调 vs 提示工程 vs RAG:怎么选?](#微调 vs 提示工程 vs RAG:怎么选?)
- [2. 为什么要做微调?五个核心驱动力](#2. 为什么要做微调?五个核心驱动力)
-
- [驱动力 1:风格和格式控制](#驱动力 1:风格和格式控制)
- [驱动力 2:领域知识内化](#驱动力 2:领域知识内化)
- [驱动力 3:降低推理成本](#驱动力 3:降低推理成本)
- [驱动力 4:数据隐私与合规](#驱动力 4:数据隐私与合规)
- [驱动力 5:减少推理时延](#驱动力 5:减少推理时延)
- [快速回答:2026 年做微调和 2022 年有什么不同?](#快速回答:2026 年做微调和 2022 年有什么不同?)
- [3. 微调技术的发展史:一条清晰的演化路线](#3. 微调技术的发展史:一条清晰的演化路线)
- [4. 2026 年的微调方法全景图](#4. 2026 年的微调方法全景图)
-
- 方法分类
- [LoRA 的 2024 年进化:主要变体一览](#LoRA 的 2024 年进化:主要变体一览)
- [多模态微调:2024-2026 的重要方向](#多模态微调:2024-2026 的重要方向)
- [合成数据:2024 年微调实践的关键趋势](#合成数据:2024 年微调实践的关键趋势)
- 模型合并:不训练也能"微调"
- 怎么选?一张决策表
- [5. 动手实践:从零开始微调一个模型](#5. 动手实践:从零开始微调一个模型)
-
- 你需要什么
- 如何获取高质量训练数据?
- 主流工具对比
- 训练加速技术:让微调跑得更快
- [最小可行实践:用 LLaMA-Factory 微调 Qwen2.5-7B](#最小可行实践:用 LLaMA-Factory 微调 Qwen2.5-7B)
- [常见中文开源基座模型推荐(2026 年 5 月更新)](#常见中文开源基座模型推荐(2026 年 5 月更新))
- 微调完成后如何部署?
- [6. 如何评估微调效果?](#6. 如何评估微调效果?)
-
- 评估体系(由浅到深)
- 关键监控信号
- [微调效果到底能提升多少?实际 Benchmark 数据](#微调效果到底能提升多少?实际 Benchmark 数据)
- [7. 常见坑和避坑指南](#7. 常见坑和避坑指南)
-
- [坑 1:数据质量不够就堆数量](#坑 1:数据质量不够就堆数量)
- [坑 2:过拟合](#坑 2:过拟合)
- [坑 3:灾难性遗忘](#坑 3:灾难性遗忘)
- [坑 4:LoRA rank 设置不当](#坑 4:LoRA rank 设置不当)
- [坑 5:评估方法不对](#坑 5:评估方法不对)
- [坑 6:学习率设置错误](#坑 6:学习率设置错误)
- [坑 7:MoE 模型微调的特殊注意事项](#坑 7:MoE 模型微调的特殊注意事项)
- 微调效果不好怎么办?退出策略
- [8. 实战选择:遇到问题时怎么选](#8. 实战选择:遇到问题时怎么选)
- [9. 负责任的微调:安全与伦理](#9. 负责任的微调:安全与伦理)
- 总结:一张图理解大模型微调
- 参考资料
30 秒速览:微调是让通用大模型学会特定技能的过程。2026 年,用 QLoRA + 1000 条高质量数据 + 一张 RTX 4090,你就能在几小时内让 7B-9B 参数模型变成领域专家。本文从"什么是微调"讲到"怎么实操",覆盖完整方法演进(LoRA→QLoRA→DPO→GRPO)和 2026 年最佳实践。文章信息更新至 2026 年 5 月。
你可能已经用过 ChatGPT、文心一言或通义千问,对大语言模型的能力感到惊叹。但当你想让它专门为你的业务工作时------比如用你公司的风格写客服回复、按你的代码规范生成代码、或者理解你行业的专业术语------你会发现通用模型总是差那么一点意思。
这就是微调(Fine-tuning) 要解决的问题。
在读这篇文章之前,先问自己几个问题:
- 为什么一个训练了万亿 token 的大模型,还需要额外"再训练"?
- 微调和从零训练有什么区别?代价差多少?
- LoRA、QLoRA 这些名字到底在说什么?它们解决了什么问题?
- 2026 年做微调,和 2022 年有什么不同?
- 我自己能不能在一张消费级显卡上微调一个 70 亿参数的模型?
这篇文章会系统地回答这些问题。我们从最基本的概念讲起,沿着技术发展的时间线走一遍,最后给出 2026 年做微调的实践路线图。
本文结构
本文按三条主线展开:
- 是什么 --- 微调的本质和与其他方法的区别
- 为什么 --- 什么场景需要微调,什么场景不需要
- 怎么做 --- 从全量微调到 LoRA 到对齐训练,方法演进和实操指南
每个部分都会回答一个核心问题,并配合图示帮你建立心智模型。
1. 什么是大模型微调?先建立正确的心智模型
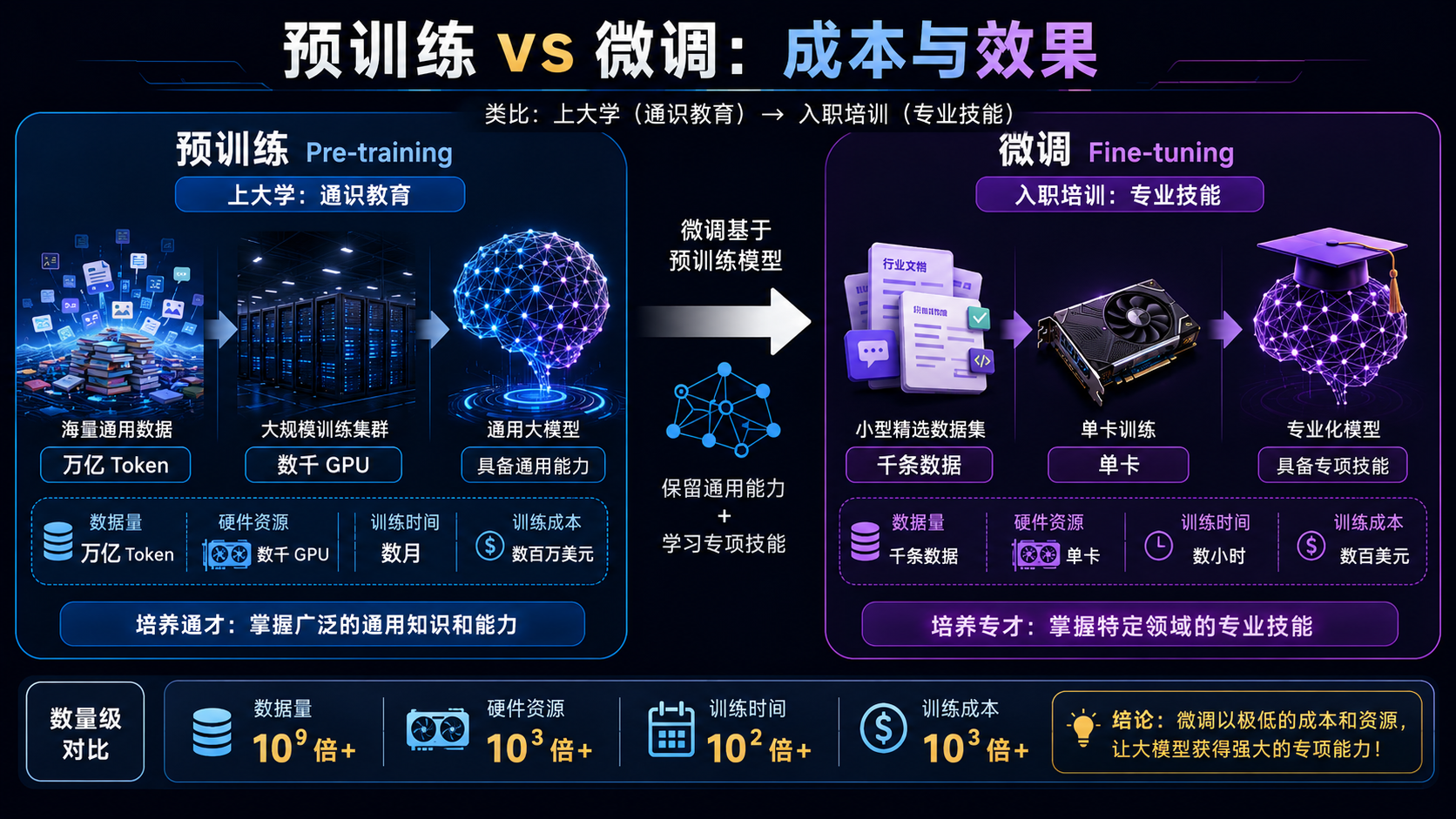
一句话定义
微调 = 在一个已经学会"通用语言能力"的预训练大模型基础上,用少量特定数据继续训练,让它学会新的技能或适应新的场景。
关键类比
把大模型想象成一个刚从综合大学毕业的学生:
- 预训练(Pre-training)= 上大学:读了海量书籍、论文、代码,掌握了通用的语言理解和推理能力。成本极高,通常需要数千张 GPU 训练数月,花费数百万到数千万美元。
- 微调(Fine-tuning)= 入职培训:针对具体岗位,用几百到几万条示例数据,花几小时到几天时间,让模型学会特定的工作方式。成本低得多,一张消费级显卡就能完成。
这不是从零开始学习,而是在已有能力基础上的"专项提升"。这是微调最重要的特征。
成本差异有多大?用数字说话
为了让你对"代价差多少"有直观感受,这里给出一组真实数字对比:
| 操作 | 以 LLaMA-2 7B 为例 | 以 LLaMA-2 70B 为例 |
|---|---|---|
| 从零预训练 | 2万亿 token、2048 张 A100、21 天、约 300 万美元 | 2万亿 token、数万张 A100、数月、约 3000 万美元 |
| 全量微调 | 需要 ~120GB 显存(含优化器状态)、多卡并行、数小时-数天 | 需要 ~1200GB 显存、16+ 张 A100 80GB |
| LoRA 微调 | ~28GB 显存、单卡 A100 即可、数小时 | ~80GB 显存、2 张 A100 即可 |
| QLoRA 微调 | ~6GB 显存、RTX 3060 即可、数小时 | ~48GB 显存、单张 A6000 或 2×RTX 4090 |
全量微调的显存开销为什么这么大? 不只是模型参数本身(7B × 2字节 = 14GB for FP16),还要加上:
- 梯度:和参数一样大(+14GB)
- 优化器状态(Adam):参数的 2 倍(+28GB)
- 激活值缓存:随 batch size 和序列长度增长
所以全量微调 7B 模型实际需要约 120GB 显存------远超单张消费级显卡。这正是 LoRA 和 QLoRA 要解决的核心痛点。
微调 vs 提示工程 vs RAG:怎么选?
初学者最常见的困惑是:什么时候用提示工程(Prompt Engineering),什么时候用 RAG,什么时候才需要微调?
| 方法 | 原理 | 适合场景 | 局限 |
|---|---|---|---|
| 提示工程 | 通过精心设计的指令引导模型行为 | 快速迭代、通用任务、预算有限 | 复杂逻辑难以用提示表达,token 消耗大 |
| RAG | 检索外部知识库,拼接到上下文中 | 需要最新信息、需要引用来源、知识库庞大 | 增加延迟,格式控制力弱 |
| 微调 | 修改模型内部参数 | 需要稳定的输出风格/格式、领域专业化、降低推理成本 | 需要训练数据和计算资源 |
| 微调 + RAG | 微调控制风格和能力,RAG 提供实时知识 | 需要同时控制格式和保证知识时效性 | 架构复杂度最高 |
决策流程图(按这个顺序判断):
你的需求是什么?
│
├─ 只是格式/风格问题 → 先试 few-shot 提示工程(零成本)
│ └─ 效果不稳定? → SFT 微调(几百条数据搞定)
│
├─ 需要专业知识 → 知识会经常更新吗?
│ ├─ 会 → RAG 优先
│ └─ 不会 → 微调(内化到模型里)
│
├─ 推理延迟要求高 → 微调小模型替代大模型
│
└─ 以上组合 → 微调 + RAG2. 为什么要做微调?五个核心驱动力
驱动力 1:风格和格式控制
通用模型的回复风格是"什么都会一点,但什么都不像你要的"。微调可以让模型稳定输出:
- 特定的 JSON 结构(如 API 返回格式)
- 公司品牌的语气和用词(如客服系统)
- 固定的代码风格和注释规范(如团队编码规范)
仅靠提示工程很难做到 100% 稳定遵循------尤其在输出复杂结构时,微调的格式一致性远胜于纯提示。
驱动力 2:领域知识内化
RAG 可以把知识"借"给模型用,但模型并没有真正理解这些知识的内在关联。微调让知识成为模型参数的一部分:
- 医疗问诊模型理解疾病之间的关联
- 法律模型掌握条文之间的引用关系
- 金融模型理解行业术语和报表逻辑
驱动力 3:降低推理成本
一个经过微调的小模型(7B 参数),在特定任务上可能达到或超过通用大模型(70B+)的效果。以实际数字为例:
- 调用闭源 API(如 GPT-4o/GPT-5.4):约 $2.5/百万输入 token(2026 年价格)
- 本地部署微调后的 Qwen2.5-7B:硬件摊销后约 $0.1-0.3/百万 token
- 成本差距:10-50 倍,且调用量越大差距越明显
驱动力 4:数据隐私与合规
如果你的数据涉及用户隐私、商业机密或合规要求(如 GDPR、等保),不能发送到第三方 API,本地部署 + 微调是唯一选择。
驱动力 5:减少推理时延
微调后的小模型本地部署,响应时间通常在 50-200ms/token;而调用云端大模型 API,网络延迟 + 排队等待通常在 500ms-2s。对实时交互场景(如代码补全、对话机器人)影响显著。
快速回答:2026 年做微调和 2022 年有什么不同?
| 对比项 | 2022 年 | 2026 年 |
|---|---|---|
| 主流方法 | 全量微调或简单 LoRA | QLoRA/DoRA + DPO/SimPO/GRPO |
| 硬件门槛 | 多张 A100(数万美元) | 单张 RTX 4090(~1万元) |
| 数据需求 | 数万-数十万条 | 1000-5000 条精选数据 |
| 对齐训练 | RLHF(极复杂,仅大厂能做) | DPO/KTO/GRPO(简单,人人可做) |
| 工具成熟度 | 需要自己写训练脚本 | LLaMA-Factory/Unsloth Web UI 零代码 |
| 可选基座模型 | LLaMA-1、BLOOM(质量一般) | Qwen3.5/3.6、DeepSeek-R1、LLaMA 4(质量极高+多模态+MoE) |
| 新兴方向 | 无 | 小模型微调(SLM)、Evolution Strategies(无梯度微调)、Agentic 微调 |
一句话总结:2026 年,用 1/20 的成本和 1/10 的数据量,可以达到 2022 年同等或更好的微调效果。9B 开源模型微调后可匹敌 120B 级别的闭源模型。
3. 微调技术的发展史:一条清晰的演化路线
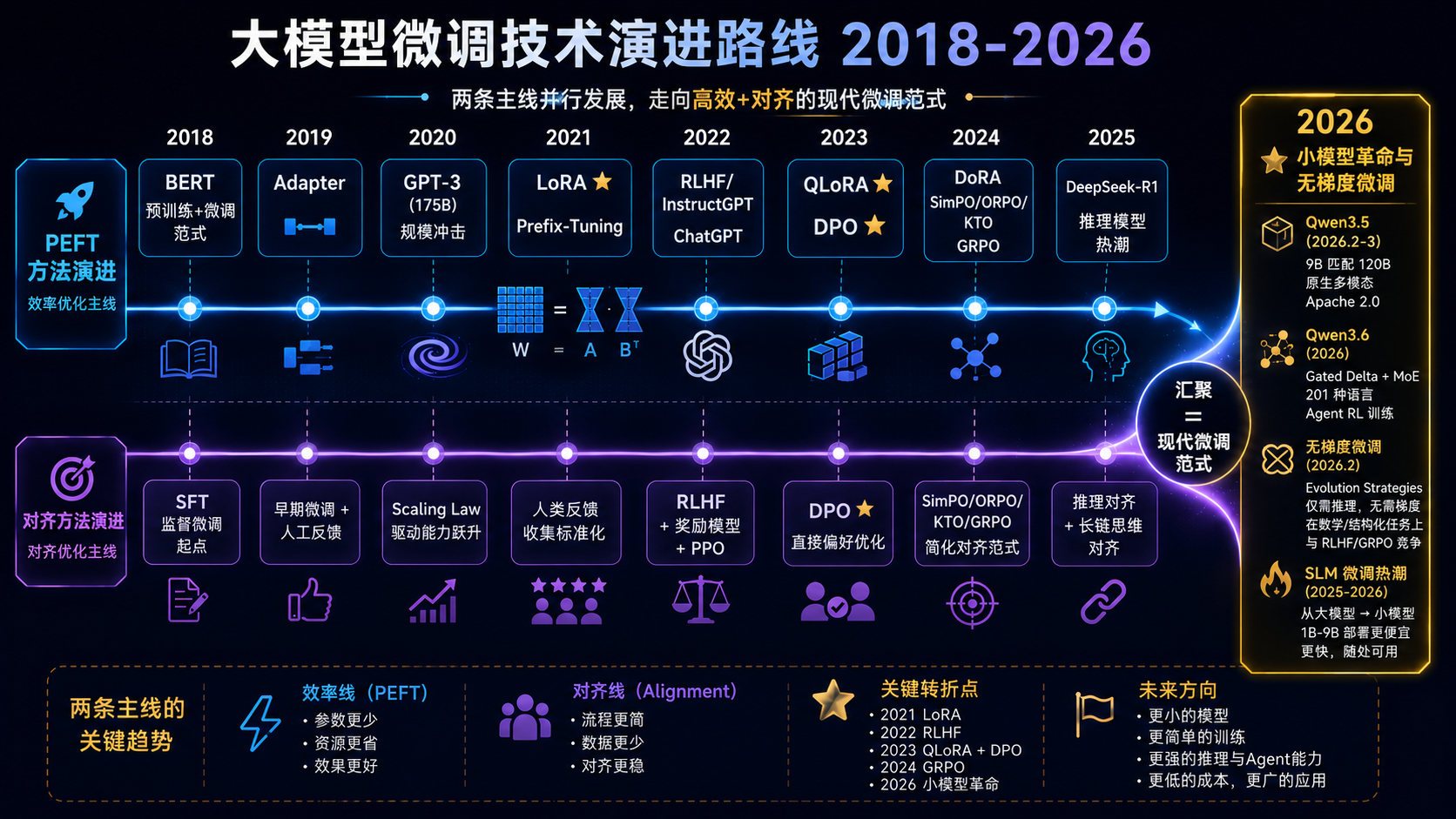
阅读提示 :下面会出现很多方法名称。你不需要记住每一个------只需要理解一个核心趋势:研究者一直在想办法用更少的资源达到更好的效果。每个新方法都是对上一个方法的"省钱或提效升级"。我会用 ⭐ 标记最重要的里程碑,用简单类比解释每个方法的核心思想。
第一阶段:预训练-微调范式的确立(2018-2020)
2018 年 --- BERT 开创 "预训练 + 微调" 范式
Google 发布 BERT(3.4 亿参数),证明了一个革命性的思路:先在海量文本上无监督预训练,然后在下游任务上只需少量标注数据微调,就能刷新几乎所有 NLP 榜单。
这个范式的核心发现是:通用的语言理解能力是可以迁移的。你不需要为每个任务从零训练一个模型。
当时的微调很简单:模型不大(1-3 亿参数),单张 GPU 就能跑,整个模型的所有参数都更新(全量微调)。这就像一个小团队的创业公司------所有人都参与所有工作,管理成本不高。
2020 年 --- GPT-3 带来规模冲击
OpenAI 发布 GPT-3(1750 亿参数)。模型突然大了 500 倍,全量微调变得不现实------全量微调 GPT-3 需要 至少 1.2TB 显存(约 15 张 A100 80GB),单次训练成本数十万美元。
这个规模断裂催生了两条技术路线:
- 参数高效微调(PEFT):只训练少量参数就能达到类似效果
- 对齐训练(Alignment):让模型不只是"能力强",还要"听话、安全、有帮助"
术语说明:"PEFT"(Parameter-Efficient Fine-Tuning)这个统称是后来才流行的。早期各方法(Adapter、Prefix-Tuning 等)各自独立发展,直到 2022 年 Hugging Face 发布 PEFT 库后,这个术语才成为通用框架性概念。
第二阶段:参数高效微调的崛起(2019-2023)
模型越来越大,但资源有限的团队和个人也需要微调。这个矛盾推动了一系列"花小钱办大事"的方法。
2019 --- Adapter(适配器):在模型里加"小旁路"
Google 的 Houlsby 等人提出在 Transformer 每一层插入小型 Adapter 模块。微调时冻结原始模型,只训练 Adapter(约 3.6% 的参数)。
类比:把一条高速公路(原模型)冻结不动,在每个收费站旁边加一条专用匝道(Adapter)。车辆(数据)通过匝道时会被"定制化处理",但高速公路本身不变。
- 核心思想:不动原模型,加一个小旁路
- 效果:在 GLUE 基准上达到全量微调 99.6% 的性能
- 局限:推理时增加延迟(每一层都多了额外计算),且 Adapter 不能合并回主网络
2021 --- Prefix-Tuning 和 Prompt Tuning:只学"怎么提问"
斯坦福 Li & Liang 提出 Prefix-Tuning:在模型每一层的注意力机制前面插入可学习的"虚拟前缀"向量,只训练这些向量(~0.1% 参数)。模型本身完全不动。
Google 的 Lester 等人进一步简化为 Prompt Tuning:只在输入层加可学习的 soft token,更简单。
类比:你不改造工厂的生产线(模型参数),而是改变给工厂的"生产订单"(输入前缀)。订单写得好,同一条生产线就能产出不同的产品。
- 核心思想:模型不动,只学"怎么提问"
- 效果:模型越大效果越好。在 10B+ 参数模型上接近全量微调
- 局限:小模型效果不佳;前缀长度会占用上下文窗口
2021 --- LoRA:改变游戏规则的方法 ⭐
微软的 Edward Hu 等人提出 LoRA(Low-Rank Adaptation),这是目前最广泛使用的微调方法。
核心洞察 :研究者发现,模型在微调过程中的权重变化量(ΔW)是低秩的------也就是说,看起来巨大的参数变化,实际上可以用两个小矩阵的乘积来精确近似。
类比 :想象一个 4096×4096 的巨大电子屏幕(权重矩阵 W)。全量微调相当于逐个像素修改这 1677 万个点。LoRA 的发现是:你要做的修改,其实只相当于画 16 条线就能组合出来(低秩 = 只需要很少的基本方向就能表达)。
具体做法:
原始权重: W (d×d 矩阵,比如 4096×4096 = 16,777,216 个参数)
LoRA 分解: ΔW = B × A
其中 B 是 4096×16 矩阵(65,536 个参数)
其中 A 是 16×4096 矩阵(65,536 个参数)
r=16 就是"秩",控制表达能力
训练时:冻结 W,只训练 A 和 B(共 131,072 个参数)
推理时:把 B×A 直接加到 W 上,变成 W' = W + BA,没有额外开销参数量从 16,777,216 降到 131,072,减少了 128 倍。
LoRA 的四个关键优势:
- 参数量极小:可训练参数只有全量微调的 0.01%-1%
- 零推理开销:训练完成后 B×A 可以合并回 W,推理时没有任何额外计算
- 可插拔:同一个基础模型可以搭配不同的 LoRA 适配器,切换任务只需切换一个小文件
- 效果接近全量微调:在多数任务上达到全量微调 95-100% 的性能
2023 --- QLoRA:让消费级 GPU 也能微调大模型 ⭐
华盛顿大学的 Dettmers 等人提出 QLoRA,核心思想是把基础模型量化到 4-bit 精度(大幅压缩体积),再在这个压缩版本上训练 LoRA 适配器。
类比:LoRA 是"只改 16 条线",QLoRA 进一步说"你连那个大屏幕本身都不用高清显示------用标清版本做参考就够了"。参考画面模糊一点不影响你画新的线。
三项关键创新:
- NF4(4-bit NormalFloat):专门为正态分布权重设计的 4-bit 量化格式,信息损失最小
- 双重量化(Double Quantization):连量化本身用到的缩放常数也做量化,每个参数再省 0.37 bit
- 分页优化器(Paged Optimizers):当 GPU 显存满时,自动把优化器状态卸载到 CPU 内存
结果:
| 对比项 | 全量微调 LLaMA-65B | QLoRA 微调 LLaMA-65B |
|---|---|---|
| 显存需求 | ~780GB(约 10 张 A100) | ~48GB(1 张 A6000) |
| 训练成本 | 数万美元 | 数百美元 |
| 效果 | 最佳基线 | 达到 ChatGPT 99.3% 的效果(Guanaco) |
QLoRA 是微调民主化的关键转折点------个人开发者用一张 RTX 4090 就能微调 330 亿参数的模型。
第三阶段:对齐训练与推理能力的演进(2022-2026)
训练模型"有能力"只是第一步,还需要让它"听话、安全、有帮助"。这就是对齐训练要解决的问题。
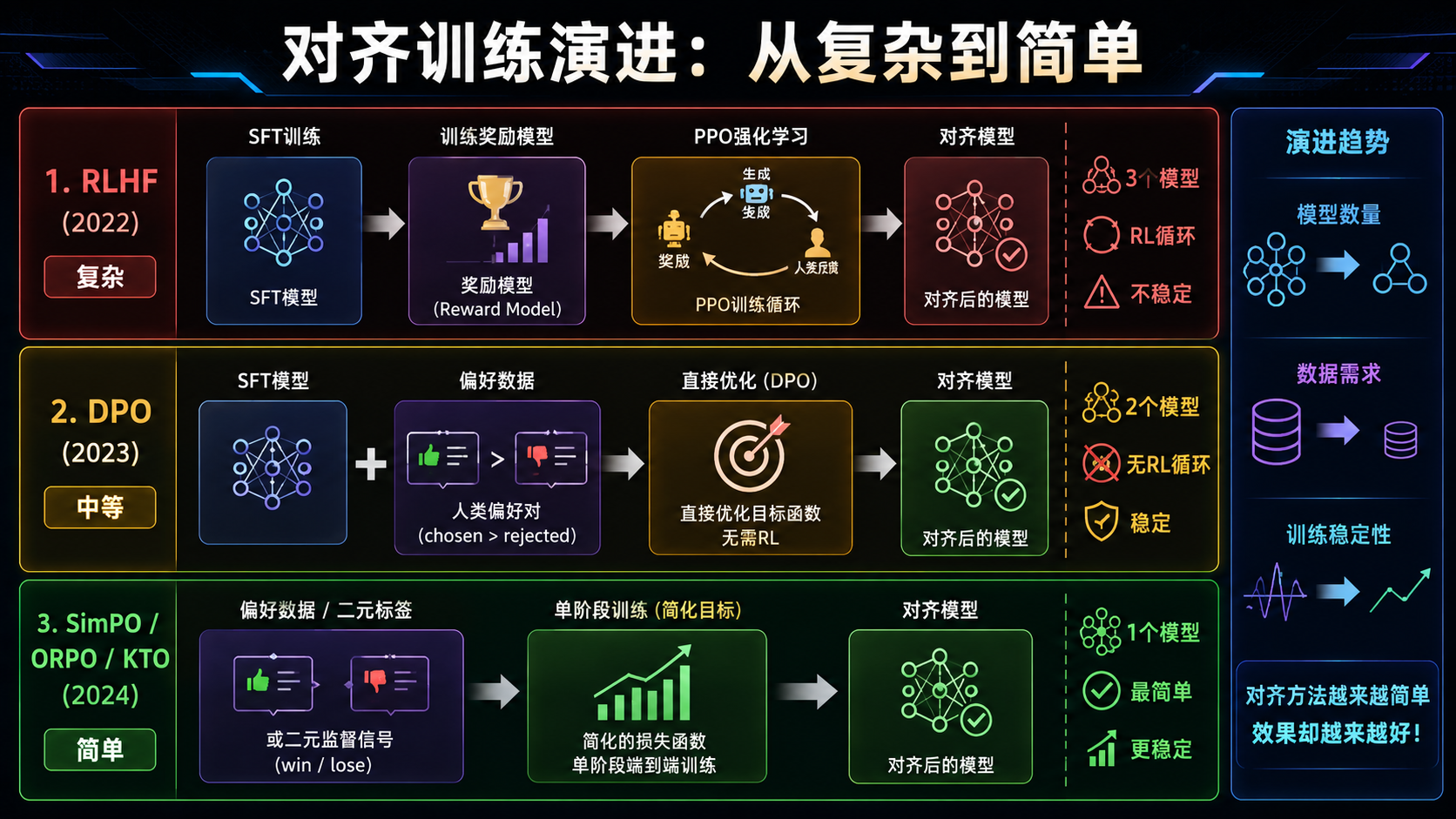
对齐训练和 SFT 有什么区别? SFT(监督微调)教模型"怎么回答"------给什么指令就照着做。对齐训练教模型"什么是好的回答"------在多个可能的回答中选择更好的那个。SFT 是教动作,对齐是教判断。
2022 --- RLHF:基于人类反馈的强化学习 ⭐
RLHF(Reinforcement Learning from Human Feedback)的概念最早由 Christiano 等人在 2017 年 提出(论文 "Deep Reinforcement Learning from Human Preferences"),但真正大规模落地是在 2022 年 OpenAI 的 InstructGPT 论文中。ChatGPT 正是基于这套方法训练出来的。
InstructGPT 建立的三阶段流水线:
阶段 1:SFT(监督微调)
输入:人工编写的高质量 "指令→回答" 示范
目标:让模型学会基本的指令遵循能力
阶段 2:训练奖励模型(Reward Model)
输入:同一个问题的多个回答 + 人类排序(哪个更好)
目标:训练一个"打分器",能预测人类偏好
阶段 3:PPO 强化学习
过程:让模型生成回答 → 奖励模型打分 → 用 PPO 算法强化高分行为
目标:让模型学会产生人类偏好的回答一个 13 亿参数的 InstructGPT 被人类评价者认为比 1750 亿参数的 GPT-3 更好------证明对齐比单纯的规模更重要。
但 RLHF 很复杂:
- 需要训练额外的奖励模型(成本翻倍)
- PPO 训练极不稳定,超参数敏感
- 需要在训练过程中反复采样生成(很慢)
- 实现难度高,debug 困难
2023 --- DPO:把 RLHF 简化成一个分类问题 ⭐
斯坦福的 Rafailov 等人做了一个优雅的数学推导:RLHF 的最优策略可以用闭式解表达。这意味着你完全不需要训练奖励模型、不需要 RL 循环、不需要采样------直接用偏好数据训练一个简单的 loss 函数就行。
DPO 为什么是里程碑? 它消除了 RLHF 中最复杂和最不稳定的部分(奖励模型 + PPO),把对齐训练的门槛从"只有大厂能做"降低到"任何能做 SFT 的团队都能做"。
训练数据格式极其简单:
json
{
"prompt": "如何减肥?",
"chosen": "科学减肥需要结合合理饮食和适量运动...(详细、负责任的回答)",
"rejected": "你可以试试三天断食法...(不负责任的回答)"
}DPO 迅速成为 2023-2024 年开源社区最广泛使用的对齐方法。
2024 --- 更简单、更高效的对齐方法涌现
DPO 虽然已经很简单,但研究者们继续简化流程、降低数据需求:
| 方法 | 核心创新 | 数据需求 | 相比 DPO 的优势 |
|---|---|---|---|
| SimPO (2024.5) | 用平均 log 概率做隐式奖励 | 偏好对 | 无需参考模型(省内存),AlpacaEval 2 高出 6.4 分 |
| ORPO (2024.3) | 把 SFT 和对齐合并成一阶段 | 偏好对 | 不需要单独的 SFT 阶段,总训练时间减半 |
| KTO (2024.2) | 基于前景理论,只需点赞/踩 | 好/坏标签 | 不需要成对偏好数据,数据收集成本最低 |
| GRPO (2024.2) | 群组相对策略优化,去掉 critic 模型 | 结果奖励 | 定位不同于上述方法:核心价值在推理/数学任务训练,是 DeepSeek-R1 的技术基础 |
注意:SimPO/ORPO/KTO 解决的是"通用对齐如何更简单",而 GRPO 解决的是"如何通过 RL 提升推理能力"。它们是互补的方向,不是同一条简化路线。
对齐方法的演进趋势:越来越简单、越来越少的数据需求、越来越低的训练成本。从 RLHF 需要 3 个模型 + RL 循环,到 DPO 需要 2 个模型 + 偏好对,到 ORPO/SimPO 只需要 1 个模型,到 KTO 只需要点赞/踩标签。
2025 --- DeepSeek-R1:纯强化学习激发推理能力
DeepSeek 发现,不需要用人类标注的推理过程作训练数据,只通过 GRPO + 结果奖励(答案对不对),模型就能自发涌现出推理链、自我检查和策略切换等高级行为。
这项工作于 2025 年 1 月发布(arXiv:2501.12948),是对齐训练思想的一次重要延伸:RL 不只是让模型"更听话",还能让模型"更聪明"。这直接催生了 2025-2026 年"推理模型"的研发热潮------多个中国团队用 GRPO 训练各自的推理模型。
2025-2026 --- 最新发展:小模型革命与无梯度微调
- Qwen3.5(2026.2-3):9B 参数的开源模型在 GPQA Diamond 上匹配 120B 级闭源模型,原生多模态(文本+图像+视频),Apache 2.0 许可
- Qwen3.6(2026):引入 Gated Delta Networks + MoE 混合架构,201 种语言,百万级 Agent RL 训练,专注 Agentic 能力
- Evolution Strategies for LLM Fine-tuning(2026.2,Cognizant):gradient-free、仅需推理的微调方法,在数学推理和 Sudoku/ARC-AGI 等结构化任务上与 RLHF/GRPO 竞争,不需要计算梯度
- SLM(小语言模型)微调热潮:2025-2026 年的趋势从"微调大模型"转向"微调 1B-9B 小模型"------在消费级设备上部署,成本更低,速度更快
4. 2026 年的微调方法全景图
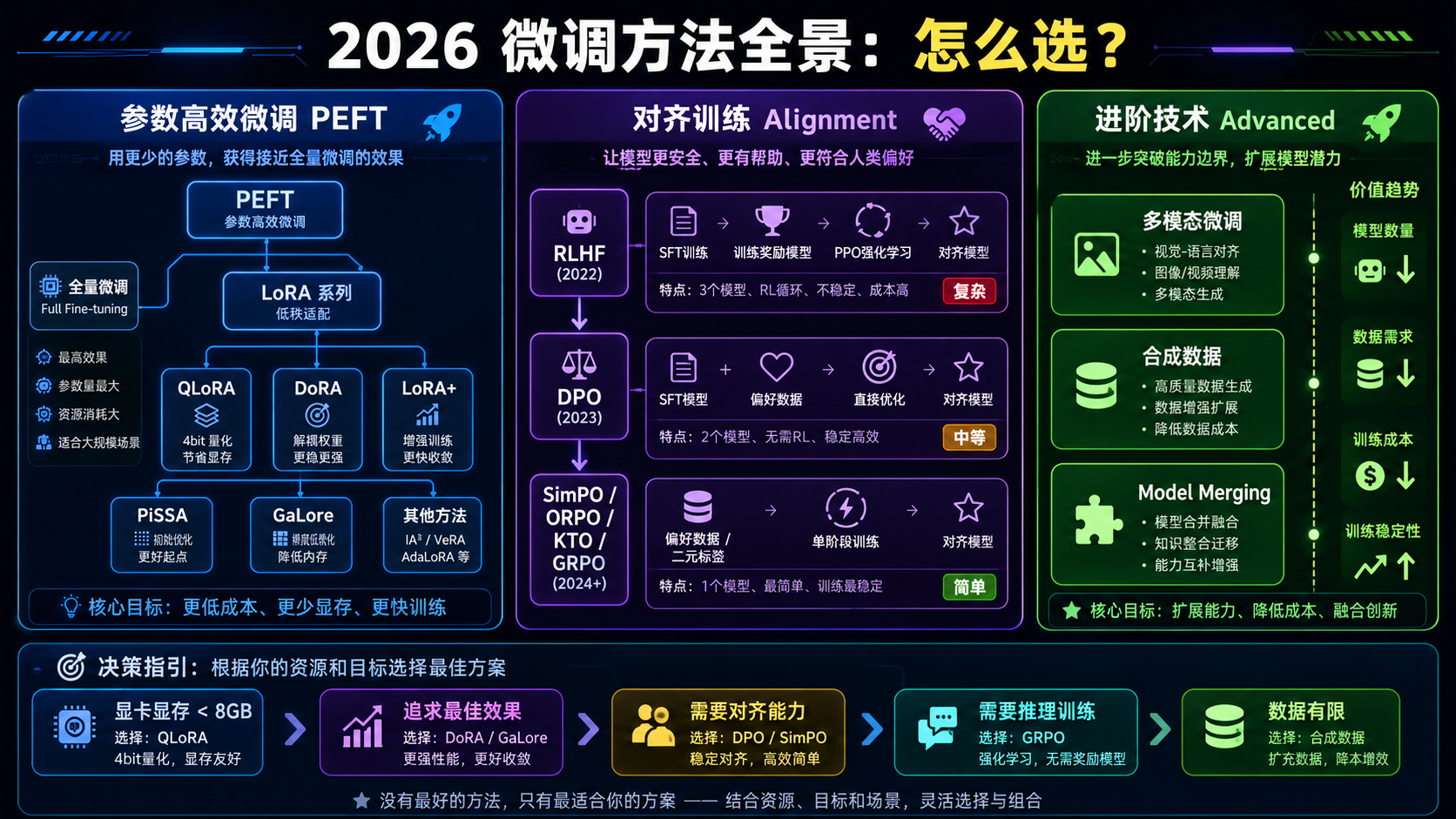
方法分类
大模型微调
├── 全量微调 (Full Fine-tuning)
│ └── 更新所有参数。效果天花板最高,但需要巨大显存
│
├── 参数高效微调 (PEFT)
│ ├── LoRA 系列(最主流)
│ │ ├── LoRA (2021) --- 低秩适配,行业标准
│ │ ├── QLoRA (2023) --- 4-bit 量化 + LoRA,最省显存 ⭐
│ │ ├── DoRA (2024) --- 权重分解为幅度+方向,缩小与全量微调的差距
│ │ ├── LoRA+ (2024) --- A/B 矩阵用不同学习率,训练快 2x
│ │ ├── rsLoRA (2023) --- 修正缩放因子,高 rank 时效果更好
│ │ └── PiSSA (2024) --- SVD 初始化 LoRA,起点更优
│ ├── GaLore (2024) --- 梯度低秩投影,兼具全参数学习质量和 LoRA 级内存效率
│ ├── Prompt/Prefix Tuning (2021) --- 只学习输入提示向量,极致轻量
│ └── Adapter (2019) --- 插入小型适配层,历史方法
│
├── 对齐训练 (Alignment)
│ ├── RLHF/PPO (2017/2022) --- 经典三阶段,效果好但复杂
│ ├── DPO (2023) --- 直接偏好优化,简单稳定 ⭐
│ ├── SimPO (2024) --- 无参考模型,效果超 DPO
│ ├── ORPO (2024) --- SFT+对齐一步完成
│ ├── KTO (2024) --- 只需二元反馈(最低数据门槛)
│ └── GRPO (2024) --- 推理能力训练首选(DeepSeek-R1 验证)
│
├── 新兴方向 (2025-2026)
│ ├── Evolution Strategies --- 无梯度微调,仅需推理,不需反向传播
│ ├── Agentic 微调 --- 训练模型使用工具、多步规划、自主行动
│ └── SLM 微调 --- 1B-9B 小模型微调后部署到端侧/边缘设备
│
└── 进阶技术
├── 多模态微调 --- 视觉-语言模型(LLaVA、Qwen-VL、Qwen3.5)的微调
├── 模型合并 (Model Merging) --- 不训练,直接合并多个模型权重
└── 合成数据微调 --- 用强模型生成训练数据LoRA 的 2024 年进化:主要变体一览
LoRA 是 2021 年提出的,但 2024 年涌现了大量改进。对比如下:
| 方法 | 核心改进 | 相比标准 LoRA 的提升 | 额外成本 |
|---|---|---|---|
| DoRA | 把权重拆成幅度和方向,LoRA 只改方向 | 多项任务提升 1-3%,更接近全量微调 | 零额外推理开销 |
| LoRA+ | A 和 B 矩阵用不同学习率 | 训练速度快 2x,精度提升 1-2% | 零额外成本 |
| PiSSA | 用 SVD 初始化(让可训练部分从"重要方向"开始) | GSM8K 提升 5+ 百分点 | 初始化多花几秒 |
| rsLoRA | 缩放因子从 1/r 改为 1/√r | 高 rank 时训练更稳定 | 零额外成本 |
| GaLore | 投影梯度而非权重(全参数学习) | 不受低秩限制,适合高要求场景 | 略慢 |
实用建议:如果你已经在用 LoRA,最容易的升级是 LoRA+(只改学习率配置)和 DoRA(一行代码切换)。
多模态微调:2024-2026 的重要方向
随着 GPT-4V、Qwen-VL、LLaVA 等多模态模型的普及,多模态微调成为新热点。核心区别:
- 文本模型微调:只处理文本输入输出
- 多模态微调:同时处理图像+文本,需要决定"冻结视觉编码器还是一起训练"
典型流程(以 LLaVA 为例):
- 阶段一:冻结视觉编码器和语言模型,只训练连接层(对齐视觉和语言表征)
- 阶段二:冻结视觉编码器,微调语言模型(学会理解图像内容并生成回答)
工具支持:LLaMA-Factory、Unsloth 2024 年均已支持多模态模型的 LoRA 微调。
合成数据:2024 年微调实践的关键趋势
核心思想:用强模型(如 GPT-4、Claude)生成高质量训练数据,用来微调较小的模型。
为什么这很重要?因为高质量人工标注数据贵、慢、难以规模化。而用强模型生成:
- 成本低 10-100 倍
- 速度快(小时级 vs 周级)
- 质量可控(可以设计提示词控制输出质量)
关键方法:
- Self-Instruct (2022):让模型自己生成指令-回答对
- Evol-Instruct (WizardLM, 2023):逐步增加指令复杂度
- LIMA 原则 (2023):只需 1000 条精选数据就能达到惊人效果
2024-2026 共识:数据质量 >> 数据数量。1000-5000 条高质量合成数据通常优于 10 万条粗糙数据。
模型合并:不训练也能"微调"
2024 年兴起的一种零成本方法------直接把多个已微调模型的权重按规则合并:
- TIES (2023):解决合并时的参数冲突
- DARE (2023):随机丢弃 delta 参数后合并
- Evolutionary Merging (Sakana AI, 2024):用进化算法搜索最优合并配方
适用场景:你想要一个模型同时具备 "代码能力强" 和 "中文对话好" 两个特性,可以把分别擅长这两项的模型合并起来。
局限:效果不如专门训练一个多能力模型,且合并结果不完全可控。
怎么选?一张决策表
| 你的情况 | 推荐方法 | 理由 |
|---|---|---|
| 刚入门,想快速跑通 | QLoRA + LLaMA-Factory | 最低门槛,Web UI 操作 |
| 单卡 24GB,微调 7B 模型 | QLoRA (rank 16-64) | 显存占用约 6-12GB |
| 追求最佳效果,不在乎成本 | 全量微调或 GaLore | 不受低秩约束 |
| 想在 LoRA 基础上提升效果 | DoRA 或 PiSSA | 即插即用替换 LoRA |
| 让模型更安全、更听话 | DPO 或 SimPO | 数据格式简单,训练稳定 |
| 只有好/坏标注,没有偏好对 | KTO | 数据需求最低 |
| 训练推理/数学能力 | GRPO | DeepSeek-R1 验证有效 |
| 想一步完成 SFT + 对齐 | ORPO | 节省训练流程 |
| 合并已有模型能力,不想训练 | Model Merging | 零训练成本 |
| 微调多模态模型 | LLaMA-Factory + LoRA | 冻结视觉编码器,只微调 LLM |
5. 动手实践:从零开始微调一个模型
你需要什么
硬件最低要求(QLoRA 方式):
| 模型大小 | 最低显存 | 推荐显卡 | 预计训练时间(1000 条数据) |
|---|---|---|---|
| 1.5B-3B | 4GB | RTX 3060 | 10-30 分钟 |
| 7B | 6GB | RTX 3060 12GB | 30-60 分钟 |
| 13B-14B | 12GB | RTX 4070 12GB | 1-3 小时 |
| 32B-34B | 24GB | RTX 4090 | 3-8 小时 |
| 70B | 48GB | A6000 或 2×RTX 4090 | 8-24 小时 |
数据准备指南:
| 微调类型 | 数据量建议 | 数据格式 | 关键质量要求 |
|---|---|---|---|
| 格式/风格适配 | 200-1000 条 | 指令-回答对 | 格式完全一致,回答示范标准 |
| 领域知识注入 | 1000-5000 条 | 指令-回答对 | 知识准确,覆盖关键场景 |
| 对齐训练 | 1000-10000 条 | 偏好对/二元标签 | 好坏对比清晰,边界案例充分 |
| 推理能力训练 | 5000-50000 条 | 问题-推理过程-答案 | 推理链完整正确 |
关键原则:数据质量远比数量重要。01.AI 的 Yi 模型仅用不到 1 万条精选数据就达到了极强的指令遵循能力(LIMA 原则的工业验证)。
CPT vs SFT:领域知识注入应该用哪个?
很多初学者把"领域知识注入"等同于 SFT,但实际上有两种不同的方法:
方法 全称 数据形式 作用 典型场景 CPT(继续预训练) Continued Pre-training 无标注纯文本(如法律条文、医学论文、代码库) 让模型"读懂"领域知识 模型不认识行业术语/概念 SFT(监督微调) Supervised Fine-Tuning 指令-回答对 让模型"会回答"领域问题 模型知道知识但回答格式不对 推荐路径:如果领域和通用语言差异大(如古文、法律条文、生物信息学),先 CPT 再 SFT;如果只是让模型按特定方式回答已知领域问题,直接 SFT 即可。
CPT 的数据量通常远大于 SFT(10 万-100 万 token 级别的领域文本),且使用标准的语言模型训练目标(next token prediction)。
CPT 实操要点:
- 数据准备:收集领域纯文本(PDF 论文、法规全文、行业报告),清洗后拼接成长文档
- 训练方式:在 LLaMA-Factory 中选择
finetuning_type: full或lora,stage: pt(预训练模式)- 学习率:比 SFT 更小(通常 5e-6 到 2e-5),避免覆盖通用知识
- 数据量基准:至少 50MB-500MB 的领域文本(约 2500 万-2.5 亿 token)
- 典型流程:CPT 1-2 epoch(注入知识)→ SFT 2-3 epoch(学会回答格式)→ 可选对齐
如何获取高质量训练数据?
-
人工编写:最高质量,但成本高、速度慢
-
合成数据 :用 GPT-4/Claude 生成,性价比最高
python# 用 GPT-4 批量生成训练数据的伪代码 for topic in domain_topics: prompt = f"请针对'{topic}'生成一个高质量的问答对..." response = gpt4.generate(prompt) training_data.append(response) -
开源数据集:如 Alpaca、ShareGPT、UltraChat
-
从真实用户日志中筛选:如果有产品在线,真实交互是最好的数据来源
主流工具对比
| 工具 | 特点 | 适合谁 | 2026 支持情况 |
|---|---|---|---|
| LLaMA-Factory | 全功能、Web UI、100+ 模型、方法最全 | 入门者和生产环境 | Qwen3, LLaMA 4, DeepSeek R1, GRPO |
| Unsloth | 速度快 2x、省显存 60-70%、Dynamic 2.0 量化(逐层智能量化,精度远超标准 4-bit) | 追求极致效率 | Qwen3/LLaMA 4/DeepSeek, GRPO, 长上下文, Dynamic v2.0 GGUF |
| Axolotl | YAML 配置驱动,灵活可复现 | 经验丰富的研究者 | DPO/KTO/ORPO/GRPO, 多模态 |
| HF TRL | Hugging Face 官方,与生态深度集成 | 做对齐训练的团队 | SFT/DPO/KTO/ORPO/PPO/GRPO |
| Swift (ModelScope) | 阿里出品,深度集成魔搭生态 | 使用阿里系模型的团队 | Qwen 全系列 |
| XTuner | 上海 AI Lab 出品,InternLM 首选 | InternLM 生态用户 | InternLM/多模态 |
训练加速技术:让微调跑得更快
以下技术可以在不牺牲效果的情况下显著加速训练:
| 技术 | 作用 | 加速幅度 | 使用方法 |
|---|---|---|---|
| Flash Attention 2 | 优化注意力计算的内存访问模式 | 训练速度提升 2-4x,显存省 5-20x | LLaMA-Factory 中设置 flash_attn: fa2 |
| 梯度检查点 | 用时间换空间,不缓存中间激活值 | 显存省 60-70%,速度慢 20-30% | 默认开启(gradient_checkpointing: true) |
| 混合精度训练 (BF16) | 用半精度计算,保持精度的同时加速 | 速度提升 2x | 设置 bf16: true(需要 Ampere+ GPU) |
| DeepSpeed ZeRO | 跨多卡切分优化器状态/梯度/参数 | 多卡线性扩展 | 多卡场景配置 deepspeed: ds_z2_config.json |
| Unsloth 优化 | 自定义 Triton 内核优化前向/反向传播 | 速度提升 2x + 显存省 60-70% | 使用 Unsloth 库替代标准训练 |
实用建议:入门时只需确保 Flash Attention 2 和 BF16 开启即可。这两项零成本配置就能让训练速度翻倍。
以上是优化训练效率的进阶技巧,入门时无需全部掌握。下面我们从最简单的方式开始,手把手跑通第一个微调实验。
最小可行实践:用 LLaMA-Factory 微调 Qwen2.5-7B
步骤一:环境准备
shell
# 安装(需要 Python 3.8+ 和 CUDA)
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
# 验证 GPU 可用
python -c "import torch; print(torch.cuda.is_available())"步骤二:准备数据
创建训练数据文件 data/my_dataset.json:
json
[
{
"instruction": "请用专业但友好的语气回复这个客户投诉",
"input": "你们的产品太烂了,退货退了一个月还没到账!",
"output": "非常抱歉给您带来了不好的体验。我理解退款等待过久的焦虑。我已经查询了您的退款记录,单号为 RF2024xxx,目前状态是...预计 3 个工作日内到账。如有更多问题,可以随时联系我。"
},
{
"instruction": "请用专业但友好的语气回复这个客户投诉",
"input": "买了你们的会员但是功能根本用不了!",
"output": "非常抱歉您遇到了功能使用问题。为了尽快帮您解决,请问您遇到的具体情况是:1)功能入口找不到,2)点击后报错,还是 3)其他情况?我这边为您逐一排查。"
}
]如果你的场景是多轮对话(如客服机器人),使用 ShareGPT 格式更合适:
json
[
{
"conversations": [
{"from": "human", "value": "我想退货"},
{"from": "gpt", "value": "好的,请问您的订单号是多少?"},
{"from": "human", "value": "DD20240315001"},
{"from": "gpt", "value": "已查到您的订单。请问退货原因是什么?我帮您提交退货申请。"}
]
}
]在 data/dataset_info.json 中注册:
json
{
"my_dataset": {
"file_name": "my_dataset.json",
"formatting": "sharegpt"
}
}步骤三:开始训练
方式 A --- Web UI(推荐新手):
shell
llamafactory-cli webui
# 浏览器打开 http://localhost:7860
# 在界面上选择模型、数据集、训练参数,点击"开始"方式 B --- YAML 配置文件(推荐生产使用,可复现):
创建 train_config.yaml:
yaml
### 模型配置
model_name_or_path: Qwen/Qwen2.5-7B
template: qwen
### 微调方法
finetuning_type: lora
lora_rank: 16
lora_target: all
quantization_bit: 4
### 数据集
dataset: my_dataset
preprocessing_num_workers: 4
### 训练参数
output_dir: output/qwen25-7b-my-task
per_device_train_batch_size: 4
gradient_accumulation_steps: 4
num_train_epochs: 3
learning_rate: 2.0e-4
lr_scheduler_type: cosine
warmup_ratio: 0.05
logging_steps: 10
save_steps: 500运行训练:
shell
llamafactory-cli train train_config.yaml步骤四:测试效果
shell
llamafactory-cli chat \
--model_name_or_path Qwen/Qwen2.5-7B \
--adapter_name_or_path output/qwen25-7b-my-task \
--template qwen \
--finetuning_type lora常见中文开源基座模型推荐(2026 年 5 月更新)
| 模型 | 参数量 | 许可证 | 中文能力 | 特色 | QLoRA 最低显存 |
|---|---|---|---|---|---|
| Qwen3.5 / Qwen3.6 | Dense: 0.8B-9B (Qwen3.5 Small); MoE: 235B-A22B (Qwen3.5 Plus, 1M上下文) | Apache 2.0 | 最强 | Qwen3.5(2026.2): 9B 模型匹配 120B 级性能、原生多模态;Qwen3.6: Gated Delta Networks + MoE、201 种语言、Agent RL | 9B: 6GB |
| Qwen3 | Dense: 0.6B-32B; MoE: 30B-A3B, 235B-A22B | Apache 2.0 | 极强 | Qwen3(2025.4): thinking/non-thinking 双模式切换、119 种语言 | 8B: 6GB |
| LLaMA 4 | Scout 109B(17B激活,16专家); Maverick 400B(17B激活,128专家) | Llama License | 强 | Meta 2025.4 发布,原生多模态 MoE,Scout 支持 10M token 上下文 | Scout INT4: 单卡 H100 |
| DeepSeek-V3 | 671B (MoE) | MIT | 极强 | MoE 架构推理高效 | 蒸馏版 7B: 6GB |
| DeepSeek-R1 | 蒸馏版 1.5B-70B | MIT | 极强 | 推理能力突出 | 7B: 6GB |
| GLM-4 | 9B+ | 开源 | 强 | 工具调用、Agent 能力 | 9B: 8GB |
| Yi-1.5 | 6B-34B | Apache 2.0 | 强 | 数据质量极高、200K 上下文 | 6B: 5GB |
| InternLM2.5 | 7B-20B | Apache 2.0 | 强 | 推理强、社区活跃 | 7B: 6GB |
| Gemma 3 | 1B-27B | 开源 | 中等 | Google 出品,端侧/边缘部署 | 4B: 4GB |
| MiniCPM | 2B-4B | Apache 2.0 | 中等 | 端侧部署首选 | 2B: 3GB |
选择建议(2026.5 更新) :入门微调首选 Qwen3.5-9B------Apache 2.0、原生多模态、性能匹配百亿级模型、社区工具全面支持。如果追求最新 Agentic 能力,用 Qwen3.6。如果需要 thinking 推理模式,Qwen3-8B/32B 仍是成熟选择。如果需要超长上下文(10M token),LLaMA 4 Scout 是唯一选项。DeepSeek-R1 蒸馏版仍是数学/代码推理的性价比首选。
微调完成后如何部署?
微调产出的是一个 LoRA 适配器文件(通常几十 MB)。部署方式:
| 部署方式 | 工具 | 适合场景 | 说明 |
|---|---|---|---|
| 本地测试 | LLaMA-Factory chat | 验证效果 | 上面步骤四已展示 |
| 单机生产 | Ollama | 个人/小团队 | 把 LoRA 合并后导出为 GGUF,一行命令启动 |
| 高并发生产 | vLLM | 企业级 | 支持 Multi-LoRA 热切换------同一基座加载多个 LoRA,按请求路由 |
| 云端部署 | TGI (HuggingFace) | 需要 Docker 标准化 | 原生支持 LoRA adapter 热加载 |
Multi-LoRA 的核心价值:一个基座模型同时服务多个微调场景(客服模型、代码模型、翻译模型),按请求动态加载对应的 LoRA 适配器,显存开销只有一个基座模型 + 多个小适配器。
6. 如何评估微调效果?
微调不是"训练完就结束"------你必须验证模型真的学会了你想教的东西,且没有丢掉原有能力。
评估体系(由浅到深)
| 层次 | 方法 | 适合阶段 | 衡量什么 |
|---|---|---|---|
| 1. 训练指标 | 监控 training loss 和 eval loss | 训练过程中 | 模型是否在学习、是否过拟合 |
| 2. 自动指标 | Perplexity、BLEU、ROUGE、准确率 | 训练完成后 | 和标准答案的相似度 |
| 3. 基准测试 | MMLU、C-Eval、HumanEval 等 | 验证通用能力 | 微调是否导致能力退化 |
| 4. 人工评估 | 人类评审 50-100 个测试用例 | 上线前 | 真实使用场景的回答质量 |
| 5. LLM-as-Judge | 用 GPT-4/Claude 打分 | 快速迭代 | 自动化的人类偏好近似 |
关键监控信号
好的训练过程:
- Training loss 稳定下降
- Eval loss 同步下降(差距不大)
- 基准测试分数基本持平
坏的信号(需要停止或调整):
- Eval loss 开始上升 → 过拟合,减少 epoch 或增加数据
- Training loss 很低但人工评估差 → 数据质量问题
- 基准测试分数大幅下降 → 灾难性遗忘,降低学习率微调效果到底能提升多少?实际 Benchmark 数据
很多初学者想知道:微调真的有效果吗?提升有多大?以下是经过验证的实际数据:
| 场景 | 基座模型 | 方法 | 效果提升 | 来源 |
|---|---|---|---|---|
| 通用对话质量 | LLaMA-65B | QLoRA 24小时 | 达到 ChatGPT 99.3% 水平(Vicuna 基准) | QLoRA 论文 (2023) |
| 金融任务准确率 | LLaMA-3.1-8B | LoRA/QLoRA/DoRA | 平均提升 36% 准确率(vs 未微调基线) | FinLoRA (2025) |
| 对齐质量 | Gemma-2-9B | SimPO | AlpacaEval 2 提升 6.4 分,Arena-Hard 提升 7.5 分(vs DPO) | SimPO 论文 (2024) |
| 代码生成 | StarCoder-15B → WizardCoder-15B | SFT + Evol-Instruct | HumanEval pass@1 从 33.6% 提升到 57.3% | WizardCoder 论文 arXiv:2306.08568 |
| 中文理解 | Qwen2.5-7B | LoRA SFT | C-Eval 提升 5-10 个百分点(领域数据) | LLaMA-Factory 示例 |
关键结论:
- 对于特定领域任务,LoRA/QLoRA 微调通常能带来 20-40% 的准确率提升
- 对于通用对话质量,少量高质量数据 + QLoRA 就能接近顶尖闭源模型
- 对于对齐优化,SimPO/DPO 能在已有 SFT 基础上再提升 5-8 个百分点
- LoRA 能恢复全量微调 90-95% 的效果(2025-2026 年业界共识)
7. 常见坑和避坑指南
坑 1:数据质量不够就堆数量
症状:训练 loss 下降了,但模型效果没变好甚至变差。
诊断方法:随机抽查 20 条训练数据,如果你自己觉得"这个回答不够好",数据质量就有问题。
解决方案:
- 先人工审查 100 条样本,确保每条都是"你希望模型学会的理想回答"
- 去重、去矛盾(同一个问题不要有矛盾的答案)
- 格式统一(所有样本遵循相同的格式规范)
- 考虑用 GPT-4 对数据做质量评分,过滤低分样本
坑 2:过拟合
症状:训练集 loss 接近 0,但新问题回答质量差,或者回复变得重复、死板。
诊断方法:对比 training loss 和 eval loss。如果 training loss 持续下降但 eval loss 开始上升,就是过拟合。
解决方案:
- 通常 1-3 个 epoch 就够(不要轻易超过 3 个)
- 保留 10% 数据做验证集,开启 early stopping
- 增加数据量或数据多样性
- 适当增大 lora_dropout(如 0.05-0.1)
坑 3:灾难性遗忘
症状:微调后模型在目标任务上变好了,但通用对话能力、常识推理等大幅下降。
诊断方法:微调前后分别跑一组通用基准(如 MMLU 中文、C-Eval),对比分数变化。下降超过 5% 就值得警惕。
解决方案:
- 使用 LoRA/QLoRA(天然限制了修改幅度,是最有效的防遗忘手段)
- 降低学习率(具体推荐值见下方"坑 6:学习率设置")
- 在训练数据中混入 5-10% 的通用指令数据(data replay)
- 减小 LoRA 的 rank(限制修改空间)
坑 4:LoRA rank 设置不当
症状:rank 太小导致欠拟合(模型改变不够),rank 太大导致过拟合或训练变慢。
解决方案:
| 任务复杂度 | 推荐 rank | target_modules | 说明 |
|---|---|---|---|
| 简单(格式适配) | 8-16 | q_proj, v_proj | 修改幅度小,够用 |
| 中等(风格+知识) | 16-32 | q_proj, k_proj, v_proj, o_proj | 默认安全选择 |
| 复杂(深度领域) | 32-64 | all linear layers | 2024 研究表明 all linear 效果更好 |
| 不确定 | 32 | q_proj, v_proj, up_proj, down_proj | 安全的默认值 |
坑 5:评估方法不对
症状:自动指标(loss、BLEU)很好看,但人工评估发现回答质量不行。
解决方案:
- 永远要有人工评估环节------自动指标只是筛选用的
- 准备 50-100 个代表性测试用例,覆盖正常情况和边界情况
- 用 LLM-as-Judge 方式做快速迭代(让 GPT-4 对比打分)
- A/B 测试:同时看微调前和微调后的回答,盲评打分
坑 6:学习率设置错误
症状:训练 loss 剧烈波动或根本不下降。
解决方案:
- QLoRA/LoRA 推荐学习率:1e-4 到 2e-4
- 全量微调推荐学习率:1e-5 到 5e-5
- 使用 cosine 学习率调度器
- warmup steps 设置为总步数的 3-10%
- 进阶技巧 :Layer-wise 差异化学习率------对底层(靠近输入)设置更小的学习率或直接冻结,对顶层(靠近输出)设置更大的学习率。这能有效减少灾难性遗忘,因为底层存储的是通用语言知识,顶层存储的是任务特定表征。LLaMA-Factory 中可通过设置
freeze_layers参数实现部分层冻结。
坑 7:MoE 模型微调的特殊注意事项
随着 DeepSeek-V3(671B 总参/37B 激活)、Qwen3-235B-A22B(235B 总参/22B 激活)、LLaMA 4 Scout(109B 总参/17B 激活)等 MoE 架构模型的普及,微调 MoE 模型有几个特殊注意点:
MoE 模型和 Dense 模型的关键区别:MoE(Mixture of Experts)模型虽然总参数量巨大(如 LLaMA 4 Scout 有 109B),但每次推理只激活少量"专家"参数(如 Scout 每次只激活 17B),所以推理速度接近一个 17B 的 Dense 模型。
微调 MoE 模型需注意:
- 显存计算不同:虽然激活参数少,但 QLoRA 仍需加载完整模型权重到内存(4-bit 压缩后)
- Router 通常冻结:MoE 的路由器(决定激活哪些专家的模块)通常在微调时冻结,只训练专家层的 LoRA
- 稳定性更敏感:MoE 微调比 Dense 模型更容易出现训练不稳定,建议使用更小的学习率(比同等激活参数的 Dense 模型小 2-5 倍)
- 推荐做法:使用蒸馏版 Dense 模型(如 DeepSeek-R1-7B-distill)入门,MoE 原版留给有经验的团队
微调效果不好怎么办?退出策略
如果经过多轮调整效果仍然不理想,按这个优先级排查:
- 数据问题(最常见):重新审查数据质量,清洗后重训
- 换更大的基座模型:7B 不行试 14B,14B 不行试 32B
- 增加数据量:从 1000 条增加到 5000 条
- 换方法:LoRA 不行试全量微调或 GaLore
- 退回 RAG:有些任务本质上更适合 RAG(尤其是知识密集型问答)
- 组合方案:微调控制格式 + RAG 补充知识
8. 实战选择:遇到问题时怎么选
| 你遇到的问题 | 推荐路径 | 预计投入 |
|---|---|---|
| 模型不按我要的格式输出 | SFT 微调(几百条格式示例) | 200-500 条数据,1-2 小时 |
| 模型对我的行业术语理解不对 | SFT 微调 + 领域数据 | 1000-3000 条数据,3-6 小时 |
| 模型回复太长/太短/语气不对 | SFT(风格数据)或 DPO(偏好对比) | 500-1000 条数据 |
| 模型会输出不安全/有害内容 | DPO/SimPO 对齐训练 | 1000+ 偏好对 |
| 模型推理和数学能力不够 | GRPO 强化学习 | 5000+ 条带答案的题目 |
| 显存不够 | QLoRA + 4-bit 量化 | 7B 模型只需 6GB |
| 不确定是否需要微调 | 先试 few-shot prompting 和 RAG | 零成本验证 |
| 知识需要频繁更新 | RAG 优先,微调不适合频繁变动的知识 | RAG 搭建成本 |
| 想要多种能力的组合 | 分别微调 + Model Merging | 多个 LoRA + 合并 |
9. 负责任的微调:安全与伦理
微调是一把双刃剑。2024 年多项研究表明,仅需 100 条恶意数据微调几分钟,就能完全移除大模型的安全护栏。因此负责任地微调不是可选项,而是必须。
核心原则
- 不要移除安全对齐:Jailbreak fine-tuning 已被证实极易实现。不要发布去除安全限制的模型,不要在训练数据中混入绕过安全的示例。
- 注意数据偏见:训练数据中的性别、种族、地域偏见会被模型放大。微调前审查数据分布。
- 遵守许可证:不同基座模型有不同的许可证限制(如 LLaMA License 有使用限制,Apache 2.0 最宽松)。商用前务必确认。
- 保护数据隐私:微调数据中不应包含可识别的个人信息(PII),除非有合规依据。
安全评估工具
微调完成后,应使用安全分类器检查模型输出:
| 工具 | 开发者 | 功能 | 使用方式 |
|---|---|---|---|
| Llama Guard 4 | Meta | 12B 多模态安全分类器,检测输入/输出是否违反安全策略 | 作为 input/output filter 串联在推理链路中 |
| Prompt Guard | Meta | 检测恶意提示注入和越狱攻击 | 前置于模型输入 |
| Harmbench | 学术界 | 标准化的安全评测基准 | 评估模型安全对齐程度 |
| 人工红队测试 | 自建 | 模拟攻击者尝试绕过安全限制 | 上线前必做 |
实操建议:在微调后、部署前,至少用 Llama Guard 4 跑一遍模型输出的安全检测。如果 unsafe 比例超过 5%,需要加入安全数据重新微调或加入 output filter。
总结:一张图理解大模型微调
把大模型微调想象成一条流水线:
预训练(通用能力)------ 花费千万美元,数月时间
↓
SFT 监督微调(学会执行指令、掌握领域知识)------ 花费数百美元,数小时
↓
对齐训练(学会区分好坏、安全负责地回答)------ 花费数百美元,数小时
↓
部署服务每一步都在前一步的基础上做增量优化。你不一定每一步都需要------很多场景只做 SFT 就够了。
2026 年做微调的最佳起点:
- 选一个好的基座模型(推荐 Qwen3.5-9B 或 Qwen3-8B/14B)
- 准备 1000-5000 条高质量数据(合成数据 + 人工筛选)
- 用 QLoRA + LLaMA-Factory/Unsloth 跑起来(Web UI 零代码入门)
- 用 LLM-as-Judge 快速评估效果
- 根据效果决定是否升级方法(DoRA/GaLore/DPO/GRPO)
- 部署前用 Llama Guard 4 做安全检测
带走三个心智模型:
- 效率演进线:全量微调 → Adapter → LoRA → QLoRA → DoRA/PiSSA --- 越来越少的资源达到越来越好的效果
- 对齐演进线:RLHF(3模型+RL) → DPO(2模型) → SimPO(1模型) → KTO(点赞/踩) --- 越来越简单的流程和数据需求
- 决策顺序:Prompting → RAG → 微调 --- 从零成本方案开始,证明不够再升级
技术在演进,但核心逻辑没变:好数据 + 合适的方法 + 正确的评估 = 有效的微调。
参考资料
基础必读
- Hu et al., "LoRA: Low-Rank Adaptation of Large Language Models", 2021. arXiv:2106.09685
- Dettmers et al., "QLoRA: Efficient Finetuning of Quantized LLMs", 2023. arXiv:2305.14314
- Rafailov et al., "Direct Preference Optimization: Your Language Model is Secretly a Reward Model", 2023. arXiv:2305.18290
- Ouyang et al., "Training Language Models to Follow Instructions with Human Feedback" (InstructGPT), 2022. arXiv:2203.02155
进阶方法
- Liu et al., "DoRA: Weight-Decomposed Low-Rank Adaptation", 2024. arXiv:2402.09353
- Hayou et al., "LoRA+: Efficient Low Rank Adaptation of Large Models", 2024. arXiv:2402.12354
- Meng et al., "PiSSA: Principal Singular Values and Singular Vectors Adaptation", 2024. arXiv:2404.02948
- Zhao et al., "GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection", 2024. arXiv:2403.03507
- Meng et al., "SimPO: Simple Preference Optimization with a Reference-Free Reward", 2024. arXiv:2405.14734
- Hong et al., "ORPO: Monolithic Preference Optimization without Reference Model", 2024. arXiv:2403.07691
- Ethayarajh et al., "KTO: Model Alignment as Prospect Theoretic Optimization", 2024. arXiv:2402.01306
- DeepSeek-AI, "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning", 2025. arXiv:2501.12948
实践工具
- Zheng et al., "LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models", ACL 2024. arXiv:2403.13372
- Unsloth: https://github.com/unslothai/unsloth
- Hugging Face PEFT: https://github.com/huggingface/peft
- Hugging Face TRL: https://github.com/huggingface/trl
综述与深度阅读
- Xu et al., "A Survey on Knowledge Distillation of Large Language Models", 2024. arXiv:2402.13116
- Biderman et al., "LoRA Learns Less and Forgets Less", 2024. arXiv:2405.09673
- Zhou et al., "LIMA: Less Is More for Alignment", 2023. arXiv:2305.11206