引言:算力孤岛与架构的"不可能三角"
在企业级 AI 视频项目中,我们经常面临一个尴尬的局面:中心机房是 X86 服务器,边缘节点是 ARM 架构的国产芯片(如瑞芯微、昇腾),而算法模型又依赖特定的 CUDA 或 ONNX Runtime。 传统的单体架构应用一旦编译,就锁死了硬件环境。想要支持多平台,往往需要维护多套代码分支,开发和运维成本呈指数级上升。
YiheCode Server 的出现,打破了这一僵局。它通过将业务逻辑 与计算密集型任务 彻底解耦,构建了一套适应未来信创环境的弹性架构。
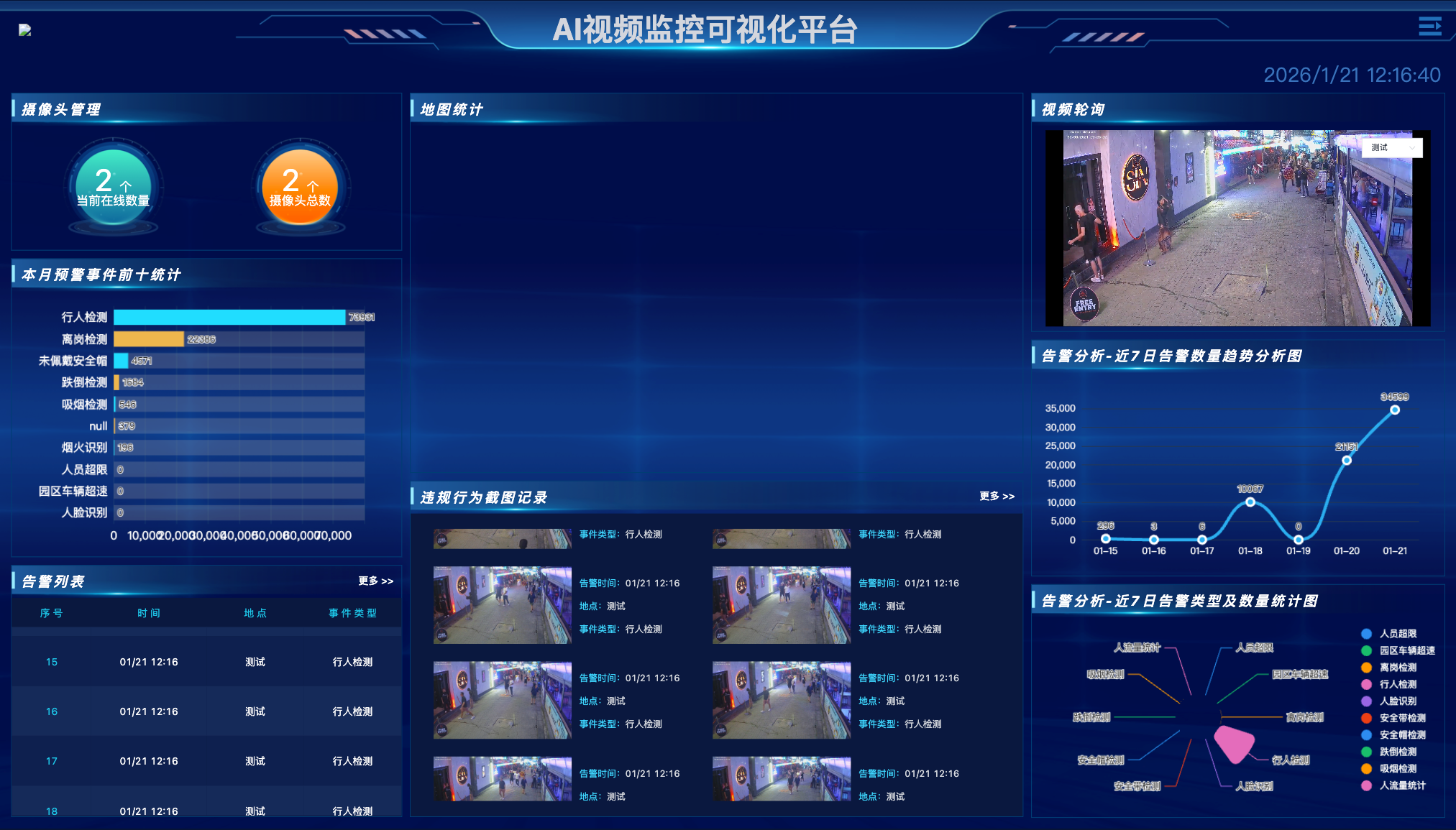
一、 核心架构设计:微服务与边缘计算的"分而治之"
该平台采用了经典的分层架构设计,将系统划分为:Web 控制层、业务逻辑层、流媒体服务层和边缘计算层。
1.1 控制流与媒体流的分离
- 控制平面(Java Spring Boot):负责设备管理、用户权限、告警逻辑。这部分代码是纯 Java 实现,具备天然的跨平台特性(Write Once, Run Anywhere),无论是部署在 X86 的 Docker 容器还是 ARM 的物理机上,都能完美运行。
- 数据平面(ZLMediaKit + Edge SDK):负责音视频流的拉取、转码和分发。这里采用了 C++ 编写的核心库,针对不同硬件平台进行独立编译。
1.2 边缘-云协同机制
平台并不强制要求所有计算都在云端完成。相反,它通过边缘代理(Edge Agent),将算法任务下发到靠近数据源头的 NPU/GPU 边缘盒子中。这种设计不仅节省了带宽,更关键的是实现了算力的按需调度。
二、 异构部署实战:Docker 如何解决"水土不服"
YiheCode Server 最大的技术亮点在于其容器化部署策略 。它利用 Docker 的多架构镜像支持,实现了同一套 Compose 文件在不同环境下的自适应运行。
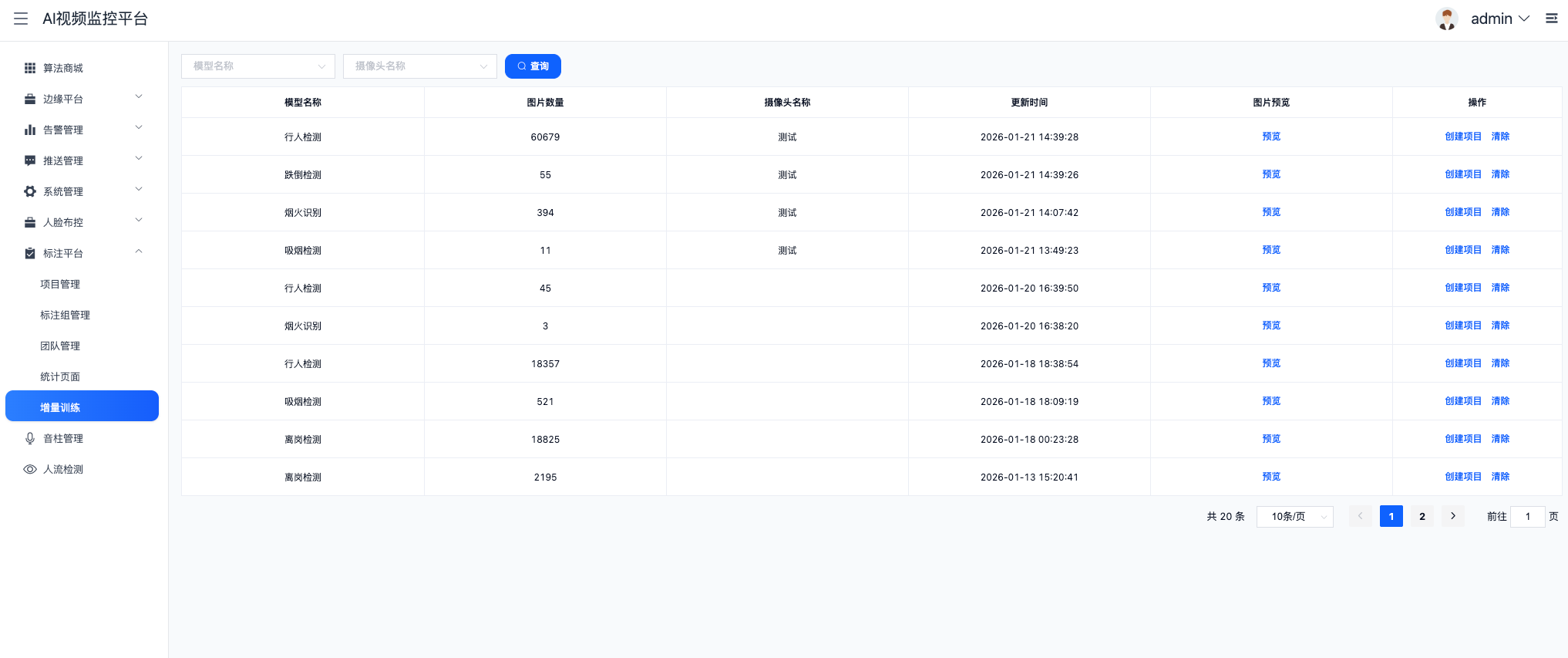
2.1 X86 与 ARM 的镜像策略
项目通过 Gitee CI/CD 流水线,构建了针对不同 CPU 指令集的镜像:
- X86 环境:直接利用 NVIDIA Docker 镜像,调用 CUDA 进行 GPU 加速推理。
- ARM 环境:使用轻量级的基础镜像,并挂载国产芯片(如 RK3588, 1684X)的 NPU 驱动库。
Docker-Compose 部署示例(异构适配):
yaml
version: '3.8'
services:
# 业务后端 (Java - 跨平台)
backend-app:
image: yihecode/backend:latest
# Java镜像天然支持多架构,无需修改
ports:
- "8080:8080"
environment:
- SPRING_PROFILES_ACTIVE=prod
# 边缘推理服务 (多架构适配关键)
inference-engine:
# 核心点:根据部署环境选择不同的Tag或镜像
# X86环境使用 nvidia-docker
# ARM环境使用 arm64v8/ubuntu + NPU驱动
image: yihecode/inference:${ARCH}
# 通过环境变量注入硬件类型
environment:
- HARDWARE_TYPE=${ACCELERATOR} # 可选: CUDA, NPU, CPU, ONNX
volumes:
- ./models:/app/models # 挂载算法模型
- /dev:/dev # 关键:挂载设备文件以访问NPU/GPU硬件
# GPU资源限制 (仅X86+NVIDIA有效)
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]2.2 算法与硬件的解耦(Plugin Architecture)
平台设计了抽象的算法插件层。开发者不需要关心底层是英伟达的 Tesla T4 还是国产的寒武纪 MLU。
- 接口标准化 :定义统一的
InferenceInterface,所有算法模型(无论是 PyTorch, TensorRT 还是 RKNN)都必须实现该接口。 - 动态加载:系统在启动时扫描插件目录,根据硬件环境自动加载对应的动态链接库(.so 文件)。
伪代码逻辑:
python
class InferenceManager:
def __init__(self):
self.hardware = self.detect_hardware() # 自动检测环境
def load_model(self, model_path):
# 根据硬件环境选择执行后端
if self.hardware == "NVIDIA_GPU":
self.backend = TensorRTBackend(model_path)
elif self.hardware == "ROCKCHIP_NPU":
self.backend = RKNNBackend(model_path) # 自动转译为NPU指令
elif self.hardware == "CPU_ONLY":
self.backend = ONNXRuntimeBackend(model_path)
else:
raise RuntimeError("Unsupported Hardware")
def run(self, video_frame):
return self.backend.execute(video_frame)三、 私有化交付:源码级的灵活性
对于寻求私有化部署的技术决策者来说,YiheCode Server 的源码交付模式具有极高的战略价值:
- 驱动级定制:如果客户使用了非常冷门的国产显卡,开发团队可以直接修改 C++ 层的推理代码,接入厂商提供的 SDK,而无需重写整个 Java 业务系统。
- ARM 信创适配:随着信创替代浪潮的来临,企业可以直接在麒麟操作系统(ARM版)上编译部署,无需等待原厂提供适配版本。
四、 总结
YiheCode Server 通过**"Java 业务层 + C++ 推理层 + Docker 容器化"的组合拳,成功构建了一个 硬件无关**的视频底座。它证明了企业无需为了适配不同的芯片(X86/ARM, GPU/NPU)而重复造轮子。
对于正在寻找低代码开发 路径、希望实现全栈源码可控的集成商而言,这套架构提供了一个极佳的参考范本:将不变的业务逻辑固化,将变化的算力环境容器化。
架构师建议 :
如果您正面临多品牌硬件混用 或国产化替代 的项目压力,建议直接下载源码,尝试修改
Dockerfile以适配您手中的特定边缘计算盒子。这种"源码级"的掌控力,才是企业应对未来技术不确定性的最大底气。欢迎在评论区交流您在异构计算中遇到的坑。