ElasticSearch(以下简称 ES )除了强大的全文检索能力外,其 聚合(Aggregations)功能 是实现数据统计、分析与挖掘的核心利器。
它能快速响应各类业务分析需求,广泛应用于 商业智能、日志分析、用户行为追踪、金融风控 等场景。
本文将系统性地拆解 ES 聚合的 核心概念、分类体系、实战用法、精度问题及性能优化策略,并配套思维导图逻辑,助你高效掌握并落地到真实业务中。
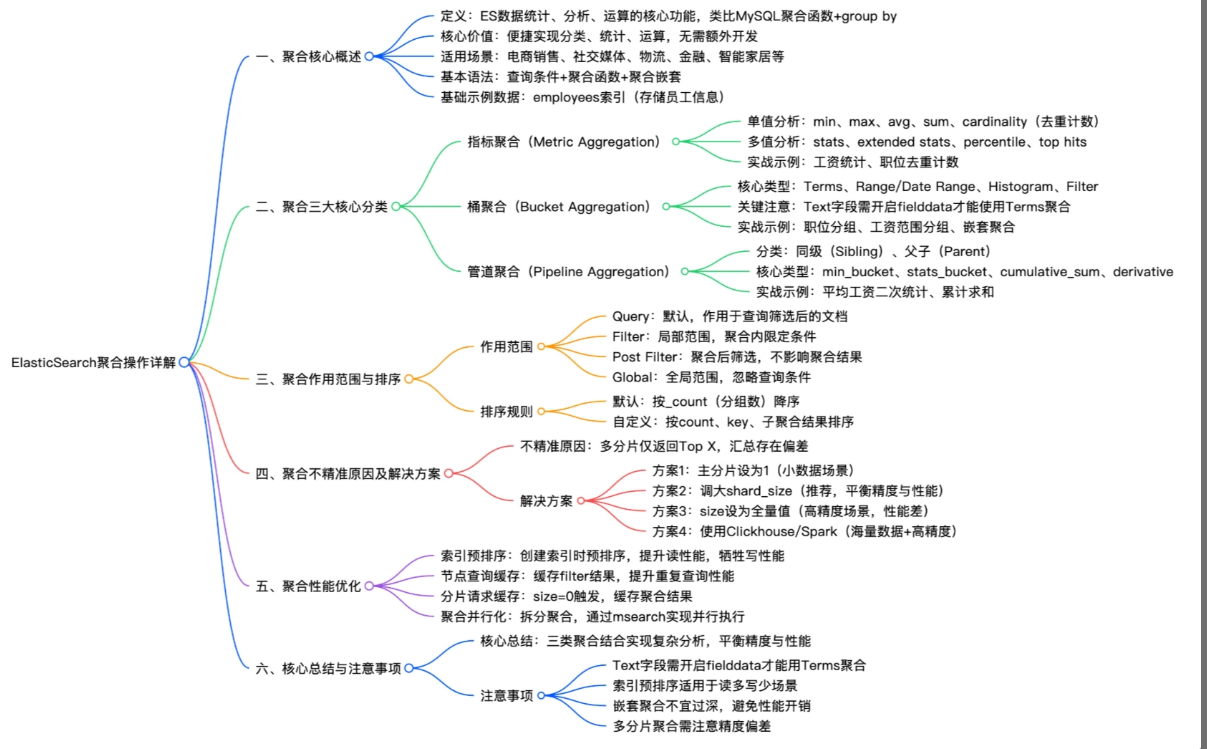
一、聚合操作核心概述
1.1 什么是聚合?为什么重要?
聚合 是 ES 提供的一种对索引数据进行 分组、统计、计算 的机制,无需编写复杂代码即可完成以下典型分析:
- 什么品牌的手机最受欢迎? → 分类统计(桶聚合)
- 平均价格、最高/最低价是多少? → 数值统计(指标聚合)
- 每月销售趋势如何? → 时间序列分析(Date Histogram)
✅ 核心价值 :用声明式查询替代程序逻辑,实现秒级数据分析。
1.2 典型应用场景
| 行业 | 应用场景 |
|---|---|
| 电商 | 各地区销售额、用户消费总额、热销商品排行 |
| 社交平台 | 用户发帖/评论/转发频次,按地域/时间/话题分组 |
| 物流 | 区域运输量、司机里程、车辆使用率 |
| 金融 | 客户交易总额、产品销量、交易员绩效 |
| IoT/智能家居 | 设备使用频率、家庭能耗、时段活跃度 |
1.3 聚合基本语法结构
json
GET /<index_name>/_search
{
"query": { ... }, // 可选:限定聚合范围
"aggs": {
"<自定义聚合名>": {
"<聚合类型>": {
"field": "<字段名>"
}
}
}
}🔑 关键参数说明:
aggs:聚合根节点(也可写作aggregations)<聚合名>:自定义标识符,用于结果引用<聚合类型>:如terms,avg,histogram等field:目标字段,必须与字段类型匹配
💡 建议:设置
"size": 0可 仅返回聚合结果,提升性能并触发缓存。
1.4 实战数据准备(employees 索引)
为便于演示,我们创建一个员工信息索引:
json
// 删除旧索引
DELETE /employees
// 创建索引 + 映射
PUT /employees
{
"mappings": {
"properties": {
"age": { "type": "integer" },
"gender": { "type": "keyword" },
"job": {
"type": "text",
"fields": {
"keyword": { "type": "keyword", "ignore_above": 50 }
}
},
"name": { "type": "keyword" },
"salary": { "type": "integer" }
}
}
}
// 批量插入 20 条测试数据(略,见原文)⚠️ 注意:
job字段采用 多字段(multi-field)设计 ,job.keyword用于精确聚合。
二、聚合三大核心分类(附实战)
ES 聚合分为三类,可 单独使用或嵌套组合,形成强大分析能力:
| 类型 | 作用 | 类比 SQL |
|---|---|---|
| 指标聚合(Metric) | 对字段做数学运算 | MIN(),AVG(),COUNT(DISTINCT) |
| 桶聚合(Bucket) | 将文档分组(建"桶") | GROUP BY |
| 管道聚合(Pipeline) | 对聚合结果再聚合 | 无直接对应,类似窗口函数 |
2.1 指标聚合(Metric Aggregation)
✅ 单值指标(返回单一数值)
| 聚合类型 | 说明 |
|---|---|
min/max |
最小/最大值 |
avg/sum |
平均值/总和 |
cardinality |
去重计数(近似) |
🔧 示例:工资统计
json
POST /employees/_search
{
"size": 0,
"aggs": {
"max_salary": { "max": { "field": "salary" } },
"min_salary": { "min": { "field": "salary" } },
"avg_salary": { "avg": { "field": "salary" } }
}
}🔧 示例:职位去重数量
json
{
"aggs": {
"job_distinct_count": {
"cardinality": { "field": "job.keyword" }
}
}
}⚠️
cardinality使用 HyperLogLog++ 算法 ,结果为近似值 ,可通过precision_threshold调整精度。
✅ 多值指标(返回多个统计量)
| 聚合类型 | 说明 |
|---|---|
stats |
min/max/avg/sum/count |
extended_stats |
+ 方差、标准差等 |
percentiles |
百分位(如 P95、P99) |
top_hits |
返回桶内原始文档 |
🔧 示例:工资全维度统计
json
{
"aggs": {
"salary_stats": {
"stats": { "field": "salary" }
}
}
}2.2 桶聚合(Bucket Aggregation)
💡 核心思想:把满足条件的文档"装进桶",每个桶有唯一 key。
🔑 常用桶类型
| 类型 | 用途 |
|---|---|
terms |
按字段值分组(最常用) |
range/date_range |
按数值/日期区间分组 |
histogram/date_histogram |
按固定间隔分组 |
filter |
按条件筛选出一个桶 |
🔧 示例 1:按职位分组(Terms)
json
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10,
"order": { "_count": "desc" }
}
}
}
}✅ 最佳实践 :始终使用
.keyword字段进行terms聚合!
🔧 示例 2:限定聚合范围(Query + Agg)
json
{
"query": { "range": { "salary": { "gte": 10000 } } },
"aggs": {
"jobs": { "terms": { "field": "job.keyword" } }
}
}🔧 示例 3:Text 字段开启 fielddata(不推荐!)
json
PUT /employees/_mapping
{
"properties": {
"job": { "type": "text", "fielddata": true }
}
}⚠️ 警告 :开启
fielddata会大幅增加内存消耗 ,且按分词结果 聚合,语义可能失真。优先使用.keyword!
🔧 示例 4:工资区间分组(Range)
json
{
"aggs": {
"salary_range": {
"range": {
"field": "salary",
"ranges": [
{ "to": 10000, "key": "低薪" },
{ "from": 10000, "to": 20000, "key": "中薪" },
{ "from": 20000, "key": "高薪" }
]
}
}
}
}🔧 示例 5:嵌套聚合(桶内再聚合)
按职位分组,每组返回年龄最大的 3 人
json
{
"size": 0,
"aggs": {
"jobs": {
"terms": { "field": "job.keyword" },
"aggs": {
"old_employee": {
"top_hits": {
"size": 3,
"sort": [{ "age": { "order": "desc" } }]
}
}
}
}
}
}2.3 管道聚合(Pipeline Aggregation)
💡 特点 :不操作原始文档,而是对已有聚合结果进行二次计算。
🔑 两大类型
| 类型 | 说明 | 示例 |
|---|---|---|
| 同级管道(Sibling) | 结果与原聚合平级 | min_bucket,avg_bucket |
| 父子管道(Parent) | 结果嵌入原聚合内部 | cumulative_sum,derivative |
🔧 示例 1:找出平均工资最低的职位(min_bucket)
json
{
"aggs": {
"jobs": {
"terms": { "field": "job.keyword" },
"aggs": { "avg_salary": { "avg": { "field": "salary" } } }
},
"min_avg_salary": {
"min_bucket": { "buckets_path": "jobs>avg_salary" }
}
}
}✅
buckets_path语法:聚合名 > 子聚合名
🔧 示例 2:累计求和(cumulative_sum)
json
{
"aggs": {
"age_hist": {
"histogram": { "field": "age", "interval": 1 },
"aggs": {
"avg_sal": { "avg": { "field": "salary" } },
"cum_sal": { "cumulative_sum": { "buckets_path": "avg_sal" } }
}
}
}
}三、聚合作用范围与排序控制
3.1 四种作用范围
| 方式 | 说明 | 适用场景 |
|---|---|---|
| Query | 默认:仅聚合匹配 query 的文档 | 常规筛选后分析 |
| Filter(聚合内) | 在 agg 内部定义局部 filter | 多维度对比(如"35 岁以上 vs 全体") |
| Post Filter | 聚合后过滤返回文档 | 聚合不受影响,仅展示部分文档 |
| Global | 忽略 query,聚合全部文档 | 如"查某人,但统计全局平均工资" |
🔧 Global 示例:
json
{
"query": { "term": { "name": "Emma" } },
"aggs": {
"emma_job": { "terms": { "field": "job.keyword" } },
"global_avg": {
"global": {},
"aggs": { "salary_avg": { "avg": { "field": "salary" } } }
}
}
}3.2 聚合结果排序
默认按 _count 降序,可通过 order 自定义:
json
"order": [
{ "avg_salary": "desc" }, // 按子聚合结果排序
{ "_count": "asc" }, // 按文档数升序
{ "_key": "desc" } // 按桶 key 降序
]✅ 支持多字段排序,数组顺序即优先级。
四、聚合不精准?原因与解决方案
4.1 为什么聚合结果不精确?
📌 根本原因 :ES 是分布式系统,每个分片独立计算 Top-N,再合并,导致最终结果偏差。
尤其在 terms 聚合中,若 size=10,每个分片可能返回不同的前 10,合并后并非全局前 10。
4.2 提升精度的 4 种方案
| 方案 | 说明 | 适用场景 |
|---|---|---|
| 1. 主分片 = 1 | 避免分片合并误差 | 小数据量、单机部署 |
2. 调大 shard_size |
**推荐!**每个分片返回更多候选 | 中等数据量,平衡精度与性能 |
3.size = 2^31-1 |
全量聚合 | 极高精度要求,容忍慢查询 |
| 4. 外部工具(ClickHouse/Spark) | 离线精准计算 | 海量数据、T+1 报表 |
🔧 shard_size 设置建议:
json
"terms": {
"field": "xxx",
"size": 10,
"shard_size": 25, // ≈ size * 1.5 + 10
"show_term_doc_count_error": true // 显示误差估计
}五、聚合性能优化技巧
✅ 5.1 索引预排序(Index Sorting)
适用于 读多写少 场景(如日志、时序数据)
json
PUT /logs
{
"settings": {
"index.sort.field": "timestamp",
"index.sort.order": "desc"
}
}⚠️ 写入性能下降 40%~50%,慎用!
✅ 5.2 利用节点查询缓存(Node Query Cache)
- 自动生效 :当使用
filter上下文时 - 多次相同 filter 聚合可复用缓存
json
"query": {
"bool": {
"filter": { "term": { "status": "active" } } // 缓存命中
}
}✅ 5.3 启用分片请求缓存
- 当
"size": 0时自动启用 - 缓存整个聚合结果(非文档)
✅ 5.4 拆分聚合,并行执行(msearch)
将多个无关聚合拆成独立请求,并行处理:
GET _msearch
{"index":"employees"}
{"size":0,"aggs":{"job_agg":{"terms":{"field":"job.keyword"}}}}
{"index":"employees"}
{"size":0,"aggs":{"max_salary":{"max":{"field":"salary"}}}}💡 在 CPU 富余、网络延迟低的集群中,**响应时间可缩短 30%~50%**。
六、核心总结与避坑指南
✅ 核心总结
- 三大聚合类型:指标(算数)、桶(分组)、管道(二次聚合)
- 嵌套是王道:桶内可嵌指标,指标可被管道再聚合
- 精度 vs 性能 :根据业务容忍度选择
shard_size或外部计算 - 性能优化四板斧:预排序、缓存、size=0、并行化
⚠️ 高频注意事项
| 问题 | 解决方案 |
|---|---|
| Text 字段无法 terms 聚合 | 使用 .keyword 子字段 |
| 聚合结果不准 | 调大 shard_size,避免多分片 Top-N 合并误差 |
| 内存溢出 | 避免对高基数字段(如 user_id)做 terms 聚合 |
| 响应慢 | 检查是否未设 size:0,是否可拆分并行 |
| 嵌套过深 | 控制在 2~3 层,避免指数级计算开销 |
🎯 最后建议:
聚合是 ES 的"分析引擎",但不是万能数据库。
对于 超高精度、超大数据量、复杂 JOIN 场景,建议结合 OLAP 引擎(如 ClickHouse、Doris) 使用。