语言模型是自然语言处理领域的核心技术,它通过学习语言的统计规律来预测文本序列的概率分布。从最早的n-grams统计模型到如今的Transformer架构,语言模型的发展经历了从简单到复杂、从浅层到深层的技术演进。本文将系统梳理语言模型的基础技术,涵盖统计方法、循环神经网络、Transformer架构以及采样和评测方法,为AI研究员提供全面的技术参考。
一、基于统计方法的语言模型
1.1 n-grams语言模型的数学原理
n-grams语言模型是基于统计的语言建模方法,其核心思想是用局部上下文近似全局语言依赖关系。在介绍n-grams之前,我们需要理解语言模型的基本目标:估计一句话出现的概率P(w₁,w₂,...,wₙ),其中wᵢ表示句子中的第i个词。
根据概率的链式法则,我们可以将联合概率分解为条件概率的乘积:
P(w1,w2,...,wn)=∏i=1nP(wi∣w1,...,wi−1)P(w_1,w_2,...,w_n) = \prod_{i=1}^{n} P(w_i \mid w_1,...,w_{i-1})P(w1,w2,...,wn)=i=1∏nP(wi∣w1,...,wi−1)
然而,这个公式的条件概率依赖于历史所有词,参数规模呈指数级增长,无法直接估计。为了解决这一问题,研究者引入了马尔可夫假设(Markov Assumption):一个词的出现只依赖于它前面最近的n-1个词,与更早期的词无关。基于这个假设,条件概率可以简化为:
P(wt∣w1,w2,...,wt−1)≈P(wt∣wt−n+1,...,wt−1)P(w_t \mid w_1, w_2, ..., w_{t-1}) ≈ P(w_t \mid w_{t-n+1}, ..., w_{t-1})P(wt∣w1,w2,...,wt−1)≈P(wt∣wt−n+1,...,wt−1)
n-grams模型正是基于这一假设,认为一个词的出现仅与它之前的n-1个词有关。整个句子出现的概率可以表示为:
p(w1,w2,...,wn)=∏p(wi∣wi−1...wi−N−1)p(w_1,w_2,...,w_n) = \prod p(w_i \mid w_{i-1}...w_{i-N-1})p(w1,w2,...,wn)=∏p(wi∣wi−1...wi−N−1)
当n=1时,称为unigram模型,每个词的概率独立于序列中其他词的概率。当n=2时,称为bigram模型,条件概率简化为:
P(w1,w2,w3,...)≈∏P(wk∣wk−1)P(w_1, w_2, w_3, ...) \approx \prod P(w_k \mid w_{k-1})P(w1,w2,w3,...)≈∏P(wk∣wk−1)
1.2 模型训练与参数估计
n-grams模型的训练过程本质上就是统计词频的过程。以bigram为例,我们需要统计所有连续两个词的组合(wi-1,wi)的出现次数count(wi-1,wi),然后通过最大似然估计计算条件概率:
P(wi∣wi−1)=count(wi−1,wi)count(wi−1)P(w_i \mid w_{i-1}) = \frac{\text{count}(w_{i-1}, w_i)}{\text{count}(w_{i-1})}P(wi∣wi−1)=count(wi−1)count(wi−1,wi)
具体实现时,我们可以使用Python的Counter类来构建词频统计。以下是unigram、bigram和trigram的统计实现代码:
python
from collections import Counter
from nltk.util import ngrams
def build_unigram(tokenized_corpus):
"""构建unigram词频统计"""
unigram_counts = Counter()
for tokens in tokenized_corpus:
unigram_counts.update(tokens)
return unigram_counts
def build_bigram(tokenized_corpus):
"""构建bigram词频统计"""
bigram_counts = Counter()
for tokens in tokenized_corpus:
bigram_counts.update(ngrams(tokens, 2))
return bigram_counts
def build_trigram(tokenized_corpus):
"""构建trigram词频统计"""
trigram_counts = Counter()
for tokens in tokenized_corpus:
trigram_counts.update(ngrams(tokens, 3))
return trigram_counts1.3 平滑技术的必要性
随着n值增大,参数空间呈指数级增长。设词表大小为V,则unigram的参数规模为O(V),bigram为O(V²),trigram为O(V³)。例如,若V=50,000,bigram参数量约为2.5×10⁹,trigram参数量约为1.25×10¹⁴,几乎所有n-gram在语料中都不会出现,导致概率为0,这就是数据稀疏性问题。
为解决零概率问题,研究者提出了多种平滑技术。最简单的是拉普拉斯平滑(Laplace Smoothing),也称为加一平滑(Add-One Smoothing),其数学公式为:
PAdd-1(wi∣wi−1)=c(wi−1,wi)+1c(wi−1)+VP_{\text{Add-1}}(w_i \mid w_{i-1}) = \frac{c(w_{i-1}, w_i) + 1}{c(w_{i-1}) + V}PAdd-1(wi∣wi−1)=c(wi−1)+Vc(wi−1,wi)+1
其中V是词表大小。拉普拉斯平滑假设每个可能的词组合至少出现过一次(虚拟观测),因此未出现的n-gram不再概率为0。
除了加一平滑,还有更复杂的技术,如Good-Turing折扣或回退模型(back-off models)。Add-λ平滑是另一种简单的技术,可以理解为在训练数据中"幻想"出现频率为λ的n-gram。
1.4 n-grams模型的优缺点分析
n-grams模型具有以下优点:
- 简单直观:原理容易理解,实现简单
- 推理高效:基于查表操作,速度很快
- 计算高效:基于统计频率进行计算,在大规模语料库上也能较快完成训练和预测
- 对局部语言模式捕捉较好:能够较好地反映语言中的局部上下文关系
- 可扩展性强:可以很容易地应用于不同的语言和领域,只需要收集相应的语料库进行统计分析即可
然而,n-grams模型也存在明显的局限性:
- 数据稀疏性:当N取值较大时,很多N-Gram序列在语料库中出现的次数极少甚至为零,导致概率估计不准确
- 无法捕捉长距离依赖:由于只考虑前n-1个元素,对于文本中长距离的上下文关联无法捕捉
- 短视问题:N-gram通常只能考虑前2-3个词,无法捕捉长距离依赖。如果关键信息在较远的位置,模型会"忘记"上下文
- 缺乏语义理解:N-gram模型只是基于统计的方法,缺乏对语言的语义理解
1.5 实际应用场景
尽管存在局限性,n-grams模型在实际应用中仍有其价值。它广泛用于文本生成、文本分类、机器翻译、拼写纠正、语音识别等自然语言处理任务中。具体应用场景包括:
- 搜索引擎和输入法的联想提示:这是n-gram的典型应用
- 语音识别系统:n-gram语言模型是使用大量文本开发的概率模型,可以在给定n-1个词序列的情况下预测最可能的下一个词
- 实时语音识别:虽然现代ASR多采用神经网络语言模型,但由于其轻量级、低延迟、易于集成的特点,n-gram模型仍广泛应用于端侧或资源受限环境下的实时语音识别系统
二、基于RNN的语言模型
2.1 RNN的基本结构与工作原理
循环神经网络(RNN)通过引入隐藏状态(Hidden State)作为记忆单元,将历史信息传递到当前时刻。RNN的核心思想是通过在网络中引入循环连接,使得网络在处理当前输入时能够利用之前的信息,这种结构使得RNN具有记忆能力,能够捕捉序列数据中的长期依赖关系。
RNN的核心是循环连接,即网络在处理序列数据时,会将前一时刻的输出(或隐藏状态)作为当前时刻的输入之一,从而实现对"上下文信息"的记忆。RNN的最小计算单元在每个时间步的输入包括两部分:当前输入xₜ和前一时刻的隐藏状态hₜ₋₁。
RNN的数学表达可以表示为:
ht=tanh(Whht−1+Wxxt+bh)h_t = \tanh(W_h h_{t-1} + W_x x_t + b_h)ht=tanh(Whht−1+Wxxt+bh)
其中hₜ是t时刻的隐藏状态("记忆"),Wₕ和Wₓ是权重矩阵,bₕ是偏置项。所有时间步使用同一组权重Wₕ、Wₓ,使模型能处理任意长度序列。
2.2 RNN语言模型的优势
相比n-grams模型,RNN语言模型具有以下优势:
- 彻底抛弃固定窗口:理论上可以处理任意长度的序列,不再受窗口大小的限制
- 参数共享:在每个时间步使用同一套权重矩阵,模型规模不随序列长度增长,同时天然满足了平移不变性
- 更好的语义理解:RNN在读取每个单词时,不仅会考虑当前单词的含义,还会结合之前已经读过的单词信息,从而更好地理解整个句子的语境
2.3 梯度消失问题及其解决方案
RNN存在严重的梯度消失问题。当序列很长时,如果梯度值小于1,连续相乘会趋近于0,导致梯度消失------远处的信息无法影响当前参数的更新(网络"遗忘"了长距离依赖)。RNN的反向传播通过时间展开实现,等效于一个深度为序列长度的前馈网络。若使用sigmoid/tanh激活函数(导数≤0.25),每一步的Jacobian范数小于1,连乘后梯度以指数速度趋近于0。
为解决这一问题,研究者提出了门控机制,代表模型是LSTM和GRU。
LSTM(长短期记忆网络) 通过精巧的设计解决了梯度消失问题。LSTM的核心创新在于引入了门控机制,可以把LSTM想象成一个智能的记忆盒子,这个盒子里有一条叫做单元状态的信息高速公路,让重要信息能够长时间传递。而盒子上装了三个智能门:遗忘门、输入门和输出门。
LSTM的梯度在反向传播通过细胞状态时是加性的,避免了连乘效应,从而缓解了梯度消失问题,使网络能够学习到非常长的依赖关系。
GRU(门控循环单元) 是LSTM的简化版本,它将遗忘门和输入门合并为更新门(Update Gate),并用重置门(Reset Gate)控制历史信息的遗忘程度。GRU只有两个门控机制:
- 更新门:结合了LSTM的遗忘门和输入门功能,既决定丢弃哪些旧信息,也决定添加哪些新信息
- 重置门:控制历史信息的遗忘程度
GRU相比LSTM,结构更简单,参数更少,训练速度更快,但在很多任务上表现相当。
2.4 RNN语言模型的实现示例
以下是一个基于PyTorch的字符级RNN语言模型实现示例:
python
import torch
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
# 输入包括类别、当前字母和隐藏状态
self.i2h = nn.Linear(n_categories + input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(n_categories + input_size + hidden_size, output_size)
self.o2o = nn.Linear(hidden_size + output_size, output_size)
self.dropout = nn.Dropout(0.1)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, category, input, hidden):
# 拼接输入
input_combined = torch.cat((category, input, hidden), 1)
# 计算新的隐藏状态
hidden = self.i2h(input_combined)
# 计算输出
output = self.i2o(input_combined)
# 再次处理输出
output_combined = torch.cat((hidden, output), 1)
output = self.o2o(output_combined)
output = self.dropout(output)
output = self.softmax(output)
return output, hidden
def initHidden(self):
return torch.zeros(1, self.hidden_size)2.5 RNN语言模型的应用场景
RNN语言模型在以下场景中得到广泛应用:
- 文本生成:基于字符级或词级的文本生成任务
- 语音识别:处理语音信号的时序特征
- 机器翻译:序列到序列的转换任务
- 情感分析:理解文本的情感倾向
三、基于Transformer的语言模型
3.1 Transformer架构概述
Transformer模型架构是一种基于自注意力机制(Self-Attention)的深度学习模型,由Google团队在2017年的论文《Attention Is All You Need》中首次提出。Transformer架构的核心突破在于自注意力机制,它彻底摆脱了RNN的序列依赖限制。
Transformer架构由编码器和解码器两部分组成,但在语言模型应用中,不同模型选择了不同的组件。原版Transformer是为机器翻译设计的,天然分两半:编码器(Encoder)读懂输入,把它压缩成一个富含语义的"理解结果";解码器(Decoder)根据编码器的输出和已生成的部分,逐步生成目标序列。
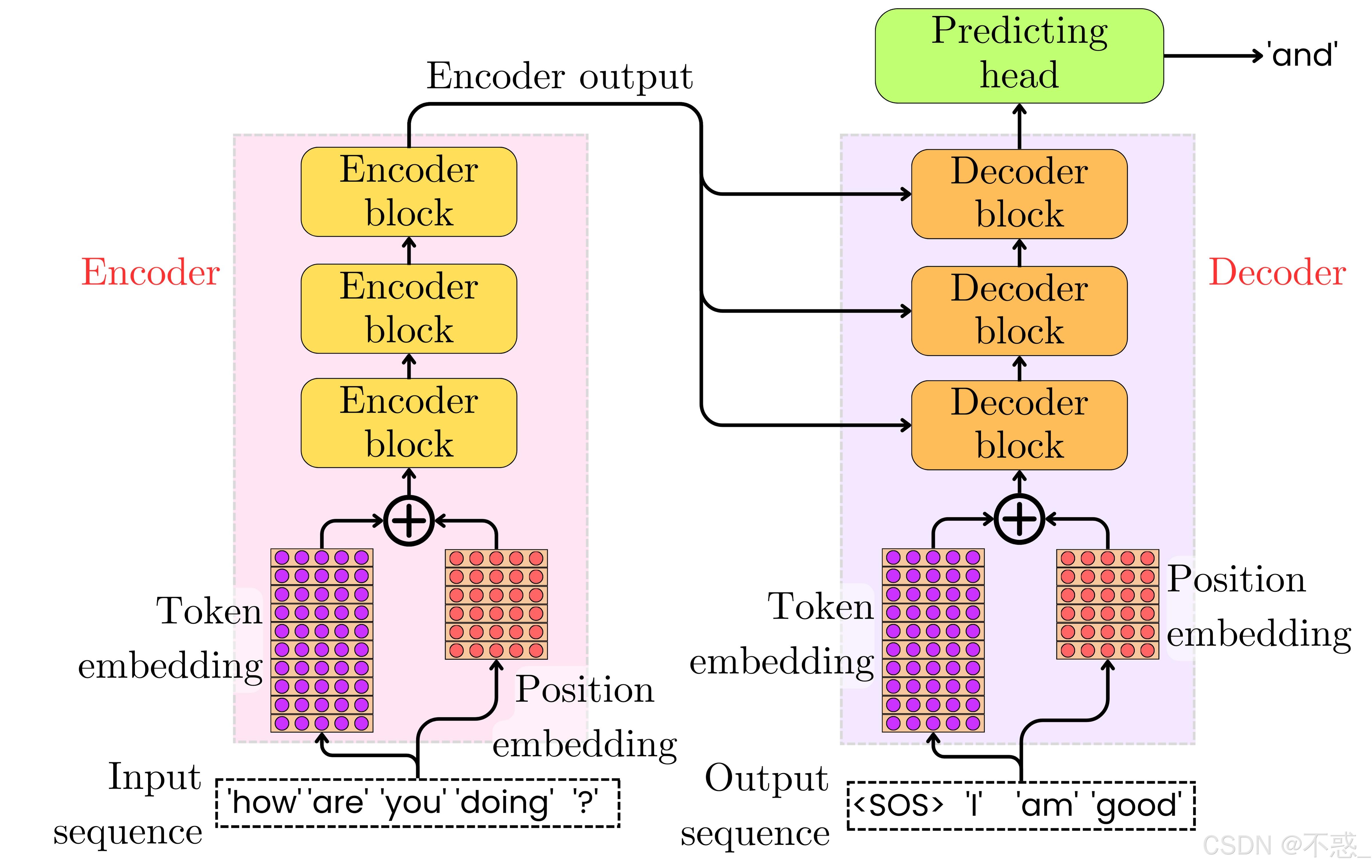
3.2 自注意力机制的数学原理
自注意力机制是Transformer的"灵魂",其作用是让序列中的每个元素都能"看到"序列中所有其他元素,并计算它们之间的关联强度(权重),从而精准捕捉全局语义/时序关联。
自注意力机制的计算依赖于Query (Q)、Key (K)、Value (V)三个关键向量,三者各司其职:
- Q (Query):当前词的"查询向量"(核心是"我想找什么")
- K (Key):其他词的"键向量"(核心是"我能提供什么信息")
- V (Value):其他词的"值向量"(核心是"我实际的信息内容")
在自注意力中,Q、K、V均来自同一输入序列的嵌入向量。计算过程如下:
- 第一步:将输入序列通过线性变换得到Q、K、V矩阵
- 第二步:计算Q×Kᵀ------计算词间"相似度"(注意力得分)
- 第三步:对注意力得分进行Softmax归一化
- 第四步:将归一化后的权重与V相乘,得到加权和
3.3 多头注意力机制
多头注意力的主要思想是允许模型联合关注来自不同表示子空间的信息(类似集成),通过多个并行的注意力层实现,每个注意力层有自己的参数,将结果连接后通过线性投影。
具体实现时,在实际的编码器中,通常不只用一个注意力头,而是将输入的QKV分别通过不同的线性变换矩阵投影到h个不同的子空间,这样就得到了h组新的QKV。然后在这h个子空间里分别独立计算attention,每个头就像是一个独立的专家,专注于学习特定类型的模式。
3.4 位置编码技术
由于Transformer架构本身不包含时序信息,需要通过位置编码(Position Embedding)来引入序列中的位置信息。位置编码可以是可学习的,也可以是固定的正弦余弦函数。
3.5 全连接前馈层
Transformer中的前馈层是一个两层的全连接神经网络,中间加入非线性激活函数(原论文用ReLU,改进版多用效果更好的GELU),核心结构为:
- 第一层全连接:将输入向量升维(如512维→2048维),扩大特征表达空间,提取更多细粒度特征
- 第二层全连接:将向量降维回原始维度(2048维→512维)
位置前馈网络是一个全连接前馈网络,每个位置的词都单独经过这个完全相同的前馈神经网络。其由两个线性变换组成,第一个全连接层的激活函数为ReLU激活函数。整个前馈网络的输入和输出维度都是d_model=512,第一个全连接层的输出和第二个全连接层的输入维度为d_ff=2048。
3.6 层正则化与残差连接
层正则化(Layer Normalization)和残差连接(Residual Connection)是Transformer架构的重要组成部分。
残差连接在注意力层、前馈网络层的输入与输出之间建立"直连通道",避免深层网络训练时的梯度消失,加速信息流动。即使梯度很大(容易爆炸),残差结构也能把训练变成"在恒等映射附近做增量修正",通常更容易稳定。
层正则化用于稳定数值分布,在每个子层的输入或输出进行归一化操作。根据归一化位置的不同,有两种变体:
- Post-LN:在每个残差块的输出后应用层归一化
- Pre-LN:在每个子层的输入前应用层归一化
标准Transformer编码器层由两个子层构成:多头自注意力(Multi-Head Attention)和前馈网络(FFN),每个子层都包裹着残差连接和层归一化。
3.7 基于Transformer的主流语言模型
基于Transformer架构,研究者开发了多种成功的语言模型:
BERT(Bidirectional Encoder Representations from Transformers)
BERT是由Google在2018年提出的双向编码器表示模型,其模型架构是基于原始实现的多层双向Transformer编码器。BERT的核心是堆叠多层编码器,完全舍弃了解码器。与传统的单向语言模型不同,BERT能够同时利用上下文信息进行理解,这使得它在各种NLP任务中表现出色。
BERT采用完形填空(Masked Language Model)的训练方式,通过随机遮盖句子中的部分词汇,让模型预测被遮盖的词汇。这种预训练方式能够让模型学习到双向的上下文信息。
GPT(Generative Pre-trained Transformer)
GPT是由OpenAI在2018年提出的生成式预训练Transformer,基于Transformer的解码器部分构建。GPT采用Decoder-only架构,核心是因果注意力(Causal Attention)。与BERT的双向编码器不同,GPT只使用Transformer的解码器部分(且去除了编码器-解码器注意力)。
GPT是一种基于Transformer解码器部分的生成式预训练语言模型,专注于文本生成任务。它采用自回归的方式,从左到右依次生成每个词汇。
3.8 Transformer相比RNN的优势
Transformer相比RNN具有以下显著优势:
- 并行计算能力:自注意力机制可以并行计算,大大提高了训练速度
- 长距离依赖建模:能够直接建模任意两个位置之间的关系,不受序列长度限制
- 避免梯度消失:残差连接和层正则化技术有效解决了梯度消失问题
- 更好的可解释性:注意力权重可以可视化,便于理解模型决策过程
四、语言模型的采样方法
语言模型的采样方法决定了如何从模型预测的概率分布中选择下一个词,直接影响生成文本的质量和多样性。
4.1 贪心搜索(Greedy Search)
贪心搜索是最简单的解码策略,每一步都选择当前概率最高的词,不考虑其他可能性。其数学定义为:
idt=argmaxwp(id∣id1:t−1)id_t = \arg\max_w p(id \mid id_{1:t-1})idt=argwmaxp(id∣id1:t−1)
即在每个时间步t选择概率最高的token id。
贪心搜索的优缺点如下:
- 优点:确定性、速度快、通常语法正确
- 缺点:重复乏味、可能陷入循环、错过好的替代方案
- 适用场景:确定性任务、短文本补全
4.2 束搜索(Beam Search)
束搜索是对贪心搜索的改进策略,在每一步生成过程中,它会跟踪多个可能的序列(称为束),而非仅一个。为了缓解贪心搜索的短视,束搜索每一步保留概率最高的k个候选序列(k称为束宽),最后从这k个完整序列中选择总概率最高的一个。
束搜索的工作原理:
- 初始时,选择概率最高的k个词作为初始序列
- 对每个序列,计算下一步的所有可能词,得到k×V个候选
- 选择概率最高的k个候选序列
- 重复直到达到最大长度或遇到结束符
束搜索通过并行维护多个候选序列来优化解码过程,能够产生更多样化和连贯的文本。
4.3 Top-k采样
Top-k采样是一种随机采样方法,将所有候选词按概率从高到低排序,只保留前k个,然后在这k个词中按概率进行采样。其数学公式为:
p^i=pi⋅1{i≤K}∑j=1Kpj\hat{p}i = \frac{p_i \cdot \mathbb{1}\{i \leq K\}}{\sum{j=1}^{K} p_j}p^i=∑j=1Kpjpi⋅1{i≤K}
其中1是指示函数,K是超参数。
Top-k采样的特点:
- 保留概率最高的K个词作为候选,其余的词直接忽略
- 减少了低概率词被采样的可能性
- 可以控制随机性的范围
4.4 Top-p采样(Nucleus Sampling)
Top-p采样也叫核采样或累积概率采样,核心是限定模型只从"概率累计和达到p的候选词集合"中选词。模型会把所有可能的下一个词按概率从高到低排序,然后从前往后累加概率,直到总和超过设定的top_p值,最后只在这个"候选词子集"里随机选择。
Top-p采样的数学定义为:
p^i=pi′∑j=1∣V∣pj′\hat{p}i = \frac{p_i'}{\sum{j=1}^{|V|} p_j'}p^i=∑j=1∣V∣pj′pi′
其中pi′=pi⋅1{∑j=1i−1pj<P}p_i' = p_i \cdot \mathbb{1}\{\sum_{j=1}^{i-1} p_j < P\}pi′=pi⋅1{j=1∑i−1pj<P}
Top-p采样的特点:
- top_p = 1.0时,不做任何限制,模型会从所有候选词中选择
- 相比Top-k更优雅,但两种方法在实践中都很有效
4.5 Temperature机制
Temperature(温度)是控制模型输出随机性最直接的参数,取值通常在0到2之间,默认值一般为1。Temperature是对模型原始输出Logits进行缩放的参数,公式为:
P(yi)=e(xi−xmax)/T∑j=1Ve(xj−xmax)/TP(y_i) = \frac{e^{(x_i - x_{max})/T}}{\sum_{j=1}^{V} e^{(x_j - x_{max})/T}}P(yi)=∑j=1Ve(xj−xmax)/Te(xi−xmax)/T
Temperature的作用机制:
- 低温度(0.1-0.3):使概率分布更尖锐,高概率词被优先选择,输出更确定、更保守
- 中等温度(0.4-0.6):平衡创造性和一致性
- 高温度(1.0以上):使概率分布变平,让原本低概率的词也有机会被选中,从而提升创造性
Temperature通过缩放log概率来重塑分布:
p^i=exp(log(pi)/T)∑j=1∣V∣exp(log(pj)/T)\hat{p}i = \frac{\exp(\log(p_i) / T)}{\sum{j=1}^{|V|} \exp(\log(p_j) / T)}p^i=∑j=1∣V∣exp(log(pj)/T)exp(log(pi)/T)
4.6 采样方法的综合应用
在实际应用中,通常会组合使用多种采样方法。例如,Temperature + Top-P是目前最主流的做法,推荐的参数设置为:Temperature: 0.7 ~ 1.0。
以下是一个综合采样方法的Python实现示例:
python
import torch
import numpy as np
def sample_top_p(logits, top_p=0.9, temperature=1.0):
"""Top-p采样"""
# 对logits应用temperature
logits = logits / temperature
# 计算概率分布
probs = torch.nn.functional.softmax(logits, dim=-1)
# 排序
sorted_probs, sorted_indices = torch.sort(probs, descending=True)
# 计算累积概率
cumulative_probs = torch.cumsum(sorted_probs, dim=-1)
# 找到累积概率超过top_p的位置
mask = cumulative_probs < top_p
# 确保至少保留一个token
mask[..., -1] = True
# 应用mask
masked_probs = probs * mask.scatter(-1, sorted_indices, mask)
# 重新归一化
masked_probs = masked_probs / torch.sum(masked_probs, dim=-1, keepdim=True)
# 采样
indices = torch.multinomial(masked_probs, num_samples=1)
return indices
def sample_top_k(logits, top_k=50, temperature=1.0):
"""Top-k采样"""
# 对logits应用temperature
logits = logits / temperature
# 计算概率分布
probs = torch.nn.functional.softmax(logits, dim=-1)
# 找到top-k的索引
top_k = min(top_k, probs.size(-1))
indices_to_remove = probs < torch.topk(probs, top_k)[0][..., -1, None]
# 应用mask
probs = probs * (1 - indices_to_remove)
# 重新归一化
probs = probs / torch.sum(probs, dim=-1, keepdim=True)
# 采样
indices = torch.multinomial(probs, num_samples=1)
return indices五、语言模型的评测
语言模型的评测是评估模型性能和指导模型改进的重要手段,主要分为内在评测和外在评测两大类。
5.1 内在评测
内在评测主要关注模型本身的特性,不涉及具体的下游任务。
困惑度(Perplexity)
困惑度是评估语言模型最常用的指标之一,用于衡量模型对测试数据的预测不确定性。它反映了模型在每个位置平均需要考虑的可能词数------困惑度越低,模型预测越准确。
困惑度的定义为:
PP(W)=exp(−1N∑i=1NlogP(wi∣wi−1))PP(W) = \exp(-\frac{1}{N}\sum_{i=1}^{N}\log P(w_i \mid w_{i-1}))PP(W)=exp(−N1i=1∑NlogP(wi∣wi−1))
其中N是序列长度。困惑度越低,说明模型对数据的拟合程度越好,预测能力越强。如果一个模型的困惑度为100,意味着在预测下一个词时,模型的表现相当于在100个等概率的候选词中随机选择。
困惑度的计算可以通过以下代码实现:
python
import math
def calculate_perplexity(model, tokenized_corpus):
"""计算困惑度"""
total_log_prob = 0.0
total_tokens = 0
for tokens in tokenized_corpus:
# 计算句子的对数概率
log_prob = 0.0
for i in range(1, len(tokens)):
context = tokens[:i]
target = tokens[i]
# 获取模型预测
logits = model(context)
# 获取目标词的log概率
prob = torch.nn.functional.log_softmax(logits, dim=-1)
target_idx = vocab[target]
log_prob += prob[target_idx]
total_log_prob += log_prob
total_tokens += len(tokens) - 1
# 计算平均对数概率
avg_log_prob = total_log_prob / total_tokens
# 计算困惑度
perplexity = math.exp(-avg_log_prob)
return perplexity5.2 外在评测-基于指标的评测
外在评测关注模型在具体任务上的表现,基于指标的评测使用各种预定义的评估指标。
BLEU(Bilingual Evaluation Understudy)
BLEU是机器翻译领域最著名的自动评估指标,其核心思想是质量被认为是机器输出与人类输出之间的对应关系:"机器翻译越接近专业人工翻译就越好"。
BLEU的计算方法:
- 测量生成文本中有多少n-gram(通常是1-gram到4-gram)出现在参考文本中
- 应用简短惩罚以避免过短输出获得不公平的高分
- BLEU分数范围从0到1(或0到100%),分数越高表示生成文本与参考文本越相似
BLEU的计算公式涉及精确率(precision)的几何平均和简短惩罚(brevity penalty):
BLEU=BP×exp(∑n=1Nwnlogpn)BLEU = BP \times \exp(\sum_{n=1}^{N} w_n \log p_n)BLEU=BP×exp(n=1∑Nwnlogpn)
其中p_n是n-gram精确率,w_n是权重,BP是简短惩罚因子。
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
ROUGE是另一个广泛用于文本生成任务的评估指标,主要用于摘要和机器翻译任务的评估。ROUGE-LCS F1是常用的变体,如某研究中的结果显示:mean (± sd) 0.201 (± 0.053) 0.334 (± 0.120) 0.347 (± 0.120)。
5.3 外在评测-基于语言模型的评测
基于语言模型的评测使用其他语言模型来评估目标模型的输出质量。
语言模型困惑度
使用高质量语言模型计算生成文本的困惑度。如果生成的文本符合自然语言规律,那么在高质量语言模型上的困惑度应该较低。
零样本学习能力评估
零样本学习能力是评估大语言模型的重要维度。零样本评估是指模型仅根据问题本身生成答案,不提供任何示例。
评估零样本学习能力的基准包括:
-
MMLU(Massive Multitask Language Understanding):该基准旨在通过评估零样本和少样本设置下的模型表现,全面衡量文本模型在多种任务上的准确性和泛化能力。它测试模型在57个不同学科(包括人文、社科、STEM等)上的零样本和少样本推理能力。
-
SuperGLUE:SuperGLUE是继GLUE之后的一个更为复杂和挑战性的基准测试,它引入了更难的任务和更复杂的数据集,用以推动语言理解模型的发展。SuperGLUE包括问答、因果推理和多项选择等任务。
5.4 主流评测基准
GLUE(General Language Understanding Evaluation)
GLUE旨在测试模型在理解英语文本方面的能力。它是一个用于训练、评估和分析自然语言理解系统的资源集合。
SuperGLUE
SuperGLUE是一个新的基准测试,借鉴了原始GLUE基准的经验教训,提供了一组更困难的语言理解任务、改进的资源和新的公共排行榜。SuperGLUE是一个用于评估通用英语语言理解系统的多任务基准。
LAMBADA
LAMBADA(Language Models for Dialog Applications)是一个评估LLM对话技能的基准。它使用模拟对话,其中LLM与人类交互,并在以下方面进行评估:
- 对话连贯性
- 上下文理解能力
- 知识回答准确性
- 对话策略合理性
5.5 综合评测体系
现代语言模型评测通常采用综合评测体系,结合多种指标和方法:
- 自动指标与人工评估结合:BLEU和ROUGE分数用于基本质量评估,同时结合人工评估确保结果的可靠性
- 内在评测与外在评测结合:困惑度评估模型的语言建模能力,下游任务性能评估模型的实际应用效果
- 零样本、少样本和微调评估:全面评估模型的泛化能力和适应能力
在实际评测中,建议将困惑度与BLEU等外部评估指标结合使用。例如,在本次评测中,主要报告BLEU和ROUGE分数,若需要进一步分析模型的语言流畅度及语义一致性,亦可结合perplexity和BERTScore。
结语
语言模型技术从早期的n-grams统计方法发展到如今的Transformer架构,经历了从简单到复杂、从浅层到深层的演进历程。每种技术都有其独特的优势和适用场景:
- n-grams模型虽然简单,但在实时性要求高、资源受限的场景中仍有价值
- RNN及其变体LSTM、GRU通过循环结构和门控机制实现了对序列依赖的建模
- Transformer通过自注意力机制彻底解决了长距离依赖问题,实现了高度并行化
在采样方法方面,从贪心搜索到各种随机采样策略,为不同应用需求提供了丰富的选择。评测体系的完善则为模型改进和性能对比提供了科学依据。
随着技术的不断发展,语言模型在自然语言处理领域的应用将更加广泛和深入。理解这些基础技术,对于把握语言模型的发展趋势和推动相关研究具有重要意义。未来,我们可以期待更多创新的架构和方法出现,进一步提升语言模型的能力边界。