1.4 核心名词解释:Token、RAG、Agent、MCP是什么
本文适合谁:刚接触AI开发、被各种术语搞晕的读者。读完这篇,你会对课程中反复出现的核心词有清晰的直觉理解,不再看到这些词就发懵。
本文阅读时间:约14分钟
学这门课,你会反复看到这些词:Token、Embedding、RAG、Agent、MCP......
每次看到都似懂非懂?这篇文章专门解决这个问题。
我们会对照权威定义,用生活化的类比,把这些词一次性说清楚。
1.1 Token:人与机器对话的"翻译官"
在了解AI开发的第一天起,你可能就遇到了这个词:token。
它频繁出现在各种场合:API文档说"每1000个token收费多少钱",开发者说"这个模型的上下文窗口是128K token",技术文章说"LLM的训练目标是预测下一个token"。
那么,token到底是什么?
1.1.1 Token是什么?
Token是大语言模型处理文字时使用的最小单位。
不是按照"词"来分,也不是按照"字"来分,而是由一套专门的"分词算法"切割的基本片段。token可以是一个词、半个词、一个字、一个标点符号,甚至是一个空格。
举个例子:
英文句子: "Hello, world!"
Token切割:["Hello", ",", " world", "!"] → 4个Token
中文句子: "你好世界"
Token切割:["你好", "世界"] → 2个Token
英文单词: "understanding"
Token切割:["under", "stand", "ing"] → 3个Token1.1.2 为什么中英文Token数不同?
这是很多人第一次接触Token时会困惑的问题。
根本原因是训练数据的构成。主流大语言模型的训练数据中,英文内容占绝大多数。分词算法(Tokenizer)是在这些训练数据上优化的,英文词汇被切割成了非常紧凑的token------常见英文单词通常是1个token,不常见单词被拆分成2-3个。
而中文字符对分词算法来说是"高频但不熟悉"的字符组合,所以切割粒度更粗。
实际结果:
- 英文:1个token ≈ 4个字母(或约0.75个单词)
- 中文:1个token ≈ 1到1.5个汉字
这意味着同样的内容,用中文写的token数要比英文多。这直接影响API调用成本和模型的实际处理能力。
一个实际影响:如果一个模型的上下文窗口是128K token,处理英文内容大约能支持约10万个单词(约200页),而处理中文内容大约只有约10万个汉字(约140页)。
1.1.3 Token在模型里是怎么工作的?
在大模型生成内容的过程中,需要先把人们输入的文字转化成一个个token,然后根据对上下文中所有token的理解和分析,预测接下来应该生成的token内容,再将这些token转换成人们熟悉的文字输出。
在整个过程中,token像极了人类与机器对话的"翻译官"------让不懂机器语言的普通人,也能跨越技术鸿沟,轻松和机器对话。
1.1.4 Token和上下文窗口的关系
模型能"记住"的对话内容是有上限的------这就是上下文窗口(Context Window),以token为单位计量。
超过这个上限,模型就会"忘记"最早的内容,就像工作记忆有容量限制一样。
主流模型的上下文窗口(以官方最新文档为准,以下为参考值):
- GPT-4o:128K token(约10万英文单词)
- Claude 3.5 Sonnet:200K token(约15万英文单词)
- Gemini 1.5 Pro:1M token(约75万英文单词)
越大的上下文窗口,意味着可以处理更长的文档、更长的对话历史------但成本也更高。
1.1.5 Token也是计费单位
除了文本处理的最小单位,token也是AI API的计费单位。你每次调用大模型API,费用取决于:
- 输入了多少token(你发给模型的内容)
- 输出了多少token(模型返回给你的内容)
通常输出token比输入token贵2-4倍,因为生成比理解需要更多计算。
后续学习:第6章《LLM基础》会详细讲token化(Tokenization)的工作原理。
1.2 Embedding:把文字变成"坐标"
如果说token是把文字切碎,那Embedding就是把这些碎片放进一个"意义空间",给每段文字标上坐标。
1.2.1 为什么要把文字变成数字?
计算机不理解文字,只会算数学。要让AI知道"猫"和"狗"比"猫"和"汽车"更相似,必须把文字转成数字才能计算相似度。
Embedding(向量化/嵌入)做的就是这件事:把每段文字转换成一串数字(向量),使得语义相近的文字,转成的数字向量也更接近。
"猫" → [0.2, 0.8, 0.1, ...]
"狗" → [0.3, 0.7, 0.2, ...] ← 和猫的向量很接近(语义相关)
"汽车" → [0.9, 0.1, 0.8, ...] ← 和猫的向量差很远(语义无关)1.2.2 这有什么用?
最重要的应用是语义搜索------不是找关键词,而是找意思相近的内容。
你问"怎么提升工作效率",传统关键词搜索找不到标题是"时间管理技巧"的文章(因为词不一样);语义搜索可以,因为两者的Embedding向量很接近,AI知道它们讲的是相关的事情。
这正是RAG系统(下一节)的核心机制。
后续学习:第6章《LLM基础》和第11章《RAG》会深入讲Embedding的原理和应用。
1.3 RAG:给AI接上"外挂知识库"
全称:Retrieval-Augmented Generation(检索增强生成)
1.3.1 大模型的两个硬伤
大语言模型有两个天然的局限:
第一,知识有截止日期。 模型在某个时间点完成训练,之后发生的事它一概不知。你问它"最新的iPhone是哪款",它只能告诉你训练截止前的信息。
第二,不认识你的私有数据。 公司内部文档、你的个人笔记、行业私有数据库------这些模型从来没见过,自然无法回答相关问题。
RAG就是为了解决这两个问题而生的。
1.3.2 RAG是怎么工作的?
按照AWS的定义:RAG对LLM输出进行优化,使其能在生成前引用训练数据来源之外的权威知识库。
思路很朴素------让AI在回答之前先去查资料。
没有RAG:
用户问:"我们公司Q3的销售数据是多少?"
AI答:"对不起,我没有这个信息。"
有RAG:
① 先去公司知识库检索相关文档
② 找到Q3销售报告
③ 基于报告内容回答:"根据Q3报告,销售额为..."一个很好的类比:RAG就像开卷考试。没有RAG的AI是闭卷考试------只能用脑子里记住的知识;有RAG的AI是开卷考试------可以翻书查资料,但最终还是要自己理解和组织答案。
1.3.3 RAG的四个阶段
按照AWS的定义,RAG完整流程包括四个阶段:
第一阶段:创建外部数据
把你的知识库(PDF文档、网页、数据库、内部Wiki等)转换成AI可以检索的格式:
- 把文档切割成合适大小的片段(比如每段500字)
- 用Embedding模型把每个片段转成向量
- 存入向量数据库(一种专门存储和检索向量的数据库)
第二阶段:检索相关内容
用户提问时,同样把问题转成向量,然后在向量数据库里找出最相似的几个文档片段------这就是"检索"。
第三阶段:增强提示词
把检索到的文档片段塞进发给LLM的提示词里,告诉它:"这是相关参考资料,请基于这些内容回答问题"。
第四阶段:持续更新
外部数据需要定期更新------新文档加进来,旧文档过期了要删除。这保证了知识库始终是最新的。
用户问题
↓
① 问题向量化(Embedding)
↓
② 向量检索(找相似文档片段)
↓
③ 把检索结果塞进Prompt
↓
④ LLM基于Prompt作答
↓
答案给用户后续学习:第11章《RAG》完整讲解如何构建RAG系统,从文档切割到向量检索到最终生成。
1.4 Agent:能自主行动的AI
如果说普通AI是一个博学的顾问------你问什么它答什么,那Agent就是一个既能出主意、又能亲自去执行的助理。
1.4.1 普通AI和Agent的区别
普通AI(问答模式):你问,它答。它能说,但不能做。
Agent(行动模式):你给它一个目标,它自己制定计划、调用工具、一步步完成任务。
普通AI:
用户:"帮我分析这份报告"
AI:(分析后)"报告的主要结论是..."
→ 只能说,不能做
Agent:
用户:"帮我分析这份报告,然后发邮件给老板"
Agent:
① 读取报告文件(调用文件读取工具)
② 分析内容(用LLM推理)
③ 起草邮件(用LLM生成)
④ 发送邮件(调用邮件发送工具)
→ 能说,也能做按照AWS的定义:**AI Agent是与环境交互、收集数据、执行满足预定目标的自主任务的软件程序。**核心循环:感知→决策→行动。
1.4.2 Agent的四个核心能力
| 能力 | 说明 | 类比 |
|---|---|---|
| 感知 | 接收输入(文字、图片、文件、网页) | 眼睛和耳朵 |
| 规划 | 把大任务拆成小步骤 | 大脑思考 |
| 行动 | 调用工具执行(搜索、读写文件、发请求) | 手脚 |
| 反思 | 检查结果,出错了重试 | 自我纠错 |
1.4.3 工具调用:Agent行动的基础
Agent能行动,靠的是工具调用(Function Calling / Tool Use)。
简单说,就是给LLM准备一批可以调用的函数,比如:
search_web(query)--- 搜索网络read_file(path)--- 读取文件send_email(to, subject, body)--- 发邮件query_database(sql)--- 查询数据库
LLM决定"什么时候用哪个工具、传什么参数",工具负责实际执行,结果再返回给LLM。整个过程LLM是"大脑",工具是"手脚"。
1.4.4 Agent的七种类型
按照AWS的分类,Agent根据复杂度和能力,可以分为七种类型:
| 类型 | 特点 | 类比 |
|---|---|---|
| 简单反射型 | 只根据当前输入做决定,不考虑历史 | 自动门(有人就开) |
| 基于模型型 | 维护一个内部世界模型,考虑历史状态 | 导航APP(知道你在哪里) |
| 基于目标型 | 根据目标来规划行动,不只是反应 | 旅行规划助手 |
| 基于效用型 | 权衡不同选项的"效用",选最优方案 | 投资顾问(评估风险收益) |
| 学习型 | 能从经验中学习,不断改进策略 | 个性化推荐系统 |
| 分层型 | 由多个层级的Agent组成,高层指挥低层 | 公司管理体系 |
| 多Agent型 | 多个Agent协作,各有分工 | 协作团队 |
当前主流的LLM Agent,大多是基于目标型或基于效用型的变体。多Agent型是目前的研究热点------让多个专业Agent分工协作,完成复杂任务。
后续学习:第9章《工具调用》讲如何给AI接工具;第12章《Agent基础》讲如何构建完整的Agent系统。
1.5 MCP:让AI工具标准化的"USB接口"
全称:Model Context Protocol(模型上下文协议)
1.5.1 没有标准之前的混乱
在MCP出现之前,每家公司给AI接工具的方式都不一样:
- 给Claude接GitHub工具要写一套代码
- 给GPT接同一个GitHub工具,要重新写一套
- 换个新模型,所有工具代码全部重写
这就像每家电器厂商都用自己的充电接口------你买了三台设备,就得带三根不同的充电线。
1.5.2 MCP的出现
2024年底,Anthropic提出了MCP这个开放标准,定义了AI模型和外部工具之间"怎么沟通"的统一格式。
就像USB标准的出现,让所有设备都能插到同一个口子上:
没有MCP(接口碎片化):
Claude ←→ 专属GitHub连接器(一套代码)
GPT ←→ 另一套GitHub连接器(要重写)
有MCP(统一接口):
Claude ──┐
GPT ──┤── MCP标准接口 ──→ GitHub MCP Server
Gemini ──┘ ──→ 数据库MCP Server
──→ Slack MCP Server任何支持MCP的AI,都能直接用任何MCP工具------写一次,到处用。
1.5.3 MCP的三个角色
| 角色 | 作用 | 类比 |
|---|---|---|
| MCP Server | 提供工具的服务(如GitHub Server) | USB设备 |
| MCP Client | 使用工具的AI应用 | 带USB接口的电脑 |
| MCP协议 | 两者之间的通信规范 | USB标准本身 |
1.5.4 MCP的生态现状(截至2026年3月)
MCP从2024年底发布以来,生态扩展速度超出预期:
- 主流AI平台支持:Claude(Anthropic原生支持)、GPT(OpenAI官方支持)、Gemini(Google支持)已成为标配
- 官方MCP Server:Anthropic维护了一批官方MCP Server,包括文件系统、数据库、浏览器、GitHub、Slack等常用工具
- 社区生态:GitHub上已有数千个社区贡献的MCP Server,覆盖从ERP系统到各类SaaS服务
- IDE集成:Cursor、VS Code等主流开发工具已内置MCP支持,让AI编程助手能直接访问本地文件和工程上下文
- 企业采用:越来越多的企业开始将内部系统通过MCP暴露给AI,用于自动化内部流程
MCP已成为Agent工具集成的主流标准,几乎所有新的AI应用框架都在优先支持MCP。
后续学习:第10章《MCP协议》完整讲解如何使用和开发MCP工具。
1.6 一张图,把它们串起来
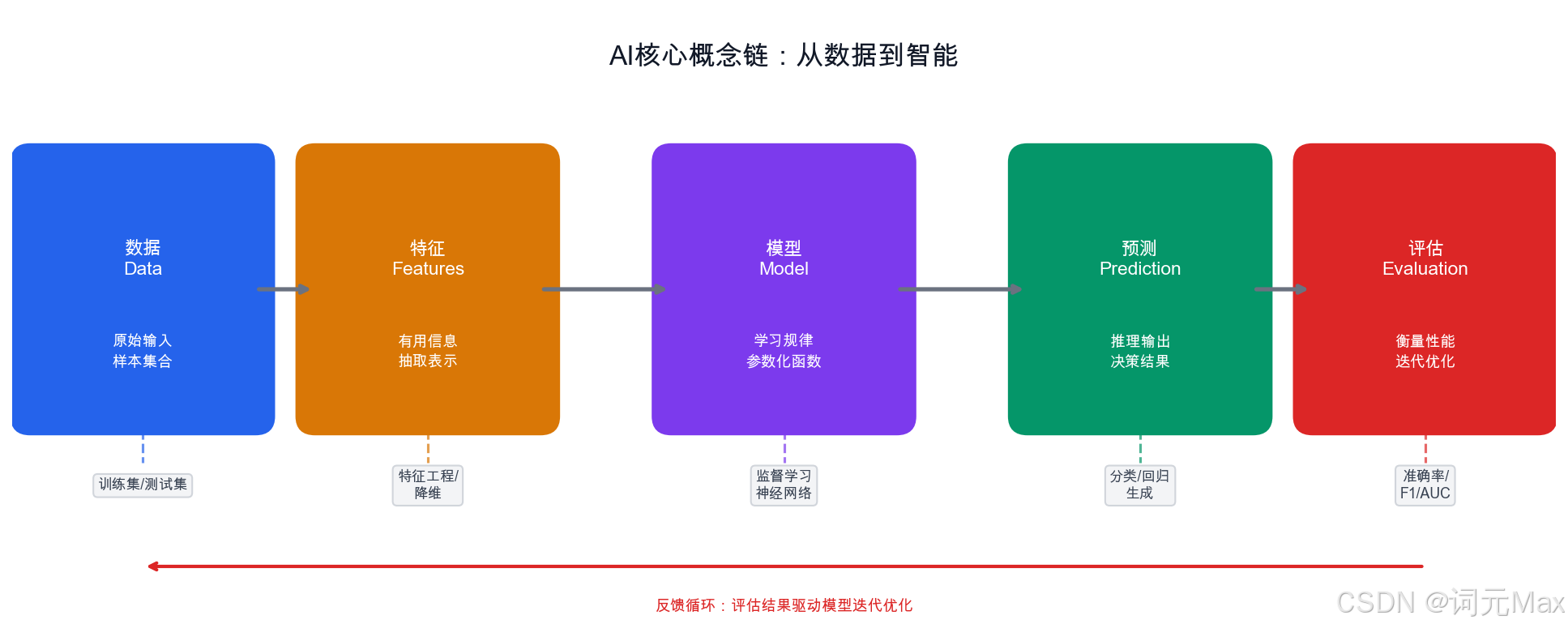
图1.6:核心概念协同工作流------从用户输入到最终输出的完整链路
串联起来理解:
- 你的文字输入被切成Token送给LLM
- LLM如果需要查资料,通过Embedding 在RAG知识库里找相关内容
- 如果需要执行任务,LLM作为Agent 大脑,通过MCP协议调用各种工具
- 工具执行完把结果返回,最终给你答案
1.7 快速记忆卡片
| 词 | 一句话 |
|---|---|
| Token | AI读文字的最小片段,也是计费单位;中文比英文多用token |
| Embedding | 把文字变成数字向量,语义相近的向量也相近,让AI能算相似度 |
| RAG | 先查资料再回答,四个阶段:创建数据/检索/增强/持续更新 |
| Agent | 能自主感知、规划、调用工具、完成多步任务的AI,有7种类型 |
| 工具调用 | Agent调用函数/API执行实际操作的机制,是Agent行动的基础 |
| MCP | AI工具的统一接口标准,写一次到处用,已成主流 |
下一步:第1章到这里结束。带着这张名词地图,进入第2章《Python基础》------从这里开始动手写代码。