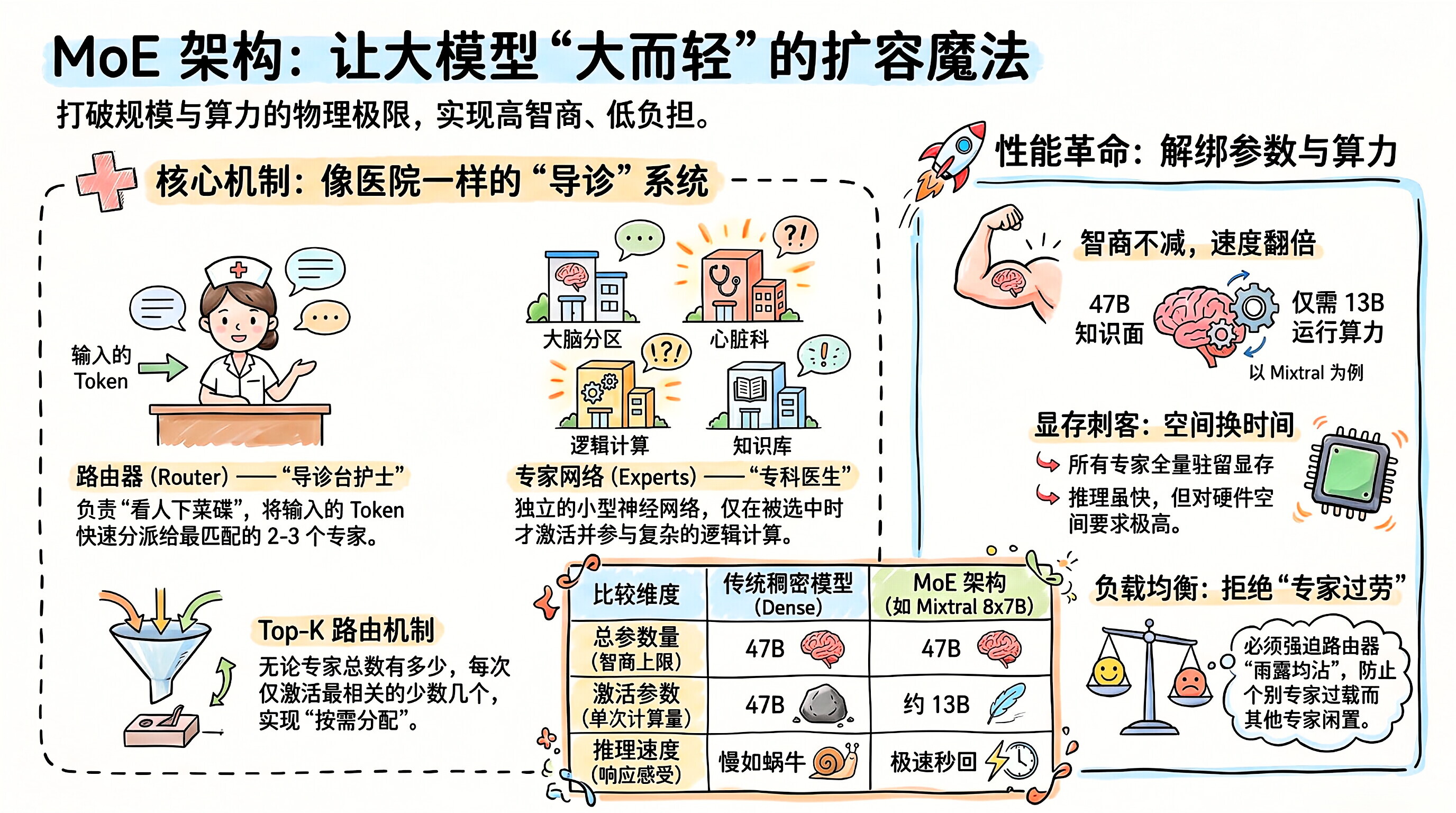
MoE (Mixture of Experts, 混合专家架构) 是大模型突破"物理极限"、实现千亿甚至万亿参数的终极扩容魔法。
如果说传统的稠密模型(Dense Model,比如 Llama 2 或早期的 GPT-3)是一个**"通才"** ,每次遇到问题都要调动全身所有的脑细胞去思考; 那么 MoE 就是一家极其庞大的**"综合性三甲医院"** ,里面养着上百个**"专科医生"** 。
它完美解决了 AI 圈的一个死结:我们想让模型变得无限大(更聪明),但我们的 显卡 算力 却不够它每一次都全盘运转。
1.🛑 核心痛点:大模型的"体重焦虑"
AI 圈有一个铁律叫 Scaling Law (缩放定律):参数量越大,模型越聪明。
-
传统架构的悲哀 :在传统的稠密(Dense)架构中,模型如果有一千亿个参数,那么当你输入一个字(Token)时,这一千亿个参数全都要参与计算。
-
物理极限:随着模型朝着万亿规模进发,如果每个字都要做万亿次矩阵乘法,不仅推理速度会慢如蜗牛,全世界的电网和显卡算力也吃不消。
我们需要一种机制:让模型"看起来很大,但跑起来很轻"。
2.💡 破局之道:分管包干与"只激活部分脑区"
科学家借鉴了人脑的工作机制:你算数学题时,主要激活负责逻辑的脑区;听音乐时,激活听觉皮层。你不需要 100% 的脑细胞同时放电(那样叫癫痫)。
MoE 架构就实现了这一点。它把 Transformer 中的前馈神经网络(FFN,也就是最占参数量的部分)切分成了多个独立的"小网络",我们称之为专家 (Experts)。
3.⚙️ MoE 的两大核心组件
当一个字(Token)进入 MoE 模型时,会发生以下流程:
A. 路由器 (Router / Gate Network) ------ "导诊台护士"
-
功能:这是一个非常小、但极其关键的神经网络。它的工作是**"看人下菜碟"**。
-
机制:当读取到"苹果"这个词时,路由器会飞速计算,然后决定:"这个词跟水果和科技有关,把它派给 2 号专家和 5 号专家!"
-
Top-K 路由 :通常,模型不会激活所有专家。比如"8 选 2(Top-2)",意味着不管总共有多少个专家,每个 Token 只激活最匹配的 2 个专家。
B. 专家网络 (Experts) ------ "专科医生"
-
功能:负责干粗活。被路由器选中的专家接收数据,进行复杂的计算。
-
数学融合:算完之后,路由器会根据每个专家的"权威度(权重)"把他们的结果加权混合起来。
-
底层公式:y = \\sum_{i=1}\^{K} G_i(x) E_i(x) (G 是路由器的评分,E 是专家的计算结果,K 是激活的专家数量)。
4.🚀 逆天优势:参数量与计算量的"完美解绑"
这是理解 MoE 最关键的一个概念:总参数量 vs. 激活参数量。
以著名的开源模型 Mixtral 8x7B 为例:
-
它由 8 个 70 亿(7B)参数的专家组成,总参数量高达 470 亿(47B)。所以它的知识面非常广、非常聪明。
-
但是,因为它采用了"8 选 2"的路由机制,每次处理一个字时,只有 2 个专家在工作。它的激活参数量(实际计算量)只有大约 130 亿(13B)。
结果:你得到了一个拥有 47B 智商的模型,但它的运行速度和消耗的算力,仅仅相当于一个 13B 的小模型!
(传闻中, GPT-4 也是一个由 8 个 2200 亿参数组成的超级 MoE ,所以它既极其强大,又能做到秒回。)
5.⚔️ 致命代价:MoE 不是免费的午餐
既然 MoE 这么强,为什么大家不全用它?因为它有两大"命门":
-
显存 刺客 ( VRAM 墙):
-
虽然每次只激活 2 个专家,但你必须把所有的 8 个专家都常驻在显卡的 内存 ( VRAM ) 里,以备路由器随时调用。
-
所以,MoE 省的是算力 (FLOPs/时间) ,但绝不省内存 (空间)。普通人的电脑根本装不下庞大的 MoE 模型。
-
-
负载不均 (Load Balancing 灾难):
-
路由器是一个喜欢"偷懒"的组件。如果训练不好,它可能会发现把所有问题都丢给 1 号专家最省事。
-
结果导致 1 号专家过劳死(算力瓶颈),而其他 7 个专家天天喝茶(闲置)。科学家必须在训练时加入"负载均衡损失函数",强迫路由器雨露均沾。
-
总结
MoE (混合专家架构) 是一场极其优雅的架构魔术。
它通过"导诊台分发"的逻辑,打破了算力对模型规模的诅咒,成为了当今(如 GPT-4、DeepSeek-V3)通往超级 AI 的标配底层架构。