目录
[3.Anchor Free](#3.Anchor Free)
[5.正负样本匹配策略 SimOTA](#5.正负样本匹配策略 SimOTA)
1.前言
- YOLOX是旷视科技在2021年发表的一篇文章,当时主要对标的网络就是很火的YOLO v5,如果对YOLO v5不了解的可以看下我之前的文章。那么在YOLOX中引入了当年的哪些黑科技呢,简单总结主要有三点:decoupled head(解耦检测头)、anchor-free以及advanced label assigning strategy(SimOTA)。YOLOX的性能如何呢,可以参考下图,YOLOX比当年的YOLO v5略好一点,并且论文中说他们利用YOLOX获得了当年的Streaming Perception Challenge的第一名。
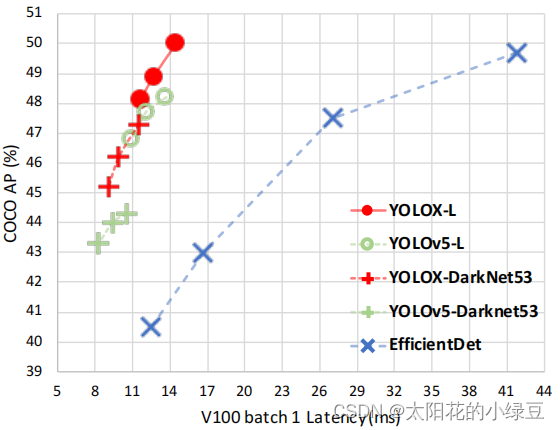
- 那在项目 中YOLO v5和YOLOX到底应该选择哪个。建议是,如果你的数据集图像分辨率不是很高,比如640x640,那么两者都可以试试。如果你的图像分辨率 很高,比如1280x1280,那么我建议使用YOLO v5。
2.网络结构
- 下图是YOLOX-L网络结构。因为它是基于YOLO v5构建的,所以Backbone以及PAN部分和YOLO v5是一模一样的(红圈),注意这里说的YOLO v5是对应tag:v5.0版本的,而我们之前讲的YOLO v5文章中是tag:v6.1版本,所以在Backbone部分有些细微区别。
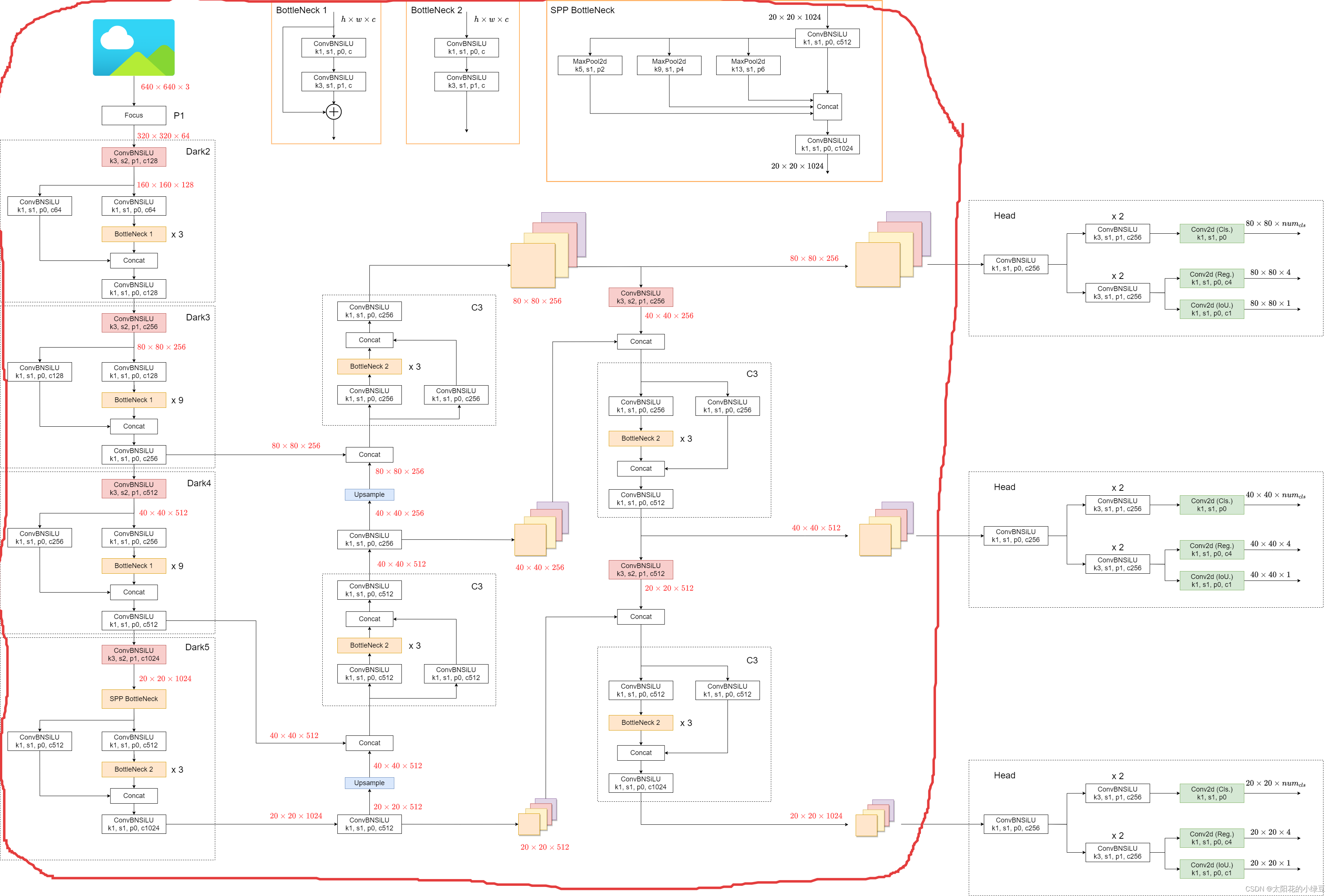
- 那YOLOX和YOLO v5在网络结构上有什么差别呢,主要的差别就在检测头head部分。之前的检测头就是通过一个卷积核大小为1x1的卷积层实现的,即这个卷积层要同时预测类 别分数、边界框回归参数以及object ness ,这种方式在文章中称之为耦合的检测头(coupled detection head)。作者说采用耦合的检测头是对网络有害的,如果将耦合的检测头换成解耦的检测头(decoupled detection head)能够大幅提升网络的收敛速度。
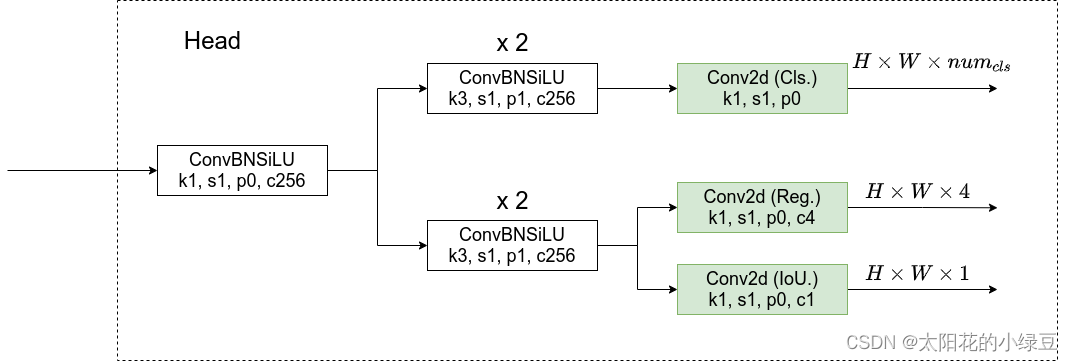
- 解耦检测头结构如下图。解耦检测头中对于预测Cls.、Reg.以及IoU参数分别使用三个不同的分支,这样就将三者进行了解耦。这里需要注意一点,在YOLOX中对于不同的预测特征图采用不同的head,即参数不共享(就是说上图右边的三个检测头参数不共享)。
3.Anchor Free
- YOLOX是Anchor-Free的网络,所以head在每个位置处直接预测4个目标边界框参数tx,ty,tw,th,如下所示,这4个参数分别对应预测目标中心点相对Grid Cell左上角(c_x, c_y)的偏移量,以及目标的宽度、高度因子。注意这些值都是相对预测特征图尺度上的,如果要映射回原图需要乘上当前特征图相对原图的步距stride。
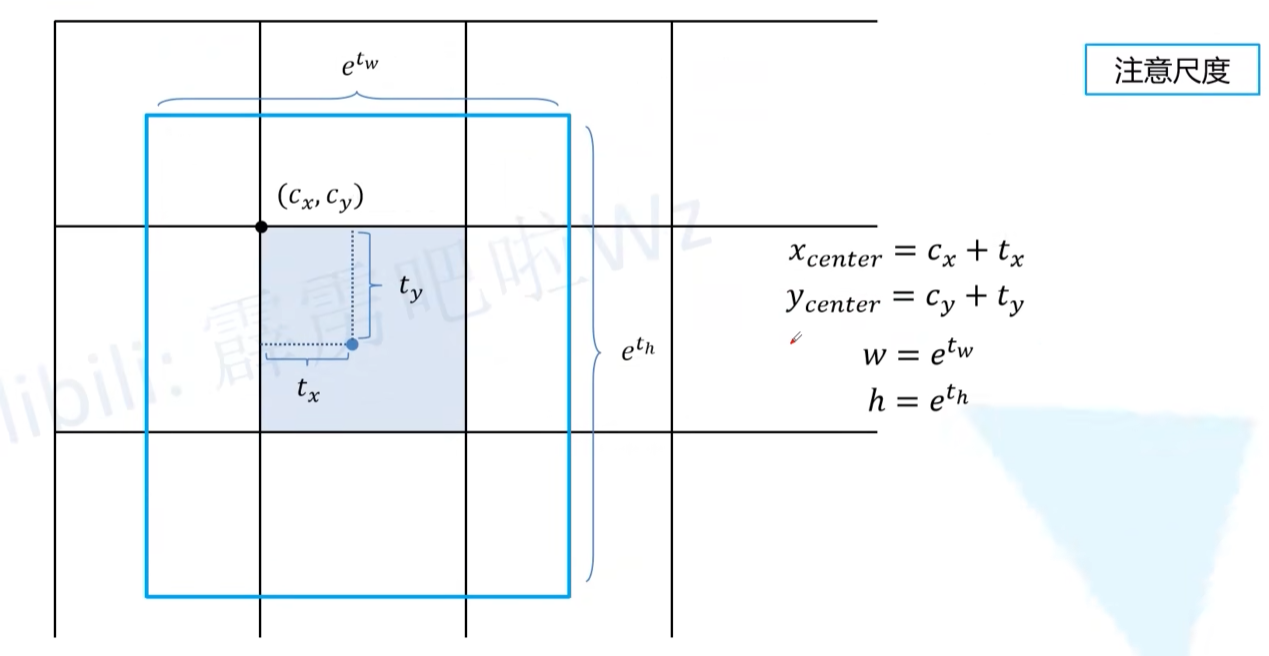
- 可以发现w和h的公式没有×anchor的长宽,所以和anchor已经没有关系了。
4.损失计算
- 损失由分类损失、定位损失和obj损失三部分组成。

- Npos就是正样本的个数。
5.正负样本匹配策略 SimOTA
(1)SimOTA原理
- SimOTA简单来说,就是将匹配正负样本的过程看成一个最优传输问题。方便理解就举个简单的例子。如下图所示,假设有1到6共6个城市(图中的五角星),有2个牛奶生产基地A和B。现在要求这两个牛奶生产基地为这6个城市送牛奶,究竟怎样安排才能最小化运输成本。假设运输成本(cost)仅由距离决定,那么很明显城市1、2、3由牛奶生产基地A负责,城市4、5、6由牛奶生产基地B负责,运输成本最低。
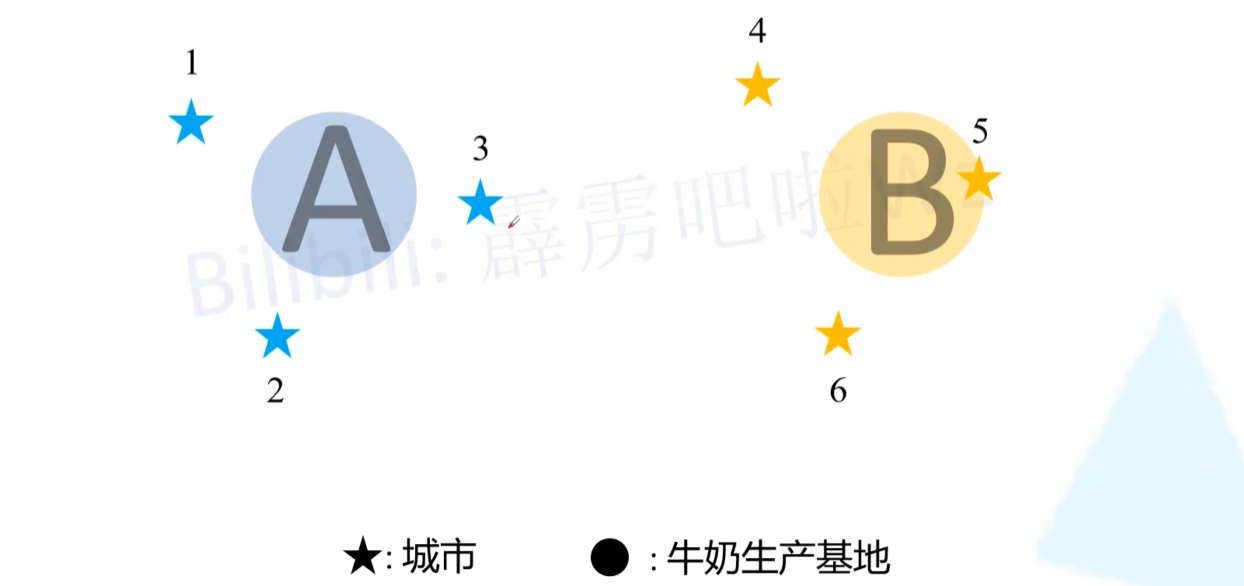
- 那么在SimOTA正负样本匹配过程中,城市对应的是每个样本(对应grid网格中的每个cell),牛奶生产基地对应的是标注好的GT Bbox(真实目标框),那现在的目标是怎样以最低的成本将GT分配给对应的样本(cell) 。根据论文中的公式1,cost的计算公式如下,其中λ为平衡系数,代码中设置的是3.0:

(2)cost计算
- 在SimOTA中,首先会将落入目标GT Bbox内或落入fixed center area内的样本给筛选出来,在源码中作者将center_ratius设置为2.5,即fixed center area是一个5x5大小的box。如上图所示,feature map(或者称grid网格)中所有打勾的位置都是通过预筛选得到的样本。注意,这里将落入GT Bbox与fixed center area相交区域内的样本用橙色的勾表示。
- 接着计算网络在这些样本(anchor point)位置处的预测值(目标类别以及目标边界框)和每个GT的以及(由于回归损失是IoULoss,所以这里也知道每个样本和每个GT的IoU),然后再计算每个样本和每个GT之间的cost(cost公式为下图右边)。
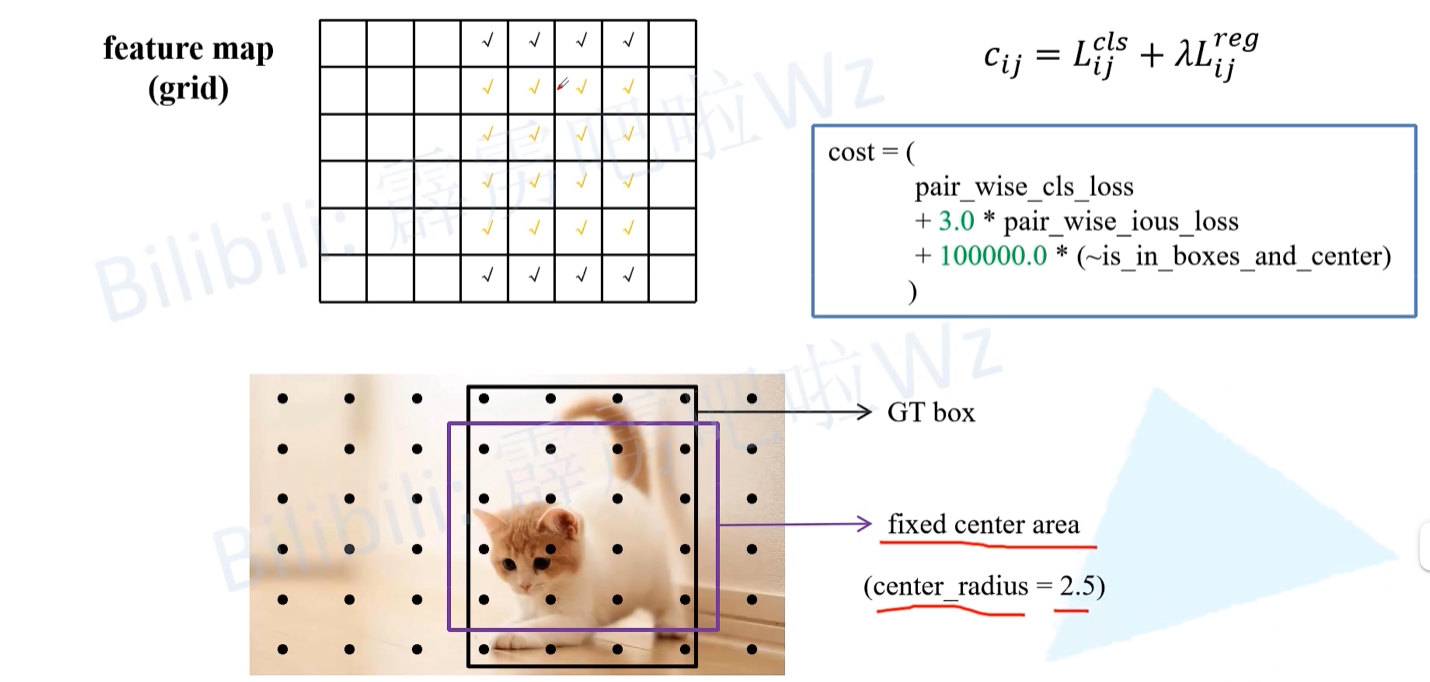
- pair_wise_cls_loss就是每个样本与每个GT之间的分类损失
- pair_wise_ious_loss是每个样本与每个GT之间的回归损失
- is_in_boxes_and_center代表那些落入GT Bbox与fixed center area交集内的样本,即上图中橙色勾对应的样本,然后这里进行了取反~表示不在GT Bbox与fixed center area交集内的样本(非橙色样本),即上图中黑色勾对应的样本。接着又乘以100000.0,也就是说对于GT Bbox与fixed center area交集外的样本cost加上了一个非常大的数,这样在最小化cost过程中会优先选择GT Bbox与fixed center area交集内的样本。
(3)正负样本的匹配
- 接下来利用cost去进行正负样本的匹配
- 首先构建两个矩阵,一个是之前筛选出的Anchor Point与每个GT之间的cost矩阵 ,另一个是Anchor Point与每个GT之间的IoU矩阵。
- 接着计算n_candidate_k并结合IoU对Anchor Point做进一步筛选(保留IoU大的Anchor Point),n_candidate_k是取10和Anchor Point数量之间的最小值,在下面给的这个示例中由于Anchor Point数量为6,所以n_candidate_k=6,故保留所有的Anchor Point。
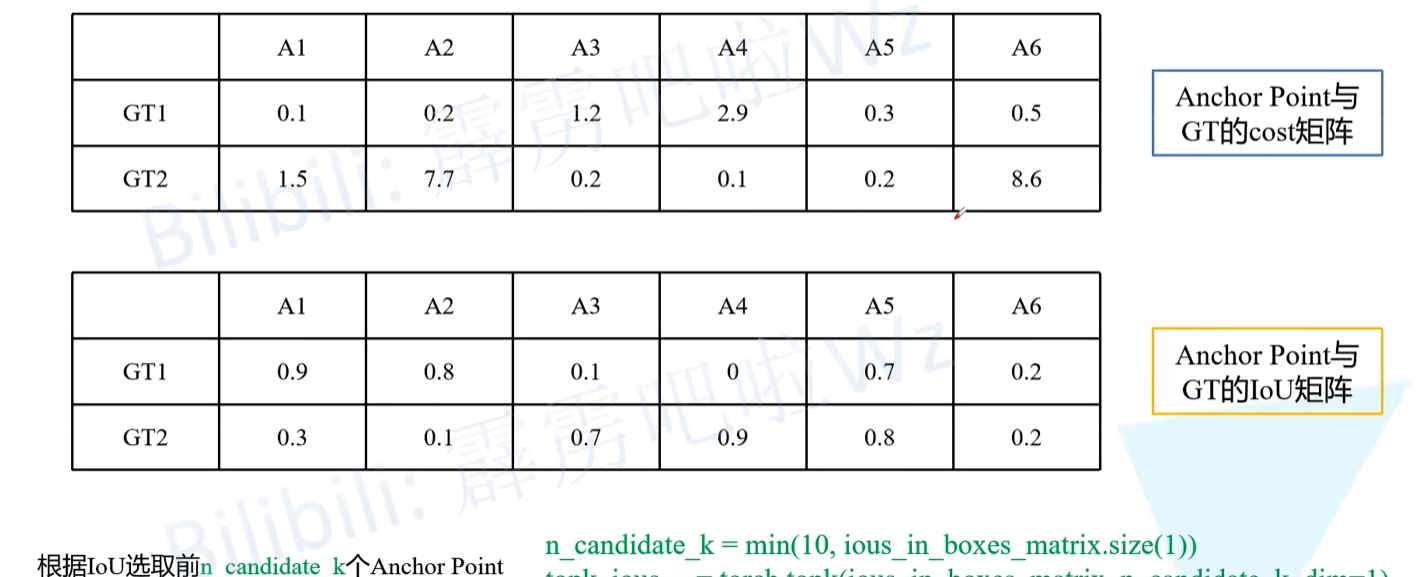
- 然后通过IOU矩阵计算每个GT的IOU的和(结果向下取整),得到dynamic_ks,这里对于GT1和GT2都是3,所以GT1有3个正样本,GT2也有3个正样本。
- 然后在cost矩阵中取cost最小的三个为正样本,GT1是A1,A2,A5,GT2是A3,A4,A5.
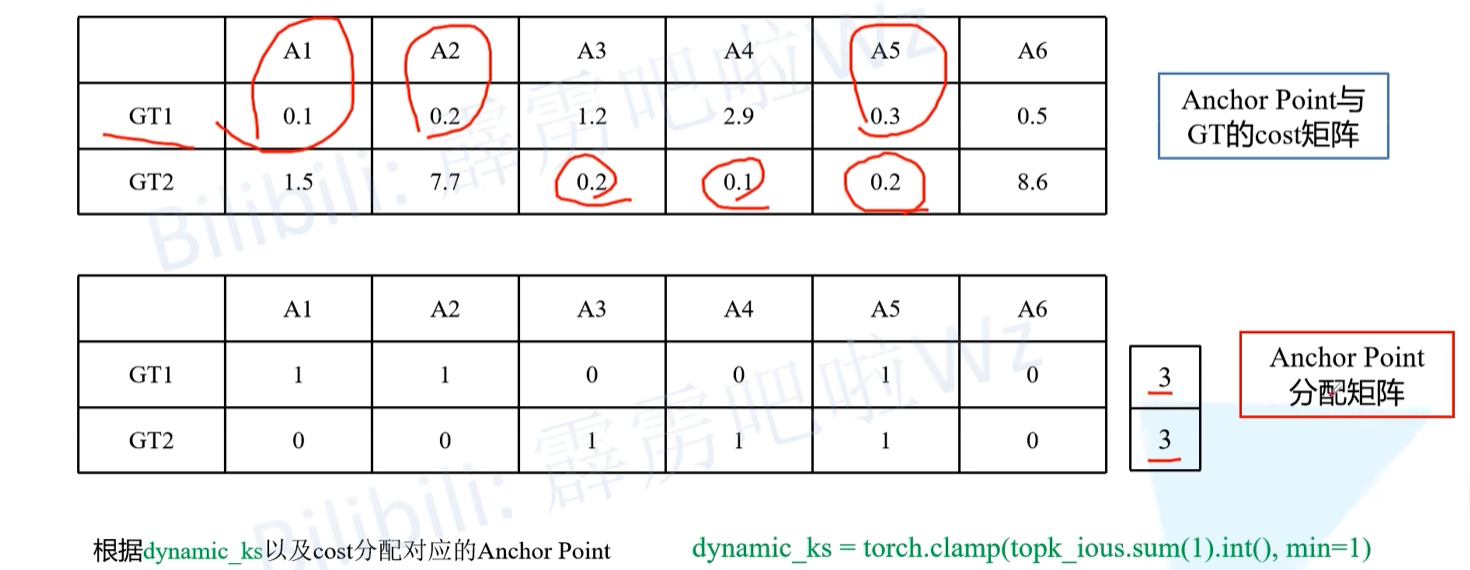
- 最后我们发现一个问题,两个GT都把正样本分配给了A5,但A5只能有一个正样本,这时就取cost最小的,因为0.3>0.2,所以最后正样本分配给GT2,GT1就只有两个正样本了。
- 剩下的全分为负样本