一、引言
在实际爬虫开发中,我们经常会遇到这样一种场景:网站的前端数据并非直接渲染在HTML中,而是通过AJAX异步加载JSON数据,再由JavaScript动态渲染页面。这种情况下,传统的HTML解析方式将完全失效,必须直接与后端API交互。
本文将深入分析一个针对 polymerupdate.com博客模块 的爬虫设计案例。该爬虫创新性地解决了 "JSON接口数据解析" 和 "对象数组遍历处理" 两大难题,实现了对博客数据的高效采集。
与之前案例的核心差异:
- 数据源差异:不再是HTML页面,而是JSON API接口
- 数据结构差异:返回的是对象数组,而非简单的URL列表
- 解析方式差异:使用JSONPath而非CSS选择器
- URL构建差异:基于对象属性动态构建URL
二、系统架构与核心流程
2.1 整体架构设计
该爬虫采用 "JSON API交互 + 对象数组处理 + 动态URL构建" 的架构,整体流程如下:
是
否
否
是
开始
时间范围计算
30天窗口
查询数据库已有记录
是否有新数据?
POST请求JSON接口
获取博客列表数据
结束流程
JSONPath解析
提取对象数组
输出数组
用于调试
循环处理每个对象
是否已存在?
从对象中提取ID
动态构建URL
抓取博客详情页
提取结构化数据
标题/时间/内容
存入数据库
2.2 数据流向图

三、关键技术难点与解决方案
难点一:JSON接口数据解析
问题描述:
该网站的博客列表并非通过HTML返回,而是通过AJAX请求JSON数据。传统的CSS选择器完全无法工作,必须使用JSONPath解析。
解决方案:
使用JSONPath从响应中提取对象数组:
javascript
// 抓取网站列表节点配置
{
"url": "https://www.polymerupdate.com/Blogs/ListingJson",
"method": "POST",
"body-type": "form-data",
"parameter-form-name": ["SearchCriteria[Search]: ", "SearchCriteria[Page]", "SearchCriteria[Type]"],
"parameter-form-value": ["", "${page}", "All"]
}
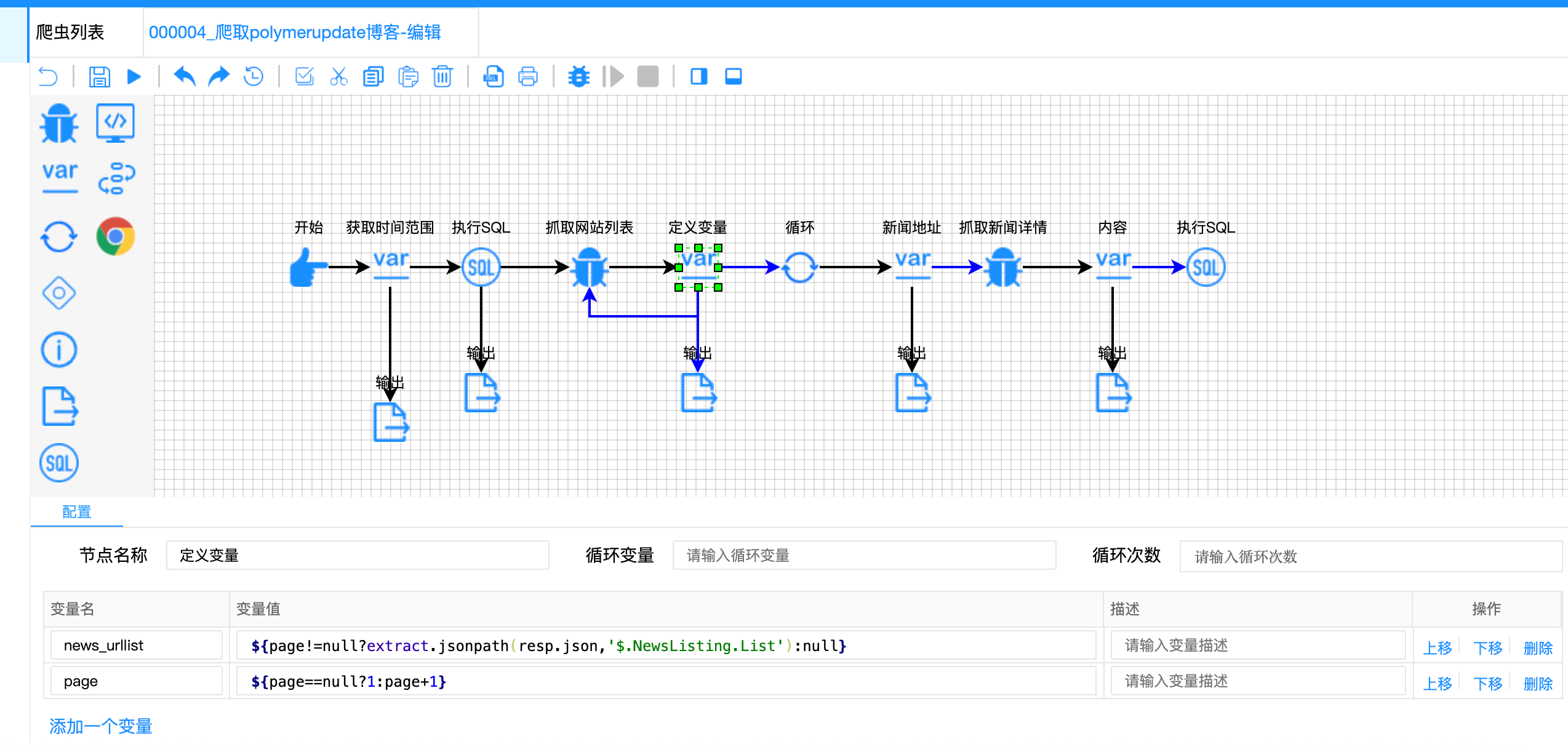
// 定义变量节点 - JSONPath解析
{
"variable-name": ["news_urllist", "page"],
"variable-value": [
// 从JSON响应中提取List数组
"${page!=null?extract.jsonpath(resp.json, '$.NewsListing.List'):null}",
"${page==null?1:page+1}"
]
}
JSON数据结构示意:
json
{
"NewsListing": {
"List": [
{
"Id": 12345,
"Title": "博客标题1",
"PublishDate": "2024-01-15",
"Url": "/blogs/details/12345"
},
{
"Id": 12346,
"Title": "博客标题2",
"PublishDate": "2024-01-14",
"Url": "/blogs/details/12346"
}
],
"TotalCount": 50,
"PageSize": 10
}
}JSONPath解析原理图:
JSON响应
提取结果
对象1, 对象2, 对象3, ...
JSONPath表达式
$.NewsListing.List
{
'NewsListing': {
'List':
{'Id':12345, 'Title':'...'},
{'Id':12346, 'Title':'...'},
{'Id':12347, 'Title':'...'}
}
}
难点二:对象数组的遍历处理
问题描述:
从JSON接口获取的不是简单的URL列表,而是一个包含多个属性的对象数组。循环时需要处理整个对象,而不仅仅是字符串。
解决方案:
将对象数组直接传递给循环节点,在循环中通过索引访问对象属性:
javascript
// 循环节点配置
{
"value": "循环",
"loopVariableName": "index",
"loopCount": "${list.length(news_urllist)}", // 遍历对象数组
"loopStart": "0",
"loopEnd": "-1"
}
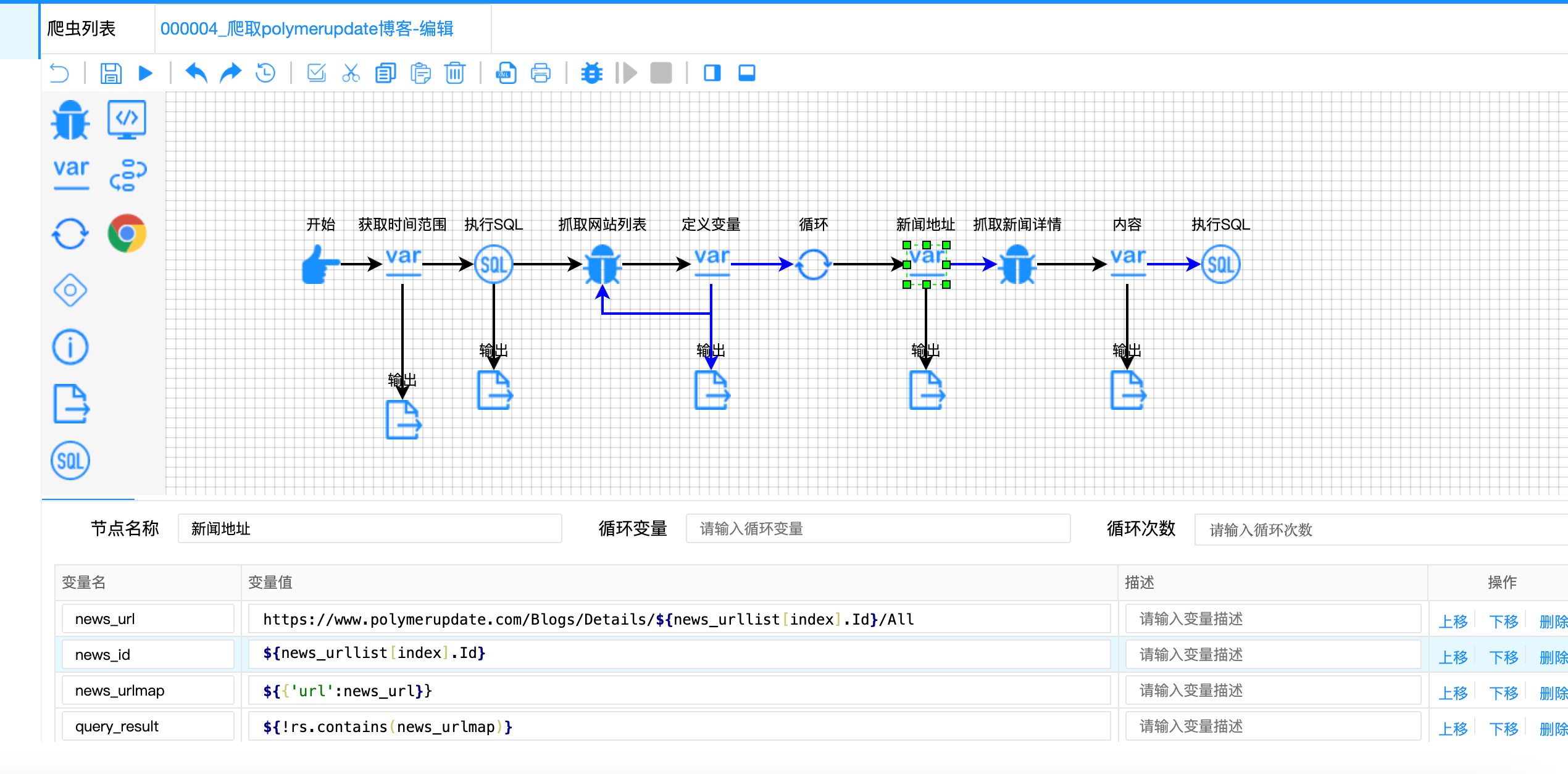
// 新闻地址节点 - 从对象中提取属性
{
"variable-name": ["news_url", "news_id", "news_urlmap", "query_result"],
"variable-value": [
// 动态构建URL:使用对象中的Id属性
"https://www.polymerupdate.com/Blogs/Details/${news_urllist[index].Id}/All",
// 直接获取对象中的Id属性
"${news_urllist[index].Id}",
"${{'url': news_url}}",
"${!rs.contains(news_urlmap)}"
]
}
### 难点三:动态URL构建
**问题描述:**
博客详情的URL格式为 `/Blogs/Details/{Id}/All`,需要从对象中提取Id属性动态构建。
**解决方案:**
使用模板字符串动态构建URL:
```javascript
// 动态URL构建
"https://www.polymerupdate.com/Blogs/Details/${news_urllist[index].Id}/All"
// 示例:当news_urllist[index].Id = 12345 时
// 生成:https://www.polymerupdate.com/Blogs/Details/12345/AllURL构建流程图:

难点四:30天时间窗口的业务适配
问题描述:
与前几个案例的7天、90天窗口不同,该爬虫设置了30天的时间范围。这反映了博客内容的更新频率适中。
解决方案:
动态时间范围计算:
javascript
// 获取时间范围节点
{
"variable-name": ["start_date", "end_date"],
"variable-value": [
"${date.format(date.addDays(date.now(),-30),'yyyy-MM-dd')}", // 30天前
"${date.format(date.addDays(date.now(),1),'yyyy-MM-dd')}" // 明天
]
}时间窗口对比:
| 案例 | 时间窗口 | 适用场景 |
|---|---|---|
| chemanalyst新闻 | 7天 | 高频更新的新闻 |
| polymerupdate新闻 | 7天 | 高频更新的新闻 |
| bioplasticsnews | 90天 | 低频更新的新闻 |
| polymerupdate博客 | 30天 | 中频更新的博客 |
难点五:JSON响应中的空值保护
问题描述:
首次请求时page为null,此时不应执行JSONPath解析。
解决方案:
使用三目运算符进行空值保护:
javascript
// 带空值保护的JSONPath提取
"${page!=null?extract.jsonpath(resp.json, '$.NewsListing.List'):null}"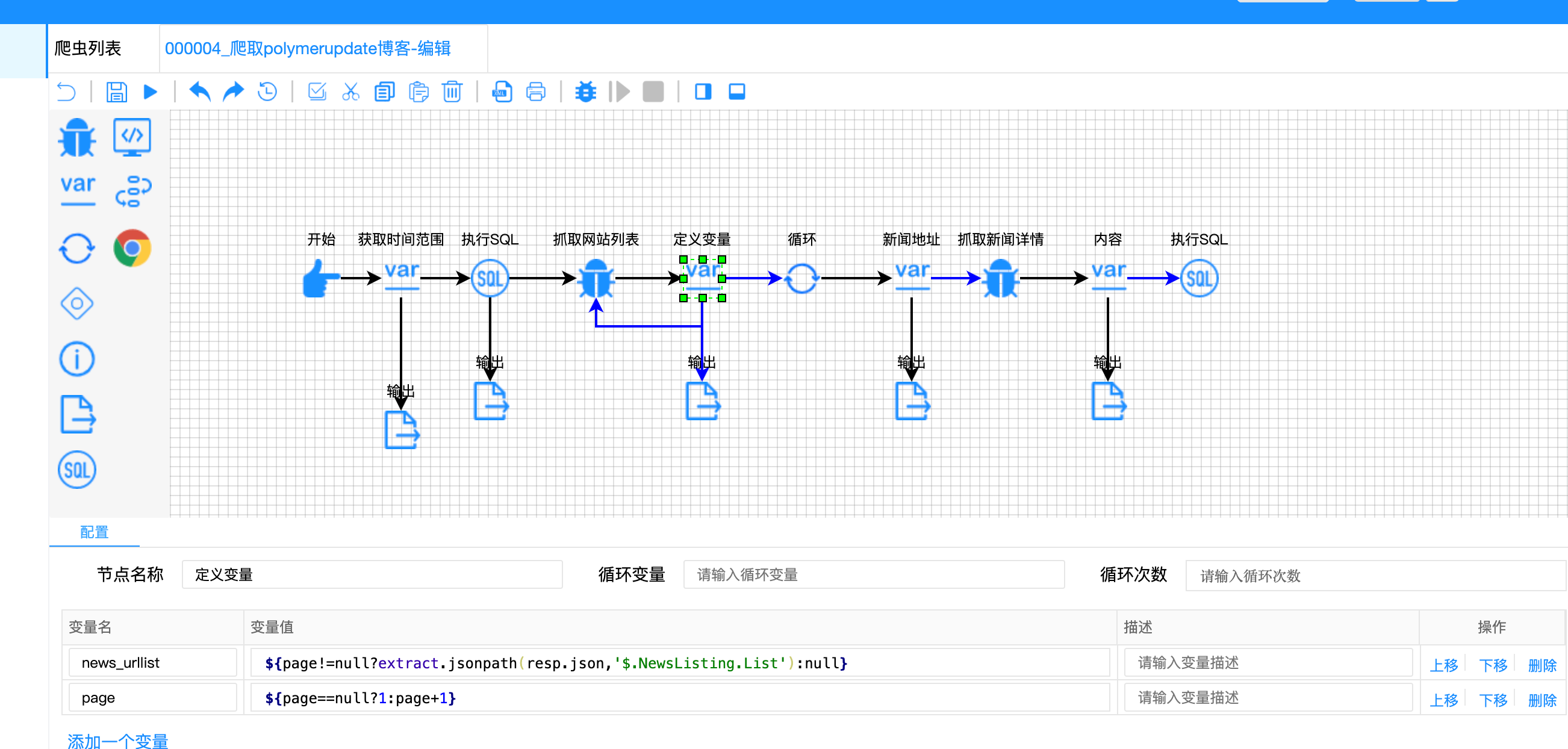
四、核心代码实现解析
4.1 JSON接口请求器
javascript
// 伪代码:JSON接口请求器
class JsonApiFetcher {
constructor(baseUrl) {
this.baseUrl = baseUrl;
}
async fetchList(page) {
const formData = new FormData();
formData.append('SearchCriteria[Search]', '');
formData.append('SearchCriteria[Page]', page);
formData.append('SearchCriteria[Type]', 'All');
const response = await fetch(this.baseUrl, {
method: 'POST',
body: formData,
headers: {
'Content-Type': 'application/x-www-form-urlencoded'
}
});
return await response.json();
}
extractListFromJson(json) {
// 使用JSONPath提取List数组
return json?.NewsListing?.List || [];
}
}4.2 对象数组处理器
javascript
// 伪代码:对象数组处理器
class ObjectArrayProcessor {
constructor(objectArray) {
this.objects = objectArray;
this.count = objectArray.length;
}
processAll() {
const results = [];
for (let i = 0; i < this.count; i++) {
const result = this.processOne(i);
if (result) {
results.push(result);
}
}
return results;
}
processOne(index) {
const obj = this.objects[index];
// 从对象中提取属性
const id = obj.Id;
const title = obj.Title;
const publishDate = obj.PublishDate;
// 动态构建URL
const url = `https://www.polymerupdate.com/Blogs/Details/${id}/All`;
return {
id: id,
title: title,
publishDate: publishDate,
url: url,
urlMap: { 'url': url }
};
}
}4.3 动态URL构建器
javascript
// 伪代码:动态URL构建器
class DynamicUrlBuilder {
constructor(baseTemplate) {
this.template = baseTemplate; // 例如: /Blogs/Details/${Id}/All
}
buildFromObject(obj) {
// 替换模板中的变量
let url = this.template;
for (const [key, value] of Object.entries(obj)) {
url = url.replace(`\${${key}}`, value);
}
return url;
}
buildWithId(id) {
return this.template.replace('${Id}', id);
}
}
// 使用示例
const builder = new DynamicUrlBuilder('/Blogs/Details/${Id}/All');
const url = builder.buildWithId(12345); // /Blogs/Details/12345/All五、与前三个案例的对比分析
5.1 核心差异点对比
| 维度 | polymerupdate博客 | polymerupdate新闻 | bioplasticsnews | chemanalyst |
|---|---|---|---|---|
| 数据源类型 | JSON API | HTML页面 | HTML页面 | HTML页面 |
| 解析方式 | JSONPath | CSS选择器 | CSS选择器 | CSS选择器 |
| 列表数据结构 | 对象数组 | URL字符串数组 | URL+ID双列表 | URL字符串数组 |
| URL构建方式 | 动态拼接(使用Id) | 直接使用 | 域名拼接 | 域名拼接 |
| ID来源 | 对象属性.Id | URL正则提取 | article的id属性 | URL正则提取 |
| 时间窗口 | 30天 | 7天 | 90天 | 7天 |
| 请求方式 | POST(JSON接口) | POST(表单) | GET(路径参数) | GET(URL参数) |
5.2 差异化技术难点
polymerupdate博客
JSON接口解析
对象数组处理
动态URL构建
30天窗口
bioplasticsnews
双列表协同提取
路径参数分页
90天窗口
polymerupdate新闻
POST表单分页
代理分层策略
chemanalyst
GET参数分页
23页全量抓取
5.3 技术演进路线
chemanalyst
基础HTML解析
polymerupdate新闻
POST表单+代理
bioplasticsnews
双列表协同提取
polymerupdate博客
JSON接口+对象数组
六、性能优化与最佳实践
6.1 JSON解析优化
javascript
// 安全的JSONPath提取
function safeJsonPathExtract(json, path) {
try {
const result = extract.jsonpath(json, path);
return result || []; // 为空时返回空数组
} catch (error) {
console.error('JSONPath解析失败:', error);
return [];
}
}6.2 对象属性访问保护
javascript
// 安全的对象属性访问
function safeGetProperty(obj, propertyName) {
if (!obj) return null;
return obj[propertyName] || null;
}
// 使用示例
const id = safeGetProperty(news_urllist[index], 'Id');
if (id) {
// 构建URL
}6.3 空值处理策略
| 场景 | 处理方式 | 目的 |
|---|---|---|
| JSON响应为空 | 返回空数组 | 循环跳过 |
| 对象属性缺失 | 返回null | 避免构建错误URL |
| 首次请求page=null | 不执行解析 | 避免空指针 |
七、总结与经验分享
7.1 核心收获
- JSON接口解析:当遇到AJAX加载的网站时,直接与后端API交互比解析HTML更高效
- 对象数组处理:将整个对象数组传递给循环,在循环内部分解属性,保持数据结构完整性
- 动态URL构建:基于对象属性动态构建URL,适应RESTful风格的API设计
- 时间窗口差异化:根据内容更新频率调整时间窗口,平衡覆盖范围和抓取效率
7.2 可复用经验
- 识别AJAX数据源:通过浏览器开发者工具的Network面板,找出真正的数据接口
- JSONPath学习:掌握JSONPath语法,高效提取JSON数据
- 对象属性访问:学会在循环中通过点语法访问对象属性
- 模板字符串 :使用
${}语法动态构建URL,代码更简洁
7.3 适用场景
该爬虫设计模式适用于:
- 采用AJAX加载数据的单页应用(SPA)
- 提供JSON数据接口的网站
- 需要处理复杂数据结构的场景
- RESTful API风格的后端服务
八、附录:核心配置对照表
| 节点类型 | 核心作用 | 关键技术点 |
|---|---|---|
| 获取时间范围 | 动态计算30天窗口 | date.addDays(now,-30) |
| 执行SQL(查询) | 获取已抓取记录 | like '%/Blogs/%' |
| 抓取网站列表 | POST请求JSON接口 | /ListingJson,表单参数 |
| 定义变量 | JSONPath解析 | extract.jsonpath() |
| 输出(对象数组) | 调试验证 | 输出整个对象数组 |
| 循环 | 遍历对象数组 | list.length()动态计算 |
| 新闻地址 | 对象属性提取+URL构建 | .Id属性访问,动态拼接 |
| 抓取新闻详情 | 获取博客详情页 | 无代理(与新闻模块对比) |
| 内容 | 结构化提取 | 标题/时间/内容 |
| 执行SQL(插入) | 存储数据 | source='polymerupdate' |
通过以上设计,该爬虫成功应对了JSON接口解析和对象数组处理的双重挑战,实现了对polymerupdate博客模块的高效增量抓取。其中的JSONPath解析、对象属性访问、动态URL构建等思路,对于处理AJAX数据源的爬虫开发具有很高的参考价值。