实验说明
全国新冠肺炎疫情数据上传到Hadoop里面的HDFS。
数据集来源:https://github.com/eAzure/Code-For-COVID-19-Data
- 数据集covid_data.tar.gz说明:
全国各省份/直辖市/特别行政区 所有的疫情数据(2020.1.1至2022.12.31)
数据集一共1224个json文件,每个文件命名规律:省份名称+月份名称,如浙江省202109.json
- 任务要求:
将covid_data.tar.gz上传到Linux虚拟机,并用tar命令解压
编写Java代码,将解压后的所有疫情数据上传到HDFS的/covid_data目录,并分类保存
分类方法:根据json文件名在HDFS /covid_data目录下自动新建各个省份的目录,并自动将相同省份的数据保存到同一个目录。如 /covid_data/浙江省/浙江省2021xx.json
解压文件
bash
#1.拖入文件到虚拟机中
#2.解压文件
#假设压缩包位于 /tmp/VMwareDnD/i9Viak/covid_data.tar.gz,解压到 /home/hadoop/covid_data:
mkdir -p /home/data/covid_data #创建文件目录
tar -xzf /tmp/VMwareDnD/i9Viak/covid_data.tar.gz -C /home/hadoop/covid_data整理文件
bash
#解压后,JSON 文件都在 /home/hadoop/covid_data/covid_data/ 下,移动到上一层:
cd /home/hadoop/covid_data
mv covid_data/* ./
rmdir covid_data验证本地文件
bash
ls /home/hadoop/covid_data/ | head #查看前几个文件名
ls /home/hadoop/covid_data/*.json | wc -l #应显示文件数量
#如果是其它格式的记得更换json为对应格式,如csv格式:
ls /home/hadoop/covid_data/*.csv | wc -l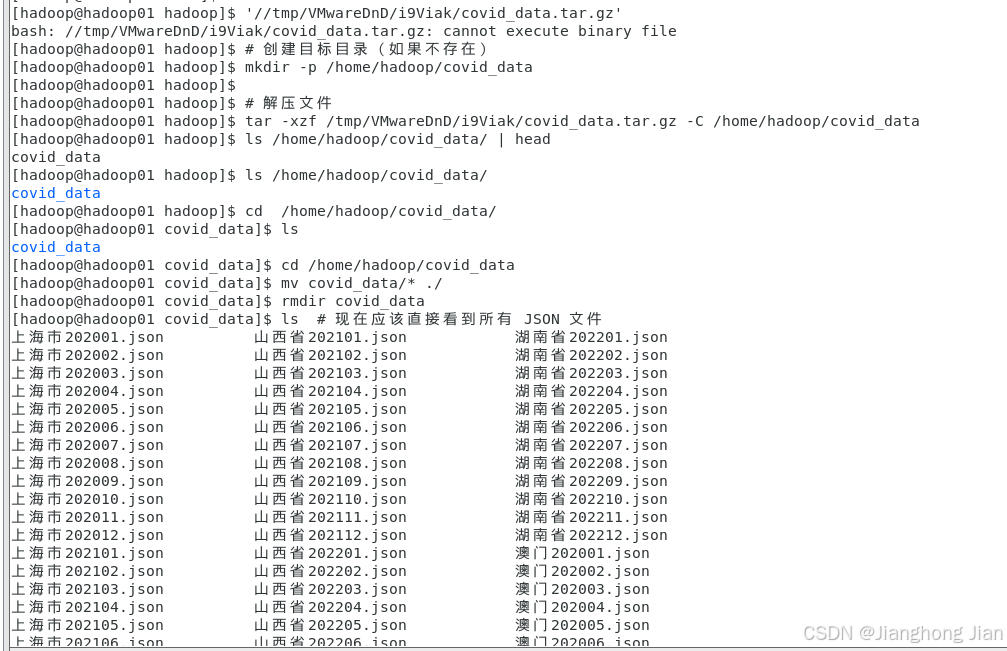
创建Java程序目录
bash
mkdir -p /home/hadoop/upload
cd /home/hadoop/upload
编写Java程序
bash
vim UploadToHDFS.java进入之后,若有东西可以先esc,再输入:%d进行全部删除,然后输入:set paste再按下i即可进入粘贴模式。
java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.File;
import java.io.FileInputStream;
import java.io.OutputStream;
public class UploadToHDFS {
public static void main(String[] args) {
// 本地数据目录(解压后的 JSON 文件所在目录)
String localDir = "/home/hadoop/covid_data";
// HDFS 根目录(题目要求)
String hdfsBase = "/covid_data";
Configuration conf = new Configuration();
// 如果 Hadoop 配置文件不在 classpath,请取消注释并修改为你的 NameNode 地址
// conf.set("fs.defaultFS", "hdfs://hadoop01:9000");
try (FileSystem fs = FileSystem.get(conf)) {
File dir = new File(localDir);
File[] files = dir.listFiles((d, name) -> name.endsWith(".json"));
if (files == null) {
System.err.println("未找到 JSON 文件!");
return;
}
for (File file : files) {
String fileName = file.getName();
// 提取省份名(假设文件名格式为"省份名+数字.json")
String province = extractProvince(fileName);
if (province == null) {
System.err.println("无法从文件名提取省份:" + fileName);
continue;
}
// 目标 HDFS 路径:/covid_data/省份名/文件名
Path hdfsPath = new Path(hdfsBase + "/" + province + "/" + fileName);
// 确保父目录存在
fs.mkdirs(hdfsPath.getParent());
// 上传文件
try (FileInputStream fis = new FileInputStream(file);
OutputStream os = fs.create(hdfsPath, true)) {
byte[] buffer = new byte[4096];
int bytesRead;
while ((bytesRead = fis.read(buffer)) != -1) {
os.write(buffer, 0, bytesRead);
}
}
System.out.println("上传成功:" + hdfsPath);
}
System.out.println("全部上传完成!");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 从文件名提取省份名
* 假设文件名格式为"省份名+数字.json",如"江西省202109.json"
*/
private static String extractProvince(String fileName) {
String nameWithoutExt = fileName.replace(".json", "");
int i = 0;
while (i < nameWithoutExt.length()) {
char c = nameWithoutExt.charAt(i);
if (Character.isDigit(c)) {
break;
}
i++;
}
if (i == 0) return null;
return nameWithoutExt.substring(0, i);
}
}编译程序
bash
javac -cp $(hadoop classpath) UploadToHDFS.java运行程序上传文件
bash
#确保HDFS服务已启动
jps #应看到NameNode、DataNode等进程
start-dfs.sh #若未启动,启动HDFS
#提前创建HDFS根目录并给权限(可选)
hdfs dfs -mkdir -p /covid_data
hdfs dfs -chmod 777 /covid_data
#运行上传程序
java -cp .:$(hadoop classpath) UploadToHDFS
上传成功后会显示:全部上传完成
验证上传结果
命令行查看
bash
hdfs dfs /covid_data #查看所有省份目录
hdfs dfs -ls /covid_data/浙江市 #查看某省份下的文件
hdfs dfs -ls -R /covid_data | grep json | wc -l #统计文件总数Web查看
访问你的hadoop:http://ip:9870(默认,或者你的对应端口)
bash
ifconfig
#其中ens33默认是你的hadoop的IP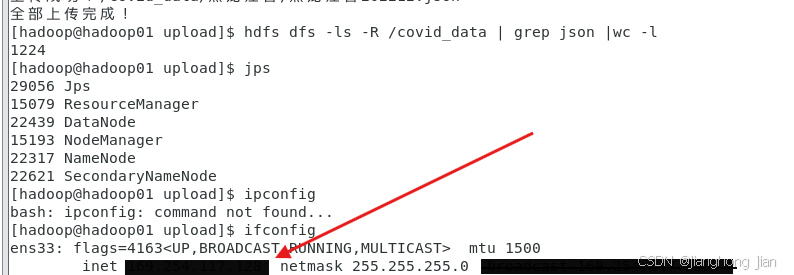
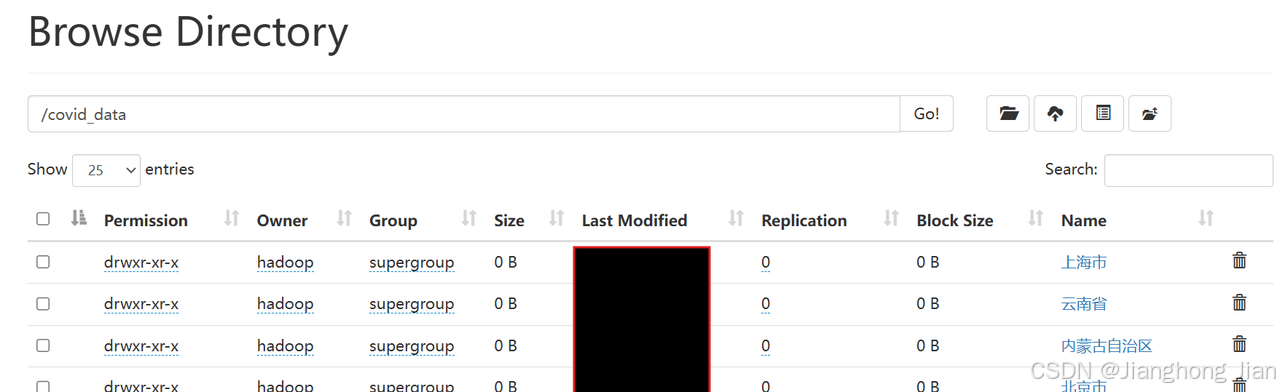 上传成功。
上传成功。