一、引言
在实际爬虫开发中,最复杂的场景之一莫过于:接口返回JSON数据,但JSON中又嵌套着HTML片段,需要先解析JSON,再从HTML中提取目标数据。这种"套娃"式的数据结构,对爬虫的解析能力提出了极高要求。
本文将深入分析一个针对 icis.com 新闻站点的爬虫设计案例。该爬虫创新性地解决了 "JSON嵌套HTML的双重解析" 和 "复杂URL正则提取" 两大核心难题,实现了对多层嵌套数据的高效采集。
与之前案例的核心差异:
- 数据源差异:JSON中嵌套HTML(前几个案例要么是纯HTML,要么是纯JSON)
- 解析层级差异:需要先JSONPath解析,再CSS选择器提取
- 正则复杂度差异:需要处理URL路径中的特定模式
- 分页控制差异:固定4页(反映内容总量有限)
二、系统架构与核心流程
2.1 整体架构设计
该爬虫采用 "JSON解析 → HTML提取 → 双重循环处理" 的架构,整体流程如下:
是
否
否
是
开始
时间范围计算
90天窗口
查询数据库已有记录
是否有新数据?
GET请求JSON接口
admin-ajax.php
结束流程
JSONPath解析
提取$.data.html
从HTML片段中
提取URL列表
输出URL列表
用于调试
循环处理每个URL
是否已存在?
复杂正则提取ID
抓取新闻详情页
提取结构化数据
标题/时间/作者/内容
存入数据库
2.2 数据流向图
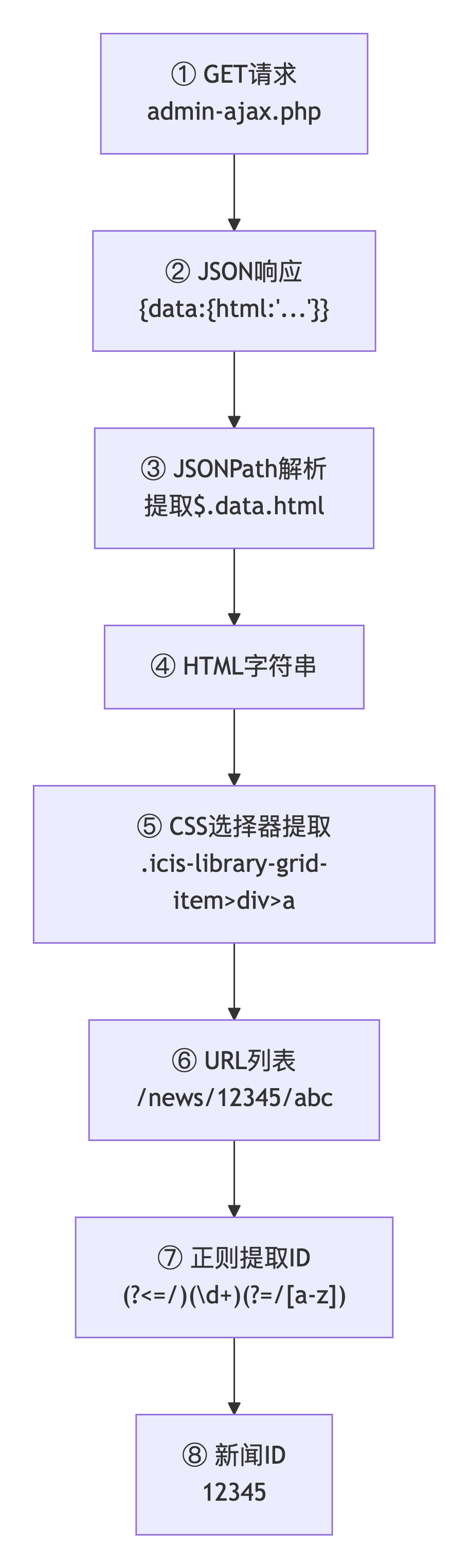
三、关键技术难点与解决方案
难点一:JSON嵌套HTML的双重解析
问题描述:
接口返回的是JSON数据,但真正的列表HTML被包裹在JSON的某个字段中。需要先解析JSON获取HTML字符串,然后再从HTML中提取URL。这种"套娃"结构无法用单一解析方式解决。
解决方案:
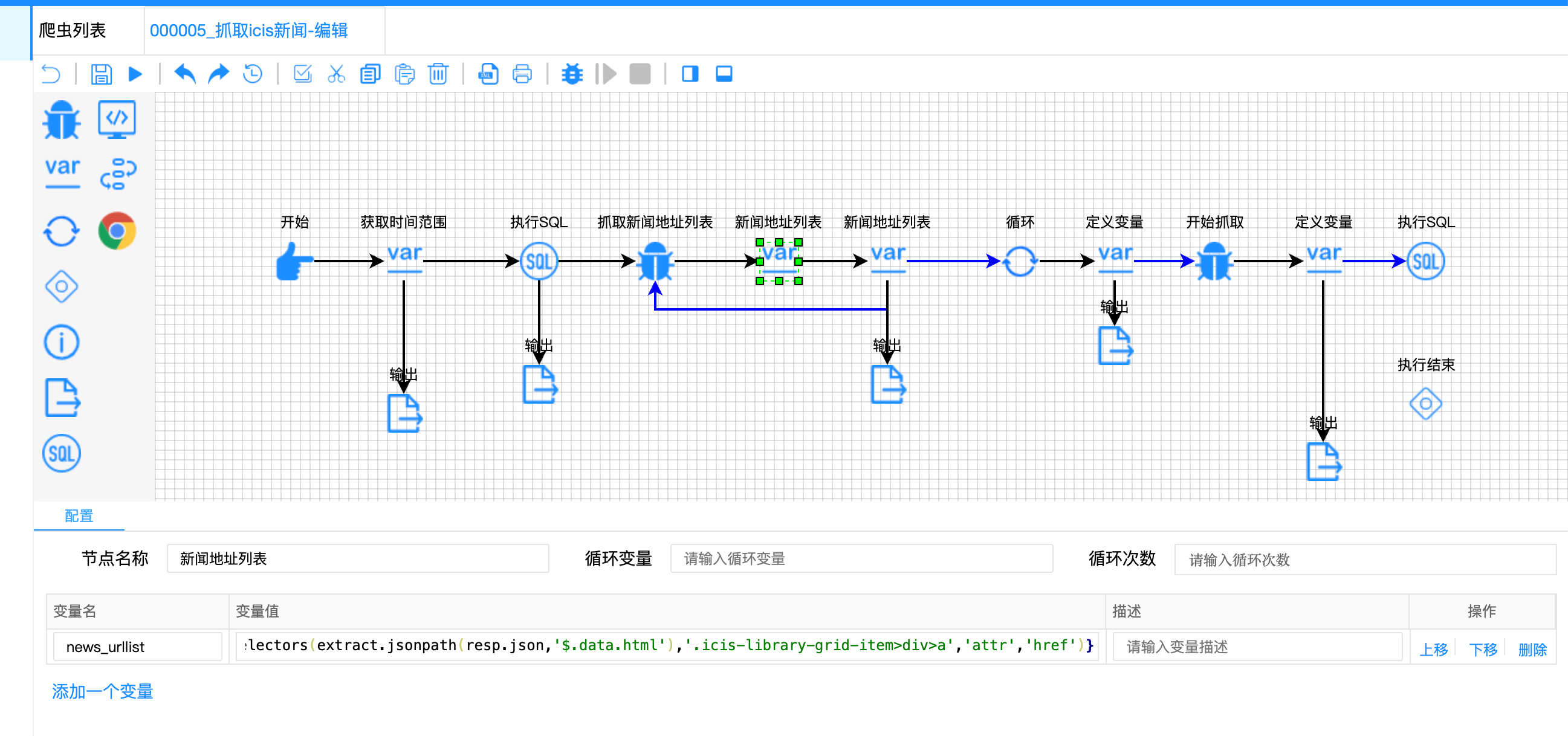
采用 "JSONPath + CSS选择器" 双层解析策略:
javascript
// 抓取新闻地址列表节点配置
{
"url": "https://www.icis.com/explore/wp/wp-admin/admin-ajax.php?action=icis-library-get-articles¤t_page=${page}",
"method": "GET"
}
// 新闻地址列表节点 - 双层解析
{
"variable-name": ["news_urllist"],
"variable-value": [
// 第一步:JSONPath提取HTML字符串
// 第二步:从HTML字符串中用CSS选择器提取href
"${page==null?null:extract.selectors(
extract.jsonpath(resp.json, '$.data.html'), // 先取JSON中的HTML
'.icis-library-grid-item>div>a', // 再从HTML中取链接
'attr',
'href'
)}"
]
}
双层解析原理图:
提取结果
HTML层
JSON层
JSONPath: $.data.html
CSS选择器
.icis-library-grid-item>div>a
CSS选择器
{
'data': {
'html': '
...
'
}
}
新闻2
/news/12345/abc
/news/12346/def
解析流程示意图:
JSONPath
$.data.html
CSS选择器
.item>a
JSON响应
HTML字符串
URL列表
难点二:复杂URL中的ID正则提取
问题描述:
新闻URL格式为 /news/12345/abc,需要提取中间的12345作为新闻ID。但URL中还有后续的字母部分,简单的数字提取会匹配到不需要的内容。
解决方案:
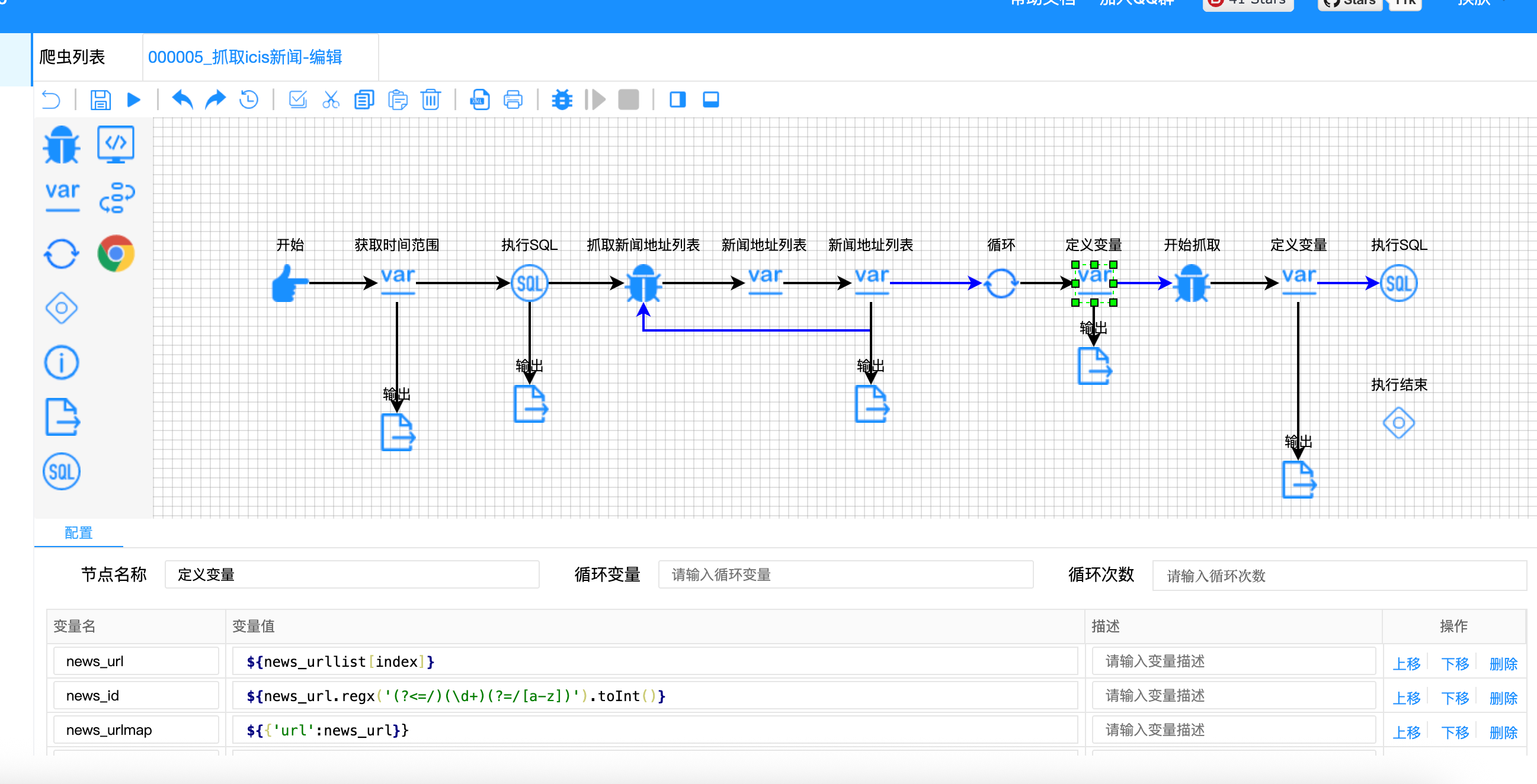
使用 "零宽断言" 精确匹配特定位置的数字:
javascript
// 定义变量节点 - 复杂正则提取
{
"variable-name": ["news_url", "news_id", "news_urlmap", "query_result"],
"variable-value": [
"${news_urllist[index]}",
// 正则解释: (?<=/) 匹配前面有斜杠的位置
// (\d+) 匹配连续数字
// (?=/[a-z]) 匹配后面有斜杠+小写字母的位置
"${news_url.regx('(?<=/)(\\d+)(?=/[a-z])').toInt()}",
"${{'url': news_url}}",
"${!rs.contains(news_urlmap)}"
]
}
正则提取原理图:
匹配过程
正则表达式
URL字符串
/news/
12345
/abc
(?<=/)
(\d+)
(?=/a-z)
定位到/news/后面
提取12345
确认后面是/abc
提取结果: 12345
正则分解说明:
| 正则部分 | 含义 | 作用 |
|---|---|---|
(?<=/) |
正向零宽断言 | 匹配位置:前面必须是斜杠 |
(\d+) |
捕获组 | 匹配连续数字并捕获 |
(?=/[a-z]) |
正向零宽断言 | 匹配位置:后面必须是斜杠+小写字母 |
示例匹配:
| URL | 匹配结果 |
|---|---|
| /news/12345/abc | ✅ 12345 |
| /news/12345/ | ❌ 不匹配(后面没有小写字母) |
| /blog/12345/abc | ❌ 不匹配(前面不是/news/) |
| /news/abc123/def | ❌ 不匹配(数字不在正确位置) |
难点三:固定页数控制(4页)
问题描述:
该网站新闻总量有限,只需要抓取前4页即可覆盖所有目标内容。
解决方案:
设置固定的分页上限:
javascript
// 分页控制条件(蓝色连线)
"condition": "${page<=4}"
// 定义变量节点 - 分页控制
{
"variable-name": ["page"],
"variable-value": ["${page==null?1:page+1}"]
}分页控制对比:
| 案例 | 分页上限 | 原因 |
|---|---|---|
| chemanalyst | 23页 | 全量抓取 |
| polymerupdate新闻 | 1页 | 仅第一页(最近新闻) |
| bioplasticsnews | 动态list.length | 每页固定30条 |
| polymerupdate博客 | 1页 | 仅第一页 |
| icis新闻 | 4页 | 内容总量有限 |
难点四:90天时间窗口
问题描述:
需要回溯90天的新闻数据,反映该网站新闻更新频率较低。
解决方案:
动态时间范围计算:
javascript
// 获取时间范围节点
{
"variable-name": ["start_date", "end_date"],
"variable-value": [
"${date.format(date.addDays(date.now(),-90),'yyyy-MM-dd')}", // 90天前
"${date.format(date.addDays(date.now(),1),'yyyy-MM-dd')}" // 明天
]
}难点五:多层嵌套的空值保护
问题描述:
由于涉及两层解析(JSONPath + CSS选择器),空值保护需要更加谨慎。
解决方案:
链式空值保护:
javascript
// 第一层:page为null时不执行任何解析
// 第二层:JSONPath结果为null时,selectors返回空列表
"${page==null?null:extract.selectors(
extract.jsonpath(resp.json, '$.data.html'),
'.icis-library-grid-item>div>a',
'attr',
'href'
)}"四、核心代码实现解析
4.1 双层解析器
javascript
// 伪代码:双层解析器
class NestedDataParser {
async fetchAndParse(page) {
// 1. 请求JSON接口
const jsonResponse = await this.fetchJson(page);
// 2. JSONPath提取HTML
const htmlString = this.extractHtmlFromJson(jsonResponse);
// 3. 从HTML中提取URL列表
const urlList = this.extractUrlsFromHtml(htmlString);
return urlList;
}
extractHtmlFromJson(json) {
// JSONPath: $.data.html
return json?.data?.html || '';
}
extractUrlsFromHtml(html) {
// 使用正则模拟CSS选择器
const regex = /<a[^>]+href="([^"]+)"[^>]*>/g;
const urls = [];
let match;
while ((match = regex.exec(html)) !== null) {
urls.push(match[1]);
}
return urls;
}
}4.2 复杂正则提取器
javascript
// 伪代码:复杂正则提取器
class RegexIdExtractor {
constructor(pattern) {
this.pattern = pattern; // (?<=/)(\d+)(?=/[a-z])
}
extractIdFromUrl(url) {
const match = url.match(this.pattern);
if (match) {
return parseInt(match[1]); // 捕获组(\d+)的内容
}
return null;
}
// 批量提取
extractAll(urls) {
return urls.map(url => this.extractIdFromUrl(url))
.filter(id => id !== null);
}
}
// 使用示例
const extractor = new RegexIdExtractor(/(?<=\/)(\d+)(?=\/[a-z])/);
const id = extractor.extractIdFromUrl('/news/12345/abc'); // 123454.3 链式解析安全处理器
javascript
// 伪代码:链式解析安全处理器
class SafeChainedParser {
static safeExtract(json, jsonPath, cssSelector, attribute) {
// 1. 检查JSON是否存在
if (!json) return [];
// 2. JSONPath提取
const html = this.safeJsonPath(json, jsonPath);
if (!html) return [];
// 3. 从HTML中提取
return this.safeCssExtract(html, cssSelector, attribute);
}
static safeJsonPath(json, path) {
try {
return extract.jsonpath(json, path);
} catch (error) {
console.error('JSONPath解析失败:', error);
return null;
}
}
static safeCssExtract(html, selector, attribute) {
try {
return extract.selectors(html, selector, attribute);
} catch (error) {
console.error('CSS提取失败:', error);
return [];
}
}
}五、与前四个案例的对比分析
5.1 核心差异点对比
| 维度 | icis新闻 | polymerupdate博客 | polymerupdate新闻 | bioplasticsnews | chemanalyst |
|---|---|---|---|---|---|
| 数据源类型 | JSON嵌套HTML | 纯JSON | HTML | HTML | HTML |
| 解析方式 | JSONPath + CSS | JSONPath | CSS选择器 | CSS选择器 | CSS选择器 |
| 解析层级 | 2层 | 1层 | 1层 | 1层 | 1层 |
| 正则复杂度 | 复杂(零宽断言) | 简单 | 简单 | 简单 | 简单 |
| 分页上限 | 4页 | 1页 | 1页 | 动态 | 23页 |
| 时间窗口 | 90天 | 30天 | 7天 | 90天 | 7天 |
| ID提取方式 | 复杂正则 | 对象属性 | URL正则 | article的id属性 | URL正则 |
5.2 差异化技术难点
icis新闻
JSON嵌套HTML解析
复杂正则提取
4页固定分页
polymerupdate博客
JSON接口解析
对象数组处理
bioplasticsnews
双列表协同提取
路径参数分页
polymerupdate新闻
POST表单分页
代理分层策略
chemanalyst
GET参数分页
23页全量抓取
5.3 解析复杂度演进
纯HTML解析
chemanalyst
纯JSON解析
polymerupdate博客
JSON嵌套HTML
icis新闻
六、性能优化与最佳实践
6.1 双层解析优化
javascript
// 缓存HTML字符串避免重复解析
class CachedParser {
constructor() {
this.htmlCache = new Map();
}
parse(json) {
const html = json?.data?.html;
if (!html) return [];
// 使用HTML作为缓存key
if (this.htmlCache.has(html)) {
return this.htmlCache.get(html);
}
const urls = extract.selectors(html, '.item>a', 'attr', 'href');
this.htmlCache.set(html, urls);
return urls;
}
}6.2 正则表达式优化
| 正则类型 | 表达式 | 性能 | 适用场景 |
|---|---|---|---|
| 贪婪匹配 | .* |
低 | 不推荐 |
| 懒惰匹配 | .*? |
中 | 一般场景 |
| 零宽断言 | (?<=/)(\d+)(?=/) |
高 | 精确定位 |
6.3 空值处理链
javascript
// 完整的空值处理链
const urls = page != null
? (json?.data?.html
? extract.selectors(json.data.html, '.item>a', 'attr', 'href')
: [])
: [];七、总结与经验分享
7.1 核心收获
- 双层解析技术:JSON + HTML嵌套结构的处理技巧
- 复杂正则提取:零宽断言精确定位URL中的ID
- 链式空值保护:多层解析时的安全处理
- 固定分页控制:根据内容总量灵活设置分页上限
7.2 可复用经验
- 识别嵌套结构:通过浏览器开发者工具分析数据来源,识别是否是JSON嵌套HTML
- 分层解析策略:先JSONPath后CSS,分步处理
- 正则精确匹配:使用零宽断言提高提取精度
- 空值保护链:每层解析都要考虑空值情况
7.3 适用场景
该爬虫设计模式适用于:
- 接口返回JSON但包含HTML片段的网站
- URL结构复杂需要精确定位的场景
- 需要多层解析的数据源
- 内容总量可控的网站
八、附录:核心配置对照表
| 节点类型 | 核心作用 | 关键技术点 |
|---|---|---|
| 获取时间范围 | 动态计算90天窗口 | date.addDays(now,-90) |
| 执行SQL(查询) | 获取已抓取记录 | like '%icis.com%' |
| 抓取新闻地址列表 | GET请求JSON接口 | admin-ajax.php?action=... |
| 新闻地址列表 | 双层解析 | JSONPath + CSS选择器 |
| 新闻地址 | 复杂正则提取 | (?<=/)(\d+)(?=/a-z) |
| 开始抓取 | 获取新闻详情页 | 无代理 |
| 内容 | 结构化提取 | 标题/时间/作者/内容 |
| 执行SQL(插入) | 存储数据 | source='icis' |
通过以上设计,该爬虫成功应对了JSON嵌套HTML和复杂正则提取的双重挑战,实现了对icis.com新闻网站的高效增量抓取。其中的双层解析技术、复杂正则零宽断言等思路,对于处理多层嵌套数据结构的爬虫开发具有很高的参考价值。