论文:https://arxiv.org/abs/2106.09685
ABSTRACT
LoRA(Low-Rank Adaptation,低秩自适应)是一种参数高效微调(PEFT)技术。它的核心思想是:冻结预训练大模型的原始权重,只训练少量新增的"旁路"参数,从而以极低的成本实现模型微调。
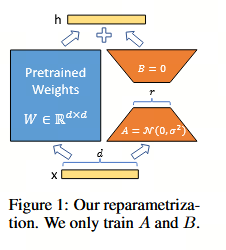
论文的核心假设是:模型在微调时的权重更新矩阵 ΔW\Delta WΔW 是低秩(Low-Rank)的。这意味着巨大的参数变化实际上可以用极小的"内在维度"来表征。
- 数学表达 :将全量更新 ΔW\Delta WΔW 分解为两个小矩阵的乘积:
Wnew=Wold+ΔW=Wold+BAW_{new} = W_{old} + \Delta W = W_{old} + BAWnew=Wold+ΔW=Wold+BA
其中 B∈Rd×rB \in \mathbb{R}^{d \times r}B∈Rd×r, A∈Rr×kA \in \mathbb{R}^{r \times k}A∈Rr×k,且秩 r≪min(d,k)r \ll \min(d,k)r≪min(d,k)。
Section 4.1 (Method)
理解算法原理的核心

Section 4.2 (Applying to Transformer)
详细说明了 LoRA 应优先应用于 WqW_qWq 和 WvW_vWv 矩阵

Experiments
提供了关于秩(rank)选择、α\alphaα 缩放因子的实证分析。
论文实践-YOLO
1. 数学原理:低秩分解
LoRA 基于一个关键假设:权重更新矩阵是低秩的。这意味着模型在适应新任务时,不需要修改所有参数,只需要一个很小的"增量"。
- 传统微调 :更新整个权重矩阵 WWW(参数量巨大)。
- LoRA 微调 :Wnew=Wold+ΔWW_{new} = W_{old} + \Delta WWnew=Wold+ΔW,其中 ΔW\Delta WΔW 被分解为两个小矩阵的乘积:ΔW=A×B\Delta W = A \times BΔW=A×B。
- A (降维矩阵)和 B(升维矩阵)的秩(rank)远小于原始权重矩阵的维度。
- 效果 :原本需要训练 m×nm \times nm×n 个参数,现在只需训练 (m+n)×r(m + n) \times r(m+n)×r 个参数(rrr 是极小的秩)。
2. 架构实现:旁路适配
在代码层面,LoRA 不是修改原有层,而是插入新的 Adapter(适配器):
python
# 原始前向传播
output = W * x
# 加入 LoRA 后的前向传播
output = W * x + (A * B) * x关键特性:
- 冻结原权重 :WWW 保持预训练状态,不计算梯度。
- 仅训练新增参数 :只更新 AAA 和 BBB 的权重。
- 可合并 :训练完成后,可以将 ΔW\Delta WΔW 合并回 WWW,推理时零开销。
在 Ultralytics 的 YOLO 配置文件中,LoRA 通常通过以下参数控制:
yaml
# 启用 LoRA
lora: true
# 关键配置项
lora_rank: 4 # 秩 (r),通常为 4, 8, 16
lora_alpha: 8 # 缩放系数 (alpha)
lora_dropout: 0.05 # 防止过拟合
# 指定应用层(YOLO 特有)
lora_targets: ['model.0.conv', 'model.1.cv2.conv'] # 通常针对卷积层或注意力层| 参数 | 作用 | 建议值(YOLO) |
|---|---|---|
| rank ( r ) | 控制适配器的参数量,越大能力越强但越慢 | 4 / 8 / 16 |
| alpha | 控制更新权重的缩放比例 | 通常设为 rank 的 2 倍 |
| dropout | 正则化,防止小数据集过拟合 | 0.05 - 0.1 |
对于目标检测任务,LoRA 具有独特的优势:
- 任务适配:YOLO 预训练模型(如 COCO)泛化能力已很强,LoRA 只需微调少量参数即可适应特定场景(如医疗影像、工业质检)。
- 资源友好:目标检测模型通常较大(如 YOLOv8l、YOLOv9x),全量微调成本极高,LoRA 是性价比最高的方案。
- 快速迭代:允许在单张消费级 GPU 上快速实验多个微调任务。