
导读
---------------------------------------------------------------------------------------------------------------------------------
用多模态大模型(LMM)做工业异常检测,不只是"有没有缺陷"的二分类------还需要回答"是什么类型的缺陷""缺陷在哪里""为什么会出现这个缺陷"。但现有 LMM 缺乏工业领域的专门知识,直接用 CoT 推理甚至会让异常判别准确率从 71.39% 掉到 61.90%------不懂领域就推理,越推越错。
Judo(Juxtaposed Domain-oriented Multimodal Reasoner)提出了一个三阶段渐进训练方案:先通过正常-缺陷图像对比学习建立视觉领域感知,再通过 SFT 注入领域知识,最后用多奖励 GRPO 强化学习统一视觉定位和领域推理。基于 Qwen2.5-VL-7B,Judo 在 MMAD 基准上达到 81.20% 的平均准确率,超越 GPT-4o 和基线 Qwen2.5-VL-7B(72.56%)。本文将拆解 Judo 的三阶段训练设计和实验结果。
论文信息
---------------------------------------------------------------------------------------------------------------------------------
标题: Judo: A Juxtaposed Domain-oriented Multimodal Reasoner for Industrial Anomaly QA
机构: 成均馆大学、首尔国立大学
发表: ICLR 2026(Conference Paper)
OpenReview: https://openreview.net/forum?id=XW4mROtaVb
骨干模型: Qwen2.5-VL-7B
一、直接用 LMM 做工业异常 QA,为什么不够?
---------------------------------------------------------------------------------------------------------------------------------
工业异常检测的问答不只是"有没有缺陷",MMAD 基准定义了四类任务:
| 任务 | 说明 |
|---|---|
| 异常判别 | 二分类:样本是否有缺陷 |
| 缺陷分类 | 判断缺陷类型 |
| 缺陷定位 | 确定缺陷的精确位置 |
| 缺陷描述 | 描述缺陷的视觉特征 |
| 缺陷分析 | 分析缺陷的潜在影响 |
| 物体分类 | 判断产品品类 |
| 物体分析 | 分析产品整体状态 |
通用 LMM 在这些任务上有两个核心问题:
问题一:缺乏领域知识。通用模型不知道"电缆的走线方式"是否偏离标准布局,也不知道"连接器的对齐状态"是否属于正常装配公差范围。
问题二:CoT 推理可能适得其反。一个反直觉的发现是:在没有领域知识支撑的情况下,让模型做 Chain-of-Thought 推理,异常判别准确率反而从 71.39% 降到 **61.90%**。模型在推理过程中引入了错误的领域假设,越推越偏。
现有方法要么通过提示(prompt)外部注入领域知识(没有内化,效果不稳定),要么直接用 GRPO 做强化学习(缺乏领域基础,收益有限)。
二、三阶段渐进训练:从视觉对比到领域推理
---------------------------------------------------------------------------------------------------------------------------------
Judo 的核心设计是三阶段渐进学习,每个阶段解决一个特定问题:
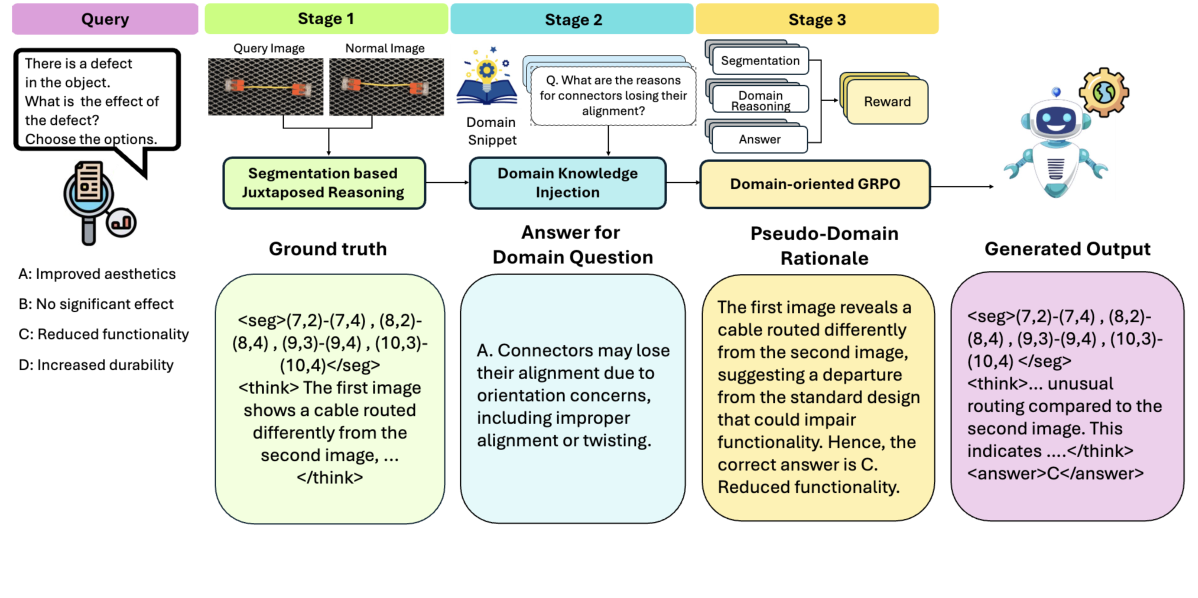
阶段一:并置分割学习(SegJux)
目标:建立领域视觉感知能力。
核心思路是让模型学会用正常图像作为参考来识别缺陷。训练时,模型同时接收一张待检图像和一张对应的正常图像,通过对比两者的差异来定位缺陷区域。
这个设计的价值在于:正常样本包含了丰富的"什么是正常"的领域信息(每类产品的正常外观、纹理、颜色分布),之前的方法大多只在推理时才用正常样本做参考,而 Judo 在训练阶段就利用这些信息。
效果:缺陷定位准确率从基线的61.17% 提升到 73.01%。训练 8 个 epoch。

阶段二:领域知识注入(DomInj)
目标:将工业领域知识内化到模型参数中。
通过监督微调(SFT),将品类特定的工业知识(缺陷类型、特征、后果等)注入模型。与通过 prompt 外部注入不同,SFT 将知识写入模型权重,使其成为模型的内在能力。
训练 2 个 epoch。根据论文消融实验,在 GRPO 基础上加入领域知识注入后,平均准确率从 77.29% 提升到 79.82%,比单纯用 RAG(检索增强生成)外部注入(76.29%)高出 3.5 个百分点,验证了将领域知识内化到模型参数比推理时外挂更有效。
阶段三:领域导向 GRPO(GRPOdom)
目标:统一视觉定位和领域推理。
使用多奖励函数的 Group Relative Policy Optimization,论文设计了三个奖励组件:
领域推理奖励(Domain Reasoning Reward):通过余弦相似度衡量模型生成的推理过程与"伪领域理据"(pseudo-domain rationale,由 GPT-4o 基于完整上下文生成)的语义一致性。关键在于不只要求答案正确,还要求推理过程与领域知识一致
分割奖励(Segmentation Reward):通过 F1 score 评估模型输出的缺陷区域坐标与真实标注的重合度
选择与结构对齐奖励(Choice and Structural Alignment Reward):包含选择正确性、输出格式规范性、推理结构合理性三个子奖励,确保模型输出可解析且逻辑连贯
训练 14 个 epoch。完成后平均准确率达到 81.20%。
为什么三阶段顺序不能打乱?
从消融实验可以看出渐进设计的必要性:直接用 vanilla GRPO(相当于 AnomalyR1 的做法)只能达到 77.29%;加入领域知识注入(DomInj)提升到 79.82%;再加入并置分割(SegJux)提升到 80.35%;最后换成领域导向的 GRPO^dom 达到 81.20%。每个阶段都有可度量的贡献。
三、MMAD 基准:39,672 个问题、38 类产品
---------------------------------------------------------------------------------------------------------------------------------
MMAD(Multimodal Large Language Models in Industrial Anomaly Detection)是当前工业异常 QA 的主要基准:
| 维度 | 数据 |
|---|---|
| 问题总数 | 39,672 |
| 图像总数 | 8,366 |
| 产品类别 | 38 |
| 数据来源 | MVTec AD、MVTec LOCO AD、VisA、GoodsAD |
| 任务类型 | 7 个子任务:异常判别、缺陷分类、缺陷定位、缺陷描述、缺陷分析、物体分类、物体分析 |
四、实验结果:7B 模型超越 GPT-4o
---------------------------------------------------------------------------------------------------------------------------------

各阶段的渐进提升
| 配置 | 平均准确率 |
|---|---|
| Qwen2.5-VL-7B(基线) | 72.56% |
| + GRPO(vanilla,无领域阶段) | 77.29% |
| + GRPO + DomInj(加入领域知识注入) | 79.82% |
| + GRPO + SegJux + DomInj(加入并置分割) | 80.35% |
| + GRPO^dom + SegJux + DomInj(完整 Judo) | 81.20% |
与其他模型的对比
论文实验结果显示,在 MMAD 的 7 个子任务上,Judo(81.20%)超越了 GPT-4o 和 Qwen2.5-VL-7B 基线(72.56%)。Judo 的优势集中在缺陷分类、定位、描述和分析四个需要领域知识的子任务上。
论文同时指出,在相对简单的异常判别(二分类)任务上,Judo(65.04%)并不占优,Kimi-VL 等更大规模的模型在这个子任务上表现更好。这说明 Judo 的提升主要来自领域推理能力,而非通用视觉感知。
CoT 推理的"双刃剑"效应
| 设置 | 异常判别准确率 |
|---|---|
| 直接回答(无 CoT) | 71.39% |
| CoT 推理(无领域知识) | 61.90%(-9.49%) |
| Judo CoT 推理(有领域知识) | 提升 |
没有领域支撑的 CoT 推理让准确率暴跌 9.5%------模型在推理过程中引入了不靠谱的假设。Judo 通过领域知识注入和领域推理奖励解决了这个问题。
五、总结与思考
---------------------------------------------------------------------------------------------------------------------------------
Judo 的核心贡献是用三阶段渐进训练将领域知识系统性地注入 LMM:
**阶段一:**建立视觉对比能力(正常 vs 缺陷)
**阶段二:**内化领域知识到模型参数
**阶段三:**用多奖励 GRPO 统一视觉和推理
最有价值的发现是 CoT 推理在没有领域知识时会适得其反(-9.5%),这对试图用 LMM 做工业检测的工作有警示意义:不是给模型加上 CoT 就能提升,领域知识是前提。
与同期工作的关系:论文提到 AnomalyR1 和 OmniAD 是同方向的近期工作。AnomalyR1 首次将 GRPO 引入异常检测,OmniAD 统一了异常分割和推理。Judo 在此基础上增加了领域知识的系统性内化。